Часть 1
Продолжаем анализировать что происходит на нашем MS SQL сервере. В этой части посмотрим как получить информацию о работе пользователей: кто и что делает, сколько ресурсов на это расходуется.
Думаю, вторая часть будет интересна не только админам БД, но и разработчикам (возможно даже разработчикам больше), которым необходимо разбираться, что не так с запросами на рабочем сервере, которые до этого отлично работали в тестовом.
Задачи анализа действий пользователей условно поделим на группы и рассмотрим каждую отдельно:
Первый пункт довольно прост, остановимся на нем кратко. Рассмотрим только некоторые малоочевидные вещи.
SSMS, кроме результатов запроса, позволяет получать дополнительную информацию о выполнении запроса:
Подытожим первую часть:
Для второго раздела вооружаемся profiler-ом. После запуска и подключения к серверу, необходимо выбрать журналируемые события. Можно пойти простым путем — запустить профилирование со стандартным темплэйтом трассировки. На закладке «General» в поле «Use the template» выбрать «Standard (default)» и нажать «Run».
Чуть более сложный путь — к выбранному шаблону добавить (или убавить) фильтров или событий. Данные опции на второй закладке диалога. Чтобы увидеть полный набор возможных событий и колонок для выбора — отметьте пункты «Show All Events» и «Show All Columns».
Из событий нам потребуются (лишние лучше не включать — чтобы создавать меньше трафика):
Эти события фиксируют все внешние sql-вызовы к серверу. Они возникают, как видно из названия (Completed), после окончания обработки запроса. Имеются аналогичные события фиксирующие старт sql-вызова:
Но они нам подходят меньше, так как не содержат информации о затраченных на выполнение запроса ресурсах сервера. Очевидно, что такая информация доступна только по окончании выполнения. Соответственно, столбцы с данными по CPU, Reads, Writes в событиях *Starting будут пустыми.
Еще полезные события, которые мы пока не будем включать:
Эти события удобны для отслеживания шагов выполнения. Например, когда использование отладчика невозможно.
По колонкам
Какие выбирать, как правило, понятно из названия колонки. Нам будут нужны:
Прочие колонки добавляйте на свой вкус.
По кнопке «Column Filters...» можно вызвать диалог установки фильтров событий. Если интересует активность конкретного пользователя — задать фильтр по номеру сессии или имени пользователя. К сожалению, в случае подключения приложения через app-server c пулом коннектов — отследить конкретного пользователя сложнее.
Фильтры можно использовать, например, для отбора только «тяжелых» запросов (Duration>X). Или запросов которые вызывают интенсивную запись (Writes>Y). Да хоть просто по содержимому запроса.
Что же еще нам нужно от профайлера? Конечно же план выполнения!
Такая возможность имеется. Необходимо добавить в трассировку событие «Performance \ Showplan XML Statistics Profile». Выполняя наш запрос, мы получим примерно следующую картинку.
И это еще не всё
Трассу можно сохранять в файл или таблицу БД (а не только выводить на экран).
Настройки трассировки можно сохранить в виде личного template для быстрого запуска.
Запуск трассировки можно выполнять и без профайлера — с помощью t-sql кода, используя процедуры: sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Пример как это сделать. Данный подход может пригодиться, например, для автоматического старта записи трассы в файл по расписанию. Как именно использовать эти команды, можно подсмотреть у самого профайлера. Достаточно запустить две трассировки и в одной отследить что происходит при старте второй. Обратите внимание на фильтр по колонке «ApplicationName» — проконтролируйте, что там отсутствует фильтр на сам профайлер.
Список событий фиксируемых профайлером очень обширен и не ограничивается только получением текстов запросов. Имеются события фиксирующие fullscan, рекомпиляции, autogrow, deadlock и многое другое.
Жизненные ситуации бывают и такими, когда информация из разделов выше не помогает:
Какой-то запрос висит на «выполнении» очень долго и непонятно, закончится он когда-нибудь или нет. Проанализировать проблемный запрос отдельно — хотелось бы — но надо сначала определить что за запрос. Профайлером ловить бесполезно — starting событие мы уже пропустили, а completed неясно сколько ждать.
А может висит и не пользовательский запрос совсем, а может это сам сервер что-то активно делает…
Давайте разбираться
Все вы наверно видели «Activity Monitor». В старших студиях его функционал стал богаче. Чем он может нам помочь? В «Activity Monitor» много полезного и интересного, но третий раздел не о нем. Всё что нужно будем доставать напрямую из системных представлений и функций (а сам Монитор полезен тем, что на него можно натравить профайлер и посмотреть какие запросы он выполняет).
Нам понадобятся:
Важные примечания
Приведенный перечень — лишь малая часть. Полный список всех системных представлений и функций описан в документации. Также, имеется схема связей основных объектов в виде красивой картинки — можно распечатать на А1 и повесить на стену.
