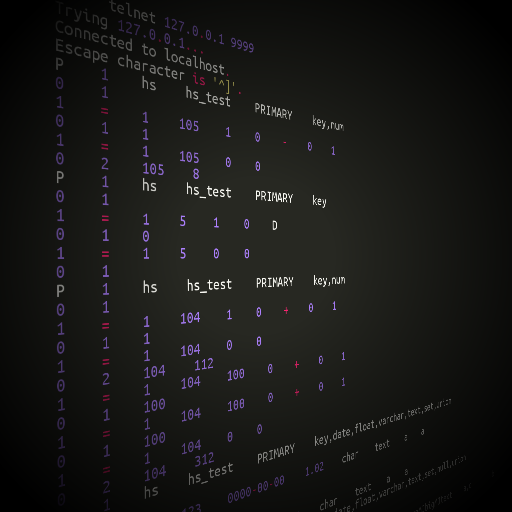
(пример работы протокола HandlerSocket на картинке)
Вступление
В предыдущем проекте возникла потребность в разгрузке базы данных, тогда жизнь и столкнула меня с HandlerSocket`ом.
HandlerSocket — это протокол, реализованный в одноимённом плагине для РСУБД MySQL, позволяющий использовать NoSQL методику для доступа к данным, хранящимся в InnoDB таблицах. Основная причина, по которой используют NoSQL решения — это очень быстрый поиск по первичному ключу.
Еще про HandlerSocket
HandlerSocket работает как демон внутри процесса mysql, принимая TCP соединения и выполняя запросы клиентов. Он не поддерживает SQL запросы, вместо этого он предоставляет простой язык запросов для CRUD операций с таблицами. Именно поэтому он гораздо быстрее mysqld/libmysql в некоторых случаях:
HandlerSocket оперирует данными без парсинга SQL запроса, что приводит к уменьшению загрузки процессора.
Он поддерживает пакетное выполнение запросов. Можно отправить несколько запросов сразу и получить результат за один раз, что опять же снижает нагрузку на процессор и на сеть.
Протокол HandlerSocket более компактный, чем у mysql/libmysql, что приводит к сокращению нагрузки на сеть.
Подробнее можно почитать здесь:
HandlerSocket оперирует данными без парсинга SQL запроса, что приводит к уменьшению загрузки процессора.
Он поддерживает пакетное выполнение запросов. Можно отправить несколько запросов сразу и получить результат за один раз, что опять же снижает нагрузку на процессор и на сеть.
Протокол HandlerSocket более компактный, чем у mysql/libmysql, что приводит к сокращению нагрузки на сеть.
Подробнее можно почитать здесь:
- Официальный репозиторий;
 Введение в HandlerSocket: описание протокола и расширения php-handlersocket;
Введение в HandlerSocket: описание протокола и расширения php-handlersocket;- То, что вы хотели знать о HandlerSocket, но не смогли нагуглить;
 Первый опыт работы с Handler Socket & php_handlersocket.
Первый опыт работы с Handler Socket & php_handlersocket.
Под катом вас ожидает:
- Новая библиотека для работы с HS, написанная на PHP;
- Сравнение производительности существующих решений + нового;
- Symfony2 bundle для работы с HS;
- Плагины к Munin для мониторинга активности HS;
- Разные мысли вслух и рассказы о «шишках».
Изучая вопрос внедрения HS в проект я был весьма удивлен тому, что под него не находилось нормальной PHP библиотеки, которая бы просто была удобной в использовании и покрывала функциональность протокола. Имеющиеся на тот момент решения были похожи на разрабатываемые, но никак ни на готовые к применению.
Нас не устроили готовые решения и мне не дали часы с проекта, чтобы я взял и накидал что-нибудь свое, поэтому вариант внедрения HS был отброшен. Проект уже давно позади, но мысль о том, что HS крутая штука овладела мной. И вот прошло уже больше года, когда я снова попытался найти решения и обнаружил, что ничего не сдвинулось с той мертвой точки.
Крутые парни из Badoo как-то рассказывали, что используют у себя под капотом HS, но я не смог найти в открытом доступе, чем они пользуются, подозреваю, что что-то самописное.
