Меня раздражает традиционная архитектура бизнес-приложений — об этом я уже говорил. Я критикую — я предлагаю. Сейчас я расскажу, к чему меня привели поиски решений для проблем из предыдущей статьи.
Мне нравится перебирать архитектурные концепции. Всю жизнь я пытаюсь найти в области архитектуры и дизайна ПО что-то работающее и в то же время простое. Не требующее разрыва мозга для понимания и кардинальной смены парадигмы. Идей накопилось порядочно и я решил объединить лучшие из них в своём фреймворке — Reinforced.Tecture. Разработка таких штук даёт гигантское количество пищи для размышлений, я хочу ими поделиться.
Тексты про такие технические вещи обычно до ужаса нудные. Я честно постарался не нудить, поэтому мой текст получился слегка агрессивным. Если вам с этим норм и интересно почитать про архитектуры .NET-приложений — заходите.
Это продолжение моей предыдущей статьи. Думаю, стоит сказать несколько слов перед тем, как перейти к сути дела.
Момент первый: я не считаю что я тут самый умный, не пытаюсь никого научить, оскорбить или что-то продать. Я уважаю многолетний опыт индустрии (и опыт читателей в том числе), но то, что я наблюдаю в кишках каждого проекта всю свою карьеру — мне совсем не нравится. Мне за это стыдно. Я делал Tecture для себя, чтобы сэкономить своё время и успокоить свои нервы. Я презираю DevRel и коммерцию в open source за лицемерие, о чём уже писал в своей старой статье. Мне никто не платит, я не выступаю от лица никакой компании и делаю свои проекты в свободное время на свой страх и риск, без всяких гарантий (о чём сказано в MIT-лицензии). Я делюсь своими наработками на языке программирования, который не высасывает мне мозг и если они будут кому-то полезны — хорошо.
Момент второй: я рассказываю про код для бизнеса. Не для игр, не для библиотек, не для фронтенда, а для бизнеса. Про кровавый интерпрайз, другими словами. Все знают что такое кровавый интерпрайз: опердни, автоматизации документооборота, складов, отчётности, делопроизводства, биллинг и прочая нудятина с префиксом "бизнес-" и привкусом офисной затхлости. Обычно такой код пишется двумя способами:
- дико обмазывается классическими ОО-паттернами родом из Java (да, даже на C#) и лихих 80х-90х. Например — MS-овский eShopOnContainers, авторы которого использовали вообще всё, что когда-либо слышали про ОО-дизайн. Меня от такого кода просто разрывает, потому что авторы таких монстров на peer review регулярно не могут объяснить нахрена они сделали именно так;
- говнокодится на коленке не самыми квалифицированными сотрудниками в тщетной попытке уложиться в дедлайны и удовлетворить бизнес на предмет требований. Как следствие — генерит больше мемов, чем полезной работы, а мне наливает фрустрации вместо утреннего кофе.
В народе первое считается "правильно", а второе вроде как "быстро". А вот чтобы и быстро и правильно — никто вроде не сделал. Поэтому я попробовал сам, со своими представления о прекрасном. Получилось крафтово, оригинально и местами кринжово для мира .NET.
Момент третий: я говорю про большие проекты для бизнеса. Не про хэллоуворлды, которых по 100 рублей пучок в базарный день можно купить на UpWork-е и не про стартапные кривожопые MVP. Я говорю про огромные, как слоновий хер проекты для бизнеса, которые делаются командами по 30 и более человек и длятся по 15 лет. Которые уже распластались на несколько баз данных, десятки подпроектов и просто вопят о том, что нужно уменьшить сложность. К таким проектам нет и никогда не было чёткой документации, но они работают в кровавом production-е, ежедневно обслуживая чёртову прорву разных бизнес-процессов. Прототипы списка покупок на node/react меня не интересуют. В них архитектура не нужна, потому что они всё равно сдохнут быстрее, чем их разработчики окончат университет. Мне с исследовательской позиции интересно управление сложностью в long term. У больших проектов остро встаёт вопрос "если переписывать, то как" и тут я попробую подкинуть пару идей.
Внешние системы
Бизнес-логика пишется в агрессивной среде: с одной стороны база данных со своими заморочками, с другой — очередь сообщений, с третьей ещё какой-нибудь SalesForce. Все эти внешние системы надо как-то прокладывать по периметру абстракциями, чтобы сконцентрироваться непосредственно на логике, а не на том, что там продактам очередного мутного API взбрело в голову. Работа с внешними системами — это краеугольный камень разработки бизнес-приложений.
