— Для чего нужны монады?
— Для того, чтобы отделить чистые вычисления от побочных эффектов.
(из сетевых дискуссий о языке Haskell)
Шерлок Холмс и доктор Ватсон летят на воздушном шаре. Попадают в густой туман и теряют ориентацию. Тут небольшой просвет — и они видят на земле человека.
— Уважаемый, не подскажете ли, где мы находимся?
— В корзине воздушного шара, сэр.
Тут их относит дальше и они опять ничего не видят.
— Это был математик, – говорит Холмс.
— Но почему?
— Его ответ совершенно точен, но при этом абсолютно бесполезен.
(анекдот)
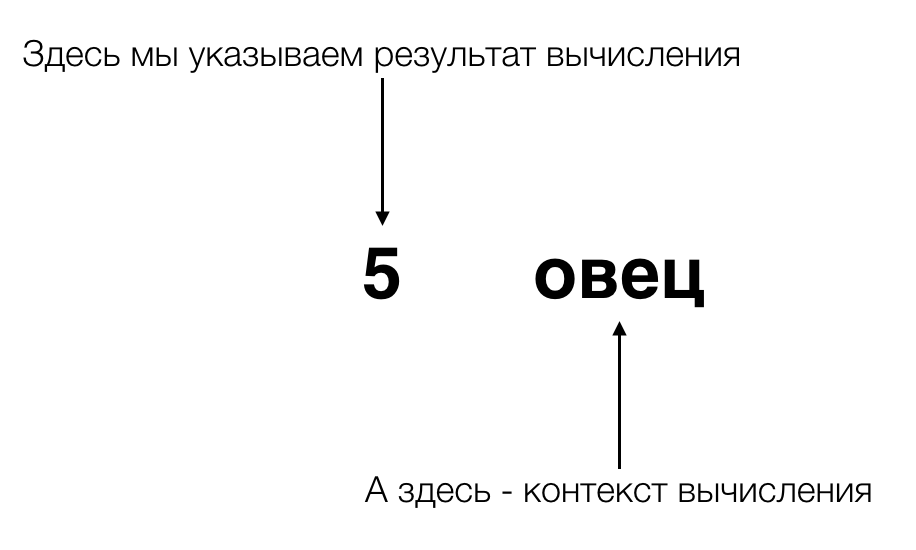
Когда древние египтяне хотели написать, что они насчитали 5 рыб, они рисовали 5 фигурок рыб. Когда они хотели написать, что насчитали 70 людей, они рисовали 70 фигурок людей. Когда они хотели написать, что насчитали в стаде 300 овец, они… — ну, в общем, вы поняли. Так и мучились древние египтяне, пока самый умный и ленивый из них не увидел нечто общее во всех этих записях, и не отделил понятие количества того, что мы подсчитываем, от свойств того, что мы подсчитываем. А потом другой умный ленивый египтянин заменил множество палочек, которыми люди обозначали количество, на значительно меньшее количество знаков, короткой комбинацией которых можно было заменить огромное количество палочек.
То, что сделали эти умные ленивые египтяне, называется абстракцией. Они подметили нечто общее, что свойственно всем записям о количестве чего-либо, и отделили это общее от частных свойств подсчитываемых предметов. Если вы понимаете смысл этой абстракции, которую мы сегодня называем числами, и то, насколько она облегчила жизнь людям, то вам не составит труда понять и абстракции языка Haskell — все эти непонятные, на первый взгляд, функторы, моноиды, аппликативные функторы и монады. Несмотря на их пугающие названия, пришедшие к нам из математической теории категорий, понять их не сложнее, чем абстракцию под названием «числа». Для их понимания совершенно не требуется знать ни теорию категорий, ни даже математику в объёме средней школы (арифметики вполне достаточно). И объяснить их тоже можно, не прибегая к пугающим многих математическим понятиям. А смысл абстракций языка Haskell точно такой же, как и у чисел — они значительно облегчают программистам жизнь (и вы пока даже не представляете, насколько!).
Отличия функциональных и императивных программ
Познаём преимущества чистых функций
Вычисления и «что-то ещё»
Инкапсуляция «чего-то ещё»
Функтор — это не просто, а очень просто!
Аппликативные функторы — это тоже очень просто!
Вы будете смеяться, но монады также просты!
А давайте определим ещё пару монад
Применяем монады
Определяем монаду Writer и знакомимся с моноидами
Моноиды и законы функторов, аппликативных функторов и монад
Классы типов: десятки функций бесплатно!
Ввод-вывод: монада IO
Для того, чтобы понять (и принять) абстракции, людям, обычно, нужно взглянуть на них с нескольких сторон:
Во-первых, им нужно понять, что введение дополнительного уровня сложности в виде предлагаемой абстракции позволяет исключить гораздо больший уровень сложности, с которым они постоянно сталкиваются. Поэтому я опишу то огромное количество проблем, с которыми программисты перестанут сталкиваться, используя чистые функции (не беспокойтесь, ниже я объясню, что это такое) и описываемые абстракции.
Во-вторых, людям нужно понять, каким образом предлагаемая абстракция была реализована, и как эта реализация позволяет использовать её не в каком-то отдельном случае, а в огромном множестве различных ситуаций. Поэтому я опишу вам логику реализации абстракций языка Haskell, и покажу, что они не только применимы, но и дают значительные преимущества в невероятном количестве ситуаций.
И, в третьих, людям нужно понять не только то, как реализованы абстракции, но и как их применять в их повседневной жизни. Поэтому я опишу в статье и это. Тем более, это не просто, а очень просто — даже проще, чем понять, как эти абстракции реализованы (а вы сами увидите, что понять реализацию описываемых абстракций совсем несложно).
Впрочем, введение несколько затянулось, поэтому, пожалуй, начнём. Я лишь добавлю, что в статье будет очень мало кода, поэтому вам совершенно не обязательно быть знакомым с синтаксисом Haskell, чтобы понять и оценить всю красоту и мощь его абстракций.
Disclaimer
Я не являюсь опытным программистом на Haskell. Мне очень нравится этот язык, и в данный момент я всё ещё нахожусь в процессе его познания (это не самый быстрый процесс, поскольку требует не только овладения знаниями, но и перестройки мышления). В последнее время мне несколько раз приходилось рассказывать про функциональное программирование и про Haskell программистам, которые знакомы лишь с императивными языками программирования. В процессе этого я понял, что мне следует поработать над более чётким и структурированным объяснением основных абстракций языка Haskell, которые, обычно, вызывают благоговейный страх у тех, кто с ними не знаком. Данный материал как раз является попыткой такого структурирования. Я буду рад, если вы, читатели, укажете мне как на возможные неточности моего изложения, так и на те моменты, которые показались вам недостаточно понятными.
Отличия функциональных и императивных программ
Если взглянуть на программы, написанные на функциональных и императивных языках, с высоты птичьего полёта, то они ничем не отличаются. И те, и другие программы представляют из себя некоторый чёрный ящик, который принимает исходные данные и выдаёт на выходе другие данные, преобразованные из исходных. Отличия мы увидим, когда захотим заглянуть внутрь чёрных ящиков, чтобы понять, каким именно образом в них происходит преобразование данных.
