 Продолжаем перевод. В этой главе разговор пойдёт о организации сервис-деска и способах построения взаимодействий с пользователями, а также получении от них обратной связи. Увидим почему 'хорошо' с точки зрения ИТ, не всегда означает 'хорошо' с точки зрения пользователя и как можно уравновесить эти две оценки.
Продолжаем перевод. В этой главе разговор пойдёт о организации сервис-деска и способах построения взаимодействий с пользователями, а также получении от них обратной связи. Увидим почему 'хорошо' с точки зрения ИТ, не всегда означает 'хорошо' с точки зрения пользователя и как можно уравновесить эти две оценки.Содержание
Глава 1. Управление вашим IT окружением: четыре вещи, которые вы делаете неправильно
Глава 2. Устранение практики управления по отдельным участкам в IT-менеджменте
Глава 3. Соединяем всё в единый цикл управления ИТ
Глава 4. Мониторинг: взгляд за пределы ЦОД
Глава 5: Превращаем проблемы в решения
Глава 6: Унифицированное управление на примерах
Глава 3. Соединяем всё в единый цикл управления ИТ
В течение долгого времени в ИТ присутствовала практика дискретных, отсоединенных от реальной жизни процессов, часто заставлявшая ключевых участников интересоваться тем, что же происходит внутри ИТ. Объединение всех – пользователей, менеджеров, ИТ-специалистов и других сотрудников в единый цикл может дать существенные выгоды, а также снизить тенденцию возврата к управлению ИТ по отдельным участкам. Именно здесь происходит истинная интеграция между сервис-деском и системой мониторинга, и эти две концепции составляют основу для самых центральных и важных тем, обсуждаемых в этой книге. Всё это касается коммуникаций – способах достижений лучшего взаимодействия, равно как и создания возможностей для постоянных улучшений. Пользователи иногда воспринимают свой ИТ-департамент как неприступных, высоколобых и странных типов с плохими навыками общения. Является ли это правдой – зависит от самих ИТ специалистов, но такое предубеждение , справедливое оно или нет, часто существует. А всё потому, что ИТ-служба может слишком часто оказываться последней, узнающей о событиях, которые пользователи воспринимают как проблему. Сервер может работать в пределах установленных значений, но приложение для ввода ордеров работает очень медленно. ИТ говорит, что почта работает замечательно, но я жду входящего сообщения с заказом на закупку уже час, так что нет никакого шанса, что почтовая система работает правильно!
ИТ иногда приходится бороться с собственными уникальными трудностями, предполагающими выпадение из процесса управления – например, поиск окон в расписании, где надо внести в инфраструктуру одобренные изменения, может оказаться крайне нетривиальной задачей. Может быть сложной простая координация изменений — предложенных, одобренных, находящихся в разработке, готовых для развертывания и так далее. Во многих организациях принят порядок действий для управления изменениями, подобно описанному способу в ITIL, выделяющий специфический процесс для ревизии и одобрения изменений. Однако физическое координирование работ, со стороны больше выглядит как попытка пасти кошачью стаю. Это даже хуже, чем ситуация, в которой ИТ управлялись по отдельным технологическим участкам: команде, занимающейся СУБД, необходимо внести изменения, запланированные на полночь, но это изменение будет конфликтовать с работами на системах электропитания, проводимых командой инфраструктуры ЦОД. Так что все наши утверждения остаются в силе – нам надо держать всех «на одной странице».
Начинаем цикл: соединяем мониторинг и сервис-деск
Сегодня большинство организаций, для координации работ в ИТ имеют системы, основанные на использовании тикетов. Также в этих организациях обычно есть системы мониторинга, позволяющие наблюдать за ИТ-системами и реагировать на любые проблемы. Однако, в очень немногих компаниях, эти две системы работают вместе. В идеале, это было бы то, что нужно: единая интегрированная система IT управления, которая в состоянии обнаруживать проблемы и затем открывать тикеты, назначаемые конкретным сотрудникам. Если упал почтовый сервер, то соответствующий администратор должен получить тикет в работу. Конечно же, эти тикеты должны иметь способы извещения, типа текстовых сообщений, почты или любого другого способа, так что адресат знает, что объявлена тревога. Автоматическое назначение тикетов, которое иногда называют автоматической маршрутизацией должно обладать изрядной долей искусственного интеллекта.
