Приветствую, Хабрахабр!
В этой статье я постараюсь приоткрыть завесу над интересной технологией из области управления бизнес-процессами ( BPM). Интеллектуальный анализ процессов ( Process Mining) фокусируется на обнаружении, анализе и оптимизации бизнес-процессов на основе данных из журналов событий (англ. event logs), представляя недостающее звено между классическим анализом бизнес-процессов с использованием их моделей и интеллектуальным анализом данных ( Data Mining).
BPM). Интеллектуальный анализ процессов ( Process Mining) фокусируется на обнаружении, анализе и оптимизации бизнес-процессов на основе данных из журналов событий (англ. event logs), представляя недостающее звено между классическим анализом бизнес-процессов с использованием их моделей и интеллектуальным анализом данных ( Data Mining).

Рисунок 1. Позиционирование Process Mining.
Далее мы разовьем тему позиционирования, коснемся вариантов использования, поговорим об исходных данных и рассмотрим различные типы интеллектуального анализа процессов.
Интеллектуальный анализ процессов использует данные для анализа бизнес-процессов, пренебрегая анализом самих данных. Другими словами, Process Mining, в отличие от Data Mining, не интересуется низкоуровневыми закономерностями в исходных данных и не пытается принимать решения на их основе, но ставит задачей оптимизацию бизнес-процессов (в особенности сквозных), вытекающих из исходных данных.
Вопросы, на которые отвечает Process Mining, можно разбить на две группы (см. стрелки влево и вправо на рисунке 1):
В таблице ниже указаны некоторые варианты использования интеллектуального анализа процессов, а также связанные с ними вопросы, разбитые по вышеуказанным группам.
Часто отправной точкой для интеллектуального анализа процессов являются данные из журналов событий. Рассмотрим подходящий нам журнал. Каждая строка в таком журнале соответствует отдельному событию. В свою очередь, каждое событие несет в себе информацию о породившем его случае, выполненной в его рамках деятельности и времени его регистрации. Подобные журналы событий можно рассматривать как совокупности случаев, а отдельные случаи — как последовательности ссылающихся на них событий.
Заручившись представленными выше предположениями, выделим основные атрибуты событий в журналах:
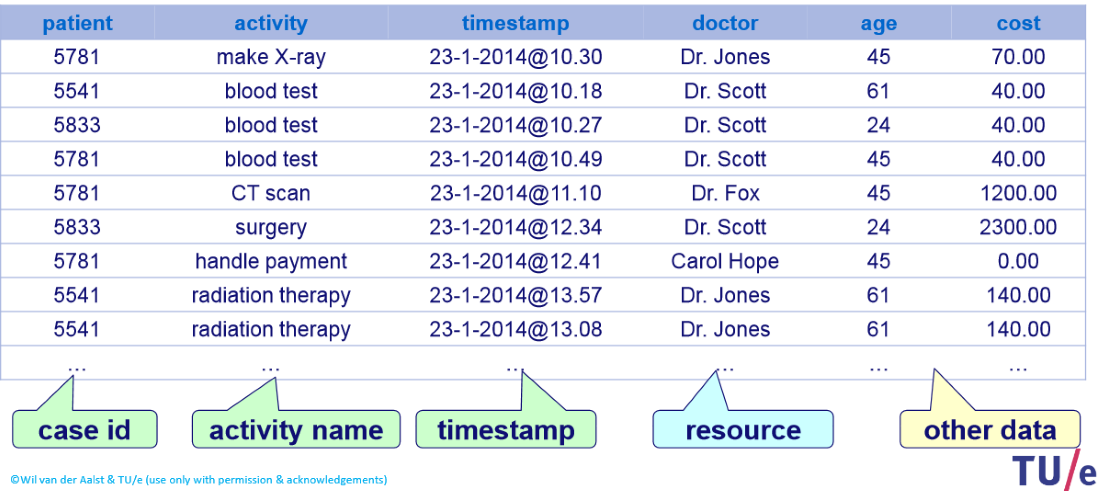
Рисунок 2. Журнал событий — данные о приеме пациентов.
Конечно, выбор указанных выше атрибутов зависит от целей анализа. Например (смотрим на рисунок 2), если нас интересует процесс, описывающий порядок получения пациентами надлежащего лечения, то в качестве идентификаторов случаев используем пациентов (столбец patient), деятельностями называем получаемые пациентами процедуры (столбец activity), а ресурсами обозначаем выполняющих данные процедуры врачей (столбец doctor). Если же нам интересен другой процесс, описывающий порядок выполнения врачами процедур, то идентификаторами событий будут сами врачи (столбец doctor), деятельностями — выполняемые данными врачами процедуры (столбец activity), а ресурсами — внимание, также станут врачи (столбец doctor).
