На прошлом внутреннем митапе Pyrus мы говорили о современных распределенных хранилищах, а Максим Нальский, CEO и основатель Pyrus, поделился первым впечатлением от FoundationDB. В этой статье рассказываем о технических нюансах, с которыми сталкиваешься при выборе технологии для масштабирования хранения структурированных данных.
Когда сервис недоступен пользователям какое-то время, это дико неприятно, но всё же не смертельно. А вот потерять данные клиента — абсолютно недопустимо. Поэтому любую технологию для хранения данных мы скрупулезно оцениваем по двум-трем десяткам параметров. Часть из них диктует текущая нагрузка на сервис.
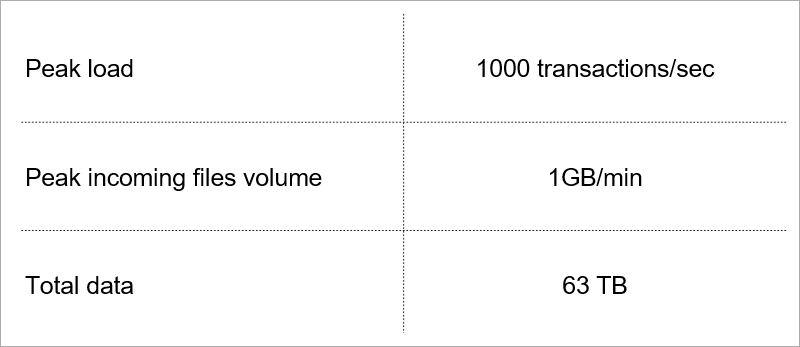 Текущая нагрузка. Технологию подбираем с учётом роста этих показателей.
Текущая нагрузка. Технологию подбираем с учётом роста этих показателей.
Классическая модель клиент-сервер — самый простой пример распределенной системы. Сервер — точка синхронизации, он позволяет нескольким клиентам делать что-то вместе скоординированно.
 Очень упрощенная схема клиент-серверного взаимодействия.
Очень упрощенная схема клиент-серверного взаимодействия.
Что ненадёжно в клиент-серверной архитектуре? Очевидно, сервер может упасть. А когда сервер падает, все клиенты не могут работать. Чтобы этого избежать, люди придумали master-slave подключение (которое теперь политкорректно называют leader-follower). Суть — есть два сервера, все клиенты общаются с главным, а на второй просто реплицируются все данные.
 Клиент-серверная архитектура с репликацией данных на фолловера.
Клиент-серверная архитектура с репликацией данных на фолловера.
Ясно, что это более надёжная система: если основной сервер упадёт, то на фолловере находится копия всех данных и её можно будет быстро поднять.
При этом важно понимать, как устроена репликация. Если она синхронная, то транзакцию нужно сохранять одновременно и на лидере, и на фолловере, а это может быть медленно. Если репликация асинхронная, то можно потерять часть данных после аварийного переключения.
А что будет, если лидер упадет ночью, когда все спят? Данные на фолловере есть, но ему никто не сказал, что он теперь лидер, и клиенты к нему не подключаются. ОК, давайте наделим фолловер логикой, что он начинает считать себя главным, когда связь с лидером потеряна. Тогда легко можем получить split brain — конфликт, когда связь между лидером и фолловером нарушена, и оба думают, что они главные. Это действительно происходит во многих системах, например в RabbitMQ — самой популярной сегодня технологии очередей.
Чтобы решить эти проблемы, организовывают auto failover — добавляют третий сервер (witness, свидетель). Он гарантирует, что у нас только один лидер. А если лидер отваливается, то фолловер включается автоматически с минимальным даунтаймом, который можно снизить до нескольких секунд. Конечно, клиенты в этой схеме должны заранее знать адреса лидера и фолловера и реализовывать логику автоматического переподключения между ними.
 Свидетель гарантирует, что есть только один лидер. Если лидер отваливается, то фолловер включается автоматически.
Свидетель гарантирует, что есть только один лидер. Если лидер отваливается, то фолловер включается автоматически.
Такая система сейчас работает у нас. Есть основная база данных, запасная база данных, есть свидетель и да — иногда мы приходим утром и видим, что ночью произошло переключение.
