
Год назад выполнял довольно интересную работу по разработке встраиваемого компьютера для одного предприятия, занимающегося электроникой. Компьютер ничего принципиально интересного не представлял: процессор Cortex A-8, работающий на субгигагерцовых частотах, 512Mb DDR3, 1Gb NAND, легковесная сборка Linux. Однако устройству, в который компьютер встраивался, а значит и ему самому, предстояло работать в довольно жестких условиях. Широкий температурный диапазон (от -40 до +85 градусов Цельсия), влагостойкость, стойкость к электромагнитным излучениям, киловольтные импульсы по питанию, защита от статики в 4 кВ и много чего интересного, что хорошо описано в различных ГОСТах на спецтехнику, – это все про него. Одно из основных требований заказчика – срок выработки на отказ не менее 10 лет. При этом производитель обеспечивает гарантийный ремонт изделия в течении пяти лет, потому вопрос не риторический, а денежный и серьезный. В изделие была заложена соответствующая элементная база. Прибор с честью прошел испытания и получил требуемые сертификаты, но разговор не про то. Проблемы начались когда была изготовлена установочная партия, и устройства разошлись по отделам и КБ для создания прикладного ПО. Пошли возвраты с формулировкой: «Чего-то не загружается».
Это был FAIL
В ходе осмотра выяснилось, что в 100% случаях отказа повреждался раздел NAND с файловой системой (rootfs), причем все остальные разделы были целы, нормально монтировались и читались. Опрос свидетелей показал, что прибор отказывался запускаться, после жесткого аварийного отключения питания. Направление исследования ясно. Сбой файловой системы может быть вызван выключением питания во время записи на носитель. Сооружаем испытательный стенд, задача которого подать питание на устройство, дождаться, когда Linux загрузится и запустит тестовый скрипт (генерирует файлы и пишет на Flash) и отрубить питание. И так по кругу. В общей сложности цикл продолжался чуть больше минуты. Поставили на испытание несколько устройств. В среднем, через 2000 итераций, каждый прибор отказывался загружаться, раздел с rootfs падал! Кажется нашли.
Из соображений долговечности и надежности в нашем устройстве в качестве ПЗУ используется SLC NAND. Варианты с eMMC (embedded Multimedia Memory Card) были отвергнуты сразу из-за небольшого количества циклов перезаписи. На сегодняшний день eMMC не является стандартом для industrial-применений, наверное по этой причине такое малое количество предложений подобных микросхем с нижней границей рабочего температурного диапазона -40С. Основное же ограничение для применения в промышленных системах – это малый срок гарантийного хранения данных. Если для SLC NAND это порядка 10 лет, то для eMMC – около года.
В отличии от решения на базе eMMC (или обычной SD «Secure Digital» Card), где программный уровень взаимодействия с физическим носителем (FTL – Flash Translation Layer) осуществляет встроенный в память контроллер, FTL должен быть реализован средствами центрально процессора. Несмотря на увеличивающуюся сложность внедрения, это дает ощутимые преимущества в гибкости конфигурации конечной системы, а также за счет возможности использования специальных алгоритмов выравнивания износа физических ячеек памяти повышает долговечность носителя. (На самом деле во встроенном в eMMC уровне FTL тоже реализованы алгоритмы выравнивания износа, но это «черный ящик»).
В операционных системах Linux для работы с физическим носителем NAND используются ряд файловых систем: JFFS2 и ее эволюционное развитие – UBI/UBIFS (спасибо Nokia за это), а также конкурент – LogFS. По совокупности параметров, предпочтение было отдано связке UBI/UBIFS. UBI/UBIFS – это два программных слоя: UBI (Unsorted Block Images) – обеспечивает работу непосредственно с физическим носителем, UBIFS (UBI File System) – собственно, сама файловая система.
