Author: Denys Zherdetskyi
From beginning of the internet development till now, almost all the servers were multithreaded servers, because they hadn't any famous and well-built alternative way. After the May 27, 2009 (Node.Js presentation date) developers started discussing the disadvantages of the multithreaded servers and advantages of Node.Js server implementation.
That's true, Node.Js is a good way of web server implementation, but spoiler it's not all so clear-cut and it all depends.
Today I want to answer all this questions.
Let's get it started.
What we're going to discuss:
The working mechanism of multithreaded servers
10k request problem
Main structure problems
Blocking I/O
The working mechanism of multithreaded servers (in block diagram)
Way to solve these problems
Introduction
Imagine the situation: You returned home from work in evening really exhausted and hungry, but of course you don't have the energy to cook. That's you decided to order pizza online on the Domino's ( it's not an advertising integration), but you see the error, that all the treads of the server are full.
Of course, it's only the imaginary situation, because nothing like this simple error cannot happen in such big company like Domino's, because their servers are used to such a big amount of the people all over the world every second. But it's possible to happen in the little company that became very popular one day, with site that isn't used to the big amount of the people, due to the low level of the RAM.
After the reading of this article you will know, why this situation is possible.
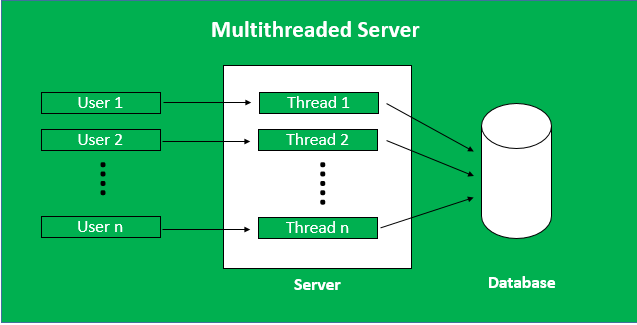
The working mechanism of multithreaded servers
When you entered the Domino's website, you send a request to Domino's web-server to receive a response with data (HTML, JSON, etc.). Then server handle your request and if there is no "free place" on the server, you should stay in the queue.
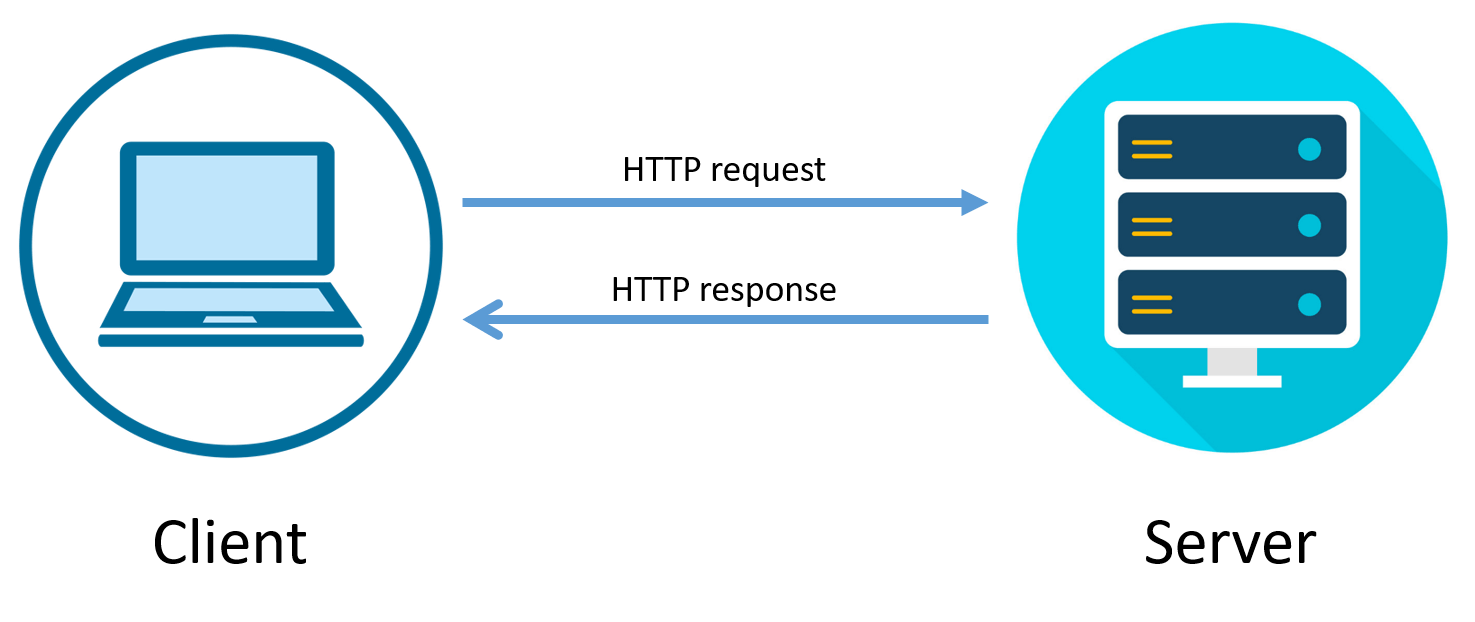
Some people can ask: "That means that the server can process only one request per one time?"
Not at all. If website uses multithreaded server, than server checks the amount of available threads and if the there aren't any, you will be waiting for available thread (you don't know, how long you should wait), if there is one, then server will use this thread to process your request.
10k request problem
As you read in the previous article the server always checks he amount of available threads, before adding a new request to the thread, to be sure that there is at least one available.
Some people can ask: "What is the amount of the threads on the server?"
Well, it isn't stable. It depends on RAM (more RAM, more threads). On the every multithreaded server the quantity of the treads are closely connected with RAM. That's why it is a really strong problem, because the number of threads is hostage to the amount of RAM.
And here takes place a 10k request problem:
10k (10000) problem is a problem that tells us about the linear dependence between the server request (possible threads) and the RAM. This problem appeared in 2000-x years, when the server wanted to handle 10000 parallel request.
This problem takes place, because native server allocate 1 mb in the memory for every thread and that's why 10000 request (possible threads) needs at least 9.77 Gb memory, but for 2000-x years it was almost impossible, because the price of this RAM was really hight.

