В данном мануале описывается процесс настройки постоянного (continuous) бекапирования для баз данных PostgreSQL.
В нашей фирме (business to business) под каждого клиента создается свой собственный сервер, на который устанавливается база данных PostgreSQL и наш софт. Таким образом, у нас не единый instance продакшена, а десятки с разными экземплярами базы. Процесс настройки бекапов является частью процесса установки продакшена, а само бекапирование начинается до выхода системы в продакшен и продолжается в течение всего жизненного цикла сотрудничества с клиентом. Спецификацию железа и базового software определяем мы, поэтому все инстансы, как правило, имеют одни и те же версии Linux и PostgreSQL. Изредка этот инвариант нарушается — например, где-то по тем или иным причинам может стоять не Ubuntu, а Debian либо PostgreSQL более старой мажорной версии, чем у остальных. В последнем случае нужно быть особенно аккуратным — при возникновении сбоя следует иметь ввиду, что восстановление базы должно осуществляться на ту же мажорную версию PostgreSQL, на которой был сделан бекап, так как описываемый подход требует бинарной совместимости файлов данных, которая гарантируется только при переходе между минорными версиями PostgreSQL. Как поступить, если этот инвариант нарушен, также описано в конце данной статьи.
Подразумевается, что у читающего может быть довольно мало знаний как в области бекапов PostgreSQL, так и в сфере работы с Linux (а в особенности с инструментами ее командной строки), поэтому tutorial написан как можно более подробно.
Базовая концепция Continuous Archiving and Point-in-Time Recovery
В этом разделе укажем основные идеи, лежащие в основе подхода Continuous Archiving and Point-in-Time Recovery. При необходимости подробные детали можно найти в документации PostgreSQL.
Пожалуй, как и все СУБД, PostgreSQL имеет файлы данных, в которых хранит текущее состояние базы данных. Однако, кроме этого PostgreSQL ведет и сохраняет логи изменений в базе данных. Эти логи представлены в виде так называемых write ahead logs (WAL) файлов, которые сохраняются в подпапке pg_wal директории с данными:
WAL-файлы используются PostgreSQL для защиты от сбоев. Упрощенно говоря, при коммите транзакции PostgreSQL убеждается, что именно изменения в соответствующем WAL-файле гарантированно сохранились на диск, но, вообще говоря, может не делать такую же проверку по отношению к файлам с данными, например, кешируя их изменения до определенного момента в оперативной памяти. Если после последнего гарантированного сохранения файлов данных на диск (checkpoint) произошел сбой и текущее состояние еще не было сохранено, то после восстановления работы PostgreSQL возьмет последний checkpoint файлов данных (назовем его base backup) и последовательно применит к нему изменения, сохраненные в WAL-файлах (replay log entries).
Вышеописанную модель также можно использовать и для бекапирования с последующим восстановлением (например) на другом сервере. Для этого, очевидно, требуется реализовать следующую схему:
- Сначала (один раз) снять бекап файлов данных (и отправить файлы в безопасное место на другой сервер)
- В процессе работы по мере появления WAL-файлов тоже их бекапить
Модель восстановления после сбоя, таким образом, тоже становится очевидной:
- На новом сервере PostgreSQL загрузить файлы данных из бекапа (упрощенно это соответствует их простому копированию в соответствующую рабочую папку данных)
- На новом сервере PostgreSQL загрузить WAL-файлы из бекапа (упрощенно это соответствует их простому копированию в соответствующую подпапку рабочей папки данных)
Стоит иметь ввиду следующие особенности рассматриваемой модели бекапов:
- Бекапятся сразу все базы данных текущего PostgreSQL-сервера, т.е. нет возможности забекапить, например, только одну из них
- Не обязательно накатывать на base backup все записи WAL-файлов, можно остановиться на каком-то временном моменте (point-in-time recovery). Эта фича позволяет восстановить базу и в том случае, если сбой произошел в виду программной ошибки (например, была удалена какая-то таблица посредством drop table и т.п.).
В следующих разделах описываются технические детали описанной схемы.
