Случайным образом пару недель назад я наткнулся на прошлогоднюю статью товарища System32 про Transparent Page Sharing, что собственно и подтолкнуло меня нарушить свой график подготовки к VCAP-DCA и совершить глубокое погружение в совершенно незнакомую для меня доселе технологию управления памяти в vSphere, а если быть более точным — в TPS. Коллега System32 очень толково изложил общие принципы работы с памятью, алгоритм работы TPS, но при этом сделал не совсем верные выводы. Еще больше меня раззадорили вопросы в комментариях, на которые никто не ответил, касательно высоких значений SHRD памяти в esxtop, при том, что согласно этой же статье при использовании Large Pages технология TPS попросту не будет работать. Вообщем обнаружились серьезные противоречия между красивой теорией и практикой.
После 4-5 дней копания в форумах Vmware, чтения Вики, западных блогеров, у меня кое что отложилось в голове и я смог наконец то ответить на вопросы из комментариев. Чтобы как-то упорядочить свежие знания я решил написать несколько статей на эту тему в своем англоязычном блоге. Я также пошерстил Хабр на предмет новых статей на эту тему, но к моему удивлению с 2010 года ничего нового не обнаружил. Поэтому и решил ради постоянно читаемого Хабра и возможности активно участвовать в комментариях перевести свою же статью про Transparent Page Sharing и нюансы его использования на системах с процессорами семейства Nehalem/Opteron и с установленной ESX(i) 4.1.
Мне не хочется делать статью слишком длинной, поэтому я настоятельно рекомендую вам (особенно если вы vSphere админ) сначала прочитать статью, ссылку на которую я дал в самом начале. Но все таки в некоторых мелочах я повторюсь.
Итак, для чего нужен TPS?
Ответ достаточно банален — сэкономить оперативной памяти, показать виртуальным машинам больще памяти, чем есть на самом хосте, ну и следовательно обеспечивать более высокий уровень консолидации.
Как он работает?
Исторически сложилось так, что в x86 системах вся память разделяется на 4 кбайтные блоки, так называемые страницами. Когда у вас на одном ESX хосте крутятся 20 виртуальных машин (ВМ) с одной и той же ОС можно легко представить, что у этих ВМ достаточно много идентичных страниц памяти. Чтобы обнаружить одинаковые страницы на ESX хосте запускается TPS процесс с периодичностью в 60 минут. Он сканирует абсолютно все страницы в памяти и вычисляет хэш каждой страницы. Все хэши складываются складываются в одну таблицу и проверяются кернелом на предмет совпадения. Чтобы избежать проблемы под названием hash collision при обнаружении одинаковых хэшей кернел сверяет соответствующие страницы побитово. И только убедившись, что они 100% одинаковы кернел оставляет одну единственную копию страницы в памяти, а все обращения на удаленные страницы переправляются на ту самую первую копию. Если же какой либо из ВМ вздумается изменить что либо в этой странице, то ESX создаст еще одну копию оригинальной страницы и уже с ней позволит работать ВМ, которая отправила запрос на изменение. Посему в терминологии Vmware такой тип страниц называется Copy-on-write (COW). Процесс сканирования памяти на современных серверах с подчас сотнями гигабайт оперативной памяти может длиться достаточно долго, поэтому не стоит ожидать немедленных результатов.
NUMA и TPS
NUMA — это достаточно любопытная технология разделения доступа к памяти между процессорами. На наше счастье последние версии ESX достаточно умны и знают, что для эффективной на NUMA системах TPS должен работать только в пределах NUMA нода. В принципе, если в ESX поправить значение VMkernel.Boot.sharePerNode, то можно заставить TPS сравнивать страницы в пределах всей памяти, а не отдельных NUMA нодов. Понятно, что в этом случае можно добиться более высоких значений SHARED памяти, но вам надо учитывать возможное серьезное падение производительности. Например, представьте, что в вашем ESX хосте 4 Xeon 5560 процессора, то есть 4 NUMA нода и каждый содержит идентичную копию страницы памяти. Если TPS оставит одну копию в первом ноде и удалит 3 остальные, то это значит, что каждый раз, когда какой либо из ВМ работающих на этих 3 нодах понадобится искомая страница памяти, 3 процессорам придется обращаться к ней не через локальную и очень быструю шину памяти, а через общую и медленную. Чем больше у вас таких страниц, тем меньше пропускной способности остается на общей шине, ну и следовательно больше страдает производительность ваших виртуальных машин.
