Данная статья является первой частью текстовой версии одноименного доклада с февральской конференции C++ CoreHard Winter 2017. Так уж получилось, что вот уже 15 лет я отвечаю за разработку фреймворка SObjectizer. Это один из тех немногих все еще живых и все еще развивающихся OpenSource фреймворков для C++, которые позволяют использовать Модель Акторов. Соответственно, за это время неоднократно доводилось попробовать Модель Акторов в деле, в результате чего накопился некоторый опыт. В основном это был положительный опыт, но есть и некоторые неочевидные моменты, про которые было бы хорошо узнать заранее. О том, на какие грабли довелось наступить, какие шишки были набиты, как можно упростить себе жизнь и как это сказалось на развитии SObjectizer-а и пойдет речь далее.
Подозреваю, что многое из того, о чем я буду говорить, хорошо известно в Erlang-сообществе. Но Erlang-сообщество слабо пересекается с C++ сообществом. Кроме того, есть разница между тем, что доступно Erlang-разработчику и тем, что доступно C++ разработчику. Поэтому надеюсь, что данная статья окажется интересной и полезной C++никам.
Сам SObjectizer появился весной 2002-го года в компании «Интервэйл». SObjectizer создавался исключительно как рабочий инструмент. Поэтому он сразу же пошел «в дело» и использовался внутри нескольких продуктов как внутри компании, так и за ее пределами:
- электронная и мобильная коммерция;
- мобильный банкинг;
- агрегация SMS/USSD-трафика;
- имитационное моделирование;
- тестовые стенды для проверки ПО АСУ ж/д транспорта;
- прототипирование распределенной системы сбора измерительной информации.
Часть из этих продуктов находится в эксплуатации до сих пор.
Пара слов об актуальности Модели Акторов
Коротко освежим в памяти основные моменты Модели Акторов:
- актор – это сущность, обладающая поведением;
- акторы реагируют на входящие сообщения;
- получив сообщение, актор может:
- отослать некоторое (конечное) количество сообщений другим акторам;
- создать некоторое (конечное) количество новых акторов;
- определить для себя новое поведение для обработки последующих сообщений.
Модель Акторов подразумевает, что прикладная работа в приложении выполняется отдельными сущностями, акторами, которые взаимодействуют друг с другом только посредством асинхронных сообщений.
Актор спит в ожидании входящего сообщения, затем, когда входящее сообщение появляется, он просыпается и выполняет обработку сообщения, после чего снова засыпает до получения следующего сообщения.
По историческим причинам у нас в SObjectizer используется термин агент, а не актор, поэтому далее в тексте будут употребляться оба термина, обозначать они будут одно и то же.
И еще пара слов о применимости Модели Акторов в С++
По моему личному мнению, использование Модели Акторов в C++ дает нам целый ряд бонусов:
- каждый актор обладает собственным состоянием, которое доступно только ему одному. Это очень сильно упрощает жизнь в многопоточном программировании;
- передача информации посредством асинхронных сообщений является удобным и естественным способом решения некоторых типов задач. И Модель Акторов в таких задачах снижает семантический разрыв между предметной областью и реализацией;
- при использовании Модели Акторов связность компонентов оказывается очень слабой, что упрощает их композицию и тестирование;
- механизм взаимодействия на основе асинхронных сообщений очень хорошо дружит с таймерами. Использовать таймеры в виде отложенных или периодических сообщений в Модели Акторов — это одно удовольствие;
- C++ники-новички входят в тему многопоточного программирования на базе Модели Акторов на удивление быстро. Вчерашние студенты за короткое время начинают писать надежный многопоточный код.
Грабли и набитые шишки
Описанные выше бонусы мы получаем только если задача хорошо ложится на Модель Акторов. А хорошо ложится далеко не всегда. Так что нужно проявлять осмотрительность: если мы возьмемся за Модель Акторов, например, в тяжелых вычислительных задачах, то можем получить больше боли, чем удовольствия.
