В этой статье я сфокусируюсь на оптимизации производительности систем NetApp FAS.
Объектами оптимизации с точки зрения СХД могут быть настройки:

Для поиска узкого места обычно выполняют методику последовательного исключения. Предлагаю перво-наперво начать с СХД. А дальше двигаться СХД -> Сеть (Ethernet / FC) -> Хост ( Windows / Linux / VMware ESXi 5.Х и ESXi 6.X ) -> Приложение.
Напомню парадигму устройства внутренней структуры СХД NetApp FAS, согласно идеологии «share nothing», которая практически всегда соблюдается у систем FAS: Диски объединяются в Рейд группы (RAID-DP), Рейд группы объединяются в Plex (Plex. Используются в случае зеркалирования между СХД, аналог RAID1), оба Plex'а объединяются в Aggregate, на Aggregate создаются FlexVol, данные в FlexVol равномерно размазаны по всем дискам в Aggregate, в FlexVol создаются Qtree (что-то типа папки, на которые можно назначать всякие квоты), Qtree не могут быть вложенными, далее внутри Qtree создаются LUN'ы.
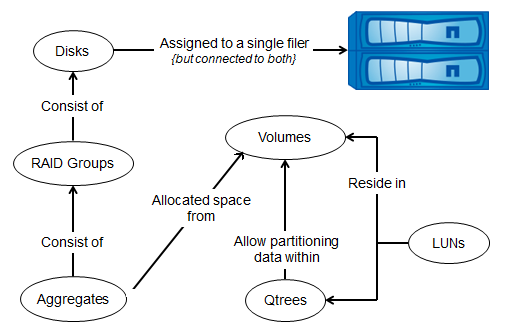
Объекты СХД NetApp FAS
В один момент времени один диск может принадлежать только одному контроллеру, это самая базовая потребность DataONTAP, глубоко зашитая в недра ОС. Стоит лишь отметить, что диском для DataONTAP на самом деле может быть как диск целиком, так и партиция (раздел). Другими словами один такой объект ( весь диск или его партиция) всегда имеет приналежность (ownership), только к одному контроллеру в НА паре. Таким образом есть нюанс на который сейчас можно не обращать внимание для простоты картины: во втором случае, все-же один физический диск может иметь несколько разделов, ownership которых назначен и исспользуется, для одних разделов — одним контроллером, для других разделов — другим контроллером НА пары.
Итак в один момент времени «диски» (в терминах DataONTAP), луны, вольюмы и агрегаты принадлежат только одному контроллеру. Доступ к этому луну тем не мение может осуществляться через партнёра в HA паре или вообще через другие ноды кластера. Но оптимальными путями к такому луну всегда будут только те, которые проходят через порты того контроллера, который владеет дисками на которых расположен лун->вольюм->агрегат. Если на контроллере владельце больше чем один порт, то все эти порты являются оптимальными путями к луну который расположен на этом контроллере. Использование всех возможных оптимальных путей к луну через все порты на контроллере, как правило, положительно скаывается на скорости доступа к нему. Хост может использовать все оптимальные пути одновременно или только часть оптимальных путей, это зависит от настроек мультипасинга в ОС такого хоста и настроек portset на хранилище.
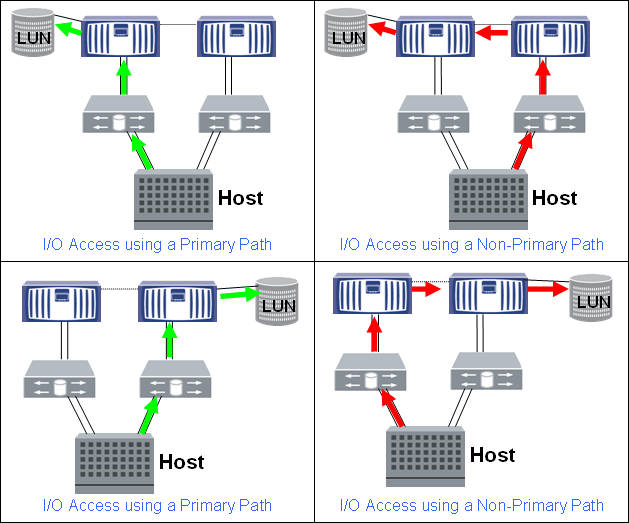
Тоже касается и всех других протоколов для систем FAS в режиме Cluster-Mode — оптимальными путями являются те, которые проходят через порты того контроллера, на котором собственно расположены данные. В режиме 7-Mode попросту нет доступа к данным через не оптимальные пути для протоколов CIFS/iSCSI/NFS.
Таким образом необходимо следить за тем, чтобы пути на Front-End всегда были оптимальными для всех протоколов доступа к СХД.
Так в случае с протоколами FC/FCoE/iSCSI решить этот вопрос помогает механизм ALUA, объясняющий хостам где оптимальные пути, а где нет, а правильные настройки мультипасинга обеспечивают использование только оптимальных путей в нормальной работе.
Для протокола NFS вопрос использования оптимальных путей решен в pNFS, поддержка которого уже реализована в RedHat Linux. Что позволяет автоматически без дополнительных настроек клиенту понимать и переключаться на оптимальный путь. Для среды виртуализации VMware ESXi 6.0 с протоколом NFS v3.0 вопрос оптимальных путей реализован при помощи технологии vVol, поддержка которого присутствует на СХД NetApp FAS с ClusteredONTAP.
Для протокола CIFS (SMB) в версии 3.0 реализован механизм SMB Auto Location позволяющий подобно pNFS переключаться на оптимальный путь к файловой шаре.
При использовании NetApp FAS в режиме 7-Mode и Cluster-Mode на FC/FCoE необходимо включать ALUA. Настройки для iSCSI для режимов 7-Mode и Cluster-Mode отличаются, так для первого случая режим ALUA не может быь включён, а для второго обязателен.
Multipathing должен по-умолчанию использовать предпочтительные пути — пути к LUN через порты контроллера на котором он расположен. Сообщения в консоли СХД FCP Partner Path Misconfigured будут говорить о неправильно настроенном ALUA или MPIO. Это важный параметр, не стоит его игнорировать, так как был один реальный случай, когда взбесившийся драйвер мультипасинга хоста безостановочно переключался между путями создавая таким образом большие очереди в системе ввода-вывода.
С размером SAN кластера в 8 нод (4 НА пары) систем FAS, количество путей доступа (а следовательно и портов на контроллерах) к луну, может достигать невообразимых количеств. Количество нод в кластере будет только расти, при этом, за частую, можно ограничиться вполне разумным количеством основных и запасных путей не жертвуя отказоустойчивостью. Так на помощь в решении этого вопроса приходит portset, разрешая «видеть» лун только на заданных портах. По-этому порты хранилища, через которые видны ваши луны должны быть скоммутированы и настроены на коммутаторе, плюс соответствующим образом нужно сконфигурировать зонинг.
Начиная с версии DataONTAP 8.3 по-умолчанию применяется метод SLM уменьшаюший количество путей к луну до двух контроллеров: владеющего луном и его партнёра в HA паре. При миграции луна использующего механизм SLM на другую ноду кластера, от администратора не тредуется дополнительных манипуляций по указанию портов через которые будет доступен лун, всё происходит автоматически. Нужно проследить, чтобы WWPN наших LIF интерфейсов хранилища, на которых будет доступен мигрировавший лун, были добавлены в нужную зону на коммутаторах. Рекомендуется сразу прописать все возможные WWPN всех нод кластера в соответствующие зоны, а механизм SLM позаботиться чтобы путей к луну было «адекватно не большое» количество. Подробнее.
В случае онлайн миграции необходимо, на нодах которые принимают мигрирующий лун, разрешить «рассказывать» драйверам мультипасинга хостов, что лун теперь доступен по новым, дополнительным путям.
Подробнее о траблшутинге NetApp + VMWare с SAN. Подробнее о рекомендациях зонирования для NetApp в картинках.
Начиная с Data Ontap 8.2.1 поддерживается DCB (Lossless) Ethernet на всех конвергентных (CNA/UTA) портах хранилищ NetApp FAS. Рекомендации по настройке Ethernet сети.
