У одного из наших достаточно крупных клиентов, в системе электронного документооборота которого ежедневно одновременно работают более 10000 пользователей, были применены так называемые sparse-колонки или разреженные столбцы.
Статья – попытка свести предпосылки и результаты применения этой функциональности (и некоторых других настроек СУБД) в едином месте.
Для погружения в тему пара слов о системе: система представляет из себя продукт разработка которого началась в 2000-х. На текущий момент система активно развивается. Продукт имеет клиент-северную архитектуру с несколькими серверами приложений.
В качестве серверной стороны используется СУБД Microsoft SQL Server.
C учетом того, что система уже не «новичок», в структуре БД есть соответствующие механизмы/опции/объекты, использование которых на текущий момент выглядит необоснованным и устаревшим. Постепенно идет отказ от этих объектов, но встречаются ситуации, когда они до сих пор используются.
На очередном из аудитов производительности совместно с Заказчиком обратили внимание на быстрый рост одной из таблиц (назовем ее таблицей X). Объем таблицы X без малого составлял более 350 ГБ (к слову объем всей БД составляет порядка ~2ТБ). При этом распределение по собственно данным таблицы и индексам было следующим:
Т.е. ситуация достаточно незаурядная, когда индексов на таблице больше самих данных примерно в ~2 раза. Т.е. получаем достаточно высокие накладные расходы, которые в свою очередь негативно влияют на:
По-крупному схему работы СУБД можно описать следующим образом: все данные перед обработкой загружаются с дисков в буферный пул (кэш). Это позволяет сократить число дисковых операций и ускорить обработку наиболее частоиспользуемых данных. Более детально с механизмом можно ознакомиться, например, в статье. Эффективность использования буферного пула косвенно можно отследить с помощью счетчика Page Life Expectancy – время жизни страницы в буферном пуле.
В интервале в несколько месяцев выявили негативную динамику по уменьшению времени жизни страницы в буферном пуле.
Бездействие могло привести к:
Как итог было принято решение провести анализ причин.
Поскольку система в эти месяцы не была статичной и постоянно модифицировалась, анализ решили начать с содержимого буферного пула. Для этого использовали данные динамического представления: sys.dm_os_buffer_descriptors.
Пример запроса:
При объеме буферного пула в ~185 ГБ порядка 80-90 ГБ составляли данные кластерного индекса нашей проблемной таблицы X. Объем остальной части буферного пула был распределен между индексами достаточно равномерно. Из этого следовало, что максимальный эффект можно было бы получить, оптимизировав каким-то образом данные таблицы X (в данном случае речь о ее кластерном индексе).
Практика показывает накопление большого объема данных в единственной таблице рано или поздно скажется на производительности, если не всех, то по крайней мере части операций, связанных с этой таблицей. Ситуация нелинейно усугубляется при большом числе столбцов в этой таблице.
Кроме того, когда проанализировали таблицу X на предмет заполненности данными, увидели следующую картину: для практически всех строк заполненным был только определенный набор столбцов (за счет чего достигается гибкость системы и адаптация под конкретные бизнес-требования). Что по сути снова приводит к низкой эффективности хранения и обработки данных, т.к. часть ячеек не хранит информации, но тем не менее, место под эти ячейки резервируется (например, добавление пустого столбца с типом данных int увеличит расходы на хранение таблицы как минимум на [4 байта * кол-во строк в таблице]).
С учетом всех исходных данных представленных выше было выделено 4 направления для дальнейшей проработки:
Вот что нам говорит официальная документация:
«Фильтруемый индекс — это оптимизированный некластеризованный индекс, особенно подходящий для запросов, осуществляющих выборку из хорошо определенного подмножества данных…Хорошо спроектированный фильтруемый индекс позволяет повысить производительность запросов, а также снизить затраты на обслуживание и хранение индексов по сравнению с «полнотабличными» индексами».
Если сказать чуть проще, то речь о возможности создания индекса только для части данных в таблице, например, мы можем создать индекс в таблице X под конкретный бизнес-кейс.
