Пропускная способность каналов связи непрерывно возрастает, если ещё пару лет назад сервер с каналом 10Gbit/s был привилегией лишь немногих, то теперь на рынке появились предложения, доступные для маленьких и средних компаний. В то же время, стек протоколов TCP/IP разрабатывался во времена, когда о скоростях порядка 10Gbit/s можно было только мечтать. Вследствие этого, в коде большинства современных операционных систем общего назначения имеется множество оверхедов, впустую съедающих ресурсы. В этих условиях, возрастает важность задач высокопроизводительной обработки сетевых потоков.
Статья сделана на основе моего доклада на Highload++ 2012 и предназначена для быстрого введения в удобный и очень эффективный opensource framework, который включен в HEAD/STABLE FreeBSD, называется NETMAP и позволяет работать с пакетами на скоростях 1-10Gbit/s без использования специализированного железа в обычных *nix операционных системах.
Netmap использует хорошо известные техники увеличения производительности, такие как мапирование в память буферов сетевой карты, пакетная обработка I/O и использование принимающих и передающих кольцевых буферов памяти, соответствующих аппаратным буферам в сетевой карте, что позволяет генерировать и принимать трафик до 14 миллионов пакетов в секунду (что соответствует теоретическому максимуму для 10Gbit/s).
В статье собраны ключевые фрагменты публикаций автора NETMAP — Luigi Rizzo, рассматриваются архитектура и ключевые особенности внутренней реализации netmap framework'а, который инкапсулирует критические функции при работе с ядром OS и сетевой картой, предоставляя в userland простой и понятный API.
Под катом рассматриваются основные примитивы использования фреймворка для разработки приложений связанных с обработкой пакетов на скоростях 14Mpps, рассмотрен практический опыт использования netmap фреймворка при разработке компонента системы DDOS защиты, ответственного за уровень L3. Отдельно рассматриваются сравнительные характеристики производительности netmap на каналах 1/10Gbit/s, одном/нескольких ядрах процессора, больших и коротких пакетах, сравнение производительности со стеками OS FreeBSD / Linux.
Современные операционные системы общего назначения, предоставляют богатые и гибкие возможности для обработки пакетов на низком уровне в программах сетевого мониторинга, генерации трафика, программных коммутаторах, роутерах, межсетевых экранах и системах распознавания атак. Программные интерфейсы, такие как: raw sockets, the Berkley Packet Filter (BPF), интерфейс AF_PACKET и подобные им в настоящее время используются для разработки большей части подобных программ. Высокая скорость обработки пакетов, которая требуется для этих приложений, по всей видимости, не была главной целью при разработке указанных выше механизмов, т.к. в каждой из реализаций присутствуют значительные накладные расходы (далее overhead).
В то же время, значительно увеличившаяся пропускная способность среды передачи, сетевых карт и сетевых устройств, предполагают необходимость такого интерфейса для низкоуровневой обработки пакетов, который бы позволил выполнять обработку на скоростях среды передачи данных (wire speed), т.е. миллионы пакетов в секунду. Для получения лучшей производительности, некоторые системы работают непосредственно в ядре операционной системы или получат доступ непосредственно к структурам сетевой карты (далее NIC) в обход стека TCP/IP и драйвера сетевой карты. Эффективность этих систем обусловлена учётом специфических особенностей железа сетевых карт, обеспечивающих прямой доступ к структурам данных NIC.
NETMAP фреймворк, успешно комбинирует и расширяет идеи, реализованные в решениях по прямому доступу к NIC. Помимо кардинального увеличения производительности, NETMAP предоставляет в userland hardware independent интерфейс для высокопроизводительной обработки пакетов. Приведу здесь одну только метрику для того, чтобы Вы смогли оценить скорость обработки пакетов: пересылка пакета из среды передачи (кабеля) в userspace занимает менее 70 тактов CPU. Другими словами, используя NETMAP только на одном ядре процессора с частотой 900MHz, имеется возможность осуществлять быстрый форвардинг 14.88 миллионов пакетов в секунду (Mpps), что соответствует предельной скорости передачи фреймов Ethernet в канале 10Gbit/s.
Другой важной особенностью NETMAP является то, что он предоставляет аппаратно независимый интерфейс для доступа к регистрам и структурам данных NIC. Эти структуры, а также критические области памяти ядра недоступны для пользовательской программы, что повышает надёжность работы, т.к. из userspace сложно вставить неверный указатель на область памяти и вызвать сбой в ядре OS. Вместе с этим, в NETMAP используется очень эффективная модель данных, позволяющая осуществлять zero-copy packet forwarding, т.е. форвардинг пакетов без необходимости копирования памяти, что позволяет получить колоссальную производительность.
В статье сделан акцент на архитектуре и возможностях, которые предоставляет NETMAP, а также на показателях производительности, которые с его помощью можно получить на обычном железе.
Эта часть статьи будет особенно интересна для разработчиков, которые делают такие приложения как программные свичи, роутеры, файрволы, анализаторы трафика, системы распознавания атак или генераторы трафика. Операционные системы общего назначения, как правило, не предоставляют эффективных механизмов доступа к raw пакетам на высоких скоростях. В этом разделе статьи мы сконцентрируемся на анализе стека TCP/IP в OS, рассмотрим откуда берутся overhead’ы и поймём какова стоимость обработки пакета на разных стадиях его прохождения через стек OS.
Сетевые адаптеры (NIC) для обработки входящих и исходящих пакетов используют кольцевые очереди (rings) дескрипторов буферов памяти, как показано на Рис.№1
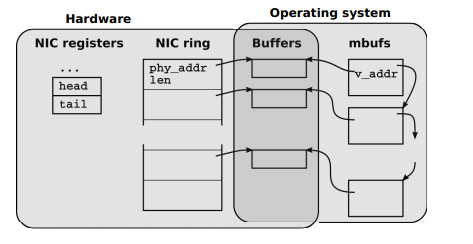
«Рис №1. Структуры данных NIC и их взаимосвязь со структурами данных OS»
Каждый слот в кольцевой очереди (rings) содержит длину и физический адрес буфера. Доступные (адресуемые) для CPU регистры NIC содержат информацию об очередях для приёма и передачи пакетов.
Когда пакет приходит в сетевую карту, он размещается в текущий буфер памяти, его размер и статус записываются в слот, а информация о том, что появились новые входящие данные для обработки, записывается в соответствующий регистр NIC. Сетевая карта инициирует прерывание, чтобы сообщить CPU о поступлении новых данных.
В случае, когда пакет отправляется в сеть, NIC предполагает, что OS заполнит текущий буфер, разместит в слоте информацию о размере передаваемых данных, запишет в соответствующем регистре NIC количество слотов для передачи, что инициирует отправку пакетов в сеть.
В случае высоких скоростей приёма и передачи пакетов, большое количество прерываний может привести к невозможности выполнить какую-либо полезную работу («receive live-lock»). Для решения этих проблем в OS используют механизм polling или interrupt throttling. Некоторые высокопроизводительные NIC используют множественные очереди для приёма/передачи пакетов, что позволяет распределить нагрузку на процессор по нескольким ядрам или разделить сетевую карту на несколько устройств, для использования в виртуальных системах, работающих с такой сетевой картой.
OS осуществляет копирование структур данных NIC в очередь из буферов памяти, которая является специфической для каждой конкретной OS. В случае FreeBSD это mbufs её эквиваленты sk_buffs и NdisPackets. По своей сути эти буферы памяти являются контейнерами в которых содержится большое количество метаданных о каждом пакете: размер, интерфейс с/на которого пакет пришёл, различные атрибуты и флаги определяющие порядок обработки данных буфера памяти в NIC и/или OS.
Драйвер NIC и стек TCP/IP операционной системы (далее host stack), как правило, предполагают, что пакеты могут быть разбиты в произвольное количество фрагментов, следовательно и драйвер и host stack должны быть готовы к обработке пакетной фрагментации. Соответствующее API экспортируемое в userspace предполагает, что различные подсистемы могут оставить пакеты для отсроченной обработки, следовательно буферы памяти и метаданные не могут быть просто переданы по ссылке в процессе обработки вызова, но они должны быть скопированы или обработаны механизмом подсчёта ссылок (reference counting). Всё это является платой высокими overhead’ами за гибкость и удобство работы.
Дизайн рассмотренного выше API был разработан довольно продолжительно время назад и на сегодняшний день является слишком затратным для современных систем. Стоимость выделения памяти, управления и прохождения через цепочки буферов часто выходит за рамки линейной зависимости от полезных данных, передаваемых в пакетах.
Стандартное API для ввода/вывода raw пакетов в пользовательской программе требует, как минимум выделения памяти для копирования данных и метаданных между ядром OS и userspace и один системный вызов на каждый пакет (в отдельных случаях, на последовательность пакетов).
