Ниже дан перевод статьи
A SIMPLE BUT EFFICIENT REAL-TIME VOICE ACTIVITY DETECTION ALGORITHM
М.H. Moattar and M.M. Homayonpour
Laboratory for Intelligent Sound and Speech Processing (LISSP), Computer Engineering and Information Technology Dept., Amirkabir University of Technology, Tehran, Iran
Оригинал по ссылке
Алгоритм обнаружения активности голоса (Voice Activity Detection, далее VAD) очень важный метод в приложениях обработки речи и аудио. Эффективность большинства, если не всех методов обработки речи/аудио сильно зависит от эффективности применяемого алгоритма VAD. Идеальный детектор активности голоса должен быть независимым от области применения приложения, от уровня шума и быть наименее зависимым от максимума параметров приложения, в котором его используют. В этой статье предлагается близкий к идеальному алгоритм VAD, который одновременно легок в реализации и устойчив к шуму. Предложенный метод использует такие кратковременные характеристики как Spectral Flatness (SF) (спектральная плоскостность, ровность) и Short-term Energy, что делает метод целесообразным для применения в реальном времени. Этот метод был проверен на нескольких записях с разным уровнем шума и сравнивался с недавно преложенными методами. Эксперименты показали удовлетворительные результаты при разных уровнях шума.
Voice Activity Detection(VAD) то-есть обнаружение тишины в речевом или аудио сигнале — это очень важная задача для многих приложений, которые работаю с аудио или речью, включая кодирование, распознавание, повышения разборчивости речи, и индексации аудио. Например, в стандарте GSM 729 [1] используется два VAD модуля для кодирования с разным количеством бит в сэмпле. Устойчивость VAD к шуму также очень важна для распознавания речи (Automatic Speech Recognition ASR). Хороший детектор улучшит точность и скорость любого ASR в шумном окружении.
Согласно [2], необходимые характеристики для идеального детектора активности голоса это: надежность, устойчивость, точность, адаптивность, простота, возможность применения в реальном времени, без информации о присутствующем шуме. Достичь устойчивости к шуму сложнее всего. В условиях высокого SNR (Signal-to-noise ratio), простейшие VAD алгоритмы работают удовлетворительно, но при условиях низкого SNR все алгоритмы VAD деградируют до определенной степени. В тоже время, алгоритм VAD должен оставаться простым, для удовлетворения требования применимости в реальном времени. Поэтому простота и устойчивость к шуму — это две существенные характеристики практичного детектора активности речи.
Было предложено много алгоритмов VAD, главное отличие которых в используемых характеристиках. Среди всех характеристик, Short-term Energy и zero-crossing rate из-за своей простоты использовались чаще. Однако, они сильно деградируют при наличии шумов. Для того что бы исправить этот недостаток были предложены разные устойчивые акустические характеристики на основе — функции автокорреляции [3, 4], спектра(spectrum based ) [5], мощности на узкополосном отрезке (power in the band-limited region) [1, 6, 7], MFCC (Mel-frequency Cepstral Coefficients [4] — Кепстральные коэффициенты тональной частоты. Почитать можно в книге spbu), дельт спектральных частот (delta line spectral frequencies)[6] и статистик высшего порядка [8]. Эксперименты показали, что использование этих характеристик приводит к увеличению устойчивости VAD к шумам. В некоторых работах предлагается использование разных характеристик в комбинации с некоторыми моделирующими алгоритмами как CART (Classification and Regression Tree)[9] и ANN (Artificial Neural-Network) [10], однако эти алгоритмы по сложности сравнимы с самим VAD.
C другой стороны, некоторые методы используют модели шумов [11], или используют улучшенный спектр речи, полученный после статистической фильтрации шумов фильтром Винера (Wiener filter) [7, 12]. Большинство характеристик предполагают наличие стационарного шума в течении определенного периода, поэтому они чувствительны к изменениям в SNR обрабатываемого сигнала. Некоторые работы предлагают вычисление шума и адаптацию для улучшения устойчивости VAD [13], но эти методы имеют большую вычислительную сложность.