В случае использования «файловых» протоколов NFS и CIFS очень просто получать преимущество от использования технологии Thin Provitioning, возвращая высвобожденное пространство внутрь файловой шары. А вот в случае с SAN использование ThinProvitioning приводит к необходимости постоянного контроля над свободным пространством плюс высвобождение свободного пространства (SCSI-3 механизм доступен для современных ОС и доступен в Data Ontap начиная с версии 8.1.3) происходит не «внутрь» того же LUN, а как бы внутрь Volume содержащий этот LUN.
В случае когда есть 10GBE подключения и БД Oracle, очень рекомендуется рассмотреть возможность подключения по протоколу dNFS, так как по внутренним тестам NetApp ( у других вендоров СХД эта ситуация может отличаться) производительность и латенси в сравнении с FC8G такая же или немного лучше на OLTP нагрузке. Также NFS очень удобен при виртуализации, когда есть один большой датастор со всеми виртуальными машинами который «видят» все хосты, облегчая миграцию между хостами, более простое обслуживание и настройку сетевой инфраструктуры в отличие от зонинга в SAN сетях.
Также очень удобно при виртуализации создавать thick диски виртуальной машины (следуя лучшим практикам VMWare для высоконагруженных сред) и при этом иметь Thin (с точки зрения СХД) датастор отданный по NFS имея одновременно и производительность и экономию, а не компромисс между тем и другим. Использование одного датастора позволяет более рационально распределять свободное пространство, отдавая его тем виртуальным машинам, которые в этом больше нуждаются, поднимая экономию пространства на новый уровень, а не жестко фиксируя «кому сколько», как это происходит в FC и iSCSI. В тоже время свободное пространство высвобожденное к примеру блочной дедубликацией или реалокацией «возвращает» это пространство и может быть задействовано той же NFS/CIFS шарой.
Линукс команда showmount -e поддерживается начиная с cDOT 8.3. для того чтобы команда showmount -e смогла дисковерить NFS, необходимо включить эту фичу со стороны хранилища:
При использовании MS Windows есть возможность применять iSCSI MCS позволяющий использовать в рамках одной iSCSI сесии несколько TCP соединений. Комбинация MPIO с MCS может давать существенный прирост в производительности.
Throughput in MB/s с разным количеством сессий/TCP соединений для MCS/MPIO и 10GBE для Windows 2008 R2 и FAS 3070
Новая версия CIFS (SMB) 3.0 позволяет использовать этот протокол не просто для целей файловой помойки но и раскрывает новые возможности для применения на базах данных MS SQL и виртуальных машин с MS Hyper-V.
Continuous availability shares (CA) расширяют возможности протокола. В предыдущих версиях клиенты были вынуждены переподключаться к хранилищу в случае Fail-Over или переезда LIF на другой порт. Теперь с механизмом CA, файлы будут доступны без прерывания сервиса в течении короткого времени отсутствия соединения при Fail-Over или переезде LIF.
Для наиболее оптимального задействования всех ядер CPU СХД, используйте не мение 8 вольюмов, это улучшит распаралеливание, их утилизацию и как следствие скорость работы.
Утилита perfstat собирающая в текстовый файл нагрузку на СХД. Также может одновременно собирать информацию по нагрузке с хоста на котором запущена утилита. Скачать с сайта support.netapp.com раздел Download — Utility ToolChest (Для входа нужен NetApp NOW ID). Очень важно в момент нагрузки собрать статистику с СХД, так как часто бывает так, что хост не способен дать достаточную нагрузку на СХД, что будет видно из лога perfstat, в таком случае нужно будет использовать несколько хостов.
При помощи этой утилиты можно отследить общую нагрузку на СХД от всех хостов, в том числе и проблемы на стороне СХД, к примеру когда повреждённый диск тормозит всю систему на Back-End и как следствие на Front-End.
Сопоставляя результаты теста с хоста и с СХД можно найти «узкое место» в тестируемой системе. Так по выводу команды perfstat ниже, видно, что СХД не достаточно нагружена (параметры CPU, Disk Usage и Total), использующая FC. Большинство операций в этой системе совершается в виде чтения содержимого кэша (значение Cache hit). Из чего делаем вывод — хост не может достаточно нагрузить систему хранения.
Расшифровка параметра Cache age, Cache hit, CP ty. Ещё немного об оптимизации производительности и поиске узкого горлышка (bottleneck).
ФС хоста может вносить существенные коррективы при тестировании производительности.
Размер блока ФС должен быть кратным 4КБ. К примеру, если мы запускаем синтетическую нагрузку подобную генерируемой OLTP, где размер оперируемого блока в среднем равен 8КБ, то ставим 8КБ. Хочу также обратить внимание что как сама ФС, её реализация для конкретной ОС и версия может очень сильно влиять на общую картину производительности. Так для при записи 10 МБ блоками в 100 потоков командой dd файлов от БД на ФС UFS расположенной на LUN отданный по FC4G с СХД FAS 2240 и 21+2 дисками SAS 600 10k в одном агрегате показывал скорость 150 МБ/сек, тогда как та же конфигурация но с ФС ZFS показывала в два раза больше (приближаясь к теоретическому максимуму сетевого канала), а параметр Noatime вообще никак не влиял на ситуацию.
Также этот же параметр нужно установить на разделе СХД с данными, к которым производится доступ. Включение этой опции предотвращает обновление времени доступа к файлу в инодах WAFL. Таким образом следующая команда применима для файловых шар SMB CIFS/NFS.
Для любой ОС нужно при создании LUN'а выбрать правильную геометрию. В случае неправильно указанного размера блока ФС, неправильно указанной геометрии LUN, не правильно выбранного на хосте параметра MBR/GPT мы будем наблюдать в пиковые нагрузки сообщения в консоли о неком событии "LUN misalignment". Иногда эти сообщения могут появляться ошибочно, в случае редкого их появления просто игнорируйте их. Проверить это можно выполнив на системе хранения команду lun stats, ниже пример вывода, обратите внимание на align_histo.1:100% и write_align_histo.1:97%, так не должно быть в нормально сконфигурированной системе — блок должен начинаться с «0» в параметрах «align_histo».
misalignment также может возникать в среде виртуализации, на «общих datastor'ах» с VMFS, что может приводить к деградации производительности системы. В этом случае есть два варианта устранения проблемы существующей виртуальной машины — через плагин NetApp VSC для vCenter, запускается миграция виртуальной машины (Storage vMoution) на новый datastore (с правильно выставленной геометрией LUN) или вручную при помощи утилиты командной строки MBRalign выполнить выравнивание границ блоков в vmdk файле. Хочу отметить что ручной режим скорее всего сделает не рабочим загрузчик ОС виртуальной машины и его потребуется восстанавливать. Подробнее смотри документ Best Practices for File System alignment in Virtual Environments. Подробнее что такое I/O Misalignment и как его устранить.
Обязательно необходимо проверить, что все данные размазываются по всем дискам, к примеру после добавления дисков в уже созданный агрегат. Для проверки состояния «размазанности» данных вольюма по дискам запустите на 7-Mode:
на Custered ONTAP:
Давайте посмотрим пример вывода такой команды:
Значение 12, больше чем threshold 4, говорит о том, что на вольюме необходимо запустить реалокацию. Значение hotspot 5 говорит о том, что горячие блоки находятся на 5-ти дисках, а не на всех дисках агрегата (если не устраняется простой реалокацией, смотри здесь).
Не достаточное свободное пространство и наличие снепшотов могут не дать выполнить реалокацию. На вольюме нужно иметь не мение 5% свободного пространства в активной файловой системе и 10% свободного пространства в SnapReserve.
В случае добавления новых дисков имеет смысл разбалансировать не только данные но и пусте блоки.
Запустим физическую реалокацию данных вольюма для оптимизации производительности на 7-Mode
На Clustered ONTAP. Для Clustered ONTAP команда reallocate не вернёт вывод, его нужно запросить:
Во время теста очень важно удостовериться в том, что один из дисков не умер и/или не тормозит весь агрегат.
Мы видим, что aggregate наш состоит из двух RAID-групп — rg0 и rg1, в конфигурации RAID-DP 11d+2p. Диски 0c.16, 1b.17 и 0c.29, 0c.33 – диски parity, остальные – Data.
Когда дата-диски не равномерно нагружены
В выводе комманды statit/statistics, ищем странности. Величина использования дисков 0с.25, 26 и 28, по сравнению с остальными data-дисками (для дисков parity действуют другие правила, на них не смотрим). При средней нагрузке ut% по дискам группы 35%, на этих дисках загрузка почти вдвое выше, около 75% плюс на них высокие значения latency (ureads usecs и writes usecs), по сравнению с другими дисками, которая достигает 60-70 миллисекунд, против 14-17 для остальных. В нормально же работающем aggregate нагрузка должна равномерно распределяться по всем data-дискам в aggregate. Нужно выранять нагрузку на агрегате реалокацией или заменить такие диски.