Разные системы, установленные в разных местах, в разное время – все они могут влиять на способ создания тикета, а также менять круг лиц, привлекаемых к работе над проблемой.
Тикеты должны быть полными насколько это возможно, в том смысле, что значения для заполняемых полей «тревожного билета», должны собираться автоматически, насколько это возможно. При заполнении деталей, не следует сильно полагаться на хелп-деск или кого-то еще.
В детализированных сведениях может содержаться информация относительно серверов, на которые повлияла проблема. На рис.3.1. показано как, примерно, может выглядеть автоматически созданный тикет, с основными полями, предварительно заполненными системой.

Рисунок 3.1: Тикеты, автоматически создаваемые системой в ответ на получаемые сигналы тревоги.
Идея заключается в наличии решения для организации сервис-деска – программном обеспечении, помогающем координировать и управлять ИТ активностями (часто посредством тикетов), работающем совместно с системой мониторинга, что, таким образом, создаёт действительно интегрированное решение для работы с проблемами, возникающими в ИТ.
Предполагается, что из всего этого будет извлекаться своя выгода. Первое, и самое главное – более быстрое разрешение инцидентов. Не дожидаясь пока ваши пользователи сообщат о проблеме, вы приступаете к её оперативному решению, а при наличии предварительно заполненных тикетов, ИТ специалисты работают быстрее, потому что у них на руках больше информации.
Можно углубиться в этот процесс еще больше, если у вас будет внедрено правильное ПО для организации сервис-деска. Фреймворки, типа ITIL, всячески поощряют анализ исходной причины, означающий, что ваша команда должна заниматься не только решением сиюминутных затруднений, но также делать общее окружение более стабильным и устойчивым к возникновению трудностей. Чтобы этого достичь, решение для сервис-деска должно определять два типа ситуаций: глобальная проблема и специфичный инцидент.
Специфичный инцидент может быть обычным затруднением типа: «Электронная почта работает медленно», «Программа ввода заказов тормозит» и так далее. Оба инцидента могут быть связаны с глобальной проблемой «Непонятные замедления в работе сети», которые должны быть проверены и исправлены – возможно, дело в перегруженном маршрутизаторе, сбрасывающем пакеты чаще, чем обычно.
Иногда, специфичные инциденты не могут быть полностью разрешены до тех пор, пока не разрешится перекрывающая их глобальная проблема. Отслеживая индивидуальные инциденты вместе с глобальной проблемой, вы можете помочь вашим пользователям и их руководителям быть более информированными. Например, после того как перегревшийся маршрутизатор был обнаружен и заменен, каждому сотруднику, которого затрагивала эта специфичная проблема может быть отослано сообщение «Скорее всего мы нашли причину медленной работы, так что сейчас не должно быть проблем». На рис.3.2. показано как единая глобальная проблема может привязываться ко многим инцидентам.

Рисунок 3.2: Связь между несколькими инцидентами и одной проблемой.
Я использовал пару ключевых слов в текущем обсуждении и хотел бы их оговорить в контексте данной книги:
- Инцидент – нечто, что случается в окружении, например, вышедший из строя сервер или медленно работающее приложение.
- Чтобы справиться с инцидентом, ИТ персонал создает запись о проблеме. Проблемы, по факту, могут оказаться связанными со многими инцидентами, как, например, в случае с перегревшимся маршрутизатором, который вызвал неоднократные, на первый взгляд, не связанные между собой сбои, проявившиеся во всём окружении.
С этого места я собираюсь использовать эти два термина именно в таком понимании. Надеюсь, что некоторые преимущества комбинирования мониторинга и решения проблем станут понятны. Например, более простые решения, используемые для организации хелп-деска, позволяют открывать множество тикетов по событию, являющемуся на самом деле, одной и той же проблемой. Это может приводить к существенному дублированию усилий, когда множество специалистов пытаются, каждый — сам по себе, решить одну и ту же проблему. Также это может привести к большому количеству бюрократической работы, потому что попытки поисков исходной причины требуют большого количества времени на обработку и закрытие каждого тикета. Если используется более совершенная система, все поступающие события могут быть консолидированы в единый, управляемый процесс. Кроме того, это дает дополнительные выгоды, такие например как поиск подходящего решения или обходного приема(workaround), которые мы будем обсуждать в следующих главах.