Рассмотрим overhead’ы возникающие в OS FreeBSD при отправке UDP-пакета из userlevel с помощью функции sendto(). В данном примере userspace программа в цикле посылает UDP-пакет. Таблица №2 иллюстрирует время, в среднем потраченное на обработку пакета в userspace и различных функциях ядра. В поле Time записано среднее время в наносекундах на обработку пакета, значение записывается, когда функция возвращает управление. В поле delta указано время, прошедшее до начала выполнения следующей функции в цепочке выполнения системного вызова. Для примера, 8 наносекунд занимает выполнение в контексте userspace, 96 наносекунд занимает вход в контекст ядра OS.
Для тестов используем следующие макроопределения, работающие в OS FreeBSD:
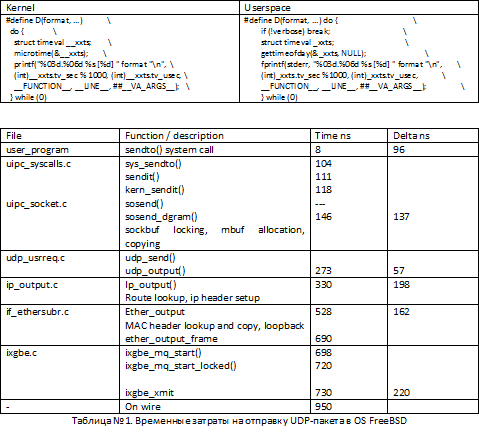
Тест выполнялся на компьютере под управлением OS FreeBSD HEAD 64bit, i7-870 2.93GHz (TurboBoost), Intel 10Gbit NIC, ixgbe драйвер. Значения усреднены по нескольким десяткам 5-и секундных тестов.
Как видно из Таблицы №1, имеются несколько функций потребляющих критически большое количество времени на всех уровнях обработки пакета в стеке OS. Любой API для сетевого ввода/вода, будь то TCP, RAW_SOCKET, BPF будет вынужден отправить пакет сквозь несколько очень затратных уровней. Используя это стандартное API нет возможности для обхода механизмов выделения памяти и копирования в mbuf’ах, проверке правильных маршрутов, подготовке и конструированию заголовков TCP/UDP/IP/MAC и в конце этой цепочки обработки, преобразования структур mbuf и метаданных в формат NIC для передачи пакета в сеть. Даже в случае локальной оптимизации, например, кэширование маршрутов и заголовков вместо их построения с нуля, не даёт радикального увеличения скорости, которая требуется для обработки пакетов на интерфейсах 10 Gbit/s.
Поскольку проблема высокоскоростной обработки пакетов стоит относительно давно, уже разработаны и используются различные техники увеличения производительности, позволяющие качественно увеличить скорость обработки.
Berkley Packet Filter (далее BPF) является наиболее популярным механизмом для получения доступа к raw пакетам. BPF подключается к драйверу сетевой карты и отправляет копию каждого принятого или отправленного пакета в файловый дескриптор из которого его может получать/отправлять пользовательская программа. Linux имеет подобный механизм, называемый семейство сокетов AF_PACKET. BPF работает вместе со стеком TCP/IP, хотя в большинстве случаев, он переводит сетевую карту в «прозрачный» режим (promiscuous), что приводит к большому потоку постороннего трафика, который попадает в ядро и тут же там удаляется.
Netgraph (FreeBSD), Netfilter (Linux), Ndis Miniport драйверы (MS Windows) являются встроенными в ядро механизмами, которые используются в случае, когда копирование пакетов не требуется и приложение, например firewall, должно быть встроено в цепочку прохождения пакетов. Эти механизмы принимают трафик от драйвера сетевой карты и передают его в модули обработки без дополнительного копирования. Очевидно, что все указанные в данном пункте механизмы опираются на представление пакетов в виде mbuf/sk_buff.
Одним из простых способов избежать дополнительного копирования в процессе передачи пакета из kernel space в user space и наоборот является возможность разрешить приложению прямой доступ к структурам NIC. Как правило, для этого требуется, чтобы приложение работало в ядре OS. Примерами могут быть проект программного роутера Click или генератор трафика kernel mode pkt-gen. Наряду с простотой доступа, kernel space является очень хрупкой средой, ошибки в которой могут привести к падению системы, поэтому более правильный механизм это экспортирование пакетных буферов в userspace. Примерами данного подхода являются PF_RING и Linux PACKET_MMAP, которые экспортируют область разделяемой памяти, содержащей заранее выделенные области для сетевых пакетов. Ядро операционной системы при этом осуществляет копирование данных между sk_buff’ерами и пакетными буферами в разделяемой памяти. Это позволяет выполнять групповую обработку пакетов, но при этом остаются overheads связанные с копированием и управлением цепочкой sk_buff.
Ещё более высокую производительность можно достигнуть в случае разрешения доступа к NIC прямо из userspace. Этот подход требует специальных драйверов NIC и увеличивает некоторые риски, т.к. NIC DMA engine сможет записать данные по любому адресу памяти и неправильно написанный клиент может случайно «убить» систему затерев критические данные где-нибудь в ядре. Справедливо заметить, что в большом количестве современных сетевых карт имеется блок IOMMU, который осуществляет ограничение записи NIC DMA engine в память. Примером данного подхода в ускорении производительности являются PF_RING_DNA и некоторые коммерческие решения.
В предыдущем материале рассматривались различные механизмы увеличения производительности обработки пакетов на высоких скоростях. Были проанализированы затратные операции в обработке данных, такие как: копирование данных, управление метаданными и другие overhead’ы возникающие при прохождении пакета из userspace через стек TCP/IP в сеть.
Представленный в докладе фреймворк, именуемый NETMAP, представляет собой систему, которая предоставляет userspace приложению очень быстрый доступ к сетевым пакетам, как для приёма, так и для отправки, как при обмене с сетью, так и при работе со стеком TCP/IP OS (host stack). При этом, эффективность не приносится в жертву рискам, возникающим при полном открытии структур данных и регистров сетевой карты в userspace. Фреймворк самостоятельно управляет сетевой картой, операционная система, при этом, выполняет защиту памяти.
Также, отличительной особенностью NETMAP является тесная интеграция с существующими механизмами OS и отсутствие зависимости от аппаратных особенностей специфических сетевых карт. Для достижения желаемых высоких характеристик по произвдительности NETMAP использует несколько известных техник:
• Компактные и лёгкие структуры метаданных пакета. Простые для использования, они скрывают аппаратно-зависимые механизмы, предоставляя удобный и простой способ работы с пакетами. Кроме того, метаданные NETMAP построены таким образом, чтобы обрабатывать множество самых разных пакетов за один системный вызов, уменьшая, таким образом, накладные расходы на передачу пакетов.
• Линейные preallocated буферы, фиксированных размеров. Позволяют уменьшать накладные расходы на управление памятью.
• Zero copy операции при форвардинге пакетов между интерфейсами, а также между интерфейсами и host stack’ом.
• Поддержка таких полезных аппаратных особенностей сетевых карт, как множественные аппаратные очереди.
В NETMAP каждая подсистема делает ровно то, для чего предназначена: NIC пересылает данные между сетью и оперативной памятью, ядро OS выполняет защиту памяти, обеспечивает многозадачность и синхронизацию.
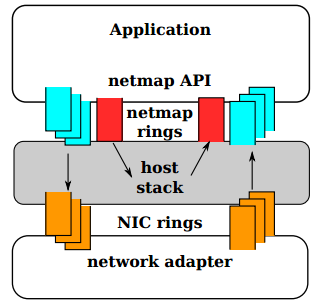
Рис. №2. В режиме NETMAP очереди NIC отключены от стека TCP/IP OS. Обмен между сетью и host stack осуществляется только через NETMAP API
На самом верхнем уровне, когда приложение через NETMAP API переводит сетевую карту в режим NETMAP, очереди NIC отсоединяются от host stack. Программа таким, образом получает возможность контролировать обмен пакетами между сетью и стеком OS, используя для этого кольцевые буферы, которые называются «netmap rings». Netmap rings, в свою очередь, реализованы в разделяемой памяти (shared memory). Для синхронизации очередей в NIC и стеке OS используются обычные системные вызовы OS: select()/poll(). Несмотря на отключение стека TCP/IP от сетевой карты, операционная система продолжает работать и выполнять свои операции.
Ключевые структуры данных NETMAP изображены на Рис. №3. Структуры были разработаны с учётом следующих задач:
• Уменьшение overhead’ов при обработки пакетов
• Увеличение эффективности при передаче пакетов между интерфейсами, а также между интерфейсами и стеком
• Поддержка аппаратных множественных очередей в сетевых картах
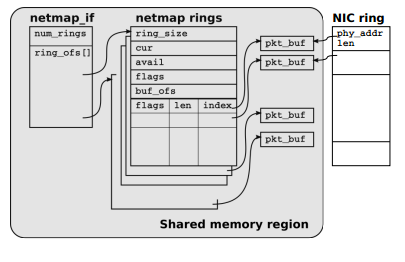
Рис. №3. Структуры экспортируемые NETMAP в userspace
NETMAP содержит три типа объектов, видимых из userspace:
• Пакетные буферы ( packet buffers )
• Кольцевые буферы-очереди ( netmap rings )
• Дескриптор интерфейса ( netmap_if )
Все объекты всех netmap enabled интерфейсов системы находятся в одной и той же области невыгружаемой разделяемой памяти, которая выделена ядром и доступна между процессам из user space. Использование такого выделенного сегмента памяти позволяет удобным образом осуществлять zero copy обмен пакетами между всеми интерфейсами и стеком. Вместе с тем, NETMAP поддерживает разделение интерфейсов или очередей таким образом, чтобы изолировать области памяти предоставляемые разным процессам друг от друга.
