Расшифровка доклада 2015 года Алексея Лесовского "Deep dive into PostgreSQL internal statistics"
Disclaimer от автора доклада: Замечу что доклад этот датирован ноябрем 2015 года — прошло больше 4 лет и прошло много времени. Рассматриваемая в докладе версия 9.4 уже не поддерживается. За прошедшие 4 года вышло 5 новых релизов в которых появилась масса новшеств, улучшений и изменений относительно статистики и часть материала устарела и не актуальна. По мере ревью я постарался отметить эти места чтобы не вводить тебя читатель в заблуждения. Переписывать же эти места я не стал, их очень много и получится в итоге совсем другой доклад.
СУБД PostgreSQL — это огромный механизм, при этом состоит этот механизм из множества подсистем, от слаженной работы которых напрямую зависит производительность СУБД. В процессе эксплуатации обеспечивается сбор статистики и информации о работе компонентов, что позволяет оценить эффективность PostgreSQL и принять меры для повышения производительности. Однако, этой информации очень много и представлена она в достаточно упрощенном виде. Обработка этой информации и ее интерпретация порой совсем нетривиальная задача, а "зоопарк" инструментов и утилит запросто поставит в тупик даже продвинутого DBA.

Добрый день! Меня зовут Алексей. Как Илья сказал, я буду рассказывать про статистику PostgreSQL.

Статистика активности PostgreSQL. У PostgreSQL есть две статистики. Статистика активности, про которую будет речь. И статистика планировщика о распределении данных. Я буду рассказывать именно о статистике активности PostgreSQL, которая позволяет нам судить о производительности и как-то ее улучшать.
Расскажу, как эффективно использовать статистику для решения самых разных проблем, которые у вас возникают или могут возникнуть.

Чего не будет в докладе? В докладе я не буду касаться статистики планировщика, т.к. это отдельная тема на отдельный доклад о том, как данные хранятся в базе и о том как планировщик запросов получает представление о качественных и количественных характериситках этих данных.
И не будет обзоров инструментов, я не буду сравнивать один продукт с другим. Никакой рекламы не будет. Отбросим это.

Я хочу вам показать, что использовать статистику – это полезно. Это нужно. Использовать ее нестрашно. Нам понадобится всего лишь обычный SQL и базовые знания о SQL.
И поговорим, какую статистику выбирать для решения проблем.

Если мы посмотрим на PostgreSQL и в операционной системе запустим команду для просмотра процессов, то увидим "черный ящик". Мы увидим какие-то процессы, которые что-то делают, и мы по названию можем примерно представить, что они там делают, чем занимаются. Но, по сути, это черный ящик, вовнутрь мы заглянуть не можем.
Мы можем посмотреть нагрузку на процессор в top, можем посмотреть утилизацию памяти какими-то системными утилитами, но заглянуть вовнутрь PostgreSQL мы не сможем. Для этого нам нужны другие инструменты.

И продолжая дальше я расскажу, куда тратится время. Если мы представим PostgreSQL в виде такой схемы, то можно будет ответить, куда тратится время. Это две вещи: это обработка клиентских запросов от приложений и фоновые задачи, которые выполняет PostgreSQL для поддержания своей работоспособности.
Если мы начнем рассматривать с левого верхнего угла, то мы можем проследить, как обрабатывается клиентские запросы. Запрос приходит от приложения и для дальнейшей работы открывается клиентская сессия. Запрос передается в планировщик. Планировщик строит план запроса. Отправляет его дальше на выполнение. Происходит какой-то блочный ввод-вывод данных связанный с таблицами и индексами. Необходимые данные читаются с дисков в память в специальную область "shared buffers". Результаты запроса, если это updates, deletes, фиксируются в журнале транзакций в WAL. Некоторая статистическая информация попадает в лог или в коллектор статистики. И результат запроса отдается уже клиенту обратно. После чего клиент может повторить все заного с новым запросом.
Что у нас с фоновыми задачами и с фоновыми процессами? У нас есть несколько процессов, которые обеспечивают работоспособность и поддерживают базу данных в нормальном рабочем режиме. Эти процессы также будут затрагиваться в докладе: это autovacuum, checkpointer, процессы, связанные с репликацией, background writer. Каждого из них я буду затрагивать по мере доклада.

Какие проблемы есть со статистикой?
- Информации много. PostgreSQL 9.4 предоставляет 109 метрик для просмотра данных статистики. Однако, если в базе данных хранятся много таблиц, схем, баз, то все эти метрики придется умножить на соответствующее количество таблиц, баз. Т. е. информации становится еще больше. И утонуть в ней очень легко.
- Следующая проблема – это то, что статистика представлена счетчиками. Если мы посмотрим эту статистику, то мы увидим постоянно увеличивающиеся счетчики. И если с момента сброса статистики прошло очень много времени, мы увидим миллиардные значения. И они нам ничего не говорят.
- Нет истории. Если у вас произошел какой-то сбой, что-то упало 15-30 минут назад, не получится воспользоваться статистикой и посмотреть, что происходило 15-30 минут назад. Это проблема.
- Отсутствие встроенного в PostgreSQL инструмента – это проблема. Разработчики ядра не предоставляют никакой утилиты. У них нет ничего такого. Они просто дают статистику в базе. Пользуйтесь, делайте к ней запрос, что хотите, то и делайте.
- Так как встроенного в PostgreSQL инструмента нет, то это является причиной другой проблемы. Множество сторонних инструментов. Каждая компания, у которой есть более-менее прямые руки, пытается написать свою программу. И в итоге в community очень много инструментов, которыми можно пользоваться для работы со статистикой. И в одних инструментах есть одни возможности, в других инструментах нет других возможностей, либо есть какие-то новые возможности. И возникает ситуация, что нужно использовать два-три-четыре инструмента, которые друг друга перекрывают и обладают разными функциями. Это очень неприятно.

Что из этого следует? Важно уметь брать статистику напрямую, чтобы не зависеть от программ, либо как-то самому улучшить эти программы: добавить какие-то функции, чтобы получить свою выгоду.
И нужны базовые знания SQL. Чтобы получить какие-то данные из статистики, нужно составить запросы SQL, т. е. вам нужно знать, как составляются select, join.

Статистика предлагает нам несколько вещей. Их можно разделить на категории.
- Первая категория – это события, происходящие в базе. Это когда в базе происходит какое-то событие: запрос, обращение к таблице, автовакуум, коммиты, то это все события. Соответствующие этим события счетчики инкрементируются. И мы можем отследить эти события.
- Вторая категория – это свойства объектов такие, как таблицы, базы. У них есть свойства. Это размер таблиц. Мы можем отследить рост таблиц, рост индексов. Можем посмотреть изменения в динамике.
- И третья категория – это время, затраченное на событие. Запрос – это событие. У него есть своя конкретная мера длительности. Здесь запустился, тут закончился. Мы можем это отследить. Либо время чтения блока с диска или записи. Такие вещи тоже отслеживаются.

Источники статистики представлены следующим образом:
- В разделяемой памяти (shared buffers) есть сегмент для размещения там статичтических данных, там есть и те самые счетчики, которые постоянно инкрементируются, когда происходит те или иные события, либо возникают какие-то моменты в работе базы.
- Все эти счетчики не доступны пользователю и даже не доступны администратору. Это низкоуровневые вещи. Чтобы к ним обратиться PostgreSQL предоставляет интерфейс в виде SQL функций. Мы можем сделать select выброки с помощью этих функций и получить какую-то метрику (или набор метрик).
- Однако использовать эти функции не всегда удобно, поэтому функции являются базой для представлений (VIEWs). Это виртуальные таблицы, которые предоставляют статистику по какой-то конкретной подсистеме, либо по какому-то набору событий в базе данных.
- Эти встроенные представления (VIEWs) являются основным интерфейсом пользователя для работы со статистикой. Они доступны по-умолчанию без какой-либо дополнительной настройки, можете сразу ими пользоваться, смотреть, брать оттуда информацию. А еще есть contrib'ы. Contrib'ы есть официальные. Вы можете установить пакет postgresql-contrib (например, postgresql94-contrib), подгрузили необходимый модуль в конфигурации, указать для него параметры, перезапустить PostgreSQL и можно пользоваться. (Примечани��. В зависимости от дистрибутива, в последних версиях contrib пакет является частью основного пакета).
- И есть неофициальные contrib. Они не поставляются в стандартной поставке PostgreSQL. Их нужно либо скомпилировать, либо установить как библиотеку. Варианты могут быть самые разные, в зависимости от того, что придумал разработчик этого неофициального contrib’а.