Также, существуют стандарты VADs, которые используются для создания новых методов детектирования. Среди них GSM 729 [1], ETSI AMR [14] и AFE [15]. Например, стандарт GSM 729 использует линейный спектр пары частот, full-band energy и low-band energy, zero-crossing rate и применяет классификатор с использованием фиксированных границ в ограниченном пространстве [1].
В этой работе предложен алгоритм VAD, который одновременно легок в реализации и может быть использован для обработки речи/аудио в реальном времени, а также дает удовлетворительную устойчивость к шумам. В секции 3 детально разбирается алгоритм предложенного VAD.
В предложенном методе мы используем три разных характеристики для каждого фрэйма. Первая характеристика это краткосрочная энергия (Е). Энергия — наиболее часто используемая характеристика в определении речи/тишины. Однако, она становится неэффективной в условиях шума, особенно при низких SNR. Поэтому, мы используем еще две характеристики, которые вычисляются из частот.
Вторая характеристика это мера спектральной плоскостности (SFM — Spectral Flatness Measure). Мера зашумленности спектра хорошо себя показывает в Голосовом/Неголосовом детекритовании и обнаружении тишины.
Считается SFM по следующей формуле:
SMFdb= 10log10(Gm / Am)
Где Am и Gm это соответственно среднее арифметическое и среднее геометрическое спектра речи.
Кроме этих двух характеристик было обнаружено, что составляющая фрэйма речи с преобладающими частотами (most dominant frequency component) может быть очень полезна для различения фрэймов с речью и тишиной. В этой работе эта характеристика обозначена через F. Она легко вычисляется через нахождения такой частоты, которая соответствует максимальному значению величины спектра | S(k) |.
В предложенном методе для детектирования голосовой активности все три характеристики вычисляются одновременно для каждого фрейма.

Изображение 1. Значения характеристик на чистом речевом сигнале
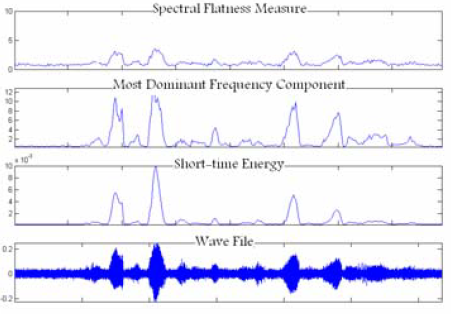
Изображение 2. Значение характеристик на сигнале, поврежденном белым шумом
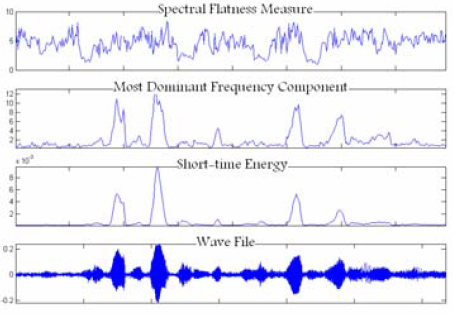
Изображение 3. Значение характеристик на сигнале, поврежденном шумом лепета
Изображения 1-3 представляют эффективность этих трех характеристик на чистом и поврежденном шумом сигнале.
Предложенный алгоритм начинается с разбиения аудио-сигнала на фреймы. В нашей реализации не применяется оконная функция. Первые N фреймов используются для инициализации порогового значения. Для каждого входящего фрейма вычисляются три характеристики. Аудио-фрейм считается речевым, если значение более одной характеристики превышает пороговое значение. Полная процедура предложенного метода представлена ниже:
В алгоритме есть три параметра, которые необходимо установить в первую очередь. Эти параметры были найдены автоматически на конечном наборе чистых речевых сигналов. Ниже представлены оптимальные значения, полученные в результате экспериментов.
