Можешь выбрать подходящую к заголовку поста картинку?

Тогда научи робота! Он тоже хочет.
Команда проекта Открытый корпус просит хабралюдей помочь разметить свободно доступный (CC-BY-SA) корпус текстов. Под катом мы расскажем о том, что такое корпус, зачем он нужен, как обстоят дела с корпусами в России и за рубежом, почему так плохо и какой у нас план.
Корпус текстов — это лингвистическая база данных, включающая тексты, разные метаданные, относящиеся к этим текстам, а также грамматические разборы входящих в них слов и предложений. Метаданные и грамматические разборы — это разметка. Она бывает разных уровней: морфологическая, синтаксическая, семантическая, и т.д. Без размеченных корпусов текстов трудно (или даже невозможно) разрабатывать софт для анализа текста. Для программ, использующих машинное обучение, из размеченного корпуса берётся обучающая выборка. В остальных случаях корпус нужен для тестирования.
Размеченные корпуса существуют для многих языков мира. Чаще всего корпус текстов доступен через специализированные поисковые машины, позволяющие выбирать примеры употребления различных языковых конструкций. Эти сервисы предназначены для лингвистов. Скачивать корпуса целиком оттуда нельзя, т.к. входящие в них тексты чаще всего защищены копирайтом. Для разработки лингвистического софта нужны корпуса, которые можно скачивать целиком, вместе с разметкой. На Хабре уже писали об этом здесь (про POS-tagging) и здесь (про синтаксис).
Корпуса текстов в России и за рубежом
Здесь у русского языка всё не так хорошо, как, например, у английского, для которого есть несколько разных доступных и вручную размеченных корпусов текстов. Это не удивительно как минимум потому, что на английском говорит больше людей, чем на русском. Удивительно, что даже для венгерского языка, на котором говорят в 10 раз меньше людей, чем на русском, есть доступный и размеченный корпус размером больше 1 млн. слов.
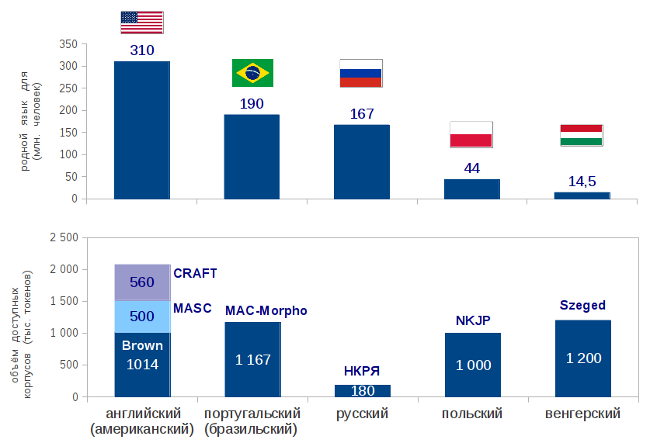
А что у нас?
Национальный корпус русского языка (НКРЯ), создаваемый совместными усилиями многих организаций (включая Институт русского языка РАН), доступен только в режиме поиска по корпусу. Из 6 млн. слов, размеченных вручную, можно скачать только выборку размером 180 тысяч слов, в которой предложения идут с нарушенным порядком. Если вы хотите сделать морфологический анализатор со снятием неоднозначности, то вам придётся либо воспользоваться этими 180 тысячами, которых чаще всего будет недостаточно для машинного обучения, либо попробовать какой-нибудь другой язык, например, польский. Такое положение дел, очевидно, не способствует развитию компьютерной лингвистики в нашей стране.
Для того, чтобы русский язык не попадал в категорию «under-resourced languages», мы решили сделать новый Открытый корпус русского языка, учитывая опыт создания НКРЯ и других проектов. Поскольку Национальный корпус предоставляет хороший интерфейс поиска, и, таким образом, решает задачи связанные с поиском примеров употребления различных слов и конструкций, мы решили сфокусироваться на создании свободно доступного корпуса для разработчиков: его можно скачать и использовать для машинного обучения или для тестирования. Поиска по нему нет, но это не страшно, т.к. он есть в НКРЯ. Чтобы вопрос копирайта не мешал распространению в корпус включаются только тексты либо доступные на условиях лицензии Creative Commons, либо находящиеся в общественном достоянии. Разметка создаётся на условиях CC-BY-SA.
На предыдущем этапе нашей работы (в 2011 году) мы собрали корпус в 700 тыс. слов и расставили вручную границы слов и предложений. Эти данные уже можно скачивать. Сейчас нашей основной целью является снятие неоднозначности в морфологической разметке. Эту работу тоже нужно делать вручную, её много, и мы просим вас нам помочь.
Вспомним школу или что такое морфологическая разметка
Морфологическая разметка (tagging, part-of-speech tagging) — это сопоставление каждому слову в тексте его словарной формы («большого» — «БОЛЬШОЙ», «столу» — «СТОЛ», «читал» — «ЧИТАТЬ») и указание грамматических характеристик слова: род, число, падеж, время и др. Первичная морфологическая разметка делается по словарю автоматически. Мы используем словарь проекта АОТ, доработанный для наших целей. Для большинства слов разметка получается неоднозначной, т. е. для многих слов в тексте в словаре находится несколько гипотез. Чаще всего только одна из гипотез является правильной. Бывают и неоднозначные предложения, имеющие несколько вариантов разбора. Например:
«Эти типы стали есть в цехе»
СТАЛЬ (существительное) или СТАТЬ (глагол)?
«Он видел их семью своими глазами»
СЕМЬЯ (существительное) или СЕМЬ (числительное)?
