
Асинхронность… Услышав это слово, у программистов начинают блестеть глаза, дыхание становится поверхностным, руки начинают трястись, голос — заикаться, мозг начинает рисовать многочисленные уровни абстракции… У менеджеров округляются глаза, звуки становятся нечленораздельными, руки сжимаются в кулаки, а голос переходит на обертона… Единственное, что их объединяет — это учащенный пульс. Только причины этого различны: программисты рвутся в бой, а менеджеры пытаются заглянуть в хрустальный шар и осознать риски, начинают судорожно придумывать причины увеличения сроков в разы… И уже потом, когда большая часть кода написана, программисты начинают осознавать и познавать всю горечь асинхронности, проводя бесконечные ночи в дебаггере, отчаянно пытаясь понять, что же все-таки происходит…
Именно такую картину рисует мое воспаленное воображение при слове “асинхронность”. Конечно, все это слишком эмоционально и не всегда правда. Ведь так?.. Возможны варианты. Некоторые скажут, что “при правильном подходе все будет работать хорошо”. Однако это можно сказать всегда и везде при всяком удобном и не удобном случае. Но лучше от этого не становится, баги не исправляются, а бессонница не проходит.
Так что же такое асинхронность? Почему она так привлекательна? А главное: что с ней не так?
Введение
Асинхронность на текущий момент является достаточно популярной темой. Достаточно просмотреть последние статьи на хабре, чтобы в этом убедиться. Тут тебе и обзор различных библиотек, и использования языка Go, и всякие асинхронные фреймворки на JS, и много чего другого.Обычно асинхронность используется для сетевого программирования: всякие сокеты-шмокеты, читатели-писатели и прочие акцепторы. Но бывают еще забавные и интересные события, особенно в UI. Здесь я буду рассматривать исключительно сетевое использование. Однако, как будет показано в следующей статье, подход можно расширять и углублять в неведомые дали.
Чтобы быть совсем уж конкретным, будем писать простой HTTP сервер, который на некий любой запрос посылает некий стандартный ответ. Это чтоб не писать парсер, т.к. к теме асинхронности он имеет ровно такое же отношение, как положение звезд к характеру человека (см. астрологию).
Синхронный однопоточный сервер

Хм. Синхронный? А при чем тут синхронный, спросит внимательный читатель, открыв статью про асинхронность. Ну, во-первых, надо же с чего-то начать. С чего-то простого. А во-вторых… Короче, я автор, поэтому будет так. А потом и сами узнаете, зачем.
Для того, чтобы не писать низкоуровневый платформозависимый код, для всех наших целей я буду использовать мощную асинхронную библиотеку под названием boost.asio. Благо, статей уже написано про нее достаточно, чтобы быть хотя бы немножко в теме.
Опять же, для большей наглядности и “продакшенности” кода я сделаю обертки для вызова соответствующих функций из библиотеки boost.asio. Конечно, кому-то могут нравиться портянки наподобие
boost::asio::ip::tcp::socket или boost::asio::ip::udp::resolver::iterator, но ясность и читабельность кода при этом значительно уменьшается.Итак, описание сокета и акцептора:
typedef std::string Buffer; // forward declaration struct Acceptor; struct Socket { friend struct Acceptor; Socket(); Socket(Socket&& s); // чтение данных фиксированного размера void read(Buffer&); // чтение данных не больше, чем указанный размер буфера void readSome(Buffer&); // чтение данных вплоть до строки until int readUntil(Buffer&, const Buffer& until); // запись данных фиксированного размера void write(const Buffer&); // закрытие сокета void close(); private: boost::asio::ip::tcp::socket socket; }; struct Acceptor { // слушать порт для принятия соединений explicit Acceptor(int port); // создание сокета на новое соединение void accept(Socket& socket); private: boost::asio::ip::tcp::acceptor acceptor; };
Ничего лишнего, просто сервер.