Первое, что надо сделать чтобы отлепить свой код от внешних систем — это понять и принять факт, что сделать это полностью невозможно. Откройте свой рабочий проект, найдите то, что у вас называется "бизнес-логика": это просто код, который сам ничего не делает, а только говорит что делать внешним по отношению к вашей системам. Какие-то действительно сложные вычисления руками в рамках формошлёпства — скорее исключение, чем правило.
За примером далеко ходить не надо: скорее всего вы работаете с реляционной базой данных. Такие базы удобны бизнесу, который пользуется вашей системой, но не удобны вам. Поэтому вы используете O/RM, который по сути здоровенный конструктор SQL-я. Но в своё время вокруг O/RM-ов раздули дикий хайп и преподносили их чуть ли не как серебряную пулю от всех бед. А бизнесу тем временем совершенно пофигу — напишете вы INSERT-ы руками, или за вас их слепит библиотека. Я, кстати, не доверяю O/RM-ам уже давно и вот почему: они старательно пытаются внушить мне что "ложки нет". Есть, мол объекты, ты их меняешь. Есть коллекции, ты в них объекты добавляешь и удаляешь. А базы данных не существует. Ну подумаешь — надо вызывать SaveChanges время от времени.
И это полная чушь. Как и все подобные абстракции, O/RM безбожно течёт. Он рвётся от натуги, когда пытается полностью заменить собой базу. Регулярно приходится выбирать — сделать "как по ООП" или выразиться в терминах SQL, чтобы работало быстрее. Не я первый натолкнулся на эту проблему, она довольно известна и называется "object-relational impedance mismatch". При попытке понять причины и придумать решение можно легко потонуть в высокопарных рассуждениях о несоответствии контрактов. Поэтому, я предлагаю проще: дело в том, что я не работаю с объектами. Моя конечная цель — изменения в базе данных, пусть и сделанные через объекты. Нельзя долго делать вид, что базы нет, а то она обидится и даст по роже в самый неподходящий момент самым непредсказуемым образом. Но и писать интерпрайз целиком в примитивах базы данных — тоже хреновая затея. Я ж не DBA какой-нибудь и не хочу перевести всю логику на stored-процедуры.
Нужен разумный баланс. Я нашёл его в концепции каналов и аспектов. Моё авторское мнение: лучше не спорить с объективной реальностью и признать что у нас есть внешние системы. До них мы прокидываем каналы, с которыми работаем в тех или иных определённые аспектах.
Именно такое положение дел перетекло в Tecture дословно. И вот первая абстракция, которую я добавляю. Даже две абстракции, которые ходят парой.
Каналы (описаны в документации)
Канал олицетворяет любую внешнюю систему, с которой мы будем взаимодействовать. База данных, очередь, кэш или что у вас там. В Tecture канал — это интерфейс, не требующий реализации. Чтобы его задекларировать — достаточно написать:
public interface Db { }
Букву I перед именем канала писать не нужно.
Если бы я хотел поумничать и ляпнуть со сцены условного CodeFest-а что-то солидное от лица компании, то я бы наверняка сказал, что канал — "это типовой разделитель логики, который мы используем для извлечения метаинформации посредством HKT", но нет. Мне за умные слова никто не платит, поэтому я объясню проще.
В C# нет ключевого слова type как в F# или TypeScript, а его самый близкий аналог — interface без реализации. Каналы будут использоваться именно как type — подставляться в методы и классы тип-аргументами, предоставляя метаинформацию и шевеля шарповый type inference под нужными мне углами. Плюс, в C# нет HKT, поэтому с реальными системами каналы будут сопоставляться через позднее связывание на reflection-е.
Аспекты (в документации тут)
Канал есть. Теперь надо привязать к нему аспекты. Аспект определяет как мы работаем с системой. Но он не определяет как система работает на самом деле. У нас есть канал базы данных и в куске кода ниже по тексту мы хотим сказать что мы будем работать с ним через O/RM, а ещё будем пулять в неё голым SQL-ем. И если по-честному, то прятаться за этим каналом может всё, что угодно, и ему не обязательно поддерживающее смапленные на типы множества или SQL нативно. Достаточно исполнять обязательства по аспектам. Это как интерфейс, только обыгранный чуть по-другому.
Сначала я называл это "фича", но мне сказали что если переименовать в "аспект" — будет круче звучать. Я не очень хочу начинать со слов, что я сделал аспектно-ориентированный фреймворк. Вся теория вокруг AOP сложна и содержит кучу не очень удачных терминов. В Tecture можно разглядеть и аспекты, и советы, и срезы и точки соединения, но зачем? Я хочу уменьшить сложность, а не увеличить.