Поскольку разные пользовательские процессы работают в различных виртуальных адресах, все ссылки в экспортируемых NETMAP структурах данных являются относительными, т.е. являются смещениями.
Пакетные буферы (packet buffers) имеют фиксированный размер (2K в настоящее время) и используются одновременно NIC и пользовательскими процессами. Каждый буфер идентифицируется по уникальному индексу, его виртуальный адрес может быть легко вычислен пользовательским процессом, а его физический адрес может быть легко вычислен NIC DMA engine’ом.
Все netmap буферы выделяются в тот момент, когда сетевая карта переводится в режим NETMAP. Метаданные, описывающие буфер, такие как, индекс, размер и некоторые флаги, сохраняются в слотах ( slots ), которые являются основной ячейкой netmap ring’а, о котором будет рассказано ниже. Каждый буфер привязан к netmap ring и соответствующе й очереди в сетевой карте ( hardware ring ).
«Netmap ring» является абстракцией аппаратных кольцевых очередей сетевой карты. Netmap ring характеризуется следующими параметрами:
• ring_size, количество слотов в очереди (netmap ring)
• cur, текущий слот для записи/чтения в очереди
• avail, количество доступных слотов: в случае TX – это пустые слоты, через которые можно отправить данные, в случае RX – это заполненные NIC DMA engine’ом слоты в которые пришли данные
• buf_ofs, смещение между началом очереди и началом массива пакетных буферов фиксированного размера ( netmap buffers )
• slots[], массив состоящий из ring_size количества метаданных фиксированного размера. Каждый слот содержит индекс пакетного буфера, содержащего принятые данные (либо данные для отправки), размер пакета, некоторые флаги используемые при обработке пакета
Наконец, netmap_if содержит readonly информацию описывающую netmap интерфейс. Эта информация включает в себя: количество очередей (netmap rings) ассоциированных с сетевой картой и смещение, для получения указателя на каждую из ассоциированных с NIC очередей
Как уже говорилось выше, структуры данных NETMAP используются совместно ядром и пользовательскими программами. В NETMAP’е строго определены «права доступа» и владельцы каждой из структур таким образом, чтобы обеспечить защиту данных. В частности, netmap rings всегда управляются из пользовательской программы, за исключением случаев, когда выполняется системный вызов. В ходе системного вызова, код из kernel space обновляет netmap rings, но делает это в контексте пользовательского процесса. Обработчики прерываний и другие kernel threads никогда не трогают netmap rings.
Пакетные буферы между cur и cur + avail – 1, также управляются пользовательской программой, тогда, как оставшиеся буферы обрабатываются кодом из ядра. В действительности только NIC осуществляет доступ к пакетным буферам. Границы между этими двумя регионами обновляются в ходе системного вызова.
Для того, чтобы перевести сетевую карту в режим netmap, программе следует открыть файловый дескриптор на специальное устройство /dev/netmap и выполнить
Ioctl(…, NIOCREGIF, arg)
Аргументы этого системного вызова содержат: имя интерфейса и (опционально) какой из netmap ring’ов мы хотим открыть, используя только что открытый файловый дескриптор. В случае успеха, вернётся размер разделяемой области памяти, в которой находятся все экспортированные NETMAP’ом структуры данных и смещение к области памяти netmap_if, через которую мы получаем указатели на эти структуры.
После того, как сетевая карта переведена в режим netmap, два следующих системных вызова используются для форсирования приёма или отправки пакетов:
• ioctl (…, NIOCTXSYNC) – синхронизация очередей (netmap rings) для отправки с соответствующими очередями сетевой карты, что эквивалентно отправке пакетов в сеть, синхронизация начинается с позиции cur
• ioctl (…, NIOCRXSYNC) – синхронизация очередей сетевой карты с соответствующими очередями netmap rings, для получения пакетов, поступивших из сети. Запись осуществляется начиная с позиции cur
Оба приведённых выше системных вызова являются не блокирующимися, не выполняют лишнего копирования данных, за исключение копирования из сетевой карты в netmap rings и наоборот и работают как с одном, так и с многими пакетами за один системный вызов. Эта особенность является ключевой и даёт кардинальное уменьшении overhead’ов при обработке пакетов. Ядерная часть обработчика NETMAP в ходе указанных системных вызовов выполняет следующие действия:
• проверяет cur/avail поля очереди и содержимое слотов вовлеченных в обработку (размеры и индексы пакетных буферов в netmap rings и в hardware rings (очередях сетевой карты)
• синхронизирует содержимое вовлечённых в обработку пакетных слотов между netmap rings и hardware rings, выдаёт команду сетевой карте отправить пакеты, либо сообщает о наличии новых свободных буфером для приёма данных
• обновляет поле avail в netmap rings
Как видно, ядерный обработчик NETMAP выполняет минимум работы и включает в себя проверку введённых пользовательских данных для предотвращения краха системы.
Блокируемый ввод/вывод поддерживается с помощью системных вызовов select() / poll() с файловым дескриптором /dev/netmap. Результатом является либо досрочный возврат управления с параметром avail > 0. Перед возвратом управления из контекста ядра система выполнит те же действия, что и в вызовах ioctl(…NIOC**SYNC). Используя данную технику пользовательская программа может, не загружая CPU, в цикле проверять состояние очередей, используя только один системный вызов за проход.
Мощные сетевые карты с несколькими очередями NETMAP позволяет конфигурировать двумя способами в зависимости от того, какое количество очередей необходимо контролировать программе. В режиме по умолчанию один файловый дескриптор /dev/netmap контролирует все netmap rings, но в случае, если при открытии файлового дескриптора указано поле ring_id, файловый дескриптор ассоциируется с единственной парой netmap rings RX/TX. Использование этой техники позволяет привязывать обработчики различных очередей netmap к определённым ядрам процессора через setaffinity() и осуществлять обработку независимо и без необходимости синхронизации.
Пример указанный на рис №5 является прототипом простейшего генератора трафика на базе NETMAP API. Пример предназначен для иллюстрации простоты использования NETMAP API. В примере используются упрощающие понимание кода макросы NETMAP_XXX, позволяющие вычислить указатели на соответствующие структуры данных NETMAP. Для использования NETMAP API нет необходимости использовать какие-либо библиотеки. API разрабатывалось, таким образом, чтобы код получался максимально простым и понятным.
Прототип генератора трафика.
Даже когда сетевая карта переведена в режим netmap, сетевой стек OS всё ещё продолжает управлять сетевым интерфейсом и ничего «не знает» про отключение от сетевой карты. Пользователь может использовать ifconfig и/или генерировать/ожидать пакеты с сетевого интерфейса. Этот трафик, полученный или направленный в сетевой стек OS может быть обработан с использованием специальной пары netmap rings, ассоциированных с файловым дескриптором устройства /dev/netmap.
В случае, когда выполняется NIOCTXSYNC на этом netmap ring, ядерный обработчик netmap инкапсулирует пакетные буферы в структуры mbuf сетевого стека OS, посылая, таким образом, пакеты в стек. Соответственно, пакеты приходящие из стека OS размещаются в специальном netmap ring и становятся доступными пользовательской программе через вызов NIOCRXSYNC. Таким образом, вся ответственность при передаче пакета между netmap rings связанными с host stack и netmap rings связанными с NIC лежит на пользовательской программе.
Процесс, использующий NETMAP, даже если делает, что-то неправильно, не имеет возможности сделать крах системы, в отличие от некоторых других систем, например, таких как UIO-IXGBE, PF_RING_DNA. Фактически, область памяти, экспортируемая NETMAP в user space не содержит критических областей, все индексы и размеры пакетных и других буферов легко проверяются на валидность ядром OS перед использованием.
Наличие всех буферов для всех сетевых карт в одной и той же области разделяемой памяти позволяет осуществлять очень быструю (zero copy) передачу пакетов с одного интерфейса на другой или в host stack. Для этого, всего лишь, необходимо сделать обмен индексами на пакетные буферы в netmap ring’ах ассоциированных с входящим и исходящим интерфейсах, обновить размер пакетов, флаги слотов и выставить значения текущей позиции в netmap ring’е (cur), а также обновить значения netmap ring/avail, которое сигнализирует о появившемся новом пакете для приёма и отправки.