Но для применения индекса необходимо было использовать новую версию ПО, в которой была изменена в том числе структура БД. В частности, в новой версии были изменены значения параметров соединения клиентского ПО с СУБД на режим ON:
Но в нашем случае обновление было запланировано через полгода, а ждать столько времени мы не могли. Более того, использовать фильтрованные индексы также не предполагалось, т.к. это делало неэффективным, например, использование опции принудительной параметризации.
Поскольку у клиента была установлена версия СУБД – 2012, то сжатие данных для этой версии возможно двух видов:
Если рассматривать версию SQL 2016 – есть некоторые изменения, но в нашем случае они были также неактуальны (переход на следующую версию SQL на мощном железе достаточно затратен с финансовой точки зрения). Поэтому остановились на первых двух детальнее.
Согласно документации сжатие на уровне страниц является более ресурсоемкой операцией для CPU, чем сжатие на уровне строк. Исходя из этого вариант сжатия на уровне страниц был отброшен сразу.
Далее была попытка использовать row compression, но в документации также наткнулись на упоминание о том, что даже оно расходует дополнительные ресурсы. А так как процессор – ресурс весьма ограниченный, то от этого варианта также пришлось отказаться.
Разреженные столбцы — это обычные столбцы, имеющие оптимизированное хранилище для значений NULL. Разреженные столбцы уменьшают пространство, необходимое для хранения значений NULL, однако увеличивается стоимость получения значений, отличных от NULL.
Для достижения положительного эффекта в каждом конкретном столбце должен быть определенный процент NULL-значений. Этот процент зависит от типа данных в столбце, например:
При этом не каждый столбец м.б. переведен в sparse. Список ограничений и несовместимостей приведен в официальной документации.
Т.е. для оценки возможности перевода в sparse по-крупному необходимо было проанализировать:
Сделать это помог запрос, текст которого доступен по ссылке ниже. Сам запрос на больших объемах выполняется достаточно долго, рекомендуется указывать конкретную таблицу которую вам необходимо проанализировать.
Далее из полученного списка необходимо определить колонки максимально удовлетворяющие нашим условиям (с мах показателями NULL-значений) и изменить их на sparse. Само изменение лучше лучше делать в single_user режиме БД для исключения возникновения длительных блокировок. После перевода столбца в sparse необходимо выполнить ребилд индекса, только после этого можно будет увидеть изменение размера таблицы.
Особо отмечу, использование механизма не повышает загрузку процессора сервера СУБД (проверяли как на практике, так и нагрузочном тестировании).
Пожалуй, это одна из тех редких ситуаций, которую кратко можно изобразить следующими картинками:
В данном случае работы можно было также разбить на блоки:
Оба пункта являются достаточно дорогостоящими и разделение таблицы было последним в списке возможных оптимизаций. Все это могло затянуться на неопределенное время.
К слову реализация этого пункта на текущий момент не потребовалась. Хорошо это или плохо с точки зрения развития продукта в целом, думаю покажет время…
Ну и вместо выводов хотелось бы отметить в цифрах положительные моменты применения sparse-колонок:
Если свести данные в таблицу получим:
Тем не менее, кроме плюсов появились и ограничения:
Детальнее полный список ограничений можно прочесть здесь.
Если вы дочитали статью до конца, то, перед тем как выполнить любую из настроек, представленных выше помните, что автор данной статьи не несет никакой ответственности за возможную потерю или порчу Ваших данных. Не забывайте делать резервные копии.
Возможно кто-то уже применял настройки описанные в статье на высоконагруженных системах, отписывайтесь к каким результатам пришли вы.
Статья – попытка свести предпосылки и результаты применения этой функциональности (и некоторых других настроек СУБД) в едином месте.
Проблемы и предпосылки
Для погружения в тему пара слов о системе: система представляет из себя продукт разработка которого началась в 2000-х. На текущий момент система активно развивается. Продукт имеет клиент-северную архитектуру с несколькими серверами приложений.
В качестве серверной стороны используется СУБД Microsoft SQL Server.
C учетом того, что система уже не «новичок», в структуре БД есть соответствующие механизмы/опции/объекты, использование которых на текущий момент выглядит необоснованным и устаревшим. Постепенно идет отказ от этих объектов, но встречаются ситуации, когда они до сих пор используются.