На этом слайде представлены все те представления (VIEWs) и часть тех функций, которые доступны в PostgreSQL 9.4. Как мы видим, их очень много. И довольно легко запутаться, если вы столкнулись с этим в первый раз.
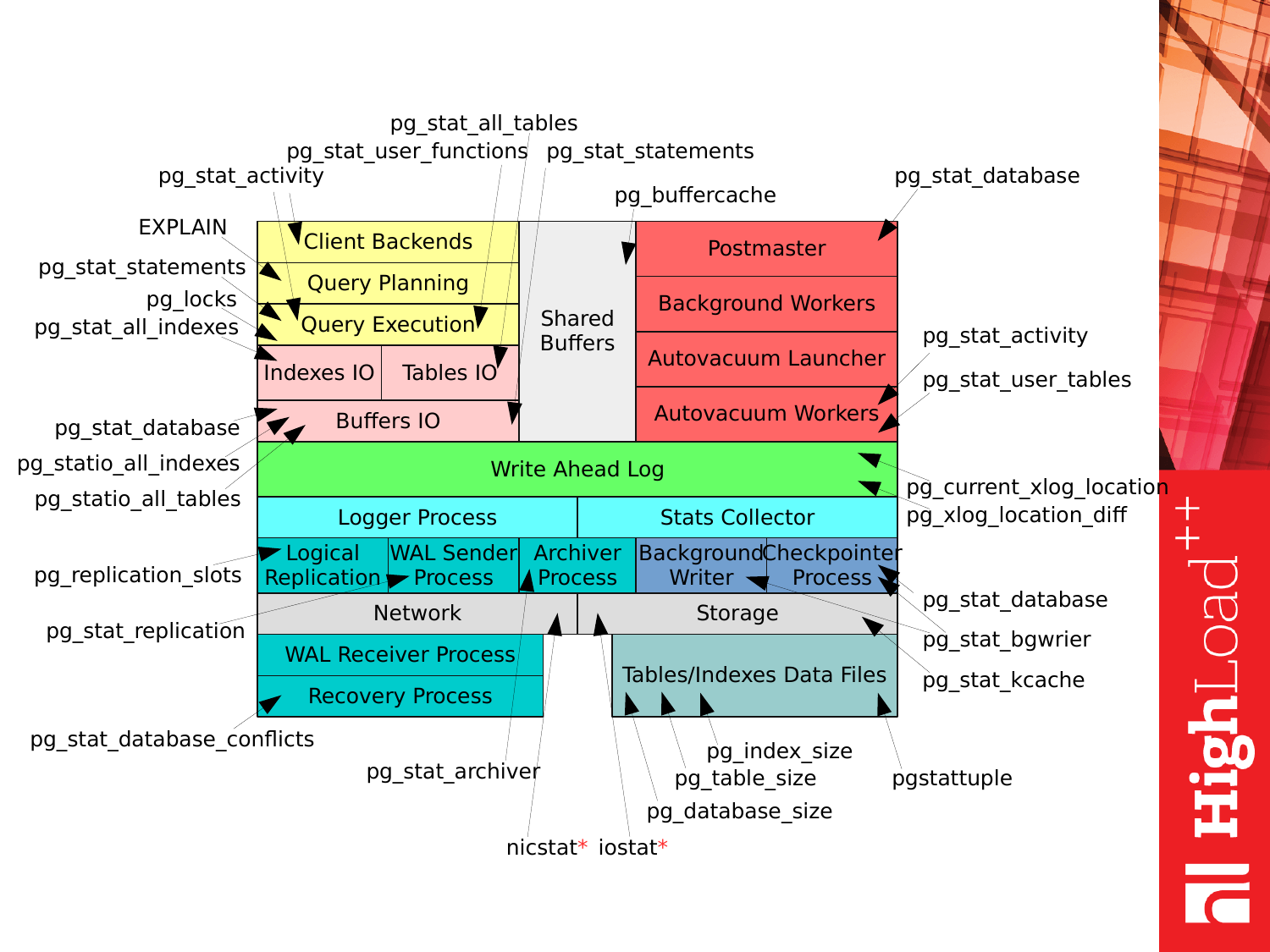
Однако, если мы возьмем предыдущую картинку Как тратится время на PostgreSQL и совместим с этим списком, то получим вот такую картинку. Каждое представление (VIEWs), либо каждую функцию мы можем использовать в тех или иных целях для получения соответствующей статистики, когда у нас работает PostgreSQL. И можем получить уже какую-то информацию о работе подсистемы.

Первое, что мы рассмотрим, это pg_stat_database. Как мы видим, это представление. В ней очень много информации. Самая разнообразная информация. И она дает очень полезное знание, что у нас происходит в базе данных.
Что мы можем полезное оттуда взять? Начнем c самых простых вещей.