Заглянув в императивный чёрный ящик, мы увидим, что входящие в него данные присваиваются переменным, а затем эти переменные многократно последовательно изменяются, пока мы не получим нужные нам данные, которые мы и выдаём из чёрного ящика.
В функциональном чёрном ящике эта превращение входящих данных в исходящие происходит путем применения к ним некоторой формулы, в которой конечный результат выражен в терминах зависимости от входящих данных. Помните из школьной программы, от чего зависит средняя скорость движения? Правильно: от пройденного пути и времени, за которое он пройден. Зная исходные данные (путь S и время t), а также формулу вычисления средней скорости (S / t), мы можем вычислить конечный результат — среднюю скорость движения. По такому же принципу зависимости конечного результата от исходных данных вычисляется и конечный результат работы программы, написанной в функциональном стиле. При этом, в отличие от императивного программирования, в процессе вычисления у нас не происходит никакого изменения переменных — ни локальных, ни глобальных.
Вообще-то, в предыдущем абзаце правильнее было бы употребить вместо слова формула слово функция. Я этого не сделал из-за того, что словом функция в императивных языках программирования чаще всего называют совсем не то, что подразумевается под этим термином в математике, физике и в функциональных языках программирования. В императивных языках функцией зачастую называют то, что правильнее называть процедурой — то есть именованной частью программы (подпрограммой), которая используется, чтобы избежать повторения неоднократно встречающихся кусков кода. Чуть позже вы поймете, чем функции в функциональных языках программирования (так называемые чистые функции, или pure functions) отличаются от того, что называют функциями в императивных языках программирования.
Примечание: Деление языков программирования на императивные и функциональные достаточно условно. Можно программировать в функциональном стиле на языках, которые считаются императивными, а в императивном стиле на языках, которые считаются функциональными (вот пример программы, вычисляющей факториал, в императивном стиле на Haskell и ее сравнение с такой же программой на C) — просто это будет неудобно. Поэтому давайте считать императивными языками те, которые поощряют программирование в императивном стиле, а функциональными языками — те, которые поощряют программирование в функциональном стиле.
Познаём преимущества чистых функций
Подавляющую часть времени программист на языке Haskell имеет дело с так называемыми чистыми функциями (все, конечно, зависит от программиста, но мы здесь говорим о том, как должно быть). Вообще-то, «чистыми» эти функции называют для того, чтобы их не путали с тем, что подразумевают под термином «функция» в императивном программировании. На самом деле это самые обычные функции в математическом понимании этого термина. Вот простейший пример такой функции, складывающей три числа:
addThreeNumbers x y z = x + y + z
Объяснение для тех, кто не знаком с синтаксисом Haskell
В той части функции, которая находится слева от знака =, на первом месте всегда идет имя функции, а затем, разделенные пробелами, идут аргументы этой функции. В данном случае имя функции addThreeNumbers, а x, y и z — ее аргументы.
Справа от знака = указывается, каким образом вычисляется результат функции, в терминах ее аргументов.
Справа от знака = указывается, каким образом вычисляется результат функции, в терминах ее аргументов.
Обратите внимание на знак = (равно). В отличие от императивного программирования, он не означает операции присваивания. Знак равно означает, что то, что стоит слева от него — это то же самое, что и выражение справа от него. Совсем как в математике: 6 + 4 — это то же самое, что 10, поэтому мы пишем 6 + 4 = 10. В любом вычислении мы можем вместо десятки подставить выражение (6 + 4), и мы получим тот же самый результат, как если бы мы подставили десятку. То же самое и в Haskell: вместо
addThreeNumbers x y z мы можем подставить выражение x + y + z, и получим тот же самый результат. Компилятор, кстати, так и делает — когда он встречаем имя функции, то подставляет вместо него выражение, определённое в её теле.В чем же заключается «чистота» этой функции?
Результат функции зависит только лишь от ее аргументов. Сколько бы раз мы ни вызвали эту функцию с одними и теми же аргументами, она всегда вернет нам один и тот же результат, потому что функция не обращается к какому-либо внешнему состоянию. Она полностью изолирована от внешнего мира и при вычислениях учитывает только то, что мы явно передали ей в качестве ее аргументов. В отличие от такой науки, как история, результат математических вычислений не зависит от того, коммунисты ли у власти, демократы или Путин. Наша функция родом из математики — она зависит лишь от переданных ей аргументов и ни от чего больше.
Вы можете проверить это сами: сколько бы раз вы ни передавали этой функции в качестве аргументов значения 1, 2 и 4, вы всегда в качестве результата получите 7. Вы даже можете вместо «3» передавать "(2 + 1)", а вместо «4» — "(2 * 2)". Вариантов получить с этими аргументами другой результат попросту нет.
Функция addThreeNumbers называется чистой еще и потому, что она не только не зависит от внешнего состояния, но и не способна его изменять. Она даже не может изменять локальные переменные, переданные ей в качестве аргументов. Все, что она может (и должна) делать — это вычислить результат, исходя из значений переданных ей аргументов. Другими словами, эта функция не обладает побочными эффектами. Что же нам это дает? Почему хаскеллисты так держатся за эту «чистоту» своих функций, презрительно кривясь, глядя на традиционные функции императивных языков программирования, построенных на мутации локальных и глобальных переменных?
Поскольку результат вычисления чистых функций никак не зависит от внешнего состояния и никак не изменяет внешнее состояние, мы можем вычислять такие функции параллельно, не заботясь о гонке данных, которые конкурируют друг с другом за общие ресурсы. Побочные эффекты — погибель параллельных вычислений, а раз наши чистые функции их не имеют, нам не о чем беспокоиться. Мы просто пишем чистые функции, не заботясь ни о порядке вычисления функций, ни о том, как нам распараллелить вычисления. Распараллеливание мы получаем «из коробки», просто потому, что пишем на Haskell.
Кроме того, поскольку вызывая чистую функцию несколько раз с одними и теми же аргументами, мы всегда гарантировано получим один и тот же результат, Haskell запоминает вычисленный однажды результат, и при повторном вызове функции с теми же аргументами не вычисляет его снова, а подставляет ранее вычисленный. Это называется мемоизацией (memoization). Он является весьма мощным инструмент оптимизации. Зачем считать снова, если мы знаем, что результат всегда будет одинаков?
Если суть императивного программирования — в мутации (изменении) переменных в строго определённой последовательности, то суть функционального программирования — в иммутабельности данных и в композиции функций.