Текст запроса, его план и статистика исполнения — данные хранящиеся в процедурном кэше. Во время выполнения они доступны. После выполнения доступность не гарантируется и зависит от давления на кэш. Да, кэш можно очищать вручную. Иногда это советуют делать когда «поплыли» планы выполнения, но тут очень много нюансов… В общем, «Имеются противопоказания, рекомендовано проконсультироваться со специалистом».
Поле «command» — для пользовательских запросов оно практически бессмысленно — ведь мы можем получить полный текст… Но не всё так просто. Это поле очень важно для получения информации о системных процессах. Как правило, они выполняют какие-то внутренние задачи и не имеют текста sql. Для таких процессов, информация о команде единственный намек на тип активности. В комментариях к предыдущей статье был вопрос про то, чем занят сервер, когда он, вроде бы, ничем не должен быть занят — возможно ответ будет в значении этого поля. На моей практике, поле «command» для активных системных процессов всегда выдавало что-то вполне понятное: autoshrink/autogrow/checkpoint/logwriter/и т.п.
Как же это использовать
Перейдем к практической части. Я приведу несколько примеров использования, но не стоит ограничивать вашу фантазию. Возможности сервера этим не исчерпываются — можете придумывать что-то своё.
Пример 1: Какой процесс расходует cpu/reads/writes/memory
Для начала, посмотрим какие сессии больше всего потребляют, например, CPU. Информация в sys.dm_exec_sessions. Но данные по CPU (а также reads, writes) — накопительные. Т.е цифра в поле содержит «итого» за все время подключения. Понятно, что больше всего будет у того кто подключился месяц назад, да так и не отключался ни разу. Это вовсе не означает, что он прямо сейчас грузит систему.
Немного кода решает проблему, алгоритм примерно такой:
В коде я использую две таблицы: #tmp — для первой выборки, #tmp1 — для второй. При первом запуске, скрипт создает и заполняет #tmp и #tmp1 с интервалом в одну секунду, и делает остальную часть. При последующих запусках, скрипт использует результаты предыдущего выполнения в качестве базы для сравнения. Соответственно, длительность п.2 при последующих запусках будет равна длительности вашего ожидания между запусками скрипта. Пробуйте выполнять, можно сразу на рабочем сервере — скрипт создает только «временные таблицы» (доступны только внутри текущей сессии и самоуничтожаются при отключении) и не несёт в себе опасности.
Те, кто не любят выполнять запрос в студии — могут его завернуть в приложение написанное на своём любимом языке программирования. Я покажу как это сделать в MS Excel без единой строки кода.
В меню «Данные» подключаемся к серверу. Если будет требовать выбрать таблицу — выбираем произвольную — потом поменяем это. Как всегда, жмем «Next» и «Finish» пока не увидим диалог «Импорт данных» — в нем нужно нажать «Свойства...». В свойствах необходимо сменить «тип команды» на значение «SQL» и в поле «текст команды» вставить немного измененный наш запрос.
Запрос придется немного поменять:
Когда данные будут в Excel-е, можете их сортировать как вам нужно. Для актуализации информации — жмите «Обновить». В настройках книги, для удобства, можете поставить «автообновление» через заданный период времени и «обновление при открытии». Файл можете сохранить и передать коллегам. Таким образом, мы изнавоза и веточек подручных средств собрали ЫнтерпрайзМониторингТул удобный и простой инструмент.
Пример 2: На что сессия расходует ресурсы
Итак, в предыдущем примере мы определили проблемные сессии. Теперь определим, что именно они делают. Используем sys.dm_exec_requests, а также функции получения текста и плана запроса.
Подставляйте в запрос номер сессии и выполняйте. После выполнения, на закладке «Results» будут планы (два: первый для всего запроса, второй для текущего шага — если шагов в запросе несколько), на закладке «Messages» — текст запроса. Для просмотра плана — необходимо кликнуть в строке на текст оформленный в виде url. План откроется в отдельной закладке. Иногда бывает что план открывается не в графическом виде, а в виде xml-текста. Это, скорее всего, связано с тем что версия студии ниже чем сервера. Попробуйте пересохранить полученный xml в файл с расширением sqlplan, предварительно удалив из первой строки упоминания «Version» и «Build», а затем отдельно открыть его. Если и это не помогает — напоминаю, что 2016 студия официально доступна бесплатно на сайте MS.
Очевидно, полученный план будет «оценочным», т.к. запрос еще выполняется. Но некоторую статистику по выполнению получить всё равно можно. Используем представление sys.dm_exec_query_stats с фильтром по нашим хэндлам.
Допишем в конец предыдущего запроса
После выполнения, в результатах получим информацию о шагах выполняемого запроса: сколько раз они выполнялись и какие ресурсы потрачены. Информация в статистику попадает после выполнения — при первом выполнении там, к сожалению, пусто. Статистика не привязана к пользователю, а ведется в рамках всего сервера — если разные пользователи выполняют один и тот же запрос — статистика будет суммарная по всем.
Пример 3: А можно всех посмотреть
Давайте объединим рассмотренные системные представления и функции в одном запросе. Это может быть удобно для оценки ситуации в целом.