Анализ готовых решений
Готовых решений было три: 1 написано на PHP (HSPHP) и 2 расширения к интерпретатору, написанные на С.
У всех 3-х была пара общих проблем:
- отсутствие поддержки суффиксов;
- отсутствие поддержки авторизации;
- слабая документация;
- уровень покрытия тестами не очень высок.
С таким набором проблем Си расширения сразу были забракованы, потому что разбираться в них и допиливать на С совсем желания не было, оставался HSPHP.
Пока разбирался с HSPHP, успел сделать пару пулл реквестов. Внутри написано все через коллбеки, что мне не очень по душе. Все это вместе заставило меня отказаться и от этой библиотеки. Кстати, совсем недавно добавили поддержку авторизации в HSPHP, но при этом полностью сломалось все.
Почему свой велосипед
Мне нужен был простой в использовании инструмент, который из коробки не требовал бы никаких доработок, был удобен в использовании и явно поддерживался в актуальном состоянии. Поскольку ничего подобного я не нашел, а интерес к протоколу еще не остыл, то время и желание нашлись сами собой и организм в полуавтоматическом режиме сел писать код.
Встречаем — HandlerSocketLibrary
Коротко о результатах:
- на данный момент библиотека покрывает 100% протокола;
- распространяется под MIT лицензией;
- несколько способов отправления запроса;
- select запросы могут возвращать ассоциативный массив (например array(‘id’ => ‘1’, ‘message’ => ‘text’)), в остальных библиотеках мапить все с колонкам приходилось своими силами или запоминать порядок колонок при открытии индекса;
- был изучен код HS, на основании которого получилось создать Exception на каждую ошибку протокола HS. Внутри класса на человеко-понятном языке описано, что может приводить к появлению такой ошибки;
- написан скрипт для бенчмарка библиотек(PHPBenchHs);
- документация написана на русском и английском языках;
- покрыто тестами
 ;
;
- качество кода
 .
.
Архитектура
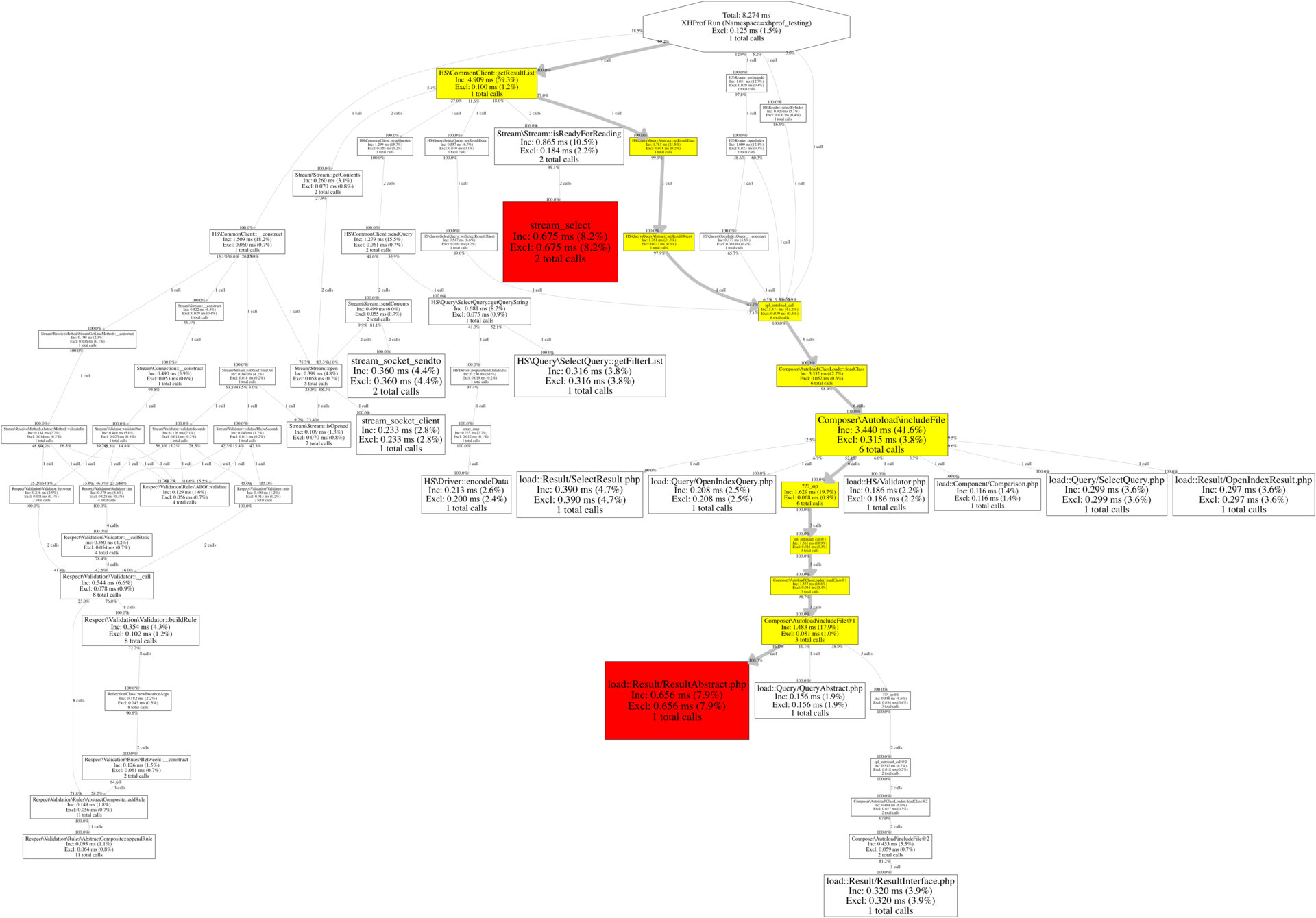
(Изображение кликабельное)
Это граф методов, вызываемых под капотом, библиотеки, нарисованный с помощью профайлера XHProf. На нем отчетливо видно, что 2 самых медленных участка кода — это работа с сокетом и парсинг ответа. Я использую обертку для работы со стримами\сокетами SteamLibrary.