Интеллектуальный анализ процессов фокусируется на отношениях между моделями бизнес-процессов и данными о событиях. Выделяют три типа подобных отношений, которые и определяют типы анализа.
Начинаем с готовой модели процесса. Далее симулируем различные сценарии выполнения процесса (согласно модели) для наполнения журнала событий данными о регистрируемых при симуляции событиях.

Рисунок 3. Пример Play-Out.
На рисунке 3 показан пример симуляции по готовой модели рабочего процесса (англ. workflow). Модель процесса выполнена с использованием упрощенной нотации BPMN. Красным показаны шаги на одном из возможных путей выполнения процесса, а журнал внизу наполнен данными о событиях в порядке их регистрации при прохождении данного пути.
Play-Out применяется для проверки разработанных моделей процессов на соответствие ожидаемым данным (последовательностям событий) от их выполнения.
Начинаем с готовых данных в журнале событий. Далее получаем модель процесса, обеспечивающего выполнение представленных в журнале последовательностей событий (обучаем модель процесса на основе данных).

Рисунок 4. Пример Play-In.
На рисунке 4 показан пример получения модели процесса по готовым последовательностям событий (указаны красным). Если приглядеться, то можно заметить, что все последовательности событий на рисунке начинаются с шага a и заканчиваются шагом g или h. Результирующая модель процесса в точности соответствует подмеченным особенностям, что иллюстрирует основной принцип ее вывода из данных.
Play-In полезен при необходимости формального описания процессов, генерирующих известные данные.
Одновременно используем модель процесса (возможно, полученную при помощи Play-In) и данные в журнале событий (возможно, полученные при помощи Play-Out) для воспроизведения реальных последовательностей событий согласно модели.
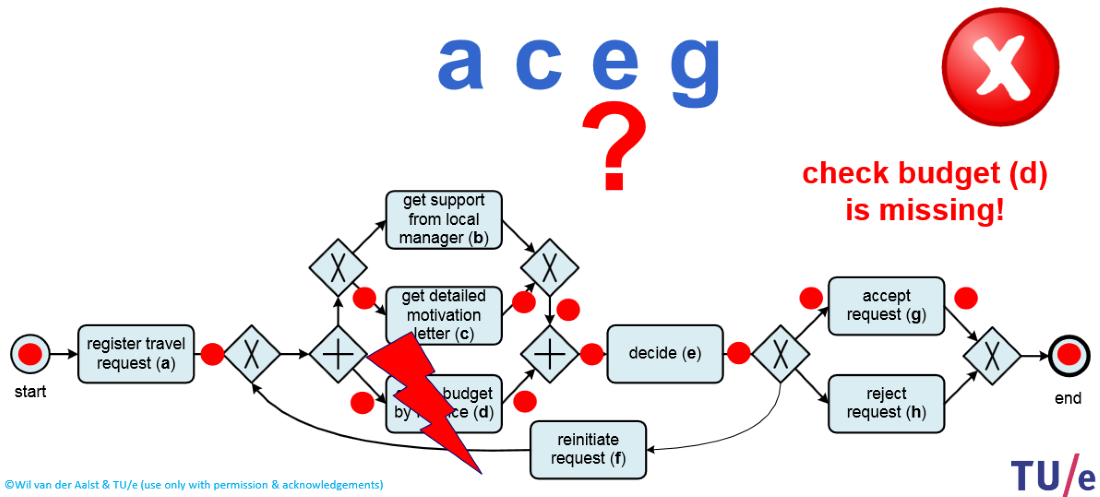
Рисунок 5. Пример Replay.
На рисунке 5 представлен пример попытки воспроизведения имеющейся последовательности событий согласно готовой модели процесса. Попытка закончилась неудачей по причине того, что модель требует прохождения шага d прежде, чем будет открыт переход к шагу e (подробнее разобраться с причинами неудачи поможет изучение шлюзов (англ. gateways) нотации BPMN).
Replay позволяет находить отклонения моделей от реальных процессов, но также может использоваться и для анализа производительности процессов — стоит при воспроизведении начать отмечать время регистрации событий, как станут видны места задержек и скоростные участки на путях выполнения процессов.