Запрос выводит список активных сессий и тексты их запросов. Для системных процессов, напоминаю, обычно запрос отсутствует, но заполнено поле «command». Видна информация о блокировках и ожиданиях. Можете попробовать скрестить этот запрос с примером 1, чтобы еще и отсортировать по нагрузке. Но будьте аккуратны — тексты запросов могут оказаться очень большими. Выбирать их массово может оказаться ресурсоемко. Да и трафик будет большим. В примере я ограничил получаемый запрос первыми 500 символами, а получение плана не стал делать.
Примеры запросов выложил на гитхаб.
Было бы ещё неплохо, получить Live Query Statistics для произвольной сессии. По заявлению производителя, на текущий момент, постоянный сбор статистики требует значительных ресурсов и поэтому, по умолчанию, отключен. Включить не проблема, но дополнительные манипуляции усложняют процесс и уменьшают практическую пользу. Возможно, попробуем это сделать в отдельной статье.
В этой части мы рассмотрели анализ действий пользователей. Попробовали несколько способов: используя возможности самой студии, используя профайлер, а также прямые обращения к системным представлениям. Все эти способы позволяют оценить затраты на выполнение запроса и получить план исполнения. Ограничиваться одним из них не нужно — каждый способ удобен в своей ситуации. Пробуйте комбинировать.
Впереди у нас еще анализ нагрузки на память и сеть, а также прочие нюансы. Дойдем и до них. Материала еще на несколько статей.
Спасибо Владу за помощь в создании статьи.
Продолжаем анализировать что происходит на нашем MS SQL сервере. В этой части посмотрим как получить информацию о работе пользователей: кто и что делает, сколько ресурсов на это расходуется.
Думаю, вторая часть будет интересна не только админам БД, но и разработчикам (возможно даже разработчикам больше), которым необходимо разбираться, что не так с запросами на рабочем сервере, которые до этого отлично работали в тестовом.
Задачи анализа действий пользователей условно поделим на группы и рассмотрим каждую отдельно:
- проанализировать конкретный запрос
- проанализировать нагрузку от приложения в конкретных условиях (например, при нажатии пользователем какой-то кнопки в стороннем приложении работающим с БД)
- анализ ситуации происходящей в данный момент
Предупреждение
Анализ производительности требует глубокого понимания устройства и принципов работы сервера БД и ОС. Поэтому, чтение только этих статей не сделает из вас эксперта.
Рассматриваемые критерии и счетчики в реальных системах находятся в сложной зависимости друг от друга. Например высокая нагрузка HDD, часто связана с проблемой не самого HDD, а с нехваткой оперативной памяти. Даже если вы проведете некоторые из замеров — этого недостаточно для взвешенной оценки проблем.
Цель статей — познакомить с базовыми вещами на простых примерах. Рекомендации не стоит рассматривать как «руководство к действию», рассматривайте их как учебные задачи (упрощенно отражающие действительность) и как варианты «на подумать», призванные пояснить ход мысли.
Надеюсь, по итогу статей вы научитесь аргументировать цифрами свои заключения о работе сервера. И вместо слов «сервер тормозит» будете приводить конкретные величины конкретных показателей.
Рассматриваемые критерии и счетчики в реальных системах находятся в сложной зависимости друг от друга. Например высокая нагрузка HDD, часто связана с проблемой не самого HDD, а с нехваткой оперативной памяти. Даже если вы проведете некоторые из замеров — этого недостаточно для взвешенной оценки проблем.
Цель статей — познакомить с базовыми вещами на простых примерах. Рекомендации не стоит рассматривать как «руководство к действию», рассматривайте их как учебные задачи (упрощенно отражающие действительность) и как варианты «на подумать», призванные пояснить ход мысли.
Надеюсь, по итогу статей вы научитесь аргументировать цифрами свои заключения о работе сервера. И вместо слов «сервер тормозит» будете приводить конкретные величины конкретных показателей.
Анализируем конкретный запрос
Первый пункт довольно прост, остановимся на нем кратко. Рассмотрим только некоторые малоочевидные вещи.
SSMS, кроме результатов запроса, позволяет получать дополнительную информацию о выполнении запроса:
- Практически все знают, что план запроса получается кнопками «Display Estimated Execution Plan» (оценочный план) и «Include Actual Execution Plan» (фактический план). Отличаются они тем, что оценочный план строится без выполнения запроса. Соответственно, информация о количестве обработанных строк в нем будет только оценочная. В фактическом плане будут как оценочные данные, так и фактические. Сильные расхождения этих величин говорят о неактуальности статистики. Впрочем, анализ плана — тема для отдельной большой статьи — пока не будем углубляться.
- Менее известный факт — можно получать замеры затрат процессора и дисковых операций сервера. Для этого необходимо включить SET опции либо в диалоге через меню «Query» / «Query options...»