Ещё канал может подсасывать несколько аспектов сразу. Я снасильничал над компилятором C# и обыграл это через множественный экстенд интерфейсов. Получается приятно и лаконично:
PM> Install-Package Reinforced.Tecture.Aspects.Orm PM> Install-Package Reinforced.Tecture.Aspects.DirectSql
public interface Db : CommandQueryChannel < Reinforced.Tecture.Aspects.Orm.Command, Reinforced.Tecture.Aspects.Orm.Query>, CommandQueryChannel < Reinforced.Tecture.Aspects.DirectSql.Command, Reinforced.Tecture.Aspects.DirectSql.Query> { }
Аспекты подтягиваются из отдельных пакетов, в ядре же самого Tecture ничего нет кроме поддержки корневых концепций (сервисы, каналы, команды и запросы). Вся конкретика by design должна лежать отдельно. Это сознательное решение: ядро и аспекты не требуют ничего сверх netstandard2.0. Конкретного кода там довольно мало — считай одни абстракции. А сборки на нетстандарте превосходно подключаются и к .NET Core и к полноразмерному фреймворку.
Более того, ядро и аспекты (по задумке) являются необходимыми и достаточными зависимостями для реализации бизнес-логики. А это значит, что target framework для неё так же будет не выше netstandard2.0. В воздухе отчётливо запахло переездом на неткор. Таким образом, Tecture не мешает отвязке от полноразмерного .NET (читай: от windows), а очень даже потворствует.
Но на практике всё зависит от того, какие ещё зависимости подтягиваются в логику. Если там есть что-то хитрое, требующее полноразмерный .NET Framework, то чуда не случится.
А ещё умные мужики, придумавшие SOLID, называют это O/CP и Separation of Concerns. И благословляют.
Также аспекты — это крутая тема с организационной точки зрения. Башковитый системный архитект может сам нахерачить аспект и связать его с каналом, таким образом закрепив для линейных разрабов формальные правила работы с внешними системами, специфичные для проекта. И эти правила ни один джун не сможет перепрыгнуть в силу строгой типизации — компилятор тупо не даст. Если так строить систему, то в ней будет соблюдаться порядочек, которым архитект рулит формально и может контролировать.
И каналов, в общем-то, можно сделать сколько угодно. Тут есть свои бенефиты: можно организовать separated contexts в дань традиции DDD, а можно не мудрствуя лукаво использовать несколько баз данных из одного приложения без разрыва жопы.
Вот такие вот они — каналы и аспекты. Выглядит на самом деле слишком оторванно от реальности, надо приложить к чему-то конкретному чтобы заиграло. Поэтому я перейду к более приземлённой штуке: сервисам. Я считаю что сервис-ориентированная архитектура хороша, и реализовал её поддержку в Tecture. Вроде как интуитивно понятно к чему это, но есть своя специфика.
Сервисы
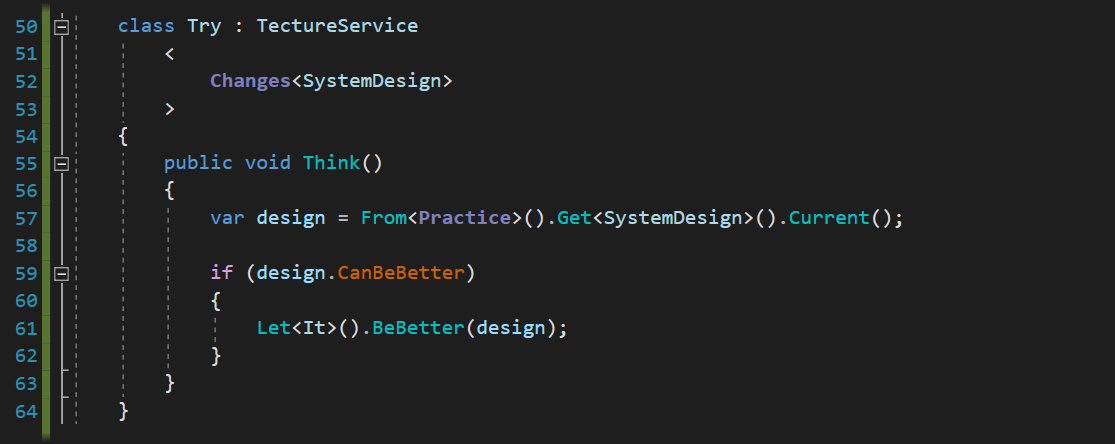
Сервисы — это место, где живёт бизнес-логика. Они оптимизированы именно под неё и ни для чего другого не подходят. Вот типичный сервис в Tecture, в котором лежит до ужаса тупая логика:
// это сервис public class Orders : TectureService < Updates<Order>, // он обновляет ордеры Adds<OrderLine> // и создаёт OrderLine-ы > { private Orders() { } // это форсирование правил инстанцирования. // шучу. это приватный конструктор. так надо. // это бизнес-метод бизнес-логики бизнес-бизнеса public void AddLine(int orderId, int productId, int quantity) { // вот так мы читаем из канала var order = From<Db>().Get<Order>().ById(orderId); // а вот так пишем To<Db>().Update(order) .Set(x => x.TotalQuantity, order.TotalQuantity + quantity); // потому что можем To<Db>().Add(new OrderLine { OrderId = orderId, ProductId = productId, Quantity = quantity}); // а так зовём другой сервис, если не можем Let<Products>().Reserve(productId, quantity); } // всё. }
Такие сервисы уделывают обычные, сделанные руками по всем пунктам:
Во-первых их не надо регистрировать ни в каком IoC-е. Вызвать один сервис из другого можно написав Let<Products>().СделатьЧтото(...) в любом месте сервиса (кроме конструктора). Одна только эта примочка начисто сносит 90% однотипных записей в регистрации IoC-а (вместе с модулями да) и выпиливает из проекта километровые портянки бессмысленного и тупого интеграционного кода, в котором легко потерять строчку при рефакторинге. И сидеть потом в ожидании runtime exception. Да и вообще, когда те же проблемы решаются за меньшее количества кода — это хорошо. Всё по ТРИЗ, как деды завещали.
