Привет, я работаю в команде проекта РРД КП (распределенный реестр данных для контроля жизненного цикла колесных пар). Здесь я хочу поделиться опытом нашей команды в разработке корпоративного блокчейна для данного проекта в условиях ограничений, накладываемых технологией. По большей части я буду говорить о Hyperledger Fabric, но описанный здесь подход может быть экстраполирован на любой permissioned блокчейн. Конечная цель наших изысканий — готовить корпоративные блокчейн-решения так, чтобы итоговым продуктом было приятно пользоваться и не слишком тяжело поддерживать.
Здесь не будет никаких открытий, неожиданных решений и здесь не будут освещаться никакие уникальные разработки (потому что их у меня нет). Я просто хочу поделиться своим скромным опытом, показать, что «так можно было» и, возможно, прочитать о чужом опыте принятия хороших и не очень решений в комментариях.
Сегодня усилия многих разработчиков направлены на то, чтобы сделать блокчейн действительно удобной технологией, а не бомбой замедленного действия в красивой обертке. Каналы состояний, optimistic rollup, plasma и шардинг, возможно, станут повседневностью. Когда-нибудь. А возможно, TON снова отложит запуск на полгода, а очередная Plasma Group прекратит своё существование. Мы можем верить в очередной roadmap и читать на ночь блестящие white papers, но здесь и сейчас нужно что-то делать с тем, что мы имеем. Get shit done.
Задача, поставленная перед нашей командой в текущем проекте, выглядит в общем виде так: есть множество субъектов, достигающее нескольких тысяч, не желающее строить отношения на доверии; необходимо построить на DLT такое решение, которое будет работать на обычных ПК без специальных требований к производительности и обеспечивать пользовательский опыт не хуже любых централизованных систем учета. Технология, лежащая в основе решения, должна свести к минимуму возможность злонамеренных манипуляций с данными — именно поэтому здесь блокчейн.
Лозунги из whitepapers и СМИ обещают нам, что очередная разработка позволит совершать миллионы транзакций в секунду. Что же на самом деле?
Mainnet Ethereum сейчас работает со скоростью ~30 tps. Уже только из-за этого его сложно воспринимать как сколько-нибудь пригодный для корпоративных нужд блокчейн. Среди permissioned-решений известны бенчмарки, показывающие 2000 tps (Quorum) или 3000 tps (Hyperledger Fabric, в публикации чуть меньше, но нужно учитывать, что бенчмарк проводился на старом consensus engine). Была попытка радикальной переработки Fabric, давшая не самые плохие результаты, 20000 tps, но пока это лишь академические изыскания, ждущие своей стабильной имплементации. Вряд ли корпорация, которая может себе позволить содержать отдел блокчейн-разработчиков, будет мириться с такими показателями. Но проблема не только в throughput, есть ещё latency.
Задержка от момента инициации транзакции до её окончательного утверждения системой зависит не только от скорости прохождения сообщения через все этапы валидаций и упорядочивания, но и от параметров формирования блока. Даже если наш блокчейн позволяет нам коммитить со скоростью 1000000 tps, но требует при этом 10 минут на формирование блока размером 488 Мб, станет ли нам легче?
Давайте посмотрим поближе на жизненный цикл транзакции в Hyperledger Fabric, чтобы понять, на что уходит время и как это соотносится с параметрами формирования блока.

взято отсюда: hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane
(1) Клиент формирует транзакцию, отправляет на endorsing peers, последние симулируют транзакцию (применяют изменения, вносимые чейнкодом, на текущее состояние, но не коммитят в леджер) и получают RWSet — имена ключей, версии и значения, взятые из коллекции в CouchDB, (2) endorsers отправляют обратно клиенту подписанный RWSet, (3) клиент либо проверяет наличие подписей всех необходимых пиров (endorsers), а потом отправляет транзакцию на ordering service, либо отправляет без проверки (проверка все равно состоится позже), ordering service формирует блок и (4) отправляет обратно на все пиры, не только endorsers; пиры проверяют соответствие версий ключей в read set версиям в базе данных, наличие подписей всех endorsers и наконец коммитят блок.