Такие примеры встречаются редко. Морфологический разбор становится однозначным в контексте предложения: прочитав его целиком, мы можем определить, в какой именно форме стоит то или иное слово. Например, для предложения «Мама мыла раму» в конечном итоге должен быть построен вот такой разбор:

Проведя морфологический анализ при помощи словаря, только одно из слов мы сможем разобрать однозначно. Для слов «МЫЛА» и «РАМУ» мы получим четыре и две гипотезы соответственно:
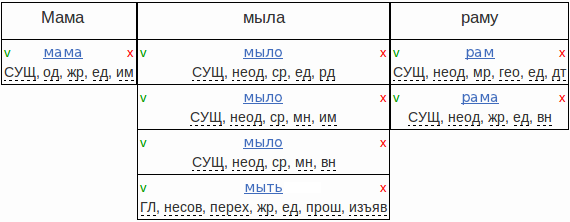
Снять морфологическую неоднозначность — это значит выбрать одну правильную гипотезу для каждого слова. Для носителей языка это, чаще всего, не представляет трудности.
У нас есть план!
Чтобы упростить задачу снятия неоднозначности, мы разделили её на простые вопросы, которые вместе представляют собой дерево решений для каждого примера неоднозначности. В случае со словом «МЫЛА», первый вопрос будет «Существительное или глагол?». Для предложения «Мама мыла раму» снятие неоднозначности на этом закончится, т. к. это глагол, а глагольная гипотеза только одна. В других случаях нужно будет ответить ещё на один или, в худшем случае, ещё на два вопроса.
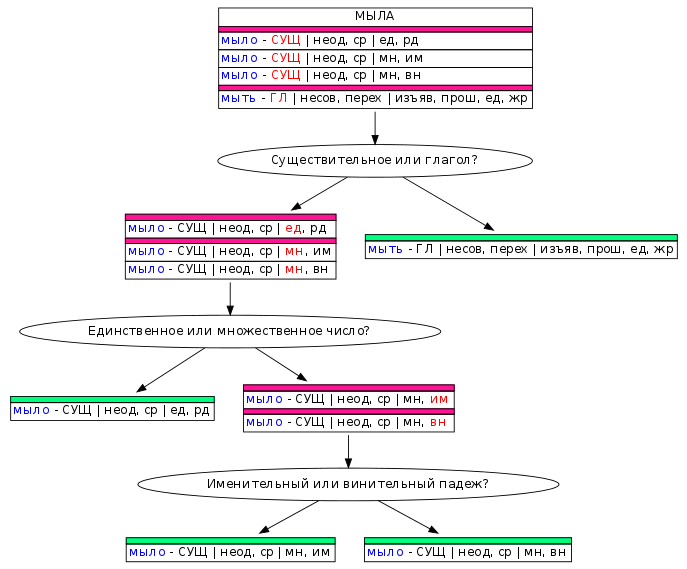
Однотипные вопросы мы объединили в группы. Участник может выбрать тип вопросов и отвечать только на вопросы этого типа про случайно выбранные слова в их контекстах, сфокусировавшись, таким образом, на одной задаче. Так размечать быстрее, т.к. не тратится время на переключение между разными типами вопросов.
Чтобы разметка была достаточно точной, каждый вопрос задаётся трём разным людям, и только если ответы полностью совпадают, и никто не написал комментариев, они используются без перепроверки. Если один ответ отличается от двух других, или если оставлен комментарий, то этот пример проверяет модератор.
Сколько у нас этого плана?
По грубым подсчётам, чтобы снять неоднозначность в собранной на настоящий момент коллекции текстов, с учётом того, что вопросы задаются трижды, нужно ответить на
Для участия в проекте можно использовать приступы прокрастинации, время по дороге на работу (интерфейс разметки работает на смартфонах) и другие вынужденные паузы в полезной деятельности. В этом смысле разметка корпуса похожа на пасьянс, только полезнее. Поскольку никаких особенных лингвистических знаний не требуется, то каждый дочитавший до этого места может принять участие, и мы вместе создадим морфологический слой разметки корпуса. На этой странице находится пошаговая инструкция по разметке.
Недавно мы начали собирать и публиковать подмножество предложений, в которых вся неоднозначность уже снята. Этот подкорпус пока очень маленький — около 9500 слов. По мере того, как идёт разметка, он становится больше, и, в дальнейшем, эти данные можно будет использовать для создания свободно доступных морфологических анализаторов, умеющих снимать неоднозначность.
Открытый корпус. Не стесняйтесь снимать неоднозначность!
Ссылки на упомянутые корпуса
Русский
[НКРЯ] Национальный корпус русского языка: ruscorpora.ru (23 октября об этом проекте будет лекция в лектории Политехнического музея в Москве)
[OpenCorpora] Статьи и презентации об Открытом корпусе: opencorpora.org/?page=publications
Английский
[Brown] Брауновский корпус: en.wikipedia.org/wiki/Brown_Corpus
[MASC] Manually Annotated Sub-Corpus (часть Американского национального корпуса, размеченная вручную): www.anc.org/MASC/Home.html
[CRAFT] The Colorado Richly Annotated Full Text Corpus (67 статей по био-медицинской тематике с лингвистической и онтологической разметками): bionlp-corpora.sourceforge.net/CRAFT/index.shtml
Португальский, польский, венгерский
[MAC-Morpho] Тексты из газеты «Folha de São Paulo» на бразильском португальском: www.nilc.icmc.usp.br/lacioweb/english/plancamento.htm
[NKJP] Narodowy Korpus Języka Polskiego. Подкорпус NKJP, доступный на условиях лицензии GNU GPL v.3: nkjp.pl/index.php?page=14&lang=1
[Szeged] Szeged Corpus, корпус текстов на венгерском языке: www.inf.u-szeged.hu/projectdirs/hlt/index_en.html
Картинки в начале поста: «Family portrait» и «Totem moster».