Socket позволяет писать и читать, в том числе до определенных символов (readUntil). Acceptor слушает указанный порт и принимает соединения.Реализация всего этого хозяйства приведена ниже:
boost::asio::io_service& service() { return single<boost::asio::io_service>(); } Socket::Socket() : socket(service()) { } Socket::Socket(Socket&& s) : socket(std::move(s.socket)) { } void Socket::read(Buffer& buffer) { boost::asio::read(socket, boost::asio::buffer(&buffer[0], buffer.size())); } void Socket::readSome(Buffer& buffer) { buffer.resize(socket.read_some(boost::asio::buffer(&buffer[0], buffer.size()))); } bool hasEnd(size_t posEnd, const Buffer& b, const Buffer& end) { return posEnd >= end.size() && b.rfind(end, posEnd - end.size()) != std::string::npos; } int Socket::readUntil(Buffer& buffer, const Buffer& until) { size_t offset = 0; while (true) { size_t bytes = socket.read_some(boost::asio::buffer(&buffer[offset], buffer.size() - offset)); offset += bytes; if (hasEnd(offset, buffer, until)) { buffer.resize(offset); return offset; } if (offset == buffer.size()) { LOG("not enough size: " << buffer.size()); buffer.resize(buffer.size() * 2); } } } void Socket::write(const Buffer& buffer) { boost::asio::write(socket, boost::asio::buffer(&buffer[0], buffer.size())); } void Socket::close() { socket.close(); } Acceptor::Acceptor(int port) : acceptor(service(), boost::asio::ip::tcp::endpoint(boost::asio::ip::tcp::v4(), port)) { } void Acceptor::accept(Socket& socket) { acceptor.accept(socket.socket); }
Здесь я использовал синглтон для
io_service, чтобы не передавать его каждый раз в сокет явно во входных параметрах. И откуда пользователю знать, что там должен быть какой-то io_service? Поэтому я его спрятал подальше, чтобы глаза не мозолил. Остальное, я полагаю, вполне понятно, за исключением, быть может, функции readUntil. Но суть ее проста: читать байтики до тех пор, пока не встретится заветное окончание. Это нужно как раз для HTTP, т.к. заранее размер мы, увы, не можем задать. Приходится ресайзиться.Давайте теперь напишем долгожданный сервер. Вот он:
#define HTTP_DELIM "\r\n" #define HTTP_DELIM_BODY HTTP_DELIM HTTP_DELIM // наш ответ Buffer httpContent(const Buffer& body) { std::ostringstream o; o << "HTTP/1.1 200 Ok" HTTP_DELIM "Content-Type: text/html" HTTP_DELIM "Content-Length: " << body.size() << HTTP_DELIM_BODY << body; return o.str(); } // слушаем 8800 порт (вдруг 80 занят?) Acceptor acceptor(8800); LOG("accepting"); while (true) { Socket socket; acceptor.accept(socket); try { LOG("accepted"); Buffer buffer(4000, 0); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello sync singlethread!</h1>")); socket.close(); } catch (std::exception& e) { LOG("error: " << e.what()); } }
Сервер готов!
Синхронный многопоточный сервер
Недостатки предыдущего сервера очевидны:- Невозможно обрабатывать несколько соединений одновременно.
- Клиент может переиспользовать соединение для более эффективного взаимодействия, а мы его всегда закрываем.
Поэтому появляется идея, чтобы обрабатывать соединения в другом потоке, продолжая принимать следующие соединения. Для этого нам понадобится функция создания нового потока, которую я внезапно назову
go:typedef std::function<void ()> Handler; void go(Handler handler) { LOG("sync::go"); std::thread([handler] { try { LOG("new thread had been created"); handler(); LOG("thread was ended successfully"); } catch (std::exception& e) { LOG("thread was ended with error: " << e.what()); } }).detach(); }
Стоит отметить одну забавную вещь: если убрать
detach(), то угадайте, что сделает программа?Ответ:
Тупо завершится без каких-либо сообщений. Спасибо разработчикам стандарта, так держать!
Теперь можно и сервер написать:
Acceptor acceptor(8800); LOG("accepting"); while (true) { Socket* toAccept = new Socket; acceptor.accept(*toAccept); LOG("accepted"); go([toAccept] { try { Socket socket = std::move(*toAccept); delete toAccept; Buffer buffer; while (true) { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello sync multithread!</h1>")); } } catch (std::exception& e) { LOG("error: " << e.what()); } }); }
Казалось бы, все хорошо, но не тут то было: на реальных задачах под нагрузкой это дело ложится быстро и потом не отжимается. Поэтому умные дядьки подумали, подумали, и решили использовать асинхронность.
Асинхронный сервер
В чем проблема предыдущего подхода? А в том, что потоки вместо реальной работы большую часть времени ожидают на событиях из сети, отжирая ресурсы. Хочется как-то более эффективно использовать потоки для выполнения полезной работы.Поэтому теперь буду реализовывать аналогичные функции, но уже асинхронно, используя модель проактора. Что это означает? Это означает, что мы для всех операций вызываем функцию и передаем callback, который автомагически позовется по окончании операции. Т.е. нас позовут сами, как только операция завершится. Это отличается от модели реактора, когда мы должны сами вызывать нужные обработчики, наблюдая за состоянием операций. Типичный пример реактора: epoll, kqueue и различные select’ы. Пример проактора: IOCP на Windows. Я буду использовать кроссплатформенный проактор boost.asio.