Но и у этой схемы есть недостатки. Представьте, что вы ставите сервис паки или обновляете ОС на лидер-сервере. До этого вы вручную переключили нагрузку на фолловера и тут… он падает! Катастрофа, ваш сервис недоступен. Что делать, чтобы защититься от этого? Добавляют третий резервный сервер — ещё один фолловер. Три — что-то вроде магического числа. Если вы хотите, чтобы система работала надежно, два сервера недостаточно, нужно три. Один на обслуживании, второй падает, остаётся третий.
 Третий сервер обеспечивает надежную работу, если первые два недоступны.
Третий сервер обеспечивает надежную работу, если первые два недоступны.
Если обобщить, то избыточность должна равняться двум. Избыточности, равной единице, недостаточно. По этой причине в дисковых массивах люди начали вместо RAID5 применять схему RAID6, переживающую падение сразу двух дисков.
Хорошо известны четыре основных требования к транзакциям: атомарность, согласованность, изолированность и долговечность (Atomicity, Consistency, Isolation, Durability — ACID).
Когда мы говорим о распределенных базах данных, то подразумеваем, что данные надо масштабировать. Чтение масштабируется очень хорошо — тысячи транзакций могут читать данные параллельно без проблем. Но когда одновременно с чтением другие транзакции пишут данные, возможны разные нежелательные эффекты. Очень легко получить ситуацию, при которой одна транзакция прочитает разные значения одних и тех же записей. Вот примеры.
Dirty reads. В первой транзакции мы два раза отправляем один и тот же запрос: взять всех пользователей, у которых ID = 1. Если вторая транзакция поменяет эту строчку, а потом сделает rollback, то база данных с одной стороны никаких изменений не увидит, а с другой стороны первая транзакция прочитает разные значения возраста для Joe.

Non-repeatable reads. Другой случай — если транзакция записи завершилась успешно, а транзакция чтения при выполнении одного и того же запроса также получила разные данные.

В первом случае клиент прочитал данные, которые вообще в базе отсутствовали. Во втором случае клиент оба раза прочитал данные из базы, но они отличаются, хотя чтение происходит в рамках одной транзакции.
Phantom reads — это когда мы в рамках одной транзакции повторно читаем какой-нибудь диапазон и получаем разный набор строк. Где-то посередине влезла другая транзакция и вставила или удалила записи.

Чтобы избегать этих нежелательных эффектов, современные СУБД реализуют механизмы блокировок (транзакция ограничивает другим транзакциям доступ к данным, с которыми она сейчас работает) или мультиверсионный контроль версий, MVCC (транзакция никогда не изменяет ранее записанные данные и всегда создает новую версию).
Стандарт ANSI/ISO SQL определяет 4 уровня изоляции транзакций, которые влияют на степень их взаимной блокировки. Чем выше уровень изоляции, тем меньше нежелательных эффектов. Платой за это является замедление работы приложения (поскольку транзакции чаще находятся в ожидании снятия блокировки с нужных им данных) и повышение вероятности deadlocks.
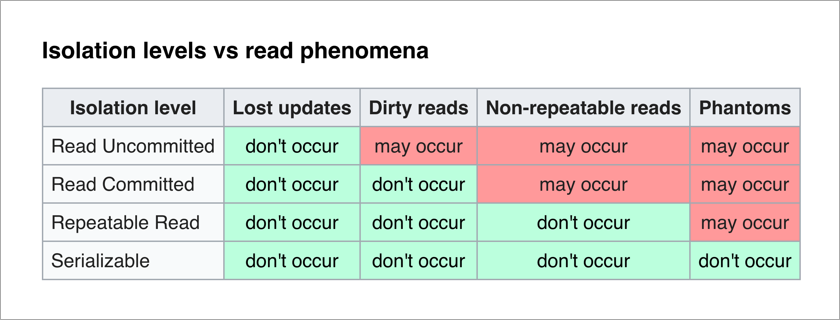
Самым приятным для прикладного программиста является уровень Serializable — нет никаких нежелательных эффектов и вся сложность обеспечения целостности данных переложена на СУБД.
Давайте подумаем о наивной реализации уровня Serializable — при каждой транзакции мы просто блокируем все остальные. Каждая транзакция записи может теоретически выполняться за 50мкс (время одной операции записи у современных SSD дисков). А мы хотим сохранять данные на три машины, помните? Если они находятся в одном дата-центре, то запись займет 1-3 мс. А если они, для надежности, находятся в разных городах, то запись легко может занять 10-12мс (время путешествия сетевого пакета из Москвы в Санкт-Петербург и обратно). То есть при наивной реализации уровня Serializable последовательной записью мы сможем выполнять не больше 100 транзакций в секунду. При том, что отдельный диск SSD позволяет выполнять порядка 20 000 операций записи в секунду!