Для 7-Mode:
Для C-Mode:
Удостоверимся, что нет затыка на CPU или в кеше и проверим нагрузку на протоколы:
Подробнее про оптимизацию и проверку дисковой подсистемы здесь.
Если не оговорено иначе в лучших практиках, отключайте снепшоты на агрегатах, так как они занимают лишнее пространство и необходимы в очень редких конфигурациях, таких как SyncMirror (MetroCluster) и некоторых других.
Для Clustered ONTAP перед каждой командой добавьте
Virtual Storage Tiering (VST) — кеширование данных второго уровня. FlashCache — плата PCIe, кеширующая все операции чтения на контроллере. FlashPool — гибридный агрегат состоящий из вращающихся дисков (SAS/SATA HDD) и дисков SSD выделенных в RAID группу(ы), кеширует как операции чтения, так и операции перезаписи (Операции записи всегда кешируются в системном кэше контроллера, т.е. кеше первого уровня). Перед тем как покупать дорогостоющий акселератор стоит проверить, что он нужен и какой размер кеша будет наиболее оптимален, для этого есть следующие механизмы:
Широко применяйте матрицу совместимости в вашей практике для уменьшения потенциальных проблем в инфрастурктуре ЦОД.
Уверен что по мере получения новой информации мне будет что добавить в эту статью, так что заглядывайте сюда изредка за адептами.
Замечания по ошибкам в тексте и предложения прошу направлять в ЛС.
Объектами оптимизации с точки зрения СХД могут быть настройки:
- SAN в СХД
- Ethernet в СХД
- NAS в СХД
- Дисковой подсистемы на Back-End СХД
- Дисковой подсистемы на Front-End СХД
- Проверка совместимости прошивок
- Ускорители
Для поиска узкого места обычно выполняют методику последовательного исключения. Предлагаю перво-наперво начать с СХД. А дальше двигаться СХД -> Сеть (Ethernet / FC) -> Хост ( Windows / Linux / VMware ESXi 5.Х и ESXi 6.X ) -> Приложение.
Краткий ликбез по NetApp:
Напомню парадигму устройства внутренней структуры СХД NetApp FAS, согласно идеологии «share nothing», которая практически всегда соблюдается у систем FAS: Диски объединяются в Рейд группы (RAID-DP), Рейд группы объединяются в Plex (Plex. Используются в случае зеркалирования между СХД, аналог RAID1), оба Plex'а объединяются в Aggregate, на Aggregate создаются FlexVol, данные в FlexVol равномерно размазаны по всем дискам в Aggregate, в FlexVol создаются Qtree (что-то типа папки, на которые можно назначать всякие квоты), Qtree не могут быть вложенными, далее внутри Qtree создаются LUN'ы.
Объекты СХД NetApp FAS
В один момент времени один диск может принадлежать только одному контроллеру, это самая базовая потребность DataONTAP, глубоко зашитая в недра ОС. Стоит лишь отметить, что диском для DataONTAP на самом деле может быть как диск целиком, так и партиция (раздел). Другими словами один такой объект ( весь диск или его партиция) всегда имеет приналежность (ownership), только к одному контроллеру в НА паре. Таким образом есть нюанс на который сейчас можно не обращать внимание для простоты картины: во втором случае, все-же один физический диск может иметь несколько разделов, ownership которых назначен и исспользуется, для одних разделов — одним контроллером, для других разделов — другим контроллером НА пары.
Итак в один момент времени «диски» (в терминах DataONTAP), луны, вольюмы и агрегаты принадлежат только одному контроллеру. Доступ к этому луну тем не мение может осуществляться через партнёра в HA паре или вообще через другие ноды кластера. Но оптимальными путями к такому луну всегда будут только те, которые проходят через порты того контроллера, который владеет дисками на которых расположен лун->вольюм->агрегат. Если на контроллере владельце больше чем один порт, то все эти порты являются оптимальными путями к луну который расположен на этом контроллере. Использование всех возможных оптимальных путей к луну через все порты на контроллере, как правило, положительно скаывается на скорости доступа к нему. Хост может использовать все оптимальные пути одновременно или только часть оптимальных путей, это зависит от настроек мультипасинга в ОС такого хоста и настроек portset на хранилище.
Тоже касается и всех других протоколов для систем FAS в режиме Cluster-Mode — оптимальными путями являются те, которые проходят через порты того контроллера, на котором собственно расположены данные. В режиме 7-Mode попросту нет доступа к данным через не оптимальные пути для протоколов CIFS/iSCSI/NFS.
Таким образом необходимо следить за тем, чтобы пути на Front-End всегда были оптимальными для всех протоколов доступа к СХД.
Так в случае с протоколами FC/FCoE/iSCSI решить этот вопрос помогает механизм ALUA, объясняющий хостам где оптимальные пути, а где нет, а правильные настройки мультипасинга обеспечивают использование только оптимальных путей в нормальной работе.
Для протокола NFS вопрос использования оптимальных путей решен в pNFS, поддержка которого уже реализована в RedHat Linux. Что позволяет автоматически без дополнительных настроек клиенту понимать и переключаться на оптимальный путь. Для среды виртуализации VMware ESXi 6.0 с протоколом NFS v3.0 вопрос оптимальных путей реализован при помощи технологии vVol, поддержка которого присутствует на СХД NetApp FAS с ClusteredONTAP.
Для протокола CIFS (SMB) в версии 3.0 реализован механизм SMB Auto Location позволяющий подобно pNFS переключаться на оптимальный путь к файловой шаре.
SAN Multipathing
При использовании NetApp FAS в режиме 7-Mode и Cluster-Mode на FC/FCoE необходимо включать ALUA. Настройки для iSCSI для режимов 7-Mode и Cluster-Mode отличаются, так для первого случая режим ALUA не может быь включён, а для второго обязателен.
Multipathing должен по-умолчанию использовать предпочтительные пути — пути к LUN через порты контроллера на котором он расположен. Сообщения в консоли СХД FCP Partner Path Misconfigured будут говорить о неправильно настроенном ALUA или MPIO. Это важный параметр, не стоит его игнорировать, так как был один реальный случай, когда взбесившийся драйвер мультипасинга хоста безостановочно переключался между путями создавая таким образом большие очереди в системе ввода-вывода.
PortSet
С размером SAN кластера в 8 нод (4 НА пары) систем FAS, количество путей доступа (а следовательно и портов на контроллерах) к луну, может достигать невообразимых количеств. Количество нод в кластере будет только расти, при этом, за частую, можно ограничиться вполне разумным количеством основных и запасных путей не жертвуя отказоустойчивостью. Так на помощь в решении этого вопроса приходит portset, разрешая «видеть» лун только на заданных портах. По-этому порты хранилища, через которые видны ваши луны должны быть скоммутированы и настроены на коммутаторе, плюс соответствующим образом нужно сконфигурировать зонинг.
Selective LUN Map
Начиная с версии DataONTAP 8.3 по-умолчанию применяется метод SLM уменьшаюший количество путей к луну до двух контроллеров: владеющего луном и его партнёра в HA паре. При миграции луна использующего механизм SLM на другую ноду кластера, от администратора не тредуется дополнительных манипуляций по указанию портов через которые будет доступен лун, всё происходит автоматически. Нужно проследить, чтобы WWPN наших LIF интерфейсов хранилища, на которых будет доступен мигрировавший лун, были добавлены в нужную зону на коммутаторах. Рекомендуется сразу прописать все возможные WWPN всех нод кластера в соответствующие зоны, а механизм SLM позаботиться чтобы путей к луну было «адекватно не большое» количество. Подробнее.
Онлайн миграция и SLM
В случае онлайн миграции необходимо, на нодах которые принимают мигрирующий лун, разрешить «рассказывать» драйверам мультипасинга хостов, что лун теперь доступен по новым, дополнительным путям.
Зонинг
Подробнее о траблшутинге NetApp + VMWare с SAN. Подробнее о рекомендациях зонирования для NetApp в картинках.
Ethernet
Начиная с Data Ontap 8.2.1 поддерживается DCB (Lossless) Ethernet на всех конвергентных (CNA/UTA) портах хранилищ NetApp FAS. Рекомендации по настройке Ethernet сети.