Если у нас есть функция
g :: a -> b (читается как «функция g, принимающая аргумент типа a и возвращающая значения типа b») и функция f :: b -> c, то мы можем путём их композиции получить функцию h :: a -> c. Подавая на вход функции g значение типа a, мы получим на выходе значение типа b — а значения именно такого типа принимает на вход функция f. Поэтому результат вычисления функции g мы можем сразу передать в функцию f, результатом которой будет значение типа c. Записывается это так: h :: a -> c h = f . g
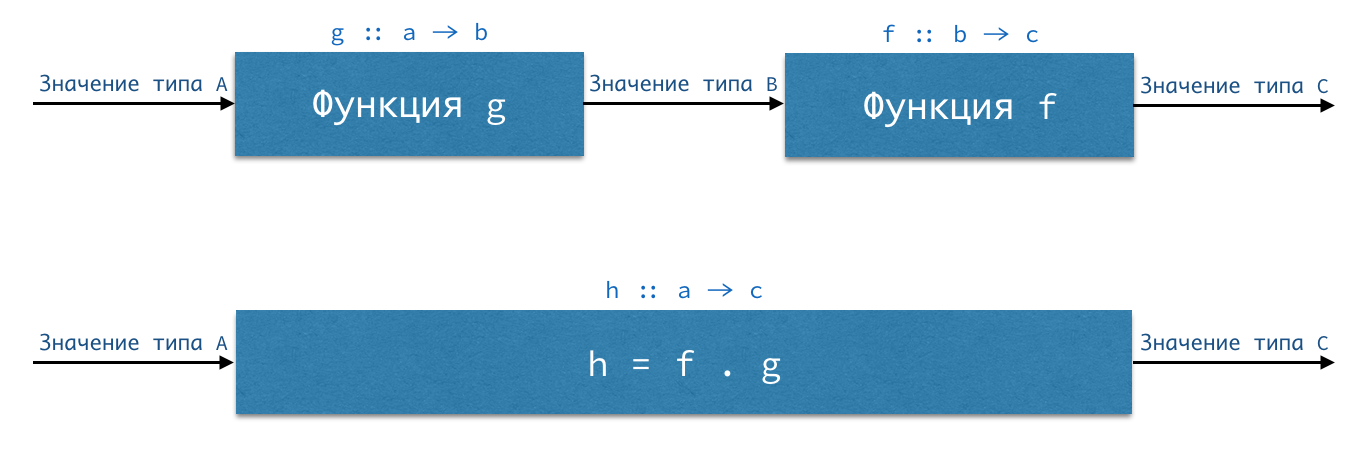
Точка между функциями f и g — это оператор композиции, который имеет следующий тип:
(.) :: (b -> c) -> (a -> b) -> (a -> c)
Оператор композиции здесь взят в скобки потому, что именно так (в скобках) он используется в префиксном стиле, как обычная функция. Когда же мы используем его в инфиксном стиле — между двумя его аргументами — то он используется без скобок.
Мы видим, что оператор композиции в качестве первого аргумента принимает функцию
b -> c (стрелка тоже обозначает тип — тип функции), что соответствует нашей функции f. Вторым аргументом он тоже принимает функцию — но уже с типом a -> b, что соответствует нашей функции g. И возвращает нам оператор композиции новую функцию — с типом a -> c, что соответствует нашей функции h :: a -> c. Поскольку функциональная стрелка имеет правую ассоциативность, последние скобки мы можем опустить: (.) :: (b -> c) -> (a -> b) -> a -> c
Теперь мы видим, что оператору композиции нужно передать две функции — с типами
b -> c и a -> b, а также аргумент типа a, который передастся на вход второй функции, и на выходе мы получим значение типа c, которое возвратит нам первая функция. Почему оператор композиции обозначается точкой
В математике для обозначения композиции функций используется запись
f ∘ g, что означает «f после g». Точка похожа на этот символ, и поэтому её и выбрали в качестве оператора композиции. Композиция функций
f . g означает то же самое, что и f (g x) — т.е. функция f, применённая к результату применения функции g к аргументу x. Постойте! А куда потерялся аргумент типа a в определении функции h = f . g? Две функции в качестве аргументов оператора композиции вижу, а значение, передаваемое на вход в функцию g не вижу!
Когда в определении функции на последнем месте слева и справа от знака "=" стоит один и тот же аргумент, и этот аргумент нигде больше не используется, то его можно опустить (но обязательно с обеих сторон!). В математике аргумент называется «точкой применения функции», поэтому такой стиль записи называется «бесточечным» (хотя обычно при такой записи точек, как операторов композиции, бывает немало :)).
Почему именно композиция функций является сутью функциональных языков программирования? Да потому, что любая программа, написанная на функциональном языке, является ничем иным, как композицией функций! Функции — это кирпичики нашей программы. Композируя их, мы получаем другие функции, которые, в свою, композируем для получения новых функций — и т.д. Данные перетекают из одной функции в другую, трансформируясь, и единственное условие для композиции функций — чтобы данные, возвращаемые одной функцией, имели тот же самый тип, который принимает следующая функция.
Поскольку функции в Haskell у нас чистые, и зависят только от явно переданных им аргументов, то мы легко можем «вытащить» из цепочки композиции функций какой-то «кирпичик», чтобы отрефакторить или даже полностью заменить его. Всё, о чём нам надо позаботиться — это чтобы наша новая функция-кирпичик принимала на входе и выдавала на выходе значения того же типа, что и старая функция-кирпичик. И всё! Чистые функции никак не зависят от внешнего состояния, поэтому тестировать функции мы можем без оглядки на него. Вместо тестирования программы целиком мы тестируем отдельные функции. Ситуация, описанная в этом весьма жизненном рассказе, в нашем случае становится просто невозможной:
Маркетолог спрашивает программиста:
— В чём сложность поддержки большого проекта?
— Ну, представь, что ты писатель, и поддерживаешь проект «Война и мир», — отвечает программист. — У тебя ТЗ — написать главу о том, как Наташа Ростова гуляла под дождём по парку. Ты пишешь «шёл дождь», сохраняешься — и тебе вылетает сообщение об ошибке: «Наташа Ростова умерла, продолжение невозможно». Как умерла, почему умерла? Начинаешь разбираться. Выясняется, что у Пьера Безухова скользкие туфли, он упал, его пистолет ударился о землю, а пуля от столба срикошетила в Наташу. Что делать? Зарядить пистолет холостыми? Поменять туфли? Решили убрать столб. Убрали, сохраняемся и получаем сообщение: «Поручик Ржевский умер». Опять садишься, разбираешься и выясняется, что в следующей главе он облокачивается на столб, которого уже нет…
Надеюсь, теперь вы поняли, почему хаскеллисты так ценят чистые функции. Во-первых, они позволяют им без всяких усилий писать распараллеливаемый код, не заботясь о гонке данных. Во-вторых, это позволяет компилятору эффективно оптимизировать вычисления. И, в третьих, отсутствие побочных эффектов и независимость работы чистых функций от внешнего состояния, позволяет программисту легко поддерживать, тестировать и рефакторить даже очень большие проекты.