select
sum(blks_hit)*100/sum(blks_hit+blks_read) as hit_ratio
from pg_stat_database;Первое, что мы можем посмотреть – это процент попадания в кэш. Процент попадания в кэш – это полезная метрика. Она позволяет оценить, какой объем данных берется из кэша shared buffers, а какой объем читается с диска.
Понятное дело, что чем большее у нас попадание в кэш, то тем лучше. Мы оцениваем эту метрику как процент. И, например, если у нас процентное отношение этих попаданий в кэш больше 90 %, то это хорошо. Если оно опускается ниже 90 %, значит, у нас памяти недостаточно для удержания горячей "головы" данных в памяти. И чтобы эти данные использовать, PostgreSQL вынужден обращаться к диску и это медленнее чем если бы данные читались из памяти. И нужно уже думать над увеличением памяти: либо shared buffers увеличивать, либо наращивать железную память (RAM).
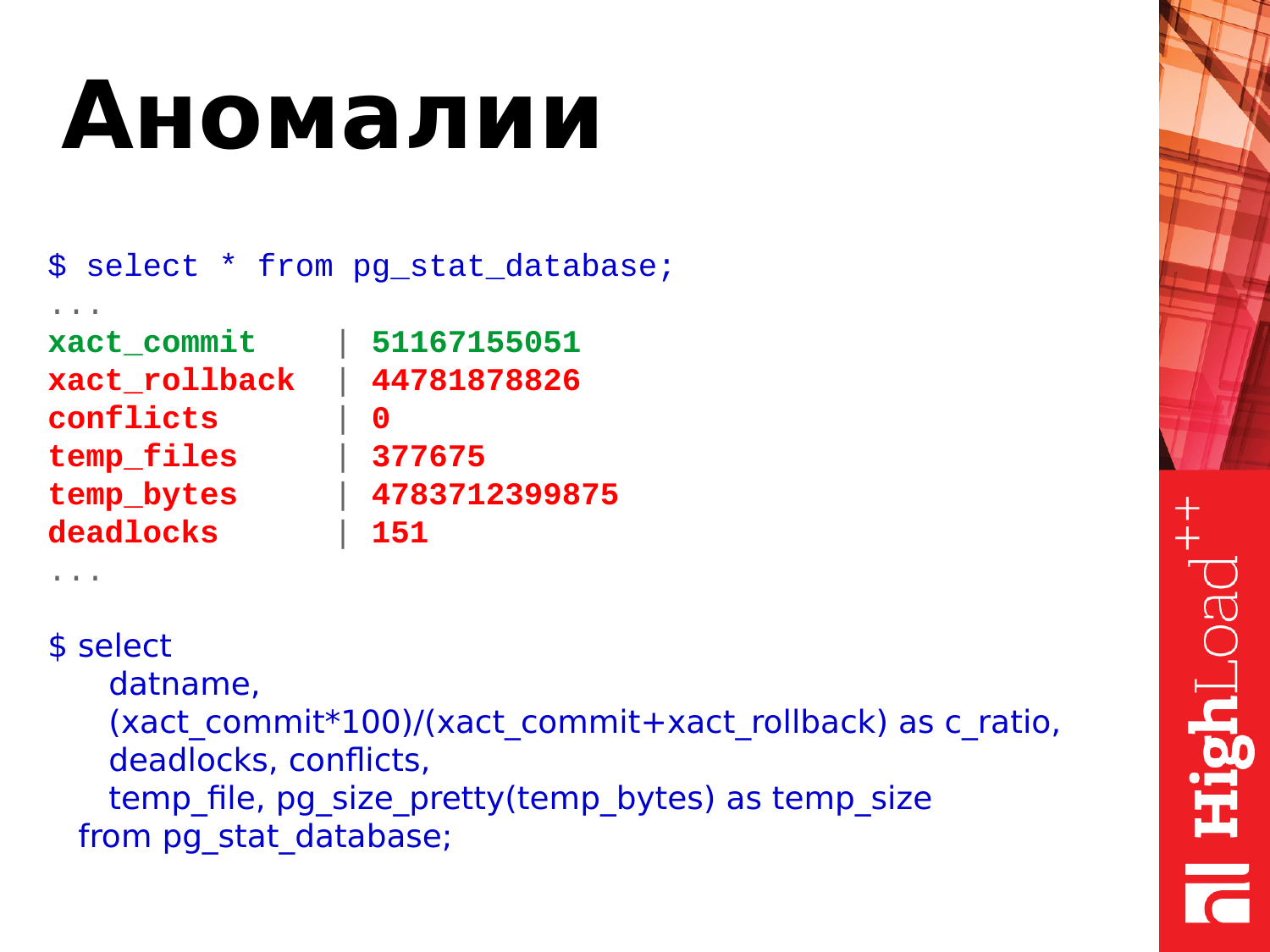
select
datname,
(xact_commit*100)/(xact_commit+xact_rollback) as c_ratio,
deadlocks, conflicts,
temp_file, pg_size_pretty(temp_bytes) as temp_size
from pg_stat_database;Что можно еще взять из этого представления? Можно посмотреть аномалии происходящие в базе. Что здесь показано? Здесь есть commits, rollbacks, создание временных файлов, их объем, deadlocks и конфликты.
Мы можем воспользоваться этим запросом. Этот SQL довольно простой. И можем посмотреть вот эти данные у себя.

И здесь сразу пороговые значения. Мы смотрим соотношение commits и rollbacks. Commits – это успешное подтверждение транзакции. Rollbacks – это откат, т. е. транзакция делала какую-то работу, напрягала базу, что-то считала, а потом произошел сбой, и результаты транзакции отбрасываются. Т. е. количество rollbacks, постоянно увеличивающихся, это плохо. И следует как-то избегать их, и править код, чтобы такого не происходило.
Конфликты (conflicts) связаны с репликацией. И их тоже следует избегать. Если у вас какие-то запросы, которые выполняются на реплике и возникают конфликты, то нужно эти конфликты разбирать, смотреть, что происходит. Детали можно найти в логах. И устранять конфликтные ситуации, чтобы запросы приложения работали без ошибок.
Deadlocks – это тоже плохая ситуация. Когда запросы борются за ресурсы, один запрос обратился к одному ресурсу и взял блокировку, второй запрос обратился ко второму ресурсу и также взял блокировку, а потом оба запроса обратились к ресурсам друг друга и заблокировались в ожидании когда сосед отпустит блокировку. Это тоже проблемная ситуация. Их нужно решать на уровне переписывания приложений и сериализации доступа к ресурсам. И если вы видите, что у вас deadlocks увеличиваются постоянно, нужно смотреть детали в логах, разбирать возникашие ситуации и смотреть в чем проблема.
Временные файлы (temp_files) – это тоже плохо. Когда пользовательскому запросу не хватает памяти для размещения оперативных, временных данных, он создает на диске файл. И все операции которые бы он мог выполнить во временном буфере в памяти, начинает выполнять уже на диске. Это медленно. Это увеличивает время выполнения запроса. И клиент, отправивший запрос к PostgreSQL получит ответ чуть позже. Если эти все операции будут выполняться в памяти, Postgres ответит гораздо быстрее и клиент будет меньше ждать.

Pg_stat_bgwriter – это представление описывает работу двух фоновых подсистем PostgreSQL: это checkpointer и background writer.

Для начала разберем контрольные точки, т.н. checkpoints. Что такое контрольные точки? Контрольная точка это позиция в журнале транзакций сообщающая что все изменения данных зафиксированные в журнала успешно синхронизированны с данными на диске. Процесс в зависимости от рабочей нагрузки и настроек может быть длительными и по большей части заключается в синхронизации грязных страниц в shared buffers с датфайлами на диске. Для чего это нужно? Если бы PostgreSQL все время обращался к диску и брал оттуда данные, и записывал данные при каждом обращении, это было бы медленно. Поэтому у PostgreSQL есть сегмент памяти, размер которого зависит от параметров в конфигурации. Postgres размещает в этой памяти оперативные данные для последующей обработки или выдачи по запросам. В случае запросов на изменение данных происходит их изменение. И мы получаем две версии данных. Одна у нас в памяти, другая на диске. И периодически нужно эти данные синхронизировать. Нам нужно то, что изменено в памяти, синхронизировать на диск. Для этого нужны checkpoint.
Checkpoint проходит по shared buffers, помечает грязные страницы, что они нужны для checkpoint. Потом запускает второй проход по shared buffers. И страницы, которые помечены для checkpoint, он их уже синхронизирует. Таким образом выполняется синхронизация данных уже с диском.
Есть два типа контрольных точек. Один checkpoint выполняется по тайм-ауту. Это checkpoint полезный и хороший – checkpoint_timed. И есть checkpoints по требованию – checkpoint required. Такая контрольная точка происходит когда у нас идет очень большая запись данных. Мы записали очень много журналов транзакций. И PostgreSQL считает, что ему нужно все это как можно быстрее синхронизировать, сделать контрольную точку и жить дальше.
И если вы посмотрели статистику pg_stat_bgwriter и увидели, что у вас checkpoint_req гораздо больше, чем checkpoint_timed, то это плохо. Почему плохо? Это значит, что PostgreSQL находится в постоянной стрессовой ситуации, когда ему нужно записывать данные на диск. Checkpoint по таймауту менее стрессовый и выполняется согласно внутреннему расписанию и как бы растянут по времени. У PostgreSQL есть возможность сделать паузы в работе и не напрягать дисковую подсистему. Это для PostgreSQL полезно. И запросы, которые выполняются во время checkpoint не будут испытывать стрессы от того, что дисковая подсистема занята.
И для регулировки checkpoint есть три параметра:
сheckpoint_segments.
сheckpoint_timeout.
сheckpoint_competion_target.
Они позволяют регулировать работу контрольных точек. Но не буду на них задерживаться. Их влияние – это уже отдельная тема.
Внимание: Рассматриваемая в докладе версия 9.4 уже неактуальна. В современных версиях PostgreSQL параметр checkpoint_segments заменен параметрами min_wal_size и max_wal_size.