Energy_PrimThresh = 40
F_PrimThresh (Hz) = 185
SF_PrimThresh = 5
В оригинальной статье предоставлены результаты экспериментов проведенных в условиях разной зашумленности. Хотелось бы узнать мнение сообщества о данной теме и о самом переводе. Есть ли смысл продолжать выкладывать переводы на эту тему? О всех неточностях перевода, ошибках писать в личные сообщения.
Не нашел как указать что это перевод, кроме как приписать пост к хабу Переводы.
A SIMPLE BUT EFFICIENT REAL-TIME VOICE ACTIVITY DETECTION ALGORITHM
М.H. Moattar and M.M. Homayonpour
Laboratory for Intelligent Sound and Speech Processing (LISSP), Computer Engineering and Information Technology Dept., Amirkabir University of Technology, Tehran, Iran
Оригинал по ссылке
РЕЗЮМЕ
Алгоритм обнаружения активности голоса (Voice Activity Detection, далее VAD) очень важный метод в приложениях обработки речи и аудио. Эффективность большинства, если не всех методов обработки речи/аудио сильно зависит от эффективности применяемого алгоритма VAD. Идеальный детектор активности голоса должен быть независимым от области применения приложения, от уровня шума и быть наименее зависимым от максимума параметров приложения, в котором его используют. В этой статье предлагается близкий к идеальному алгоритм VAD, который одновременно легок в реализации и устойчив к шуму. Предложенный метод использует такие кратковременные характеристики как Spectral Flatness (SF) (спектральная плоскостность, ровность) и Short-term Energy, что делает метод целесообразным для применения в реальном времени. Этот метод был проверен на нескольких записях с разным уровнем шума и сравнивался с недавно преложенными методами. Эксперименты показали удовлетворительные результаты при разных уровнях шума.
1. ВВЕДЕНИЕ
Voice Activity Detection(VAD) то-есть обнаружение тишины в речевом или аудио сигнале — это очень важная задача для многих приложений, которые работаю с аудио или речью, включая кодирование, распознавание, повышения разборчивости речи, и индексации аудио. Например, в стандарте GSM 729 [1] используется два VAD модуля для кодирования с разным количеством бит в сэмпле. Устойчивость VAD к шуму также очень важна для распознавания речи (Automatic Speech Recognition ASR). Хороший детектор улучшит точность и скорость любого ASR в шумном окружении.
Согласно [2], необходимые характеристики для идеального детектора активности голоса это: надежность, устойчивость, точность, адаптивность, простота, возможность применения в реальном времени, без информации о присутствующем шуме. Достичь устойчивости к шуму сложнее всего. В условиях высокого SNR (Signal-to-noise ratio), простейшие VAD алгоритмы работают удовлетворительно, но при условиях низкого SNR все алгоритмы VAD деградируют до определенной степени. В тоже время, алгоритм VAD должен оставаться простым, для удовлетворения требования применимости в реальном времени. Поэтому простота и устойчивость к шуму — это две существенные характеристики практичного детектора активности речи.
Было предложено много алгоритмов VAD, главное отличие которых в используемых характеристиках. Среди всех характеристик, Short-term Energy и zero-crossing rate из-за своей простоты использовались чаще. Однако, они сильно деградируют при наличии шумов. Для того что бы исправить этот недостаток были предложены разные устойчивые акустические характеристики на основе — функции автокорреляции [3, 4], спектра(spectrum based ) [5], мощности на узкополосном отрезке (power in the band-limited region) [1, 6, 7], MFCC (Mel-frequency Cepstral Coefficients [4] — Кепстральные коэффициенты тональной частоты. Почитать можно в книге spbu), дельт спектральных частот (delta line spectral frequencies)[6] и статистик высшего порядка [8]. Эксперименты показали, что использование этих характеристик приводит к увеличению устойчивости VAD к шумам. В некоторых работах предлагается использование разных характеристик в комбинации с некоторыми моделирующими алгоритмами как CART (Classification and Regression Tree)[9] и ANN (Artificial Neural-Network) [10], однако эти алгоритмы по сложности сравнимы с самим VAD.