Основные возможности UBI:
- работает с разделами, позволяет создавать, удалять, или менять их размер;
- обеспечивает выравнивание записи по всему объему носителя;
работает с Bad-блоками; - минимизирует вероятность потери данных при аварийном отключении питании или других сбоях.
UBIFS, кроме всего прочего, занимается ведением журналов.
Несмотря на то, что в целом UBI и UBIFS разрабатывались с учетом требования толерантности к прерыванию питания, как показала практика в процессе эксплуатации устройства при определенных условиях, после аварийного завершения работы (другими словами, отключения питания) раздел оказывается испорчен. Если это раздел с rootfs, то устройство теряет работоспособность в целом. Вероятность этого события не велика, устройство может стабильно работать несколько месяцев или даже несколько лет, благополучно пережить ни один сбой питания. Однако этот фактор нельзя не учитывать, если устройство предназначено для работы в труднодоступном месте, с ограниченным доступом человека или выход его из строя может носить фатальные последствия.
Причина сбоев в заключается в физической особенности строения NAND. Запись данных происходит постранично, предварительно, страница должна быть стерта – в область записаны все единицы. Стирание происходит блоками, такой блок называется PEB (physical erase blocks). Для того, чтобы стереть страницу, нужно стирать блок целиком. В одном блоке может быть множество страниц, например, страница 4КБ, а блок 256КБ. Разработчики технологии UBI/UBIFS знают о такой проблеме и во всем винят так называемые «нестабильные биты» (unstable bits). Они указывают на четыре основных события, когда данные с носителя могут быть утеряны.
Причины сбоев и потери информации в NAND
- Питание было отключено перед тем как работа со страницей памяти была завершена. После перезагрузки страница может быть прочитана корректно, но при повторном чтении можно получить ошибку ECC. Это происходит потому что появилось некоторое количество нестабильных бит, которые могут читаться корректно или не корректно.
- Отключение питания происходит в момент начала работы со страницей NAND. После перезагрузки, страница может быть прочтена корректно: считаются все единицы (0xFF), но иногда, после перезагрузки можно из этой области считать только нули. Кроме того, если потом опять записать эту страницу, иногда может возникнуть ошибка ECC. Причина – опять нестабильные биты.
- Отключение питания во время стирания блока. После перезагрузки, опять же, могут появится нестабильные биты, и данные в блоке становятся поврежденными.
- Питание отключается после того, как операция очистки блока была запущена. И опять же, после перезагрузки блок содержит нестабильные биты: или при чтении возвращает нули, или поврежденные данные, при попытке записать туда информацию.
Во всех случаях, после аварийного отключения питания область памяти может быть прочитана корректно, в результате система журналирования не увидит подвоха. Но при последующим доступе к этой области данные могут быть повреждены. Количество таких «нестабильных бит» может быть больше, чем алгоритм ECC сможет скорректировать. Поэтому, ранее читаемые страницы становятся нечитаемыми, или наоборот, ранее нечитаемая страница может стать вдруг читаемой. Проблема усугубляется тем, что нестабильные биты могут возникнуть в журнале файловой системы, так как статистически, эта область NAND наиболее часто модифицируется.
Спасаем систему
Для повышения живучести файловой системы мы решили внести избыточность в архитектуру корневой файловой системы (КФС). Идея следующая: создаем «виртуальный» раздел из двух физических разделов на носителе. Один раздел содержит образ rootfs, доступный только для чтения, а во время работы операционной системы все изменения заносятся во второй раздел, который доступен для чтения и записи. Так как запись осуществляется только во второй раздел, при аварийном отключении питания повредиться может только он. Второй раздел останется исходным. Такая технология известна как каскадно-объединенное монтирование.
Кроме того, решили разнести системное ПО (имеется в виду rootfs, ядро изначально было на отдельном read-only разделе) и прикладное ПО на разные физические разделы. В силу специфики нашего устройства (работает с массивными базами данных), выделили раздел для резервного копирования. В этом месте радуемся, что в устройство заложили достаточно памяти (1 ГиБ).