В Tecture есть свой мини-IoC на типах. Тупой ровно настолько же, насколько и эффективный. Лайфтаймы в нём прописывать не надо — они всё равно во всех проектах одинаковые и прибиты гвоздями к лайфтайму подключений к базе (и остальным внешним системам). Инстансы сервисов Tecture создаёт лениво, поэтому можно не бояться циклических зависимостей. И за потребление памяти тоже можно не бояться. В довершении всего: никакого дискаверинга сервисов при старте не происходит, что позволяет Tecture не добавлять приложению перфоманс-оверхеда без необходимости.
Во-вторых интерфейс для такого сервиса не нужон. Обычно сервисы прячутся за интерфейсы чтобы писать моки, но Tecture построен так, что потребность в моках отпадает. Как и почему это происходит я объясню потом. Пока важно вот что: выносить сервисы за интерфейсы не надо и точка. Да, можно выкинуть из кодовой базы кучу бесполезных файлов с ISomethingService. Это тоже хорошо. Меньше типов, меньше абстракций — проще проект. Я терпеть не могу интерфейсы, у которых ровна одна реализация и постоянно заменяю их на классы (расставляя virtual если потребуется). Они не нужны примерно ни за чем, кроме как чтобы добавить мне ещё один клик мышкой при попытке увидеть код метода.
В-третьих с такими сервисами, например, можно резать систему по семантическим швам и закатывать в отдельные сборки вместе с используемыми сущностями. Вот есть у нас отдел обработки заказов на фирме — сделаем под него отдельную dll-ку, декларирующую все, используемые отделом заказов сущности. Отведём на обслуживание этой части системы отдельную команду. А наружу будут торчать сервисы для работы с заказами. Сущности для полного счастья можно закрыть на изменение модификатором internal так, чтобы все изменения проходили только через сервисы. Готово, вы великолепны: система гранулирована на мелкие кусочки, всё разложено по полочкам — хоть инкрементальные билды делай. Зависимости между такими сборками будут иерархическими, а иерархия всегда проще для понимания чем линейная структура. Ну и назвать такие сборки можно "domains", типа бизнес-домен.