Вывод: транзакции записи нужно выполнять параллельно, и для их масштабирования нужен хороший механизм разрешения конфликтов.
Что делать, когда данные перестают влезать на один сервер? Есть два стандартных механизма масштабирования:
Ключ шардирования — это параметр, по которому данные распределяются между серверами, например идентификатор клиента или организации.
Представьте, что вам нужно записать в кластер данные обо всех жителях Земли. В качестве ключа шарда можно взять, например, год рождения человека. Тогда хватит 116 серверов (и каждый год нужно будет добавлять новый сервер). Или вы можете взять в качестве ключа страну, где проживает человек, тогда вам понадобится примерно 250 серверов. Предпочтительнее всё-таки первый вариант, потому что дата рождения человека не меняется, и вам никогда не нужно будет перекидывать данные о нём между серверами.
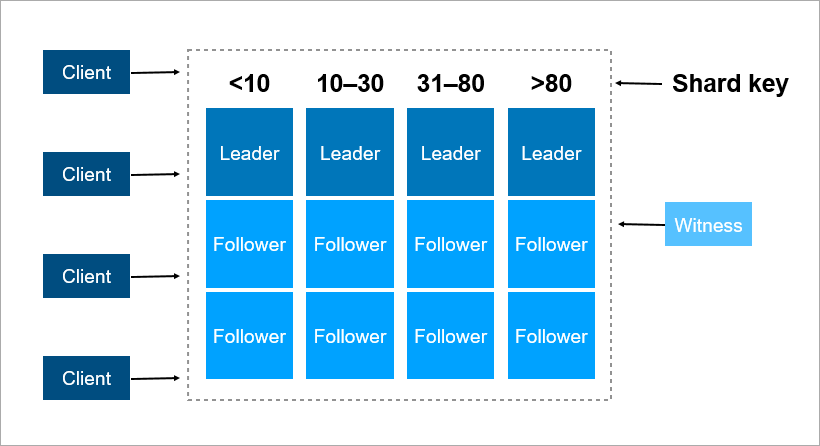
В Pyrus в качестве ключа шардирования можно взять организацию. Но они сильно отличаются по размеру: есть как огромный Совкомбанк (более 15 тысяч пользователей), так и тысячи небольших компаний. Когда ты присваиваешь организации определенный сервер, ты заранее не знаешь, как она вырастет. Если организация крупная и использует сервис активно, то рано или поздно ее данные перестанут помещаться на одном сервере, и придется делать решардинг. А это непросто, если данных терабайты. Представьте: нагруженная система, каждую секунду идут транзакции, и в этих условиях вам нужно перемещать данные с одного места на другое. Останавливать систему нельзя, такой объем может перекачиваться несколько часов, и бизнес-заказчики не переживут столь длительный простой.
В качестве ключа шардирования лучше выбирать данные, которые редко меняются. Однако далеко не всегда прикладная задача позволяет это легко сделать.
Когда машин в кластере много и часть из них теряют связь с остальными, то как решить, кто хранит самую последнюю версию данных? Просто назначить witness-сервер недостаточно, ведь он тоже может потерять связь со всем кластером. Кроме того, в ситуации split brain несколько машин могут записывать разные версии одних и тех же данных — и нужно как-то определить, какая из них самая актуальная. Для решения этой задачи люди придумали консенсус-алгоритмы. Они позволяют нескольким одинаковым машинам прийти к единому результату по любому вопросу путем голосования. В 1989 году был опубликован первый такой алгоритм, Paxos, а в 2014 году ребята из Стэнфорда придумали более простой в реализации Raft. Строго говоря, чтобы кластеру из (2N+1) серверов достичь консенсуса, достаточно, чтобы в нем было одновременно не более N отказов. Чтобы переживать 2 отказа, в кластере должно быть не менее 5 серверов.
Большинство баз данных, с которыми разработчики привыкли работать, поддерживают реляционную алгебру. Данные хранятся в таблицах и временами нужно соединить данные из разных таблиц путем операции JOIN. Рассмотрим пример БД и простого запроса к ней.