Асинхронные интерфейсы:
typedef boost::system::error_code Error; typedef std::function<void(const Error&)> IoHandler; struct Acceptor; struct Socket { friend struct Acceptor; Socket(); Socket(Socket&&); void read(Buffer&, IoHandler); void readSome(Buffer&, IoHandler); void readUntil(Buffer&, Buffer until, IoHandler); void write(const Buffer&, IoHandler); void close(); private: boost::asio::ip::tcp::socket socket; }; struct Acceptor { explicit Acceptor(int port); void accept(Socket&, IoHandler); private: boost::asio::ip::tcp::acceptor acceptor; };
Стоит остановиться на некоторых вещах:
- Обработка ошибок теперь существенно отличается. В случае синхронного подхода у нас 2 варианта: возврат кода ошибки либо генерация исключения (именно этот способ и использовался в начале статьи). В случае асинхронного вызова способ существует ровно один: передача ошибки через обработчик. Т.е. даже не через результат, а как входной параметр обработчика. И хочешь, не хочешь — будь любезен обрабатывай ошибки как в старые добрые времена, когда исключений еще не было: на каждый чих по проверке. Но самое интересное, конечно, не это; интересное — это когда возникла ошибка в обработчике и ее надо обработать. Вспоминание контекста — излюбленная задача асинхронного программирования!
- Для единообразного подхода я использовал
IoHandler, что делает код более простым и универсальным.
Если внимательно присмотреться, то отличие от синхронных функций только в том, что асинхронные содержат дополнительный обработчик в качестве входного параметра.
Ну что ж, вроде пока ничего страшного нет.
Реализация:
Socket::Socket() : socket(service()) { } Socket::Socket(Socket&& s) : socket(std::move(s.socket)) { } void Socket::read(Buffer& buffer, IoHandler handler) { boost::asio::async_read(socket, boost::asio::buffer(&buffer[0], buffer.size()), [&buffer, handler](const Error& error, std::size_t) { handler(error); }); } void Socket::readSome(Buffer& buffer, IoHandler handler) { socket.async_read_some(boost::asio::buffer(&buffer[0], buffer.size()), [&buffer, handler](const Error& error, std::size_t bytes) { buffer.resize(bytes); handler(error); }); } bool hasEnd(size_t posEnd, const Buffer& b, const Buffer& end) { return posEnd >= end.size() && b.rfind(end, posEnd - end.size()) != std::string::npos; } void Socket::readUntil(Buffer& buffer, Buffer until, IoHandler handler) { VERIFY(buffer.size() >= until.size(), "Buffer size is smaller than expected"); struct UntilHandler { UntilHandler(Socket& socket_, Buffer& buffer_, Buffer until_, IoHandler handler_) : offset(0), socket(socket_), buffer(buffer_), until(std::move(until_)), handler(std::move(handler_)) { } void read() { LOG("read at offset: " << offset); socket.socket.async_read_some(boost::asio::buffer(&buffer[offset], buffer.size() - offset), *this); } void complete(const Error& error) { handler(error); } void operator()(const Error& error, std::size_t bytes) { if (!!error) { return complete(error); } offset += bytes; VERIFY(offset <= buffer.size(), "Offset outside buffer size"); LOG("buffer: '" << buffer.substr(0, offset) << "'"); if (hasEnd(offset, buffer, until)) { // found end buffer.resize(offset); return complete(error); } if (offset == buffer.size()) { LOG("not enough size: " << buffer.size()); buffer.resize(buffer.size() * 2); } read(); } private: size_t offset; Socket& socket; Buffer& buffer; Buffer until; IoHandler handler; }; UntilHandler(*this, buffer, std::move(until), std::move(handler)).read(); } void Socket::write(const Buffer& buffer, IoHandler handler) { boost::asio::async_write(socket, boost::asio::buffer(&buffer[0], buffer.size()), [&buffer, handler](const Error& error, std::size_t) { handler(error); }); } void Socket::close() { socket.close(); } Acceptor::Acceptor(int port) : acceptor(service(), boost::asio::ip::tcp::endpoint(boost::asio::ip::tcp::v4(), port)) { } void Acceptor::accept(Socket& socket, IoHandler handler) { acceptor.async_accept(socket.socket, handler); }
Тут должно быть все понятно, за исключением метода
readUntil. Для того, чтобы несколько раз вызывать асинхронное чтение на сокете, необходимо сохранять состояние. Для этого предназначен специальный класс UntilHandler, который сохраняет текущее состояние асинхронной операции. Похожую реализацию можно встретить в boost.asio для различных функций (например boost::asio::read), которые требуют нескольких вызовов более простых (но не менее асинхронных) операций.Помимо этого необходимо написать аналог
go и диспетчеризацию:void go(Handler); void dispatch(int threadCount = 0);
Здесь указывается обработчик, который будет запускаться асинхронно в пуле потоков и, собственно, создание пула потоков с последующей диспетчеризацией.