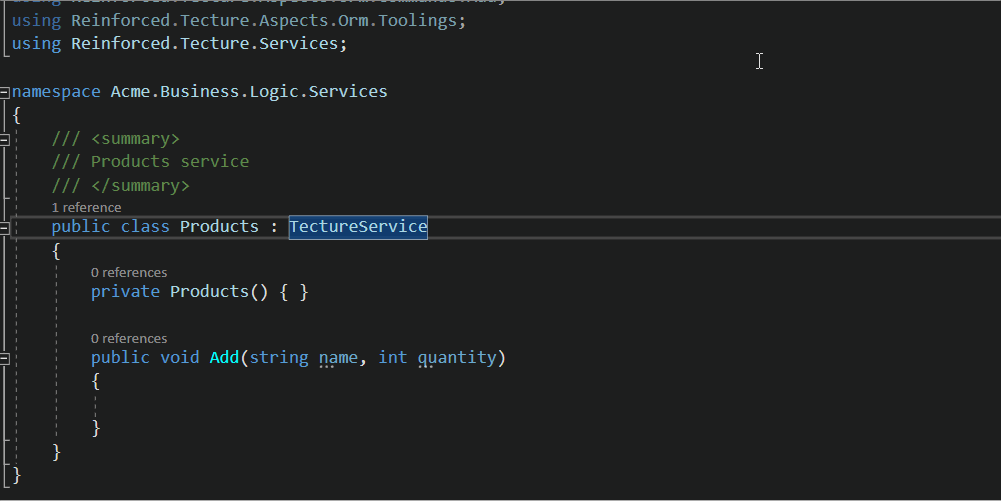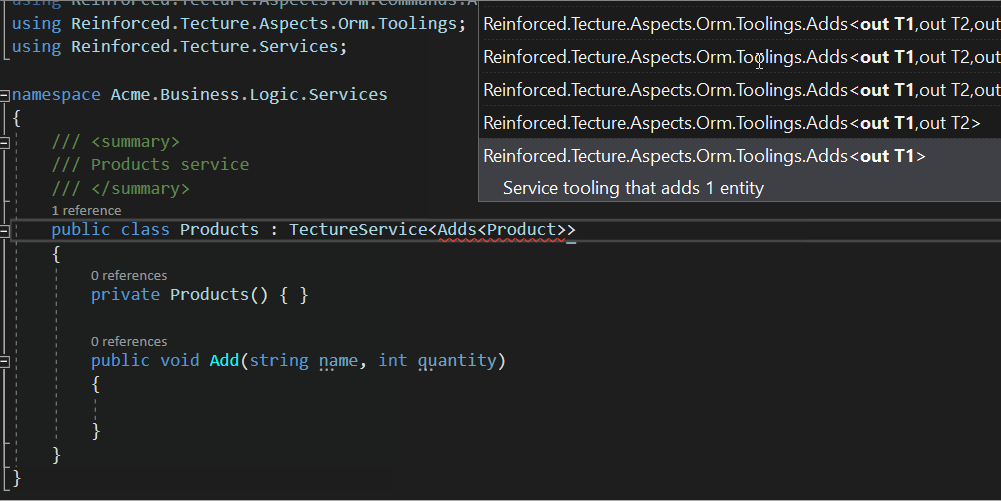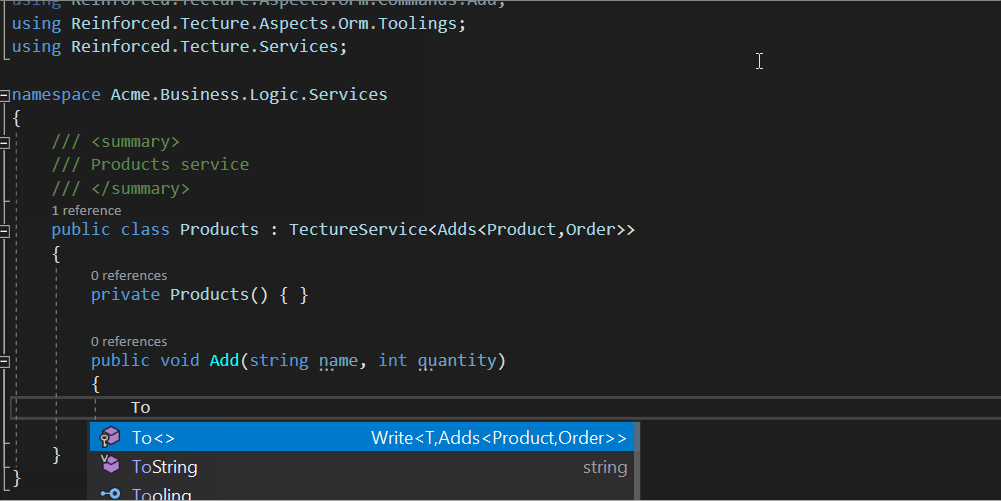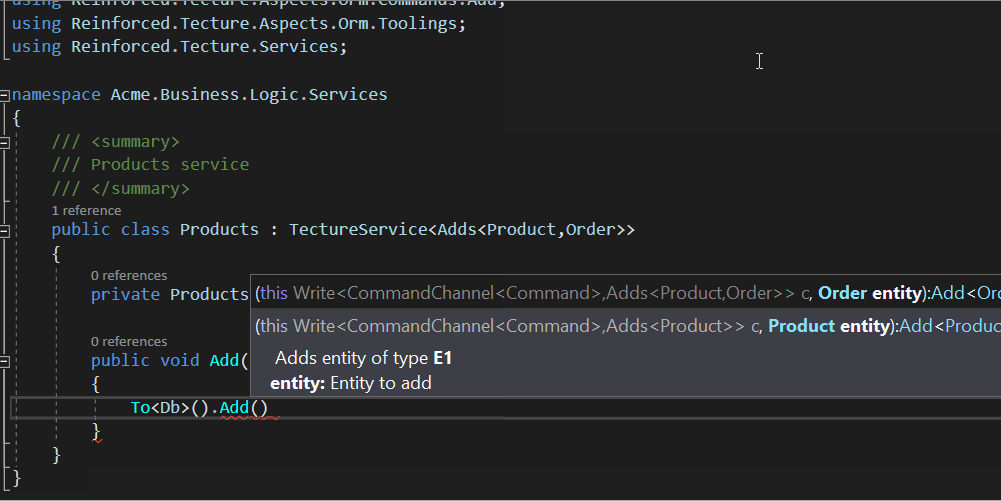
В-четвёртых: тулинги. Я не нашёл подходящего названия для этого механизма, поэтому называю его тулинг. Это вот там, где у сервиса указаны тип-параметры:
public class Orders : TectureService < Updates<Order>, Adds<OrderLine> > {
Тулинги явно описывают что в этом сервисе делается, а чего в нём точно не делается. Степень детализации этой информации зависит от аспекта. Вот про сервис из примера выше точно можно сказать что Order-ы он не удаляет, а OrderLine-ы не меняет (только создаёт). И это мы глянули только на шапку сервиса, а уже сколько информации. Я могу так сделать, потому что строгая типизация в C# решительно даёт прикурить остальным языкам. Если попробовать написать в этом сервисе, скажем To<Db>().Delete(order) — компиляция упадёт с ошибкой, как бы говоря нам: "хэй, чувак, это наш двор и ордеры тут не удаляют".
Тулинги гибкие. Они тоже подсасываются из аспекта. Вот интерфейсы Updates<> и Adds<> определены в аспекте ORM до восьми сущностей включительно. Само собой, это автогенерированный код, я не писал это всё руками. Жаль что в шарпе пока нет квазицитирования и HKT — приходится собирать подобные конструкции из говна и палок.
Но с другой стороны — оно и к лучшему. Отсутствие HKT не позволяет писать типы, параметризуемые потенциально бесконечными числом аргументов и вынуждает меня ограничивать как сервисы, так и их тулинги по числу тип-параметров. Это можно использовать чтобы предотвратить появление в системе god object-ов. Я считаю так, что если вы добавляете девятую по счёту обязанность сервису, то ему уже хватит и надо его декомпозировать, а не накидывать. Компилятор просто помогает мне как архитекту доносить эту мысль до линейных разработчиков наиболее эффективно. По задумке — сделать заготовку для TectureService с девятью параметрами будет сложнее, чем потратить 10 минут и разбить сервис на два. Так я ситуативно использую лень разработчика, чтобы направить его по пути декомпозиции.