Вследствие комбинирования предельно высокой производительности и удобных механизмов по доступу к содержимому пакетов, управлению маршрутизацией пакетов между интерфейсами и сетевым стеком, NETMAP является очень удобным фреймворком для систем выполняющих обработку сетевых пакетов на больших скоростях. Примерами таких систем являются приложения по мониторингу трафика, IDS/IPS системы, firewall’ы, роутеры и в особенности системы очистки трафика, являющиеся ключевым компонентом систем DDOS защиты.
В качестве основных требований к подсистеме очистки трафика в системе DDOS защиты выбраны возможность фильтрации пакетов на предельных скоростях и возможности по обработке пакетов в системе фильтров, реализующие различные, известные на сегодняшний день техники противодействия DDOS атакам.
Поскольку предполагается, что прототип подсистемы очистки трафика будет анализировать и изменять содержимое пакетов, а также управлять собственными списками и структурами данных, необходимыми для выполнения DDOS защиты, требуется максимально перераспределить ресурсы CPU для выполнения операций модуля DDOS, соответственно, по возможности, оставив в NETMAP необходимый для работы на полной скорости минимум. Для этих целей предполагается ассоциировать несколько ядер CPU для работы со «своими» netmap rings.
В случае, если мы планируется обмен пакетами с сетевым стеком OS, необходимо открыть netmap rings пару ответственную за взаимодействие со стеком.
В результате, после запуска всех thread’ов, в системе остаются max_threads + 1 независимых потока, каждый из которых работает со своим netmap ring без необходимости синхронизации друг с другом. Синхронизация потребуется только в случае обмена с сетевым стеком.
Цикл ожидания и обработки пакетов, таким образом, работает в rx_thread().
Таким образом, после получения сигнала о том, что в одним из netmap_ring после системного вызова poll() поступили входящие пакеты, управление передаётся в функцию process_incoming() для обработки пакетов в фильтрах.
После передачи управления в process_incoming, необходимо получить доступ к содержимому пакетов для анализа и обработки различными техниками распознавания DDOS.
Рассмотренные примеры кода раскрывают основные приёмы по работе с NETMAP, начиная от перевода сетевой карты в режим NETMAP и заканчивая получением доступа к содержимому пакетов при прохождении пакета через цепочку фильтров.
При выполнении тестов на оценку производительности всегда необходимо вначале определиться с метриками тестирования. В обработку пакетов вовлечено множество подсистем: CPU, кэши, шина данных и т.п. В докладе рассмотрена параметр загрузки CPU, т.к. этот параметр может быть наиболее зависим от правильной реализации фреймворка, осуществляющего обработку пакетов.
Загрузку CPU принято измерять исходя из двух подходов: в зависимости от размера передаваемых данных (per-byte costs) и в зависимости от количества обработанных пакетов (per-packet cost). В случае NETMAP, из-за того, что выполняется zero copy packet forwarding, измерение загрузки CPU на основе per-byte не так так интересно, по сравнению с per-packet costs, т.к. отсутствует копирование памяти и следовательно при передаче больших объёмов, нагрузка на CPU будет минимальной. В то же время, при измерениях на основе per-packet costs NETMAP осуществляет относительно много действий при обработке каждого пакета и следовательно, измерение производительности в данном подходе представляет особенный интерес. Итак, измерения проводились на основе самых коротких пакетов, размером 64 байта (60 байт + 4 байта CRC).
Для измерений использовались две программы: генератор трафика на базе NETMAP и получатель трафика, который осуществлял исключительно входящих подсчёт пакетов. Генератор трафика в качестве параметров принимает: количество ядер, размер передаваемого пакета, количество пакетов, передаваемых за оди системный вызов (batch size).
В качестве тестового железа использовалась система с i7-870 4-core 2.93GHz CPU (3.2 GHz в режиме turbo-boost), оперативная память работала на частоте 1.33GHz, в систему установлена двухпортовая сетевая карта на базе чипсета Intel 82599. В качестве операционной системы использовалась FreeBSD HEAD/amd64.
Все измерения проводились на двух одинаковых системах соединённых кабелем напрямую друг с другом. Полученные результаты, хорошо коррелируются, максимальное отклонение от среднего составляет около 2%.
Первые результаты тестов показали, что NETMAP очень эффективен и полностью заполняет канал 10GBit/s максимальным количеством пакетов. Поэтому для выполнения экспериментов было выполнено понижение частоты процессора, с целью определения эффективности изменений, сделанных за счёт кода NETMAP и получения различных зависимостей. Базовая частота (base clock) для СPU Core i7 составляет 133MHz, соответственно, используя CPU multiplier (max х21) имеется возможность запускать систему на наборе дискретных значений вплоть до 3GHz.
Первый тест – выполнение генерации трафика на различных частотах процессора, с использованием различного количества ядер, передавая множество пакетов за один системный вызов (batch mode).
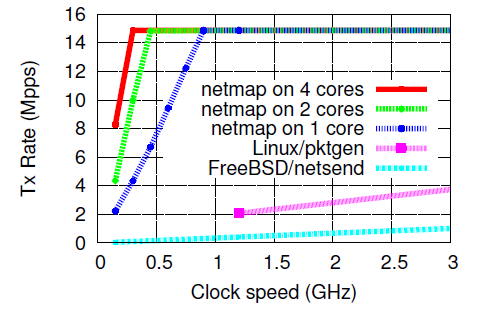
При передаче 64-х байтовых пакетов позволяет мгновенно полностью заполнить 10GBit/s канал на одном ядре и частоте 900Mz. Простые расчёты показывают, что на обработку одного пакета затрачивается примерно 60-65 тактов процессора. Очевидно, что в данном тесте затрагиваются только затраты, которые вносит NETMAP обработку пакета. Не выполняется анализ содержимого пакета и прочие действия по полезной обработке пакета.
Дальнейшее увеличение количества ядер и частоты процессора приводит к тому, что CPU бездействует, до тех пор пока, сетевая карта занимается отправкой пакетов и не сообщит ему о появлении новых свободных слотов для отправки пакетов.
С увеличением частоты, можно наблюдать следующие показатели по загрузке процессора на одном ядре:

Предыдущий тест показывает производительность на самых коротких пакетах, которые являются самым затратным с точки зрения per-packet costs. Данный тест измеряет производительность NETMAP в зависимости от размера передаваемого пакета.
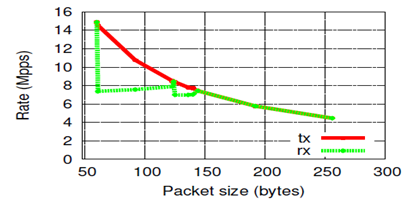
Как видно из рисунка, скорость отправки пакетов почти по формуле 1/size снижается с увеличением размера пакета. Вместе с этим, в качестве сюрприза мы видим, что скорость приёма пакетов изменяется необычным образом. При передаче пакетов размером от 65 до 127 байт скорость падает до 7.5 Mpps. Данная особенность проверена в нескольких сетевых картах, включая 1Gbit/s.
Очевидно, что работа с большим количеством пакетов одновременно снижает overhead’ы и уменьшает стоимость обработки одного пакета. Поскольку не все приложения могут себе позволить работать таким образом, представляет интерес измерение скорости обработки пакетов в зависимости от количества пакетов обрабатываемых за один системный вызов.

Автору NETMAP’а (Luigi Rizzo) удалось добиться кардинального увеличения производительности за счёт исключения из процесса обработки пакетов overhead’ов, возникающих при прохождении пакета через сетевой стек OS. Скорость, которую NETMAP позволяет получить ограничивается только пропускной способностью канала. В NETMAP’е объединены лучшие техники увеличения производительности в обработке сетевых пакетов, а концепция, заложенная в NETMAP API предлагает новый, здоровый подход к разработке высокопроизводительных приложений по обработке сетевого трафика.
В настоящее время эффективность NETMAP оценена сообществом FreeBSD, NETMAP включён в HEAD версию OS FreeBSD, а также в ветки stable/9, stable/8.
Статья сделана на основе моего доклада на Highload++ 2012 и предназначена для быстрого введения в удобный и очень эффективный opensource framework, который включен в HEAD/STABLE FreeBSD, называется NETMAP и позволяет работать с пакетами на скоростях 1-10Gbit/s без использования специализированного железа в обычных *nix операционных системах.
Netmap использует хорошо известные техники увеличения производительности, такие как мапирование в память буферов сетевой карты, пакетная обработка I/O и использование принимающих и передающих кольцевых буферов памяти, соответствующих аппаратным буферам в сетевой карте, что позволяет генерировать и принимать трафик до 14 миллионов пакетов в секунду (что соответствует теоретическому максимуму для 10Gbit/s).
В статье собраны ключевые фрагменты публикаций автора NETMAP — Luigi Rizzo, рассматриваются архитектура и ключевые особенности внутренней реализации netmap framework'а, который инкапсулирует критические функции при работе с ядром OS и сетевой картой, предоставляя в userland простой и понятный API.