Идея проста — создаете подключение к сокету, отправляете команду, получаете ответ. В архитектуру заложена возможность гибко играться с различными вариантами чтения данных через сокет(fgets, fgetc, fread...). Я еще не тестировал по скорости работы через различные обертки над сокетами, но это все заложено уже в архитектуру.
Примеры запросов
Я не буду рассматривать все возможные запросы здесь, потому что они описаны в документации (ссылка на документацию), постараюсь привести общие примеры и рассказать про особенности.
Есть 2 сокета — читающий и пишущий. Разница в них вся сводится к поддерживаемым командам. Читающий сокет способен обработать 3 команды:
- команда авторизации;
- команда открытия индекса;
- чтение информации из открытого индекса.
Чтобы подключиться к читающему сокету:
$reader = new \HS\Reader('localhost', 9998, 'passwordRead');
Конструктор принимает — host, port и пароль для авторизации(не обязателен). Команда авторизации отправляется автоматически.
Открываем индекс:
$indexId = $reader->getIndexId( 'database', 'tableName', 'PRIMARY', array('key', 'text'), array('num') );
Обязательно необходимо указывать базу данных, таблицу и ключ (если ключ будет empty, то по умолчанию работа продолжится с PRIMARY ключем), дальше список колонок (key, text), которые нужно открыть, и дополнительная колонка для фильтрации (num). Фильтрация необязательна к заполнению, но только эти колонки будут доступны в будущем для фильтрации, кроме того значения этих колонок не будут возвращаться при ответе сервера.
При последующих вызовах индекс открываться не будет, будет использоваться уже открытый.
Для получения данных через открытый индекс выполняем код:
$selectQuery = $reader->selectByIndex($indexId, Comparison::EQUAL, array(42));
Мы берем значения, которые равны 42, поскольку в списке колонок данного индекса последовательность идет (key, text), то 42 сопоставляется 1 колонке, а именно key, тип сравнения равенство (Comparison::EQUAL).
По умолчанию HS возвращает просто список значений. Вы можете на выходе получить данные в виде ассоциативного массива (значения автоматически мапятся в массив по названию колонки) или вектора.