Если же Модель Акторов хорошо подходит под какую-то предметную область, то за счет использования правильного инструментария можно очень сильно упростить себе жизнь.
Но и в этом случае крайне желательно иметь представление о некоторых вещах, которые можно отнести к категории «граблей» или «подводных камней». Далее я буду рассказывать о некоторых граблях, по которым довелось потоптаться лично. Надеюсь это поможет кому-то набить меньше шишек, чем довелось мне.
Перегрузка агентов
Один из самых страшных подводных камней — это проблема перегрузки акторов.
Перегрузка возникает тогда, когда агент не успевает обрабатывать свои сообщения.
Например, кто-то нагружает агента с темпом 3 сообщения в секунду, а агент может обработать только 2 сообщения в секунду. Получается, что в очереди агента на каждом такте оказывается еще одно необработанное сообщение.
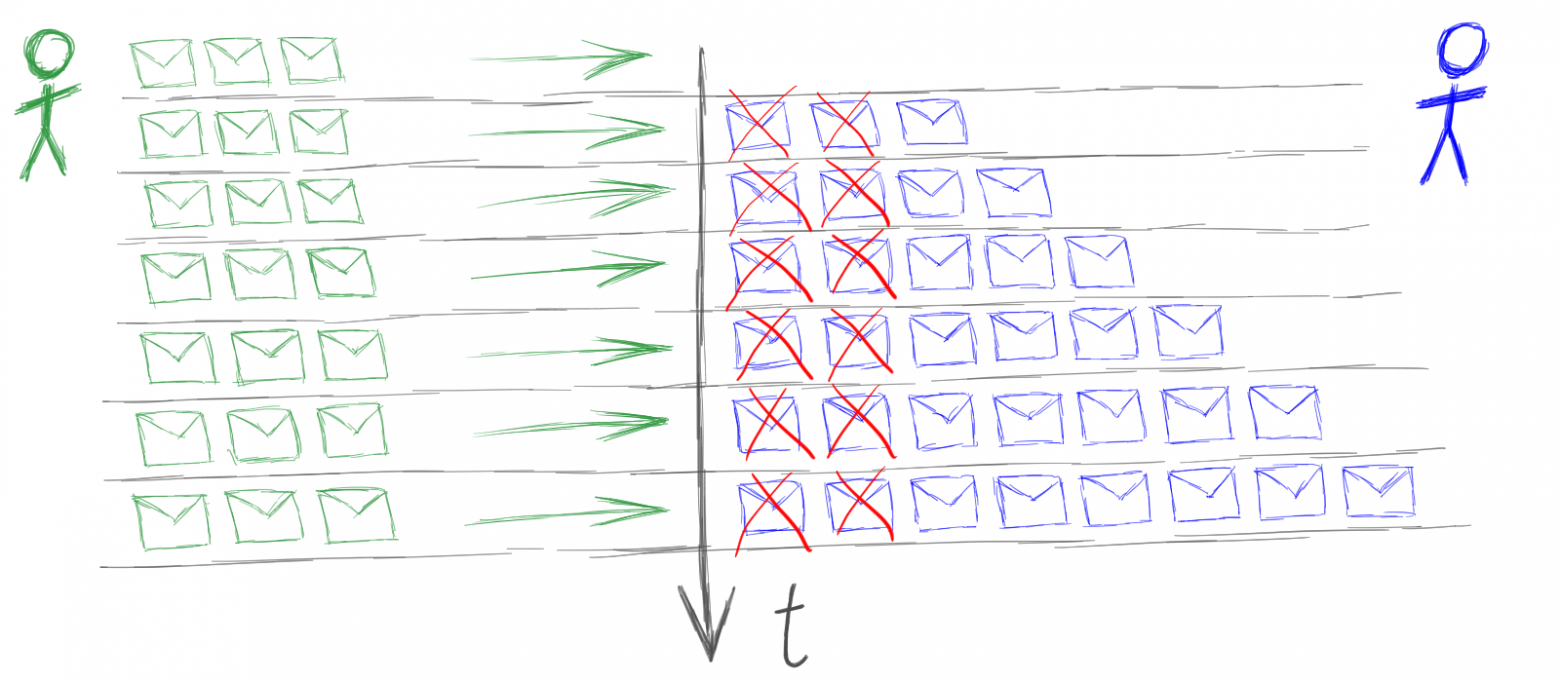
Если агент никак не защищен от перегрузок, то последствия будут печальными: очередь входящих сообщений будет распухать, память будет отжираться, расход памяти будет приводить к замедлению скорости работы, что будет приводить еще к более быстрому росту очередей и т.д. В итоге приложение деградирует до полной потери работоспособности.