Другими словами, создатели языка Haskell придумали себе (и нам) такой полностью изолированный от внешнего состояния мирок, эдакого сферического коня в вакууме, в котором все функции чистые, нет никакого состояния, все оптимизировано до невозможности и все само собой распараллеливается без всяких усилий с нашей стороны. Не язык, а мечта! Осталось только понять, что делать с «сущими мелочами», которые в своей научной работе, посвященной концепции монад, перечислил Eugenio Moggi:
Как в этом самом сферическом коне в вакууме получать исходные данные для наших программ, которые приходят как раз из внешнего мира, от которого мы изолировались? Можно, конечно, использовать в качестве аргумента нашей чистой функции результат пользовательского ввода (например, функциюgetChar, принимающую ввод символа с клавиатуры), но, во-первых, таким образом мы впустим в наш уютный чистый мирок «грязную» функцию, которая нам все там сломает, а, во-вторых, у такой функции аргумент всегда будет один и тот же (функцияgetChar), а вот вычисляемое значение всегда будет разным, потому что пользователь (вот засада!) будет все время нажимать разные клавиши.
Как выдавать результат в изолированный нами же от нашего уютного чистофункционального мирка внешний мир результат работы программы? Ведь функция в математическом смысле этого слова всегда должна возвращать результат, а функции, отправляющие какие-то данные во внешний мир, ничего нам не возвращают, а значит, и не являются функциями!
Что делать с так называемыми частично определёнными функциями — то есть с функциями, которые определены не для всех аргументов? Например, всем известная функция деления не определена для деления на ноль. Такие функции тоже не являются полноценными функциями в математическом смысле этого термина. Можно, конечно, для таких аргументов бросать исключение, но...
… но что нам делать с исключениями? Исключения — это совсем не тот результат, который мы ожидаем от чистых функций!
А что делать с недетерминированными вычислениями? То есть с такими, где правильный результат вычислений не один, а их много. Например, мы хотим получить перевод какого-то слова, а программа выдает нам сразу несколько его значений, каждое из которых является правильным результатом. Чистая функция всегда должна выдавать только один результат.
А что делать с продолжениями? Продолжения — это когда мы производим какие-то вычисления, а затем, не дождавшись их окончания, сохраняем текущее состояние и переключаемся на выполнение какой-то другой задачи, чтобы после ее выполнения вернуться к незавершенным вычислениям и продолжить с того места, где мы остановились. О каком состоянии мы ведем речь в нашем чистофункциональном мирке, где никакого состояния нет и быть не может?
И что, наконец, нам делать, когда нам нужно не только как-то считать внешнее состояние, но и как-то изменить его?
Давайте вместе подумаем, как можно и сохранить чистоту наших вычислений, и решить озвученные проблемы. И посмотрим, можно ли найти общее решение для всех этих проблем.
Вычисления и «что-то ещё»
Итак, мы познакомились с чистыми функциями и поняли, что их чистота позволяет нам избавиться от самых сложных проблем, с которыми сталкиваются программисты. Но мы также описали целый ряд проблем, которые предстоит нам решить, чтобы сохранить возможность пользоваться преимуществами чистых функций. Я приведу их снова (исключив проблемы, связанные с вводом-выводом, которые мы рассмотрим чуть позже), несколько переформулировав их, чтобы мы смогли увидеть в них общий паттерн:
Иногда у нас есть функции, которые определены не для всех аргументов. Когда мы передаём этой функции аргументы, на которых функция определена, мы хотим, чтобы она вычислила результат. Но при передаче её аргументов, на которых она не определена, мы хотим, чтобы функция возвратила нам что-то ещё (исключение, сообщение об ошибке или аналог императивного null).Иногда функции могут выдавать нам не один результат, а что-то ещё (например, целый список результатов, или вообще никакого результата (пустой список результатов)).
Иногда, для вычисления значения функции, мы хотим получать не только аргументы, но и что-то ещё (например, какие-то данные из внешнего окружения, или какие-то настройки из конфигурационного файла).
Иногда мы хотим не только получить результат вычисления для передачи следующей функции, но и применить его в качестве аргумента к чему-то ещё (получив некоторое состояние, к которому можно затем вернуться, чтобы продолжить вычисления, что является смыслом продолжений (continuations).
Иногда мы хотим не только произвести вычисления, но и сделать что-то ещё (например, записать что-то в лог).
Иногда, композируя функции, мы хотим передать следующей функции не только результат нашего вычисления, но и что-то ещё (например, некоторое состояние, которое мы сначала считали откуда-то, а затем как-то контролируемо изменили).
Заметили общий паттерн? На псевдокоде его можно записать примерно так:
функция (аргументы и/или иногда что-то ещё) { // сделай чистые вычисления и/или // сделай что-то ещё return (результат чистых вычислений и/или что-то ещё) }
Можно, конечно, передавать это «что-то ещё» в качестве дополнительного аргумента в наши функции (такой подход применяется в императивном программировании, и называется «выделением состояния» (threading state)), но смешивать чистые вычисления с «чем-то ещё» в одну кучу — не самая лучшая идея. Кроме того, это не позволит нам получить единое решение для всех описанных ситуаций.
Давайте вспомним древних египтян, о которых шла речь в начале, и которые изобрели числа. Вместо рисования множества фигурок овец они отделили вычисление от его контекста. Выражаясь современным языком, они инкапсулировали вычисления и их контекст. И если до них понятие вычисления количества было неразрывно связано с тем, что именно мы считаем, то их инновация разделила это на два параллельных «потока исполнения» — на поток, связанный непосредственно с вычислениями, и на поток, в котором хранится или обрабатывается что-то ещё — а именно, контекст вычисления (потому что в ходе вычисления контекст может не только храниться, но и изменяться, если мы, например, подсчитываем, сколько шашлыков получится из овец, находящихся в стаде).
Когда мы хотим в Haskell’е выразить «что-то ещё», и при этом получить максимально обобщённое решение, это «что-то ещё» мы выражаем в виде дополнительного типа. Но не простого типа, а типа-функции, который принимает в качестве аргумента другие типы. Звучит сложно и непонятно? Не волнуйтесь, это очень просто, и через несколько минут вы сами убедитесь в этом.