Для этого нужно лишь добавить после запроса и перед его отправкой строку:
$selectQuery->setReturnType(SelectQuery::ASSOC); // пример для получения ассоциативного массива
Чтобы получить данные, вам нужно отправить запрос и распарсить результаты:
$resultList = $reader->getResultList();
Переменная $resultList содержит в себе массив результатов всех команд, которые были отправлены за эту итерацию, но разгребать все ответы не быстро и неудобно, поэтому все ответы автоматически мапятся к запросам.
$selectResult = $selectQuery->getResult(); // вернет не NULL только после выполнения $reader->getResultList(); $arrayResultList = $selectResult->getData(); // является массивом с результатами.
Другой способ — открытие индекса и отправка команды разом:
$selectQuery = $reader->select( array('key', 'text'), // колонки 'database', 'tableName', 'PRIMARY', Comparison::MORE, // тип сравнения, в нашем случае это > array('1'), // sql like: key > 1 0, // offset 99, // limit array('num'), // колонка фильтрации array(new Filter(Comparison::EQUAL, 0, '3')) // sql like: num = 3 ); // SELECT key,text from database.tableName WHERE key > 1 and num = 3 LIMIT 0,99; $this->getReader()->getResultList();
Прежде всего будет проверено, есть ли индекс, который содержит весь список колонок. Если да — будет использоваться он, а если нет — откроется новый индекс с необходимым кол-вом колонок.
Третий способ — это через “СтроителяЗапросов”(QueryBuilder), думаю уже комментировать здесь нет смысла:
$selectQueryBuilder = \HS\QueryBuilder::select(array('key', 'date', 'varchar', 'text', 'set', 'union')) ->fromDataBase($this->getDatabase()) ->fromTable($this->getTableName()) ->where(Comparison::MORE, array('key' => 2)) ->andWhere('float', Comparison::EQUAL, 3); $selectQuery = $reader->addQueryBuilder($selectQueryBuilder); $reader->getResultList(); $selectQuery->getResult()->getData();
Это все команды, которые могут работать через читающий сокет. Все остальные будут выпадать с ReadOnlyError.
Пишущий сокет обрабатывает эти 3 команды и еще 5:
- insert
- delete
- update
- increment
- decrement
Примеры, как работать с этими командами, есть в доках HandlerSocketLibrary. Первые 3 я вообще считаю интуитивно понятными и достаточно будет просто посмотреть примеры, поэтому я их пропускаю.
А вот инкремент и декремент — команды, которые увеличивают или уменьшают значения в базе данных. Вам нужно знать, что в случае, когда значение в процессе операции должно поменяться с отрицательного на положительное или наоборот, такая операция не пройдет и значение не изменится. То есть значение -1 никогда не станет 0 с помощью команды инкремента. Это особенность самого плагина HS.
Если в модифицирующих командах выставить флаг $suffix = true, то ответом будет SelectResult со значениями, подходящими под ваши критерии на модификацию ДО процесса модицикации. То есть, если вы обновляете 2 колонки и указываете suffix = true, то вам вернутся значения этих колонок до обновления, а не после.
Если лимит и оффсет не указаны, то по умолчанию они 1 и 0 соответственно.
Важно не забывать такую особенность инкрементного\декрементного запросов: значение лимита умножается со значением, на которое нужно увеличить или уменьшить запись.
Сравнение производительности с аналогами
На графиках сравнение происходило по скорости обработки запросов и по потребляемой на это оперативной памяти. Всего было выполнено 1000 запросов.
Замеры производились на синтетической базе данных под управлением Mac Os X, i5 + 4Gb Ram. Мне было не критичны абсолютные значения, нужно было процентное соотношение, вы же можете все тоже самое проделать на своем железе. Для этого вы можете использовать скрипты моих тестов, выложенные на github.
При Insert`е я «читерил» и просто вставил всю 1000 элементов 1-им запросом.

Больше — лучше.

Меньше — лучше.
Нужно отдать должно HSPHP, я думал, что она будет сильнее проигрывать по скорости и потребляемой памяти СИшным расширениям, а оказалось на деле, что совсем малость. Но такой огромный отрыв по производительности просто застал меня в расплох, я ожидал максимум 30-50% отставание.