Под катом рассматриваются основные примитивы использования фреймворка для разработки приложений связанных с обработкой пакетов на скоростях 14Mpps, рассмотрен практический опыт использования netmap фреймворка при разработке компонента системы DDOS защиты, ответственного за уровень L3. Отдельно рассматриваются сравнительные характеристики производительности netmap на каналах 1/10Gbit/s, одном/нескольких ядрах процессора, больших и коротких пакетах, сравнение производительности со стеками OS FreeBSD / Linux.
1. Введение
Современные операционные системы общего назначения, предоставляют богатые и гибкие возможности для обработки пакетов на низком уровне в программах сетевого мониторинга, генерации трафика, программных коммутаторах, роутерах, межсетевых экранах и системах распознавания атак. Программные интерфейсы, такие как: raw sockets, the Berkley Packet Filter (BPF), интерфейс AF_PACKET и подобные им в настоящее время используются для разработки большей части подобных программ. Высокая скорость обработки пакетов, которая требуется для этих приложений, по всей видимости, не была главной целью при разработке указанных выше механизмов, т.к. в каждой из реализаций присутствуют значительные накладные расходы (далее overhead).
В то же время, значительно увеличившаяся пропускная способность среды передачи, сетевых карт и сетевых устройств, предполагают необходимость такого интерфейса для низкоуровневой обработки пакетов, который бы позволил выполнять обработку на скоростях среды передачи данных (wire speed), т.е. миллионы пакетов в секунду. Для получения лучшей производительности, некоторые системы работают непосредственно в ядре операционной системы или получат доступ непосредственно к структурам сетевой карты (далее NIC) в обход стека TCP/IP и драйвера сетевой карты. Эффективность этих систем обусловлена учётом специфических особенностей железа сетевых карт, обеспечивающих прямой доступ к структурам данных NIC.
NETMAP фреймворк, успешно комбинирует и расширяет идеи, реализованные в решениях по прямому доступу к NIC. Помимо кардинального увеличения производительности, NETMAP предоставляет в userland hardware independent интерфейс для высокопроизводительной обработки пакетов. Приведу здесь одну только метрику для того, чтобы Вы смогли оценить скорость обработки пакетов: пересылка пакета из среды передачи (кабеля) в userspace занимает менее 70 тактов CPU. Другими словами, используя NETMAP только на одном ядре процессора с частотой 900MHz, имеется возможность осуществлять быстрый форвардинг 14.88 миллионов пакетов в секунду (Mpps), что соответствует предельной скорости передачи фреймов Ethernet в канале 10Gbit/s.
Другой важной особенностью NETMAP является то, что он предоставляет аппаратно независимый интерфейс для доступа к регистрам и структурам данных NIC. Эти структуры, а также критические области памяти ядра недоступны для пользовательской программы, что повышает надёжность работы, т.к. из userspace сложно вставить неверный указатель на область памяти и вызвать сбой в ядре OS. Вместе с этим, в NETMAP используется очень эффективная модель данных, позволяющая осуществлять zero-copy packet forwarding, т.е. форвардинг пакетов без необходимости копирования памяти, что позволяет получить колоссальную производительность.
В статье сделан акцент на архитектуре и возможностях, которые предоставляет NETMAP, а также на показателях производительности, которые с его помощью можно получить на обычном железе.
2. TCP/IP стек современных OS
Эта часть статьи будет особенно интересна для разработчиков, которые делают такие приложения как программные свичи, роутеры, файрволы, анализаторы трафика, системы распознавания атак или генераторы трафика. Операционные системы общего назначения, как правило, не предоставляют эффективных механизмов доступа к raw пакетам на высоких скоростях. В этом разделе статьи мы сконцентрируемся на анализе стека TCP/IP в OS, рассмотрим откуда берутся overhead’ы и поймём какова стоимость обработки пакета на разных стадиях его прохождения через стек OS.
2.1. Структуры данных NIC и операции с ними
Сетевые адаптеры (NIC) для обработки входящих и исходящих пакетов используют кольцевые очереди (rings) дескрипторов буферов памяти, как показано на Рис.№1
«Рис №1. Структуры данных NIC и их взаимосвязь со структурами данных OS»
Каждый слот в кольцевой очереди (rings) содержит длину и физический адрес буфера. Доступные (адресуемые) для CPU регистры NIC содержат информацию об очередях для приёма и передачи пакетов.
Когда пакет приходит в сетевую карту, он размещается в текущий буфер памяти, его размер и статус записываются в слот, а информация о том, что появились новые входящие данные для обработки, записывается в соответствующий регистр NIC. Сетевая карта инициирует прерывание, чтобы сообщить CPU о поступлении новых данных.
В случае, когда пакет отправляется в сеть, NIC предполагает, что OS заполнит текущий буфер, разместит в слоте информацию о размере передаваемых данных, запишет в соответствующем регистре NIC количество слотов для передачи, что инициирует отправку пакетов в сеть.
В случае высоких скоростей приёма и передачи пакетов, большое количество прерываний может привести к невозможности выполнить какую-либо полезную работу («receive live-lock»). Для решения этих проблем в OS используют механизм polling или interrupt throttling. Некоторые высокопроизводительные NIC используют множественные очереди для приёма/передачи пакетов, что позволяет распределить нагрузку на процессор по нескольким ядрам или разделить сетевую карту на несколько устройств, для использования в виртуальных системах, работающих с такой сетевой картой.
2.2. Ядро и API для пользователя
OS осуществляет копирование структур данных NIC в очередь из буферов памяти, которая является специфической для каждой конкретной OS. В случае FreeBSD это mbufs её эквиваленты sk_buffs и NdisPackets. По своей сути эти буферы памяти являются контейнерами в которых содержится большое количество метаданных о каждом пакете: размер, интерфейс с/на которого пакет пришёл, различные атрибуты и флаги определяющие порядок обработки данных буфера памяти в NIC и/или OS.
Драйвер NIC и стек TCP/IP операционной системы (далее host stack), как правило, предполагают, что пакеты могут быть разбиты в произвольное количество фрагментов, следовательно и драйвер и host stack должны быть готовы к обработке пакетной фрагментации. Соответствующее API экспортируемое в userspace предполагает, что различные подсистемы могут оставить пакеты для отсроченной обработки, следовательно буферы памяти и метаданные не могут быть просто переданы по ссылке в процессе обработки вызова, но они должны быть скопированы или обработаны механизмом подсчёта ссылок (reference counting). Всё это является платой высокими overhead’ами за гибкость и удобство работы.
Дизайн рассмотренного выше API был разработан довольно продолжительно время назад и на сегодняшний день является слишком затратным для современных систем. Стоимость выделения памяти, управления и прохождения через цепочки буферов часто выходит за рамки линейной зависимости от полезных данных, передаваемых в пакетах.
Стандартное API для ввода/вывода raw пакетов в пользовательской программе требует, как минимум выделения памяти для копирования данных и метаданных между ядром OS и userspace и один системный вызов на каждый пакет (в отдельных случаях, на последовательность пакетов).
Рассмотрим overhead’ы возникающие в OS FreeBSD при отправке UDP-пакета из userlevel с помощью функции sendto(). В данном примере userspace программа в цикле посылает UDP-пакет. Таблица №2 иллюстрирует время, в среднем потраченное на обработку пакета в userspace и различных функциях ядра. В поле Time записано среднее время в наносекундах на обработку пакета, значение записывается, когда функция возвращает управление. В поле delta указано время, прошедшее до начала выполнения следующей функции в цепочке выполнения системного вызова. Для примера, 8 наносекунд занимает выполнение в контексте userspace, 96 наносекунд занимает вход в контекст ядра OS.
Для тестов используем следующие макроопределения, работающие в OS FreeBSD:
Тест выполнялся на компьютере под управлением OS FreeBSD HEAD 64bit, i7-870 2.93GHz (TurboBoost), Intel 10Gbit NIC, ixgbe драйвер. Значения усреднены по нескольким десяткам 5-и секундных тестов.
Как видно из Таблицы №1, имеются несколько функций потребляющих критически большое количество времени на всех уровнях обработки пакета в стеке OS. Любой API для сетевого ввода/вода, будь то TCP, RAW_SOCKET, BPF будет вынужден отправить пакет сквозь несколько очень затратных уровней. Используя это стандартное API нет возможности для обхода механизмов выделения памяти и копирования в mbuf’ах, проверке правильных маршрутов, подготовке и конструированию заголовков TCP/UDP/IP/MAC и в конце этой цепочки обработки, преобразования структур mbuf и метаданных в формат NIC для передачи пакета в сеть. Даже в случае локальной оптимизации, например, кэширование маршрутов и заголовков вместо их построения с нуля, не даёт радикального увеличения скорости, которая требуется для обработки пакетов на интерфейсах 10 Gbit/s.
2.3. Современные техники увеличения производительности при обработке пакетов на больших скоростях
Поскольку проблема высокоскоростной обработки пакетов стоит относительно давно, уже разработаны и используются различные техники увеличения производительности, позволяющие качественно увеличить скорость обработки.