Однако, проблемы и инциденты не являются единственной причиной, по которой пользователи взаимодействуют с ИТ службой, более того, я надеюсь, что это не главная причина, по которой пользователи обращаются в ИТ службу! Помимо сообщений об инцидентах, пользователи также запрашивают рутинные сервисы: спрашивают совета, делают запросы на обновление аппаратного обеспечения, внесение изменений, запросы на предоставление доступа и т.д. Все эти запросы должны обрабатываться через формализованный набор процедур (workflow), на входе в который пользователи размещают свой запрос, и после одобрения он попадает к соответствующему техническому специалисту, а внутри самого процесса есть возможность отслеживать статус запросов.
Например:
- Пользователь посещает веб-сайт, чтобы выбрать отдельно взятый запрос из «каталога», которые он может создать – доступ к системам, замена оборудования и т.д.
- Пользователь выбирает элемент из каталога и вносит дополнительную уточняющую информацию для завершения запроса.
- В сервис-деске создается тикет, содержащий запрос пользователя. В зависимости от запроса, тикет может быть направлен к руководителю пользователя для согласования.
- После согласования, тикет может быть автоматически передан в работу соответствующему техническому специалисту ИТ службы.
- По мере работы, пользователь может получать информацию о состоянии запроса, например через e-mail. Информация включает в себя сообщение о статусе «завершено», после того как тикет будет закрыт.
- При использовании одной и той же системы для обработки тикетов, как для решения проблем, так и для обработки рутинных запросов, ИТ-специалисты могут пользоваться единым интерфейсом для управления своей рабочей нагрузкой. Рис. 3.3 показывает, как может выглядеть запрос на обработку тикета, связанного с рутинным запросом.

Рисунок 3.3: Рутинные запросы также могут быть оформлены в виде тикетов.
Гораздо лучше, когда управление ИТ может полагаться на полное документирование и отслеживание своей собственной работы в единой системе — это дает возможность руководству быть в курсе проблем и иметь весь необходимый набор отчётности, панелей индикаторов и других механизмов. На рис.3.4. показан пример как может выглядеть такой отчет:

Рисунок 3.4: Управленческие отчеты становятся более эффективными, когда они включают все работы по ИТ службе.
Основная идея – удерживать в едином цикле всех: пользователей, ИТ, руководство — чтобы все были информированы о состоянии дел. Основное бремя по извещению ложится на программное обеспечение, имеющее возможность рассылки обновленной информации о состоянии дел посредством электронной почты или другими способами, благодаря чему все в курсе текущей ситуации.
Внесение изменений. Как найти правильное окно
Большие ИТ департаменты, со многими специализациями, имеют свои специфичные проблемы. В предыдущей главе, я рассказывал о проблемах управления по отдельным технологическим секторам, где узкие эксперты тратили много времени, передавая проблему друг другу, а из-за того, что каждый пользовался исключительно своим собственным инструментом и считал, что проблема находится не у него, поиск и устранение причин затягивались. Без всякого сомнения, мы не собираемся избавляться от узких специалистов, и наше решение заключается в использовании инструментов, которые позволят свести информацию из разных источников в единую консоль, что даёт возможность объединить общие усилия.
Еще одна проблема, создаваемая практикой управления по отдельным технологическим участкам, связана с управлением изменениями. В начале этой главы, я обрисовал одну из этих проблем: специалисты по БД, готовы внести свои изменения в систему, но они конфликтуют с изменениями, которые собирается внести другая группа. Управление окнами в расписании для внесения изменений становится крайне затруднительным. Приложения и сервисы не только требуют круглосуточной работы, что приводит к очень небольшим окнам для внесения изменений, но и приводит к конкуренции за эти окна разных групп специалистов.
«Шеф, нам надо давно поставить этот пакет исправлений, но это можно сделать только ночью. Нам потребуется 4 часа, и мы помещаемся в окно. Но всю прошлую неделю, другие группы использовали это же окно и их работа, не давала нам заниматься нашей работой одновременно». Ситуация не такая редкая; для менеджмента становится сложным отслеживать какие изменения надо внести в конфигурацию, и когда под них выделить и без того ограниченное время среди окон для обслуживания.