Скрин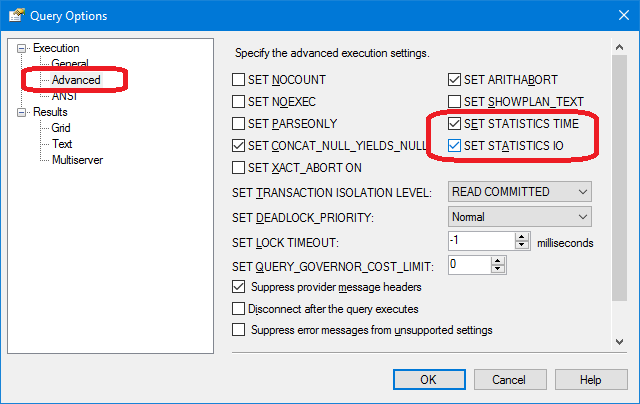
либо напрямую командами SET в запросе, например
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM Production.Product p JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductID
В результате выполнения, получим данные по затратам времени на компиляцию и выполнение, а также, количество дисковых операций.
Пример выводаВремя синтаксического анализа и компиляции SQL Server:
время ЦП = 16 мс, истекшее время = 89 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
(32 row(s) affected)
Таблица «ProductProductPhoto». Число просмотров 32, логических чтений 96, физических чтений 5, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «Product». Число просмотров 0, логических чтений 64, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «ProductDocument». Число просмотров 1, логических чтений 3, физических чтений 1, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Время работы SQL Server:
Время ЦП = 15 мс, затраченное время = 35 мс.
Здесь стоит обратить внимание на время компиляции и текст «логических чтений 96, физических чтений 5». При втором и последующих выполнениях одного и того же запроса — физические чтения могут уменьшаться, а повторная компиляция может не потребоваться. Из-за этого часто возникает ситуация, что второй и последующие разы запрос выполняется быстрее чем первый. Причина, как вы поняли, в кэшировании данных и скомпилированных планов запросов. - Еще полезная кнопочка рядом с кнопками планов — «Include Client Statistics» — выводит информацию по сетевому обмену, количестве выполненных операций и суммарном времени выполнения, с учетом затрат на сетевой обмен и обработку клиентом.
Пример, на котором видно что первое выполнение занимает больше времени
- В SSMS 2016 версии появилась кнопка «Include Live Query Statistics». Отображает картинку как и в случае с планом запроса, только на ней цифры обработанных строк не статические, а меняются на экране прямо в процессе выполнения запроса. Картинка получается очень наглядная — по мигающим стрелкам и бегущим цифрам сразу видно где тратится время. Кнопка есть в 2016 студии, но работает с серверами начиная с 2014 версии.
Подытожим первую часть:
- Затраты процессора смотрим используя SET STATISTICS TIME ON.
- Дисковые операции: SET STATISTICS IO ON. Не забываем, что «логическое чтение» — это операция чтения, завершившаяся в кэше диска без физического обращения к дисковой системе. «Физическое чтение» требует значительно больше времени.
- Объем сетевого трафика оцениваем с помощью «Include Client Statistics».
- Детально алгоритм выполнения запроса анализируем по «плану выполнения» с помощью «Include Actual Execution Plan» и «Include Live Query Statistics».
Анализируем нагрузку от приложения
Для второго раздела вооружаемся profiler-ом. После запуска и подключения к серверу, необходимо выбрать журналируемые события. Можно пойти простым путем — запустить профилирование со стандартным темплэйтом трассировки. На закладке «General» в поле «Use the template» выбрать «Standard (default)» и нажать «Run».
Картинка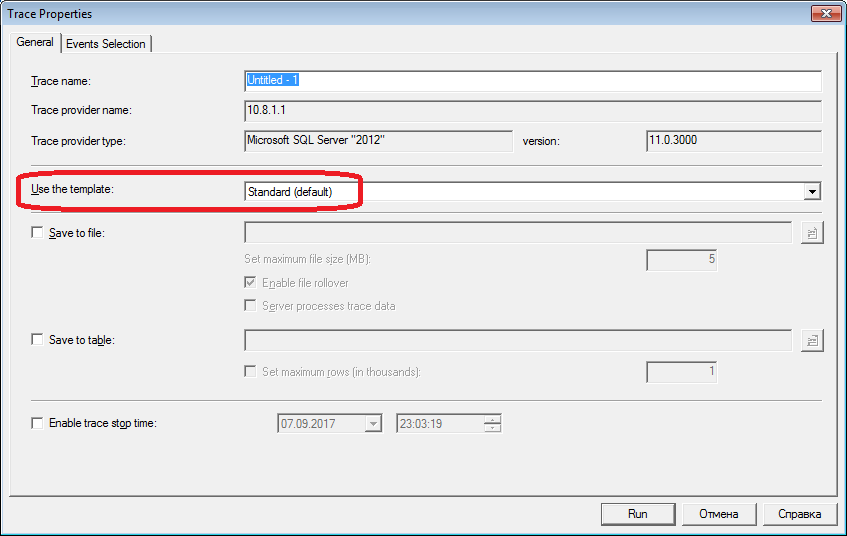
Чуть более сложный путь — к выбранному шаблону добавить (или убавить) фильтров или событий. Данные опции на второй закладке диалога. Чтобы увидеть полный набор возможных событий и колонок для выбора — отметьте пункты «Show All Events» и «Show All Columns».