Thin Provitioning
В случае использования «файловых» протоколов NFS и CIFS очень просто получать преимущество от использования технологии Thin Provitioning, возвращая высвобожденное пространство внутрь файловой шары. А вот в случае с SAN использование ThinProvitioning приводит к необходимости постоянного контроля над свободным пространством плюс высвобождение свободного пространства (SCSI-3 механизм доступен для современных ОС и доступен в Data Ontap начиная с версии 8.1.3) происходит не «внутрь» того же LUN, а как бы внутрь Volume содержащий этот LUN.
NFS
В случае когда есть 10GBE подключения и БД Oracle, очень рекомендуется рассмотреть возможность подключения по протоколу dNFS, так как по внутренним тестам NetApp ( у других вендоров СХД эта ситуация может отличаться) производительность и латенси в сравнении с FC8G такая же или немного лучше на OLTP нагрузке. Также NFS очень удобен при виртуализации, когда есть один большой датастор со всеми виртуальными машинами который «видят» все хосты, облегчая миграцию между хостами, более простое обслуживание и настройку сетевой инфраструктуры в отличие от зонинга в SAN сетях.
Также очень удобно при виртуализации создавать thick диски виртуальной машины (следуя лучшим практикам VMWare для высоконагруженных сред) и при этом иметь Thin (с точки зрения СХД) датастор отданный по NFS имея одновременно и производительность и экономию, а не компромисс между тем и другим. Использование одного датастора позволяет более рационально распределять свободное пространство, отдавая его тем виртуальным машинам, которые в этом больше нуждаются, поднимая экономию пространства на новый уровень, а не жестко фиксируя «кому сколько», как это происходит в FC и iSCSI. В тоже время свободное пространство высвобожденное к примеру блочной дедубликацией или реалокацией «возвращает» это пространство и может быть задействовано той же NFS/CIFS шарой.
Showmount
Линукс команда showmount -e поддерживается начиная с cDOT 8.3. для того чтобы команда showmount -e смогла дисковерить NFS, необходимо включить эту фичу со стороны хранилища:
nfs server modify -vserver * -showmount enabled
iSCSI
При использовании MS Windows есть возможность применять iSCSI MCS позволяющий использовать в рамках одной iSCSI сесии несколько TCP соединений. Комбинация MPIO с MCS может давать существенный прирост в производительности.
Throughput in MB/s с разным количеством сессий/TCP соединений для MCS/MPIO и 10GBE для Windows 2008 R2 и FAS 3070
| Number of connections | SQLIO NTFS MCS | SQLIO NTFS MPIO |
| 1 | 481 | 481 |
| 2 | 796 | 714 |
| 3 | 893 | 792 |
| 4 | 1012 | 890 |
| 5 | 944 | 852 |
| 6 | 906 | 902 |
| 7 | 945 | 961 |
| 8 | 903 | 911 |
CIFS
Новая версия CIFS (SMB) 3.0 позволяет использовать этот протокол не просто для целей файловой помойки но и раскрывает новые возможности для применения на базах данных MS SQL и виртуальных машин с MS Hyper-V.
Continuous availability shares (CA) расширяют возможности протокола. В предыдущих версиях клиенты были вынуждены переподключаться к хранилищу в случае Fail-Over или переезда LIF на другой порт. Теперь с механизмом CA, файлы будут доступны без прерывания сервиса в течении короткого времени отсутствия соединения при Fail-Over или переезде LIF.
VMWare VAAI & NFS
NetApp поддерживает примитивы VAAI для VMWare ESXi с протоколом NFS позволяя сгружать «рутинные задачи» с хоста на СХД. Требует установки NFS VAAI плагина на каждый ESXi хост (для FC плагин не требуется).CPU СХД
Для наиболее оптимального задействования всех ядер CPU СХД, используйте не мение 8 вольюмов, это улучшит распаралеливание, их утилизацию и как следствие скорость работы.
PerfStat
Утилита perfstat собирающая в текстовый файл нагрузку на СХД. Также может одновременно собирать информацию по нагрузке с хоста на котором запущена утилита. Скачать с сайта support.netapp.com раздел Download — Utility ToolChest (Для входа нужен NetApp NOW ID). Очень важно в момент нагрузки собрать статистику с СХД, так как часто бывает так, что хост не способен дать достаточную нагрузку на СХД, что будет видно из лога perfstat, в таком случае нужно будет использовать несколько хостов.
perfstat7.exe -f 192.168.0.10,192.168.0.12 -t 2 -i 3,0 -l root -S pw:123456 -F -I -w 1 >"20140114_1311.out"
При помощи этой утилиты можно отследить общую нагрузку на СХД от всех хостов, в том числе и проблемы на стороне СХД, к примеру когда повреждённый диск тормозит всю систему на Back-End и как следствие на Front-End.
Интерпретация вывода perfstat
Сопоставляя результаты теста с хоста и с СХД можно найти «узкое место» в тестируемой системе. Так по выводу команды perfstat ниже, видно, что СХД не достаточно нагружена (параметры CPU, Disk Usage и Total), использующая FC. Большинство операций в этой системе совершается в виде чтения содержимого кэша (значение Cache hit). Из чего делаем вывод — хост не может достаточно нагрузить систему хранения.
perfstat.out
Открыть текстовый файл.
=-=-=-=-=-= PERF 192.168.0.12 POSTSTATS =-=-=-=-=-= Begin: Wed Jan 15 07:16:45 GMT 2014 CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s in out read write read write age hit time ty util in out in out 8% 0 0 0 227 1 1 2307 24174 0 0 8 89% 11% : 22% 3 224 0 12401 852 0 0 12% 0 0 0 191 1 5 3052 24026 0 0 6s 90% 14% F 27% 1 190 0 21485 864 0 0 18% 0 0 0 517 0 1 5303 46467 0 0 0s 90% 33% 2 38% 1 516 0 23630 880 0 0 15% 0 0 0 314 1 2 4667 24287 0 0 0s 91% 15% F 33% 27 287 0 27759 853 0 0 12% 0 0 0 252 0 1 3425 24601 0 0 9 91% 16% F 28% 20 232 0 22280 852 0 0 24% 0 0 0 1472 2 5 9386 46919 0 0 1s 82% 34% F 47% 9 1463 0 26141 673 0 0 14% 0 0 0 303 1 3 3970 24527 0 0 8s 90% 27% F 33% 1 302 0 22810 967 0 0 14% 0 0 0 299 2 6 3862 24776 0 0 0s 91% 21% F 29% 1 298 0 21981 746 0 0 13% 0 0 0 237 1 3 4608 24348 0 0 9 94% 15% F 30% 1 236 0 22721 958 0 0 17% 0 0 0 306 1 2 5603 48072 0 0 2s 92% 32% F 37% 1 305 0 22232 792 0 0 13% 0 0 0 246 0 1 3208 24278 0 0 8s 92% 14% F 26% 20 226 0 24137 598 0 0 -- Summary Statistics ( 11 samples 1.0 secs/sample) CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s in out read write read write age hit time ty util in out in out Min 8% 0 0 0 191 0 1 2307 24026 0 0 0s 82% 11% * 22% 0 190 0 0 0 0 0 Avg 14% 0 0 0 396 0 2 4490 30588 0 0 2 90% 21% * 31% 7 389 0 22507 821 0 0 Max 24% 0 0 0 1472 2 6 9386 48072 0 0 9 94% 34% * 47% 27 1463 0 27759 967 0 0 Begin: Wed Jan 15 07:18:36 GMT 2014
Расшифровка параметра Cache age, Cache hit, CP ty. Ещё немного об оптимизации производительности и поиске узкого горлышка (bottleneck).
Файловая система
ФС хоста может вносить существенные коррективы при тестировании производительности.
Размер блока ФС должен быть кратным 4КБ. К примеру, если мы запускаем синтетическую нагрузку подобную генерируемой OLTP, где размер оперируемого блока в среднем равен 8КБ, то ставим 8КБ. Хочу также обратить внимание что как сама ФС, её реализация для конкретной ОС и версия может очень сильно влиять на общую картину производительности. Так для при записи 10 МБ блоками в 100 потоков командой dd файлов от БД на ФС UFS расположенной на LUN отданный по FC4G с СХД FAS 2240 и 21+2 дисками SAS 600 10k в одном агрегате показывал скорость 150 МБ/сек, тогда как та же конфигурация но с ФС ZFS показывала в два раза больше (приближаясь к теоретическому максимуму сетевого канала), а параметр Noatime вообще никак не влиял на ситуацию.