Отсутствие видимости окон, конкуренция за них, часто приводит к невозможности принять правильные управленческие решения. К примеру, если руководство видит определенное количество ожидающих внесения изменений, и видит конкуренцию, то оно может решить расширить окно обслуживания на период, достаточный для реализации этих задач. А может решить этого и не делать. По крайней мере, это будет осознанно принятое решение, но не игнорирование серьёзных проблем.
Выход из ситуации – использование программного обеспечения, делающего удобным координацию различных департаментов. Подумайте об этом: если вы используете решение для организации сервис-деска для отслеживания тикетов, то тогда тикеты могут быть созданы и для предполагаемых изменений. Эти тикеты могут быть назначены техническому специалисту, направлены для согласования или пересмотра и так далее, и всё – через разработанный вами поток работ.
Кстати, это очень хороший способ для реализации процессов ITIL. Тикеты затем могут быть внесены в унифицированный календарь, встроенный прямо в сервис-деск, и сотрудники, занимающиеся планированием, могут сформировать приемлемое расписание работ. Они могут видеть согласованные окна обслуживания, управлять конкуренцией между конфликтующими изменениями и так далее. Получая эту информацию в знакомом календарном виде, они также могут принимать решения о том, расширять или нет окна обслуживания, если это так необходимо и принесёт пользу организации. Рисунок 3.5 показывает календарь управления изменениями:

Рисунок 3.5: Расписание управления изменениями в виде календаря.
Это всего лишь еще один способ, помогающий удержать всех в едином цикле взаимодействия. У менеджмента теперь есть четкое визуальное отображение изменений и конкуренции за расписание. Такой календарь может даже быть сделан доступным для пользователей, так, что бы они могли правильно и осознанно планировать свою работу.
Коммуникации: как вовлечь пользователей в единый цикл
Идея поддержки информирования пользователей, конечно, не нова, но многие компании, пытавшиеся вовлечь своих пользователей в процесс, потерпели неудачу. Слишком часто «вовлечение пользователей в единый цикл» принимает вид веб-порталов самообслуживания, где зарегистрированные пользователи могут посмотреть статус своих тикетов или проверить состояние какого-то конкретного сервиса. Это всё хорошо и здорово, но порталы такого типа далеко не всегда совпадают с естественным ходом мыслей пользователя. Например, большинство пользователей, если они сталкиваются с какими-то проблемами, совершенно не обязательно подумают, что надо пойти и проверить информацию на веб-сайте — они просто звонят в хелп-деск.
Зато пользователи достаточно много времени тратят на проверку почты в своем почтовом ящике. Почему бы не сделать это вашим каналом коммуникаций? Организации стараются не использовать этот способ связи, частично из-за того, что он легко может стать большим пожирателем времени для вашей ИТ службы. «Я полностью занимаюсь решением проблемы, и при этом должен рассылать ежечасные апдейты о состоянии дел?» Прямо мультфильм про Дилберта какой-то.
В действительности, хорошее решение для сервис-деска может это сделать за вас. Рассылка апдейтов через е-мейлы, если, к примеру, пользовательский тикет изменился — это несложная операция для программного обеспечения. Такие сообщения могут быть информативны и снимают у пользователей большинство беспокойства по поводу состояния их запросов. На рисунке 3.6. показано как это может выглядеть.
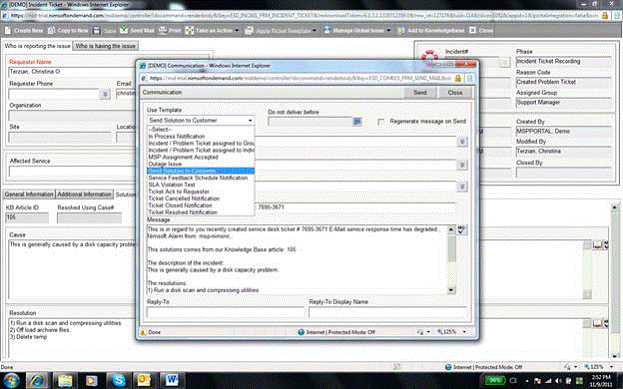
Рисунок 3.6. Информирование пользователей посредством детальных е-мейлов.