Но это ещё не всё. За словами «ордерер формирует блок» скрывается не только упорядочивание транзакций, но и 3 последовательных сетевых запроса от лидера к фолловерам и обратно: лидер добавляет сообщение в лог, отправляет фолловерам, последние добавляют в свой лог, отправляют подтверждение успешной репликации лидеру, лидер коммитит сообщение, отправляет подтверждение коммита фолловерам, фолловеры коммитят. Чем меньше размер и время формирования блока, тем чаще придется ordering service устанавливать консенсус. В Hyperledger Fabric есть два параметра формирования блока: BatchTimeout — время формирования блока и BatchSize — размер блока (количество транзакций и размер самого блока в байтах). Как только один из параметров достигает лимита, выпускается новый блок. Чем больше нод ордереров, тем дольше это будет происходить. Следовательно, нужно увеличивать BatchTimeout и BatchSize. Но поскольку RWSet'ы версионируются, то чем больше мы сделаем блок, тем выше вероятность MVCC-конфликтов. К тому же, с увеличением BatchTimeout катастрофически деградирует UX. Мне кажется разумной и очевидной следующая схема для решения этих проблем.
Чем больше время формирования и размер блока, тем выше пропускная способность блокчейна. Одно из другого прямо не следует, однако следует вспомнить, что установление консенсуса в RAFT требует трех сетевых запросов от лидера к фолловерам и обратно. Чем больше нод ордеров, тем дольше это будет происходить. Чем меньше размер и время формирования блока, тем больше таких интеракций. Как увеличивать время формирования и размер блока, не увеличивая время ожидания ответа системы для конечного пользователя?
Во-первых, нужно как-то решать MVCC-конфликты, вызванные большим размером блока, который может включать разные RWSet'ы с одной и той же версией. Очевидно, на стороне клиента (по отношению к блокчейн-сети, это вполне может быть бекенд, и я имею в виду именно его) нужен хендлер MVCC-конфликтов, который может быть как отдельным сервисом, так и обычным декоратором над инициирующем транзакцию вызовом с логикой retry.
Retry можно реализовать с экспоненциальной стратегией, но тогда latency будет деградировать так же экспоненциально. Так что следует использовать либо рандомизированный в определенных небольших пределах retry, либо постоянный. С оглядкой на возможные коллизии в первом варианте.
Следующий этап — сделать взаимодействие клиента с системой асинхронным, чтобы он не ждал 15, 30 или 10000000 секунд, которые мы установим в качестве BatchTimeout. Но при этом нужно сохранить возможность удостовериться в том, что изменения, инициированные транзакцией, записаны/не записаны в блокчейн.
Для хранения статуса транзакций можно использовать базу данных. Самый простой вариант — CouchDB из-за удобства использования: у базы есть UI из коробки, REST API, для неё легко можно настроить репликацию и шардирование. Можно создать просто отдельную коллекцию в том же инстансе CouchDB, который использует Fabric для хранения своего world state. Нам нужно хранить документы такого вида.
Этот документ записывается в базу до передачи транзакции на пиры, пользователю возвращается ID сущности (этот же ID используется в качестве ключа), если это операция создания чего-либо, а затем поля Status, TxID и Error обновляются по мере поступления релевантной информации от пиров.
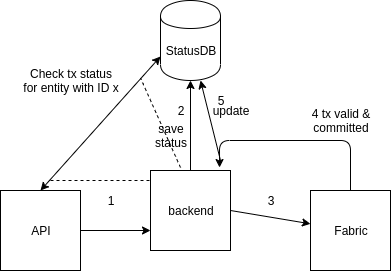
В этой схеме пользователь не ждет, когда же наконец сформируется блок, наблюдая крутящееся колесико на экране 10 секунд, он получает моментальный отклик системы и продолжает работать.