Инкапсуляция «чего-то ещё»
11 декабря 1998 г. для исследования Марса был запущен космический аппарат Mars Climate Orbiter. После того, как аппарат достиг Марса, он был потерян. После расследования выяснилось, что в управляющей программе одни дистанции считались в дюймах, а другие — в метрах. И в одном, и в другом случае эти значения были представлены типом
Double. В результате функции, считающей в дюймах, были переданы аргументы, выраженные в метрах, что закономерно привело к ошибке в расчётах. Если мы хотим избежать таких ошибок, то нам нужно, чтобы значения, выраженные в метрах, отличались от значений, выраженных в дюймах, и чтобы при попытке передать в функцию значение, выраженное не в тех единицах измерения, компилятор сообщал нам об ошибке. В Хаскелле это сделать очень легко. Давайте объявим два новых типа:
data DistanceInMeters = Meter Double data DistanceInInches = Inch Double
DistanceInMeters и DistanceInInches называются конструкторами типов, а Meter и Inch — конструкторами данных (конструкторы типов и конструкторы данных обитают в разных областях видимости, поэтому их можно было бы сделать и одинаковыми). Присмотритесь к этим объявлениям типов. Не кажется ли вам, что конструкторы данных ведут себя как функции, принимая в качестве аргумента значение типа
Double и возвращая в результате вычисления значение типа DistanceInMeters или DistanceInInches? Так и есть — конструкторы данных у нас тоже являются функциями! И если раньше мы могли случайно передать в функцию, принимающую Double, любое значение, имеющее тип Double, то теперь в этой функции мы можем указать, что её аргумент должен содержать не только значение типа Double, но и что-то ещё, а именно — соответствующую «обёртку» Meter или Inch. Однако данном случае у нас получилось не самое обобщённое решение. В качестве аргумента наши функции-конструкторы_данных
Meter и Inch могут принимать только значения типа Double. Это продиктовано логикой данной конкретной задачи, однако для решения нашей основной задачи — отделения чистых вычислений от «чего-то ещё» — нам нужно, чтобы наши «обёртки», выражающие это «что-то ещё», могли принимать в качестве своих аргументов любой тип. И эта задача тоже очень легко решается в Haskell. Посмотрим на один из встроенных типов Haskell: data Maybe a = Nothing | Just a
Объяснение для тех, кто не разобрался, что тут написано
Мы видим, что конструктор данных
Maybe находится не в одиночестве, а принимает некоторый тип a. Эта буковка называется «переменной типа» и означает, что вместо неё мы можем поставить любой тип — хоть Double, хоть Bool, хоть тип DistanceInMeters, который мы определили раньше. И мы видим, что у типа Maybe a есть 2 конструктора данных — Nothing и Just (который принимает в качестве аргумента значение переменной типа a). Вертикальная между конструкторами данных означает слово «либо»: либо мы используем конструктор данных Nothing, либо мы применяем конструктор данных Just к значению какого-то типа (например, Just True) — и в обоих случаях мы получаем значение типа Maybe a (если мы применили конструктор Just к значению True, то мы получаем значение типа Maybe Bool).Смотрите, у нас есть обёртка
Maybe, которая может принимать значения любого типа. Эта обёртка может либо содержать какое-то значение (если использован конструктор данных Just), либо не содержать ничего (если использован конструктор данных Nothing). Для того, чтобы узнать, есть ли какие-то данные внутри обёртки Maybe, нам нужно лишь проинспектировать обёртку. Это как с коробком спичек: чтобы узнать, пустой коробок или нет, нам не обязательно его открывать — мы лишь подносим к уху коробок и встряхиваем его. Тип
Maybe используется в Haskell для решения одной из наших задач — что делать с чистыми функциями, которые определены не для всех своих аргументов. Например, у нас есть функция lookup, которой можем передать ключ и ассоциативный список пар (ключ, значение), чтобы она нашла нам значение, ассоциированное с этим ключом. Но ведь эта функция может и не найти пары с тем ключом, который мы её передали. В этом случае она возвратит нам Nothing, а если найдёт — то возвратит нам значение, обёрнутое в Just. Т.е. когда мы передаём функции значения, на которых она определена, мы получим результат вычислений (в обёртке Just), а когда передаём значения, на которых она не определена — мы получаем «что-то ещё» (Nothing). Но что, если мы хотим получить не просто
Nothing, но и сообщение о том, почему функция нам возвратила «что-то ещё» вместо результата вычислений? Давайте более чётко определим задачу: мы хотим, чтобы если вычисления были удачными, нам был возвращён их результат, а если неудачными — то сообщение об ошибке, причём результат вычислений и сообщение об ошибке могут быть разных типов. ОК, давайте так и запишем: data Either a b = Left a | Right b
Мы видим, что конструктор типа
Either принимает 2 переменных типа — a и b (которые могут быть разными типами, но могут быть и одного типа — как нам захочется). Если результат вычислений был удачен, мы получаем их в обёртке Right (результат вычислений будет иметь тип b), а если вычисления закончились неудачей, то мы получаем сообщение об ошибке типа a в обёртке конструктора данных Left. Ну а что с работой с внешним окружением? Что, если значение нашего вычисления зависит от некоторого внешнего окружения, которое мы должны прочитать и передать в качестве аргумента функции, вычисляющей нужное нам значение? Как сформулировано, так и запишем:
data Reader e a = Reader (e -> a)
Окружение (Environment), от которого зависит наш результат вычислений, обозначается переменной типа
e (напомню, что вместо переменной типа можно подставить любой нужный нам тип), а тип результата вычисления обозначен переменной типа a. При этом само вычисление имеет тип e -> a, т.е. это функция из окружения в нужное нам значение. То же самое и с недетерминированными вычислениями, которые могут нам вернуть единственный результат или что-то ещё (ноль результатов или множество результатов): мы оборачиваем их в дополнительный тип, обозначающий это самое «что-то ещё». И этот тип вам наверняка знаком — это тип списка
[a] (который можно написать и так: [] a, где [] обозначает это «что-то ещё», а переменная типа a — это тип наших чистых вычислений).Аналогично мы поступаем с любым «чем-то ещё» — будь то состояние, которое нам нужно изменить параллельно с исполнением наших чистых вычислений, или исключения, которые могут возникать в процессе исполнения нашей программы. Мы инкапсулируем это «что-то ещё» в типе, в который мы «оборачиваем» наши чистые вычисления, и разделяем обработку «чего-то ещё» и чистые вычисления на два параллельных потока, с каждым из которых мы работаем явно.
Давайте резюмируем и обобщим то, что мы узнали на этот момент:
Работа с чистыми функциями позволяет нам получить огромные преимущества, связанные с лёгкостью распараллеливания вычислений, оптимизаций вычислений компилятором и лёгкостью тестирования, поддержки и рефакторинга даже очень больших программ.
Однако мы встретились с рядом других проблем, которые, как мы выяснили, можно привести к единому паттерну под кодовым названием «что-то ещё». Наши функции могут возвращать, помимо результата вычислений, «что-то ещё», или мы можем передавать в них кроме обычных аргументов «что-то ещё».
Нам нужно инкапсулировать это «что-то ещё», отделив их от чистых вычислений. Чистые вычисления и вычисления с этим «что-то ещё» должны выполняться параллельно.
Мы инкапсулируем это «что-то ещё» в «обёрточном» типе, в который мы «оборачиваем» наши чистые вычисления.
На уровне типов эту инкапсуляцию мы можем представить так:
a -> m b
гдеm— это некоторый «обёрточный тип», в который обёрнут результат чистых вычисленийb.
ОК, концептуально мы поставленные проблемы решили. Но нам стоит решить ещё несколько задач, чтобы из-за нашего решения нам не пришлось писать больше кода:
У нас есть множество функций с типомa -> b, т.е. работающие с обычными значениями. Но теперь у нас появились значения типаm a. Нам нужно либо вручную писать новые функцииm a -> m b, либо придумать универсальный механизм, позволяющий «впрыскивать» наши функции типаa -> bвнутрь обёртокm, чтобы вычислениеa -> bпроизошло внутри обёртки, и мы получили значение типаm b.