Нужно было исправлять, нужно было искать, в чем беда. Первым делом вытащил из под стола XHProf и записал результат для 1000 Select запросов:
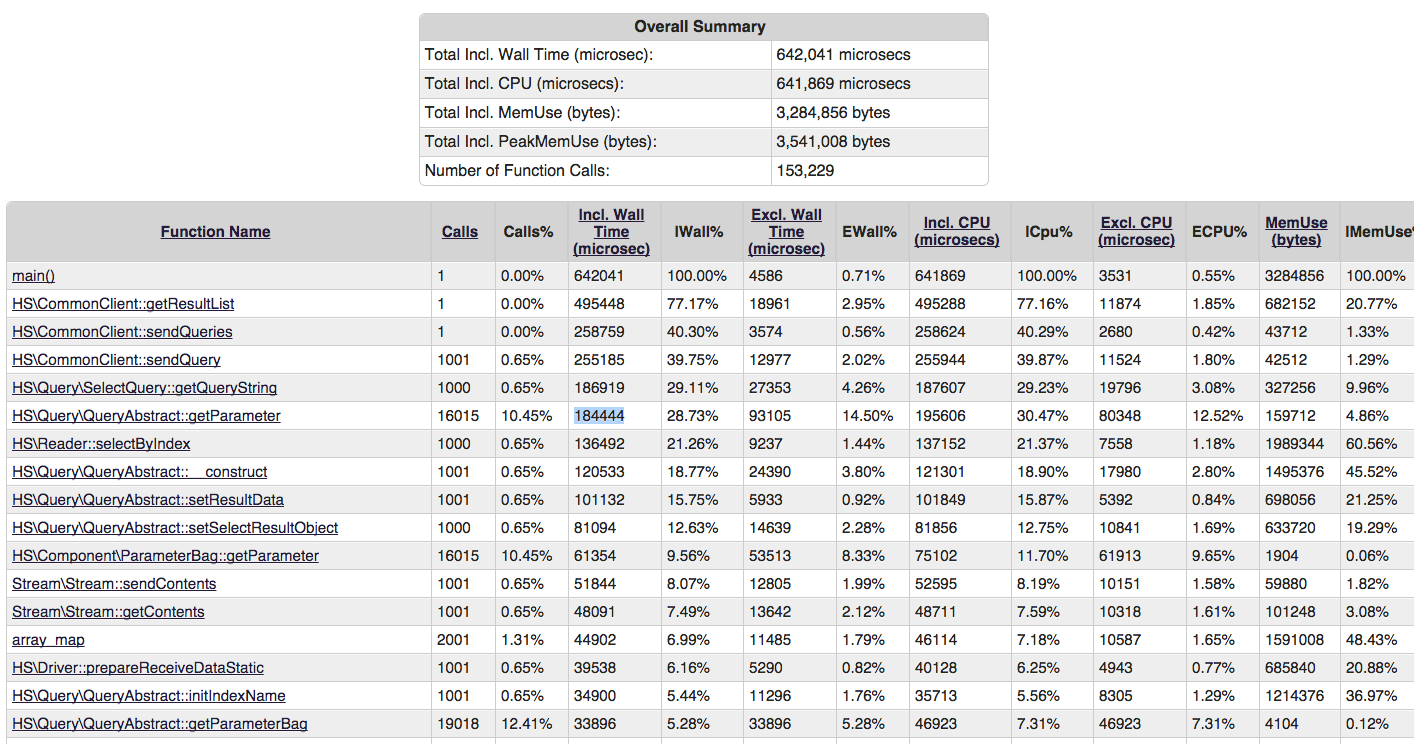
Первая проблема — работа через массив.
При проектировании был выбран array для внутреннего обмена информацией. Я, конечно же, понимал, что потеряю в производительности, но чтобы настолько…
Использовался сильно урезанный класс ParameterBag из компонентов HttpFoundation для работы с array. Смысл в том, что если в массиве есть значения с ключом N, то мы их возвращаем, если нет — defaultValue, которое можно указать самому для любого значения.