Предполагаем, что A.id — это первичный ключ с кластерным индексом. Тогда оптимизатор построит план, который скорее всего вначале выберет нужные записи из таблицы A и затем возьмет из подходящего индекса (A,B) соответствующие ссылки на записи в таблице B. Время выполнения этого запроса растет логарифмически от количества записей в таблицах.
Теперь представьте, что данные распределены по четырем серверам кластера и вам нужно выполнить тот же самый запрос:

Если СУБД не хочет просматривать все записи всего кластера, то она вероятно попробует найти записи с A.id равным 128, 129, или 130 и найти для них подходящие записи из таблицы B. Но если A.id не является ключом шардирования, то СУБД заранее не может знать, на каком сервере лежат данные таблицы А. Придется все равно обратиться ко всем серверам, чтобы узнать, есть ли там подходящие под наше условие записи A.id. Потом каждый сервер может сделать JOIN внутри себя, но этого не достаточно. Видите, запись на ноде 2 нам нужна в выборке, но там нет записи c A.id=128? Если ноды 1 и 2 будут делать JOIN независимо, то результат запроса будет неполным — часть данных мы не получим.
Поэтому для выполнения этого запроса каждый сервер должен обратиться ко всем остальным. Время выполнения растет квадратично от количества серверов. (Вам повезет, если вы сможете шардировать все таблицы по одному и тому же ключу, тогда все сервера обходить не нужно. Однако, на практике это малореально — всегда будут запросы, где требуется выборка не по ключу шардирования.)
Таким образом, операции JOIN масштабируются принципиально плохо и это фундаментальная проблема реляционного подхода.
Сложности с масштабированием классических СУБД привели к тому, что люди придумали NoSQL-базы данных, в которых нет операции JOIN. Нет джойнов — нет проблем. Но нет и ACID-свойств, а об этом в маркетинговых материалах умолчали. Быстро нашлись умельцы, которые испытывают на прочность разные распределенные системы и выкладывают результаты публично. Оказалось, бывают сценарии, когда кластер Redis теряет 45% сохраненных данных, кластер RabbitMQ — 35% сообщений, MongoDB — 9% записей, Cassandra — до 5%. Причем речь идет о потере после того, как кластер сообщил клиенту об успешном сохранении. Обычно ты ожидаешь более высокий уровень надежности от выбранной технологии.
Компания Google разработала базу данных Spanner, которая работает глобально по всему миру. Spanner гарантирует ACID-свойства, Serializability и даже больше. У них в дата-центрах стоят атомные часы, которые обеспечивают точное время, и это позволяет выстраивать глобальный порядок транзакций без необходимости пересылать сетевые пакеты между континентами. Идея Spanner в том, что пусть лучше программисты разбираются с проблемами производительности, которые возникают при большом количестве транзакций, чем делают костыли вокруг отсутствия транзакций. Однако, Spanner — закрытая технология, он вам не подходит, если вы по каким-либо причинам не хотите зависеть от одного вендора.
Выходцы из Google разработали open source аналог Spanner и назвали его CockroachDB («cockroach» по-английски «таракан», что должно символизировать живучесть БД). На Хабре уже писали о неготовности продукта к production, потому что кластер терял данные. Мы решили проверить более новую версию 2.0, и пришли к аналогичному выводу. Данные мы не потеряли, но некоторые простейшие запросы выполнялись необоснованно долго.
В итоге на сегодняшний день есть реляционные БД, которые хорошо масштабируются только вертикально, а это дорого. И есть NoSQL-решения без транзакций и без гарантий ACID (хочешь ACID — пиши костыли).
Как же делать mission-critical приложения, у которых данные не умещаются на один сервер? На рынке появляются новые решения и про одно из них — FoundationDB — мы подробнее расскажем в следующей статье.
Когда сервис недоступен пользователям какое-то время, это дико неприятно, но всё же не смертельно. А вот потерять данные клиента — абсолютно недопустимо. Поэтому любую технологию для хранения данных мы скрупулезно оцениваем по двум-трем десяткам параметров. Часть из них диктует текущая нагрузка на сервис.
Текущая нагрузка. Технологию подбираем с учётом роста этих показателей.Клиент-серверная архитектура
Классическая модель клиент-сервер — самый простой пример распределенной системы. Сервер — точка синхронизации, он позволяет нескольким клиентам делать что-то вместе скоординированно.
