This article is aimed to describe FreeBSD OS as a platform to launch cloud guest OSes with simple API capabilities, using MyBee and DevOPS I really like!
Introduction
Time to time i have thoughts: 'do i become rarted'? and my hands are trying to check out current job positions with some fresh or exotic approaches and tools, which are not completely hackneyed. But during scrolling list of companies with their devops positions i face simple picture: names of companies are changing, technology stack stays completely same bored Linux, OpenStack, Docker, Kubernetes/OpenShift, GitLab, Ansible, Terraform with minor variation. Products of tech companies with huge investements and marketing budget.
This set of tools, with which anyone will recognize who's working in devops field for last 2-3 years. The lack of alternative solutions leads to professional burnout, work causes a feeling of disgust, fatigue and loss of motivation from repetitive activities.
This is OK, if you're not real IT-geek, but is not acceptable, if information technology is not only dayjob, but also hobby and it makes you happy. In this case, you do not pay attention on how this or that piece of code is called, whether it is in trend or not, what Anonymous writes and thinks about it. It is way more interesting to try it yourself, get acquainted with the code / services / architecture, and if you have a specific problem that the product is focused on - try to solve that problem.
Such dissatisfaction is partially offset by experiments outside of working hours and participation in various non-upstream, little-known and marginal projects. For example, if we talk about the OS, it is always interesting to experiment with Minix, ReactOS, SmartOS, KolibriOS, MinocaOS, Haiku.
Distributions of the BSD family occupy a special niche: they are not only up-to-date, which means that developers quickly close vulnerabilities if such are found. Drivers are released on regular basis, ensuring the operation of systems on new equipment. And if some of the aforementioned OS will work only in VirtualBox, then with BSD systems you can take a break with Linux and play with bare metal.
In addition, these systems are quite 'clean' in terms of clutter: there is no overabundance of the functionality of the basic mandatory components, they do not have the constant deprecation cycle of every single component - leapfrog, when every year, instead of updating one utility, it is replaced by another, completely incompatible with the previous one. Commitment to tradition and adherence to the KISS principle is highly valued by hotheads who bring any service to industrial operation on BSD platforms in a 'set and forget' style.
Any activity related to R&D in OS context and other software is convenient to carry out using virtual machines, due to the presence of snapshots (quick rollback of changes) and the ability to quickly launch and destroy any number of instances. In my practice in industrial operation, I probably had to use all the currently available solutions: AWS, DO, Azure clouds, self-hosted solutions based on OpenStack, OpenNebula, Proxmox, Triton Compute, Nutanix, XEN Orchestra. I also used several domestic developments (usually, this is OpenStack with changed logo, or Django-based applications over virsh / kvm), not to mention a large number of lightweight blotches for virsh / kvm, like Kimchi, virt-manager, nemu and other frontends. Despite the abundance of solutions, I could not find a tool with the simplest and fastest mechanism for creating cloud VMs. Meanwhile, only a small number of products have ZFS support (there is a high interest in it due to the high-quality snapshot mechanism), and the stability and reliability of snapshots based on QCOW2 did not satisfy me. In some systems, a 'snapshot' meant the operation of sending a disk image to S3 storage with a similar recovery.
Therefore, for my own purposes, I used a dedicated server running FreeBSD OS, in which cloud virtual machines based on the bhyve hypervisor were launched via the command line and the cbsd utility (analogous to qm in the Proxmox CLI), and snapshots were processed using ZFS. (For reference: bhyve is an open-source BSD-licensed type-2 hypervisor and is included in the base distribution of the FreeBSD OS since version 10.0. It is currently ported to the MacOS (xhyve) and SmartOS) At some point in time, the resources of one physical the servers have been exhausted. In addition, historically (with approximately the following slogan: "Well, you have a server - can you give me a VM?"), some of the resources were given to friends for some of their services, which, despite the "Yes, it won't last for long!" these services quickly filled my servers and from time to time, I had to do something with them (snapshot, reset ..).
The Bee way
I was looking for a system, which is:
Free and without annoying 'I'm free, but still - get a paid subscription, otherwise poke this button all the time!';
Transparent (requiring no additional actions on my part) scaling to multiple physical hosts;
Having some kind of basic RBAC to separate your VMs from strangers;
Required availability of API: yes, many projects have a very nice and sprawling UI, however, this certainly good trump card is dissapearing when it comes to automation and / or intensive launch-destruction cycles
ZFS-based, for snapshots (I don't know anything better than 'zfs snapshot');
Due to the fact that CBSD had already description of capabilities and demo code for working on multiple servers with API a few years ago, CBSD, FreeBSD and the bhyve hypervisor were left as the basis. It was necessary to isolate our virtual machines from other people's 'guests' and ensure that there are no collisions in server naming between our 'namespaces'.
The second solution is trivial - the system should always produce an unique index for new VMs, which can be implemented in sh in one line:
id=$(( id + 1 ))
and save the mapping between that ID and instance name, requested by client.
When diving into the RBAC problem, I wanted to avoid creating accounts on the server and still try not to complicate the API or logic.