На графике выше как раз видно, что работа через ParameterBag уносит с собой непозволительное количество процессорного времени.
Загвостка в том, чтобы проверить — есть там что-то или нет, существует 2 наиболее очевидных способа:isset и array_key_exists.
Isset не обрабатывает корректно null, поэтому если его использовать, то нужно из архитектуры убирать все возможные моменты, когда в массив приходит null или пустая строка, так как при этом элемент не будет находиться через isset. В array_key_exists с этим все нормально, поэтому его и выбрал изначально. А вот благодаря профайлеру открытие было неожиданное и погуглив проблему скорости обнаружил, что array_key_exists проигрывает примерно в 10! раз isset`у. Самым очевидным решением был временный костыль — изменить условие проверки значения в массиве — перед array_key_exists добавить isset. Получилась такая проверка:
if(isset($array[$key]) || array_key_exists($array, $key)) { // ~(0.0)~ }
Просто добавив перед array_key_exists проверку через isset производительность всей библиотеки выросла на 4%! Это было прикольно, но 4% это недостаточно прикольный результат в целом, поэтому пришлось полностью избавиться от ParameterBag`а, переписав все на конкретные значения в запросах.
Результат был ожидаемым:

Выкинутый array сократил время выполнения Select запросов на 44%, и потребляемую память на 45%.
Не могу сказать, что скорость работы сейчас отличная, я ей еще недоволен. Дальше предстоит избавляться от лишних абстракций и внутренних оптимизаций под каждый конкретный запрос. Эту работу еще предстоит проделать, но отставание сократилось до 2.5-3 раз, вместо 5.
Error list
Еще одна приятная штука, которая появилась благодаря большому кол-ву вопросов в сети о расшифровке ошибок HS. Были изучены исходники HS и выписаны все возможные виды ошибок, благо написан он на понятном языке и исходников не так много. Ниже приведен список, какие ошибки могут возвращаться при работе HS с помощью HandlerSocketLibrary и что они означают. Я бы не стал выкладывать этот список в статье, если бы не дифицит информации на эту тему в сети.
error list
Вот в этом php файле видна логика парсинга ошибок.
- AuthenticationError — сервер требует авторизации и вы еще не прошли;
- ComparisonOperatorError — передан невалидный оператор сравнения (доступно только 4 >=, <=, <, >);
- InListSizeError — выбран режим поиска по списку значений и количество этих значений указано неправильное;
- KeyIndexError — указанный номер колонки превышает общее количество колонок в открытом индексе;
- ModifyOperatorError — передан невалидный модифицирующий оператор.(+,-,D,U,+?,-?,D?,U?);
- UnknownError — супер приз — ааааавтомобиль! Если вы выйграли автомобиль — создайте об этом issue;
- ColumnParseError — переданы невалидные значения колонок;
- FilterColumnError — вы пытаетесь открыть колонку с номером большим, чем количество открытых колонок для фильтрации;
- IndexOverFlowError — вы пытаетесь использовать не инициализированный номер индекса;
- KeyLengthError — длинна списка ключей либо больше списка, либо < 1 ;
- OpenTableError — пытаетесь открыть несуществующую таблицу, либо несуществующий индекс;
- CommandError — вы отправили невалидную команду;
- FilterTypeError — передали неправильный тип фильтрации.(F,W);
- InternalMysqlError — MySQL не смог выполнить команду.(например вставить уже существующее значение);
- LockTableError — вы пытаетесь открыть залоченную таблицу;
- ReadOnlyError — модифицирующая команда была отправлена на читающий сокет.
Вот в этом php файле видна логика парсинга ошибок.
Планы
Прежде всего, нужно добавить все возможные кейсы использования и покрыть их тестами. В результате борьбы за скорость выполнения запросов в коде появились рудименты, которые нужно рефакторить. Не все запросы имеют полный список возможностей, то есть у каких-то запросов может быть пропущена возможность использовать фильтры или списки ключей (да, код слегка еще сыроват). В уже существующих тестах легкий бардак, потому что по началу писал аккуратно, под конец уже просто, чтобы покрыть кейс. Тесты на модификацию базы данных не проверяют состояние всей таблицы после модифицирующего запроса.