Для этой цели будут использоваться следующие наименования: целевой сервер — текущий рабочий сервер, с которого делаем бекапы, сервер бекапов — сервер на который отправляются бекапы, новый сервер — сервер, на котором восстанавливается бекап целевого сервера после сбоя.
Оффтоп: несколько слов по безопасности
Ввиду особой ценности бекапов для бизнеса как с точки зрения восстановления после сбоев, так и с точки зрения возможных утечек информации нелишним будет пройтись по базовой безопасности Linux серверов. В целом, это не относится напрямую к рассматриваемой теме, поэтому, можно просто пробежаться глазами по этому разделу и, если у вас все устроено так же, спокойно пойти дальше. В случае если ваши решения по безопасности лучше описанных — просьба отписаться в комментариях и рассказать о своем опыте. Если же вы считаете, что с безопасностью у вас хуже, то описанные ниже решения стоит, вероятно, как можно скорее применить и к вашим продакшенам. Рассматриваться будет Ubuntu 18.04, на других версиях Linux инструкция может отличаться.
- Ваша система имеет последние обновления
sudo apt-get update && sudo apt-get upgrade - Вы не работаете от пользователя 'root', вместо этого у вас создан персонифицированный (то есть, для каждого сотрудника, которому требуется доступ на сервер, свой) пользователь в группе sudo (в нашем случае, назовем его alex)
sudo adduser alex # Вводим пароль и др. данные типа Full Name и т.п. sudo adduser alex sudo # Для проверки успешности создания пользователя можно зайти от него... sudo su - alex # ...и посмотреть список файлов в /root, куда имеют доступ только sudoers sudo ls -la /root # Если же ввести команду без sudo, то должна возникнуть ошибка авторизации ls -la /root - При подключении по SSH вы не используете авторизацию по логину/паролю, применяя вместо этого доступ по ключу
# ---Локальная машина сотрудника--- # Считаем, что сотрудник на локальной машине сгенерировал пару приватный/публичный ключ, # например, так, если у сотрудника Linux: ssh-keygen -t rsa -b 4096 # При этом парольную фразу при генерации ключа сотрудник не оставил пустой, а установил достаточно сложный пароль
# ---Продакшен, пользователь alex--- # Создадим файл публичного ключа и сохраним туда содержимое публичного ключа с локальной машины сотрудника nano ~/alex.pub # Затем скопируем открытый ключ в authorized_keys mkdir -p ~/.ssh touch ~/.ssh/authorized_keys chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys cat ~/alex.pub >> ~/.ssh/authorized_keys rm ~/alex.pub # Перезагрузим сервер sudo reboot - В конфиге ssh включена опция доступа по ключу, кроме этого порт доступа ssh изменен со стандартного на рандомный (макроподстановка [generatedPortNumber] в скрипте ниже) в диапазоне от 1024 до 57256 (т.к. часто сканеры портов для экономии ресурсов проверяют лишь стандартные порты)
# Открыть файл настроек ssh sudo nano /etc/ssh/sshd_config # Раскоментировать и поменять значения следующих ключей: PubkeyAuthentication yes # Если в файле присутствует ключ AuthenticationMethods, то в этом (и только в этом!) случае # поменять его значение или раскоментировать AuthenticationMethods publickey # Поменять значение порта на [generatedPortNumber] и раскоментировать Port [generatedPortNumber] # Перезагрузиться sudo reboot
# --- После перезагрузки --- # Убедиться в успешности подключения по ssh на новый порт по ключу пользователя alex... - Доступ root-а по ssh — запрещен, доступ по паролю по ssh — запрещен
# Открыть файл настроек ssh sudo nano /etc/ssh/sshd_config # Раскоментировать и поменять значения следующих ключей: PermitRootLogin no ChallengeResponseAuthentication no PasswordAuthentication no UsePAM no # Перезагрузиться sudo reboot
Настройка сервера бекапов
Создание папок для бекапа
Поскольку у нас множество инсталляций, с которых будут собираться бекапы, структура папок будет следующей. Папка для хранения бекапов — /var/lib/postgresql/backups. Под каждую инсталляцию в папке для хранения бекапов создается подпапка по имени клиента [clientName]. В каждой такой подпапке будут лежать 2 папки: base для базового бекапа и wal для continious archiving WAL-файлов с целевого сервера. Таким образом, при настройке бекапирования для клиента [clientName] выполняем следующие команды по созданию соответствующих директорий:
sudo mkdir -p /var/lib/postgresql/backups/[clientName]/base sudo mkdir -p /var/lib/postgresql/backups/[clientName]/wal
Разумеется, структура папок может быть и любой другой, которую вы находите более удобой для вас. Например, если хранить бекапы в home директориях соответствующих пользователей (см. ниже), то в следующем пункте можно сэкономить пару команд по раздаче прав на чтение и запись в эти папки.