Zero Pages
Одной из новых замечательных функций представленных в vSphere 4.0 было распознавание нулевых страниц. В принципе это обычная страница, которая от начала до конца заполнена нулями. Каждый раз, когда включается Windows ВМ вся память обнуляется, это помогает ОС определить точные размеры доступной ей памяти. ESX может моментально обнаруживать такие страницы у виртуальных машин, и вместо бесполезного процесса выделения физической памяти под нулевые страницы, а потом удаления их в процессе работы TPS, ESX сразу все такие страницы перенаправляет на одну единственную нулевую страницу. Если вы запустите esxtop и проверите значения памяти для только что запущенной ВМ, вы обнаружите, что значения ZERO и SHRD практически идентичны.

Однако здесь важно отметить то, что эту новую замечательную функцию ESX 4.0 (и старше) умеет применять только на процессорах с EPT (Intel) или RVI (AMD) технологиями. На эту тему есть пара отличнейших статей на сайте Kingston (часть первая, часть вторая). Если вкратце, то там рассказывается и показывается как на новых процессорах нулевые страницы распознаются без выделения им физической памяти, а на старых процессорах физическая память таки выделяется, и только когда TPS полноценно отработает начинается снижение используемой физической памяти. Для обычных vSphere ферм это в принципе не критично, но для VDI инфрастуктур, где у вас могут быть сотни одновремено стартующих виртуальных машин это архиполезно.
Пара особенностей работы TPS с нулевыми страницами.
1. В OC Windows существует технлогия называемая «кэширование файловой системы» (прощу прощения если кое где мой перевод названий и определений грешит неточностями). Используя определение MS мы можем сказать, что «Кэширование файловой системы это область памяти, которая хранит недавно используемую информацию для быстрого доступа». Кэш этот располагается в адресном пространстве кернела, и поэтому образом в 32битных системах его размер ограничен 1 гигабайтом. Однако в 64битных системах его размер может достигать 1 терабайта (пруф). В принципе технология очень полезная для производительности, но если мы имеем ситуацию с виртуальными машинами и нулевыми большими страницами (2 мегабайта), то значение SHRD в esxtop у вас будет стремиться к нулю.
Скриншот выше показывал значение esxtop сразу после запуска Windows 2008 R2 виртуальной машины, а вот что показывал esxtop спустя полчаса.

Хотя в Task Manager-е этой виртуальной машины вы запросто увидите сколько еще свободной (нулевой) памяти у нас имеется.
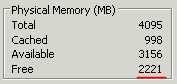
Я, к сожалению, не докопался почему именно так все складывается, но мне сдается, что кэширование файловой системы происходит не в виде непрерывной записи в память, а в различные ее области.
2. Обнуление страниц памяти в виртуальной машине происходит только при ее включении. При стандартном перезапуске страницы не обнуляются.
Large Pages
Размер больших страниц используемых кернелом в ESX равен 2 мегабайтам. Шансы, что в физической памяти обнаружатся две идентичные большие страницы вобщем то почти нулевой, поэтому ESX даже и не пытается сравнивать их. Когда вы используете новые процессоры с EPT/RVI это значит, что хост будет агрессивно пытаться использовать большие страницы где только возможно. Если вы взгляните на SHRD значение в таких хостах, то вы будете неприятно удивлены его низким значением, но тем не менее это все таки существенная величина. На моем продакшн хосте при выделенных 70 Гбайт около 4 Гбайт было SHRD. Это, кстати, был один из самых интересных вопросах в комментариях статьи, с которой и начался мой интерес к этой теме. Теперь то я знаю, что это просто нулевые страницы, а тогда я жутко мучался незнанием и догадками.
Этот низкий показатель изначально вызвал бурные дискуссии на форумах Vmware по той простой причине, что люди решили, что в их ESX 4.0 хостах TPS вообще перестал работать. Vmware была вынуждена опубликовать разъяснение по этому поводу.