Мы выбрали BoltDB для хранения статусов транзакций, потому что нам нужно экономить память и не хочется тратить время на сетевое взаимодействие с отдельно стоящим сервером базы данных, тем более когда это взаимодействие происходит по plain text протоколу. Кстати, используете вы CouchDB для реализации описанной выше схемы или просто для хранения world state, в любом случае имеет смысл оптимизировать способ хранения данных в CouchDB. По умолчанию в CouchDB размер b-tree узлов равен 1279 байт, что сильно меньше размера сектора на диске, а значит как чтение, так и перебалансировка дерева будет требовать больше физических обращений к диску. Оптимальный размер соответствует стандарту Advanced Format и составляет 4 килобайта. Для оптимизации нам нужно установить параметр btree_chunk_size равным 4096 в файле конфигурации CouchDB. Для BoltDB такое ручное вмешательство не требуется.
Но сообщений может быть очень много. Больше, чем система способна обработать, разделяя ресурсы с десятком других сервисов кроме отраженных на схеме — и все это должно работать безотказно даже на машинах, на которых запуск Intellij Idea будет делом крайне утомительным.
Проблема разной пропускной способности сообщающихся систем, продьюсера и консьюмера, решается разными способами. Посмотрим, что мы могли бы сделать.
Dropping: мы можем заявить, что способны обрабатывать не более X транзакций за T секунд. Все запросы, превышающие этот лимит, сбрасываются. Это довольно просто, но про UX тогда можно забыть.
Controlling: у консьюмера должен быть некий интерфейс, через который он в зависимости от нагрузки сможет контролировать tps продьюсера. Неплохо, но это накладывает обязательства на разработчиков клиента, создающего нагрузку, реализовывать этот интерфейс. Для нас это неприемлемо, так как блокчейн в перспективе будет интегрирован в большое количество давно существующих систем.
Buffering: вместо того, чтобы ухищряться в сопротивлении входному потоку данных, мы можем буферизовать этот поток и обрабатывать его с необходимой скоростью. Очевидно, это лучшее решение, если мы хотим обеспечить хороший пользовательский опыт. Буфер мы реализовывали с помощью очереди в RabbitMQ.

В схему добавилось два новых действия: (1) после поступления запроса на API в очередь кладется сообщение с параметрами, необходимыми для вызова транзакции, и клиент получает сообщение о том, что транзакция принята системой, (2) бекенд с задаваемой в конфиге скоростью читает данные из очереди; инициирует транзакцию и обновляет данные в хранилище статусов.
Теперь можно увеличивать время формирования и вместимость блока настолько, насколько захочется, скрывая задержки от пользователя.
Здесь не было ничего сказано про чейнкод, потому что в нем, как правило, нечего оптимизировать. Чейнкод должен быть максимально простым и безопасным — это всё, что от него требуется. Писать чейнкод просто и безопасно нам сильно помогает фреймворк ССKit от S7 Techlab и статический анализатор revive^CC.
Кроме того, наша команда разрабатывает набор утилит для того, чтобы сделать работу с Fabric простой и приятной: блокчейн эксплорер, утилита для автоматического изменения конфигурации сети (добавление/удаление организаций, нод RAFT), утилита для отзыва сертификатов и удаления identity. Если хотите внести свой вклад — welcome.
Этот подход позволяет легко заменить Hyperledger Fabric на Quorum, другие приватные Ethereum сети (PoA или даже PoW), существенно снизить реальную пропускную способность, но при этом сохранить нормальный UX (как для пользователей в браузере, так и со стороны интегрируемых систем). При замене Fabric на Ethereum в схеме нужно будет изменить только логику retry-сервиса/декоратора c обработки MVCC-конфликтов на атомарный инкремент nonce и повторную отправку. Буферизация и хранилище статусов позволили отвязать время отклика от времени формирования блока. Теперь можно добавлять тысячи нод ордеров и не бояться, что блоки формируются слишком часто и нагружают ordering service.