Следующая подсистема это фоновый писатель — background writer. Что он делает? Он работает постоянно в бесконечном цикле. Сканирует страницы в shared buffers и странички грязные, которые он нашел, сбрасывает на диск. Таким образом он помогает checkpointer'у делать меньше работы в процессе выполнения контрольных точек.
Для чего он еще нужен? Он обеспечивает потребность в чистых страницах в shared buffers если они вдруг потребуются (в большом количестве и сразу) для размещения данных. Предположим возникла ситуация когда для выполнения запроса потребовались чистые страницы и они уже есть в shared buffers. Постгресовый backend просто берет их и использует, ему не надо самому ничего чистить. Но если вдруг таких страниц нет, бэкенд приостанавливает работу и начинает поиск страниц чтобы сбросить их на диск и взять для своих нужд — что негативно сказывается на времени выполняющегося в данный момент запроса. Если вы видите, что у вас параметр maxwritten_clean большой, это значит, что background writer не справляется со своей работой и нужно увеличивать параметры bgwriter_lru_maxpages, чтобы он смог за один цикл сделать больше работы, больше очистить страничек.
И другой очень полезный показатель – это buffers_backend_fsync. Бэкенды не делают fsync, потому что это медленно. Они передают fsync выше по IO stack checkpointer’у. У checkpointer есть своя очередь, он периодически fsync обрабатывает и страницы в памяти синхронизирует с файлами на диске. Если очередь большая у checkpointer и заполнена, то бэкенд вынужден сам делать fsync и это замедляет работу бэкенда, т. е. клиент получит ответ позже, чем мог бы. Если вы видите, что у вас это значение больше нуля, то это уже проблема и нужно обратить внимание на настройки background writer'а и также оценить производительность дисковой подсистемы.

Внимание: _Следующий текст описывает статистические представления связанные с репликацией. Большая часть имен представлений и функций была переименована в Postgres 10. Суть переименований сводилась к замене xlog на wal и location на lsn в именах функций/представлений и т.п. Частный пример, функция pg_xlog_location_diff() была переименована в pg_wal_lsn_diff()._
Тут тоже у нас много всего. Но понадобятся нам всего лишь пункты, связанные с location.
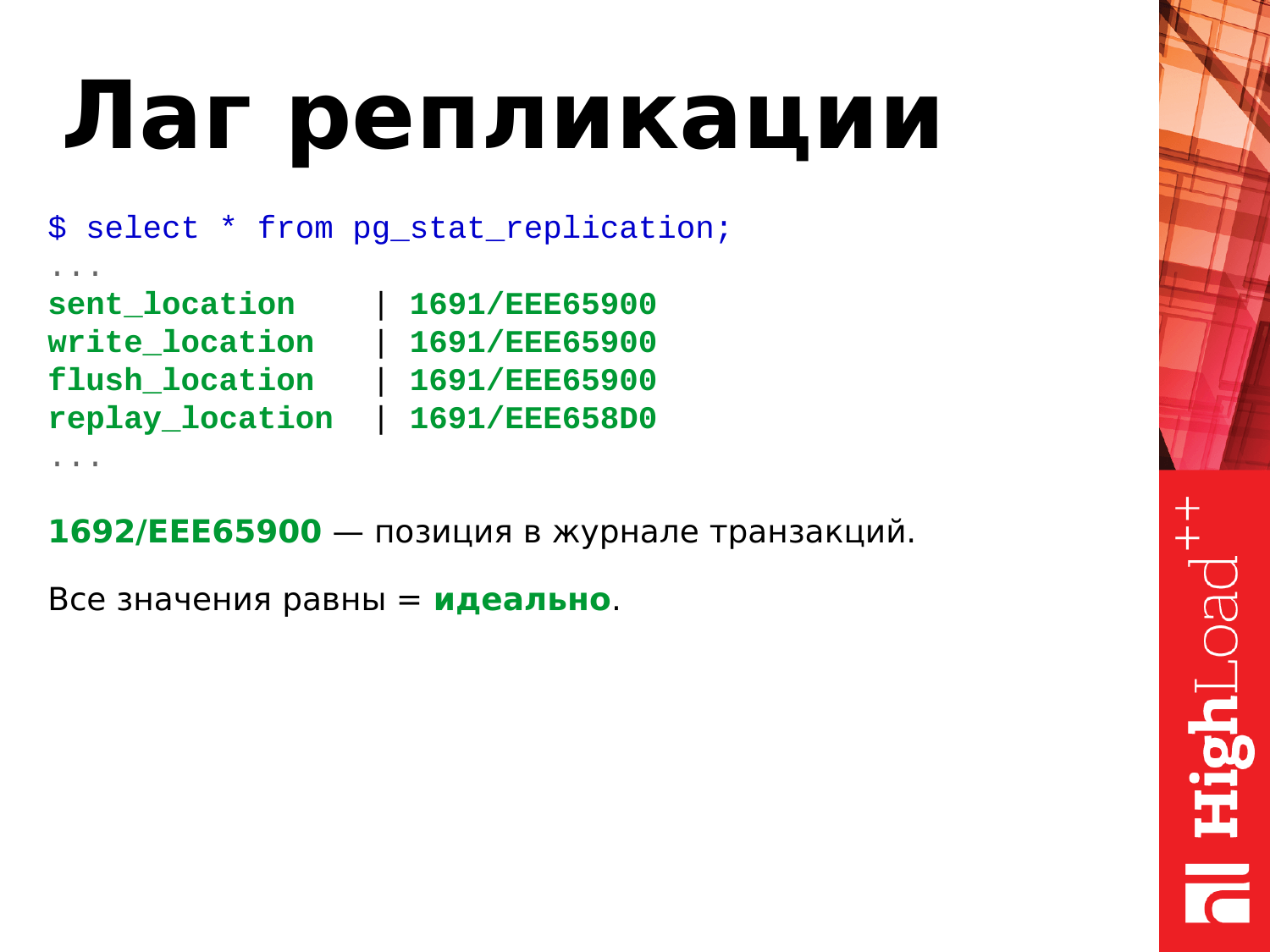
Если мы видим, что все значения равны, то это идеальный вариант и реплика не отстает от мастера.
Вот эта шестнадцатеричная позиция – это позиция в журнале транзакций. Она постоянно увеличивается, если в базе есть какая-то активность: inserts, deletes и т. д.