Почему перегрузка так страшна в Модели Акторов?
При асинхронном взаимодействии на базе отсылки сообщений нет простой возможности реализовать обратную связь (она же back pressure). Т.е. агент-отправитель просто не знает, насколько заполнена очередь агента-получателя и не может просто так приостановиться до тех пор, пока агент-получатель разгребет свою очередь. В частности, и агент-отправитель, и агент-получатель, могут работать на одной и той же рабочей нити, поэтому если агент-отправитель «уснет», то заблокирует общую рабочую нить вместе с агентом-получателем.
Сложность борьбы с перегрузками в том, что хороший механизм защиты от перегрузки должен быть заточен под конкретную задачу. Где-то при возникновении перегрузки можно выбрасывать самые свежие сообщения. Где-то нужно выбрасывать самые старые. Где-то для старых сообщений нужно выбирать другую стратегию обработки.
Где выход?
Мы на своем опыте убедились, что довольно хорошо зарекомендовал себя поход на базе двух агентов: collector-а и performer-а, каждый из которых работает на разных рабочих нитях. Агент-collector накапливает сообщения и обеспечивает защиту от перегрузки. Агент-perfomer периодически запрашивает очередную порцию сообщений у агента-collector-а. Когда очередная порция обработана, агент-performer вновь запрашивает следующую порцию и т.д.
Но плохо здесь то, что это все нужно делать прикладному программисту. Было бы лучше иметь набор готовых инструментов для этих целей. Поэтому мы встроили в SObjectizer специальный механизм под названием "лимиты для сообщений" который позволяет программисту использовать несколько готовых простых политик для защиты своих агентов от перегрузки.
Выглядеть в коде это может вот так:
class collector : public so_5::agent_t { public : collector(context_t ctx, so_5::mbox_t quick_n_dirty) : so_5::agent_t(ctx // Запроса get_status достаточно всего одного. + limit_then_drop<get_status>(1) // Лишние запросы будут передаваться другому агенту, // который работает более грубо, но быстро. + limit_then_redirect<request>(50, [quick_n_dirty]{ return quick_n_dirty; } ) // Если же не успеваем отдавать накопленное, то работать // дальше не имеет смысла. + limit_then_abort<get_messages>(1)) ... };
Небольшие пояснения
Посредством «лимитов для сообщений» можно указать, например, что в очереди сообщений агента достаточно иметь только одно сообщение типа get_status, а остальные сообщения этого типа можно просто и безболезненно выбрасывать:
limit_then_drop<get_status>(1)
Можно указать, что в очереди должно быть не более 50 сообщений типа request, а остальные сообщения этого типа нужно отсылать другому агенту, который выполнит обработку каким-то другим способом (скажем, если это запрос на ресайз картинки, то сделать ресайз можно более грубо, но значительно быстрее):
limit_then_redirect<request>(50, [quick_n_dirty]{ return quick_n_dirty; } )
В некоторых случаях превышение допустимого количества сообщений в очереди является свидетельством того, что все совсем плохо и лучше прервать работу всего приложения. Например, если в очереди появляется второе сообщение типа get_messages, пока еще не было обработано первое,
то явно что-то идет совсем не так, поэтому нужно вызвать std::abort, рестартовать и начать все заново:
limit_then_abort<get_messages>(1)
Добавленные в SObjectizer лимиты для сообщений не являются полноценным механизмом защиты от перегрузки (поскольку такие механизмы должны затачиваться под конкретную задачу), но в простых случаях и при быстром прототипировании лимиты для сообщений зарекомендовали себя вполне успешно.