Noatime для файловых шар на хранилище
Также этот же параметр нужно установить на разделе СХД с данными, к которым производится доступ. Включение этой опции предотвращает обновление времени доступа к файлу в инодах WAFL. Таким образом следующая команда применима для файловых шар SMB CIFS/NFS.
vol options vol1 no_atime_update on
Misalignment
Для любой ОС нужно при создании LUN'а выбрать правильную геометрию. В случае неправильно указанного размера блока ФС, неправильно указанной геометрии LUN, не правильно выбранного на хосте параметра MBR/GPT мы будем наблюдать в пиковые нагрузки сообщения в консоли о неком событии "LUN misalignment". Иногда эти сообщения могут появляться ошибочно, в случае редкого их появления просто игнорируйте их. Проверить это можно выполнив на системе хранения команду lun stats, ниже пример вывода, обратите внимание на align_histo.1:100% и write_align_histo.1:97%, так не должно быть в нормально сконфигурированной системе — блок должен начинаться с «0» в параметрах «align_histo».
TR-3593
There are various ways of determining if you do not have proper alignment. Using perfstat counters, under the wafl_susp section, “wp.partial_writes“, “pw.over_limit“, and “pw.async_read“ are indicators of improper alignment. The “wp.partial write“ is the block counter of unaligned I/O. If more than a small number of partial writes happen, then WAFL will launch a background read. These are counted in “pw.async_read“; “pw.over_limit“ is the block counter of the writes waiting on disk reads.
Using Data ONTAP 7.2.1 or newer, there are some per LUN counters to track I/O alignment:
If any of these except for read/write_align_histo[0] is nonzero, you had some misaligned I/O.
Using Data ONTAP 7.2.1 or newer, there are some per LUN counters to track I/O alignment:
- lun:read_align_histo: 8bin histogram for reads that tracks how many 512b sectors off the beginning of a WAFL block an I/O was. Reported as a % of reads.
- lun:write_align_histo: Same for writes.
- lun:read_partial_blocks: % reads that are not a multiple of 4k.
- lun:write_partial_blocks: same for writes.
If any of these except for read/write_align_histo[0] is nonzero, you had some misaligned I/O.
lun stats для 7-Mode
priv set -q advanced; lun show -v lun status lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:display_name:/vol/vol0/drew_smi lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_ops:1/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_ops:26/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:other_ops:0/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_data:10758b/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_data:21997484b/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:queue_full:0/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:avg_latency:290.19ms lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:total_ops:27/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:scsi_partner_ops:0/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:scsi_partner_data:0b/s lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.0:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.1:100% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.2:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.3:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.4:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.5:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.6:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_align_histo.7:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.0:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.1:97% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.2:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.3:1% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.4:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.5:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.6:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_align_histo.7:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:read_partial_blocks:0% lun:/vol/vol0/drew_smi-W9mAeJb3vzGS:write_partial_blocks:1%
lun show для Cluster-Mode
cl1::*> set -privilege advanced; lun show -vserver <your_vserver> -path <your_path_to_the_lun> Vserver Name: vs_infra LUN Path: /vol/vol_infra_10/qtree_1/lun_10 Volume Name: vol_infra_10 Qtree Name: qtree_1 LUN Name: lun_10 LUN Size: 500.1GB Prefix Size: 0 Extent Size: 0 Suffix Size: 0 OS Type: vmware Space Reservation: disabled Serial Number: 804j6]FOQ3Ls Comment: Space Reservations Honored: true Space Allocation: disabled State: online LUN UUID: 473e9853-cc39-4eab-a1ef-88c43f42f9dc Mapped: mapped Vdisk ID: 80000402000000000000000000006a6a0335be76 Block Size: 512 Device Legacy ID: - Device Binary ID: - Device Text ID: - Read Only: false Inaccessible Due to Restore: false Inconsistent Filesystem: false Inconsistent Blocks: false NVFAIL: false Alignment: partial-writes Used Size: 89.44GB Maximum Resize Size: 4.94TB Creation Time: 10/31/2014 20:40:10 Class: regular Clone: false Clone Autodelete Enabled: false Has Metadata Provisioned: true QoS Policy Group: - cl1::*> set -privilege diagnostic; lun alignment show -vserver vs_infra -path * Vserver Name: vs_infra LUN Path: /vol/vol_infra_10/qtree_1/lun_10 OS Type: vmware Alignment: partial-writes Write Alignment Histogram: 62, 0, 0, 0, 0, 0, 0, 0 Read Alignment Histogram: 89, 0, 2, 0, 0, 0, 0, 0 Write Partial Blocks: 36 Read partial Blocks: 4 Vserver Name: vs_infra LUN Path: /vol/vol_0_a/lun_03032015_095833 OS Type: windows_2008 Alignment: aligned Write Alignment Histogram: 99, 0, 0, 0, 0, 0, 0, 0 Read Alignment Histogram: 99, 0, 0, 0, 0, 0, 0, 0 Write Partial Blocks: 0 Read partial Blocks: 0 Vserver Name: vs_infra LUN Path: /vol/vol_1_b/lun_03052015_095855 OS type: linux Alignment: misaligned Write alignment histogram percentage: 0, 0, 0, 0, 0, 0, 0, 100 Read alignment histogram percentage: 0, 0, 0, 0, 0, 0, 0, 100 Partial writes percentage: 0 Partial reads percentage: 0 Vserver Name: vs_infra LUN Path: /vol/vol_infra_20/qtree_2/lun_20 OS Type: linux Alignment: indeterminate Write Alignment Histogram: 0, 0, 0, 0, 0, 0, 0, 0 Read Alignment Histogram: 100, 0, 0, 0, 0, 0, 0, 0 Write Partial Blocks: 0 Read partial Blocks: 0
misalignment также может возникать в среде виртуализации, на «общих datastor'ах» с VMFS, что может приводить к деградации производительности системы. В этом случае есть два варианта устранения проблемы существующей виртуальной машины — через плагин NetApp VSC для vCenter, запускается миграция виртуальной машины (Storage vMoution) на новый datastore (с правильно выставленной геометрией LUN) или вручную при помощи утилиты командной строки MBRalign выполнить выравнивание границ блоков в vmdk файле. Хочу отметить что ручной режим скорее всего сделает не рабочим загрузчик ОС виртуальной машины и его потребуется восстанавливать. Подробнее смотри документ Best Practices for File System alignment in Virtual Environments. Подробнее что такое I/O Misalignment и как его устранить.
Reallocation
Обязательно необходимо проверить, что все данные размазываются по всем дискам, к примеру после добавления дисков в уже созданный агрегат. Для проверки состояния «размазанности» данных вольюма по дискам запустите на 7-Mode:
reallocate measure –o /vol/<volume>
на Custered ONTAP:
reallocate measure -vserver <vserver> -path /vol/<volume> -once true -threshold 3
Давайте посмотрим пример вывода такой команды:
Sat Mar 1 20:26:16 EET [fas-a:wafl.reallocate.check.highAdvise:info]: Allocation check on '/vol/vol_vol01' is 12, hotspot 5 (threshold 4), consider running reallocate.
Значение 12, больше чем threshold 4, говорит о том, что на вольюме необходимо запустить реалокацию. Значение hotspot 5 говорит о том, что горячие блоки находятся на 5-ти дисках, а не на всех дисках агрегата (если не устраняется простой реалокацией, смотри здесь).
Не достаточное свободное пространство и наличие снепшотов могут не дать выполнить реалокацию. На вольюме нужно иметь не мение 5% свободного пространства в активной файловой системе и 10% свободного пространства в SnapReserve.
В случае добавления новых дисков имеет смысл разбалансировать не только данные но и пусте блоки.