When working with the API and ordering cloud (cloud-init) VMs, the user operates with the basic resources: "number of virtual cores", "RAM", "disk size", "VM image", which cannot be found fault with, but the fifth parameter is " public key "of the user, which will be saved as the user key (whose name can also be arbitrary). Thus, "pubkey" turned out to be the only parameter that can be used to separate and identify users. The solution was formed by itself - when there's request to create a VM, the API calculates md5(pubkey) and then operates with this hash as a key to control the VM. The solution does not work if the API is provided to unknown, dubious individuals, but it is not a problem when giving access to friends or colleagues, where in a test environment everyone can delete everything anyway.
API refactoring taking into account the requirements took 1 full day and the work was uploaded for everyone to check it out. What happened at the output:
A single point of interaction is an API that sends and receives tasks to the hypervisor (physical servers) through a message broker (in my case, a minimalistic beanstalkd was taken for this role), where each physical server subscribes to one queue by its name. Adding a node to a cluster is done by launching a consumer on a broker and adding a server to the list of servers and their number is not limited.
Users do not have any operations on login, passwords or any other extra steps to get a jwt / token, everyone works only with their own virtual environments, without fear of intersections in VM names with neighbors.
A unified interface where the client does not need to know anything about some weird FreeBSD operating system.
Solution price: 1 day of development, but it was time spent with pleasure.
Some conclusions
conclusion number 1: Despite the abundance of solutions and the oversaturation of the market, it is sometimes difficult to find a product that would satisfy you. And the point here is not at all that trendy products lack the functionality you need. On the contrary, good marketing and product owners never sleep: they try to get the widest possible userbase, they force developers to implement more and more of the most diverse features. This is especially true for proprietary commercial solutions. Look at solutions such as VMware or kubernetes - their capabilities are now difficult to grasp, and at the same time, 99% of these capabilities are simply not needed or used. However, using 1%, you often have to pay for 99% of the rest of the features - it's not just the cost of the product or subscription: you also get several volumes of documentation on the capabilities and configurations of the product, which you can swim in for months. Sometimes these tools don't bring feeling like these are tools to make your life easier. Not to mention the high demands on the resources.

conclusion number 2: with narrow tasks, with the help of far from trendy and marginal technologies, you can get the same efficiency of expensive and well-known trend solutions and at the same time spend much less effort.
conclusion number 3: (without the relative NIH-syndrome syndrome) - it is often way cheaper to implement what you need yourself. A good example is kubernetes. What do users want from it? Typically you need a service scheduler / supervisor and scaling capability for your application. You can buy OpenShift / Rancher, hire a department of 10+ devops for it, who will write and rewrite yamls every day, 365 days a year, rake problems and deprecate solutions with each update. I am sure that Google needs kubernetes and uses it correctly, but all the companies where I worked used it only to launch the container. You can simply write the implementation of scaling and fault tolerance yourself in your application - fortunately, today everyone can develop with Stack overflow and other https://copilot.github.com/, and with that volume of libraries for replication, RAFT-algorithms and related tools ( brokers, etcd, zookeeper), it is not difficult to write the very 1% of VMware / K8S capabilities you need, but at the same time it will come out for you more fun and exciting pastime.
Who knows - maybe the time is gradually coming to boycott the yaml-devops movement, which has become too expensive, bloated and completely dead-end clumsy in comparison with development, since today the DevOPS position in most companies has degraded into a 'kubernetes operator' and a 'yaml-developer' ...
conclusion number 4: Despite the fact that KVM / QEMU is the "gold standard" among open-source hypervisors, and Linux platforms are mainstream, alternative operating systems and solutions continue to appear and develop. Given the versatility of Linux / KVM, there is no doubt that in case of problems, I can always transfer work to Linux, but minimalism, and the fact you are designing the system, and not the system designs your workflow - that fact really bribes you.
Welcome MyBee
As a side effect and a bonus, as well as to get acquainted with the work of the bhyve hypervisor for people who are far from FreeBSD, the work was framed as a separate distribution kit called MyBee: https://myb.convectix.com, for work with it all what you need is curl (but there is also thin client). Perhaps someone will find this work useful for themselves.
What can do MyBee?
Install the "curl" utility (for working with API) and "jq" (for more readable json in responses). After installing MyBee on the server, open the IP address of the host in a browser for general information on the possibilities: In the base installation, there are links for the following virtual machine images:

"centos7"
"centos8" ( CentOS Stream )
"ubuntu" ( Ubuntu 20.x )
"debian" ( Debian 10 )
"freebsd_ufs" ( FreeBSD 13.0, UFS FS )
"freebsd_zfs" ( FreeBSD 13.0, ZFS FS )
"openbsd" ( OpenBSD 6.x )
"netbsd" ( NetBSD 9.x )
You can also easy extend that list.