Socket API
Berkley Packet Filter (далее BPF) является наиболее популярным механизмом для получения доступа к raw пакетам. BPF подключается к драйверу сетевой карты и отправляет копию каждого принятого или отправленного пакета в файловый дескриптор из которого его может получать/отправлять пользовательская программа. Linux имеет подобный механизм, называемый семейство сокетов AF_PACKET. BPF работает вместе со стеком TCP/IP, хотя в большинстве случаев, он переводит сетевую карту в «прозрачный» режим (promiscuous), что приводит к большому потоку постороннего трафика, который попадает в ядро и тут же там удаляется.
Packet filter hooks
Netgraph (FreeBSD), Netfilter (Linux), Ndis Miniport драйверы (MS Windows) являются встроенными в ядро механизмами, которые используются в случае, когда копирование пакетов не требуется и приложение, например firewall, должно быть встроено в цепочку прохождения пакетов. Эти механизмы принимают трафик от драйвера сетевой карты и передают его в модули обработки без дополнительного копирования. Очевидно, что все указанные в данном пункте механизмы опираются на представление пакетов в виде mbuf/sk_buff.
Direct buffer access
Одним из простых способов избежать дополнительного копирования в процессе передачи пакета из kernel space в user space и наоборот является возможность разрешить приложению прямой доступ к структурам NIC. Как правило, для этого требуется, чтобы приложение работало в ядре OS. Примерами могут быть проект программного роутера Click или генератор трафика kernel mode pkt-gen. Наряду с простотой доступа, kernel space является очень хрупкой средой, ошибки в которой могут привести к падению системы, поэтому более правильный механизм это экспортирование пакетных буферов в userspace. Примерами данного подхода являются PF_RING и Linux PACKET_MMAP, которые экспортируют область разделяемой памяти, содержащей заранее выделенные области для сетевых пакетов. Ядро операционной системы при этом осуществляет копирование данных между sk_buff’ерами и пакетными буферами в разделяемой памяти. Это позволяет выполнять групповую обработку пакетов, но при этом остаются overheads связанные с копированием и управлением цепочкой sk_buff.
Ещё более высокую производительность можно достигнуть в случае разрешения доступа к NIC прямо из userspace. Этот подход требует специальных драйверов NIC и увеличивает некоторые риски, т.к. NIC DMA engine сможет записать данные по любому адресу памяти и неправильно написанный клиент может случайно «убить» систему затерев критические данные где-нибудь в ядре. Справедливо заметить, что в большом количестве современных сетевых карт имеется блок IOMMU, который осуществляет ограничение записи NIC DMA engine в память. Примером данного подхода в ускорении производительности являются PF_RING_DNA и некоторые коммерческие решения.
3. Архитектура NETMAP
3.1. Основные особенности
В предыдущем материале рассматривались различные механизмы увеличения производительности обработки пакетов на высоких скоростях. Были проанализированы затратные операции в обработке данных, такие как: копирование данных, управление метаданными и другие overhead’ы возникающие при прохождении пакета из userspace через стек TCP/IP в сеть.
Представленный в докладе фреймворк, именуемый NETMAP, представляет собой систему, которая предоставляет userspace приложению очень быстрый доступ к сетевым пакетам, как для приёма, так и для отправки, как при обмене с сетью, так и при работе со стеком TCP/IP OS (host stack). При этом, эффективность не приносится в жертву рискам, возникающим при полном открытии структур данных и регистров сетевой карты в userspace. Фреймворк самостоятельно управляет сетевой картой, операционная система, при этом, выполняет защиту памяти.
Также, отличительной особенностью NETMAP является тесная интеграция с существующими механизмами OS и отсутствие зависимости от аппаратных особенностей специфических сетевых карт. Для достижения желаемых высоких характеристик по произвдительности NETMAP использует несколько известных техник:
• Компактные и лёгкие структуры метаданных пакета. Простые для использования, они скрывают аппаратно-зависимые механизмы, предоставляя удобный и простой способ работы с пакетами. Кроме того, метаданные NETMAP построены таким образом, чтобы обрабатывать множество самых разных пакетов за один системный вызов, уменьшая, таким образом, накладные расходы на передачу пакетов.
• Линейные preallocated буферы, фиксированных размеров. Позволяют уменьшать накладные расходы на управление памятью.
• Zero copy операции при форвардинге пакетов между интерфейсами, а также между интерфейсами и host stack’ом.
• Поддержка таких полезных аппаратных особенностей сетевых карт, как множественные аппаратные очереди.
В NETMAP каждая подсистема делает ровно то, для чего предназначена: NIC пересылает данные между сетью и оперативной памятью, ядро OS выполняет защиту памяти, обеспечивает многозадачность и синхронизацию.
Рис. №2. В режиме NETMAP очереди NIC отключены от стека TCP/IP OS. Обмен между сетью и host stack осуществляется только через NETMAP API
На самом верхнем уровне, когда приложение через NETMAP API переводит сетевую карту в режим NETMAP, очереди NIC отсоединяются от host stack. Программа таким, образом получает возможность контролировать обмен пакетами между сетью и стеком OS, используя для этого кольцевые буферы, которые называются «netmap rings». Netmap rings, в свою очередь, реализованы в разделяемой памяти (shared memory). Для синхронизации очередей в NIC и стеке OS используются обычные системные вызовы OS: select()/poll(). Несмотря на отключение стека TCP/IP от сетевой карты, операционная система продолжает работать и выполнять свои операции.
3.2. Структуры данных
Ключевые структуры данных NETMAP изображены на Рис. №3. Структуры были разработаны с учётом следующих задач:
• Уменьшение overhead’ов при обработки пакетов
• Увеличение эффективности при передаче пакетов между интерфейсами, а также между интерфейсами и стеком
• Поддержка аппаратных множественных очередей в сетевых картах
Рис. №3. Структуры экспортируемые NETMAP в userspace
NETMAP содержит три типа объектов, видимых из userspace:
• Пакетные буферы ( packet buffers )
• Кольцевые буферы-очереди ( netmap rings )
• Дескриптор интерфейса ( netmap_if )
Все объекты всех netmap enabled интерфейсов системы находятся в одной и той же области невыгружаемой разделяемой памяти, которая выделена ядром и доступна между процессам из user space. Использование такого выделенного сегмента памяти позволяет удобным образом осуществлять zero copy обмен пакетами между всеми интерфейсами и стеком. Вместе с тем, NETMAP поддерживает разделение интерфейсов или очередей таким образом, чтобы изолировать области памяти предоставляемые разным процессам друг от друга.
Поскольку разные пользовательские процессы работают в различных виртуальных адресах, все ссылки в экспортируемых NETMAP структурах данных являются относительными, т.е. являются смещениями.
Пакетные буферы (packet buffers) имеют фиксированный размер (2K в настоящее время) и используются одновременно NIC и пользовательскими процессами. Каждый буфер идентифицируется по уникальному индексу, его виртуальный адрес может быть легко вычислен пользовательским процессом, а его физический адрес может быть легко вычислен NIC DMA engine’ом.
Все netmap буферы выделяются в тот момент, когда сетевая карта переводится в режим NETMAP. Метаданные, описывающие буфер, такие как, индекс, размер и некоторые флаги, сохраняются в слотах ( slots ), которые являются основной ячейкой netmap ring’а, о котором будет рассказано ниже. Каждый буфер привязан к netmap ring и соответствующе й очереди в сетевой карте ( hardware ring ).
«Netmap ring» является абстракцией аппаратных кольцевых очередей сетевой карты. Netmap ring характеризуется следующими параметрами:
• ring_size, количество слотов в очереди (netmap ring)
• cur, текущий слот для записи/чтения в очереди
• avail, количество доступных слотов: в случае TX – это пустые слоты, через которые можно отправить данные, в случае RX – это заполненные NIC DMA engine’ом слоты в которые пришли данные
• buf_ofs, смещение между началом очереди и началом массива пакетных буферов фиксированного размера ( netmap buffers )
• slots[], массив состоящий из ring_size количества метаданных фиксированного размера. Каждый слот содержит индекс пакетного буфера, содержащего принятые данные (либо данные для отправки), размер пакета, некоторые флаги используемые при обработке пакета
Наконец, netmap_if содержит readonly информацию описывающую netmap интерфейс. Эта информация включает в себя: количество очередей (netmap rings) ассоциированных с сетевой картой и смещение, для получения указателя на каждую из ассоциированных с NIC очередей
3.3. Контексты обработки данных
Как уже говорилось выше, структуры данных NETMAP используются совместно ядром и пользовательскими программами. В NETMAP’е строго определены «права доступа» и владельцы каждой из структур таким образом, чтобы обеспечить защиту данных. В частности, netmap rings всегда управляются из пользовательской программы, за исключением случаев, когда выполняется системный вызов. В ходе системного вызова, код из kernel space обновляет netmap rings, но делает это в контексте пользовательского процесса. Обработчики прерываний и другие kernel threads никогда не трогают netmap rings.