Тем не менее, даже когда ваш хост активно использует большие страницы TPS совсем не дремлет. Он так же методично сканирует память на предмет одинаковых 4 кбайтных страниц, которые бы он мог поудалять будь его на то воля. Как только он обнаруживает одинаковые страницы, он ставит там закладку (hint). Когда значение используемой в ESX памяти достигает 94% ваш хост незамедлительно разбивает большие страницы на малые и уже не тратя время на сканирование (TPS ведь понаставил уже закладок) опять же начинает удалять идентичные страницы. Если у вас до этого еще не дошло, то в том же esxtop, в поле COWH (Copy-on-write hints) вы можете посмотреть сколько вы приблизительно сможете сэкономить после того как большие страницы будут разбиты на малые.

И снова я бы хотел обратить внимание на разницу в работе с большими страницами между старыми и новыми процессорами. Сама Vmware включила поддержку больших страниц еще начиная с версии 3.5. В соответствии с документом "Large Page Performance" от Vmware, если ОС вашей виртуальной машины использует большие страницы, то ESX хост будет выделять большие страницы в физической памяти именно под эту ВМ. Однако если та же виртуальная машина работает на ESX хосте с EPT/RVI процессорами, то вне зависимости от поддержки больших страниц вашей ВМ, ESX будет использовать большие страницы в физической памяти, что как известно из этого же документа ведет к серьезному приросту производительности процессора.
Что интересно, на паре хостов со старыми процессорами и ESX 4.1, на которых крутятся 90% Windows 2008R2 я все равно вижу очень высокий показатель SHRD, что говорит о том, что там скорей всего используются маленькие страницы. К сожалению, я так и не нашел подробной документации о том, как работает поддержка больших страниц на старых процессорах: при каких условиях, на каких ОС, и т.д будут использоваться большие страницы. Так что для меня это пока еще белое пятно. В ближайшее время я постараюсь запустить штук 10 Windows 2008 R2 на ESX 4.1 хосте со старым процессором и проверить значения памяти.
Когда я только более менее все это усвоил я был озадачен — а что будет если я вручную отключу поддержку больших страниц на своем хосте с Nehalem процессором? Сколько я увижу сэкономленной памяти и насколько упадет производительность? «Ну чего тут долго думать — надо делать» подумал я и отключил поддержку больших страниц на одном из наших продакшн хостов. Изначально на этом хосте было 70 Гбайт выделенной памяти и 4 Гбайт shared памяти (ну да, мы помним — это нулевые страницы). Средний показатель загрузки процессоров никогда не поднимался выше 25%. Спустя два часа после отключения больших страниц значение shared памяти выросло до 32 Гбайт, а загрузка процессоров осталась на прежнем уровне. Уже прошло 4 недели с тех пор и ни одной жалобы на падение производительности мы еще не слышали.
Ну и наконец мое заключение
После того как я поделился информацией с коллегами меня спросили «А нафига париться с выключением поддержки больших страниц, если хост и так отключит их при надобности?». И я сразу знал ответ — имея включенной поддержку больших страниц по умолчанию я не могу полноценно видеть сколько я потенциально могу сэкономить памяти с TPS, я не могу правильно планировать дополнительное размещение ВМ на моих ESX хостах, я не могу прогнозировать уровень консолидации, вобщем я чуточку слеп в плане управления ресурсами своей vSphere фермы. Однако гуру vSphere, например Данкан Эппинг, уверял — «не парьтесь, TPS все равно когда надо сработает, и при этом у вас отличный прирост производительности». Спустя еще пару дней я нашел замечательную дискуссию между ним и другими авторитетами мира виртуализации, которая только подтвердила правильность моего решения об отключении больших страниц. Некоторые говорят, что можно использовать значение COWH для планирования использования своих ресурсов, но по каким то причинам это значение не всегда правдиво. На этом скриншоте показаны значения одного из моих Windows 2003 серверов, который уже 3 недели работает на хосте с отключенными большими страницами, и как вы можете видеть значени SHRD и COWH очень существенно отличаются.