Картинка
Из событий нам потребуются (лишние лучше не включать — чтобы создавать меньше трафика):
- Stored Procedures \ RPC:Completed
- TSQL \ SQL:BatchCompleted
Эти события фиксируют все внешние sql-вызовы к серверу. Они возникают, как видно из названия (Completed), после окончания обработки запроса. Имеются аналогичные события фиксирующие старт sql-вызова:
- Stored Procedures \ RPC:Starting
- TSQL \ SQL:BatchStarting
Но они нам подходят меньше, так как не содержат информации о затраченных на выполнение запроса ресурсах сервера. Очевидно, что такая информация доступна только по окончании выполнения. Соответственно, столбцы с данными по CPU, Reads, Writes в событиях *Starting будут пустыми.
Еще полезные события, которые мы пока не будем включать:
- Stored Procedures \ SP:Starting (*Completed) — фиксирует внутренний вызов хранимой процедуры (не с клиента, а внутри текущего запроса или другой процедуры).
- Stored Procedures \ SP:StmtStarting (*Completed) — фиксирует старт каждого выражения внутри хранимой процедуры. Если в процедуре цикл — будет столько событий для команд внутри цикла, сколько итераций было в цикле.
- TSQL \ SQL:StmtStarting (*Completed) — фиксирует старт каждого выражения внутри SQL-batch. Если ваш запрос содержит несколько команд — будет по событию на каждую. Т.е. аналогично предыдущему, только действует не для команд внутри процедур, а для команд внутри запроса.
Эти события удобны для отслеживания шагов выполнения. Например, когда использование отладчика невозможно.
По колонкам
Какие выбирать, как правило, понятно из названия колонки. Нам будут нужны:
- TextData, BinaryData — для описанных выше событий содержат сам текст запроса.
- CPU, Reads, Writes, Duration — данные о затратах ресурсов.
- StartTime, EndTime — время начала/окончания выполнения. Удобны для сортировки.
Прочие колонки добавляйте на свой вкус.
По кнопке «Column Filters...» можно вызвать диалог установки фильтров событий. Если интересует активность конкретного пользователя — задать фильтр по номеру сессии или имени пользователя. К сожалению, в случае подключения приложения через app-server c пулом коннектов — отследить конкретного пользователя сложнее.
Фильтры можно использовать, например, для отбора только «тяжелых» запросов (Duration>X). Или запросов которые вызывают интенсивную запись (Writes>Y). Да хоть просто по содержимому запроса.
Что же еще нам нужно от профайлера? Конечно же план выполнения!
Такая возможность имеется. Необходимо добавить в трассировку событие «Performance \ Showplan XML Statistics Profile». Выполняя наш запрос, мы получим примерно следующую картинку.
Текст запроса
План выполнения
И это еще не всё
Трассу можно сохранять в файл или таблицу БД (а не только выводить на экран).
Настройки трассировки можно сохранить в виде личного template для быстрого запуска.
Запуск трассировки можно выполнять и без профайлера — с помощью t-sql кода, используя процедуры: sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Пример как это сделать. Данный подход может пригодиться, например, для автоматического старта записи трассы в файл по расписанию. Как именно использовать эти команды, можно подсмотреть у самого профайлера. Достаточно запустить две трассировки и в одной отследить что происходит при старте второй. Обратите внимание на фильтр по колонке «ApplicationName» — проконтролируйте, что там отсутствует фильтр на сам профайлер.
Список событий фиксируемых профайлером очень обширен и не ограничивается только получением текстов запросов. Имеются события фиксирующие fullscan, рекомпиляции, autogrow, deadlock и многое другое.
Анализируем активность пользователей в целом по серверу
Жизненные ситуации бывают и такими, когда информация из разделов выше не помогает:
Какой-то запрос висит на «выполнении» очень долго и непонятно, закончится он когда-нибудь или нет. Проанализировать проблемный запрос отдельно — хотелось бы — но надо сначала определить что за запрос. Профайлером ловить бесполезно — starting событие мы уже пропустили, а completed неясно сколько ждать.
А может висит и не пользовательский запрос совсем, а может это сам сервер что-то активно делает…
Давайте разбираться
Все вы наверно видели «Activity Monitor». В старших студиях его функционал стал богаче. Чем он может нам помочь? В «Activity Monitor» много полезного и интересного, но третий раздел не о нем. Всё что нужно будем доставать напрямую из системных представлений и функций (а сам Монитор полезен тем, что на него можно натравить профайлер и посмотреть какие запросы он выполняет).
Нам понадобятся:
- sys.dm_exec_sessions — информация о сессиях. Отображает информацию по подключенным пользователям. Полезные поля (в рамках этой статьи) — идентифицирующие пользователя (login_name, login_time, host_name, program_name, ...) и поля с информацией о затраченных ресурсах (cpu_time, reads, writes, memory_usage, ...)