Вот как выглядит реализация:
void go(Handler handler) { LOG("async::go"); service().post(std::move(handler)); } void run() { service().run(); } void dispatch(int threadCount) { int threads = threadCount > 0 ? threadCount : int(std::thread::hardware_concurrency()); RLOG("Threads: " << threads); for (int i = 1; i < threads; ++ i) sync::go(run); run(); }
Здесь мы используем
sync::go для создания потоков из синхронного подхода.Реализация сервера:
Acceptor acceptor(8800); LOG("accepting"); Handler accepting = [&acceptor, &accepting] { struct Connection { Buffer buffer; Socket socket; void handling() { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY, [this](const Error& error) { if (!!error) { LOG("error on reading: " << error.message()); delete this; return; } LOG("read"); buffer = httpContent("<h1>Hello async!</h1>"); socket.write(buffer, [this](const Error& error) { if (!!error) { LOG("error on writing: " << error.message()); delete this; return; } LOG("written"); handling(); }); }); } }; Connection* conn = new Connection; acceptor.accept(conn->socket, [conn, &accepting](const Error& error) { if (!!error) { LOG("error on accepting: " << error.message()); delete conn; return; } LOG("accepted"); conn->handling(); accepting(); }); }; accepting(); dispatch();

Вот такая простыня. С каждым новым вызовом растет вложенность лямбд. Обычно, конечно, такое через лямбды не пишут, т.к. есть сложности с зацикливанием: в лямбду необходимо пробрасывать саму себя, чтобы внутри самой себя позвать саму себя. Но тем не менее, читабельность кода будет примерно одинаковая, т.е. одинаково плохая при сравнении с синхронным кодом.
Итак, давайте обсудим плюсы и минусы асинхронного подхода:
- Безусловный плюс (и это, собственно, то, ради чего все эти мучения) — это производительность. Причем она не просто в разы выше, она выше на порядки!
- Ну а теперь минусы. Минус ровно один — сложный и запутанный код, который к тому же еще и сложно отлаживать.
Хорошо, конечно, если все написал правильно и оно сразу заработало и без багов. А вот если это не так… В общем, счастливого дебаггинга, как говорится в таких случаях. И это я еще рассмотрел достаточно простой пример, где можно отследить последовательность вызовов. При небольшом усложнении схемы обработки (например, одновременные чтение и запись в сокеты) сложность кода растет как на дрожжах, а количество багов начинает расти чуть ли не экспоненциально.
Так стоит ли игра свеч? Стоит ли заниматься асинхронностью? На самом деле выход есть — coroutines или сопрограммы.
Сопрограммы

Итак, чего же нам всем хочется?
На бумаге звучит замечательно. Возможно ли это? Для ответа на вопрос нам понадобится небольшое введение в сопрограммы.
Вот что такое обычные процедуры? Находимся мы, значит, в каком-то месте исполнения и тут раз, и позвали процедуру. Для вызова сначала запоминается текущее место для возврата, затем зовется процедура, она исполняется, завершается и возвращает управление в то место, откуда была позвана. А сопрограмма — это то же самое, только другое: она тоже возвращает управление в то место, откуда была позвана, но при этом она не завершается, а останавливается в некотором месте, с которого дальше продолжает работать при повторном запуске. Т.е. получается эдакий пинг-понг: вызывающий бросает мячик, сопрограмма ловит его, перебегает в другое место, бросает обратно, вызывающий тоже что-то делает (перебегает) и снова бросает в предыдущее место уже сопрограммы. И так происходит до тех пор, пока сопрограмма не завершится. В целом можно сказать, что процедура — это частный случай сопрограммы.