Очень упрощенная схема клиент-серверного взаимодействия.Что ненадёжно в клиент-серверной архитектуре? Очевидно, сервер может упасть. А когда сервер падает, все клиенты не могут работать. Чтобы этого избежать, люди придумали master-slave подключение (которое теперь политкорректно называют leader-follower). Суть — есть два сервера, все клиенты общаются с главным, а на второй просто реплицируются все данные.
Клиент-серверная архитектура с репликацией данных на фолловера.Ясно, что это более надёжная система: если основной сервер упадёт, то на фолловере находится копия всех данных и её можно будет быстро поднять.
При этом важно понимать, как устроена репликация. Если она синхронная, то транзакцию нужно сохранять одновременно и на лидере, и на фолловере, а это может быть медленно. Если репликация асинхронная, то можно потерять часть данных после аварийного переключения.
А что будет, если лидер упадет ночью, когда все спят? Данные на фолловере есть, но ему никто не сказал, что он теперь лидер, и клиенты к нему не подключаются. ОК, давайте наделим фолловер логикой, что он начинает считать себя главным, когда связь с лидером потеряна. Тогда легко можем получить split brain — конфликт, когда связь между лидером и фолловером нарушена, и оба думают, что они главные. Это действительно происходит во многих системах, например в RabbitMQ — самой популярной сегодня технологии очередей.
Чтобы решить эти проблемы, организовывают auto failover — добавляют третий сервер (witness, свидетель). Он гарантирует, что у нас только один лидер. А если лидер отваливается, то фолловер включается автоматически с минимальным даунтаймом, который можно снизить до нескольких секунд. Конечно, клиенты в этой схеме должны заранее знать адреса лидера и фолловера и реализовывать логику автоматического переподключения между ними.
Свидетель гарантирует, что есть только один лидер. Если лидер отваливается, то фолловер включается автоматически.Такая система сейчас работает у нас. Есть основная база данных, запасная база данных, есть свидетель и да — иногда мы приходим утром и видим, что ночью произошло переключение.
Но и у этой схемы есть недостатки. Представьте, что вы ставите сервис паки или обновляете ОС на лидер-сервере. До этого вы вручную переключили нагрузку на фолловера и тут… он падает! Катастрофа, ваш сервис недоступен. Что делать, чтобы защититься от этого? Добавляют третий резервный сервер — ещё один фолловер. Три — что-то вроде магического числа. Если вы хотите, чтобы система работала надежно, два сервера недостаточно, нужно три. Один на обслуживании, второй падает, остаётся третий.
Третий сервер обеспечивает надежную работу, если первые два недоступны.Если обобщить, то избыточность должна равняться двум. Избыточности, равной единице, недостаточно. По этой причине в дисковых массивах люди начали вместо RAID5 применять схему RAID6, переживающую падение сразу двух дисков.
Транзакции
Хорошо известны четыре основных требования к транзакциям: атомарность, согласованность, изолированность и долговечность (Atomicity, Consistency, Isolation, Durability — ACID).
Когда мы говорим о распределенных базах данных, то подразумеваем, что данные надо масштабировать. Чтение масштабируется очень хорошо — тысячи транзакций могут читать данные параллельно без проблем. Но когда одновременно с чтением другие транзакции пишут данные, возможны разные нежелательные эффекты. Очень легко получить ситуацию, при которой одна транзакция прочитает разные значения одних и тех же записей. Вот примеры.
Dirty reads. В первой транзакции мы два раза отправляем один и тот же запрос: взять всех пользователей, у которых ID = 1. Если вторая транзакция поменяет эту строчку, а потом сделает rollback, то база данных с одной стороны никаких изменений не увидит, а с другой стороны первая транзакция прочитает разные значения возраста для Joe.
Non-repeatable reads. Другой случай — если транзакция записи завершилась успешно, а транзакция чтения при выполнении одного и того же запроса также получила разные данные.
В первом случае клиент прочитал данные, которые вообще в базе отсутствовали. Во втором случае клиент оба раза прочитал данные из базы, но они отличаются, хотя чтение происходит в рамках одной транзакции.
Phantom reads — это когда мы в рамках одной транзакции повторно читаем какой-нибудь диапазон и получаем разный набор строк. Где-то посередине влезла другая транзакция и вставила или удалила записи.