В-пятых: я убрал дебильный суффикс "Service". И так понятно что это — сервис. В жопу суффикс.
Чтобы вызвать один сервис из другого есть Let<>. Но как вызвать сервис извне? Подробно я расскажу в следующей статье, но для полноты в двух словах: сам Tecture может регистрироваться в любом IoC-е как интерфейс ITecture (через фэктори метод). Получить инстанс ITecture можно пнув TectureBuilder и забайндив каналы. Именно так, через построитель каналы и аспекты связываются с живыми внешними системами. Штука, которая непосредственно обеспечивает коммуникации и реализует аспекты называется рантайм. И пока что достаточно о них.
Так вот, у ITecture есть метод Let<>(), такой же как и внутри сервиса. Через него можно позвать позвать любой понравившийся сервис просто подстановкой типа: tecture.Let<Orders>().CreateOne(...), как только инстанс ITecture окажется у вас в руках.
Что ещё доступно внутри сервиса? Не считая всякие службные штуки, можно сказать что в основном там обитают три интересных метода (закрыты модификатором protected):
Let<TService>(), про который я уже сказал. Он лениво резольвит инстанс другого сервиса и позволяет вызвать методы из него. У него есть брат-близнец: методDo<>. Делает ровно то же самое, просто позволяет писать более идиоматично и человеко-читаемо.From<TChannel>(): отдаёт конец канала, через который можно читать данные. Такой же, кстати, есть у инстанса ITecture;To<TChannel>(): отдаёт конец канала, через который можно писать данные. Тулинг сервиса может влиять на то, что и как можно писать;
На From<> и To<> стоит остановиться подробнее.