Неделю назад мы отключили большие страницы еще на 4 хостах, уже другой фермы, и опять никакого падения производительности я не заметил. Хотя, стоит заметить, что это все индивидуально, и вы должны учитывать специфику своей фермы, ресурсов, виртуальных машин при принятии подобного решения.
Если мне повезет, и эта статья покажется интересной, то я бы с удовольствием перевел бы еще одну свою статью о разнице в управлении памятью между процессорами старого и нового поколения.
После 4-5 дней копания в форумах Vmware, чтения Вики, западных блогеров, у меня кое что отложилось в голове и я смог наконец то ответить на вопросы из комментариев. Чтобы как-то упорядочить свежие знания я решил написать несколько статей на эту тему в своем англоязычном блоге. Я также пошерстил Хабр на предмет новых статей на эту тему, но к моему удивлению с 2010 года ничего нового не обнаружил. Поэтому и решил ради постоянно читаемого Хабра и возможности активно участвовать в комментариях перевести свою же статью про Transparent Page Sharing и нюансы его использования на системах с процессорами семейства Nehalem/Opteron и с установленной ESX(i) 4.1.
Мне не хочется делать статью слишком длинной, поэтому я настоятельно рекомендую вам (особенно если вы vSphere админ) сначала прочитать статью, ссылку на которую я дал в самом начале. Но все таки в некоторых мелочах я повторюсь.
Итак, для чего нужен TPS?
Ответ достаточно банален — сэкономить оперативной памяти, показать виртуальным машинам больще памяти, чем есть на самом хосте, ну и следовательно обеспечивать более высокий уровень консолидации.
Как он работает?
Исторически сложилось так, что в x86 системах вся память разделяется на 4 кбайтные блоки, так называемые страницами. Когда у вас на одном ESX хосте крутятся 20 виртуальных машин (ВМ) с одной и той же ОС можно легко представить, что у этих ВМ достаточно много идентичных страниц памяти. Чтобы обнаружить одинаковые страницы на ESX хосте запускается TPS процесс с периодичностью в 60 минут. Он сканирует абсолютно все страницы в памяти и вычисляет хэш каждой страницы. Все хэши складываются складываются в одну таблицу и проверяются кернелом на предмет совпадения. Чтобы избежать проблемы под названием hash collision при обнаружении одинаковых хэшей кернел сверяет соответствующие страницы побитово. И только убедившись, что они 100% одинаковы кернел оставляет одну единственную копию страницы в памяти, а все обращения на удаленные страницы переправляются на ту самую первую копию. Если же какой либо из ВМ вздумается изменить что либо в этой странице, то ESX создаст еще одну копию оригинальной страницы и уже с ней позволит работать ВМ, которая отправила запрос на изменение. Посему в терминологии Vmware такой тип страниц называется Copy-on-write (COW). Процесс сканирования памяти на современных серверах с подчас сотнями гигабайт оперативной памяти может длиться достаточно долго, поэтому не стоит ожидать немедленных результатов.
NUMA и TPS
NUMA — это достаточно любопытная технология разделения доступа к памяти между процессорами. На наше счастье последние версии ESX достаточно умны и знают, что для эффективной на NUMA системах TPS должен работать только в пределах NUMA нода. В принципе, если в ESX поправить значение VMkernel.Boot.sharePerNode, то можно заставить TPS сравнивать страницы в пределах всей памяти, а не отдельных NUMA нодов. Понятно, что в этом случае можно добиться более высоких значений SHARED памяти, но вам надо учитывать возможное серьезное падение производительности. Например, представьте, что в вашем ESX хосте 4 Xeon 5560 процессора, то есть 4 NUMA нода и каждый содержит идентичную копию страницы памяти. Если TPS оставит одну копию в первом ноде и удалит 3 остальные, то это значит, что каждый раз, когда какой либо из ВМ работающих на этих 3 нодах понадобится искомая страница памяти, 3 процессорам придется обращаться к ней не через локальную и очень быструю шину памяти, а через общую и медленную. Чем больше у вас таких страниц, тем меньше пропускной способности остается на общей шине, ну и следовательно больше страдает производительность ваших виртуальных машин.