Пакетные буферы между cur и cur + avail – 1, также управляются пользовательской программой, тогда, как оставшиеся буферы обрабатываются кодом из ядра. В действительности только NIC осуществляет доступ к пакетным буферам. Границы между этими двумя регионами обновляются в ходе системного вызова.
4. Основные операции в NETMAP
4.1. Netmap API
Для того, чтобы перевести сетевую карту в режим netmap, программе следует открыть файловый дескриптор на специальное устройство /dev/netmap и выполнить
Ioctl(…, NIOCREGIF, arg)
Аргументы этого системного вызова содержат: имя интерфейса и (опционально) какой из netmap ring’ов мы хотим открыть, используя только что открытый файловый дескриптор. В случае успеха, вернётся размер разделяемой области памяти, в которой находятся все экспортированные NETMAP’ом структуры данных и смещение к области памяти netmap_if, через которую мы получаем указатели на эти структуры.
После того, как сетевая карта переведена в режим netmap, два следующих системных вызова используются для форсирования приёма или отправки пакетов:
• ioctl (…, NIOCTXSYNC) – синхронизация очередей (netmap rings) для отправки с соответствующими очередями сетевой карты, что эквивалентно отправке пакетов в сеть, синхронизация начинается с позиции cur
• ioctl (…, NIOCRXSYNC) – синхронизация очередей сетевой карты с соответствующими очередями netmap rings, для получения пакетов, поступивших из сети. Запись осуществляется начиная с позиции cur
Оба приведённых выше системных вызова являются не блокирующимися, не выполняют лишнего копирования данных, за исключение копирования из сетевой карты в netmap rings и наоборот и работают как с одном, так и с многими пакетами за один системный вызов. Эта особенность является ключевой и даёт кардинальное уменьшении overhead’ов при обработке пакетов. Ядерная часть обработчика NETMAP в ходе указанных системных вызовов выполняет следующие действия:
• проверяет cur/avail поля очереди и содержимое слотов вовлеченных в обработку (размеры и индексы пакетных буферов в netmap rings и в hardware rings (очередях сетевой карты)
• синхронизирует содержимое вовлечённых в обработку пакетных слотов между netmap rings и hardware rings, выдаёт команду сетевой карте отправить пакеты, либо сообщает о наличии новых свободных буфером для приёма данных
• обновляет поле avail в netmap rings
Как видно, ядерный обработчик NETMAP выполняет минимум работы и включает в себя проверку введённых пользовательских данных для предотвращения краха системы.
4.2. Примитивы блокирования
Блокируемый ввод/вывод поддерживается с помощью системных вызовов select() / poll() с файловым дескриптором /dev/netmap. Результатом является либо досрочный возврат управления с параметром avail > 0. Перед возвратом управления из контекста ядра система выполнит те же действия, что и в вызовах ioctl(…NIOC**SYNC). Используя данную технику пользовательская программа может, не загружая CPU, в цикле проверять состояние очередей, используя только один системный вызов за проход.
4.3. Интерфейс с несколькими очередями
Мощные сетевые карты с несколькими очередями NETMAP позволяет конфигурировать двумя способами в зависимости от того, какое количество очередей необходимо контролировать программе. В режиме по умолчанию один файловый дескриптор /dev/netmap контролирует все netmap rings, но в случае, если при открытии файлового дескриптора указано поле ring_id, файловый дескриптор ассоциируется с единственной парой netmap rings RX/TX. Использование этой техники позволяет привязывать обработчики различных очередей netmap к определённым ядрам процессора через setaffinity() и осуществлять обработку независимо и без необходимости синхронизации.
4.4. Пример использования
Пример указанный на рис №5 является прототипом простейшего генератора трафика на базе NETMAP API. Пример предназначен для иллюстрации простоты использования NETMAP API. В примере используются упрощающие понимание кода макросы NETMAP_XXX, позволяющие вычислить указатели на соответствующие структуры данных NETMAP. Для использования NETMAP API нет необходимости использовать какие-либо библиотеки. API разрабатывалось, таким образом, чтобы код получался максимально простым и понятным.
fds.fd = open("/dev/netmap", O_RDWR); strcpy(nmr.nm_name, "ix0"); ioctl(fds.fd, NIOCREG, &nmr); p = mmap(0, nmr.memsize, fds.fd); nifp = NETMAP_IF(p, nmr.offset); fds.events = POLLOUT; for (;;) { poll(fds, 1, -1); for (r = 0; r < nmr.num_queues; r++) { ring = NETMAP_TXRING(nifp, r); while (ring->avail-- > 0) { i = ring->cur; buf = NETMAP_BUF(ring, ring->slot[i].buf_index); //... store the payload into buf ... ring->slot[i].len = ... // set packet length ring->cur = NETMAP_NEXT(ring, i); } } }
Прототип генератора трафика.
4.5. Передача/приём пакетов в/из host stack
Даже когда сетевая карта переведена в режим netmap, сетевой стек OS всё ещё продолжает управлять сетевым интерфейсом и ничего «не знает» про отключение от сетевой карты. Пользователь может использовать ifconfig и/или генерировать/ожидать пакеты с сетевого интерфейса. Этот трафик, полученный или направленный в сетевой стек OS может быть обработан с использованием специальной пары netmap rings, ассоциированных с файловым дескриптором устройства /dev/netmap.
В случае, когда выполняется NIOCTXSYNC на этом netmap ring, ядерный обработчик netmap инкапсулирует пакетные буферы в структуры mbuf сетевого стека OS, посылая, таким образом, пакеты в стек. Соответственно, пакеты приходящие из стека OS размещаются в специальном netmap ring и становятся доступными пользовательской программе через вызов NIOCRXSYNC. Таким образом, вся ответственность при передаче пакета между netmap rings связанными с host stack и netmap rings связанными с NIC лежит на пользовательской программе.
4.6. Соображения безопасности
Процесс, использующий NETMAP, даже если делает, что-то неправильно, не имеет возможности сделать крах системы, в отличие от некоторых других систем, например, таких как UIO-IXGBE, PF_RING_DNA. Фактически, область памяти, экспортируемая NETMAP в user space не содержит критических областей, все индексы и размеры пакетных и других буферов легко проверяются на валидность ядром OS перед использованием.
4.7. Zero copy packet forwarding
Наличие всех буферов для всех сетевых карт в одной и той же области разделяемой памяти позволяет осуществлять очень быструю (zero copy) передачу пакетов с одного интерфейса на другой или в host stack. Для этого, всего лишь, необходимо сделать обмен индексами на пакетные буферы в netmap ring’ах ассоциированных с входящим и исходящим интерфейсах, обновить размер пакетов, флаги слотов и выставить значения текущей позиции в netmap ring’е (cur), а также обновить значения netmap ring/avail, которое сигнализирует о появившемся новом пакете для приёма и отправки.
ns_src = &src_nr_rx->slot[i]; /* locate src and dst slots */ ns_dst = &dst_nr_tx->slot[j]; /* swap the buffers */ tmp = ns_dst->buf_index; ns_dst->buf_index = ns_src->buf_index; ns_src->buf_index = tmp; /* update length and flags */ ns_dst->len = ns_src->len; /* tell kernel to update addresses in the NIC rings */ ns_dst->flags = ns_src->flags = BUF_CHANGED; dst_nr_tx->avail--; // Для большей ясности кода проверка src_nr_rx->avail--; // avail > 0 не сделана
5. Пример: NETMAP API для использования в подсистеме очистки трафика для системы DDOS защиты
5.1. Основные требования
Вследствие комбинирования предельно высокой производительности и удобных механизмов по доступу к содержимому пакетов, управлению маршрутизацией пакетов между интерфейсами и сетевым стеком, NETMAP является очень удобным фреймворком для систем выполняющих обработку сетевых пакетов на больших скоростях. Примерами таких систем являются приложения по мониторингу трафика, IDS/IPS системы, firewall’ы, роутеры и в особенности системы очистки трафика, являющиеся ключевым компонентом систем DDOS защиты.
В качестве основных требований к подсистеме очистки трафика в системе DDOS защиты выбраны возможность фильтрации пакетов на предельных скоростях и возможности по обработке пакетов в системе фильтров, реализующие различные, известные на сегодняшний день техники противодействия DDOS атакам.