В общем-то, это всё, чем я хотел поделиться. Буду рад, если это кому-то поможет в работе.
Здесь не будет никаких открытий, неожиданных решений и здесь не будут освещаться никакие уникальные разработки (потому что их у меня нет). Я просто хочу поделиться своим скромным опытом, показать, что «так можно было» и, возможно, прочитать о чужом опыте принятия хороших и не очень решений в комментариях.
Проблема: блокчейны пока что не масштабируются
Сегодня усилия многих разработчиков направлены на то, чтобы сделать блокчейн действительно удобной технологией, а не бомбой замедленного действия в красивой обертке. Каналы состояний, optimistic rollup, plasma и шардинг, возможно, станут повседневностью. Когда-нибудь. А возможно, TON снова отложит запуск на полгода, а очередная Plasma Group прекратит своё существование. Мы можем верить в очередной roadmap и читать на ночь блестящие white papers, но здесь и сейчас нужно что-то делать с тем, что мы имеем. Get shit done.
Задача, поставленная перед нашей командой в текущем проекте, выглядит в общем виде так: есть множество субъектов, достигающее нескольких тысяч, не желающее строить отношения на доверии; необходимо построить на DLT такое решение, которое будет работать на обычных ПК без специальных требований к производительности и обеспечивать пользовательский опыт не хуже любых централизованных систем учета. Технология, лежащая в основе решения, должна свести к минимуму возможность злонамеренных манипуляций с данными — именно поэтому здесь блокчейн.
Лозунги из whitepapers и СМИ обещают нам, что очередная разработка позволит совершать миллионы транзакций в секунду. Что же на самом деле?
Mainnet Ethereum сейчас работает со скоростью ~30 tps. Уже только из-за этого его сложно воспринимать как сколько-нибудь пригодный для корпоративных нужд блокчейн. Среди permissioned-решений известны бенчмарки, показывающие 2000 tps (Quorum) или 3000 tps (Hyperledger Fabric, в публикации чуть меньше, но нужно учитывать, что бенчмарк проводился на старом consensus engine). Была попытка радикальной переработки Fabric, давшая не самые плохие результаты, 20000 tps, но пока это лишь академические изыскания, ждущие своей стабильной имплементации. Вряд ли корпорация, которая может себе позволить содержать отдел блокчейн-разработчиков, будет мириться с такими показателями. Но проблема не только в throughput, есть ещё latency.
Latency
Задержка от момента инициации транзакции до её окончательного утверждения системой зависит не только от скорости прохождения сообщения через все этапы валидаций и упорядочивания, но и от параметров формирования блока. Даже если наш блокчейн позволяет нам коммитить со скоростью 1000000 tps, но требует при этом 10 минут на формирование блока размером 488 Мб, станет ли нам легче?
Давайте посмотрим поближе на жизненный цикл транзакции в Hyperledger Fabric, чтобы понять, на что уходит время и как это соотносится с параметрами формирования блока.
взято отсюда: hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane
(1) Клиент формирует транзакцию, отправляет на endorsing peers, последние симулируют транзакцию (применяют изменения, вносимые чейнкодом, на текущее состояние, но не коммитят в леджер) и получают RWSet — имена ключей, версии и значения, взятые из коллекции в CouchDB, (2) endorsers отправляют обратно клиенту подписанный RWSet, (3) клиент либо проверяет наличие подписей всех необходимых пиров (endorsers), а потом отправляет транзакцию на ordering service, либо отправляет без проверки (проверка все равно состоится позже), ordering service формирует блок и (4) отправляет обратно на все пиры, не только endorsers; пиры проверяют соответствие версий ключей в read set версиям в базе данных, наличие подписей всех endorsers и наконец коммитят блок.