Как теперь это можно использовать для наших асинхронных задач? Ну тут наводит на мысль то, что сопрограмма сохраняет некий контекст исполнения, что для асинхронности крайне важно. Именно это и буду я использовать: если сопрограмме потребуется выполнить асинхронную операцию, то я просто вызову асинхронный метод и выйду из сопрограммы. А обработчик по завершению асинхронной операции просто продолжит исполнение нашей сопрограммы с места последнего вызова той самой асинхронной операции. Т.е. вся грязная работа по сохранению контекста ложится на плечи реализации сопрограмм.
И вот тут как раз и начинаются проблемы. Дело в том, что поддержка сопрограмм на стороне языков и процессоров — дела давно минувших дней. Для реализации переключения контекстов исполнения сегодня необходимо проделать множество операций: сохранить состояния регистров, переключить стек и заполнить некоторые служебные поля для корректной работы среды исполнения (например, для исключений, TLS и др.). Более того, реализация зависит не только от архитектуры процессора, но еще и от компилятора и операционной системы. Звучит как последний гвоздь в крышку гроба…
К счастью, есть boost.context, которая и реализует все, что необходимо для поддержки конкретной платформы. Написано все на ассемблере, в лучших традициях. Можно, конечно, использовать boost.coroutine, но зачем, когда есть boost.context? Больше ада и угара!
Реализация сопрограмм
Итак, для наших целей напишем свои сопрограммы. Интерфейс будет такой:// выход из сопрограммы void yield(); // проверка того, что мы находимся внутри сопрограммы bool isInsideCoro(); // сопрограмма struct Coro { // на всякий случай, мало ли friend void yield(); Coro(); // создание и запуск обработчика Coro(Handler); // без комментариев ~Coro(); // запуск обработчика void start(Handler); // продолжение сопрограммы (только если она завершилась yield) void resume(); // проверка того, что сопрограмму можно продолжить bool isStarted() const; private: ... };
Вот такой нехитрый интерфейс. Ну и сразу вариант использования:
void coro() { std::cout << '2'; yield(); std::cout << '4'; }
std::cout << '1'; Coro c(coro); std::cout << '3'; c.resume(); std::cout << '5';
Должен выдать на экран:
12345
Начнем с метода
start:void Coro::start(Handler handler) { VERIFY(!isStarted(), "Trying to start already started coro"); context = boost::context::make_fcontext(&stack.back(), stack.size(), &starterWrapper0); jump0(reinterpret_cast<intptr_t>(&handler)); }
Здесь
boost::context::make_fcontext создает нам контекст и передает в качестве стартовой функции статический метод starterWrapper0:TLS Coro* t_coro; void Coro::starterWrapper0(intptr_t p) { t_coro->starter0(p); }
который просто перенаправляет на метод
starter0, извлекая текущий экземпляр Coro из TLS. Вся магия по переключению контекстов находится в приватном методе jump0:void Coro::jump0(intptr_t p) { Coro* old = this; std::swap(old, t_coro); running = true; boost::context::jump_fcontext(&savedContext, context, p); running = false; std::swap(old, t_coro); if (exc != std::exception_ptr()) std::rethrow_exception(exc); }
Здесь мы заменяем старое TLS значение
t_coro на новое (нужно для рекурсивного переключения между несколькими сопрограммами), устанавливаем всякие флаги и переключаем контекст с использованием boost::context::jump_fcontext. После завершения восстанавливаем старые значения и прокидываем исключения в вызывающую функцию.Смотрим теперь на приватный метод
starter0, который и запускает нужный обработчик:void Coro::starter0(intptr_t p) { started = true; try { Handler handler = std::move(*reinterpret_cast<Handler*>(p)); handler(); } catch (...) { exc = std::current_exception(); } started = false; yield0(); }
Отмечу один интересный момент: если не сохранить обработчик внутри сопрограммы (до его вызова), то при последующем возврате программа может благополучно упасть. Это связано с тем, что, вообще говоря, обработчик хранит в себе некоторое состояние, которое может быть разрушено в какой-то момент.