Создание пользователя
В целях безопасности каждый продакшен (целевой сервер), с которого идут бекапы, будет иметь своего собственного пользователя на сервере бекапов. Это — обычный пользователь с ограниченными правами (не sudoer), который должен иметь права на чтение и запись в свою папку для бекапа, но не иметь возможность ни читать, ни писать в папки чужих продакшенов. Таким образом, даже если данный целевой сервер будет скомпрометирован, это не приведет к утечке данных других продакшенов через сервер бекапов.
Подробнее процесс выглядит следующим образом. Допустим, мы настраиваем бекап для проекта с именем foo. Для настройки сервера бекапов изначально заходим на него от пользователя из sudo. Добавляем пользователя с ограниченными правами foobackup:
# Добавить нового пользователя sudo adduser foobackup Adding user `foobackup' ... Adding new group `foobackup' (1001) ... Adding new user `foobackup' (1001) with group `foobackup' ... Creating home directory `/home/foobackup' ... Copying files from `/etc/skel' ... Enter new UNIX password: Retype new UNIX password: passwd: password updated successfully Changing the user information for foobackup Enter the new value, or press ENTER for the default Full Name []: Room Number []: Work Phone []: Home Phone []: Other []: Is the information correct? [Y/n] Y
Выдача прав пользователю на папки бекапа
Разрешаем foobackup читать и писать в свою папку, но запрещаем это делать всем остальным:
# Владельцем папки foo назначается foobackup sudo chown -R foobackup: /var/lib/postgresql/backups/foo # Никто кроме владельца не имеет доступа к этой папке sudo chmod -R 700 /var/lib/postgresql/backups/foo
Настройка публичных ключей
Для завершения настройки сервера бекапов нашему новому пользователю foobackup необходимо дать удаленный доступ, чтобы он имел возможность отсылать бекапы на сервер. Как и ранее, доступ будет осуществляться по ключам доступа и только по ним.
На целевом сервере бекапы делаются от имени пользователя postgres, соответственно генерируем (если этого не было сделано ранее) приватный и публичные ключи для него:
# Находясь на целевом сервере, в данном случае это сервер проекта foo, # заходим от имени postgres sudo su - postgres # Генерируем новый приватный ключ (только если этого не было сделано ранее!) ssh-keygen -t rsa -b 4096 Generating public/private rsa key pair. Enter file in which to save the key (/var/lib/postgresql/.ssh/id_rsa): /var/lib/postgresql/.ssh/id_rsa already exists. Overwrite (y/n)? y Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /var/lib/postgresql/.ssh/id_rsa. Your public key has been saved in /var/lib/postgresql/.ssh/id_rsa.pub.
Копируем содержимое публичного ключа из указанного при генерации системой места (Your public key has been saved in...), в нашем случае это /var/lib/postgresql/.ssh/id_rsa.pub:
# По-прежнему находясь на целевом сервере под пользователем postgres откроем файл публичного ключа и скопируем его содержимое vi /var/lib/postgresql/.ssh/id_rsa.pub
Сохраняем публичный ключ на сервер бекапов для пользователя foobackup:
# На сервере бекапов: # Заходим от имени пользователя foobackup sudo su - foobackup # В файл foobackup.pub cохранить содержимое открытого ключа, которое мы ранее скопировали nano ~/foobackup.pub # Затем записать открытый ключ пользователя в authorized_keys mkdir -p ~/.ssh touch ~/.ssh/authorized_keys chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys cat ~/foobackup.pub >> ~/.ssh/authorized_keys rm ~/foobackup.pub
Проверка работоспособности копирования
Теперь проверим, что мы все сделали правильно. В нашей схеме за копирование бекапов с целевого сервера на сервер бекапов будет отвечать scp — утилита для копирования файлов на удаленный сервер с синтаксисом, аналогичным локальному аналогу — cp. В принципе, можно использовать и другие средства доставки файлов, например, rsync и т.п.