Для каскадно-объединенного монтирования разделов использована вспомогательная файловая система aufs. Как уже говорилось выше, происходит объединение двух физических разделов. Первый раздел, в который изначально записан образ рабочей КФС, доступен только для чтения (RO – read only), второй раздел, изначально пустой, служит для хранения изменений, соответственно, он доступен как для чтения, так и для записи (RW – read write). В терминах aufs первый и второй разделы называются ветвями (branch). Объединение ветвей происходит в процессе монтирования. В результате операционная система видит смонтированную область как единое целое. Доступ к данным осуществляется драйвером ядра. Запросы на чтение файла драйвер в первую очередь направляет к RW ветви; если данные там присутствуют, то выдаются они, если там данных нет, то файл читается из ветви RO. При записи, данные попадают в ветвь RW. При удалении файла, в ветвь RW добавляется метка о том, что данный файл был удален (создается соответствующий пустой скрытый файл с определенным префиксом в названии). Физически файл остается в ветви RO целым. Такой подход позволяет избежать операций записи в разделе с критической информацией. Кроме того, так как ветвь RO доступна только для чтения, появляется принципиальная возможность добавить дополнительный контроль целостности данных. Реализовать это можно средствами UBIFS, сделав создаваемый раздел статическим. Статический раздел доступен только для чтения и данные там защищены контрольной суммой (CRC-32).
Итого, хотим чтоб получилась такая архитектура КФС:
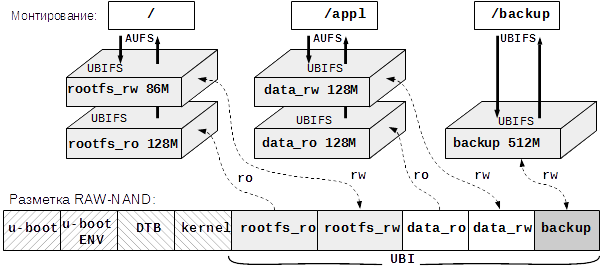
Разделы «rootfs_» содержат системную часть КФС, обеспечивающую работоспособность операционной системы Linux, разделы «data_» предназначены для хранения прикладного ПО, файлов настроек, баз данных. Раздел «backup» предназначен для периодического резервирования текущих настроек системы и баз данных. Резервирование обеспечивается прикладным ПО.
Выпекаем aufs
В настоящий момент aufs не включена в основную ветку ядра Linux, поэтому помимо утилит для работы с технологией требуется самостоятельно наложить патчи на исходники ядра. Для того, чтобы развернуть технологию aufs на целевой платформе (target) Linux нужно:
- Применить патчи на ядро. Все патчи и how-to можно найти на сайте проекта.
- В ядре включить aufs.
- Собрать ядро.
- Собрать утилиты для работы с aufs.
- Перенести ядро и утилиты на target.
Проверить технологию можно на target, выполнив:
mount -t aufs -o br=/tmp/rw=rw:${HOME}=ro none /tmp/aufs
Формат команды
mount [-fnrsvw] [-t тип_ФС] [-o параметры] устройство каталог
moun -t aufs -o br=/tmp/rw:${HOME} none /tmp/aufs
В результате содержимое домашнего каталога окажется в /tmp/aufs, можно писать туда и удалять файлы, содержимое ${HOME} не изменится.
