Notepad в windows 10 начал понимать юниксовый перевод строки, а не только формат Windows.
С проблемой «каши» вместо удобочитаемого текста десятилетиями сталкивались те, кто пытался открыть в среде Windows текстовые документы, подготовленные на других операционных системах. Теперь же всё в одночасье изменяется. И это изменение столь же мало, сколь и эпично по своим практическим результатам и идеологическим последствиям. Microsoft вновь пытается играть в кросс-интеграцию и поддержку открытых стандартов.
Долгие годы Windows Блокнот мог нормально отображать только те текстовые документы, которые содержали символы начала новой строки в формате Windows End of Line (EOL) — «возврат каретки» (CR) и «подача на строку» (LF). На деле это приводило к тому, что Notepad не смог правильно отобразить содержимое текстовых файлов, созданных в Unix, Linux и macOS, где в качестве признака конца строки использовался только символ LF.
Например, вот скриншот Notepad, пытающегося отобразить содержимое текстового файла Linux .bashrc, который содержит только символы Unix LF EOL:

А вот скриншот недавно обновленного «Блокнота», отображающего содержимое того же самого файла UNIX / Linux .bashrc, но с правильными переносами:
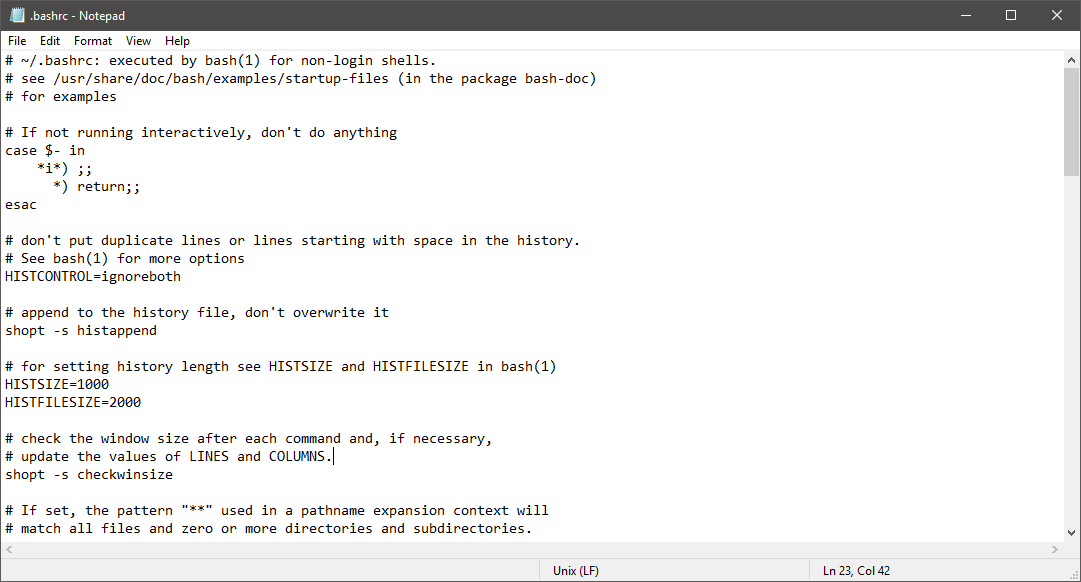
Обратите внимание, что строка состояния указывает обнаруженный формат EOL текущего открытого файла.
Так же для гибкого управления новой возможностью в разделе реестра [HKEY_CURRENT_USER\Software\Microsoft\Notepad] вводятся два дополнительных ключа:

По накалу страстей спор о способе начала новой строки в электронных документах сравним со спором о пробелах и табуляциях в исходных текстах программ. У этого противостояния «за строку» было много причин, как лежащих в области древних стандартов и традиций, так и берущих свои корни в особенностях конструкции печатных машин и телетайпов. Не меньшую роль сыграло и стремление одних программистов буквально выполнять (интерпретировать) команды и управляющие символы, а других — следовать здравому смыслу.
Исторически на механических пишущих машинках был рычаг, который возвращал каретку к левому краю страницы и прокручивал вал, подвигая бумагу вверх на строку. На телетайпах и более поздних алфавитно-цифровых печатающих устройствах (АЦПУ) вместо каретки была головка, в лазерных принтерах она перестала быть материальной, но в термине возврат каретки всё это продолжали называть кареткой, чтобы его не менять. На телетайпах возврат каретки и подачу строки разделили, откуда традиция представления перевода строки как CR+LF перешла и к текстовым файлам.
Системы, основанные на ASCII или совместимом наборе символов, используют или LF (перевод строки, 0x0A), или CR (возврат каретки, 0x0D) по отдельности, или последовательность CR+LF. Эти названия основаны на командах принтера: перевод строки означает, что одна строка на бумаге должна быть перенесена при печати, а возврат каретки означает, что каретка печатающего устройства должна вернуться к началу текущей строки.
По стандарту, любое совместимое с Юникодом приложение должно воспринимать как перевод строки каждый из нижеследующих символов:
Причем, последовательность CR+LF (U+000D U+000A) надлежит воспринимать как один перевод строки, а не два.
