 Изложение статьи от том, что давно известные эволюционные стратегии оптимизации могут превзойти алгоритмы обучения с подкреплением.
Изложение статьи от том, что давно известные эволюционные стратегии оптимизации могут превзойти алгоритмы обучения с подкреплением.Преимущества эволюционных стратегий:
- Простота реализации
- Не требуется обратного распространения
- Легко масштабируется в распределенной среде вычислений
- Малое число гиперпараметров.
Это исследование продолжает современный тренд, когда высокие результаты достигаются с помощью идей десятилетней давности. Например, в 2012 г. вышла статья об AlexNet, показавшая, как сконструировать, масштабировать и обучить сверточную нейронную сеть (СНН) для получения необычайной точности в задаче распознавания образов. Аналогично, в 2013 г. показано, что комбинация давно известного алгоритма Q-learning со сверточной нейронной сетью позволяет успешно обучить машину играть в игры для Atari. Алекснет возродил интерес к нейронным сетям в то время, когда большинство ученых считали, что СНН неперспективны в задачах компьютерного зрения. Так и эта работа демонстрирует, что эволюционная стратегия (ЭС) позволяет достичь высоких результатов на бенчмарках обучения с подкреплением, разрушая всеобщее мнение о том, что ЭС неприменима в задачах большой размерности.
ЭС легко реализовать и масштабировать. Наша имплементация способна обучить 3D гуманоида MuJoCo хождению на кластере из 80 машин (1440 ядер ЦПУ) всего за 10 минут (А3С на 32 ядрах требует около 10 часов). На 720 ядрах мы также получаем производительность для Atari, сравнимую с А3С, при сокращении времени обучения с 1 дня до 1 часа.
Обучение с подкреплением
Кратко по ОП. Представим, что нам дан некий мир (например игра), в котором мы хотим обучить агента. Для описания поведения агента мы задаем функцию политики (мозг агента). Эта функция вычисляет, как должен действовать агент в каждой конкретной ситуации. На практике политика — это обычно нейронная сеть, на входе которой текущее состояние игры, а на выходе — вероятность предпринять каждое из разрешенных действий. Типовая функция политики может включать около 1 млн. параметров, так что наша задача сводится к нахождению таких значений этих параметров, при котором политика работает хорошо (т.е. агент выигрывает в большинстве игр).
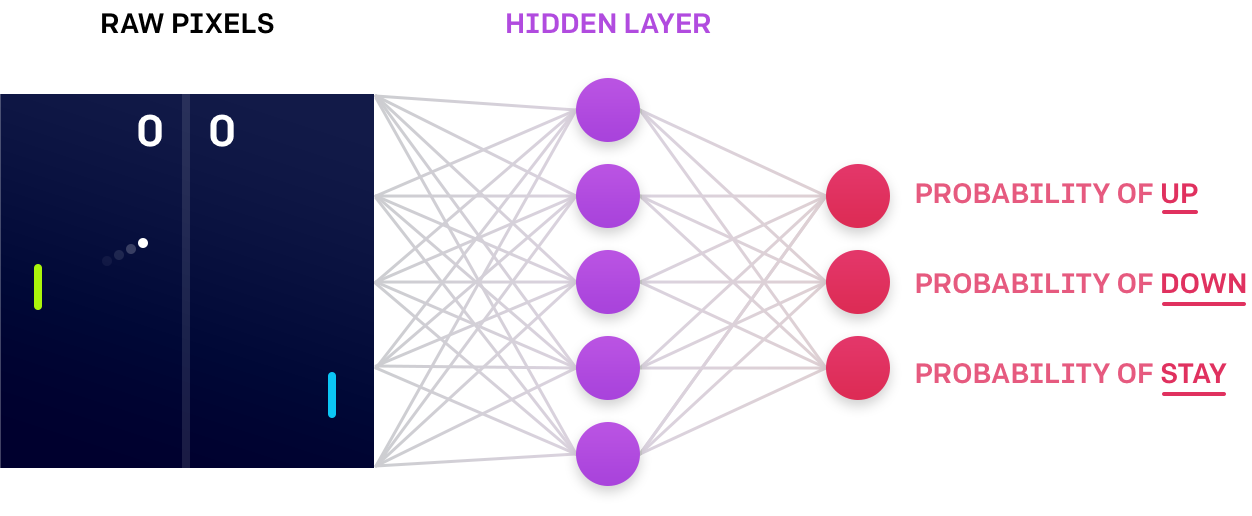
В игре «теннис» политика анализирует пикселы на экране и вычисляет вероятность перемещения ракетки вниз, вверх (или неподвижно).
Процесс обучения состоит в следующем. Начиная со случайной инициализации параметров, агент взаимодействует с игровым миром в течение какого-то времени, и накапливает эпизоды взаимодействия (например, каждый эпизод — это одна игра в теннис). Так мы получаем полную запись всего происходившего: какие состояния нам встретились, какие действия мы предприняли в каждом состоянии, какое вознаграждение получили на каждом шаге. Рецепт улучшения политики: все, что агент делал, и что приводило к улучшению награды, хорошо. К уменьшению награды — плохо. Мы можем использовать обратное распространение для вычисления малых изменений параметров сети, которые приведут к увеличению положительной награды и уменьшению отрицательной награды в будущем. Процесс повторяется итеративно: накапливаем новую порцию эпизодов, обновляем параметры, и повторяем.
Поиск в пространстве политик за счет внедрения шума
В ОП обычно используются стохастические политики, т.к. мы вычисляем лишь вероятности выполнения каждого из действий. Таким образом, за время обучения агент может оказаться в одном и том же состоянии много раз, но каждый раз он предпримет разные действия в соответствии с вероятностным сэмплированием. Это дает сигнал для обучения: некоторые из этих действий приведут к улучшению, а другие — к уменьшению вознаграждения. Таким образом мы внедряем шум в действия агента для поиска в пространстве политик, за счет сэмплирования распределения действий в каждый момент времени. Это отличается от ЭС, которая будет описана далее.