У нас функциональный язык, а это значит, что функции у нас являются first class citizens. Т.е. с функциями мы можем делать то же самое, что и с данными — передавать их в качестве аргументов, возвращать их в качестве результатов других функций и т.д. Это значит, что мы можем, в том числе, оборачивать функции в наши «обёрточные» типыm. И если у нас есть функцияf, применённая к аргументуa, то мы должны либо вручную определить, как каждую обёрнутую функциюm fможно применить к обёрнутому значениюm a, либо придумать универсальный способ «выносить обёртку за скобки»:
m f `применённое к` m a => m (f `применённое к` a).
И, наконец, нам нужно придумать, как композировать наши новые функции, ведь именно композиция, как вы помните, является сутью функционального программирования. Если у нас есть функцииf :: b -> cиg :: a -> b, то мы можем составить из них композицию функцийf . g, поскольку возвращаемое значение функцииgсовпадает по типу со значением, которое принимает функцияf. А как нам композировать функцииf :: b -> m cиg :: a -> m b? Ведьm bиb— это разные типы, несмотря на то, что типb«сидит» внутри обёрткиm.
Причём нам недостаточно просто взять и «вытащить» типbиз обёрткиm, чтобы передать его в качестве значения следующей функции. Ведь параллельно с чистыми вычислениями в нашей «обёртке» происходят вычисления нашего «чего-то ещё», и результат этого вычисления нам тоже нужно передать в следующую функцию. В общем, нам нужно придумать, как мы можем композировать функцииa -> m bиb -> m c, чтобы мы смогли из них получить новую функциюa -> m c, и чтобы при этой композиции у нас не потерялись ни чистые вычисления, ни вычисления «чего-то ещё». Причём наше решение, как вы, наверное, уже догадались, тоже должно быть универсальным.
Функтор — это не просто, а очень просто!
Итак, у нас есть три задачи:
Придумать, как мы можем применять уже имеющиеся у нас функции, работающие с обычными значениями, к обёрнутым значениям.
Придумать, как мы можем применять обёрнутые функции, работающие с обычными значениями, к обёрнутым значениям.
Придумать, как мы можем композировать функции, принимающие обычные значения и возвращающие обёрнутые значения — так, чтобы в следующую функцию передавался как результат чистых вычислений, содержащийся внутри обёртки, так и результат вычисления «чего-то ещё», содержащийся в самой обёртке.
В принципе, если бы функциональщики не были ленивыми людьми, они бы
isChar :: a -> Bool, проверяющей, является ли переданное нами значение значением типа Char, нам нужно написать столько уравнений, сколько конструкторов данных имеется в нашем обёрточном типе. Например, в обёрточном типе Maybe a есть 2 конструктора данных — Just и Nothing: maybeIsChar :: Maybe Char -> Maybe Char -> Maybe Bool maybeIsChar (Just x) = Just (isChar x) maybeIsChar Nothing = Nothing
И так мы можем, не заморачиваясь (хотя это как посмотреть), определить аналог каждой чистой функции для работы с обёрнутыми данными. Причём нам нужно будет написать соответствующий аналог не только для каждой функции, но и для каждой обёртки!
Но можно сделать и по-другому. Можно определить новую функцию, которая принимает в качестве первого аргумента уже имеющуюся у нас чистую функцию, и применяет её к значению, содержащемуся внутри обёртки, возвращая нам новое значение, обёрнутое в ту же самую обёртку. Назовём эту функцию
fmap: fmap :: (a -> b) -> m a -> m b
Теперь, вместо того, чтобы определять сотни аналогов наших обычных функций для каждого из обёрточных типов, мы можем определить для каждого из обёрточных типов всего одну функцию
fmap. Давайте определим функцию fmap для обёрточного типа Maybe a: fmap f (Just x) = Just (f x) fmap _ Nothing = Nothing
А что это за знак нижнего подчёркивания на месте первого аргумента функции fmap во втором уравнении?
Первым аргументом функции
fmap должна идти функция a -> b. Но, как вы видите, в правой части второго уравнения мы его нигде не используем, а это значит, что нас не интересует значение первого аргумента. Когда нас не интересует какое-то значение, вместо него мы можем написать знак нижнего подчёркивания. Это снижает синтаксический шум для того, кто будет читать вашу функцию в будущем.Теперь мы можем применять к обёрнутым значениям типа
Maybe a любые функции типа a -> b. Согласитесь, что определением одной лишь функции fmap мы избавились от массы дополнительной работы. Эту же фразу можно произнести и по-другому: сделав наш обёрточный тип Maybe a функтором, мы избавились от массы дополнительной работы. Да-да! Чтобы сделать обёрточный тип функтором, нужно всего лишь определить для него функцию
fmap, что позволит нам «впрыскивать» функции, работающие с обычными значениями, внутрь обёртки. Я же говорил, что функторы — это очень просто! И полезно, т.к. позволяет нам использовать ранее определённые чистые функции не только с обычными, но и с обёрнутыми значениями. Аппликативные функторы — это тоже очень просто!
Мы придумали, как нам применять функции, работающие с необёрнутыми значениями, к обёрнутым значениям. Но что, если у нас обёрнута и сама функция? Как нам её применить к обёрнутому значению?
Думаю, вы уже догадались. Нам нужно объявить функцию, которая принимает в качестве первого аргумента обёрнутую функцию, а в качестве второго аргумента — обёрнутое значение, а затем определить эту функцию для каждого обёрточного типа, для которого нам нужны такие операции. Назовём эту функцию
<*> (читается apply; то, что название функции начинается не с маленькой буквы, а со специального символа, говорит нам о том, что мы должны её использовать в инфиксном виде; если мы хотим её использовать в префиксном виде, как обычную функцию, нам нужно будет взять её в круглые скобки): (<*>) :: m (a -> b) -> m a -> m b
Давайте определим объявленную функцию для типа
Maybe a. При этом будем помнить, что у этого типа 2 конструктора, а значит, и обёрнутая в этот тип функция, и обёрнутое значение, могут быть как (Just функция или значение), так и Nothing: (Just f) <*> Nothing = Nothing Nothing <*> _ = Nothing (Just f) <*> (Just x) = Just (f x)
Всё, теперь мы можем применять любые обёрнутые функции, которые изначально могли работать лишь с обычными значениями, к обёрнутым значениям — при условии, что наша обёртка является типом
Maybe. Если же мы хотим иметь возможность делать то же самое и с другими нашими обёртками, то всё, что нам нужно — это определить для каждой из них функцию (<*>). Другими словами, нам нужно сделать эти обёртки аппликативными функторами, потому что аппликативным функтором называется обёрточный тип, для которого определены функции (<*>) и pure. Что же делает функция
pure? О, это ещё проще, чем функтор или аппликативный функтор! Функция pure принимает обычное значение и делает из него обёрнутое значение. Вот её тип: pure :: a -> m a
Давайте определим функцию
pure для обёрточного типа Maybe, сделав из него настоящий аппликативный функтор: pure x = Just x
Всё очень сложно, правда? (табличка с надписью «Сарказм!»)