C другой стороны, некоторые методы используют модели шумов [11], или используют улучшенный спектр речи, полученный после статистической фильтрации шумов фильтром Винера (Wiener filter) [7, 12]. Большинство характеристик предполагают наличие стационарного шума в течении определенного периода, поэтому они чувствительны к изменениям в SNR обрабатываемого сигнала. Некоторые работы предлагают вычисление шума и адаптацию для улучшения устойчивости VAD [13], но эти методы имеют большую вычислительную сложность.
Также, существуют стандарты VADs, которые используются для создания новых методов детектирования. Среди них GSM 729 [1], ETSI AMR [14] и AFE [15]. Например, стандарт GSM 729 использует линейный спектр пары частот, full-band energy и low-band energy, zero-crossing rate и применяет классификатор с использованием фиксированных границ в ограниченном пространстве [1].
В этой работе предложен алгоритм VAD, который одновременно легок в реализации и может быть использован для обработки речи/аудио в реальном времени, а также дает удовлетворительную устойчивость к шумам. В секции 3 детально разбирается алгоритм предложенного VAD.
2. SHORT-TERM FEATURE (кратковременные характеристики)
В предложенном методе мы используем три разных характеристики для каждого фрэйма. Первая характеристика это краткосрочная энергия (Е). Энергия — наиболее часто используемая характеристика в определении речи/тишины. Однако, она становится неэффективной в условиях шума, особенно при низких SNR. Поэтому, мы используем еще две характеристики, которые вычисляются из частот.
Вторая характеристика это мера спектральной плоскостности (SFM — Spectral Flatness Measure). Мера зашумленности спектра хорошо себя показывает в Голосовом/Неголосовом детекритовании и обнаружении тишины.
Считается SFM по следующей формуле:
SMFdb= 10log10(Gm / Am)
Где Am и Gm это соответственно среднее арифметическое и среднее геометрическое спектра речи.
Кроме этих двух характеристик было обнаружено, что составляющая фрэйма речи с преобладающими частотами (most dominant frequency component) может быть очень полезна для различения фрэймов с речью и тишиной. В этой работе эта характеристика обозначена через F. Она легко вычисляется через нахождения такой частоты, которая соответствует максимальному значению величины спектра | S(k) |.
В предложенном методе для детектирования голосовой активности все три характеристики вычисляются одновременно для каждого фрейма.
Изображение 1. Значения характеристик на чистом речевом сигнале
Изображение 2. Значение характеристик на сигнале, поврежденном белым шумом
Изображение 3. Значение характеристик на сигнале, поврежденном шумом лепета
Изображения 1-3 представляют эффективность этих трех характеристик на чистом и поврежденном шумом сигнале.