Чтобы избегать этих нежелательных эффектов, современные СУБД реализуют механизмы блокировок (транзакция ограничивает другим транзакциям доступ к данным, с которыми она сейчас работает) или мультиверсионный контроль версий, MVCC (транзакция никогда не изменяет ранее записанные данные и всегда создает новую версию).
Стандарт ANSI/ISO SQL определяет 4 уровня изоляции транзакций, которые влияют на степень их взаимной блокировки. Чем выше уровень изоляции, тем меньше нежелательных эффектов. Платой за это является замедление работы приложения (поскольку транзакции чаще находятся в ожидании снятия блокировки с нужных им данных) и повышение вероятности deadlocks.
Самым приятным для прикладного программиста является уровень Serializable — нет никаких нежелательных эффектов и вся сложность обеспечения целостности данных переложена на СУБД.
Давайте подумаем о наивной реализации уровня Serializable — при каждой транзакции мы просто блокируем все остальные. Каждая транзакция записи может теоретически выполняться за 50мкс (время одной операции записи у современных SSD дисков). А мы хотим сохранять данные на три машины, помните? Если они находятся в одном дата-центре, то запись займет 1-3 мс. А если они, для надежности, находятся в разных городах, то запись легко может занять 10-12мс (время путешествия сетевого пакета из Москвы в Санкт-Петербург и обратно). То есть при наивной реализации уровня Serializable последовательной записью мы сможем выполнять не больше 100 транзакций в секунду. При том, что отдельный диск SSD позволяет выполнять порядка 20 000 операций записи в секунду!
Вывод: транзакции записи нужно выполнять параллельно, и для их масштабирования нужен хороший механизм разрешения конфликтов.
Шардирование
Что делать, когда данные перестают влезать на один сервер? Есть два стандартных механизма масштабирования:
- Вертикальное, когда мы просто добавляем в этот сервер память и диски. Это имеет свои пределы — по количеству ядер на процессор, количеству процессоров, объему памяти.
- Горизонтальное, когда мы используем много машин и распределяем данные между ними. Наборы таких машин называются кластерами. Чтобы поместить данные в кластер, их нужно шардировать — то есть для каждой записи определить, на каком конкретно сервере она будет размещена.
Ключ шардирования — это параметр, по которому данные распределяются между серверами, например идентификатор клиента или организации.
Представьте, что вам нужно записать в кластер данные обо всех жителях Земли. В качестве ключа шарда можно взять, например, год рождения человека. Тогда хватит 116 серверов (и каждый год нужно будет добавлять новый сервер). Или вы можете взять в качестве ключа страну, где проживает человек, тогда вам понадобится примерно 250 серверов. Предпочтительнее всё-таки первый вариант, потому что дата рождения человека не меняется, и вам никогда не нужно будет перекидывать данные о нём между серверами.
В Pyrus в качестве ключа шардирования можно взять организацию. Но они сильно отличаются по размеру: есть как огромный Совкомбанк (более 15 тысяч пользователей), так и тысячи небольших компаний. Когда ты присваиваешь организации определенный сервер, ты заранее не знаешь, как она вырастет. Если организация крупная и использует сервис активно, то рано или поздно ее данные перестанут помещаться на одном сервере, и придется делать решардинг. А это непросто, если данных терабайты. Представьте: нагруженная система, каждую секунду идут транзакции, и в этих условиях вам нужно перемещать данные с одного места на другое. Останавливать систему нельзя, такой объем может перекачиваться несколько часов, и бизнес-заказчики не переживут столь длительный простой.
В качестве ключа шардирования лучше выбирать данные, которые редко меняются. Однако далеко не всегда прикладная задача позволяет это легко сделать.
Консенсус в кластере
Когда машин в кластере много и часть из них теряют связь с остальными, то как решить, кто хранит самую последнюю версию данных? Просто назначить witness-сервер недостаточно, ведь он тоже может потерять связь со всем кластером. Кроме того, в ситуации split brain несколько машин могут записывать разные версии одних и тех же данных — и нужно как-то определить, какая из них самая актуальная. Для решения этой задачи люди придумали консенсус-алгоритмы. Они позволяют нескольким одинаковым машинам прийти к единому результату по любому вопросу путем голосования. В 1989 году был опубликован первый такой алгоритм, Paxos, а в 2014 году ребята из Стэнфорда придумали более простой в реализации Raft. Строго говоря, чтобы кластеру из (2N+1) серверов достичь консенсуса, достаточно, чтобы в нем было одновременно не более N отказов. Чтобы переживать 2 отказа, в кластере должно быть не менее 5 серверов.