Предпосылка №1
На очередном из аудитов производительности совместно с Заказчиком обратили внимание на быстрый рост одной из таблиц (назовем ее таблицей X). Объем таблицы X без малого составлял более 350 ГБ (к слову объем всей БД составляет порядка ~2ТБ). При этом распределение по собственно данным таблицы и индексам было следующим:
- данных было порядка 115 ГБ,
- весь остальной объем ~235 ГБ приходился на индексы.
Т.е. ситуация достаточно незаурядная, когда индексов на таблице больше самих данных примерно в ~2 раза. Т.е. получаем достаточно высокие накладные расходы, которые в свою очередь негативно влияют на:
- длительность операций вставки/обновления данных в этой таблице (чем больше индексов, тем «дороже» операция);
- длительность сервисных операций по обслуживанию(ребилду) этих индексов;
- длительность времени резервного копирования и восстановления БД в случае сбоя;
- повышаются требования к дисковому пространству в части объема.
Предпосылка №2
По-крупному схему работы СУБД можно описать следующим образом: все данные перед обработкой загружаются с дисков в буферный пул (кэш). Это позволяет сократить число дисковых операций и ускорить обработку наиболее частоиспользуемых данных. Более детально с механизмом можно ознакомиться, например, в статье. Эффективность использования буферного пула косвенно можно отследить с помощью счетчика Page Life Expectancy – время жизни страницы в буферном пуле.
В интервале в несколько месяцев выявили негативную динамику по уменьшению времени жизни страницы в буферном пуле.
Бездействие могло привести к:
- значительному увеличению нагрузки на дисковую подсистему;
- увеличению длительности пользовательских операций.
Как итог было принято решение провести анализ причин.
Поскольку система в эти месяцы не была статичной и постоянно модифицировалась, анализ решили начать с содержимого буферного пула. Для этого использовали данные динамического представления: sys.dm_os_buffer_descriptors.
Пример запроса:
Into_BufferPool
SELECT indexes.name AS index_name, objects.name AS object_name, objects.type_desc AS object_type_description, COUNT(*) AS buffer_cache_pages, COUNT(*) * 8 / 1024 AS buffer_cache_used_MB FROM sys.dm_os_buffer_descriptors INNER JOIN sys.allocation_units ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id INNER JOIN sys.partitions ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3)) OR (allocation_units.container_id = partitions.partition_id AND type IN (2))) INNER JOIN sys.objects ON partitions.object_id = objects.object_id INNER JOIN sys.indexes ON objects.object_id = indexes.object_id AND partitions.index_id = indexes.index_id WHERE allocation_units.type IN (1,2,3) AND objects.is_ms_shipped = 0 AND dm_os_buffer_descriptors.database_id = DB_ID() GROUP BY indexes.name, objects.name, objects.type_desc ORDER BY COUNT(*) DESC;
При объеме буферного пула в ~185 ГБ порядка 80-90 ГБ составляли данные кластерного индекса нашей проблемной таблицы X. Объем остальной части буферного пула был распределен между индексами достаточно равномерно. Из этого следовало, что максимальный эффект можно было бы получить, оптимизировав каким-то образом данные таблицы X (в данном случае речь о ее кластерном индексе).
Предпосылка №3
Практика показывает накопление большого объема данных в единственной таблице рано или поздно скажется на производительности, если не всех, то по крайней мере части операций, связанных с этой таблицей. Ситуация нелинейно усугубляется при большом числе столбцов в этой таблице.
Кроме того, когда проанализировали таблицу X на предмет заполненности данными, увидели следующую картину: для практически всех строк заполненным был только определенный набор столбцов (за счет чего достигается гибкость системы и адаптация под конкретные бизнес-требования). Что по сути снова приводит к низкой эффективности хранения и обработки данных, т.к. часть ячеек не хранит информации, но тем не менее, место под эти ячейки резервируется (например, добавление пустого столбца с типом данных int увеличит расходы на хранение таблицы как минимум на [4 байта * кол-во строк в таблице]).