сколько записано xlog в байтах
$ select
pg_xlog_location_diff(pg_current_xlog_location(),'0/00000000');
лаг репликации в байтах
$ select
client_addr,
pg_xlog_location_diff(pg_current_xlog_location(), replay_location)
from pg_stat_replication;
лаг репликации в секундах
$ select
extract(epoch from now() - pg_last_xact_replay_timestamp());Если эти вещи отличаются, значит есть какой-то лаг. Лаг – это отставание реплики от мастера, т. е. данные отличаются между серверами.
Есть три причины отставания:
- Это дисковая подсистема не справляется с записью синхронизации файлов.
- Это возможные ошибки сети, либо перегрузка сети, когда данные не успевают доезжать до реплики и он не может их воспроизвести.
- И процессор. Процессор – это очень редкий случай. И я видел такое два или три раза, но такое тоже может быть.
И вот три запроса, которые нам позволяют использовать статистику. Мы можем оценить, сколько записано у нас в журнале транзакции. Есть такая функция pg_xlog_location_diff и можем оценить лаг репликации в байтах и секундах. Мы тоже для этого используем значение из этого представления (VIEWs).
Примечание: _Вместо pg_xlog_locationdiff() функции можно использовать оператор вычитания и вычитать один location из другого. Удобно.
С лагом, который в секундах, есть один момент. Если на мастере не происходит никакой активности, транзакция там была где-то 15 минут назад и активности никакой нет, и если мы на реплике посмотрим этот лаг, то мы увидим лаг в 15 минут. Об этом стоит помнить. И это может вводить в ступор, когда вы посмотрели этот лаг.
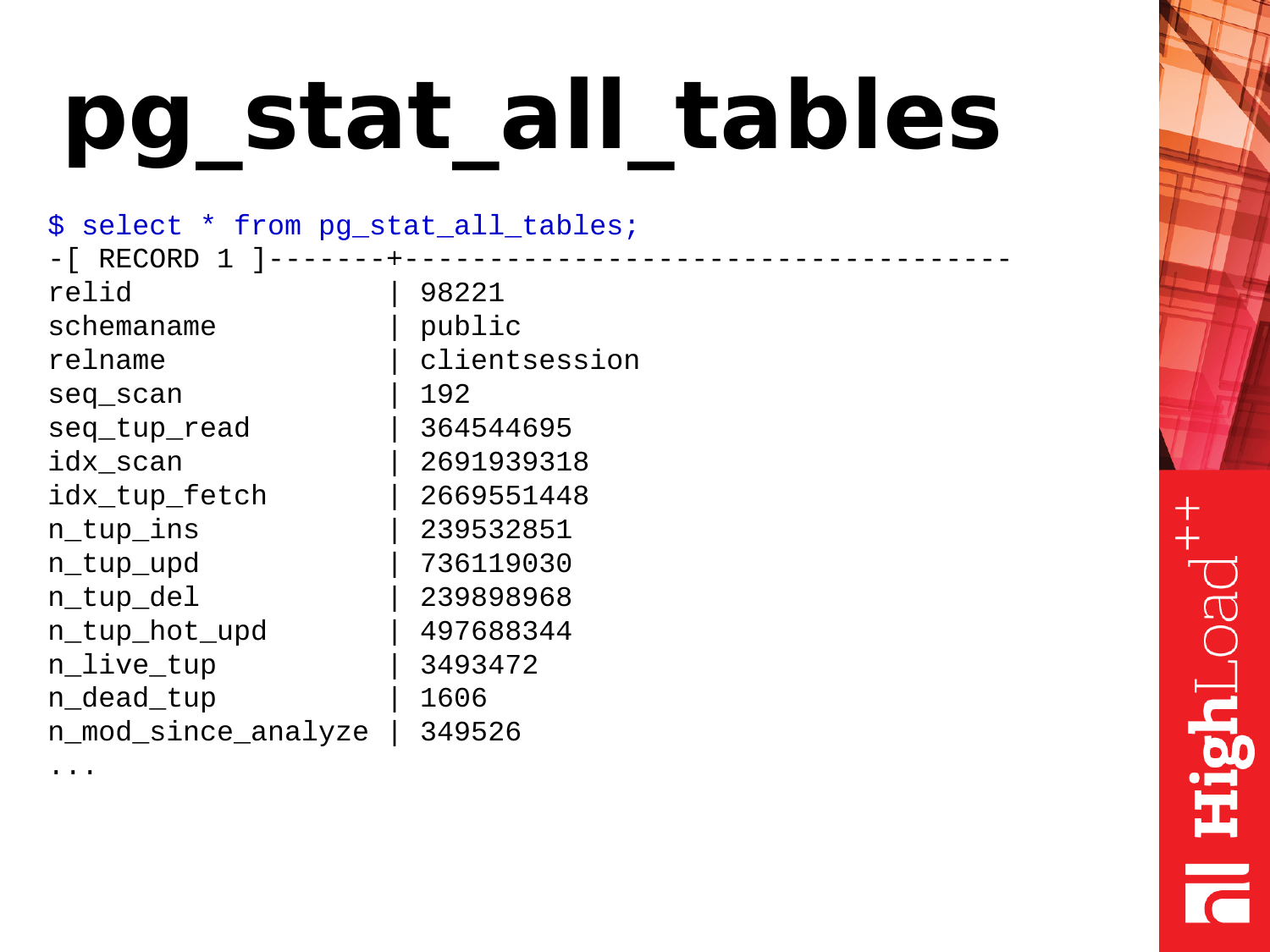
Pg_stat_all_tables – еще одно полезное представление. Оно показывает статистику по таблицам. Когда у нас в базе есть таблицы, с ним есть какая-то активность, какие-то действия, мы можем эту информацию получить из этого представления.

select
relname,
pg_size_pretty(pg_relation_size(relname::regclass)) as size,
seq_scan, seq_tup_read,
seq_scan / seq_tup_read as seq_tup_avg
from pg_stat_user_tables
where seq_tup_read > 0 order by 3,4 desc limit 5;Первое, что мы можем посмотреть, это последовательные сканирования по таблице. Само число после этих проходов еще не обязательно плохо и не показатель того, что нам нужно уже что-то предпринимать.
Однако есть вторая метрика – seq_tup_read. Это количество строк, возвращенных в результате последовательного сканирования. Если усредненное число превышает 1 000, 10 000, 50 000, 100 000, то это уже показатель, что возможно вам нужно где-то построить индекс, чтобы обращения были по индексу, либо возможно оптимизировать запросы которые использую такие последовательные сканирования, чтобы такого не было.
Простой пример – допустим, запрос с большим OFFSET и LIMIT стоит. К примеру сканируется 100 000 строк в таблице и после этого берется 50 000 нужных строк, а предыдщие отсканированные строки отбрасываются. Это тоже плохой кейс. И такие запросы нужно оптимизировать. И здесь вот такой простой SQL-запрос, на котором можно это посмотреть и оценить полученные цифры.

select
relname,
pg_size_pretty(pg_total_relation_size(relname::regclass)) as
full_size,
pg_size_pretty(pg_relation_size(relname::regclass)) as
table_size,
pg_size_pretty(pg_total_relation_size(relname::regclass) -
pg_relation_size(relname::regclass)) as index_size
from pg_stat_user_tables
order by pg_total_relation_size(relname::regclass) desc limit 10;Размеры таблиц также можно получить с помощью этой таблицы и с помощью дополнительных функций pg_total_relation_size(), pg_relation_size().
Вообще, есть метакоманды \dt и \di, которые можно использовать в PSQL и также посмотреть размеры таблиц и индексов.
Однако использование функций помогает нам посмотреть размеры таблиц еще с учетом индексов, либо без учетов индексов и уже делать какие-то оценки на основе роста базы данных, т. е. как она у нас растет, с какой интен��ивностью и делать уже какие-то выводы об оптимизации размеров.

Активность на запись. Что такое запись? Давайте рассмотрим операцию UPDATE – операцию обновления строк в таблице. По сути, update – это две операции (а то и ещё больше). Это вставка новой версии строки и пометка старой версии строки как устаревшей. В последствии придет автовакуум и вот эти устаревшие версии строк вычистит, пометит это место как доступное для повторного использования.
Кроме того, update – это не только обновление таблицы. Это еще обновление индексов. Если у вас на таблице много индексов, то при update все индексы, в которых участвуют поля, обновляемые в запросе, нужно будет также обновить. В этих индексах также будут устаревшие версии строк, которые нужно будет почистить.

select
s.relname,
pg_size_pretty(pg_relation_size(relid)),
coalesce(n_tup_ins,0) + 2 * coalesce(n_tup_upd,0) -
coalesce(n_tup_hot_upd,0) + coalesce(n_tup_del,0) AS total_writes,
(coalesce(n_tup_hot_upd,0)::float * 100 / (case when n_tup_upd > 0
then n_tup_upd else 1 end)::float)::numeric(10,2) AS hot_rate,
(select v[1] FROM regexp_matches(reloptions::text,E'fillfactor=(\\d+)') as
r(v) limit 1) AS fillfactor
from pg_stat_all_tables s
join pg_class c ON c.oid=relid
order by total_writes desc limit 50;И за счет свего дизайна, UPDATE – это тяжеловесные операции. Но их можно облегчить. Есть hot updates. Они появились в PostgreSQL версии 8.3. И что это такое? Это легковесный update, который не вызывает перестроение индексов. Т. е. мы обновили запись, но при этом обновилась только запись в страничке (которая принадлежит таблице), а индексы по-прежнему указывают на ту же самую запись в странице. Там немного такая интересная логика работы, когда приходит вакуум, то он эти цепочки hot перестраивает и все продолжает работать без обновления индексов, и происходит все с меньшей тратой ресурсов.
И когда у вас n_tup_hot_upd большое, то это очень хорошо. Это значит, что легковесные updates преобладают и это по ресурсам выходит нам дешевле и все прекрасно.