- sys.dm_exec_requests — информация о запросах выполняющихся в данный момент. Полей тут тоже довольно много, рассмотрим только некоторые:
- session_id — код сессии для связи с предыдущим представлением
- start_time — время старта запроса
- command — это поле, вопреки названию, содержит не запрос, а тип выполняемой команды. Для пользовательских запросов — обычно это что-то вроде select/update/delete/и т.п. (также, важные примечания ниже)
- sql_handle, statement_start_offset, statement_end_offset — информация для получения текста запроса: хэндл, а также начальная и конечная позиция в тексте запроса — обозначающая часть выполняемую в данный момент (для случая когда ваш запрос содержит несколько команд).
- plan_handle — хэндл сгенерированного плана.
- blocking_session_id — при возникновении блокировок препятствующих выполнению запроса — указывает на номер сессии которая стала причиной блокировки
- wait_type, wait_time, wait_resource — поля с информацией о причине и длительности ожидания. Для некоторых видов ожидания, например, блокировка данных — дополнительно указывается код заблокированного ресурса.
- percent_complete — по названию понятно, что это процент выполнения. К сожалению, доступен только для команд у которых четко прогнозируемый прогресс выполнения (например, backup или restore).
- cpu_time, reads, writes, logical_reads, granted_query_memory — затраты ресурсов.
- sys.dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) — функции получения текста и плана запроса. Ниже рассмотрим пример использования.
- sys.dm_exec_query_stats — сводная статистика выполнения в разрезе запросов. Показывает какой запрос сколько раз выполнялся и сколько ресурсов на это потрачено.
Важные примечания
Приведенный перечень — лишь малая часть. Полный список всех системных представлений и функций описан в документации. Также, имеется схема связей основных объектов в виде красивой картинки — можно распечатать на А1 и повесить на стену.
Текст запроса, его план и статистика исполнения — данные хранящиеся в процедурном кэше. Во время выполнения они доступны. После выполнения доступность не гарантируется и зависит от давления на кэш. Да, кэш можно очищать вручную. Иногда это советуют делать когда «поплыли» планы выполнения, но тут очень много нюансов… В общем, «Имеются противопоказания, рекомендовано проконсультироваться со специалистом».
Поле «command» — для пользовательских запросов оно практически бессмысленно — ведь мы можем получить полный текст… Но не всё так просто. Это поле очень важно для получения информации о системных процессах. Как правило, они выполняют какие-то внутренние задачи и не имеют текста sql. Для таких процессов, информация о команде единственный намек на тип активности. В комментариях к предыдущей статье был вопрос про то, чем занят сервер, когда он, вроде бы, ничем не должен быть занят — возможно ответ будет в значении этого поля. На моей практике, поле «command» для активных системных процессов всегда выдавало что-то вполне понятное: autoshrink/autogrow/checkpoint/logwriter/и т.п.
Как же это использовать
Перейдем к практической части. Я приведу несколько примеров использования, но не стоит ограничивать вашу фантазию. Возможности сервера этим не исчерпываются — можете придумывать что-то своё.
Пример 1: Какой процесс расходует cpu/reads/writes/memory
Для начала, посмотрим какие сессии больше всего потребляют, например, CPU. Информация в sys.dm_exec_sessions. Но данные по CPU (а также reads, writes) — накопительные. Т.е цифра в поле содержит «итого» за все время подключения. Понятно, что больше всего будет у того кто подключился месяц назад, да так и не отключался ни разу. Это вовсе не означает, что он прямо сейчас грузит систему.
Немного кода решает проблему, алгоритм примерно такой:
- сначала сделаем выборку и сохраним во временную таблицу
- затем подождем немного
- делаем выборку второй раз
- сравниваем результаты первой и второй выборки — разница, как раз и будет затратами возникшими на п.2
- для удобства, разницу можем поделить на длительность п.2, чтобы получить усредненные «затраты в секунду».
Пример скрипта
if object_id('tempdb..#tmp') is NULL BEGIN SELECT * into #tmp from sys.dm_exec_sessions s PRINT 'ждем секунду для накопления статистики при первом запуске' -- при последующих запусках не ждем, т.к. сравниваем с результатом предыдущего запуска WAITFOR DELAY '00:00:01'; END if object_id('tempdb..#tmp1') is not null drop table #tmp1 declare @d datetime declare @dd float select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp') select * into #tmp1 from sys.dm_exec_sessions s select @dd=datediff(ms,@d,getdate()) select @dd AS [интервал времени, мс] SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name, s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec, s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec, s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec, s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec, s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec, s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D], s.nt_user_name,s.nt_domain from #tmp1 s LEFT join #tmp t on s.session_id=t.session_id order BY cpu_Diff desc --totIO_Diff desc --logical_reads_Diff desc drop table #tmp GO select * into #tmp from #tmp1 drop table #tmp1
В коде я использую две таблицы: #tmp — для первой выборки, #tmp1 — для второй. При первом запуске, скрипт создает и заполняет #tmp и #tmp1 с интервалом в одну секунду, и делает остальную часть. При последующих запусках, скрипт использует результаты предыдущего выполнения в качестве базы для сравнения. Соответственно, длительность п.2 при последующих запусках будет равна длительности вашего ожидания между запусками скрипта. Пробуйте выполнять, можно сразу на рабочем сервере — скрипт создает только «временные таблицы» (доступны только внутри текущей сессии и самоуничтожаются при отключении) и не несёт в себе опасности.