Кстати, сделав обёрточный тип аппликативным функтором, мы можем применять функции, принимающие любое количество обычных аргументов, к соответствующему количеству обёрнутых аргументов (функтор позволяет нам применять к обёрнутым значениям только обычные функции одного аргумента). Вот как, например, мы можем сложить
Just 2 и Just 3: pure (+) <*> Just 2 <*> Just 3 > Just 5
Не до конца ясен код?
При помощи функции pure мы оборачиваем в обёртку
Maybe функцию (+), которая умеет работать с обычными значениями. А затем мы передаём ей 2 обёрнутых в ту же обёртку аргумента при помощи оператора аппликации (<*>). Не нравится этот синтаксис? Попробуйте вот это!
Да, согласен, дефолтный синтаксис слишком шумный и затрудняет восприятие. Но вместо него вы можете использовать функцию
Если же вы не против использовать препроцессоры, то вы можете записывать так:
liftAN, где буква A означает Applicative (functor), а вместо N подставляется число, обозначающее количество аргументов, принимаемых нашей функцией. В случае с функцией двух аргументов (+), запись выглядит так: liftA2 (+) (Just 3) (Just 2) > Just 5
Если же вы не против использовать препроцессоры, то вы можете записывать так:
( | a + b | )( | (Just 3) + (Just 2) | ) > Just 5
Вы будете смеяться, но монады также просты!
Итак, мы придумали, как нам применять обычные функции (одного аргумента) к обёрнутым значениям. Для этого нужно определить для обёрточного типа функцию
fmap. И с тех пор, как мы реализовали эту функцию для нашего обёрточного типа, он имеет право гордо именоваться функтором, ибо чтобы стать функтором, ничего больше не нужно. Также мы придумали, как можно применять обёрнутые функции к обёрнутым значениям. Для этого нужно определить для обёрточного типа две функции —
pure и <*> — и это же позволило нам применять к обёрнутым значениям обычные функции, принимающие любое количество аргументов. И как только мы определили для обёрточного типа эти функции, он сразу же заслужил право именоваться аппликативным функтором. Кстати, для того, чтобы сделать обёрточный тип аппликативным функтором, нужно сначала его сделать обычным функтором (и схитрить не получится — компилятор за этим проследит). Этому есть логичное (и, по обыкновению, простое) объяснение, которое я оставлю вам для самостоятельного изучения, ибо статья и так раздулась очень сильно. Нам осталось понять, как мы можем составлять композицию из двух функций
a -> m b и b -> m c таким образом, чтобы из первой функции во вторую передавались и результаты наших чистых вычислений, и результаты вычисления «чего-то ещё», содержащегося в нашей обёртке. Как вы уже, наверное, догадались, для этого нам также потребуется определить одну или две функции для наших обёрточных типов. А самые догадливые уже поняли, что обёрточные типы, для которых будут определены эти функции, будут называться монадами. Первая из этих функций — функция
return. Это не императивный return, который определяет точку выхода из функции. Хаскельная функция return берёт обычное значение, и делает из него обёрнутое значение: return :: a -> m a
Похоже на функцию
pure из главы, где мы превращали обёрточный тип в аппликативные функторы? Так оно и есть, эти функции делают одну и ту же работу. А поскольку есть правило, согласно которому любой обёрточный тип, который мы хотим сделать монадой, сначала должен стать аппликативным функтором (а до этого — просто функтором), а значит, для данного обёрточного типа мы уже определили функцию pure, то функцию return мы можем определить очень просто: return = pure
Вторая функция, которую нам нужно определить для обёрточного типа, чтобы сделать его монадой, называется
(>>=) (читается bind). Она имеет следующий тип: (>>=) :: m b -> (b -> m c) -> m c
Хм… Что-то она не очень напоминает композицию функций. Всё верно: функция
(>>=) принимает обёрнутое значение и функцию с типом a -> m b, и нам нужно определить, каким образом нам передать в эту функцию как результат чистых вычислений, обёрнутый в тип-обёртку, так и результат вычислений «чего-то ещё» (или результат хранения этого «чего-то ещё», если никаких вычислений с ним не производилось), содержащийся в самой обёртке. Т.е. в данном случае мы не показываем функцию a -> m b, в результате которой мы получили значение типа m b, подразумеваем, что оно уже у нас откуда-то есть. Впрочем, функцию композиции мы определим чуть позже, используя для этого функцию (>>=). А пока займёмся ею. Давайте реализуем
(>>=) для обёрточного типа Maybe. Поскольку у него 2 конструктора данных, нам потребуется для этого 2 уравнения. Давайте обзовём нашу функцию, имеющую тип b -> m c буковкой k, от названия «стрелка Клейсли» (все функции, принимающие обычное значение, и возвращающие обёрнутое значение, называются «стрелками Клейсли», и реализованная нами ранее функция return также является «стрелкой Клейсли»): — какой бы функции мы ни передали Nothing, результатом будет Nothing Nothing >>= _ = Nothing — а вот если внутри обёртки есть значение, то мы его "вынимаем" и передаём функции k (Just x) >>= k = k x
Вот и всё. Теперь наш обёрточный тип
Maybe — монада! Всё, что нужно было для этого сделать — определить для него функции return и (>>=). Что же нам это дало (помимо тех преимуществ, которые предоставляют нам чистыми функциями, и которые мы сохранили)? Представьте себе целый конвейер из стрелок Клейсли, через который мы хотим пропустить наше значение. Каждая из этих стрелок Клейсли может возвратить нам либо значение, упакованное в обёртку
Maybe при помощи конструктора данных Just, либо Nothing. Очевидно, что если какая-то стрелка Клейсли из этой цепочки выдала Nothing, нет смысла передавать это значение по конвейеру дальше. Так что же нам делать? После работы каждой стрелки Клейсли проверять при помощи if then else, не вернула ли предыдущая функция Nothing? Императивщики так и делают, строя уродливые конструкции из множества вложенных
if then else. Но мы определили функцию (>>=), которая решает эту задачу без подобной жести. Посмотрите сами: если где-то у нас появился Nothing, наш оператор (>>=) просто «протянет» его до конца конвейера, не передавая ни в какую функцию. Значит, мы можем писать наши цепочки вычислений не беспокоясь о проверке на Nothing. Монады не только позволяют нам сохранить преимущества работы с чистыми функциями, но и позволяют нам писать гораздо меньше кода и сам код получается гораздо более читабельным. А давайте определим ещё пару монад
Давайте, может, определим ещё одну монаду? Возьмём обёрточный тип
Either a b, который позволяет нам более наглядно работать с ошибками и исключениями, чем тип Maybe. Давайте вспомним определение этого типа: data Either a b = Left a | Right b
Этот тип имеет 2 конструктора, один из которых —