Отлично! aufs подключили, теперь самое интересное: как заставить систему грузиться с нее? По умолчанию, при загрузке мы не можем через cmdline указать ядру раздел с rootfs на aufs. При старте ядра такого раздела еще нет, его только предстоит создать. Значит во время старта системы, до того, как запустится процесс инициализации (процесс с PID = 0, в моем случае это systemd) мы должны смонтировать вспомогательный раздел aufs, выполнить chroot на него, и только после этого запустить /sbin/init. Для подобных задач существует механизм предварительной инициализации. В cmdline указываем путь к скрипту, который должен будет отработать до старта демона инициализации. В cmdline добавляем параметр:
init=/sbin/preinit
Скрипт пишется на shell, потому на момент исполнения в системе должны уже быть все нужные для него утилиты. То есть, фактически для выполнения скрипта должен быть уже смонтирован раздел с rootfs! Для этих целей можно использовать rootfs на RAM-диске, либо изначально грузиться с боевого раздела с rootfs, но в режиме read-only – это наш выбор. Редактируем cmdline соответствующим образом, добавляем параметр (9 – это номер раздела mtd, где у меня rootfs_ro):
root=ubi0:rootfs_ro ro ubi.mtd=9
Скрипт preinit
Монтируем системные разделы (нужны для работы shell):
mount -t proc none /proc mount -t tmpfs tmpfs /tmp mount -t sysfs sys /sys
Раздел rootfs_ro у нас уже смонтирован, мы с него загрузились, монтируем rootfs_rw во временную папку:
ubiattach -m 10 -d 1 > /dev/null mount -t ubifs ubi1:$rootfs_rw /tmp/aufs/rootfs_rw
Если при монтировании пошло что-то не так, то смело форматируем rootfs_rw, а если и это не вышло, то удаляем раздел и создаем заново. Пробуем смонтировать еще раз. Код приводить не буду, там слишком много «magic number», определяемых архитектурой NAND. Скажу лишь только, что понадобятся набор утилит UBI.
Копируем точку монтирования текущей rootfs во временную директорию:
mkdir -p /tmp/aufs/rootfs_ro mount --bind / /tmp/aufs/rootfs_ro
Склеиваем слоеный пирог – монтируем раздел aufs:
mount -t aufs -o br:/tmp/aufs/rootfs_rw :/tmp/aufs/rootfs_ro=ro none /aufs
После этого, новый раздел с rootfs доступен в /aufs.
Делаем финт ушами: переносим точки монтирования rootfs_ro и rootfs_rw в новый раздел:
mount --move /tmp/aufs/ rootfs_ro /aufs/aufs/ rootfs_ro mount --move /tmp/aufs/ rootfs_rw /aufs/aufs/ rootfs_rw
И заодно перенесем /dev:
mount --move /dev /aufs/dev
Понятно, что директории, в которые переносятся точки монтирования, должны быть заранее созданы.
Прибираемся за собой, отключаем системные разделы:
umount -l /proc umount -l /tmp umount -l /sys
Меняем КФС и запускаем инициализацию:
exec /usr/sbin/chroot /aufs /sbin/init
В боевом скрипте по такому же принципу собираем «пирог» для /appl и монтируем /backup. Ниже на рисунке показана получившаяся архитектура итоговой КФС.
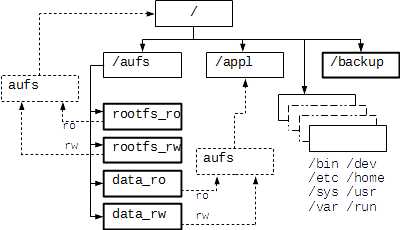
Для повышения надежности, к разделу /backup обеспечен монопольный доступ строго одной утилиты, отвечающей за резервное копирование и восстановления. Сама утилита находится в разделе «data_ro».
Заключение
В результате резко повысилась общая выживаемость системы при аварийных отключениях питания. Хотя применение технологии каскадного монтирования КФС показана на примере NAND, подобный принцип не ограничен физическим типом носителя данных и легко переносится на eMMC, SD и другое. Если же в процессе эксплуатации система не занимается накоплением данных, а лишь отрабатывает определенный алгоритм ( например, обычный роутер), то в качестве ветви RW при монтировании раздела aufs целесообразно использовать RAM диск.
И вместо P.S.: резервный источник питания пока еще никто не отменял.
Почитать по теме
UBIFS — UBI File-System
Официальный сайт проекта AUFS. Инструкция по make и исходные коды там.
