
Разбираемся на практике с API HeadHunter при помощи python.
Появилась задача анализа вакансий на рынке труда, и осуществлять ее надо базе HeadHunter. Необходимо получить все вакансии определенной компании по всем городам России. Ознакомившись с документацией по API на github, приступаем к работе.
Для решения задачи используем python. Импортируем необходимые для работы библиотеки:
import requests # Для запросов по API import json # Для обработки полученных результатов import time # Для задержки между запросами import os # Для работы с файлами import pandas as pd # Для формирования датафрейма с результатами
Стоит разобраться с такой вещью как areas. Всего существует 9 условных зон (стран):
ID страны | Название страны |
5 | Украина |
9 | Азербайджан |
16 | Беларусь |
28 | Грузия |
40 | Казахстан |
48 | Кыргызстан |
97 | Узбекистан |
113 | Россия |
1001 | Другие регионы |
Для каждой страны имеются свои внутренние зоны, которые можно просмотреть через обращение к HH (https://api.hh.ru/areas) с параметром area равным ID страны. К примеру, для России будет найдено свыше 4 тысяч различных городов, сел и других населенных пунктов.
Для получения всех стран со всеми их внутренними зонами воспользуемся следующим фрагментом кода:
def getAreas(): req = requests.get('https://api.hh.ru/areas') data = req.content.decode() req.close() jsObj = json.loads(data) areas = [] for k in jsObj: for i in range(len(k['areas'])): if len(k['areas'][i]['areas']) != 0: # Если у зоны есть внутренние зоны for j in range(len(k['areas'][i]['areas'])): areas.append([k['id'], k['name'], k['areas'][i]['areas'][j]['id'], k['areas'][i]['areas'][j]['name']]) else: # Если у зоны нет внутренних зон areas.append([k['id'], k['name'], k['areas'][i]['id'], k['areas'][i]['name']]) return areas areas = getAreas()
Если интересует запрос по конкретной зоне (стране), то в параметры request нужно указать ID необходимой зоны, к примеру, для России: {'area': 113}
Вот часть того, что будет храниться в переменной areas:
Следующим шагом стоит найти ID работодателей.
Для этого нужно получить количество работодателей на данный момент и учесть тот факт, что не все порядковые номера существуют и внутренние ограничения API HH на постраничный поиск, глубина которого равна всего 2000 значений.
def getEmployers(): req = requests.get('https://api.hh.ru/employers') data = req.content.decode() req.close() count_of_employers = json.loads(data)['found'] employers = [] i = 0 j = count_of_employers while i < j: req = requests.get('https://api.hh.ru/employers/'+str(i+1)) data = req.content.decode() req.close() jsObj = json.loads(data) try: employers.append([jsObj['id'], jsObj['name']]) i += 1 print([jsObj['id'], jsObj['name']]) except: i += 1 j += 1 if i%200 == 0: time.sleep(0.2) return employers employers = getEmployers()
Результат того, что будет храниться в переменной employers:

Возьмем для примера 2ГИС с ID 64174 и найдем все вакансии по работодателю в разрезе каждой зоны России (ID 113). В функцию getPage в качестве входных параметров сделаем только номер страницы для постраничного поиска и зону, где будем смотреть вакансии.
def getPage(page, area): params = { 'employer_id': 3529, # ID 2ГИС 'area': area, # Поиск в зоне 'page': page, # Номер страницы 'per_page': 100 # Кол-во вакансий на 1 странице } req = requests.get('https://api.hh.ru/vacancies', params) data = req.content.decode() req.close() return data
Часть кода, где функция getPage и используется:
for area in areas: for page in range(0, 20): jsObj = json.loads(getPage(page, area[2])) if not os.path.exists('./areas/'): os.makedirs('./areas/') nextFileName = './areas/{}.json'.format(str(area[2])+'_'+str(area[3])+'_'+str(page)) f = open(nextFileName, mode='w', encoding='utf8') f.write(json.dumps(jsObj, ensure_ascii=False)) f.close() if (jsObj['pages'] - page) <= 1: print('[{0}/{1}] Область: {3} ({2}) - {5} ({4}) Вакансий: {6}'.format(area_list_id+1, len(areas), area[0], area[1], area[2], area[3], jsObj['found'])) break time.sleep(0.2)
Сохраняем промежуточные результаты в формате json для каждой зоны отдельно, в том числе и для зон, где не найдено ни одной вакансии. Теперь сгруппируем их в один файл:
dt = [] for fl in os.listdir('./areas/'): f = open('./areas/{}'.format(fl), encoding='utf8') jsonText = f.read() f.close() jsonObj = json.loads(jsonText) if jsonObj['found'] != 0: for js in jsonObj['items']: if js['salary'] != None: salary_from = js['salary']['from'] salaty_to = js['salary']['to'] else: salary_from = None salaty_to = None if js['address'] != None: address_raw = js['address']['raw'] else: address_raw = None dt.append([ js['id'], js['premium'], js['name'], js['department']['name'], js['has_test'], js['response_letter_required'], js['area']['id'], js['area']['name'], salary_from, salaty_to, js['type']['name'], address_raw, js['response_url'], js['sort_point_distance'], js['published_at'], js['created_at'], js['archived'], js['apply_alternate_url'], js['insider_interview'], js['url'], js['alternate_url'], js['relations'], js['employer']['id'], js['employer']['name'], js['snippet']['requirement'], js['snippet']['responsibility'], js['contacts'], js['schedule']['name'], js['working_days'], js['working_time_intervals'], js['working_time_modes'], js['accept_temporary'] ])
Полученный промежуточный результат сохраняем в DataFrame и сохраняем как файл Excel.
df = pd.DataFrame(dt, columns = [ 'id', 'premium', 'name', 'department_name', 'has_test', 'response_letter_required', 'area_id', 'area_name', 'salary_from', 'salaty_to', 'type_name', 'address_raw', 'response_url', 'sort_point_distance', 'published_at', 'created_at', 'archived', 'apply_alternate_url', 'insider_interview', 'url', 'alternate_url', 'relations', 'employer_id', 'employer_name', 'snippet_requirement', 'snippet_responsibility', 'contacts', 'schedule_name', 'working_days', 'working_time_intervals', 'working_time_modes', 'accept_temporary' ]) df.to_excel('result_2gis.xlsx')
Скриншот части конечного результата внутри Excel:
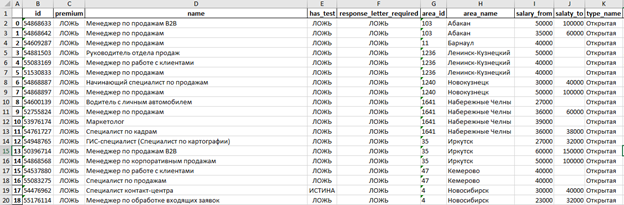
Без особых сложностей, поставленную перед нами задачу выполнили и получили все возможные вакансии по определенному работодателю на разных территориях.
В этом гайде по работе с API HeadHunter рассмотрен базовый функционал API. Тем не менее, для успешного понимая всего функционала и возможностей, вы можете самостоятельно ознакомиться на github HH.ru или подождать нашей следующей статьи по данной теме, где мы рассмотрим более сложные примеры.