Те, кто не любят выполнять запрос в студии — могут его завернуть в приложение написанное на своём любимом языке программирования. Я покажу как это сделать в MS Excel без единой строки кода.
В меню «Данные» подключаемся к серверу. Если будет требовать выбрать таблицу — выбираем произвольную — потом поменяем это. Как всегда, жмем «Next» и «Finish» пока не увидим диалог «Импорт данных» — в нем нужно нажать «Свойства...». В свойствах необходимо сменить «тип команды» на значение «SQL» и в поле «текст команды» вставить немного измененный наш запрос.
Запрос придется немного поменять:
- добавим «SET NOCOUNT ON» — т.к. Excel не любит отсечки количества строк;
- «временные таблицы» заменим на «таблицы переменные»;
- задержка всегда будет 1сек — поля с усредненными значениями не нужны
Измененный запрос для Excel
SET NOCOUNT ON; declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint) declare @d datetime; select @d=GETDATE() INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id) SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id from sys.dm_exec_sessions s; WAITFOR DELAY '00:00:01'; declare @dd float; select @dd=datediff(ms,@d,getdate()); SELECT s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name, s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, s.reads-isnull(t.reads,0) as reads_Diff, s.writes-isnull(t.writes,0) as writes_Diff, s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff], s.nt_user_name,s.nt_domain from sys.dm_exec_sessions s left join @tmp t on s.session_id=t.session_id
Картинки процесса

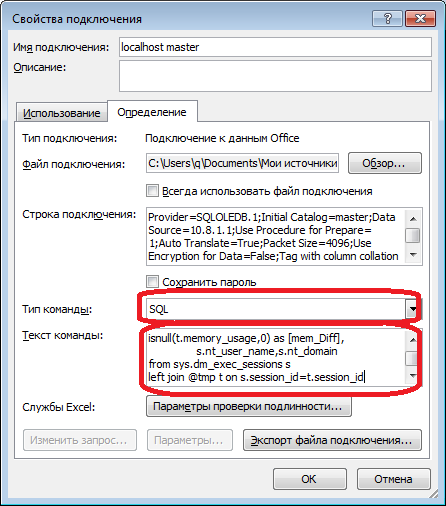
Результат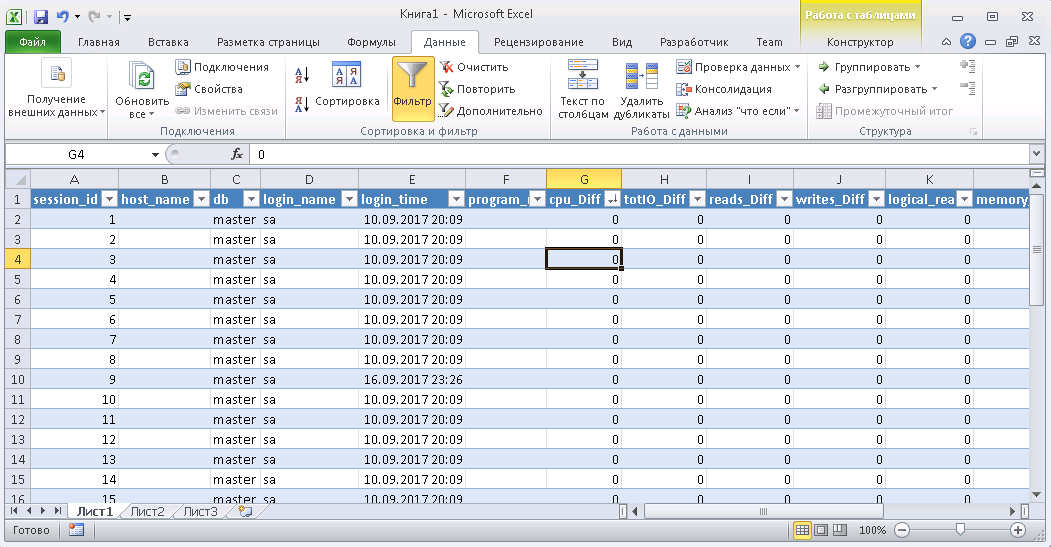
Когда данные будут в Excel-е, можете их сортировать как вам нужно. Для актуализации информации — жмите «Обновить». В настройках книги, для удобства, можете поставить «автообновление» через заданный период времени и «обновление при открытии». Файл можете сохранить и передать коллегам. Таким образом, мы из
Пример 2: На что сессия расходует ресурсы
Итак, в предыдущем примере мы определили проблемные сессии. Теперь определим, что именно они делают. Используем sys.dm_exec_requests, а также функции получения текста и плана запроса.