ALTER TABLE table_name SET (fillfactor = 70);Как увеличить объем hot updateов? Мы можем использовать fillfactor. Он определяет размер резервируемого свободного месте при заполнении страницы в таблице с помощью INSERT'ов. Когда в таблицу идут inserts, то они полностью заполняют страничку, не оставляют в ней пустого места. Потом выделяется новая страничка. Снова данные заполняются. И это поведение по умолчанию, fillfactor = 100 %.
Мы можем сделать fillfactor в 70 %. Т. е. при inserts выделилась новая страничка, но заполнилось всего лишь 70 % странички. И 30 % у нас осталось на резерв. Когда нужно будет сделать update, то он с высокой долей вероятности произойдет в той же самой страничке, и новая версия строки поместится в ту же страничку. И будет сделан hot_update. Таким образом облегчается запись на таблицах.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Очередь автовакуума. Автовакуум – это такая подсистема, по которой статистике в PostgreSQL очень мало. Мы можем в таблицах только в pg_stat_activity увидеть, сколько у нас вакуумов длятся в данный момент. Однако понять, сколько таблиц в очереди у него с ходу очень сложно.
Примечание: _Начиная с версии Postgres 10 ситуация с отслеживанием ватовакуума сильно улучшилась — появилось представление pg_stat_progressvacuum, которое существенно упрощает вопрос мониторинга автовакуума.
Мы можем использовать вот такой упрощенный запрос. И можем посмотреть, когда должен будет сделан вакуум. Но, как и когда должен запуститься вакуум? Вот эти устаревшие версии строк, о которых я говорил раньше. Update произошел, новая версия строки вставилась. Появилась устаревшая версия строки. В таблице pg_stat_user_tables есть такой параметр n_dead_tup. Он показывает количество "мертвых" строк. И как только количество мертвых строк стало больше, чем определенный порог, к таблице придет автовакуум.
И как рассчитывается этот порог? Это вполне конкретное процентное отношение от общего числа строк в таблице. Есть параметр autovacuum_vacuum_scale_factor. Он и определяет процентное отношение. Допустим, 10 % + там дополнительный базовый порог в 50 строк. И что получается? Когда у нас мертвых строк стало больше чем "10 % + 50" от всех строк в таблице, то мы ставим таблицу на автовауум.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Однако тут есть один момент. Базовые пороги у параметров av_base_thresh и av_scale_factor могут назначаться индивидуально. И, соответственно, порог будет не глобальный, а индивидуальный для таблицы. Поэтому чтобы рассчитать, там нужно использовать ухищрения и уловки. И если вам интересно, то вы можете посмотреть на опыт наших коллег из Avito (ссылка на слайде недействительно и обновлена в тексте).
Они написали для munin plugin, которые учитывает эти вещи. Там портянка на два листа. Но считает он корректно и довольно эффективно позволяет оценить, где у нас вакуума много требуется для таблиц, где мало.
Что мы можем с этим сделать? Если у нас очередь большая и автовакуум не справляется, то мы можем поднять количество воркеров вакуума, либо просто сделать вакуум агрессивнее, чтобы он триггерился раньше, обрабатывал таблицу маленькими кусочками. И тем самым очередь будет уменьшаться. — Главное здесь следить за нагрузкой на диски, т.к. вакуум штука небесплатная, хотя с появлением SSD/NVMe устройств проблема стала менее заметной.

Pg_stat_all_indexes – это статистика по индексам. Она небольшая. И мы можем по ней получить информацию по использованию индексов. И например можем определить какие индексы у нас лишние.

Как я уже говорил, update – это не только обновление таблиц, это еще и обновление индексов. Соответственно, если у нас на таблице много индексов то при обновлении строк в таблице, индексы проиндексированных полей также нужно обновить, и если у нас есть неиспользуемые индексы, по которым нет индексовых сканирований, то они у нас висят балластом. И от них нужно избавляться. Для этого нам нужно поле idx_scan. Мы просто смотрим количество индексных сканирований. Если у индексов ноль сканирований за относительно длинный период хранения статистики (не менее чем 2-3 недели), то вероятней всего это плохие индексы, нам нужно от них избавиться.
Примечание: При поиске неиспользуемых индексов в случае кластеров потоковой репликации нужно проверять все узлы кластера, т.к. статистика не глобальная, и если индекс неиспользуется на мастере, то он может использоваться на репликах (если там есть нагрузка).
Две ссылки:
https://github.com/dataegret/pg-utils/blob/master/sql/low_used_indexes.sql
http://www.databasesoup.com/2014/05/new-finding-unused-indexes-query.html
Это более продвинутые примеры запросов для того, как искать неиспользуемые индексы.
Вторая ссылка – это довольно интересный запрос. Там очень нетривиальная логика заложена. Рекомендую его для ознакомления.

Что еще стоит подытожить по индексам?
Неиспользуемые индексы – это плохо.
Занимают место.
Замедляют операции обновления.
Лишняя работа для вакуума.
Если мы удалим неиспользуемые индексы, то мы сделаем базе только лучше.
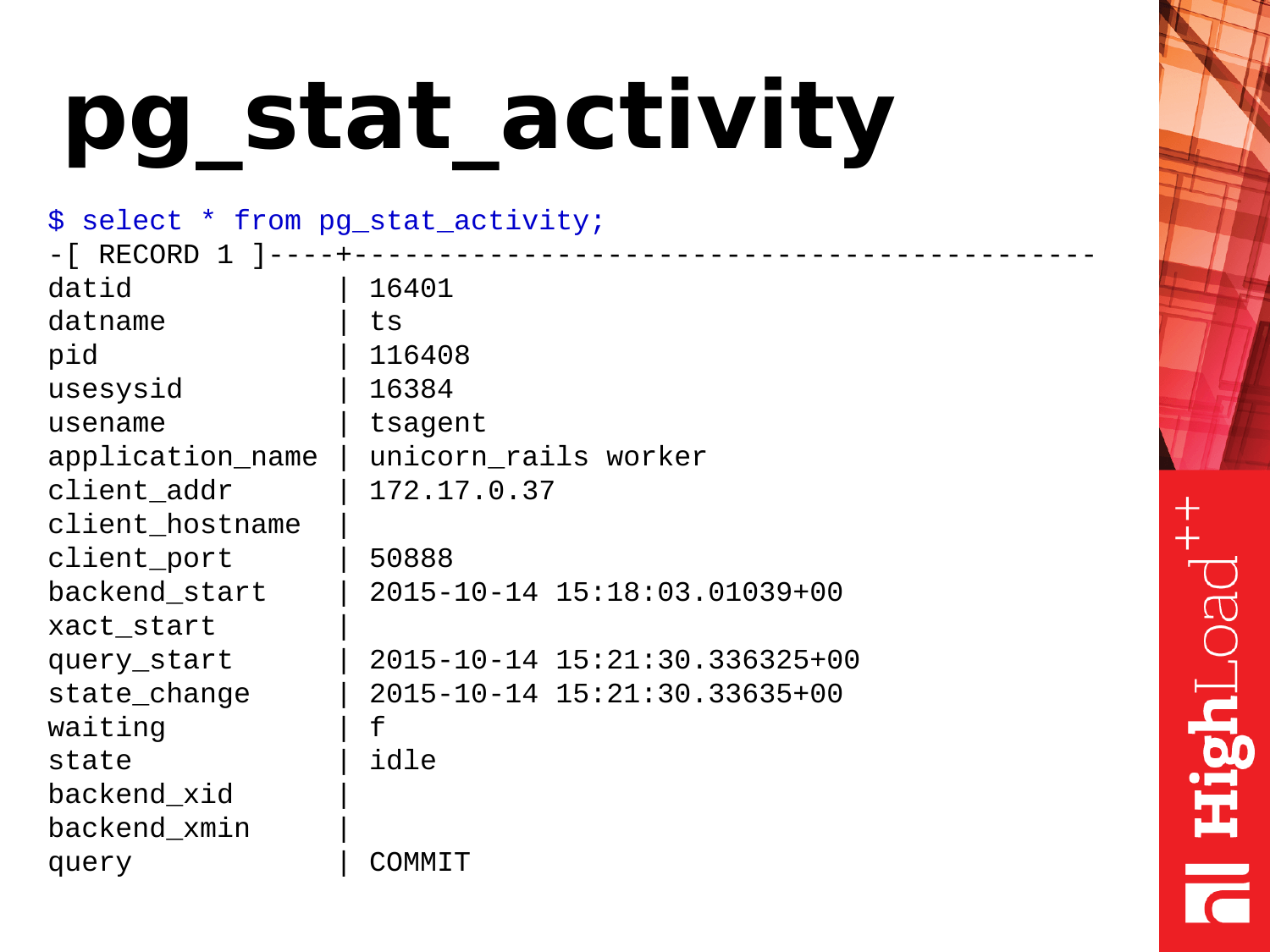
Следующее представление – это pg_stat_activity. Это аналог утилиты ps, только в PostgreSQL. Если ps'ом вы смотрите процессы в операционной системе, то pg_stat_activity вам покажет активность внутри PostgreSQL.
Что мы можем оттуда полезного взять?