Еще более востребовано сервисное решение, которое в действительности может принимать запросы посредством электронной почты вместо того, чтобы ожидать когда пользователи зайдут на веб-сайт и откроют тикет. Примите это как есть – ваши пользователи гораздо охотнее снимут телефонную трубку, чем будут посещать веб-сайт и оформлять тикет, ну, конечно, если вы не устроите существенных искусственных барьеров на этом пути – типа сложных голосовых меню в телефонной системе. Пользователи с большей охотой пошлют е-мейл. Если ваш сервис-деск, вместо технического специалиста, сможет получать эти сообщения и использовать их для создания тикетов, вы действительно создали систему, которую пользователи встретят с распростёртыми объятиями. Такие тикеты могут иметь автоматическое назначение и маршрутизацию, помогая техническому специалисту быстрее приступать к решению проблемы. Сообщения, присылаемые через е-мейл, могут быть ценны даже для рутинных, непроблемных процессов. Когда их запрос одобрен, отклонен, выполняется, завершен и т.д., сообщение по е-мейлу помогает пользователям быть информированными без дополнительных человеческих усилий.
Замечание
Я хотел бы подчеркнуть, что порталы самообслуживания являются хорошей вещью. Они могут улучшить личный опыт пользователя, подтолкнуть пользователя в нужном направлении, если он пытается решить свою проблему при помощи системы самообслуживания и многое другое, но они не должны быть единственными способами коммуникации с людьми.
Соглашения об уровне обслуживания: договоренности и соответствие реалистичным ожиданиям
Если вы, конечно, не жили последние десять лет в какой-нибудь глуши, то словосочетание 'соглашение об уровне обслуживания (SLA)’ должно быть вам знакомо. В своей простейшей форме, это обязательство, принимаемое ИТ службой и обеспечивающее конкретный уровень работоспособности, производительности и доступности для какого-то конкретного сервиса. «Почтовая служба будет доступна 99.999% рабочего времени в год» — пример простейшего SLA.
SLA очень быстро становятся сложными и вы не сможете просто так понять из них ни одной цифры. Какой уровень сервиса вы можете разумно обеспечить? Какой у вас исторически сложившийся уровень сервиса? И что соответствует нуждам бизнеса? Как вы отслеживаете уровень SLA, которые когда-то были введены в оборот, и как вы удостоверяетесь, что они соответствуют бизнесу? И есть ли у вас, в идеале, извещение о надвигающейся опасности невыполнения условий соглашения?
SLA могут быть не единственным типом соглашения которое надо принять и отслеживать. Некоторые также используют соглашения со сторонними поставщиками услуг (underpinning contracts — UC) или соглашение об уровне операционной поддержки (operational level agreements — OLA) для различных внутренних и внешних сервисов, часто поддерживаемых в SLA.
Грамотно построенный сервис-деск и решения мониторинга помогут вам более точно соблюдать эти соглашения. Вы можете начать с определения SLA верхнего уровня, затем, отталкиваясь от них определить UC и OLA, как вам требуется. (Надо делать поправку на локальное законодательство и сложившуюся деловую практику исполнения обязательств сторонними компаниями. Если, к примеру, у всех ваших локальных провайдеров связи указан интервал восстановления 72 часа, то неразумно подписываться под собственным SLA, в котором указан ответственность за меньший период, а также должны быть веские основания и одобрение руководства для поиска провайдера с меньшими сроками восстановления. Очень часто любое уменьшение таких, казалось бы, длинных интервалов влечет к несоразмерному росту стоимости услуги, и впоследствии на практике оно оказывается не таким уж и нужным– пр.перев)
Единожды прописав параметры соглашения, программное решение должно отслеживать текущую производительность и доступность, сигнализировать об этом, возможно в виде простого индикатора, приведенном на рисунке 3.7 и показывающего ваше соответствие текущим SLA. Также у вас может быть доступ к более полным и детальным отчетам по метрикам SLA.

Рисунок 3.7: Управление SLA. Индикаторы текущего состояния SLA.
Однако, что более важно, у используемого вами программного решения должна быть возможность определять правила ваших SLA, по которым могут создаваться тикеты, в случае если есть опасность нарушения условий, и в дальнейшем, как мы ранее говорили, они должны отправляться на конкретных специалистов. Решение должно поддерживать правила эскалации: если значения SLA, в отношении которого начинают не соблюдаться правила выполнения, подошли к пороговой границе и не возвращаются назад в течение определенного момента времени, то приложение должно попытаться автоматически ввести резерв, призвать дополнительных технических специалистов, известить руководство и так далее.