Для тех, кто желает самостоятельно попробовать применить полученные знания на практике, спешу сообщить об инструменте, который позволит воплотить ваши смелые начинания в жизнь. ProM — это свободный фреймворк, включающий все необходимое для выполнения интеллектуального анализа процессов. Стабильная версия ProM доступна для скачивания под Windows и под другие ОС. Общая информация (включая примеры исходных данных, руководства и упражнения) расположена на сайте ProM Tools.
Существующий разрыв между анализом моделей бизнес-процессов и данных затрудняет поиск решений множества интересных и сложных задач современного мира, где значение данных давно сравнивается со значением нефти (см. Data is the new oil). Process Mining призван ликвидировать данный разрыв, поднимая анализ бизнес-процессов на новый уровень.
Благодарю за внимание и категорически рекомендую продолжить изучение темы самостоятельно! Отличным началом станет вышеупомянутый онлайн курс Process Mining: Data Science in Action.
Process Mining: Data Science in Action.
В этой статье я постараюсь приоткрыть завесу над интересной технологией из области управления бизнес-процессами (
BPM). Интеллектуальный анализ процессов ( Process Mining) фокусируется на обнаружении, анализе и оптимизации бизнес-процессов на основе данных из журналов событий (англ. event logs), представляя недостающее звено между классическим анализом бизнес-процессов с использованием их моделей и интеллектуальным анализом данных ( Data Mining).Disclaimer
Статья подготовлена на основе материалов онлайн курса Process Mining: Data Science in Action, являющихся собственностью Технического университета Эйндховена. Использование материалов статьи возможно только с разрешения авторов курса и с указанием ссылок на источник.
Рисунок 1. Позиционирование Process Mining.
Далее мы разовьем тему позиционирования, коснемся вариантов использования, поговорим об исходных данных и рассмотрим различные типы интеллектуального анализа процессов.
Позиционирование
Интеллектуальный анализ процессов использует данные для анализа бизнес-процессов, пренебрегая анализом самих данных. Другими словами, Process Mining, в отличие от Data Mining, не интересуется низкоуровневыми закономерностями в исходных данных и не пытается принимать решения на их основе, но ставит задачей оптимизацию бизнес-процессов (в особенности сквозных), вытекающих из исходных данных.
Вопросы, на которые отвечает Process Mining, можно разбить на две группы (см. стрелки влево и вправо на рисунке 1):
- Вопросы производительности (эффективности) процессов.
- Вопросы согласованности процессов.
Варианты использования
В таблице ниже указаны некоторые варианты использования интеллектуального анализа процессов, а также связанные с ними вопросы, разбитые по вышеуказанным группам.
| № | Вариант использования | Вопросы | Группа вопросов |
|---|---|---|---|
| 1 | Обнаружение реальных бизнес-процессов | Как выглядит процесс, который на самом деле (а не на словах и не в теории) описывает текущую деятельность? | Согласованность |
| 2 | Поиск узких мест (англ. bottlenecks) в бизнес-процессах | Где в процессе расположены места, ограничивающие общую скорость его выполнения? Что вызывает появление подобных мест? | Производительность |
| 3 | Выявление отклонений в бизнес-процессах | Где реальный процесс отклоняется от ожидаемого (идеального) процесса? Почему происходят подобные отклонения? | Согласованность |
| 4 | Поиск быстрых/коротких путей выполнения бизнес-процессов | Как выполнить процесс быстрее всего? Как выполнить процесс за наименьшее количество шагов? | Производительность |
| 5 | Прогнозирование проблем в бизнес-процессах | Можно ли предсказать появление задержек/отклонений/рисков/… при выполнении процесса? | Производительность / Согласованность |
Исходные данные
Часто отправной точкой для интеллектуального анализа процессов являются данные из журналов событий. Рассмотрим подходящий нам журнал. Каждая строка в таком журнале соответствует отдельному событию. В свою очередь, каждое событие несет в себе информацию о породившем его случае, выполненной в его рамках деятельности и времени его регистрации. Подобные журналы событий можно рассматривать как совокупности случаев, а отдельные случаи — как последовательности ссылающихся на них событий.
Заручившись представленными выше предположениями, выделим основные атрибуты событий в журналах:
- Идентификатор случая (case id): хранит случаи (объекты), для которых выстраиваются последовательности событий журнала.