Запустим физическую реалокацию данных вольюма для оптимизации производительности на 7-Mode
aggr options aggr0 free_space_realloc on reallocate start -f -p /vol/<volume>
На Clustered ONTAP. Для Clustered ONTAP команда reallocate не вернёт вывод, его нужно запросить:
storage aggregate modify -free-space-realloc on reallocate start -vserver <vserver> -path /vol/<volume> -force true -threshold 3 -space-optimized true event log show -messagename wafl.reallocate* -severity *
Равномерно распределённая нагрузка по дискам после реалокации: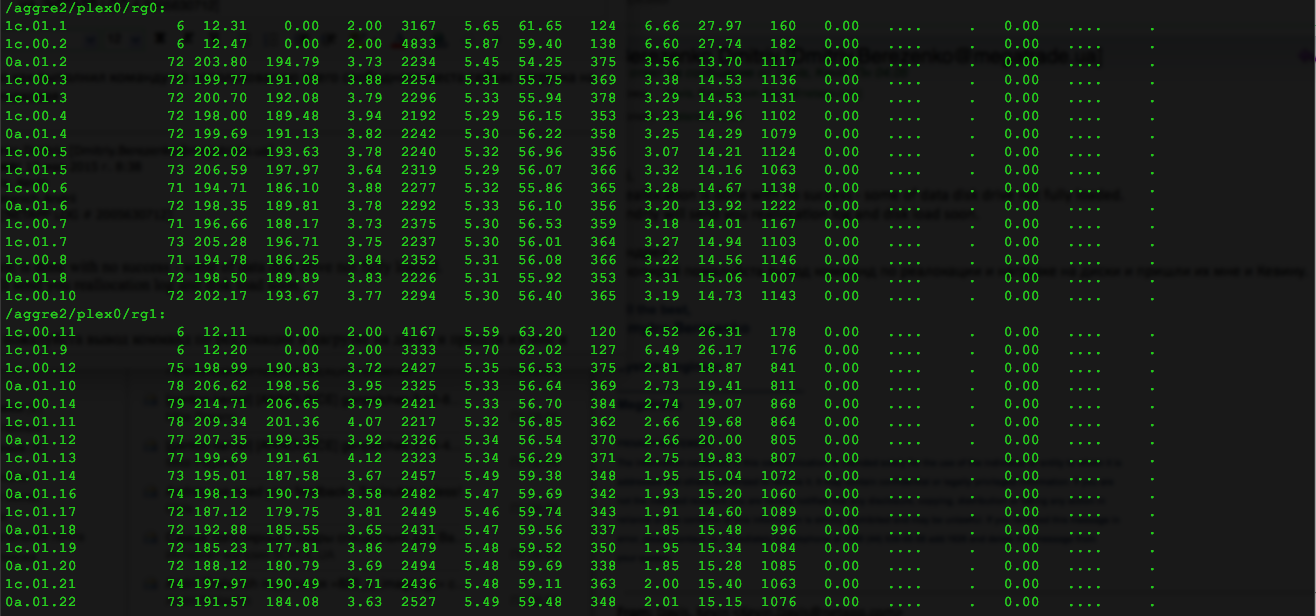
Проверка дисков на хранилище
Во время теста очень важно удостовериться в том, что один из дисков не умер и/или не тормозит весь агрегат.
statit для 7-Mode
#начинаем сбор statit -b #спустя минут двадцать заканчиваем сбор statit -e disk ut% xfers ureads--chain-usecs writes--chain-usecs cpreads-chain-usecs greads--chain-usecs gwrites-chain-usecs /aggr0/plex0/rg0: 01.0a.16 9 3.71 0.47 1.00 90842 2.94 15.14 1052 0.30 7.17 442 0.00 .... . 0.00 .... . 01.0b.17 11 3.86 0.47 1.00 126105 3.14 14.31 1170 0.25 2.20 1045 0.00 .... . 0.00 .... . 01.0a.18 35 35.52 33.62 1.24 14841 1.63 26.23 965 0.27 15.09 392 0.00 .... . 0.00 .... . 01.0b.25 78 35.15 33.47 1.13 64924 1.48 28.77 2195 0.20 16.75 1493 0.00 .... . 0.00 .... . 01.0a.24 34 33.96 32.26 1.13 17318 1.51 28.21 1007 0.20 17.00 257 0.00 .... . 0.00 .... . 01.0b.22 36 35.40 33.67 1.15 16802 1.51 28.25 1003 0.22 15.56 721 0.00 .... . 0.00 .... . 01.0a.21 35 34.98 33.27 1.16 17126 1.48 28.75 950 0.22 14.78 820 0.00 .... . 0.00 .... . 01.0b.28 77 34.93 33.02 1.13 66383 1.56 27.40 3447 0.35 10.21 8392 0.00 .... . 0.00 .... . 01.0a.23 32 33.02 31.12 1.17 14775 1.53 27.65 1018 0.37 10.80 1321 0.00 .... . 0.00 .... . 01.0b.20 35 34.41 32.38 1.29 15053 1.66 25.73 976 0.37 9.67 1076 0.00 .... . 0.00 .... . 01.0a.19 34 34.80 33.07 1.20 15961 1.51 28.30 930 0.22 15.00 681 0.00 .... . 0.00 .... . 01.0b.26 76 34.41 32.41 1.05 68532 1.63 26.09 3482 0.37 11.93 7698 0.00 .... . 0.00 .... . 01.0a.27 36 35.15 33.32 1.26 15327 1.56 27.35 1018 0.27 12.82 1170 0.00 .... . 0.00 .... . /aggr0/plex0/rg1: 02.0b.29 5 2.00 0.00 .... . 1.63 27.89 1023 0.37 9.80 231 0.00 .... . 0.00 .... . 02.0a.33 5 2.03 0.00 .... . 1.68 27.13 1095 0.35 8.21 330 0.00 .... . 0.00 .... . 02.0b.34 32 34.46 32.75 1.19 14272 1.51 29.87 927 0.20 16.63 617 0.00 .... . 0.00 .... . 02.0a.35 31 32.85 31.00 1.15 14457 1.51 29.87 895 0.35 12.36 1075 0.00 .... . 0.00 .... . 02.0b.41 32 33.10 31.44 1.20 13396 1.51 29.87 930 0.15 21.83 618 0.00 .... . 0.00 .... . 02.0a.43 31 32.73 30.92 1.19 13827 1.58 28.47 1005 0.22 15.22 920 0.00 .... . 0.00 .... . 02.0b.44 31 32.65 31.02 1.11 14986 1.51 29.85 913 0.12 26.00 408 0.00 .... . 0.00 .... . 02.0a.32 31 32.68 30.87 1.13 14437 1.58 28.48 956 0.22 15.78 627 0.00 .... . 0.00 .... . 02.0b.36 32 34.70 32.95 1.13 14680 1.56 28.94 975 0.20 16.75 582 0.00 .... . 0.00 .... . 02.0a.37 31 32.43 30.70 1.21 13836 1.51 29.89 929 0.22 14.78 797 0.00 .... . 0.00 .... .