Доставка сообщений ненадежна
Для кого-то это может стать сюрпризом, но доставка отосланного сообщения получателю не гарантируется. Т.е. сообщение может быть просто потеряно где-то по дороге. Есть несколько основных причин, по которым отосланное сообщение может не дойти до агента-получателя:
- получателя уже просто нет. Т.е. он существовал на момент отправки, но затем успел исчезнуть;
- получатель есть, сообщение до него дошло, но получатель просто проигнорировал сообщение в своем текущем состоянии;
- сообщение до получателя не доходит, например, из-за механизма «лимитов для сообщений».
Иными словами, когда вы асинхронно отсылаете кому-то сообщение, у вас нет никакой уверенности в том, что сообщение до получателя дойдет.
Давайте представим себе, что агент A отсылает сообщение x агенту B и ожидает получить в ответ сообщение y. Когда сообщение y к агенту A доходит, агент A счастлив и продолжает свою работу.
Однако, если сообщение x до агента B не дошло, а потерялось где-то по дороге, то агент A будет напрасно ждать ответного сообщения y.
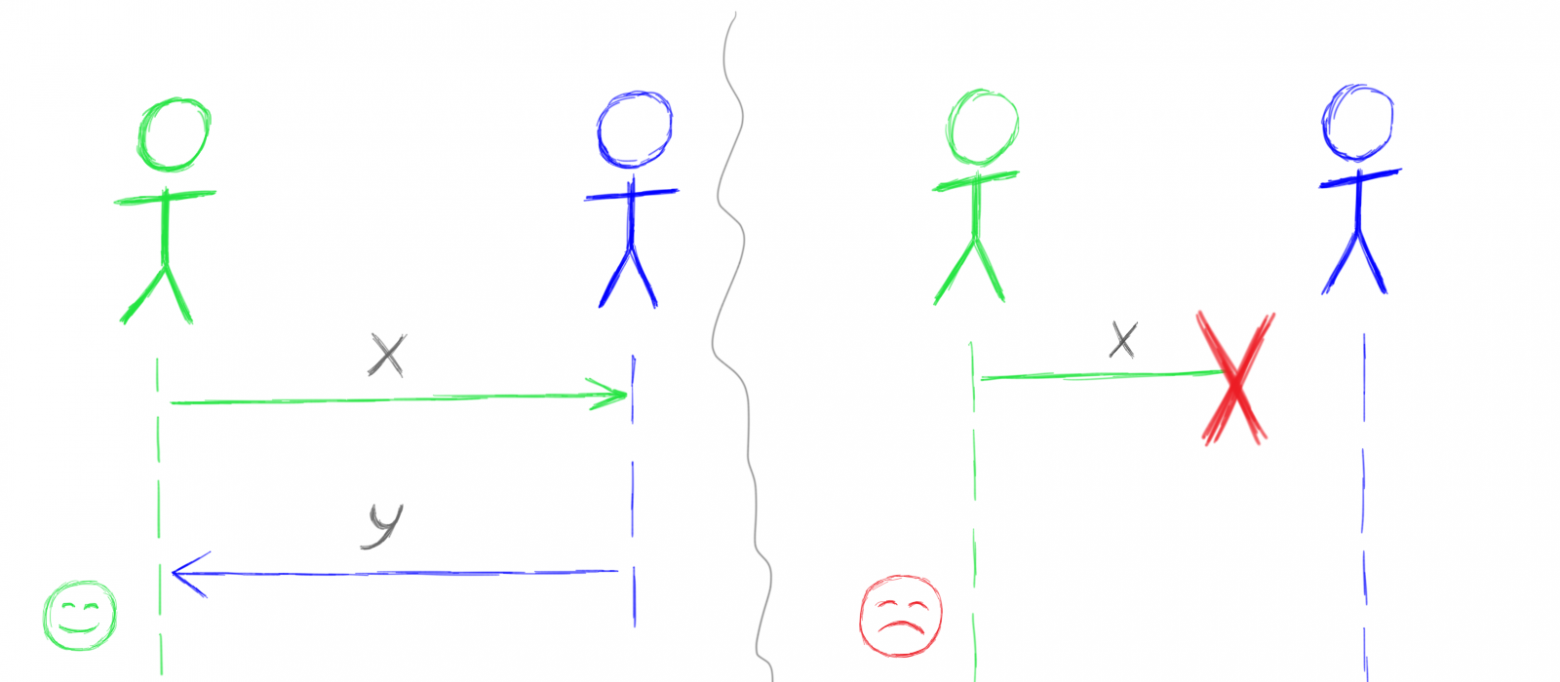
Если забыть про ненадежность сообщений, то легко можно оказаться в ситуации, когда приложение просто перестало работать после потери нескольких сообщений. Как в данном примере: агент A не сможет продолжать работу, пока не получит сообщение y.
Соответственно, возникает вопрос: «Если сообщения ненадежны, то как с этим жить?»
Что делать?
Нужно проектировать работу агентов так, чтобы потеря сообщений не сказывалась на работоспособности. Есть два простых способа для этого:
- Перепосылка сообщения после тайм-аута. Так, если агент A не получил от агента B сообщение y в течении 10 секунд, то агент A может заново перепослать сообщение x. Но! Здесь нужно понимать, что перепосылки сообщений — это прямой путь к перегрузке агентов. Поэтому агент B должен быть защищен от перегрузки сообщениями x.