3. ПРЕДЛОЖЕННЫЙ АЛГОРИТМ VAD
Предложенный алгоритм начинается с разбиения аудио-сигнала на фреймы. В нашей реализации не применяется оконная функция. Первые N фреймов используются для инициализации порогового значения. Для каждого входящего фрейма вычисляются три характеристики. Аудио-фрейм считается речевым, если значение более одной характеристики превышает пороговое значение. Полная процедура предложенного метода представлена ниже:
1 - Устанавливаем Frame_Size = 10ms и вычисляется кол-во фреймов( Num_of_frames ) //перекрытие фреймов не требуется
2 - Устанавливаем по одному пороговому значению для каждой характеристики. // единственное что устанавливается извне
* Порог для Энергии (Energy_PrimTreshhold)
* Порог для F (F_PrimTreshhold)
* Порог для SFM (SF_PrimTreshhold)
3 - For i от 1 до Num_of_frames
3.1 - Вычисляем энергию фрейма (E(i))
3.2 - Применяем FFT для каждого фрейма
3.2.1 - Находим F(i) = arg max (S(k)) - составляющую с преобладающей частотой
3.2.2 - Вычисляем значение спектральной плоскостности как Measure(SFM(i))
3.3 - Предполагаем что некоторые из 30 первых фреймов - это тишина, находим
минимальное значение для Е (Min_E), F (Min_F), SMF (Min_SF)
3.4 - Устанавливаем порог принятия решения для E, F, SFM
* Tresh_E = Energy_PrimTresh * log(Min_E)
* Tresh_F = F_PrimTresh
* Tresh_SF = SF_PrimTresh
3.5 - Устанавливаем Counter = 0
* Если ((E(i) - Min_E) >= Tresh_E) тогда Counter++
* Если ((F(i) - Min_F) >= Tresh_F) тогда Counter++
* Если ((SFM(i) - Min_SF) >= Tresh_SF) тогда Counter++
3.6 - Если Counter > 1 то отмечаем текущий фрейм как речевой, иначе как тишину
3.7 - Если текущий фрейм отмечен как тишина, обновляем значения минимума tythubb
Min_E = ((Silence_Count * Min_E) + E(i)) / (Silence_Count + 1)
3.8 Tresh_E = Energy_PrimTresh * log(Min_E)
4 - Игнорировать тишину идущую менее чем 10 фреймов
5 - Игнорировать речь идущую менее чем 5 фреймов.
В алгоритме есть три параметра, которые необходимо установить в первую очередь. Эти параметры были найдены автоматически на конечном наборе чистых речевых сигналов. Ниже представлены оптимальные значения, полученные в результате экспериментов.
Energy_PrimThresh = 40
F_PrimThresh (Hz) = 185
SF_PrimThresh = 5
В оригинальной статье предоставлены результаты экспериментов проведенных в условиях разной зашумленности. Хотелось бы узнать мнение сообщества о данной теме и о самом переводе. Есть ли смысл продолжать выкладывать переводы на эту тему? О всех неточностях перевода, ошибках писать в личные сообщения.
Не нашел как указать что это перевод, кроме как приписать пост к хабу Переводы.
Ссылки
[1] A. Benyassine, E. Shlomot, H. Y. Su, D. Massaloux, C. Lamblin and J. P. Petit, «ITU-T Recommendation G.729 Annex B: a silence compression scheme for use with G.729 optimized for V.70 digital simultaneous voice and data applications,» IEEE Communications Magazine 35, pp. 64-73, 1997.
[2] M. H. Savoji, «A robust algorithm for accurate end pointing of speech,» Speech Communication, pp. 45–60, 1989.
[3] B. Kingsbury, G. Saon, L. Mangu, M. Padmanabhan and R. Sarikaya, “Robust speech recognition in noisy environments: The 2001 IBM SPINE evaluation system,” Proc. ICASSP, 1, pp. 53-56, 2002.
[4] T. Kristjansson, S. Deligne and P. Olsen, “Voicing features for robust speech detection,” Proc. Interspeech, pp. 369-372, 2005.
[5] R. E. Yantorno, K. L. Krishnamachari and J. M. Lovekin, “The spectral autocorrelation peak valley ratio (SAPVR) – A usable speech measure employed as a co-channel detection system,” Proc. IEEE Int. Workshop Intell. Signal Process. 2001.
[6] M. Marzinzik and B. Kollmeier, “Speech pause detection for noise spectrum estimation by tracking power envelope dynamics,” IEEE Trans. Speech Audio Process, 10, pp. 109-118, 2002.
[7] ETSI standard document, ETSI ES 202 050 V 1.1.3., 2003.
[8] K. Li, N. S. Swamy and M. O. Ahmad, “An improved voice activity detection using higher order statistics,” IEEE Trans. Speech Audio Process., 13, pp. 965-974, 2005.