Команды и запросы
Что меня зацепило в архитектуре EntityFramework: запросы к базе данных делаются вот прямо вот на месте. Пишешь LINQ, транслятор его запинывает в SQL, используя метаданные, скармливает базе и выплёвывает коллекцию объектов в момент, когда разворачивается получившийся IQueryable. Но! Если хочешь что-то записать в базу, то всё происходит по-другому. Ты меняешь объекты, зовёшь .Add, .Remove — создаёшь такой… чертёж изменений. Потом хлоп — SaveChanges, всё собирается в SQL батч и летит в базу. Я зацепился за эту мысль и долго крутил её в голове. Ненавижу EF-ный ChangesTracker, который сравнивает начальное и конечное состояние объектов и выводит diff, но вот сам подход "запросы сейчас, а изменения — потом" — звучит дельно.
Вообще разделять чтение и запись — это хорошо. Даже с грёбаным файлом мы читаем и пишем по-разному. Я не о том, что читать надо методом Read, а писать методом Write. Я про концептуальную разницу.
Вот та же база данных. Какие грабли подстерегают нас при записи? Индексы тормозят из-за перебалансировки б-дерева (особенно кстати на вставке гуидов заметно), транзакции надо разруливать чтобы не перетереть чужие изменения, консистентность данных там блюсти, денормализацию ещё затриггерить. Ну что-то в этом духе.
Когда пытаешься читать — всплывает совершенно другое. Типа а как читать по-быстрее, как составить запрос, какие данные клиенту нужны, а какие не очень, что делать если требуют 10 тысяч записей одной пачкой, в какие индексы смотреть чтобы не облажаться, может вообще читать из кэша? Ну и самое очевидное — редко когда удаётся что-то записать не прочитав.
Инструментарий для чтения и записи должен быть разным. Я долго думал как это обыграть. Пошёл посмотреть что в интернете предлагают, открыл для себя дивный мир CQRS, вскоре разочаровался в нём, посмотрел на MediatR, изучил тему DDD, пролистал книгу "Entity Framework Core in Action" за авторством какого-то умного чувака и поглядел репозиторий к ней. Выпал в осадок и понял, что так делать точно не надо. Потом пошевелил мозгами и решил делать как Microsoft — тупо, нагло, прямо. Если Microsoft берётся делать фреймворк для MVC, то жди классов Model, View и Controller. Если для web-а, то будет HttpRequest и HttpResponse. Прямо, эффективно, без лишней зауми и оверинжиниринга. Местами даже тупо. Ну будем подражать великим.
В Tecture разделение чтения и записи обыгрывается в лоб: чтение выполняется через запросы, а запись — через отложенные команды.
Учимся читать (про запросы)
Чтобы сделать запрос — надо достать входной конец канала через From<>.
Тут наблюдаем мелкобытовой нацизм: в Tecture считается что команды рулят, а запросы — так. Чтобы хранить команды — отведены целые сервисы. Чтобы хранить запросы отведено целое нихрена. Потому что все запросы в Tecture — статические. Они набрасываются экстеншонами к читальному концу канала и его производным.
В этом есть глубокий теоретический смысл: запросы в основном не меняют состояние внешней системы, если отбросить concern-ы производительности. SELECT данных в базу не добавляет. В идеальном мире его можно выполнить сколько угодно раз и получить один и тот же ответ. А это уже толстый намёк на идемпотентность чтения, что в случае с базой данных реально так, если юзать транзакции — см. Repeatable Read. Тут любители ФП кричат нам с дивана: функция, которая возвращает результат, не модифицирует глобальный контекст, да ещё и собственные параметры не изменяет, что-то подозрительно похожа на чистую. А чистые функции в C# принято выражать экстеншонами.
Если отдельно проработать механизмы перехвата запросов и возможность подстановки fake-ответов, то быстро выясняется что Repository Pattern НЕ НУЖЕН. По этому пути я и пошёл. В итоге запросы в Tecture писать непривычно, но просто: берёшь "читальный конец" канала, заворачиваешь в отдельную абстракцию и просто фигачишь к ней статические методы расширения. Это хорошо тем, что становится пофигу где именно написан метод запроса — компилятор, женерик-констрейнты и маркировочные интерфейсы прицепят их куда надо. А решарпер ещё и подскажет. Вот мой любимый пример: как сделать метод GetSomethingById, выкинув из системы добрую половину репозиториев:
// Общий интерфейс сущности с Id-шником public interface IEntity { int Id {get;} } // Промежуточная абстракция над IQueryable (схематично) public interface IQueryFor<T> { IQueryable<T> All { get; } IQueryable<U> Joined<U>(); } public static class Extensions { // Достаём нужный нам IQueryFor из читального конца канала public static IQueryFor<T> Get<T>(this Read<QueryChannel<Orm.Query>> qr) where T : class { // но вообще этот код написан в аспекте var pr = qr.Aspect(); // тут он просто для наглядности return new QueryForImpl<T>(pr); } // Этот ById приклеится ко всем IQueryFor<T>, где T содержит int-овый Id public static T ById<T>(this IQueryFor<T> q, int id) where T : IEntity { return q.All.FirstOrDefault(x => x.Id == id); } }
Всё, репозитории не нужны:
// Читаемо, идиоматично, метафорично var user = From<Db>().Get<User>().ById(10);
Не то чтобы я тут изобретал что-то совсем новое — аналогично устроен весь LINQ, да и в целом весь fluent-стиль, но чёрт побери, как же это удобно.