statit/statistics для Cluster-Mode
или при помощи команды statistics :
#проверим наличие отказавших дисков storage disk show -broken #начинаем сбор run -node * -command "priv set diag; statit -b" #спустя минут двадцать заканчиваем сбор run -node * -command "priv set diag; statit -e" disk ut% xfers ureads--chain-usecs writes--chain-usecs cpreads-chain-usecs greads--chain-usecs gwrites-chain-usecs /aggr0/plex0/rg0: 01.0a.16 9 3.71 0.47 1.00 90842 2.94 15.14 1052 0.30 7.17 442 0.00 .... . 0.00 .... . 01.0b.17 11 3.86 0.47 1.00 126105 3.14 14.31 1170 0.25 2.20 1045 0.00 .... . 0.00 .... . 01.0a.18 35 35.52 33.62 1.24 14841 1.63 26.23 965 0.27 15.09 392 0.00 .... . 0.00 .... . 01.0b.25 78 35.15 33.47 1.13 64924 1.48 28.77 2195 0.20 16.75 1493 0.00 .... . 0.00 .... . 01.0a.24 34 33.96 32.26 1.13 17318 1.51 28.21 1007 0.20 17.00 257 0.00 .... . 0.00 .... . 01.0b.22 36 35.40 33.67 1.15 16802 1.51 28.25 1003 0.22 15.56 721 0.00 .... . 0.00 .... . 01.0a.21 35 34.98 33.27 1.16 17126 1.48 28.75 950 0.22 14.78 820 0.00 .... . 0.00 .... . 01.0b.28 77 34.93 33.02 1.13 66383 1.56 27.40 3447 0.35 10.21 8392 0.00 .... . 0.00 .... . 01.0a.23 32 33.02 31.12 1.17 14775 1.53 27.65 1018 0.37 10.80 1321 0.00 .... . 0.00 .... . 01.0b.20 35 34.41 32.38 1.29 15053 1.66 25.73 976 0.37 9.67 1076 0.00 .... . 0.00 .... . 01.0a.19 34 34.80 33.07 1.20 15961 1.51 28.30 930 0.22 15.00 681 0.00 .... . 0.00 .... . 01.0b.26 76 34.41 32.41 1.05 68532 1.63 26.09 3482 0.37 11.93 7698 0.00 .... . 0.00 .... . 01.0a.27 36 35.15 33.32 1.26 15327 1.56 27.35 1018 0.27 12.82 1170 0.00 .... . 0.00 .... . /aggr0/plex0/rg1: 02.0b.29 5 2.00 0.00 .... . 1.63 27.89 1023 0.37 9.80 231 0.00 .... . 0.00 .... . 02.0a.33 5 2.03 0.00 .... . 1.68 27.13 1095 0.35 8.21 330 0.00 .... . 0.00 .... . 02.0b.34 32 34.46 32.75 1.19 14272 1.51 29.87 927 0.20 16.63 617 0.00 .... . 0.00 .... . 02.0a.35 31 32.85 31.00 1.15 14457 1.51 29.87 895 0.35 12.36 1075 0.00 .... . 0.00 .... . 02.0b.41 32 33.10 31.44 1.20 13396 1.51 29.87 930 0.15 21.83 618 0.00 .... . 0.00 .... . 02.0a.43 31 32.73 30.92 1.19 13827 1.58 28.47 1005 0.22 15.22 920 0.00 .... . 0.00 .... . 02.0b.44 31 32.65 31.02 1.11 14986 1.51 29.85 913 0.12 26.00 408 0.00 .... . 0.00 .... . 02.0a.32 31 32.68 30.87 1.13 14437 1.58 28.48 956 0.22 15.78 627 0.00 .... . 0.00 .... . 02.0b.36 32 34.70 32.95 1.13 14680 1.56 28.94 975 0.20 16.75 582 0.00 .... . 0.00 .... . 02.0a.37 31 32.43 30.70 1.21 13836 1.51 29.89 929 0.22 14.78 797 0.00 .... . 0.00 .... .
или при помощи команды statistics :
set -privilege advanced ; statistics disk show -interval 5 -iterations 1 cl03 : 3/5/2015 10:30:29 Busy *Total Read Write Read Write Latency Disk Node (%) Ops Ops Ops (Bps) (Bps) (us) ----- --------------- ---- ------ ---- ----- ----- ----- ------- 1.0.4 Multiple_Values 1 5 2 3 31744 69632 6000 1.0.2 Multiple_Values 1 4 2 2 31744 65536 5263 1.0.8 Multiple_Values 0 2 1 1 62464 43008 5363 1.0.1 cl03-02 0 2 0 1 12288 7168 5500 1.0.0 cl03-02 0 2 0 1 12288 7168 5000 1.0.12 Multiple_Values 0 1 0 0 59392 53248 5000 1.0.10 Multiple_Values 0 1 0 0 60416 56320 6000 1.0.7 cl03-02 0 0 0 0 10240 0 0 1.0.6 cl03-02 0 0 0 0 11264 0 7500 1.0.5 cl03-02 0 0 0 0 10240 0 4000 1.0.3 cl03-02 0 0 0 0 10240 0 13000 1.0.17 cl03-02 0 0 0 0 10240 0 1000 1.0.16 cl03-01 0 0 0 0 10240 0 0 1.0.15 cl03-01 0 0 0 0 0 0 - 1.0.14 cl03-02 0 0 0 0 10240 0 0 1.0.11 cl03-02 0 0 0 0 10240 0 0
Мы видим, что aggregate наш состоит из двух RAID-групп — rg0 и rg1, в конфигурации RAID-DP 11d+2p. Диски 0c.16, 1b.17 и 0c.29, 0c.33 – диски parity, остальные – Data.
Когда дата-диски не равномерно нагружены
В выводе комманды statit/statistics, ищем странности. Величина использования дисков 0с.25, 26 и 28, по сравнению с остальными data-дисками (для дисков parity действуют другие правила, на них не смотрим). При средней нагрузке ut% по дискам группы 35%, на этих дисках загрузка почти вдвое выше, около 75% плюс на них высокие значения latency (ureads usecs и writes usecs), по сравнению с другими дисками, которая достигает 60-70 миллисекунд, против 14-17 для остальных. В нормально же работающем aggregate нагрузка должна равномерно распределяться по всем data-дискам в aggregate. Нужно выранять нагрузку на агрегате реалокацией или заменить такие диски.
Для 7-Mode:
disk fail 0с.25
Для C-Mode:
storage disk fail –disk 0с.25
Теперь проверяем повреждённые диски 7-Mode
Подсвечиваем LED-индикатор диска для его легкого обнаружения и последующего извлечения
Смотрим диаграмму в какой полке и позиции установлен диск.
aggr status -f sysconfig -d sysconfig -a disk show -v
Подсвечиваем LED-индикатор диска для его легкого обнаружения и последующего извлечения
led_on disk_name
Смотрим диаграмму в какой полке и позиции установлен диск.
sasadmin shelf
Теперь проверяем повреждённые диски Cluster-Mode
Подсвечиваем LED-индикатор диска для его легкого обнаружения и последующего извлечения
Смотрим диаграмму в какой полке и позиции установлен диск.
storage aggregate show -state failed run -node * -command sysconfig -d run -node * -command sysconfig -a disk show -pool * -fields disk,usable-size,shelf,type,container-type,container-name,owner,pool disk show -prefailed true disk show -broken
Подсвечиваем LED-индикатор диска для его легкого обнаружения и последующего извлечения
storage disk set-led -disk disk_name 2
Смотрим диаграмму в какой полке и позиции установлен диск.
run -node * -command sasadmin shelf
Нагрузка на CPU
Удостоверимся, что нет затыка на CPU или в кеше и проверим нагрузку на протоколы:
sysstat для 7-Mode
Подробнее про sysstat