# Находясь на целевом сервере (по-прежнему под пользователем postgres): # Заранее положим в папку /var/lib/postgresql/backups файл test.txt... # и скопируем его в соотв. папки сервера бекапов: scp /var/lib/postgresql/backups/test.txt foobackup@[backupServerIp]:/var/lib/postgresql/backups/foo/base scp /var/lib/postgresql/backups/test.txt foobackup@[backupServerIp]:/var/lib/postgresql/backups/foo/wal
После копирования заходим на сервер бекапов и убеждаемся, что файл действительно скопировался, например, так:
test -f /var/lib/postgresql/backups/foo/base/test.txt && echo 'exists in base' || echo 'not exists in base' test -f /var/lib/postgresql/backups/foo/wal/test.txt && echo 'exists in wal' || echo 'not exists in wal'
По окончании проверок файл test.txt следует удалить из соответствующих папок сервера бекапов.
Настройка целевого сервера
Конфигурация PostgreSQL
Архивирование без сжатия
В файле postgresql.conf (его расположение можно получить выполнив из psql команду "SHOW config_file;") сделать следующие изменения (с подстановкой [backupServerIp] = IP адрес сервера бекапов, [clientName] = foo):
#Раскоментировать и изменить строку с wal_level на следующее значение: wal_level = replica #Раскоментировать и изменить строку с archive_mode на следующую: archive_mode = on #Раскоментировать и изменить строку archive_command на следующее значение: archive_command = 'cat %p | ssh foobackup@[backupServerIp] "set -e; test ! -f /var/lib/postgresql/backups/[clientName]/wal/%f; cat > /var/lib/postgresql/backups/[clientName]/wal/%f.part; sync /var/lib/postgresql/backups/[clientName]/wal/%f.part; mv /var/lib/postgresql/backups/[clientName]/wal/%f.part /var/lib/postgresql/backups/[clientName]/wal/%f"' # command to use to archive a logfile segment #Раскоментировать и изменить строку archive_timeout на следующее значение: archive_timeout = 3600
В archive_command сначала проверяется не существует ли уже на сервере бекапов файл с таким именем. Это одно из требований документации PostgreSQL, которое направлено на защиту от разрушения integrity бекапа из-за администраторских ошибок — когда, например, бекапирование с двух разных серверов по ошибке настроено на одну и ту же папку. Далее происходит копирование файла по сети (scp) с использованием достаточно стандартного подхода: сначала поток записывается во временный файл и затем, только если он полностью скопирован и сброшен на диск (sync), меняется его имя (mv) с временного (.part) на постоянное. Если после переименования файла случилась ошибка и метаданные о таком переименовании не были сброшены на диск, то скрипт вернется с ошибкой и PostgreSQL просто повторит отправку файла. Ошибка на любом шаге скрипта закончит весь скрипт с ненулевым кодом (set -e).
Каждый WAL-файл занимает 16Mb и его архивирование (в нашем случае "архивирование" — это отправка на сервер бекапов) происходит только после того, как он заполнен. Таким образом, если данный клиент генерирует мало трафика БД, то бекап текущего WAL-файла может не происходить недетерменированно долго. Чтобы иметь возможность при сбое восстановить версию базы, например, не более часовой давности, необходимо в archive_timeout задать время форсированного архивирования (промежуток, через который даже неполный WAL-файл архивируется) в 1 час — в секундах это 3600. Не следует устанавливать слишком малые значения, потому что даже неполные WAL-файлы занимают 16Mb — таким образом, в заданный промежуток времени не менее 16Мб данных будет уходить на сервер бекапов. Например, при archive_timeout равном одному часу, в сутки на сервер бекапов будет уходить не менее 384Мб данных, в неделю это больше 2Gb.