Zero Pages
Одной из новых замечательных функций представленных в vSphere 4.0 было распознавание нулевых страниц. В принципе это обычная страница, которая от начала до конца заполнена нулями. Каждый раз, когда включается Windows ВМ вся память обнуляется, это помогает ОС определить точные размеры доступной ей памяти. ESX может моментально обнаруживать такие страницы у виртуальных машин, и вместо бесполезного процесса выделения физической памяти под нулевые страницы, а потом удаления их в процессе работы TPS, ESX сразу все такие страницы перенаправляет на одну единственную нулевую страницу. Если вы запустите esxtop и проверите значения памяти для только что запущенной ВМ, вы обнаружите, что значения ZERO и SHRD практически идентичны.
Однако здесь важно отметить то, что эту новую замечательную функцию ESX 4.0 (и старше) умеет применять только на процессорах с EPT (Intel) или RVI (AMD) технологиями. На эту тему есть пара отличнейших статей на сайте Kingston (часть первая, часть вторая). Если вкратце, то там рассказывается и показывается как на новых процессорах нулевые страницы распознаются без выделения им физической памяти, а на старых процессорах физическая память таки выделяется, и только когда TPS полноценно отработает начинается снижение используемой физической памяти. Для обычных vSphere ферм это в принципе не критично, но для VDI инфрастуктур, где у вас могут быть сотни одновремено стартующих виртуальных машин это архиполезно.
Пара особенностей работы TPS с нулевыми страницами.
1. В OC Windows существует технлогия называемая «кэширование файловой системы» (прощу прощения если кое где мой перевод названий и определений грешит неточностями). Используя определение MS мы можем сказать, что «Кэширование файловой системы это область памяти, которая хранит недавно используемую информацию для быстрого доступа». Кэш этот располагается в адресном пространстве кернела, и поэтому образом в 32битных системах его размер ограничен 1 гигабайтом. Однако в 64битных системах его размер может достигать 1 терабайта (пруф). В принципе технология очень полезная для производительности, но если мы имеем ситуацию с виртуальными машинами и нулевыми большими страницами (2 мегабайта), то значение SHRD в esxtop у вас будет стремиться к нулю.
Скриншот выше показывал значение esxtop сразу после запуска Windows 2008 R2 виртуальной машины, а вот что показывал esxtop спустя полчаса.
Хотя в Task Manager-е этой виртуальной машины вы запросто увидите сколько еще свободной (нулевой) памяти у нас имеется.
Я, к сожалению, не докопался почему именно так все складывается, но мне сдается, что кэширование файловой системы происходит не в виде непрерывной записи в память, а в различные ее области.
2. Обнуление страниц памяти в виртуальной машине происходит только при ее включении. При стандартном перезапуске страницы не обнуляются.
Large Pages
Размер больших страниц используемых кернелом в ESX равен 2 мегабайтам. Шансы, что в физической памяти обнаружатся две идентичные большие страницы вобщем то почти нулевой, поэтому ESX даже и не пытается сравнивать их. Когда вы используете новые процессоры с EPT/RVI это значит, что хост будет агрессивно пытаться использовать большие страницы где только возможно. Если вы взгляните на SHRD значение в таких хостах, то вы будете неприятно удивлены его низким значением, но тем не менее это все таки существенная величина. На моем продакшн хосте при выделенных 70 Гбайт около 4 Гбайт было SHRD. Это, кстати, был один из самых интересных вопросах в комментариях статьи, с которой и начался мой интерес к этой теме. Теперь то я знаю, что это просто нулевые страницы, а тогда я жутко мучался незнанием и догадками.
Этот низкий показатель изначально вызвал бурные дискуссии на форумах Vmware по той простой причине, что люди решили, что в их ESX 4.0 хостах TPS вообще перестал работать. Vmware была вынуждена опубликовать разъяснение по этому поводу.