When decided on the configuration of the desired virtual machine, create a json file (for example: centos7.json) with the following content:
{ "type": "bhyve", "imgsize": "10g", "ram": "1g", "cpus": "2", "img": "centos7", "pubkey": "ssh-ed25519 AAAA..XXX your@localhost" }
line 3 and parameter "imgsize": sets the size of first/system disk. Usually not less then 3-4 GBs
line 4 and parameter "ram": well, amount of random access memory
line 5 and parameter "cpus": number of vCPUs for virtual machine
line 6 and parameter "img": any name of image from the list above
line 7 and parameter "pubkey": your pubkey, which will be added for vm user by default
curl -X POST -H "Content-Type: application/json" -d @centos7.json http://IP/api/v1/create/vm1 | jq
During next ~20-30 seconds, VM will be launched and it will be available for connection, skipping long phase of system installation. If you didn't "warm up" of images, during the creation of vm it will take additional time (depending on internet connection of MyBee host machine). All next ops with same image will happen almost instantly. If you want to "warm up" your images,you should login into MyBee host (ssh via an unprivileged user with a transition to root: ‘sudo -s’ or ‘su -’ or through terminal / console) and enter the appropriate naming of the image to warm up:
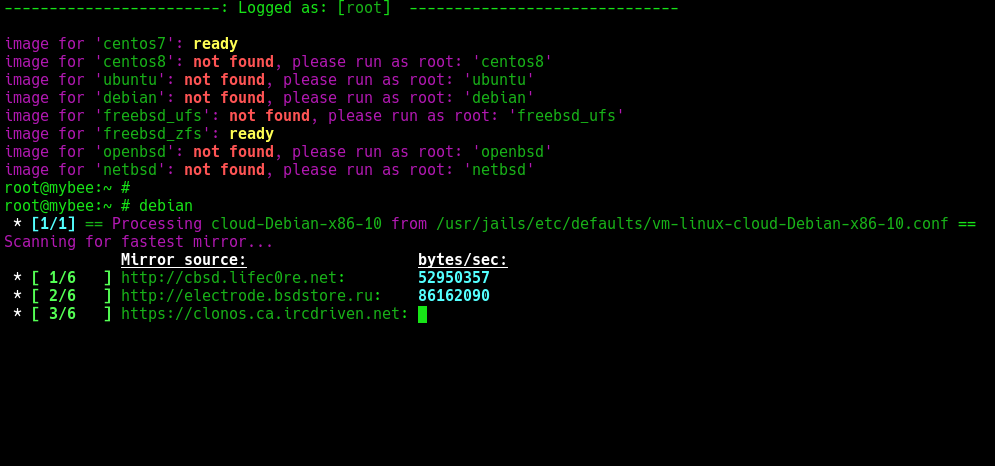
When you call /create endpoint with a correct payload, the system will return you a list of resources for further work with the API using your token (cid). If you missed or forgot it, do not despair - you can get the cid by calculating MD5 from your public key string. This cid is also a kind of namespace in which your resources are grouped. If you send a similar request, but with a different public key (or even with different signature for a key: ssh-rsa ... user@pc, ssh-rsa ... user@laptop), VMs will be created in a different group. You can see a list of all hosts in the cluster and a piece of cid by opening the MyBee dashboard at http://IP/status:

After VM creation, all further ops you may be interested in:
Information about your cluster with list of VMs:
curl -H "cid:<cid>" http://IP/api/v1/cluster | jq
State of individual VMs, where in response you also get the SSH connection string:
curl -H "cid:<cid>" http://IP/api/v1/status/vm1 | jq
Deletion of virtual machine:
curl -H "cid:<cid>" http://IP/api/v1/destroy/vm1 | jq
MyBee installation
You'll be fine with any bare metal server AMD/Intel x86-64 with virtualization support (VT-x).
Installation of MyBee can be done using ISO image (https://myb.convectix.com/download/ ) or, if you use Hetzner (or similar provider) - launch installer from Hetzner rescue image, there's a manual page for this provider: https://myb.convectix.com/hetzner/ .
In general, the installation process is similar to a regular FreeBSD installer, with which you shouldn't have a lot of questions. If there are any, the official documentation for installing FreeBSD will help you. : https://docs.freebsd.org/en/books/handbook/bsdinstall/
A note
Little cherry on the top of the cake: if you are using FreeBSD environments, using the same API and methods, you can create a jail (BSD native "containers") for yourself instead of a virtual machine. To do this, in json when creating, use the value "jail" as "type", for example:
{ "type": "jail", "imgsize": "10g", "pubkey": "ssh-ed25519 AAAA..XXX your@localhost" }
Also, there is a separate thin client for working with the MyBee API, the builds of which are available for all modern operating systems, if you find the interaction through curl unfriendly (or use limited operating systems where curl and jq are not so easy to install). For example, you can work with MyBee from Windows OS as follows:
nubectl-windows status --cloudkey="c:\authorized_keys" --cloudurl=http://IP nubectl-windows create vm --cloudkey="c:\authorized_keys" --cloudurl=http://IP nubectl-windows ssh vm --cloudkey="c:\authorized_keys" --cloudurl=http://IP [--sshkey=c:\id_ed25519]
Thank you for your attention and interest, keep finding joy in your work, even if this work is DevOPS ;-)