Но это ещё не всё. За словами «ордерер формирует блок» скрывается не только упорядочивание транзакций, но и 3 последовательных сетевых запроса от лидера к фолловерам и обратно: лидер добавляет сообщение в лог, отправляет фолловерам, последние добавляют в свой лог, отправляют подтверждение успешной репликации лидеру, лидер коммитит сообщение, отправляет подтверждение коммита фолловерам, фолловеры коммитят. Чем меньше размер и время формирования блока, тем чаще придется ordering service устанавливать консенсус. В Hyperledger Fabric есть два параметра формирования блока: BatchTimeout — время формирования блока и BatchSize — размер блока (количество транзакций и размер самого блока в байтах). Как только один из параметров достигает лимита, выпускается новый блок. Чем больше нод ордереров, тем дольше это будет происходить. Следовательно, нужно увеличивать BatchTimeout и BatchSize. Но поскольку RWSet'ы версионируются, то чем больше мы сделаем блок, тем выше вероятность MVCC-конфликтов. К тому же, с увеличением BatchTimeout катастрофически деградирует UX. Мне кажется разумной и очевидной следующая схема для решения этих проблем.
Как избежать ожидания финализации блока и не потерять возможности отслеживания статуса транзакции
Чем больше время формирования и размер блока, тем выше пропускная способность блокчейна. Одно из другого прямо не следует, однако следует вспомнить, что установление консенсуса в RAFT требует трех сетевых запросов от лидера к фолловерам и обратно. Чем больше нод ордеров, тем дольше это будет происходить. Чем меньше размер и время формирования блока, тем больше таких интеракций. Как увеличивать время формирования и размер блока, не увеличивая время ожидания ответа системы для конечного пользователя?
Во-первых, нужно как-то решать MVCC-конфликты, вызванные большим размером блока, который может включать разные RWSet'ы с одной и той же версией. Очевидно, на стороне клиента (по отношению к блокчейн-сети, это вполне может быть бекенд, и я имею в виду именно его) нужен хендлер MVCC-конфликтов, который может быть как отдельным сервисом, так и обычным декоратором над инициирующем транзакцию вызовом с логикой retry.
Retry можно реализовать с экспоненциальной стратегией, но тогда latency будет деградировать так же экспоненциально. Так что следует использовать либо рандомизированный в определенных небольших пределах retry, либо постоянный. С оглядкой на возможные коллизии в первом варианте.
Следующий этап — сделать взаимодействие клиента с системой асинхронным, чтобы он не ждал 15, 30 или 10000000 секунд, которые мы установим в качестве BatchTimeout. Но при этом нужно сохранить возможность удостовериться в том, что изменения, инициированные транзакцией, записаны/не записаны в блокчейн.
Для хранения статуса транзакций можно использовать базу данных. Самый простой вариант — CouchDB из-за удобства использования: у базы есть UI из коробки, REST API, для неё легко можно настроить репликацию и шардирование. Можно создать просто отдельную коллекцию в том же инстансе CouchDB, который использует Fabric для хранения своего world state. Нам нужно хранить документы такого вида.
{
Status string // Статус транзакции: "pending", "done", "failed"
TxID: string // ID транзакции
Error: string // optional, сообщение об ошибке
}Этот документ записывается в базу до передачи транзакции на пиры, пользователю возвращается ID сущности (этот же ID используется в качестве ключа), если это операция создания чего-либо, а затем поля Status, TxID и Error обновляются по мере поступления релевантной информации от пиров.
В этой схеме пользователь не ждет, когда же наконец сформируется блок, наблюдая крутящееся колесико на экране 10 секунд, он получает моментальный отклик системы и продолжает работать.