select
count(*)*100/(select current_setting('max_connections')::int)
from pg_stat_activity;Мы можем посмотреть общую активность, что происходит в базе. Можем сделать новый деплой. У нас там все взорвалось, коннекты новые не принимаются, ошибки сыплются в приложении.

select
client_addr, usename, datname, count(*)
from pg_stat_activity group by 1,2,3 order by 4 desc;Мы можем выполнить вот такой запрос и посмотреть общий процент подключений относительно максимального лимита подключений и посмотреть, кто у нас занимает больше всего коннектов. И в данном приведенном случае мы видим, что user cron_role открыл 508 коннектов. И что-то с ним там произошло. Нужно с ним разбираться и смотреть. И вполне возможно, что это какое-то аномальное число подключений.

Если у нас нагрузка OLTP, запросы должны выполняться быстро, очень быстро и не должно быть долгих запросов. Однако, если возникают долгие запросы, то в краткосрочной перспективе ничего страшного нет, но в долгосрочной перспективе долгие запросы вредят базе, они увеличивают bloat эффект таблиц, когда происходит фрагментация таблиц. И от bloat, и от долгих запросов нужно избавляться.

select
client_addr, usename, datname,
clock_timestamp() - xact_start as xact_age,
clock_timestamp() - query_start as query_age,
query
from pg_stat_activity order by xact_start, query_start;Обратите внимание: вот таким запросом мы можем определять долгие запросы и транзакции. Мы используем функцию clock_timestamp() для определения времени работы. Долгие запросы, которые мы нашли, мы можем их запомнить, выполнить explain, посмотреть планы и как-то оптимизировать. Текущие долгие запросы мы отстреливаем и дальше живем.

select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';Плохие транзакции – это транзакции в состоянии idle in transaction и idle in transaction (aborted).
Что это значит? Транзакции имеют несколько состояний. И одно из этих состояний могут принимать в любой момент времени. Для определения состояний есть поле state в этом представлении. И мы используем его для определения состояния.

select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';И, как я уже сказал выше, эти два состояния idle in transaction и idle in transaction (aborted) – это плохо. Что это такое? Это когда приложение открыло транзакцию, сделало какие-то действи�� и ушло по своим делам. Транзакция осталась открытая. Она висит, в ней ничего не происходит, она занимает коннект, блокировки на измененные строки и потенциально еще увеличивает bloat других таблиц, из-за архитектуры транзакционного движка Postrges'а. И такие транзакции тоже следует отстреливать, потому что они вредные вообще, при любом раскладе.
Если вы видите, что их у вас в базе больше 5-10-20, то нужно уже обеспокоиться и начинать с ними что-то делать.
Здесь мы также для времени вычисления используем clock_timestamp(). Транзакции отстреливаем, приложение оптимизируем.
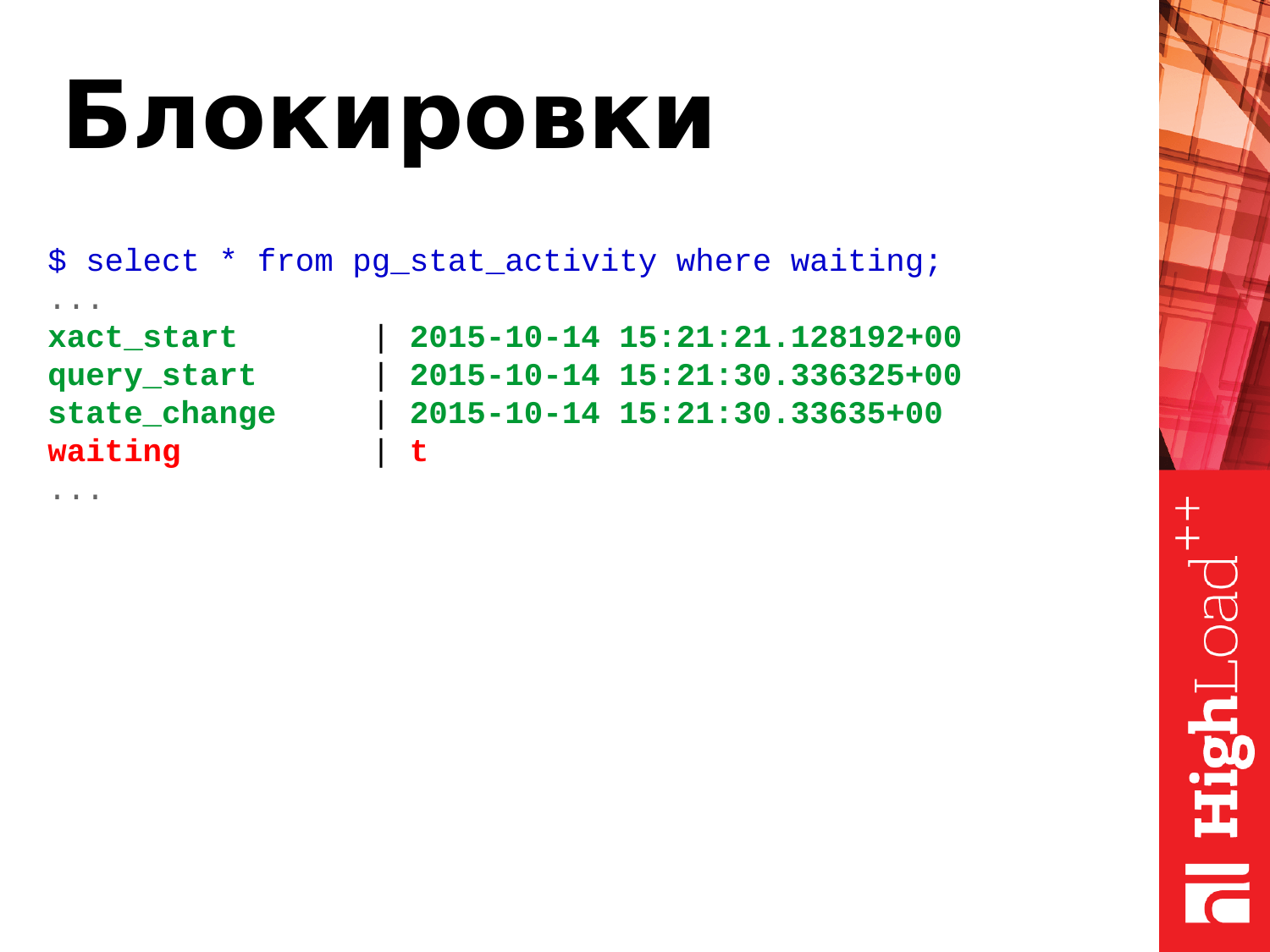
Как я уже говорил выше, блокировки – это когда две и больше транзакций борются за один или группу ресурсов. Для этого у нас есть поле waiting с булевым значением true или false.
True – это значит, что процесс находится в ожидании, нужно что-то делать. Когда процесс находится в ожидании, значит, клиент, который инициировал этот процесс тоже ждет. Клиент в браузере сидит и тоже ждет.
Внимание: _Начиная с версии Postgres 9.6 поле waiting удалено и вместо него добавлены два более информативных поля wait_event_type и wait_event._