Архивирование со сжатием
Учитывая возможные проблемы с разрастанием размера бекапов можно сразу делать сжатие и на сервер бекапов отправлять уже сжатые WAL-файлы (на своих продакшенах мы делаем именно так). В таком случае команда archive_command будет выглядеть так:
archive_command = 'gzip -c -9 %p | ssh foobackup@[backupServerIp] "set -e; test ! -f /var/lib/postgresql/backups/[clientName]/wal/%f.gz; cat > /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part; gzip -t /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part; sync /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part; mv /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part /var/lib/postgresql/backups/[clientName]/wal/%f.gz"' # command to use to archive a logfile segment
После сделанных в postgresql.conf изменений необходимо перезапустить PostgreSQL:
sudo service postgresql restart
Создание базового бекапа
Создание базового бекапа делается утилитой pg_basebackup, которая была установлена на целевом сервере вместе с PostgreSQL. Предполагается, что в PostgreSQL целевого сервера создан некий trusted пользователь с привилегиями, достаточными для осуществления бекапа всех баз данных на текущей инсталляции PostgreSQL (к примеру, это может быть администраторский аккаунт, используемый для обслуживания баз данных, или отдельный пользователь, специально созданный для создания базовых бекапов). Имя этого пользователя должно быть использовано в подстановке [trusted db user]. В процессе выполнения команды будет запрошен пароль этого пользователя. После создания бекапа сразу отправляем его на сервер бекапов.
#На целевом сервере: sudo -i -u postgres pg_basebackup --pgdata=/tmp/backups --format=tar --gzip --compress=9 --label=base_backup --host=127.0.0.1 --username=[trusted db user] --progress --verbose #При успехе в /tmp/backups будут созданы файлы base.tar.gz и pg_wal.tar.gz, #которые скопируем на сервер бекапов scp /tmp/backups/base.tar.gz /tmp/backups/pg_wal.tar.gz foobackup@[backupServerIp]:/var/lib/postgresql/backups/[clientName]/base exit
Ключи --progress и --verbose не являются обязательными и используются для наглядности наблюдения процесса создания бекапа — при наличии этих ключей PostgreSQL выдает некоторую дополнительную информацию в консоль в удобочитаемом виде.
Восстановление бекапа
Проверка работоспособности бекапирования
Перед тем, как выводить нашу инсталляцию foo в продакшен, необходимо убедиться в работоспособности настроенной системы бекапов. Проверка, очевидно, должна состоять из двух частей:
- Базовый бекап отправлен на сервер бекапов
- WAL-файлы отправляются на сервер бекапов
П.1 проверяется так: на сервере бекапов заходим в папку /var/lib/postgresql/backups/foo/base и убеждаемся, что она содержит файлы base.tar.gz и pg_wal.tar.gz:

Чтобы быстро — без долгого времени наблюдения за системой — проверить п.2, вернемся в пункт настройки PostgreSQL и поменяем таймаут архивирования (archive_timeout) на 60 секунд, затем рестартуем PostgreSQL. Теперь при наличии изменений в базе WAL-файлы будут архивироваться не реже, чем раз в минуту. Далее в течение некоторого времени (3-5 минут) будем любым (безопасным) образом генерировать изменения в базе — например, мы делаем это просто через наш фронт, вручную создавая активность тестовыми пользователями.
Параллельно нужно наблюдать за папкой /var/lib/postgresql/backups/foo/wal сервера бекапов, где примерно раз в минуту будет появляться новый файл:
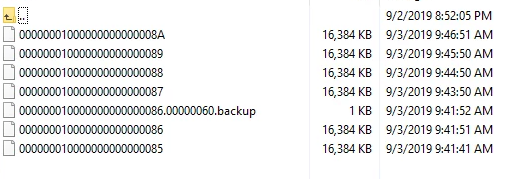
После проверки очень важно вернуть archive_timeout в продакшен значение (у нас в зависимости от клиента это минимум 1 час, т.е. 3600, максимум — сутки, т.е. 86400).