- Откат операции, если ее результат не был получен в течении разумного времени. Так, если агент A не получает от агента B сообщение у в течении 10 секунд, агент A может отменить ранее выполненые действия на своей стороне. Ну или выставить для своей текущей операции статус «результат неизвестен» и перейти к обработке следующей операции.
На первый взгляд может показаться, что если взаимодействие посредством асинхронных сообщений ненадежно, то ненадежным будет и само приложение, которое разрабатывается на базе Модели Акторов. На практике же оказывается интереснее: надежность приложения как раз таки повышается (на мой взгляд, по крайней мере). Объясняется это тем, что разработчик сразу вынужден закладывать в своих агентов какие-то механизмы преодоления нештатных ситуаций. И эти механизмы срабатывают, когда нештатные ситуации все-таки возникают.
Коды ошибок vs Исключения
На эти грабли мы наступили именно как разработчики SObjectizer-а. Хотя последствия сказываются на пользователях. Дело в том, что когда мы сделали первую версию SObjectizer в 2002-ом году, мы не стали использовать исключения для информирования об ошибках. Вместо этого использовались коды возврата.
Со временем выяснилось, что коды ошибок не есть надежно. Тут сработало правило: если что-то может быть забыто, оно будет забыто. Достаточно где-то прозевать обработку ошибок или же свести обработку ошибки только к ее логированию, то это обязательно со временем вылезет боком. Например, приложение перестанет обрабатывать какие-то запросы пользователя. Следы проблемы затем можно будет отыскать где-то в логе. Но это уже постфактум, когда проблема уже проявилась на пользователях.
Поэтому когда в 2010-ом мы начали делать новую версию SObjectizer, сломав совместимость с предыдущей, мы перешли на использование исключений для информирования о возникающих ошибках.
На мой взгляд, это положительным образом сказалось и на надежности и на качестве приложений. Проблемы теперь не «проглатываются» и любое отклонение от нормы сразу становится заметно.