Следует категорически признать, что нет совершенных SLA. Иногда, по любой причине, бизнес может решить, что заявленный сервис надо держать отключенным. Иногда это может быть, например, обновление программного обеспечения или работы по обслуживанию. В этих случаях вы НЕ нарушаете SLA; вы согласны – совместно с той частью бизнеса, которую это затрагивает – временно приостановить SLA до тех пор, пока работы не будут закончены. Программное решение для организации сервис-деска должно поддерживать данные типы исключений, включая SLA, действительные только в определенные периоды времени; правильно обрабатывать исключения в виде выходных и праздников, согласованных окон обслуживания, изменений в размерах сервисных окон и т.д.
Идея заключается в автоматизации определений SLA и их управлении, а кроме того в автоматизации извещений, которые связаны с соглашением. Если SLA нарушено, вы можете согласиться с тем, чтобы затрагиваемые пользователи бизнеса получали автоматические уведомления. Это позволит им быть в курсе, что ИТ знает про их проблемы и работает над ними – без принуждения пользователей посещать портал самообслуживания и открывать там тикеты. Такой вид проактивного ответа на проблему поможет пройти длинный путь на пути улучшения отношений ИТ и пользователей, и даст возможность ИТ получать правильную оценку с точки зрения бизнеса, а также соответствовать его требованиям и поддерживать их.
Скажите мне, что вы на самом деле думаете
ИТ-менеджеры любят когда ИТ думает о пользователях как о «клиентах». В некоторых случаях ваши пользователи действительно могут быть «клиентами», в том смысле, если они действительно «перечисляют вам деньги за те сервисы, которые вы им оказываете». В других случаях ваши пользователи – внутренние, но всё еще «клиенты» в том смысле, что они потребляют ваши сервисы, которые вы, ИТ-департамент, обеспечиваете, и за что вам, собственно говоря, платят зарплату.
Очень большая проблема в том, что ИТ всегда борется со своим восприятием у своих клиентов. Действительно ли пользователи думают, что вы делаете работу хорошо? И что есть хорошая работа?
Мониторинг метрик пользовательской оценки (EUE – End-User Experience), который мы обсуждали в первой главе, становится горячим трендом в ИТ-индустрии. Вы можете видеть, что производительность вашего сервера находится в пределах нормы, но после того как всё проходит через старые клиентские компьютеры, маршрутизаторы, кабельную систему и всё остальное, куда вовлечена доставка сервиса пользователям, они могут воспринимать производительность сервера совершенно по-другому. Измерение пользовательской оценки является возможностью заглянуть в общую картину того, с чем вашим пользователи или клиентам, если вам так угодно – приходится иметь дело.
В разных видах бизнеса используется другой важный способ раскрытия мнения пользователей: оценочный опрос. Позвоните в ваш банк, и робот, отвечающий на телефонный звонок, может сказать вам, что вы выбраны для участия в коротком обзоре удовлетворенности услугами, который начнётся сразу после того, как вы завершите разговор с вашим менеджером. Если вы пришли в парк развлечений, то улыбающийся сотрудник с планшетом наверняка задаст вам несколько вопросов. Посмотрите на чек от вашей последней покупки, вы наверняка там обнаружите, что у вас есть возможность выиграть подарочную карту или другой приз, если вы заполните онлайновый оценочный опрос о ваших впечатлениях при посещении магазина.
Оценочные обзоры представляют собой эффективный путь сбора информации о том, что действительно думают пользователи, и хорошее решение для организации сервис-деска должно давать вам возможность оценки вашей работы вашими клиентами. Вы можете захотеть, чтобы они поделились своим мнением по поводу завершения каждого запроса. А может быть, вам захочется быть менее назойливым и спрашивать пользователей только на третьем или четвёртом запросе. К какому бы вы решению не пришли, ПО для сервис-деска должно уметь автоматизировать данный процесс. Вы даже можете пожелать вовлечь пользователей в cпециальный опрос, касающихся их мнения о ежедневных задачах, уровнях обслуживания и так далее.