Теперь осталось рассмотреть остальные функции:
// возвращаем управление из сопрограммы void yield() { VERIFY(isInsideCoro(), "yield() outside coro"); t_coro->yield0(); } // проверка того, находимся ли мы внутри сопрограммы bool isInsideCoro() { return t_coro != nullptr; } // возобновление сопрограммы после yield void Coro::resume() { VERIFY(started, "Cannot resume: not started"); VERIFY(!running, "Cannot resume: in running state"); jump0(); } // проверка того, что сопрограмма еще не завершена bool Coro::isStarted() const { return started || running; } // возврат в сохраненный контекст void Coro::yield0() { boost::context::jump_fcontext(context, &savedContext, 0); }
Synca: async наоборот

Теперь пришла очередь реализовать асинхронность на сопрограммах. Тривиальный вариант реализации приведен на следующей диаграмме:
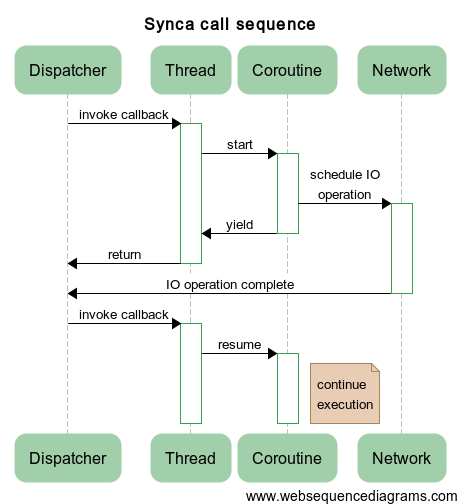
Здесь происходит создание сопрограммы, затем сопрограмма запускает асинхронную операцию и завершает свою работу с использованием функции
yield(). По завершению операции происходит продолжение работы сопрограммы посредством вызова метода resume().И все было бы хорошо, если бы не пресловутая многопоточность. Как это всегда бывает, она вносит некоторую турбулентность, поэтому приведенный выше подход не будет работать должным образом, что наглядно иллюстрирует следующая диаграмма:

Т.е. сразу после шедулинга операции может быть вызван обработчик, который продолжит исполнение до выхода из сопрограммы. Это, понятно, не входило в наши планы. Поэтому придется усложнить последовательность:
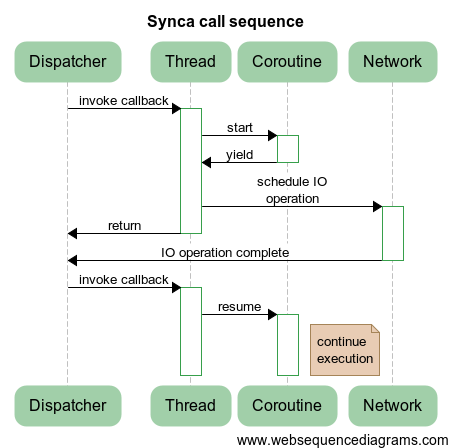
Отличие состоит в том, что мы запускаем шедулинг не в сопрограмме, а вне ее, что исключает возможность, описанную выше. При этом продолжение сопрограммы может случиться в другом потоке, что является вполне нормальным поведением, для этого сопрограммы и предназначены, чтобы иметь возможность тусовать их туда-сюда, сохраняя при этом контекст исполнения.
Небольшая ремарка
Удивительно, но в boost.asio уже есть поддержка сопрограмм. Для решения указанной выше проблемы используется
io_service::strand, но это совсем другая история. Ведь всегда же интересно написать что-то свое, родное… Да и к тому же результат, полученный в статье, использовать гораздо удобнее.Реализация
Начнем с реализации функцииgo:void go(Handler handler) { LOG("synca::go"); async::go([handler] { coro::Coro* coro = new coro::Coro(std::move(handler)); onCoroComplete(coro); }); }
Здесь мы вместо простого запуска обработчика создаем сопрограмму и запускаем обработчик уже внутри нее. Интерес тут также представляет функция
onCoroComplete, которая смотрит, не надо ли чего зашедулить:typedef std::function<void(coro::Coro*)> CoroHandler; TLS CoroHandler* t_deferHandler; void onCoroComplete(coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "Complete inside coro"); VERIFY(coro->isStarted() == (t_deferHandler != nullptr), "Unexpected condition in defer/started state"); if (t_deferHandler != nullptr) { LOG("invoking defer handler"); (*t_deferHandler)(coro); t_deferHandler = nullptr; LOG("completed defer handler"); } else { LOG("nothing to do, deleting coro"); delete coro; } }
Действия простые: смотрим, есть ли что-то для обработки. Если есть — то выполняем, нет — тогда сопрограмма закончила свою работу и ее можно удалить.