Что делать? Если вы видите true, в течение долго времени то значит, от таких запросов надо избавляться. Мы просто такие транзакции отстреливаем. Разработчикам пишем, что нужно как-то оптимизировать, чтобы не было гонки за ресурсами. И дальше разработчики оптимизируют приложение, чтобы такого не возникало.
И крайний, но при этом потенциально не фатальный случай – это возникновение deadlocks. Две транзакции обновили два ресурса, потом обращаются к ним снова, уже к противоположным ресурсам. PostgreSQL в этом случае берет и сам отстреливает транзакцию, чтобы другая могла продолжить работу. Это тупиковая ситуация и она сама не разбирается. Поэтому PostgreSQL вынужден принимать крайние меры.

https://github.com/lesovsky/uber-scripts/blob/master/postgresql/sql/c4_06_show_locked_queries.sql
https://github.com/lesovsky/uber-scripts/blob/master/postgresql/sql/show_locked_queries_95.sql
https://github.com/lesovsky/uber-scripts/blob/master/postgresql/sql/show_locked_queries_96.sql
http://big-elephants.com/2013-09/exploring-query-locks-in-postgres/
И вот два запроса, которые позволяют отслеживать блокировки. Мы используем представление pg_locks, которая позволяет отслеживать тяжеловесные блокировки.
И первая ссылка – это сам текст запроса. Он довольно-таки длинный.
И вторая ссылка – это статья по locks. Ее полезно почитать, она очень интересная.
Итак, что мы видим? Мы видим два запроса. Транзакция с ALTER TABLE – это блокирующая транзакция. Она запустилась, но не завершилась и приложение запстившее эту транзакцию где-то занимается другими делами. И второй запрос – update. Он ждет, когда закончится alter table, чтобы продолжить свою работу.
Вот так мы можем выяснять, кто кого залочил, держит и можем разбираться с этим дальше.

Следующий модуль – это pg_stat_statements. Как я уже сказал, это модуль. Чтобы им воспользоваться нужно подгрузить его библиотеку в конфигурации, перезапустить PostgreSQL, установить модуль (одной командой) и дальше у нас появится новое представление.

Cреднее время запроса в милисекундах
$ select (sum(total_time) / sum(calls))::numeric(6,3)
from pg_stat_statements;
Самые активно пишущие (в shared_buffers) запросы
$ select query, shared_blks_dirtied
from pg_stat_statements
where shared_blks_dirtied > 0 order by 2 desc;Что мы можем оттуда взять? Если говорить о простых вещах, мы можем взять среднее время выполнения запроса. Время растет, значит, у нас PostgreSQL отвечает медленно и нужно что-то предпринимать.
Можем посмотреть самые активные пишущие транзакции в базе данных, которые меняют данные в shared buffers. Посмотреть, кто у нас там обновляет или удаляет данные.
И можем просто посмотреть разную статистику по этим запросам.

https://github.com/dataegret/pg-utils/blob/master/sql/global_reports/query_stat_total.sql
Мы pg_stat_statements используем для построения отчетов. Раз в сутки сбрасываем статистику. Накапливаем ее. Перед сбросом статистики в следующий раз, строим отчет. Вот ссылка на отчет. Вы можете его посмотреть.

Что мы делаем? Мы подсчитываем общую статистику по всем запросам. За��ем для каждого запроса мы считаем его индивидуальный вклад в эту общую статистику.
И что мы можем посмотреть? Мы можем посмотреть суммарное время выполнения всех запросов конкретного типа на фоне всех остальных запросов. Можем посмотреть использование ресурсов процессора и ввода-вывода относительно общей картины. И уже оптимизировать эти запросы. Мы строим топ запросов по этому отчету и уже получаем пищу для размышления, что оптимизировать.

Что у нас осталось за кадром? Осталось еще несколько представлений, которые я не стал рассматривать, потому что время ограничено.
Есть pgstattuple – это тоже дополнительный модуль из стандартного пакета contribs. Он позволяет оценить bloat таблицы, т.н. фрагментацию таблицы. И если фрагментация большая, нужно ее убирать, использовать разные инструменты. И функция pgstattuple работает долго. И чем больше таблиц, тем дольше она будет работать.

Следующий contrib – это pg_buffercache. Он позволяет проводить инспекцию shared buffers: насколько интенсивно и под какие таблицы утилизируются страницы буфера. И просто позволяет заглянуть в shared buffers и оценить происходящее там.
Следующий модуль – это pgfincore. Он позволяет проводить низкоуровневые операции с таблицами через системный вызов mincore(), т. е. он позволяет загрузить таблицу в шаредные буфера, либо ее выгрузить. И позволяет помимо прочего проводить инспекцию страничного кэша операционной системы, т. е. в каком объеме у нас таблица занимаем в page cache, в shared buffers и просто позволяет оценить загруженность таблицы.
Следующий модуль – pg_stat_kcache. Он также использует системный вызов getrusage(). И выполняет его перед и после выполнения запроса. И в полученной статистике позволяет оценить, сколько у нас запрос затратил на выполнение дискового ввода-вывода, т. е. операции с файловой системой и смотрит использование процессора. Однако модуль молодой (кхе-кхе) и для своей работы он требует PostgreSQL 9.4 и pg_stat_statements, о котором я говорил ранее.

Умение пользоваться статистикой – полезно. Вам не нужны сторонние программы. Вы можете сами заглянуть, посмотреть, что-то сделать, выполнить.
Пользоваться статистикой несложно, это обычный SQL. Вы собрали запрос, составили, отправили, посмотрели.
Статистика помогает ответить на вопросы. Если у вас возникают вопросы, вы обращаетесь к статистике – смотрите, делаете выводы, анализируете результаты.
И экспериментируйте. Запросов много, данных много. Всегда можно оптимизировать какой-то уже существующий запрос. Можно сделать свою версию запроса, которая подходит вам больше, чем оригинал и использовать его.

Годные ссылки, которые встречались в статье, по материалам которой, были в докладе.
Автор пиши ещё
https://dataegret.com/news-blog (eng)
The Statistics Collector
https://www.postgresql.org/docs/current/monitoring-stats.html
System Administration Functions
https://www.postgresql.org/docs/current/functions-admin.html
Contrib modules
https://www.postgresql.org/docs/current/pgstatstatements.html
https://www.postgresql.org/docs/current/pgstattuple.html
https://www.postgresql.org/docs/current/pgbuffercache.html
https://github.com/klando/pgfincore
https://github.com/dalibo/pg_stat_kcache
SQL utils and sql code examples
https://github.com/dataegret/pg-utils
Всем спасибо за внимание!