Если видно, что файлы не отправляются на сервер бекапов, то исследование проблемы можно начать с анализа логов PostgreSQL, лежащих здесь /var/log/postgresql. Например, если пара приватный-публичный ключ была настроена неверно, то можно увидеть подобную запись в файле postgresql-10-main.log (название лог-файла зависит от устанавливаемой версии):
2019-09-02 15:48:52.503 UTC [12983] DETAIL: The failed archive command was: scp pg_wal/00000001000000000000003B [fooBackup]@[serverBackupIp]:/var/lib/postgresql/backups/foo/wal/00000001000000000000003B Host key verification failed. lost connection
Восстановление из бекапа
Пусть у нас заранее подготовлен новый сервер, где установлен PostgreSQL той же мажорной версии, что и на целевом сервере. Также предположим, что с сервера бекапов мы предварительно скопировали папку бекапа /var/lib/postgresql/backups/foo на новый сервер по тому же пути.
Далее по шагам описана процедура развертывания этого бекапа на новом сервере.
Выясняем путь, по которому хранятся файлы данных:
#Находясь в psql: show data_directory;
В зависимости от версии PostgreSQL выдастся что-то подобное: /var/lib/postgresql/10/main
Удаляем все содержимое папки с данными:
#Останавливаем инстанс сервера, на который будем накатывать бекап sudo service postgresql stop sudo rm -rf /var/lib/postgresql/10/main/*
Останавливаем инстанс PostgreSQL на ЦЕЛЕВОМ сервере:
Если после сбоя доступ к целевом серверу сохранился, то останавливаем там инстанс PostgreSQL, чтобы потерять как можно меньшее количество новых данных, которые не войдут в бекап.
sudo service postgresql stop
Распаковываем файлы из бекапа в папку данных PostgreSQL:
Здесь и далее снова работаем с новым сервером.
sudo tar xvzf /var/lib/postgresql/backups/[clientName]/base/base.tar.gz -C /var/lib/postgresql/10/main sudo tar xvzf /var/lib/postgresql/backups/[clientName]/base/pg_wal.tar.gz -C /var/lib/postgresql/10/main
Ожидается, что команда tar, запущенная от sudo, сохранит group и ownership распакованных файлов за пользователем postgres — это важно, поскольку далее их будет использовать PostgreSQL, работающий именно от этого пользователя.
В папке с данными создаем конфиг восстановления:
Если сжатия на шаге архивирования WAL-файлов не было:
nano /var/lib/postgresql/10/main/recovery.conf #Добавить нужно единственную строку, заменив [clientName] на актуальное наименование инсталляции (в нашем примере [clientName] = foo) restore_command = 'cp /var/lib/postgresql/backups/[clientName]/wal/%f %p' #Выйти из nano c сохранением результатов и назначить права на файл пользователю postgres sudo chown postgres:postgres /var/lib/postgresql/10/main/recovery.conf sudo chmod 600 /var/lib/postgresql/10/main/recovery.conf #Назначить права на папку с бекапом WAL-файлов и ее содержимое (с подстановкой [clientName] = foo) sudo chown -R postgres:postgres /var/lib/postgresql/backups/[clientName]/wal sudo chmod 700 /var/lib/postgresql/backups/[clientName]/wal sudo chmod 600 /var/lib/postgresql/backups/[clientName]/wal/*
Если сжатие на шаге архивирования WAL-файлов было, то restore_command должен выглядеть следующим образом (все остальное не меняется):
restore_command = 'gunzip -c /var/lib/postgresql/backups/[clientName]/wal/%f.gz > %p'
Запускаем PostgreSQL:
sudo service postgresql start
Обнаружив в папке с данными конфиг восстановления, PostgreSQL входит в режим восстановления и начинает применять (replay) WAL-файлы из архива. После окончания восстановления recovery.conf будет переименован в recovery.done (поэтому очень важно на предыдущем шаге дать пользователю postgres права на изменение файла). После этого шага сервер PostgreSQL готов к работе. Если по внешним признакам видно, что база не восстановилась либо восстановилась только до уровня базового бекапа, то исследование проблемы можно начать с анализа логов PostgreSQL, лежащих здесь /var/log/postgresql. Например, если на предыдущем шаге не были даны права пользователю postgres на папку с бекапом WAL-файлов, то можно увидеть подобную запись в файле postgresql-10-main.log (название лог-файла зависит от устанавливаемой версии):
2019-09-04 11:52:14.532 CEST [27216] LOG: starting archive recovery cp: cannot stat '/var/lib/postgresql/backups/foo/wal/0000000100000000000000A8': Permission denied
Перенос PostgreSQL базы данных между разными мажорными версиями
В этом параграфе, как и было обещано в начале статьи, рассмотрим случай, когда требуется перенести базу с одной мажорной версии на другую. Поскольку основным сценарием бекапирования для нас является подход, описанный выше, то здесь мы будем предполагать, что целевой сервер доступен и работоспособен — то есть, перенос базы нужно осуществить не из-за сбоя, а по другим (организационным) причинам.