Возникает вопрос: а как заполняется
t_deferHandler? А вот так:TLS const Error* t_error; void handleError() { if (t_error) throw boost::system::system_error(*t_error, "synca"); } void defer(CoroHandler handler) { VERIFY(coro::isInsideCoro(), "defer() outside coro"); VERIFY(t_deferHandler == nullptr, "There is unexecuted defer handler"); t_deferHandler = &handler; coro::yield(); handleError(); }
Эта функция всегда вызывается внутри сопрограммы. Здесь передается некий обработчик, который будет заниматься шедулингом операций, т.е. запуском асинхронностей. Этот обработчик запоминается, чтобы его запустить по выходу из сопрограммы (
coro::yield), после выхода сразу запускается onCoroComplete, который и запускает наш отложенный обработчик. Ниже приведено использование функции defer на примере Socket::accept:void onComplete(coro::Coro* coro, const Error& error) { LOG("async completed, coro: " << coro << ", error: " << error.message()); VERIFY(coro != nullptr, "Coro is null"); VERIFY(!coro::isInsideCoro(), "Completion inside coro"); t_error = error ? &error : nullptr; coro->resume(); LOG("after resume"); onCoroComplete(coro); } async::IoHandler onCompleteHandler(coro::Coro* coro) { return [coro](const Error& error) { onComplete(coro, error); }; } void Acceptor::accept(Socket& socket) { VERIFY(coro::isInsideCoro(), "accept must be called inside coro"); defer([this, &socket](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "accept completion must be called outside coro"); acceptor.accept(socket.socket, onCompleteHandler(coro)); LOG("accept scheduled"); }); }
onCompleteHandler возвращает асинхронный обработчик, который обрабатывает завершение асинхронной операции. Внутри обработчика происходит запоминание ошибки t_error, чтобы позже иметь возможность пробросить исключение внутри нашей сопрограммы (см. вызов handleError внутри defer), а затем продолжение исполнение сопрограммы coro->resume(), т.е. возвращение в метод defer сразу после вызова yield(). Диаграмма ниже показывает последовательность вызовов и взаимодействие различных сущностей:
Остальные функции реализуются аналогично:
void Socket::readSome(Buffer& buffer) { VERIFY(coro::isInsideCoro(), "readSome must be called inside coro"); defer([this, &buffer](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "readSome completion must be called outside coro"); socket.readSome(buffer, onCompleteHandler(coro)); LOG("readSome scheduled"); }); } void Socket::readUntil(Buffer& buffer, Buffer until) { VERIFY(coro::isInsideCoro(), "readUntil must be called inside coro"); defer([this, &buffer, until](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "readUntil completion must be called outside coro"); socket.readUntil(buffer, std::move(until), onCompleteHandler(coro)); LOG("readUntil scheduled"); }); } void Socket::write(const Buffer& buffer) { VERIFY(coro::isInsideCoro(), "write must be called inside coro"); defer([this, &buffer](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "write completion must be called outside coro"); socket.write(buffer, onCompleteHandler(coro)); LOG("write scheduled"); }); }
Везде в реализации я использую соответствующие асинхронные объекты
async::Socket и async::Acceptor, описанные в пункте про асинхронность.Использование
Перейдем к использованию нашего функционала. Тут все гораздо проще и изящнее:Acceptor acceptor(8800); LOG("accepting"); go([&acceptor] { while (true) { Socket* toAccept = new Socket; acceptor.accept(*toAccept); LOG("accepted"); go([toAccept] { try { Socket socket = std::move(*toAccept); delete toAccept; Buffer buffer; while (true) { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello synca!</h1>")); } } catch (std::exception& e) { LOG("error: " << e.what()); } }); } }); dispatch();
Приведенный код что-то напоминает… Точно! Это же практически наш синхронный код:
sync |
synca |
|---|---|
|
|
dispatch. Однако, если задаться целью, можно было бы эти подходы сделать полностью идентичными: для этого в синхронной реализации также сделать принятие сокетов в отдельном потоке, используя go, а функция dispatch тогда просто бы ждала завершения всех потоков.Но отличие в реализации носит принципиальный характер: получившийся код использует асинхронное сетевое взаимодействие, а значит является гораздо более эффективной реализацией. Собственно на этом наша цель достигнута: сделать симбиоз синхронного и асинхронного подходов, взяв из них самое лучшее, т.е. простоту синхронного и производительность асинхронного.