Учимся писать (про команды)
Для чтения у каналов есть читальный конец — From<>(). Значит для операций записи/изменения есть… я не знаю, ПИСАЛЬНЫЙ КОНЕЦ? В общем та штука, которую возвращает To<>() внутри сервиса. Получить её за пределами сервиса невозможно — так сделано, чтобы не было соблазна разбрасывать изменение данных по всему коду. Хочешь изменений — вступай в сервисы.
To<>() возвращает тип Write<...> с кучей женерик-параметров, к нему подтягиваются экстеншоны из аспекта. С учётом тулингов, конечно же. Там вот выше в примере таким способом был вызван .Add. Вот его исходники. Если аспект или тулинг не позволяет подобрать .Add с нужными аргументами — ошибка компиляции. Если позволяет — успех.
Дальше. Никакой записи прям вот на месте не происходит. Вместо этого Tecture создаёт инстанс команды Add, кладёт его во внутреннюю очередь и логика продолжает выполняться.
По итогу схема такая: бизнес-логика берёт пользовательский ввод, подтягивает недостающие данные из внешних систем и составляет список того, что с этой байдой надо сделать в сухом остатке. Это как программа, только маленькая и сравнительно простая. Тот самый чертёж изменений по аналогии с EntityFramework. Только глобальный. Для всего.
Ну и по аналогии с EntityFramework, можно сделать Save у корневого инстанса ITecture. Я называю этот этап сохранение.
В чём профит? Больше контроля из одной точки. С такой очередью удобно работать. Можно как угодно издеваться над ней программно. Например, отдельные этапы записи можно обложить логами, можно гибко сделать отлов exception-ов один раз на всё приложение, можно сериализовывать очередь. Можно вообще её не выполнять. Я подумываю над программным способом отката изменений, но пока такое сложновато.
Но самое крутое в том, что появляется чёткое разделение ошибок. Все exception-ы, пойманные в ходе выполнения логики можно смело трактовать как логические ошибки приложения. То есть смысловые. Например: не выполняется какое-то бизнес-правило, нарушаются ограничения выданные по ТЗ, недостаточно товара на складе, нет подходящей детали и иже с ними. А вот технические ошибки по причине, скажем, недоступности базы данных, отвалившейся транзакции, упавшего веб-сервиса, неушедшего e-mail-а проявляются только в моменты сохранения (ну и запросов). Становится проще концептуально отделить мух от котлет и понять — это вы лажаете, или сторонняя система гонит. Ну и чинить по обстоятельствам.
Последний узкий момент, который надо упомянуть: начать сохранение изнутри сервиса невозможно технически. Но как быть, если надо что-то сделать с только что добавленным заказом? А вот как: можно тоже положить это действие в специальную очередь, которая будет разобрана после того, как Tecture разберёт основную очередь. И это изящно обыграно синтаксически (код приводится на примере ORM-аспекта, ни один Order не пострадал):
public async Task ILikeToMoveIt() { var newOrder = To<Db>().Add(new Order()); await Save; var id = From<Db>().Key(newOrder); To<Db>().Delete<Order>().ByPk(id); }
Это Save-оцентрический await. Ну весело же, ну!
На самом деле это только выглядит красиво на простых примерах, но вообще использовать его надо с осторожностью — конфликтует с асинхронными запросами. В крайнем случае можно откатиться к явной записи через Save.ContinueWith(...).
Это были основные примитивы Tecture и я намеренно старался держать их количество под контролем, чтобы снизить порог вхождения. По той же причине я не пишу про его внутреннее устройство. Там местами свой локальный адок (связанный с обходом отдельных языковых ограничений C#), но в общем ничего криминального. Исходники открыты — вот ссылка на репозиторий.
Однако, сухой текст и теоретические рассуждения не позволяют прочувствовать как Tecture ведёт себя на практике. Тот самый Development Experience надо показывать на примерах.
Поэтому я приглашаю вас в следующую статью, в которой много картинок, а некоторые из них даже анимированные. В ней я покажу как это добро использовать на благо мироздания на примере небольшого тестового проекта.
Там и встретимся.