7M> sysstat -x 1 CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk FCP iSCSI FCP kB/s iSCSI kB/s in out read write read write age hit time ty util in out in out 5% 0 726 0 726 2555 1371 2784 24 0 0 1 91% 0% - 89% 0 0 0 0 0 0 4% 0 755 0 755 1541 1136 3312 0 0 0 1 92% 0% - 89% 0 0 0 0 0 0 6% 0 1329 0 1334 3379 2069 3836 8 0 0 1 90% 0% - 79% 0 5 0 0 74 0 4% 0 637 0 637 2804 2179 3160 24 0 0 1 92% 0% - 86% 0 0 0 0 0 0 4% 0 587 0 587 2386 1241 2532 8 0 0 1 94% 0% - 98% 0 0 0 0 0 0 8% 0 381 0 381 2374 1063 5224 15120 0 0 6s 96% 45% Tf 78% 0 0 0 0 0 0 7% 0 473 0 473 2902 840 3020 20612 0 0 6s 98% 100% :f 100% 0 0 0 0 0 0 5% 0 1131 0 1133 3542 1371 2612 400 0 0 6s 92% 35% : 70% 0 2 0 0 20 0 7% 0 1746 0 1746 3874 1675 3572 0 0 0 6s 92% 0% - 79% 0 0 0 0 0 0 8% 0 2056 0 2056 5754 3006 4044 24 0 0 6s 95% 0% - 83% 0 0 0 0 0 0 6% 0 1527 0 1527 2912 2162 2360 0 0 0 6s 94% 0% - 86% 0 0 0 0 0 0 6% 0 1247 0 1265 3740 1341 2672 0 0 0 6s 94% 0% - 96% 0 18 0 0 98 0 6% 0 1215 0 1220 3250 1270 2676 32 0 0 6s 92% 0% - 86% 0 5 0 0 61 0 4% 0 850 0 850 1991 915 2260 0 0 0 6s 90% 0% - 75% 0 0 0 0 0 0 7% 0 1740 0 1740 3041 1246 2804 0 0 0 13s 92% 0% - 80% 0 0 0 0 0 0 3% 0 522 0 531 1726 1042 2340 24 0 0 16s 88% 0% - 69% 7 0 0 12 0 0 6% 0 783 0 804 5401 1456 3424 0 0 0 1 92% 0% - 89% 17 0 0 21 0 0 10% 0 478 0 503 4229 919 5840 13072 0 0 1 95% 65% Tf 98% 12 9 0 17 94 0 9% 0 473 0 487 3290 945 2720 23148 0 0 31s 97% 100% :f 100% 12 0 0 17 0 0 6% 0 602 0 606 3196 729 2380 12576 0 0 31s 97% 89% : 100% 0 0 0 0 0 0 10% 0 1291 0 1291 15950 3017 2680 0 0 0 31s 94% 0% - 100% 0 0 0 0 0 0 9% 0 977 0 977 13452 4553 4736 24 0 0 31s 96% 0% - 92% 0 0 0 0 0 0 6% 0 995 0 995 3923 2210 2356 8 0 0 31s 94% 0% - 85% 0 0 0 0 0 0 4% 0 575 0 583 1849 2948 3056 0 0 0 31s 93% 0% - 96% 0 8 0 0 111 0 5% 0 789 0 789 2316 742 2364 24 0 0 31s 94% 0% - 91% 0 0 0 0 0 0 4% 0 550 0 550 1604 1125 3004 0 0 0 31s 92% 0% - 80% 0 0 0 0 0 0 7% 0 1398 0 1398 2910 1358 2716 0 0 0 31s 94% 0% - 87% 0 0 0 0 0 0
sysstat/statistics для Cluster-Mode
Подробнее про sysstat
Или при помощи комманды
CM::*> system node run -node local -command "priv set diag; sysstat -x 1" CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk FCP iSCSI FCP kB/s iSCSI kB/s in out read write read write age hit time ty util in out in out 5% 0 726 0 726 2555 1371 2784 24 0 0 1 91% 0% - 89% 0 0 0 0 0 0 4% 0 755 0 755 1541 1136 3312 0 0 0 1 92% 0% - 89% 0 0 0 0 0 0 6% 0 1329 0 1334 3379 2069 3836 8 0 0 1 90% 0% - 79% 0 5 0 0 74 0 4% 0 637 0 637 2804 2179 3160 24 0 0 1 92% 0% - 86% 0 0 0 0 0 0 4% 0 587 0 587 2386 1241 2532 8 0 0 1 94% 0% - 98% 0 0 0 0 0 0 8% 0 381 0 381 2374 1063 5224 15120 0 0 6s 96% 45% Tf 78% 0 0 0 0 0 0 7% 0 473 0 473 2902 840 3020 20612 0 0 6s 98% 100% :f 100% 0 0 0 0 0 0 5% 0 1131 0 1133 3542 1371 2612 400 0 0 6s 92% 35% : 70% 0 2 0 0 20 0 7% 0 1746 0 1746 3874 1675 3572 0 0 0 6s 92% 0% - 79% 0 0 0 0 0 0 8% 0 2056 0 2056 5754 3006 4044 24 0 0 6s 95% 0% - 83% 0 0 0 0 0 0 6% 0 1527 0 1527 2912 2162 2360 0 0 0 6s 94% 0% - 86% 0 0 0 0 0 0 6% 0 1247 0 1265 3740 1341 2672 0 0 0 6s 94% 0% - 96% 0 18 0 0 98 0 6% 0 1215 0 1220 3250 1270 2676 32 0 0 6s 92% 0% - 86% 0 5 0 0 61 0 4% 0 850 0 850 1991 915 2260 0 0 0 6s 90% 0% - 75% 0 0 0 0 0 0 7% 0 1740 0 1740 3041 1246 2804 0 0 0 13s 92% 0% - 80% 0 0 0 0 0 0 3% 0 522 0 531 1726 1042 2340 24 0 0 16s 88% 0% - 69% 7 0 0 12 0 0 6% 0 783 0 804 5401 1456 3424 0 0 0 1 92% 0% - 89% 17 0 0 21 0 0 10% 0 478 0 503 4229 919 5840 13072 0 0 1 95% 65% Tf 98% 12 9 0 17 94 0 9% 0 473 0 487 3290 945 2720 23148 0 0 31s 97% 100% :f 100% 12 0 0 17 0 0 6% 0 602 0 606 3196 729 2380 12576 0 0 31s 97% 89% : 100% 0 0 0 0 0 0 10% 0 1291 0 1291 15950 3017 2680 0 0 0 31s 94% 0% - 100% 0 0 0 0 0 0 9% 0 977 0 977 13452 4553 4736 24 0 0 31s 96% 0% - 92% 0 0 0 0 0 0 6% 0 995 0 995 3923 2210 2356 8 0 0 31s 94% 0% - 85% 0 0 0 0 0 0 4% 0 575 0 583 1849 2948 3056 0 0 0 31s 93% 0% - 96% 0 8 0 0 111 0 5% 0 789 0 789 2316 742 2364 24 0 0 31s 94% 0% - 91% 0 0 0 0 0 0 4% 0 550 0 550 1604 1125 3004 0 0 0 31s 92% 0% - 80% 0 0 0 0 0 0 7% 0 1398 0 1398 2910 1358 2716 0 0 0 31s 94% 0% - 87% 0 0 0 0 0 0
Или при помощи комманды
CM::*> set -privilege advanced ; statistics show-periodic cpu cpu total fcache total total data data data cluster cluster cluster disk disk pkts pkts avg busy ops nfs-ops cifs-ops ops recv sent busy recv sent busy recv sent read write recv sent ---- ---- -------- -------- -------- -------- -------- -------- ---- -------- -------- ------- -------- -------- -------- -------- -------- -------- 27% 88% 4 4 0 0 46.2KB 13.7KB 0% 35.4KB 2.36KB 0% 10.8KB 10.9KB 962KB 31.7KB 62 55 12% 62% 3 3 0 0 12.7KB 12.9KB 0% 207B 268B 0% 12.3KB 12.5KB 2.40MB 7.73MB 51 47 11% 41% 27 27 0 0 119KB 39.2KB 0% 104KB 25.6KB 0% 13.8KB 13.5KB 1.65MB 0B 155 116 cl03: cluster.cluster: 3/5/2015 10:16:17 cpu cpu total fcache total total data data data cluster cluster cluster disk disk pkts pkts avg busy ops nfs-ops cifs-ops ops recv sent busy recv sent busy recv sent read write recv sent ---- ---- -------- -------- -------- -------- -------- -------- ---- -------- -------- ------- -------- -------- -------- -------- -------- -------- Minimums: 11% 30% 1 1 0 0 12.7KB 12.9KB 0% 148B 245B 0% 10.8KB 10.9KB 947KB 0B 51 47 Averages for 12 samples: 20% 72% 7 7 0 0 58.5KB 20.4KB 0% 42.6KB 4.52KB 0% 15.7KB 15.7KB 1.57MB 4.06MB 105 90 Maximums: 30% 94% 27 27 0 0 145KB 39.2KB 0% 121KB 25.6KB 0% 23.9KB 24.4KB 3.06MB 12.4MB 198 177
Подробнее про оптимизацию и проверку дисковой подсистемы здесь.
Отключение снепшотов на агрегатах
Если не оговорено иначе в лучших практиках, отключайте снепшоты на агрегатах, так как они занимают лишнее пространство и необходимы в очень редких конфигурациях, таких как SyncMirror (MetroCluster) и некоторых других.
snap shced -A aggr1 0 0 0 snap delete -A aggr1 snap list -A aggr1 snap reserve -A aggr1 0
Для Clustered ONTAP перед каждой командой добавьте
system node run -node * -command
Кэш второго уровня VSC: FlashCache/FlashPool
Virtual Storage Tiering (VST) — кеширование данных второго уровня. FlashCache — плата PCIe, кеширующая все операции чтения на контроллере. FlashPool — гибридный агрегат состоящий из вращающихся дисков (SAS/SATA HDD) и дисков SSD выделенных в RAID группу(ы), кеширует как операции чтения, так и операции перезаписи (Операции записи всегда кешируются в системном кэше контроллера, т.е. кеше первого уровня). Перед тем как покупать дорогостоющий акселератор стоит проверить, что он нужен и какой размер кеша будет наиболее оптимален, для этого есть следующие механизмы:
- Для FlashCache это Predictive Cache Statistics (PCS)
- Для FlashPool это Advanced Workload Analyzer (AWA)
Совместимость
Широко применяйте матрицу совместимости в вашей практике для уменьшения потенциальных проблем в инфрастурктуре ЦОД.
Уверен что по мере получения новой информации мне будет что добавить в эту статью, так что заглядывайте сюда изредка за адептами.
Замечания по ошибкам в тексте и предложения прошу направлять в ЛС.