Конечно, такие обследования бесполезны без возможности собирать данные и видеть, что и как у вас делается. Итоговая часть обзора должна быть представлена в виде отчетности, возможно с таблицами и графиками, помогающими вам визуализировать восприятие вашего сервиса.
Сравните этот отчет с отчетом о соответствии работы вашим SLA – видите разницу?
Если ваши SLA показывают, что вы делаете свою работу идеально, а пользовательские оценочные обзоры далеко не такие блестящие, то возможно ваши SLA выставлены на не совсем правильный уровень – или же ваши SLA не являются единственными метриками, которые стоит рассматривать.
Я работал с определенным количеством клиентов, у которых была такая ситуация: «Наши SLA выполняются, но наши пользователи все еще не считают, что мы делаем свою работу хорошо. В чем может быть дело?». Мы нашли ответ с помощью нескольких специализированных опросов, касавшихся «небольших» затруднений, таких как «позиция» команды ИТ во время помощи пользователям. Выяснилось, что сотрудники, работавшие с клиентами, вели себя бесцеремонно, а иногда грубо. Мы провели какое-то время бок о бок с командой, и обнаружили, что они находились под невероятным прессингом из-за большого количества обслуживаемых тикетов. В итоге, в компании сумели разработать внутренние метрики, позволявшие отслеживать нагрузку каждого из специалистов и поработали над тем, чтобы снизить загрузку до приемлемого и управляемого уровня, при этом продолжая отслеживать «небольшие» проблемы отношения специалистов и пользователей.
Мораль этой истории в том, что SLA не являются единственными метриками, которые следует держать в голове, и интегрированные опросники могут помочь раскрыть критическую информацию, важную для понимания общей эффективности сервисов.
Когда каждому не нужно видеть всё: многовладельческий подход
Многовладельческий (multitenant) подход – растущий тренд среди ИТ решений, предлагаемых разными изготовителями ПО и тому есть весомые причины. Если вы являетесь сервисным провайдером, или, еще точнее провайдером управляемого сервиса — MSP (Managed Service Provider), то вы должны быть осведомлены о наличии инструментов, которые можно настроить и выделить для каждого из ваших пользователей. Клиенту А нужны такие панели индикаторов, в то время как клиенту В нужны другие. Клиенту В совершенно не надо видеть тикеты клиента А (и клиент А совершенно не хочет, чтобы клиент В их видел!). В недавнем прошлом, наличие таких многовладельческих свойств, было характерно только для решений, разрабатываемых исключительно для MSP.
Сегодня, однако, всё меняется. Большие компании, имеющие множество подразделений, хотят у себя развертывать ПО, которое может обслуживать потребности всех подразделений без обязательного наличия уникальных для каждой службы решений. В этом случае многовладельческие решения могут помочь: они позволяют взять единое решение, подстроить его под конкретные нужды, разделить его на части и предоставить в каждое подразделение таким образом, как если бы это было единственное решение для одного подразделения, хотя на самом деле это решение обслуживает всех.
Разные подразделения могут иметь различные представления для просмотра своей части окружения. Например, Подразделение А может видеть индикаторы, в то время как подразделение В видит нечто совершенно другое. И тем не менее, многовладельческий подход далеко не то, что нужно произвольной отдельно взятой компании. Однако, это достаточно хорошее свойство, которое можно придерживать в заднем кармане и пустить в ход, когда это действительно станет нужным. Поэтому данный функционал стоит принимать во внимание, если вам приходится делать оценку при выборе из нескольких решений – даже если многовладельческие особенности не являются немедленной необходимостью. Конечно, если вы MSP, то это свойство продукта обязано присутствовать в ваших решениях.
Это напрямую относится к теме данной главы о вовлечении всех в единый цикл управления: способность обеспечивать специфичные, кастомизированные окружения различным группам пользователей – как внешним, так и внутренним, помогает последним иметь более точную информацию о состоянии дел.
Назовите это частным облаком: распределение затрат
Есть еще одна вещь, на которую стоит обратить внимание, при вовлечении всех сотрудников в работу – это связанные с ними затраты и возможность предоставлять своим клиентам детальные отчеты по использованию инфраструктуры, а, в случае необходимости выставлять реальные счета, основанные на этих цифрах.
На рис. 3.8. приведен пример такого отчёта:

Рисунок 3.8: Отчет для биллинга по измерению активности пользователя.