Текст запроса и план по номеру сессии
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- для инфы по конкретному юзеру - указываем номер сессии SELECT @sid=182 -- получаем переменные состояния для дальнейшей обработки IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE der.session_id=@sid --печатаем текст выполняемого запроса DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- выводим план выполняемого батча/процы IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- и план выполняемого запроса в рамках батча/процы IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Подставляйте в запрос номер сессии и выполняйте. После выполнения, на закладке «Results» будут планы (два: первый для всего запроса, второй для текущего шага — если шагов в запросе несколько), на закладке «Messages» — текст запроса. Для просмотра плана — необходимо кликнуть в строке на текст оформленный в виде url. План откроется в отдельной закладке. Иногда бывает что план открывается не в графическом виде, а в виде xml-текста. Это, скорее всего, связано с тем что версия студии ниже чем сервера. Попробуйте пересохранить полученный xml в файл с расширением sqlplan, предварительно удалив из первой строки упоминания «Version» и «Build», а затем отдельно открыть его. Если и это не помогает — напоминаю, что 2016 студия официально доступна бесплатно на сайте MS.
Картинки

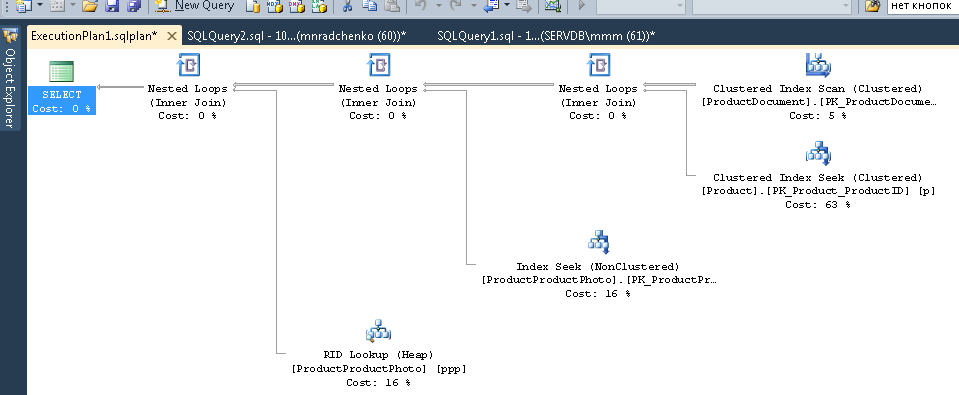
Очевидно, полученный план будет «оценочным», т.к. запрос еще выполняется. Но некоторую статистику по выполнению получить всё равно можно. Используем представление sys.dm_exec_query_stats с фильтром по нашим хэндлам.
Допишем в конец предыдущего запроса
-- статистика по плану IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE QS.sql_handle=@sql_handle
После выполнения, в результатах получим информацию о шагах выполняемого запроса: сколько раз они выполнялись и какие ресурсы потрачены. Информация в статистику попадает после выполнения — при первом выполнении там, к сожалению, пусто. Статистика не привязана к пользователю, а ведется в рамках всего сервера — если разные пользователи выполняют один и тот же запрос — статистика будет суммарная по всем.
Пример 3: А можно всех посмотреть
Давайте объединим рассмотренные системные представления и функции в одном запросе. Это может быть удобно для оценки ситуации в целом.
-- получаем список всех текущих запросов SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
Запрос выводит список активных сессий и тексты их запросов. Для системных процессов, напоминаю, обычно запрос отсутствует, но заполнено поле «command». Видна информация о блокировках и ожиданиях. Можете попробовать скрестить этот запрос с примером 1, чтобы еще и отсортировать по нагрузке. Но будьте аккуратны — тексты запросов могут оказаться очень большими. Выбирать их массово может оказаться ресурсоемко. Да и трафик будет большим. В примере я ограничил получаемый запрос первыми 500 символами, а получение плана не стал делать.
Примеры запросов выложил на гитхаб.
Заключение
Было бы ещё неплохо, получить Live Query Statistics для произвольной сессии. По заявлению производителя, на текущий момент, постоянный сбор статистики требует значительных ресурсов и поэтому, по умолчанию, отключен. Включить не проблема, но дополнительные манипуляции усложняют процесс и уменьшают практическую пользу. Возможно, попробуем это сделать в отдельной статье.
В этой части мы рассмотрели анализ действий пользователей. Попробовали несколько способов: используя возможности самой студии, используя профайлер, а также прямые обращения к системным представлениям. Все эти способы позволяют оценить затраты на выполнение запроса и получить план исполнения. Ограничиваться одним из них не нужно — каждый способ удобен в своей ситуации. Пробуйте комбинировать.
Впереди у нас еще анализ нагрузки на память и сеть, а также прочие нюансы. Дойдем и до них. Материала еще на несколько статей.
Спасибо Владу за помощь в создании статьи.