Вопрос почти на миллион
Давайте представим себе ситуацию, когда агент B обрабатывает сообщение от агента A. И в процессе обработки этого сообщения возникает ошибка, агент B выбрасывает из своего обработчика исключение. Что с этим делать?
У этой проблемы есть две составляющие:
- Агент B работает на контексте, которым владеет SObjectizer. И SObjectizer понятия не имеет, что делать с исключением, которое вылетело из агента B. Может это исключение говорит о том, что все совсем плохо и продолжать работу дальше нет смысла. А может это какая-то ерунда, на которую можно не обращать внимания.
- Даже если перехватить исключение, которое вылетело из агента B, и попытаться доставить его агенту A, то может оказаться, что:
- Агента A уже попросту нет, он уже прекратил свое существование.
- Даже если агент A есть, ему может быть просто не интересно получать информацию о проблемах агента B.
- Даже если агент A есть и даже если ему интересно получить информацию о проблемах агента B, то мы можем просто не доставить эту информацию до агента A по каким-то причинам (например, из-за защиты агента A от перегрузок).
Что же с этим сделать?
В SObjectizer мы сделали специальный флаг, который определяет, что нужно делать, если из агента вылетает исключение. Например, убить все приложение сразу, дерегистрировать проблемного агента или проигнорировать исключение.
То, что агент дерегистрируется при выпуске наружу исключения, позволяет организовать механизмы супервизоров, как в Erlang-е. Т.е., если какой-то агент «падает» из-за исключения, то агент-супервизор сможет на такое падение среагировать и рестартовать «упавшего» агента.
Здесь вам не Erlang, здесь климат иной
Только вот наша практика показывает, что в случае C++ это все не так радужно, как в Erlang-е или каком-то другом безопасном языке. В Erlang-е принцип let it crash возведен в абсолют. Там, грубо говоря, даже на деление на ноль обращать внимание не принято. Ну попробует Erlang-овый процесс поделить на ноль, ну упадет, Erlang-овая виртуальная машина почистит мусор, супервизор создаст упавший процесс заново и все. А вот в C++ попытка деления на ноль, скорее всего, убьет все приложение, а не только того агента, в котором ошибка произошла.
Еще один важный момент: агент — это C++ный объект. Если мы принимаем решение его изъять из приложения, то мы все равно должны его аккуратно удалить, как любой другой объект, время жизни которого истекло. Т.е. для объекта-агента будет вызван деструктор, и этот деструктор должен нормально отработать.
А это означает, что объект-агент должен обеспечивать хотя бы базовую гарантию безопасности исключений. Т.е., если объект-агент выпустил наружу исключение, то никаких утечек ресурсов или порчи чего-либо в программе возникнуть не должно.
Что автоматически ведет к тому, что в C++ принцип «let it crash» выглядит сильно иначе, чем в Erlang-е. И если мы уж начинаем заботиться о том, чтобы агент обеспечивал какие-то вменяемые гарантии по отношению к исключениям, то быстро выясняется, что нам незачем перекладывать заботы о преодолении последствий ошибок на фреймворк. Это может сделать сам агент.
Что ведет к тому, что агенты естественным образом начинают поддерживать nothrow гарантию. Т.е. не выпускают наружу исключений вообще. Грубо говоря, обработчики сообщений в агентах, в которых делается что-то серьезное, содержат внутри блоки try-catch. А уж если при этом из агента исключение вылетает наружу (что означает что-то непредвиденное в блоке catch), то значит что-то не так со всем приложением. И в этом случае убивать нужно не одного проблемного агента, а все приложение. Поскольку мы не можем гарантировать его дальнейшей корректной работы.
Отсюда мораль: С++ — не Erlang и не стоит в C++ переносить подходы для обработки ошибок, подходящие для Erlang-а или какого-то другого языка программирования.
На этом для первой части все, продолжение здесь.