Варианты решения/исправления
С учетом всех исходных данных представленных выше было выделено 4 направления для дальнейшей проработки:
- фильтрованные индексы (filtered indexes);
- сжатие данных средствами СУБД (data compression);
- разреженные столбцы (sparse columns);
- разделение таблицы X на несколько более мелких таблиц.
Фильтрованные индексы
Вот что нам говорит официальная документация:
«Фильтруемый индекс — это оптимизированный некластеризованный индекс, особенно подходящий для запросов, осуществляющих выборку из хорошо определенного подмножества данных…Хорошо спроектированный фильтруемый индекс позволяет повысить производительность запросов, а также снизить затраты на обслуживание и хранение индексов по сравнению с «полнотабличными» индексами».
Если сказать чуть проще, то речь о возможности создания индекса только для части данных в таблице, например, мы можем создать индекс в таблице X под конкретный бизнес-кейс.
Но для применения индекса необходимо было использовать новую версию ПО, в которой была изменена в том числе структура БД. В частности, в новой версии были изменены значения параметров соединения клиентского ПО с СУБД на режим ON:
- SET ANSI_NULLS ON;
- SET QUOTED_IDENTIFIER ON;
- SET CONCAT_NULL_YIELDS_NULL ON.
Но в нашем случае обновление было запланировано через полгода, а ждать столько времени мы не могли. Более того, использовать фильтрованные индексы также не предполагалось, т.к. это делало неэффективным, например, использование опции принудительной параметризации.
Сжатие данных
Поскольку у клиента была установлена версия СУБД – 2012, то сжатие данных для этой версии возможно двух видов:
- cжатие на уровне страниц (page compression);
- сжатие на уровне строк (row compression).
Если рассматривать версию SQL 2016 – есть некоторые изменения, но в нашем случае они были также неактуальны (переход на следующую версию SQL на мощном железе достаточно затратен с финансовой точки зрения). Поэтому остановились на первых двух детальнее.
Согласно документации сжатие на уровне страниц является более ресурсоемкой операцией для CPU, чем сжатие на уровне строк. Исходя из этого вариант сжатия на уровне страниц был отброшен сразу.
Далее была попытка использовать row compression, но в документации также наткнулись на упоминание о том, что даже оно расходует дополнительные ресурсы. А так как процессор – ресурс весьма ограниченный, то от этого варианта также пришлось отказаться.
Разреженные столбцы
Разреженные столбцы — это обычные столбцы, имеющие оптимизированное хранилище для значений NULL. Разреженные столбцы уменьшают пространство, необходимое для хранения значений NULL, однако увеличивается стоимость получения значений, отличных от NULL.
Для достижения положительного эффекта в каждом конкретном столбце должен быть определенный процент NULL-значений. Этот процент зависит от типа данных в столбце, например:
| Тип данных | Неразреженные байты | Разреженные байты | Процент значений NULL |
|---|---|---|---|
| float | 4 | 8 | 64% |
| datetime | 8 | 12 | 52% |
| varchar | 8 | 12 | 52% |
| int | 2 | 4 | 60% |
При этом не каждый столбец м.б. переведен в sparse. Список ограничений и несовместимостей приведен в официальной документации.
Т.е. для оценки возможности перевода в sparse по-крупному необходимо было проанализировать:
- наличие ограничений из документации на конкретной таблице/столбце;
- реальный процент NULL-значений в этих столбцах;
Сделать это помог запрос, текст которого доступен по ссылке ниже. Сам запрос на больших объемах выполняется достаточно долго, рекомендуется указывать конкретную таблицу которую вам необходимо проанализировать.