Эволюционные стратегии
Эволюция
Прежде чем погрузиться в ЭС, отметим, что слово «эволюция» здесь не имеет отношения к биологии. Математические основы процесса настолько абстрагированы от своих биологических аналогий, что лучше рассматривать ЭС просто как класс стохастических методов оптимизации типа черного ящика.
Оптимизация методом черного ящика
Забудем об агенте, игровом мире, нейронных сетях, времени… В ЭС рассматривается черный ящик с 1 миллионом чисел на входе (параметрами функции политики), 1 числом на выходе (суммарное вознаграждение). Мы просто хотим найти наилучшее значение этих 1 млн. чисел.
Алгоритм эволюционной стратегии
Интуитивно, оптимизация — это процесс «загадай и проверь». Мы начинаем со случайного набора параметров, и затем последовательно:
1) случайно изменяем слегка значения параметров
2) перемещаемся чуть-чуть в сторону улучшения параметров.
Конкретно, на каждом шаге мы берем вектор параметров w, и генерируем популяцию, например из 100 чуть отличающихся векторов w1… w100, прибавляя гауссовский шум. Затем оцениваем каждый из 100 кандидатов независимо путем запуска агента в своем мире в течение некоторого времени, и складываем значения вознаграждения в каждом случае. Тогда обновленный вектор параметров равен взвешенной сумме всех 100 векторов, где весовые коэффициенты пропорциональны сумме вознаграждения (т.е. более успешные кандидаты получают более высокий вес). Математически это эквивалентно оценке градиента ожидаемого вознаграждения в пространстве параметров, только мы делаем оценку лишь по 100 случайно выбранным направлениям.
Пример кода
Для конкретизации алгоритма, посмотрите на короткий пример оптимизации квадратической функции с помощью ЭС.
# simple example: minimize a quadratic around some solution point import numpy as np solution = np.array([0.5, 0.1, -0.3]) def f(w): return -np.sum((w - solution)**2) npop = 50 # population size sigma = 0.1 # noise standard deviation alpha = 0.001 # learning rate w = np.random.randn(3) # initial guess for i in range(300): N = np.random.randn(npop, 3) R = np.zeros(npop) for j in range(npop): w_try = w + sigma*N[j] R[j] = f(w_try) A = (R - np.mean(R)) / np.std(R) w = w + alpha/(npop*sigma) * np.dot(N.T, A)
Внедрение шума в параметры
Обратите внимание на то, что целевая функция та же, что и в ОП: оптимизация ожидаемого вознаграждения. Однако, в ОП шум внедряют в пространство действий и с помощью обратного распространения вычисляют изменение параметров. В ЭС шум внедряют непосредственно в пространство параметров. Поэтому можно использовать детерминированные политики (что мы и делали в наших экспериментах). Можно также комбинировать оба подхода.
Сравнение обучения с подкреплением и эволюционной стратегии
Некоторые преимущества ЭС над ОП:
- Не требуется обратное распространение. В ЭС есть только прямое распространение политики, что делает код проще и выполняется в 2-3 раза быстрее. В случае ограниченной памяти также нет необходимости хранить эпизоды для будущего обновления. Нет также проблемы взрывного роста градиентов, характерной для реккурентных сетей. Наконец, можно исследовать более широкий класс функций политики, например дифференцируемых (таких как двоичные сети) или содержащих сложные модули (поиск пути или разнообразные оптимизации).
- Высокая степень параллелизма. В ЭС требуется лишь незначительный обмен данных между процессами — скалярные данные о вознаграждении. В ОП требуется синхронизация полных векторов признаков (миллионы чисел). Поэтому в ЭС наблюдается линейный рост производительности по мере добавления вычислительных ядер.
- Устойчивость к выбору гиперпараметров. ОП чувствителен к масштабу, например при обучении для Atari мы наблюдали даже провалы в зависимости от выбора частоты кадров. ЭС в этом эксперименте практически нечувствителен к частоте кадров игры.
- Структурированное исследование. Некоторые алгоритмы ОП приводят к тому, что агент обучается «дребезгу» в управлении. Например, в игре в теннис часто нужно непрерывно давить на кнопку «вверх» в течение нескольких тактов игры. Q-обучение преодолевает этот недостаток ОП, и ЭС не страдает этим недостатком за счет использования детерминированной политики.
- Горизонт планирования шире. Анализ ЭС и ОП показал, что ЭС более предпочтителен когда количество тактов времени в эпизоде большое, т.к. действия придают более длительный эффект. Например, в игре Seaquest агент успешно обучается тому, что подводная лодка должна всплывать, когда уровень кислорода повышается.
ЭС также несвободна от недостатков. На практике, случайный шум в пространстве параметров должен приводить к различающимся результатам, чтобы сформировался обучающий сигнал. Например, в игре Montezuma’s Revenge практически невозможно получить ключ на первом уровне с помощью случайной сети, в то время, как это становится возможным при случайных действиях.
Подробное описание экспериментов и сравнение с лучшими алгоритмами ОП приведены в статье Evolution Strategies as a Scalable Alternative to Reinforcement Learning.
Исходный код опубликован на гитхабе.
Only registered users can participate in poll. Log in, please.
В предложении «Исходный код опубликован на гитхабе» где правильнее поставить гиперссылку на репозиторий?
47.62%[Исходный код] опубликован на гитхабе.50
10.48%Исходный код [опубликован] на гитхабе.11
41.9%Исходный код опубликован на [гитхабе].44
105 users voted. 32 users abstained.