5.2. Подготовка и включение режима netmap mode
Поскольку предполагается, что прототип подсистемы очистки трафика будет анализировать и изменять содержимое пакетов, а также управлять собственными списками и структурами данных, необходимыми для выполнения DDOS защиты, требуется максимально перераспределить ресурсы CPU для выполнения операций модуля DDOS, соответственно, по возможности, оставив в NETMAP необходимый для работы на полной скорости минимум. Для этих целей предполагается ассоциировать несколько ядер CPU для работы со «своими» netmap rings.
struct nmreq nmr; //… for (i=0, i < MAX_THREADS, i++) { // … targ[i]->nmr.ringid = i | NETMAP_HW_RING; … ioctl(targ[i].fd, NIOCREGIF, &targ[i]->nmr); //… targ[i]->mem = mmap(0, targ[i]->nmr.nr_memsize, PROT_WRITE | PROT_READ, MAP_SHARED, targ[i].fd, 0); targ[i]->nifp = NETMAP_IF(targ[i]->mem, targ[i]->nmr.nr_offset); targ[i]->nr_tx = NETMAP_TXRING(targ[i]->nifp, i); targ[i]->nr_rx = NETMAP_RXRING(targ[i]->nifp, i); //… }
В случае, если мы планируется обмен пакетами с сетевым стеком OS, необходимо открыть netmap rings пару ответственную за взаимодействие со стеком.
struct nmreq nmr; //… /* NETMAP ассоциирует netmap ring с наибольшим ringid с сетевым стеком */ targ->nmr.ringid = stack_ring_id | NETMAP_SW_RING; // … ioctl(targ.fd, NIOCREGIF, &targ->nmr); // … <h2>5.3. Главный цикл rx_thread</h2> После выполнения всей необходимой подготовки и переводу сетевой карты в режим NETMAP, осуществляется запуск на выполнение thread’ов <source lang="cpp"> for ( i = 0; i < MAX_THREADS; i++ ) { /* start first rx thread */ targs[i].used = 1; if (pthread_create(&targs[i].thread, NULL, rx_thread, &targs[i]) == -1) { D("Unable to create thread %d", i); exit(-1); } } //… /* Wait until threads will finish their loops */ for ( r = 0; r < MAX_THREAD; r++ ) { if( pthread_join(targs[r].thread, NULL) ) ioctl(targs[r].fd, NIOCUNREGIF, &targs[r].nmr); close(targs[r].fd); } //… }
В результате, после запуска всех thread’ов, в системе остаются max_threads + 1 независимых потока, каждый из которых работает со своим netmap ring без необходимости синхронизации друг с другом. Синхронизация потребуется только в случае обмена с сетевым стеком.
Цикл ожидания и обработки пакетов, таким образом, работает в rx_thread().
while(targ->used) { ret = poll(fds, 2, 1 * 100); if (ret <= 0) continue; … /* run filters */ for ( i = targ->begin; i < targ->end; i++) { ioctl(targ->fd, NIOCTXSYNC, 0); ioctl(targ->fd_stack, NIOCTXSYNC, 0); targ->rx = NETMAP_RXRING(targ->nifp, i); targ->tx = NETMAP_TXRING(targ->nifp, i); if (targ->rx->avail > 0) { … /* process rings */ cnt = process_incoming(targ->id, targ->rx, targ->tx, targ->stack_rx, targ->stack_tx); … } }
Таким образом, после получения сигнала о том, что в одним из netmap_ring после системного вызова poll() поступили входящие пакеты, управление передаётся в функцию process_incoming() для обработки пакетов в фильтрах.
5.5. process_incoming()
После передачи управления в process_incoming, необходимо получить доступ к содержимому пакетов для анализа и обработки различными техниками распознавания DDOS.
limit = nic_rx->avail; while ( limit-- > 0 ) { struct netmap_slot *rs = &nic_rx->slot[j]; // rx slot struct netmap_slot *ts = &nic_tx->slot[k]; // tx slot eth = (struct ether_header *)NETMAP_BUF(nic_rx, rs->buf_idx); if (eth->ether_type != htons(ETHERTYPE_IP)) { goto next_packet; // pass non-ip packet } /* get ip header of the packet */ iph = (struct ip *)(eth + 1); // … }
Рассмотренные примеры кода раскрывают основные приёмы по работе с NETMAP, начиная от перевода сетевой карты в режим NETMAP и заканчивая получением доступа к содержимому пакетов при прохождении пакета через цепочку фильтров.
6. Производительность
6.1. Метрики
При выполнении тестов на оценку производительности всегда необходимо вначале определиться с метриками тестирования. В обработку пакетов вовлечено множество подсистем: CPU, кэши, шина данных и т.п. В докладе рассмотрена параметр загрузки CPU, т.к. этот параметр может быть наиболее зависим от правильной реализации фреймворка, осуществляющего обработку пакетов.
Загрузку CPU принято измерять исходя из двух подходов: в зависимости от размера передаваемых данных (per-byte costs) и в зависимости от количества обработанных пакетов (per-packet cost). В случае NETMAP, из-за того, что выполняется zero copy packet forwarding, измерение загрузки CPU на основе per-byte не так так интересно, по сравнению с per-packet costs, т.к. отсутствует копирование памяти и следовательно при передаче больших объёмов, нагрузка на CPU будет минимальной. В то же время, при измерениях на основе per-packet costs NETMAP осуществляет относительно много действий при обработке каждого пакета и следовательно, измерение производительности в данном подходе представляет особенный интерес. Итак, измерения проводились на основе самых коротких пакетов, размером 64 байта (60 байт + 4 байта CRC).
Для измерений использовались две программы: генератор трафика на базе NETMAP и получатель трафика, который осуществлял исключительно входящих подсчёт пакетов. Генератор трафика в качестве параметров принимает: количество ядер, размер передаваемого пакета, количество пакетов, передаваемых за оди системный вызов (batch size).
6.2. Тестовое железо и OS
В качестве тестового железа использовалась система с i7-870 4-core 2.93GHz CPU (3.2 GHz в режиме turbo-boost), оперативная память работала на частоте 1.33GHz, в систему установлена двухпортовая сетевая карта на базе чипсета Intel 82599. В качестве операционной системы использовалась FreeBSD HEAD/amd64.
Все измерения проводились на двух одинаковых системах соединённых кабелем напрямую друг с другом. Полученные результаты, хорошо коррелируются, максимальное отклонение от среднего составляет около 2%.
Первые результаты тестов показали, что NETMAP очень эффективен и полностью заполняет канал 10GBit/s максимальным количеством пакетов. Поэтому для выполнения экспериментов было выполнено понижение частоты процессора, с целью определения эффективности изменений, сделанных за счёт кода NETMAP и получения различных зависимостей. Базовая частота (base clock) для СPU Core i7 составляет 133MHz, соответственно, используя CPU multiplier (max х21) имеется возможность запускать систему на наборе дискретных значений вплоть до 3GHz.
6.3. Скорость в зависимости от частоты процессора, ядер и т.п.
Первый тест – выполнение генерации трафика на различных частотах процессора, с использованием различного количества ядер, передавая множество пакетов за один системный вызов (batch mode).
При передаче 64-х байтовых пакетов позволяет мгновенно полностью заполнить 10GBit/s канал на одном ядре и частоте 900Mz. Простые расчёты показывают, что на обработку одного пакета затрачивается примерно 60-65 тактов процессора. Очевидно, что в данном тесте затрагиваются только затраты, которые вносит NETMAP обработку пакета. Не выполняется анализ содержимого пакета и прочие действия по полезной обработке пакета.
Дальнейшее увеличение количества ядер и частоты процессора приводит к тому, что CPU бездействует, до тех пор пока, сетевая карта занимается отправкой пакетов и не сообщит ему о появлении новых свободных слотов для отправки пакетов.
С увеличением частоты, можно наблюдать следующие показатели по загрузке процессора на одном ядре:
6.4. Скорость в зависимости от размера пакета
Предыдущий тест показывает производительность на самых коротких пакетах, которые являются самым затратным с точки зрения per-packet costs. Данный тест измеряет производительность NETMAP в зависимости от размера передаваемого пакета.
Как видно из рисунка, скорость отправки пакетов почти по формуле 1/size снижается с увеличением размера пакета. Вместе с этим, в качестве сюрприза мы видим, что скорость приёма пакетов изменяется необычным образом. При передаче пакетов размером от 65 до 127 байт скорость падает до 7.5 Mpps. Данная особенность проверена в нескольких сетевых картах, включая 1Gbit/s.
6.5. Скорость в зависимости от количества пакетов за один системный вызов
Очевидно, что работа с большим количеством пакетов одновременно снижает overhead’ы и уменьшает стоимость обработки одного пакета. Поскольку не все приложения могут себе позволить работать таким образом, представляет интерес измерение скорости обработки пакетов в зависимости от количества пакетов обрабатываемых за один системный вызов.
7. Заключение
Автору NETMAP’а (Luigi Rizzo) удалось добиться кардинального увеличения производительности за счёт исключения из процесса обработки пакетов overhead’ов, возникающих при прохождении пакета через сетевой стек OS. Скорость, которую NETMAP позволяет получить ограничивается только пропускной способностью канала. В NETMAP’е объединены лучшие техники увеличения производительности в обработке сетевых пакетов, а концепция, заложенная в NETMAP API предлагает новый, здоровый подход к разработке высокопроизводительных приложений по обработке сетевого трафика.
В настоящее время эффективность NETMAP оценена сообществом FreeBSD, NETMAP включён в HEAD версию OS FreeBSD, а также в ветки stable/9, stable/8.