Нужно добавить возможность возвращать значения ввиде объекта на Select запросах. HS поддерживает CRUD — поэтому можно дописать обертку к ORM, например, к той же Доктрине.
Почему же так мало информации о HS и небольшое комьюнити?
Сразу хочу прояснить: HS — отличная штука, которую можно и нужно использовать, просто не у всех может это получиться в силу особенностей протокола и его ограничений.
Так почему же не растет комьюнити и почему же с HS так тяжело начать работу в реальных проектах?
Уверен, что на моем месте были и другие разработчики, когда между идеей о внедрении HS и реальным внедрением HS всплывают задачи, по допиливанию сопряженной с HS инфраструктурой, что абсолютно не связанно с бизнес задачами по проекту. В итоге получается выбор: либо твой менеджер\тех директор\еще кто-то оплачивает эту работу и вообще дает тебе на нее добро, либо ты сам это делаешь во внеурочное время, а уже после поднимаешь вопрос, что все готово и можно внедряться и будет только профит, либо ты забиваешь на HS, что чаще всего и происходило, видимо.
Естественно, то, что у HS нет разграничения доступа по базам данных; это резко ограничивает область применения, все хостинги с количеством клиентов > 1 отпадают.
Я попытался слегка внести свой вклад в решение этой проблемы.
Мониторинг
Решили мы, значит, использовать HS на проекте, но как измерять нагрузку проходящую через него? HS имеет возможность настройки количества воркеров, вот их статусы и загрузку будем мониторить с помощью Munin.

Плагины подключаются к MySQL и парсят вывод команды show processlist. Доступны для скачки отсюда. Этих данных должно быть достаточно, чтобы оценить, насколько загружено все в пиках.
Symfony2 Bundle
Если ваш проект использует фреймворк Symfony 2-й версии, то вам из коробки достается возможность баловаться с HS. Нужно только добавить в composer.json новую зависимость: «konstantin-kuklin/handlersocket-bundle»: «dev-master».
Настройка:
Добавляем конфиги для сокета на чтение и запись:
hs: reader: host: localhost port: 9998 debug: "%kernel.debug%" auth_key: "Password_Read1" writer: host: localhost port: 9999 debug: "%kernel.debug%"
Параметр auth_key опционален и его отсутствие обозначает отсутствие необходимости в авторизации(ваш КО). Debug флаг меняет режим работы библиотеки HS под капотом, запросы отправляются поштучно и записывается время обработки на каждый запрос, также увеличивается расход оперативы на дополнительное хранение запросов.>
Дальше все просто — работаем с 2 сервисами:
/** @var \HS\Reader $reader */ $reader = $this->get("hs_reader"); /** @var \HS\Writer $writer */ $writer = $this->get("hs_writer");
Есть и «Ништяки» для дебага:
В dev режиме заходим на сайт и видим новую иконку на строке вебпрофайлера:

Собирается очень упрощенная статистика: сколько запросов и сколько на их выполнение ушло времени (время полное — отправка, получение, парсинг). При клике на эту новую кнопочку увидим более детальную информацию о запросах:

Сверху информация куда отсылались запросы и информация о самих запросах, если нажать на Display Data, то получим данные результата запроса:

На самом деле здесь моя фантазия иссякла, на этот момент я с протоколом познакомился уже достаточно хорошо и поэтому придумывать кейсы для отображения подобной информации стало тяжко. Буду рад вашим идеям о том, какая бы информация еще могла быть полезной для отладки.
Из минусов — бандл сейчас никак не тестируется.
Планирую сделать 1 точку входа в HS с указанием Базы данных, то есть в запросах не придется передавать базу данных.
Заключение
Все это теоретически можно использовать в продакшене, но мне нужна помощь в тестировании и я надеюсь этой статьей собрать людей, имеющийся опыт у людей использующий HS.
Конструктивная критика, пулл реквесты, предложения, найденные баги приветствуются.
Сейчас начать использовать HS проще простого, PerconaServer и MariaDB содержат в своих сборках этот плагин. Действуйте!
Спасибо за внимание!
P.S. В субботу пролетела новость, что код Badoo либы будет выложен.