[9] W. H. Shin, «Speech/non-speech classification using multiple features for robust endpoint detection,» ICASSP, 2000.
[10] G. D. Wuand and C. T. Lin, «Word boundary detection with mel scale frequency bank in noisy environment,» IEEE Trans. Speechand Audio Processing, 2000.
[11] A. Lee, K. Nakamura, R. Nisimura, H. Saruwatari and K. Shikano, “Noise robust real world spoken dialogue system using GMM based rejection of unintended inputs,” Interspeech, pp. 173-176, 2004.
[12] J. Sohn, N. S. Kim and W. Sung, “A statistical modelbased voice activity detection,” IEEE Signal Process. Lett., pp. 1-3, 1999.
[13] B. Lee and M. Hasegawa-Johnson, «Minimum Mean Squared Error A Posteriori Estimation of High Variance Vehicular Noise,» in Proc. Biennial on DSP for In-Vehicle and Mobile Systems, Istanbul, Turkey, June 2007.
[14] ETSI EN 301 708 recommendations, “Voice activity detector for adaptive multi-rate (AMR) speech traffic channels,” 1999.
ССЫЛКИ:
[1] A. Benyassine, E. Shlomot, H. Y. Su, D. Massaloux, C. Lamblin and J. P. Petit, «ITU-T Recommendation G.729 Annex B: a silence compression scheme for use with G.729 optimized for V.70 digital simultaneous voice and data applications,» IEEE Communications Magazine 35, pp. 64-73, 1997.
[2] M. H. Savoji, «A robust algorithm for accurate end pointing of speech,» Speech Communication, pp. 45–60, 1989.
[3] B. Kingsbury, G. Saon, L. Mangu, M. Padmanabhan and R. Sarikaya, “Robust speech recognition in noisy environments: The 2001 IBM SPINE evaluation system,” Proc. ICASSP, 1, pp. 53-56, 2002.
[4] T. Kristjansson, S. Deligne and P. Olsen, “Voicing features for robust speech detection,” Proc. Interspeech, pp. 369-372, 2005.
[5] R. E. Yantorno, K. L. Krishnamachari and J. M. Lovekin, “The spectral autocorrelation peak valley ratio (SAPVR) – A usable speech measure employed as a co-channel detection system,” Proc. IEEE Int. Workshop Intell. Signal Process. 2001.
[6] M. Marzinzik and B. Kollmeier, “Speech pause detection for noise spectrum estimation by tracking power envelope dynamics,” IEEE Trans. Speech Audio Process, 10, pp. 109-118, 2002.
[7] ETSI standard document, ETSI ES 202 050 V 1.1.3., 2003.
[8] K. Li, N. S. Swamy and M. O. Ahmad, “An improved voice activity detection using higher order statistics,” IEEE Trans. Speech Audio Process., 13, pp. 965-974, 2005.
[9] W. H. Shin, «Speech/non-speech classification using multiple features for robust endpoint detection,» ICASSP, 2000.
[10] G. D. Wuand and C. T. Lin, «Word boundary detection with mel scale frequency bank in noisy environment,» IEEE Trans. Speechand Audio Processing, 2000.
[11] A. Lee, K. Nakamura, R. Nisimura, H. Saruwatari and K. Shikano, “Noise robust real world spoken dialogue system using GMM based rejection of unintended inputs,” Interspeech, pp. 173-176, 2004.
[12] J. Sohn, N. S. Kim and W. Sung, “A statistical modelbased voice activity detection,” IEEE Signal Process. Lett., pp. 1-3, 1999.
[13] B. Lee and M. Hasegawa-Johnson, «Minimum Mean Squared Error A Posteriori Estimation of High Variance Vehicular Noise,» in Proc. Biennial on DSP for In-Vehicle and Mobile Systems, Istanbul, Turkey, June 2007.
[14] ETSI EN 301 708 recommendations, “Voice activity detector for adaptive multi-rate (AMR) speech traffic channels,” 1999.