Но как известно, стандарты стандартами, а реализации у всех часто выходят разными. И масла в огонь подливает необходимость корректно отображать унаследованные документы, созданные до эпохи юникода. Отсутствие единого общепринятого представления перевода строки в разных операционных системах надолго осложнило обмен текстовыми данными между ними.
Юникод старается примирить эту разницу, уравнивая CR, LF и CR+LF, однако вступает в противоречие с наследуемым им ASCII при трактовке последовательности LF+CR, не предварённой CR: согласно ASCII это один перевод строки, а согласно Юникоду — два.
С проблемой «каши» вместо удобочитаемого текста десятилетиями сталкивались те, кто пытался открыть в среде Windows текстовые документы, подготовленные на других операционных системах. Теперь же всё в одночасье изменяется. И это изменение столь же мало, сколь и эпично по своим практическим результатам и идеологическим последствиям. Microsoft вновь пытается играть в кросс-интеграцию и поддержку открытых стандартов.
Долгие годы Windows Блокнот мог нормально отображать только те текстовые документы, которые содержали символы начала новой строки в формате Windows End of Line (EOL) — «возврат каретки» (CR) и «подача на строку» (LF). На деле это приводило к тому, что Notepad не смог правильно отобразить содержимое текстовых файлов, созданных в Unix, Linux и macOS, где в качестве признака конца строки использовался только символ LF.
Например, вот скриншот Notepad, пытающегося отобразить содержимое текстового файла Linux .bashrc, который содержит только символы Unix LF EOL:
А вот скриншот недавно обновленного «Блокнота», отображающего содержимое того же самого файла UNIX / Linux .bashrc, но с правильными переносами:
Обратите внимание, что строка состояния указывает обнаруженный формат EOL текущего открытого файла.
Так же для гибкого управления новой возможностью в разделе реестра [HKEY_CURRENT_USER\Software\Microsoft\Notepad] вводятся два дополнительных ключа:
По накалу страстей спор о способе начала новой строки в электронных документах сравним со спором о пробелах и табуляциях в исходных текстах программ. У этого противостояния «за строку» было много причин, как лежащих в области древних стандартов и традиций, так и берущих свои корни в особенностях конструкции печатных машин и телетайпов. Не меньшую роль сыграло и стремление одних программистов буквально выполнять (интерпретировать) команды и управляющие символы, а других — следовать здравому смыслу.
Что мы можем узнать о проблеме из Википедии
Исторически на механических пишущих машинках был рычаг, который возвращал каретку к левому краю страницы и прокручивал вал, подвигая бумагу вверх на строку. На телетайпах и более поздних алфавитно-цифровых печатающих устройствах (АЦПУ) вместо каретки была головка, в лазерных принтерах она перестала быть материальной, но в термине возврат каретки всё это продолжали называть кареткой, чтобы его не менять. На телетайпах возврат каретки и подачу строки разделили, откуда традиция представления перевода строки как CR+LF перешла и к текстовым файлам.
Системы, основанные на ASCII или совместимом наборе символов, используют или LF (перевод строки, 0x0A), или CR (возврат каретки, 0x0D) по отдельности, или последовательность CR+LF. Эти названия основаны на командах принтера: перевод строки означает, что одна строка на бумаге должна быть перенесена при печати, а возврат каретки означает, что каретка печатающего устройства должна вернуться к началу текущей строки.
- CR (ASCII 0x0D) использовался в 8-битовых машинах Commodore, машинах TRS-80, Apple II, системах Mac OS до версии 9 и OS-9;
- LF (ASCII 0x0A) используется в Multics, UNIX, UNIX-подобных операционных системах (GNU/Linux, AIX, Xenix, Mac OS X, FreeBSD), BeOS, Amiga UNIX, RISC OS и других;
- CR+LF (ASCII 0x0D 0x0A) используется в DEC RT-11 и большинстве других ранних не-UNIX- и не-IBM-систем, а также в CP/M, MP/M, MS-DOS, OS/2, Microsoft Windows, Symbian OS, протоколах Интернет.
По стандарту, любое совместимое с Юникодом приложение должно воспринимать как перевод строки каждый из нижеследующих символов:
- LF (U+000A): англ. line feed — подача строки <ПС>;
- CR (U+000D): англ. carriage return — возврат каретки <ВК>;
- NEL (U+0085): англ. next line — переход на следующую строку;
- LS (U+2028): англ. line separator — разделитель строк;
- PS (U+2029): англ. paragraph separator — разделитель абзацев.
Причем, последовательность CR+LF (U+000D U+000A) надлежит воспринимать как один перевод строки, а не два.
Но как известно, стандарты стандартами, а реализации у всех часто выходят разными. И масла в огонь подливает необходимость корректно отображать унаследованные документы, созданные до эпохи юникода. Отсутствие единого общепринятого представления перевода строки в разных операционных системах надолго осложнило обмен текстовыми данными между ними.
Юникод старается примирить эту разницу, уравнивая CR, LF и CR+LF, однако вступает в противоречие с наследуемым им ASCII при трактовке последовательности LF+CR, не предварённой CR: согласно ASCII это один перевод строки, а согласно Юникоду — два.