Улучшение

Опишу некоторое улучшение для процесса принятия сокетов. Часто, после принятия происходит разветвление исполнения: тот, кто принимал, будет продолжает принимать, а новый сокет будет обрабатываться в отдельном контексте исполнения. Поэтому создадим новый метод
goAccept:async::IoHandler onCompleteGoHandler(coro::Coro* coro, Handler handler) { return [coro, handler](const Error& error) { if (!error) go(std::move(handler)); onComplete(coro, error); }; } struct Acceptor { typedef std::function<void(Socket&)> Handler; // ... }; void Acceptor::goAccept(Handler handler) { VERIFY(coro::isInsideCoro(), "goAccept must be called inside coro"); defer([this, handler](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "goAccept completion must be called outside coro"); Socket* socket = new Socket; acceptor.accept(socket->socket, onCompleteGoHandler(coro, [socket, handler] { Socket s = std::move(*socket); delete socket; handler(s); })); LOG("accept scheduled"); }); }
И тогда наш сервер перепишется в виде:
Acceptor acceptor(8800); LOG("accepting"); go([&acceptor] { while (true) { acceptor.goAccept([](Socket& socket) { try { Buffer buffer; while (true) { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello synca!</h1>")); } } catch (std::exception& e) { LOG("error: " << e.what()); } }); } }); dispatch();
Что гораздо проще для понимания и использования.
Вопрос 1. А что с производительностью?

Действительно, отличие от чисто асинхронного подхода в том, что тут возникают дополнительные накладные расходы на создание/переключение контекстов и смежной атрибутики.
Сначала я было хотел проверить предельные нагрузки, но потом оказалось, что даже в одном (!!!) потоке загружается скорее гигабитная сеть, нежели процессор. Поэтому я провел следующий тест:
- Сервер работает под постоянной нагрузкой 30K RPS (т.е. 30 тыщ запросов в секунду).
- Смотрим на загрузку процессора в случае
asyncиsynca.
Результаты приведены в таблице:
| Метод | Количество запросов в секунду | Количество потоков | Загруженность процессорного ядра |
|---|---|---|---|
| async | 30000 | 1 | 75±5% |
| synca | 30000 | 1 | 80±5% |
Тем не менее видно, что не смотря на наличие дополнительного переключения контекстов, а также пробрасыванием исключений вместо кодов возврата (исключение генерится каждый раз при закрытии сокета, т.е. каждый раз на новом запросе) накладные расходы пренебрежимо малы. А если еще добавить код, который бы честно парсил HTTP сообщение, а также код, который бы не менее честно обрабатывал запросы и делал что-нибудь важное и нужное, то можно заявить смело, что отличие в производительности не будет вообще.
Вопрос 2. Ну допустим. А можно ли таким способом решать более сложные асинхронные задачи?
Теорема. Любую асинхронную задачу можно решить с помощью сопрограмм.

Доказательство.
Вначале возьмем функцию, которая использует асинхронные вызовы. Любую функцию можно превратить в сопрограмму, т.к. функция является частным случаем сопрограммы. Далее возьмем какой-либо асинхронный вызов в такой преобразованной сопрограмме. Такой вызов можно представить в следующем виде:
// код до вызова async(..., handler); // код после вызова
Рассмотрим случай, когда у нас отсутствует код после вызова:
// код до вызова async(..., handler);
Такой код с точки зрения сопрограммы эквивалентен следующему:
// код до вызова synca(...); handler();
Т.е. внутри
synca мы вызываем соответствующую асинхронную функцию async, который нам возвращает управление в сопрограмму по завершению операции, и затем вызывается обработчик handler() явно. Результат ровно один и тот же.Теперь осталось рассмотреть более общий случай, когда у нас присутствует код после асинхронного вызова. Такой код эквивалентен:
// код до вызова go { async(..., handler); } // код после вызова
Используя то, что у нас теперь отсутствует код после вызова
async внутри go, получаем:// код до вызова go { synca(...); handler(); } // код после вызова
Т.е. на один асинхронный вызов стало меньше. Применяя такой подход к каждому асинхронному вызову функции и к каждой функции мы перепишем весь код на сопрограммах. Ч.т.д.
Выводы
Асинхронность стремительным домкратом врывается в нашу программистскую жизнь. Сложности, которые возникают при написании кода, способны привести в дрожь даже самых ярых и закаленных экспертов. Однако, не стоит списывать со счетов старый добрый синхронный подход: в умелых руках асинхронность превращается в элегантные сопрограммы.В следующей статье будет рассмотрен гораздо более сложный пример, который раскроет всю мощь и потенциал сопрограмм!
До новых встреч в эфире!

P.S. Весь код можно найти здесь: bitbucket:gridem/synca