SparseCandidate
CREATE TABLE #temp ( ColumnName varchar(50), ColumnID int, TableName varchar(50), TableId int, TypeName varchar(50), IsParse bit, IsNullable bit, NumberOfRow bigint, NumberOfRowNULL bigint, Ratio int) SET NOCOUNT ON INSERT into #temp SELECT DISTINCT sys.columns.name ColumnName, sys.columns.column_id ColumnID, OBJECT_NAME(sys.columns.object_id) AS TableName, sys.columns.object_id TableID, CASE systypes.name WHEN 'sysname' THEN 'nvarchar' ELSE systypes.name END AS TypeName, sys.columns.is_sparse IsParse, sys.columns.is_nullable IsNullable, 0,0,0 FROM sys.columns (NoLock) INNER JOIN systypes (NoLock) ON systypes.xtype = sys.columns.system_type_id WHERE sys.columns.object_id = OBJECT_ID('my_table') -- change table name and systypes.name NOT IN ('geography', 'geometry', 'image', 'ntext', 'text', 'timestamp') and sys.columns.is_sparse = 0 and sys.columns.is_nullable = 1 and sys.columns.is_rowguidcol = 0 and sys.columns.is_identity = 0 and sys.columns.is_computed = 0 and sys.columns.is_filestream = 0 and sys.columns.default_object_id = 0 and sys.columns.rule_object_id = 0 and sys.columns.system_type_id=sys.columns.user_type_id delete tps from #temp tps where exists ( select DISTINCT 'Exists' from sys.columns inner join sys.indexes i on i.object_id = tps.TableId inner join sys.index_columns ic on ic.column_id = tps.ColumnID inner join sys.columns c on c.object_id = tps.TableId and ic.column_id = c.column_id where i.type =1 or i.is_primary_key = 1) select count(*) from #temp delete tps from #temp tps inner join sys.partitions p on p.object_id = tps.TableId where p.data_compression<>0; DECLARE @TableName nvarchar(1000) DECLARE @ColumnName nvarchar(1000) DECLARE @vQuery nvarchar(1000) DECLARE @result1 INT DECLARE @result2 INT DECLARE tables_cursor CURSOR FAST_FORWARD FOR SELECT TableName,ColumnName FROM #temp OPEN tables_cursor FETCH NEXT FROM tables_cursor INTO @TableName,@ColumnName WHILE @@FETCH_STATUS = 0 BEGIN -- Search the number of row in a table SET @vQuery = 'SELECT @result1= COUNT(*) FROM [' + @TableName + ']' EXEC SP_EXECUTESQL @Query = @vQuery , @Params = N'@result1 INT OUTPUT' , @result1 = @result1 OUTPUT -- Search the number of row in a table SET @vQuery = 'SELECT @result2= COUNT(*) FROM [' + @TableName + '] where [' + @ColumnName + '] is null' EXEC SP_EXECUTESQL @Query = @vQuery , @Params = N'@result2 INT OUTPUT' , @result2 = @result2 OUTPUT update #temp set NumberOfRow = @result1,NumberOfRowNULL = @result2,Ratio = (@result2*100/@result1) where ColumnName=@ColumnName and TableName=@TableName FETCH NEXT FROM tables_cursor INTO @TableName,@ColumnName END CLOSE tables_cursor DEALLOCATE tables_cursor --delete from #temp where Ratio>10 select * from #temp --drop table #temp
Далее из полученного списка необходимо определить колонки максимально удовлетворяющие нашим условиям (с мах показателями NULL-значений) и изменить их на sparse. Само изменение лучше лучше делать в single_user режиме БД для исключения возникновения длительных блокировок. После перевода столбца в sparse необходимо выполнить ребилд индекса, только после этого можно будет увидеть изменение размера таблицы.
Особо отмечу, использование механизма не повышает загрузку процессора сервера СУБД (проверяли как на практике, так и нагрузочном тестировании).
Пожалуй, это одна из тех редких ситуаций, которую кратко можно изобразить следующими картинками:
Разделение таблицы на более мелкие
В данном случае работы можно было также разбить на блоки:
- внесение изменений в архитектуру системы;
- модификация всей прикладной разработки под новую архитектуру.
Оба пункта являются достаточно дорогостоящими и разделение таблицы было последним в списке возможных оптимизаций. Все это могло затянуться на неопределенное время.