Left — принимает значение типа a — это тот тип, который мы будем использовать для сообщения об ошибках, которые в данной обёртке являются тем самым «чем-то ещё», а второй — Right — принимает значение типа b — это тип наших «основных» вычислений. Если «основные» вычисления у нас происходят без эксцессов, то у нас по цепочке композиции стрелок Клейсли проходят значения вычислений, обёрнутые при помощи конструктора данных Right. А как только происходит ошибка — получаем в качестве результата сообщение о ней, обёрнутое при помощи конструктора данных Left. Определим для начала функцию
return: return x = Right x
Здесь всё очевидно. Поскольку мы передаём функции
return не сообщение об ошибке, а какое-то значение типа b, то мы применяем к этому значению функцию-конструктор_данных Right и получаем значение типа Either a b. Теперь определим оператор
(>>=). Логика здесь такая же, как и с монадой Maybe: если хотя бы одна из стрелок Клейсли, которой по цепочке передаётся значение типа Either a b, выдало сообщение об ошибке, обёрнутое при помощи функции-конструктора_данных Left — то и результатом всей цепочки вычислений должно быть это сообщение об ошибке. Если же все вычисления прошли успешно (т.е. каждая из стрелок Клейсли возвратила результат вычислений, обёрнутый при помощи функции-конструктора_данных Right), то каждая следующая функция должна применяться к этому результату: (Left x) >>= _ = Left x (Right x) >>= k = k x
Монады
Maybe и Either похожи. Обе имеют 2 конструктора данных, один из которых обозначает неудачу в вычислениях (и, следовательно, его нужно не передавать в следующую функцию, а «протащить» до конца композиции стрелок Клейсли). Второй же конструктор данных в обеих монадах означает удачно завершившиеся вычисления, и значение этих вычислений передаётся в следующую стрелку Клейсли. Давайте теперь реализуем монаду, которая отличается от реализованных ранее монад — монаду списка. Стрелка Клейсли для монады списка имеет тип
a -> [b]. Первым аргументом оператора (>>=) является обёрнутое значение типа m a — в данном случае, это [a] (список значений типа a). При этом список у нас может быть пустым, а может содержать одно или более значений типа a. Что же, в данном случае, означает применение стрелки Клейсли к списку значений? А это означает, что мы должны её применить к каждому значению списка. В случае с пустым списком всё понятно — там не к чему применять стрелку Клейсли, и в результате мы получим пустой же список. К каждому значению непустого списка мы можем применить стрелку Клейсли, используя функцию
fmap (раз мы делаем из списка монаду, то это значит, что список является и функтором — помните?). Однако давайте вспомним тип функции fmap, заменив для удобства восприятия абстрактный обёрточный тип m на наш конкретный обёрточный тип списка: fmap :: (a -> b) -> [a] -> [b]
А теперь заменим тип функции, передаваемой в
fmap, на тип нашей стрелки Клейсли: fmap :: (a -> [b]) -> [a] -> [[b]]
Мы видим, что в результате передачи стрелки Клейсли в
fmap у нас получится значение не типа m b, а типа m m b, т.е. у нас обёртка будет двойной. Это не соответствует типу оператора (>>=), поэтому одну из обёрток мы должны «снять». Для этого у нас есть функция concat, принимающая список списков, конкатенирующая внутренние списки, и возвращающая обычный список значений. Теперь мы готовы определить оператор (>>=) для монады списка: [] >>= _ = [] xs >>= k = (concat . fmap k) xs
Вы видите, что логика определения оператора
(>>=) во всех случаях одна и та же. В каждом обёрнутом значении у нас есть результат вычислений и «что-то ещё», и мы думаем, что нам нужно сделать с вычислениями и с этим «чем-то ещё» при передаче в другую функцию. «Что-то ещё» может быть маркером удачных или неудачных вычислений, может быть маркером удачных вычислений или сообщением об ошибке, может быть маркером того, что вычисления у нас могут возвратить от нуля до бесконечности результатов. «Что-то ещё» может быть записью в лог, состоянием, которое мы читаем и передаём в качестве аргумента для наших «основных» вычислений. Или состоянием, которое мы читаем, изменяем и передаём в другую функцию, где оно снова изменяется — параллельно с нашими «основными» вычислениями. Согласитесь, что в монадах ничего сложного нет (как и в функторах, и в аппликативных функторах). Монада — это просто обёрточный тип, для которого определены две функции —
return и (>>=). Впрочем, определения
(>>=) для обёрток, работающих с состоянием, несколько сложнее. Я не привожу их здесь потому, что их реализация требует более высокого уровня знакомства с синтаксисом Haskell, нежели тот, который был введён в данной статье. Но я хочу вас успокоить. Во-первых, даже весьма продвинутые программисты на Haskell обычно не пишут свои монады, а используют встроенные в язык, которых хватает на все случаи жизни. Во-вторых, использовать монады (в том числе и работающие с состоянием) гораздо проще, чем их определять, что вы увидите в следующей главе. Для понимания монад вам нужно просто осознать простой принцип: у нас есть «основные» вычисления и вычисления «чего-то ещё», которые происходят параллельно. А как именно происходят эти вычисления в «конвейере» «стрелок Клейсли», определяет оператор
(>>=). Поэтому, хотя вам вряд ли когда-то придётся самим определять оператор (>>=), весьма полезно разобраться в том, как он определён для различных встроенных монадических типов, чтобы лучше понять, что и как там всё происходит. Кстати, когда я говорил, что оператор
(>>=) — это усечённая версия композиции стрелок Клейсли, я обещал определить через него их настоящую композицию. Это стандартная функция в языке Haskell, и обозначается она (>=>), а произносится «рыбка» («fish operator»): (>=>) :: (a -> m b) -> (b -> m c) -> a -> m c (f >=> g) x = f x >>= g
Значение
x у нас имеет тип a, f и g — стрелки Клейсли. Применив стрелку Клейсли f к значению x, мы получим обёрнутое значение. А как передавать в следующую стрелку Клейсли обёрнутое значение, как вы помните, знает оператор (>>=). В следующей части мы увидим, как работать с определёнными в языке Haskell монадами (а другие подавляющему большинству программистов и не требуются), реализуем ещё одну стандартную монаду под названием
Writer («что-то ещё» в ней выражается в записи в лог), чтобы у меня появилось веское основание рассказать вам, что такое моноид и для чего он нужен. А дальше я расскажу вам о ещё одном мощнейшем механизме Haskell под названием «классы типов», и завершу свой рассказ тем, что объясню, как связаны функторы, аппликативные функторы и монады, с которыми мы уже познакомились, с моноидами и классами типов, о которых мне ещё предстоит рассказать. А уже в самом конце я выполню своё обещание и кратко расскажу о монаде ввода-вывода, которая отличается от обычных монад (впрочем, отличается лишь в реализации, а в использовании она так же проста, как и другие монады).