И снова, хотя данный вид отчета является очевидной и обязательной функцией для MSP, на отчеты такого рода всё больше растёт спрос у организаций, работающих только с внутренними пользователями. Одним из ключевых элементов облачных вычислений является концепция биллинга за фактическое использования ресурсов. Провайдер облака выстраивает и управляет инфраструктурой, которая определенным образом делится среди клиентов. Каждый клиент платит за те части и функции, которыми он воспользовался. Это очевидная и хорошо понимаемая модель облачных вычислений, являющаяся моделью и для частных облаков. Вместо того, чтобы представлять ИТ в виде гигантской корзины издержек, компании всё чаще ищут способы распределения затрат на ИТ между потребителями ИТ-сервисов. «Маркетинг собирается развернуть десяток виртуальных веб-серверов для нового веб-сайта? Отлично, а бюджет у них для этого есть?»
В компенсационной оплате (chargeback), как она называется, нет ничего нового. Но решения для мониторинга и для организации сервис-десков всё чаще могут предоставить такой уровень детализации, который позволит вам осуществлять учет и действительно выставлять счета. Технологические достижения, сделавшие возможным создание публичных облаков, могут быть достаточно быстро интегрированы в частные центры обработки данных и работать там в том же качестве: биллинг (или распределение затрат) за актуальное использование.
Привязывание ИТ-затрат напрямую к потребителям ИТ сервисов является отличным подходом, помогающим ИТ принимать более грамотные бизнес-решения. Вместо того, чтобы поручать ИТ роль Цербера, решающего кто может, а кто не может иметь доступ к определенным ИТ-сервисам, руководство организации должно решать кто, сколько денег и на какие сервисы может потратить. Так и должно быть. С другой стороны, ИТ всегда имело аутсорсную, неделовую активность, если смотреть на неё с точки зрения бизнеса. Хотя работа ИТ-департамента оплачивается организацией, он напрямую не участвует в создании прибыли – это отдельное подразделение. Так что, когда бизнес рассматривает ИТ как «аутсорсинговую» команду (хотя по факту она является внутренней), то почему бы ИТ не вести учет и не выставлять счета в разрезе пользователей, так же как это делает любой продавец ИТ услуг?
Это тоже еще один способ увязать всех вместе в единый процедурный цикл. Даже если вы не используете по прямому назначению внутренний биллинг или счета, они могут быть полезны для понимания высшим руководством источников затрат и ценности инвестиций в ИТ. Руководитель ИТ-службы может сказать генеральному директору: «Хорошо, вы потратили хулиард долларов на ИТ в последнем квартале, но вот здесь указано когда и каким образом эти инвестиции использовались организацией. Если вы хотите сэкономить, то начните с пользователей и найдите способы, чтобы они меньше потребляли наших сервисов»
Заключение
В данной главе говорилось о удержании сотрудников в едином цикле управления ИТ. Начиная от пользователей, информируемых о ИТ процессах, до более лучшей связи ИТ специалистов с текущими событиями и предоставлением сведений для руководства, помогающего принимать более правильные и обоснованные решения – это всё было про коммуникации. Я очень мало говорил в этой главе о том, что любая организация не сможет сделать это прямо сейчас, даже если они приложат к этому достаточно усилий. Ключевой момент в том, чтобы использовать специализированное программное обеспечение, в котором есть возможности, позволяющие это реализовать с минимумом затрат, что даёт возможности добиться поставленных целей.
В следующей главе…
В следующей главе мы собираемся рассмотреть вызовы, встречающиеся в жизни ИТ всё чаще: ключевые сервисы и ИТ элементы существуют за пределами своих центров обработки данных. Да, их можно назвать «облаком» либо просто «сервисами, вынесенными на аутсорсинг». Но как их не называй, они по-прежнему критичны для бизнеса и вам надо относиться к ним в точности так же, как если бы это были ваши локальные сервисы. Их нельзя воспринимать как отдельный технологический участок, потому что вы в итоге будете управлять ими отдельно от общей системы. Естественно, что мониторинг сервисов, вынесенных на аутсорсинг – это игра по другим правилам, в отличие от локальных сервисов, так что нам придётся поискать некоторые нетривиальные решения.
Перейти к Главе 2