Мы выбрали BoltDB для хранения статусов транзакций, потому что нам нужно экономить память и не хочется тратить время на сетевое взаимодействие с отдельно стоящим сервером базы данных, тем более когда это взаимодействие происходит по plain text протоколу. Кстати, используете вы CouchDB для реализации описанной выше схемы или просто для хранения world state, в любом случае имеет смысл оптимизировать способ хранения данных в CouchDB. По умолчанию в CouchDB размер b-tree узлов равен 1279 байт, что сильно меньше размера сектора на диске, а значит как чтение, так и перебалансировка дерева будет требовать больше физических обращений к диску. Оптимальный размер соответствует стандарту Advanced Format и составляет 4 килобайта. Для оптимизации нам нужно установить параметр btree_chunk_size равным 4096 в файле конфигурации CouchDB. Для BoltDB такое ручное вмешательство не требуется.
Backpressure: buffer strategy
Но сообщений может быть очень много. Больше, чем система способна обработать, разделяя ресурсы с десятком других сервисов кроме отраженных на схеме — и все это должно работать безотказно даже на машинах, на которых запуск Intellij Idea будет делом крайне утомительным.
Проблема разной пропускной способности сообщающихся систем, продьюсера и консьюмера, решается разными способами. Посмотрим, что мы могли бы сделать.
Dropping: мы можем заявить, что способны обрабатывать не более X транзакций за T секунд. Все запросы, превышающие этот лимит, сбрасываются. Это довольно просто, но про UX тогда можно забыть.
Controlling: у консьюмера должен быть некий интерфейс, через который он в зависимости от нагрузки сможет контролировать tps продьюсера. Неплохо, но это накладывает обязательства на разработчиков клиента, создающего нагрузку, реализовывать этот интерфейс. Для нас это неприемлемо, так как блокчейн в перспективе будет интегрирован в большое количество давно существующих систем.
Buffering: вместо того, чтобы ухищряться в сопротивлении входному потоку данных, мы можем буферизовать этот поток и обрабатывать его с необходимой скоростью. Очевидно, это лучшее решение, если мы хотим обеспечить хороший пользовательский опыт. Буфер мы реализовывали с помощью очереди в RabbitMQ.
В схему добавилось два новых действия: (1) после поступления запроса на API в очередь кладется сообщение с параметрами, необходимыми для вызова транзакции, и клиент получает сообщение о том, что транзакция принята системой, (2) бекенд с задаваемой в конфиге скоростью читает данные из очереди; инициирует транзакцию и обновляет данные в хранилище статусов.
Теперь можно увеличивать время формирования и вместимость блока настолько, насколько захочется, скрывая задержки от пользователя.
Другие инструменты
Здесь не было ничего сказано про чейнкод, потому что в нем, как правило, нечего оптимизировать. Чейнкод должен быть максимально простым и безопасным — это всё, что от него требуется. Писать чейнкод просто и безопасно нам сильно помогает фреймворк ССKit от S7 Techlab и статический анализатор revive^CC.
Кроме того, наша команда разрабатывает набор утилит для того, чтобы сделать работу с Fabric простой и приятной: блокчейн эксплорер, утилита для автоматического изменения конфигурации сети (добавление/удаление организаций, нод RAFT), утилита для отзыва сертификатов и удаления identity. Если хотите внести свой вклад — welcome.
Заключение
Этот подход позволяет легко заменить Hyperledger Fabric на Quorum, другие приватные Ethereum сети (PoA или даже PoW), существенно снизить реальную пропускную способность, но при этом сохранить нормальный UX (как для пользователей в браузере, так и со стороны интегрируемых систем). При замене Fabric на Ethereum в схеме нужно будет изменить только логику retry-сервиса/декоратора c обработки MVCC-конфликтов на атомарный инкремент nonce и повторную отправку. Буферизация и хранилище статусов позволили отвязать время отклика от времени формирования блока. Теперь можно добавлять тысячи нод ордеров и не бояться, что блоки формируются слишком часто и нагружают ordering service.
В общем-то, это всё, чем я хотел поделиться. Буду рад, если это кому-то поможет в работе.
