
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Неплохо!
Спасибо!
Оно файлы к себе затягивает или просто строит индекс?
Ambar затягивает к себе все файлы и хранит у себя
Доступ к файлу напрямую осуществляется или проксируется?
Доступ к файлу через Ambar из его базы данных
Что если у пользователя нет праа на какую-то папку?
В настройках краулера можно указать из под какой учетки ходить. Во время поиска нет разделения файлов по правам
Ambar затягивает к себе все файлы и хранит у себя
Ну если ваши секретари уже отсканировали все документы то все просто — натравливаете на эту папку Ambar, он автоматически распознает текст со сканов и позволяет по нему искать. Вот скриншот как это выглядит: 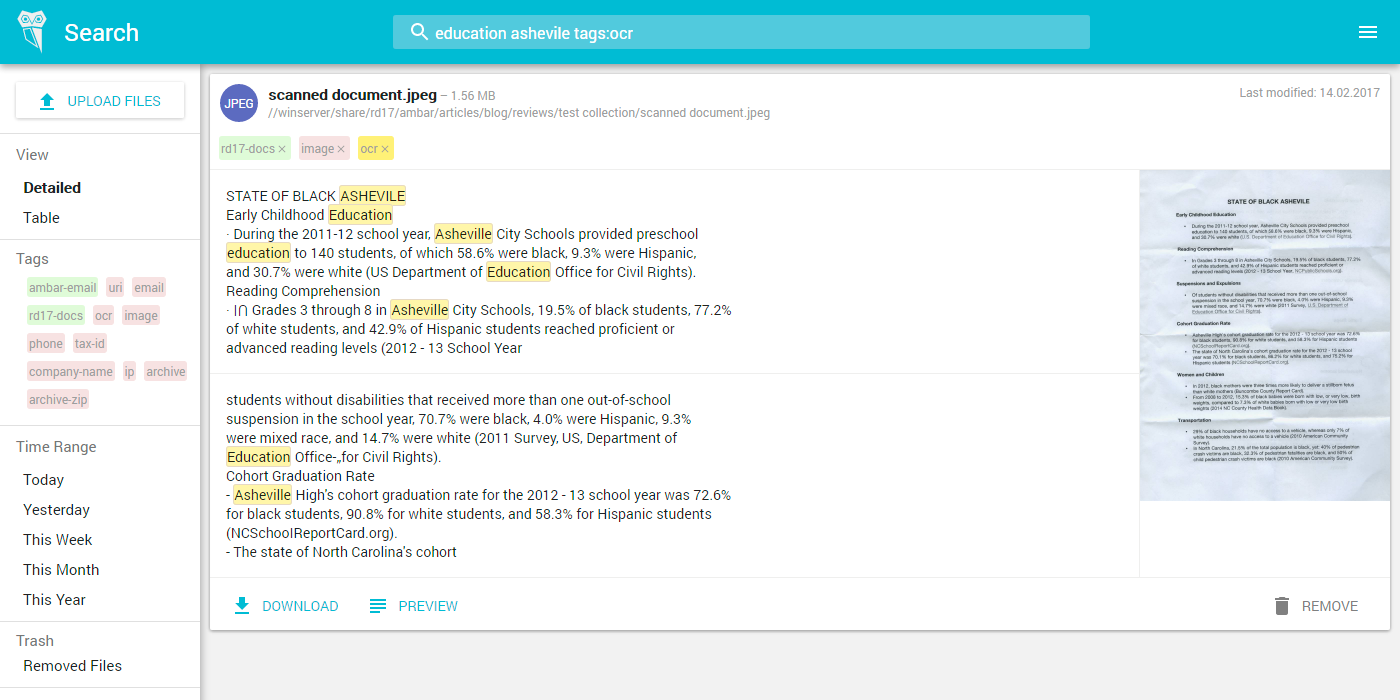
Прошу прощения за интимный вопрос, а что это вообще за рабочий процесс в котором несколько человек сканят в одну папку?
Просто мы делаем программу для работы с хотфолдерами и мне интересны пользовательские кейсы в этой области.
Если, конечно же, это не секретно.
Заранее спасибо.
Докер-докер-докер-докер-докер. Убунту-убунту-убунту-убунту-убунту.
А если я хочу, например, на macOS развернуть это все? Или на OpenBSD? Или на RHEL? А ничего, говорят мне авторы этого проекта, ставь убунту и разворачивай там докер, потому что это стильно-модно-молодежно.
Нет ничего более идиотского, чем ПО, которое безальтернативно распространяется в виде докер-контейнера.
Я вас не понял, про какой золотой образ вы говорите?
мы решились на создание своего продукта, конечно же open-source'ного.
А проект хороший, да.
Только вот он ни разу не "open source", там fair source с "Use Limitation: 1 user". Так что "хороший" при наличии массы разумных open source альтернатив — по-моему, преувеличение.
Я не уверен насчет gpl'ных, но там все как-то весьма сурово, да. Как минимум, у них в лицензировании должен быть отдельный (и большой, по идее, учитывая Docker) файлик с кучей всяких лицензий хотя бы на всякое такое. Впрочем, конкретно проект ambar-crawler у них вообще без явно указанной лицензии.
Тщательно настроенный tesseract
Да, проблема появляется, когда захочешь это на NAS поставить. Идея хороша, но реализация хромает (как с сисадминской стороны — докерпомойка, так и с программной — хранение всех файлов в кастомной бд дубликатом)
Интересно, а вы контрибьютите в проекты, которые используете? Как-то учитываете лицензии проектов, на которые опираетесь?
Например, я не вижу файла с перечислением лицензий зависимостей от слова совсем. Как минимум, часть зависимостей у вас под Apache License v2, но никакого указания этого я не вижу.
Ну и хвалиться тем, что у вас "Поддержка всех офисных форматов (в т.ч. openoffice), pdf с картинками и старых кодировок вроде CP866" довольно глупо, это есть у всех кто использует Apache Tika. Собственно, поддержку cp866/ibm866 я добавлял когда-то ради лексиконовских файлов.
Мгновенно искать по именам файлов умеет everything (voidtools.com). Строит индекс, к себе ничего не копирует, умеет прикидываться http- и ftp-сервером.
Поиск документов в сетевых шарах и файловых помойках