Будем использовать утилиту pg_dump или pg_dumpall. Обе они генерируют набор SQL-команд. Первая используется для создания бекапа конкретной базы данных, а вторая — при бекапе всего кластера. В последнем случае, кроме баз данных кластера копируются еще и его глобальные объекты — например, роли, что позволяет затем после развертывания бекапа не делать дополнительных действий в виде создания недостающих ролей, раздачи привилегий и т.п.
Создание дампа
На целевом сервере выполнить (желательно, чтобы на этот момент потребители его баз данных были остановлены и/или не проявляли активность по отношению к БД):
# Входим от имени пользователя postgres или от другого пользователя, являющегося админом текущего кластера PostgreSQL sudo -i -u postgres # Делаем дамп с опцией -с - при этой опции существующие при накатывании дампа объекты на целевом сервере будут удалены, #здесь foo.dump.gz - путь, по которому будет сохранен дамп. pg_dumpall -c | gzip -c > /tmp/backups/foo.dump.gz
Накатывание дампа
Будем считать, что на новый сервер по тому же пути (/tmp/backups/foo.dump.gz) скопирован сделанный на предыдущем шаге дамп.
Находясь на новом сервере:
# Входим от имени пользователя postgres, являющегося админом текущего кластера PostgreSQL sudo -i -u postgres #Накатим дамп на текущий кластер, выведем лог работы (включая ошибки) в файл /tmp/backups/foo.restore.out gunzip -c /tmp/backups/foo.dump.gz | psql -d postgres &> /tmp/backups/foo.restore.out
После окончания восстановления бекапа нужно просмотреть лог восстановления. По умолчанию psql работает с выключенным флагом ON_ERROR_STOP, поэтому при возникновении ошибок скрипт не прерывается, а продолжает работу. Ниже перечислены те ошибки, которые не являются проблемными, при появлении же в логе других ошибок следует считать восстановление базы не успешным.
#Если мы накатываем дамп на новый кластер, то целевой базы может не существовать, тогда появится ошибка ERROR: database "foo" does not exist #Это не проблема, так как дамп содержит команду по созданию базы данных, однако, нужно убедиться, что далее по скрипту база создалась и подключение к ней успешно. Об этом говорит строка: You are now connected to database "foo" as user "postgres". #Дамп, созданный с ключом -c (clean) содержит команды пересоздания ролей: сначала производится попытка удалить роль, а затем создать ее заново. #Эта команда будет неуспешной для текущего пользователя, от которого работает psql, в данном случае это postgres, поэтому в логах встретится такая ошибка: ERROR: current user cannot be dropped #Отметим, что даже если работать не от пользователя postgres, а, например, специально для целей накатывания бекапа создать нового пользователя, и работать от него, то все равно будет иметь место ошибка удаления роли postgres, так как эта роль требуется для работоспособности кластера. #Поскольку роль postgres не была удалена, то далее при попытке ее создания будет выдана ошибка: ERROR: role "postgres" already exists #Внимание! Более никаких ошибок в логе восстановления базы данных встретиться не должно!
Включение сервисов
После окончания накатывания дампа нужно:
- Настроить бекапирование нового сервера
- Переключить соответствующие сервисы на новый адрес базы данных и включить их для пользователя
После этого перенос можно считать завершенным.