- Деятельность (activity name): хранит действия, выполняемые в рамках событий журнала.
- Отметка времени (timestamp): хранит дату и время регистрации событий журнала.
- Ресурс (resource): хранит основных действующих лиц событий журнала (тех, кто выполняет действия в рамках событий журнала).
- Прочее (other data): сюда попадает вся оставшаяся в журнале (не интересная нам) информация.
Рисунок 2. Журнал событий — данные о приеме пациентов.
Конечно, выбор указанных выше атрибутов зависит от целей анализа. Например (смотрим на рисунок 2), если нас интересует процесс, описывающий порядок получения пациентами надлежащего лечения, то в качестве идентификаторов случаев используем пациентов (столбец patient), деятельностями называем получаемые пациентами процедуры (столбец activity), а ресурсами обозначаем выполняющих данные процедуры врачей (столбец doctor). Если же нам интересен другой процесс, описывающий порядок выполнения врачами процедур, то идентификаторами событий будут сами врачи (столбец doctor), деятельностями — выполняемые данными врачами процедуры (столбец activity), а ресурсами — внимание, также станут врачи (столбец doctor).
Типы Process Mining
Интеллектуальный анализ процессов фокусируется на отношениях между моделями бизнес-процессов и данными о событиях. Выделяют три типа подобных отношений, которые и определяют типы анализа.
Play-Out
Начинаем с готовой модели процесса. Далее симулируем различные сценарии выполнения процесса (согласно модели) для наполнения журнала событий данными о регистрируемых при симуляции событиях.
Рисунок 3. Пример Play-Out.
На рисунке 3 показан пример симуляции по готовой модели рабочего процесса (англ. workflow). Модель процесса выполнена с использованием упрощенной нотации
BPMN. Красным показаны шаги на одном из возможных путей выполнения процесса, а журнал внизу наполнен данными о событиях в порядке их регистрации при прохождении данного пути.Play-Out применяется для проверки разработанных моделей процессов на соответствие ожидаемым данным (последовательностям событий) от их выполнения.
Play-In
Начинаем с готовых данных в журнале событий. Далее получаем модель процесса, обеспечивающего выполнение представленных в журнале последовательностей событий (обучаем модель процесса на основе данных).
Рисунок 4. Пример Play-In.
На рисунке 4 показан пример получения модели процесса по готовым последовательностям событий (указаны красным). Если приглядеться, то можно заметить, что все последовательности событий на рисунке начинаются с шага a и заканчиваются шагом g или h. Результирующая модель процесса в точности соответствует подмеченным особенностям, что иллюстрирует основной принцип ее вывода из данных.
Play-In полезен при необходимости формального описания процессов, генерирующих известные данные.
Replay
Одновременно используем модель процесса (возможно, полученную при помощи Play-In) и данные в журнале событий (возможно, полученные при помощи Play-Out) для воспроизведения реальных последовательностей событий согласно модели.
Рисунок 5. Пример Replay.
На рисунке 5 представлен пример попытки воспроизведения имеющейся последовательности событий согласно готовой модели процесса. Попытка закончилась неудачей по причине того, что модель требует прохождения шага d прежде, чем будет открыт переход к шагу e (подробнее разобраться с причинами неудачи поможет изучение шлюзов (англ. gateways) нотации
BPMN).Replay позволяет находить отклонения моделей от реальных процессов, но также может использоваться и для анализа производительности процессов — стоит при воспроизведении начать отмечать время регистрации событий, как станут видны места задержек и скоростные участки на путях выполнения процессов.
Дополнительно
Для тех, кто желает самостоятельно попробовать применить полученные знания на практике, спешу сообщить об инструменте, который позволит воплотить ваши смелые начинания в жизнь. ProM — это свободный фреймворк, включающий все необходимое для выполнения интеллектуального анализа процессов. Стабильная версия ProM доступна для скачивания под Windows и под другие ОС. Общая информация (включая примеры исходных данных, руководства и упражнения) расположена на сайте ProM Tools.
Заключение
Существующий разрыв между анализом моделей бизнес-процессов и данных затрудняет поиск решений множества интересных и сложных задач современного мира, где значение данных давно сравнивается со значением нефти (см. Data is the new oil). Process Mining призван ликвидировать данный разрыв, поднимая анализ бизнес-процессов на новый уровень.
Благодарю за внимание и категорически рекомендую продолжить изучение темы самостоятельно! Отличным началом станет вышеупомянутый онлайн курс