Тем не менее, даже когда ваш хост активно использует большие страницы TPS совсем не дремлет. Он так же методично сканирует память на предмет одинаковых 4 кбайтных страниц, которые бы он мог поудалять будь его на то воля. Как только он обнаруживает одинаковые страницы, он ставит там закладку (hint). Когда значение используемой в ESX памяти достигает 94% ваш хост незамедлительно разбивает большие страницы на малые и уже не тратя время на сканирование (TPS ведь понаставил уже закладок) опять же начинает удалять идентичные страницы. Если у вас до этого еще не дошло, то в том же esxtop, в поле COWH (Copy-on-write hints) вы можете посмотреть сколько вы приблизительно сможете сэкономить после того как большие страницы будут разбиты на малые.
И снова я бы хотел обратить внимание на разницу в работе с большими страницами между старыми и новыми процессорами. Сама Vmware включила поддержку больших страниц еще начиная с версии 3.5. В соответствии с документом "Large Page Performance" от Vmware, если ОС вашей виртуальной машины использует большие страницы, то ESX хост будет выделять большие страницы в физической памяти именно под эту ВМ. Однако если та же виртуальная машина работает на ESX хосте с EPT/RVI процессорами, то вне зависимости от поддержки больших страниц вашей ВМ, ESX будет использовать большие страницы в физической памяти, что как известно из этого же документа ведет к серьезному приросту производительности процессора.
Что интересно, на паре хостов со старыми процессорами и ESX 4.1, на которых крутятся 90% Windows 2008R2 я все равно вижу очень высокий показатель SHRD, что говорит о том, что там скорей всего используются маленькие страницы. К сожалению, я так и не нашел подробной документации о том, как работает поддержка больших страниц на старых процессорах: при каких условиях, на каких ОС, и т.д будут использоваться большие страницы. Так что для меня это пока еще белое пятно. В ближайшее время я постараюсь запустить штук 10 Windows 2008 R2 на ESX 4.1 хосте со старым процессором и проверить значения памяти.
Когда я только более менее все это усвоил я был озадачен — а что будет если я вручную отключу поддержку больших страниц на своем хосте с Nehalem процессором? Сколько я увижу сэкономленной памяти и насколько упадет производительность? «Ну чего тут долго думать — надо делать» подумал я и отключил поддержку больших страниц на одном из наших продакшн хостов. Изначально на этом хосте было 70 Гбайт выделенной памяти и 4 Гбайт shared памяти (ну да, мы помним — это нулевые страницы). Средний показатель загрузки процессоров никогда не поднимался выше 25%. Спустя два часа после отключения больших страниц значение shared памяти выросло до 32 Гбайт, а загрузка процессоров осталась на прежнем уровне. Уже прошло 4 недели с тех пор и ни одной жалобы на падение производительности мы еще не слышали.
Ну и наконец мое заключение
После того как я поделился информацией с коллегами меня спросили «А нафига париться с выключением поддержки больших страниц, если хост и так отключит их при надобности?». И я сразу знал ответ — имея включенной поддержку больших страниц по умолчанию я не могу полноценно видеть сколько я потенциально могу сэкономить памяти с TPS, я не могу правильно планировать дополнительное размещение ВМ на моих ESX хостах, я не могу прогнозировать уровень консолидации, вобщем я чуточку слеп в плане управления ресурсами своей vSphere фермы. Однако гуру vSphere, например Данкан Эппинг, уверял — «не парьтесь, TPS все равно когда надо сработает, и при этом у вас отличный прирост производительности». Спустя еще пару дней я нашел замечательную дискуссию между ним и другими авторитетами мира виртуализации, которая только подтвердила правильность моего решения об отключении больших страниц. Некоторые говорят, что можно использовать значение COWH для планирования использования своих ресурсов, но по каким то причинам это значение не всегда правдиво. На этом скриншоте показаны значения одного из моих Windows 2003 серверов, который уже 3 недели работает на хосте с отключенными большими страницами, и как вы можете видеть значени SHRD и COWH очень существенно отличаются.
Неделю назад мы отключили большие страницы еще на 4 хостах, уже другой фермы, и опять никакого падения производительности я не заметил. Хотя, стоит заметить, что это все индивидуально, и вы должны учитывать специфику своей фермы, ресурсов, виртуальных машин при принятии подобного решения.
Если мне повезет, и эта статья покажется интересной, то я бы с удовольствием перевел бы еще одну свою статью о разнице в управлении памятью между процессорами старого и нового поколения.