К слову реализация этого пункта на текущий момент не потребовалась. Хорошо это или плохо с точки зрения развития продукта в целом, думаю покажет время…
Эффект от sparse
Ну и вместо выводов хотелось бы отметить в цифрах положительные моменты применения sparse-колонок:
- уменьшили объем кластерного индекса таблицы X в ~2 раза (аналогичный эффект по уменьшению объема м.б. при пересоздании некластерных индексов с key-полями, которые были переведены в sparse);
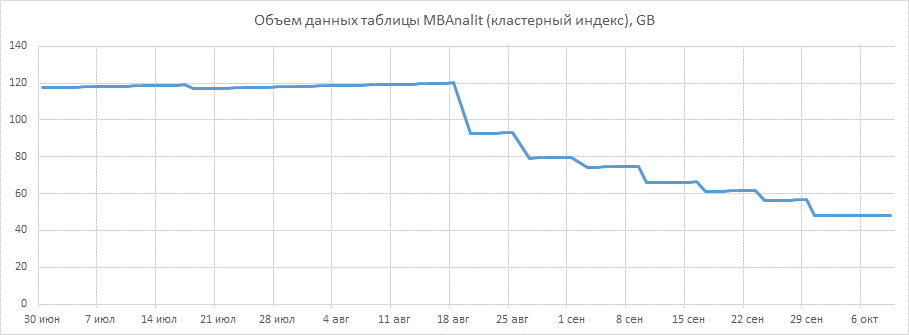
- исходя из п.1 повысилась эффективность использования буферного пула, т.к. уменьшился объем данных таблицы X в буферном пуле;

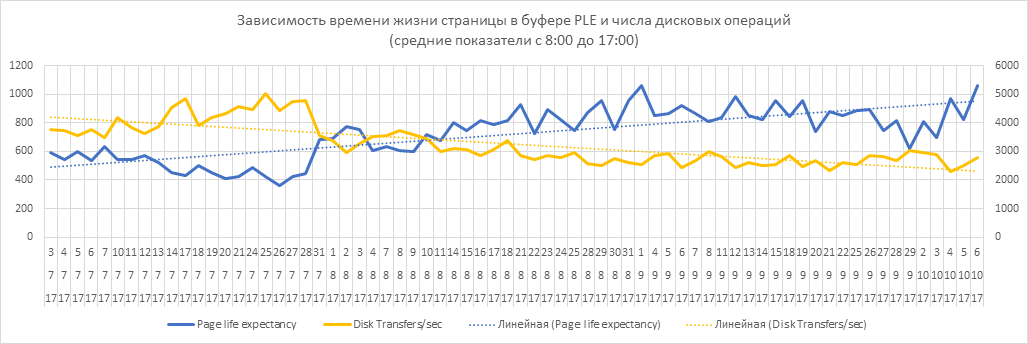
- исходя из п.1-2 увеличилось время жизни страницы в буферном пуле (синия линия), и как следствие уменьшилась нагрузка на диски (желтая линия);
- сократилась длительность части операций, связанных с большими объемами выборки данных, т.к. повысилась вероятность нахождения данных в буферном пуле;
Если свести данные в таблицу получим:
| Показатель | Примечание | |
|---|---|---|
| Объем кластерного индекса таблицы X, ГБ | На диске (HDD) | |
| Размер кластерного индекса таблицы X в буферном пуле, ГБ | В памяти (RAM) | |
| Page Life Expectancy, сек | Время жизни страницы в буферном пуле | |
| Disk Transfers/sec, iops | Число дисковых операций. Нагрузка на СХД уменьшена. |
Ограничения sparse
Тем не менее, кроме плюсов появились и ограничения:
- необходима периодическая актуализация sparse-столбцов. Через какое-то время распределение NULL и не NULL значений в sparse-колонках может измениться и использование sparse будет неоправданным;
- число столбцов, которые можно переводить в sparse ограничено. В случае превышения при обновлении строк может возникнуть ошибка 576.
Детальнее полный список ограничений можно прочесть здесь.
Если вы дочитали статью до конца, то, перед тем как выполнить любую из настроек, представленных выше помните, что автор данной статьи не несет никакой ответственности за возможную потерю или порчу Ваших данных. Не забывайте делать резервные копии.
Возможно кто-то уже применял настройки описанные в статье на высоконагруженных системах, отписывайтесь к каким результатам пришли вы.