Масштабирование реляционных СУБД
Большинство баз данных, с которыми разработчики привыкли работать, поддерживают реляционную алгебру. Данные хранятся в таблицах и временами нужно соединить данные из разных таблиц путем операции JOIN. Рассмотрим пример БД и простого запроса к ней.
Предполагаем, что A.id — это первичный ключ с кластерным индексом. Тогда оптимизатор построит план, который скорее всего вначале выберет нужные записи из таблицы A и затем возьмет из подходящего индекса (A,B) соответствующие ссылки на записи в таблице B. Время выполнения этого запроса растет логарифмически от количества записей в таблицах.
Теперь представьте, что данные распределены по четырем серверам кластера и вам нужно выполнить тот же самый запрос:
Если СУБД не хочет просматривать все записи всего кластера, то она вероятно попробует найти записи с A.id равным 128, 129, или 130 и найти для них подходящие записи из таблицы B. Но если A.id не является ключом шардирования, то СУБД заранее не может знать, на каком сервере лежат данные таблицы А. Придется все равно обратиться ко всем серверам, чтобы узнать, есть ли там подходящие под наше условие записи A.id. Потом каждый сервер может сделать JOIN внутри себя, но этого не достаточно. Видите, запись на ноде 2 нам нужна в выборке, но там нет записи c A.id=128? Если ноды 1 и 2 будут делать JOIN независимо, то результат запроса будет неполным — часть данных мы не получим.
Поэтому для выполнения этого запроса каждый сервер должен обратиться ко всем остальным. Время выполнения растет квадратично от количества серверов. (Вам повезет, если вы сможете шардировать все таблицы по одному и тому же ключу, тогда все сервера обходить не нужно. Однако, на практике это малореально — всегда будут запросы, где требуется выборка не по ключу шардирования.)
Таким образом, операции JOIN масштабируются принципиально плохо и это фундаментальная проблема реляционного подхода.
NoSQL подход
Сложности с масштабированием классических СУБД привели к тому, что люди придумали NoSQL-базы данных, в которых нет операции JOIN. Нет джойнов — нет проблем. Но нет и ACID-свойств, а об этом в маркетинговых материалах умолчали. Быстро нашлись умельцы, которые испытывают на прочность разные распределенные системы и выкладывают результаты публично. Оказалось, бывают сценарии, когда кластер Redis теряет 45% сохраненных данных, кластер RabbitMQ — 35% сообщений, MongoDB — 9% записей, Cassandra — до 5%. Причем речь идет о потере после того, как кластер сообщил клиенту об успешном сохранении. Обычно ты ожидаешь более высокий уровень надежности от выбранной технологии.
Компания Google разработала базу данных Spanner, которая работает глобально по всему миру. Spanner гарантирует ACID-свойства, Serializability и даже больше. У них в дата-центрах стоят атомные часы, которые обеспечивают точное время, и это позволяет выстраивать глобальный порядок транзакций без необходимости пересылать сетевые пакеты между континентами. Идея Spanner в том, что пусть лучше программисты разбираются с проблемами производительности, которые возникают при большом количестве транзакций, чем делают костыли вокруг отсутствия транзакций. Однако, Spanner — закрытая технология, он вам не подходит, если вы по каким-либо причинам не хотите зависеть от одного вендора.
Выходцы из Google разработали open source аналог Spanner и назвали его CockroachDB («cockroach» по-английски «таракан», что должно символизировать живучесть БД). На Хабре уже писали о неготовности продукта к production, потому что кластер терял данные. Мы решили проверить более новую версию 2.0, и пришли к аналогичному выводу. Данные мы не потеряли, но некоторые простейшие запросы выполнялись необоснованно долго.
В итоге на сегодняшний день есть реляционные БД, которые хорошо масштабируются только вертикально, а это дорого. И есть NoSQL-решения без транзакций и без гарантий ACID (хочешь ACID — пиши костыли).
Как же делать mission-critical приложения, у которых данные не умещаются на один сервер? На рынке появляются новые решения и про одно из них — FoundationDB — мы подробнее расскажем в следующей статье.