Now the 10 Gb RAM for server is not a problem and the server became in the times faster, but even now this problem also exists. However now it's not a problem of 10k, it is a problem of 10M (10000000). That's why this problem shows us not only a number, that are increasing while the technologies are developing, but a relation between a RAM and user quantity. And it's a real problem, because this increases expenses.
Main structure problems
As you have read higher multithreaded server's mechanism has two faulty problems. You have already read about the first problem: very closely relation between a RAM and user quantity. Now for you it's clear that this problem is really serious, because it wastes a lot of money and also decreases a speed of the response.
The second problem is blocking I/O. It is also very important, because it as a previous one decreases the speed of getting the response.
In the next paragraph, we will dive into the topic of blocking I/O deeper.
Blocking I/O
After the server checked the quantity of the available threads and connected your response to free one, it began to run every process one by one. Everything looked ok, till the moment when you met a blocking I/O process.
Suddenly, the thread running stoped and it started to wait for something to complete.
Some people can ask: "What the thread is waiting for? What should be completed, before the thread will continue to run another processes?"
The answer is very simple. The blocking I/O should be completed for the thread to continue to run another processes.
For instance disk reading is blocking I/O operation and when it runs, server can do nothing more but wait till it will be completed. Disk reading needs approximately 250000000 number of CPU clocks. You can just imagine, how huge is the number of the processes, that aren't connected with data from disk, could be done asynchronously, while the disk reading process is running. That's why it's no more than wasting a time, while the thread is waiting.

That's why these problems of the multithreaded servers really decrease the speed of the response.
The working mechanism of multithreaded servers (in block diagram)

Way to solve these problems
You already know two main problems, that slow down the thread running. Unfortunately the second problem can't be solved without changing the whole system. The first problem can't also be solved fully, that means that the speed will not increase. The only thing we can do, only to reduce the expenses.
The big amount of RAM is very expensive even now, but due to the new developments in scaling of services, we can make a clever decision.
Some people can ask: "How we can do that?"
Easily. New developments in scaling of services can help us to divide (scale) service by separate server with lower price and lower energy consumption.
For example: The developer knows that this service will use approximately 100000 users. That means that you will need approximately 100 Gb of RAM, but there isn't RAM with 100 Gb, only 128 Gb (more better, than less, because it will contain a reserve).
The 128 Gb with 2 * 64 Gb RAM or 128 Gb RAM are very expensive, that's why we can rent a lot of little servers with 8 Gb RAM and it will be cheaper.
It will be cheaper, because even a lot of little separate servers with the same RAM in summary like in big one, will be cheaper than one big. That's why, even the same RAM, but separated in a lot of parts, will be cheaper than one RAM (for example 128 Gb). Also every little server will consume less energy than big one, even in the time, when they are fully free.
It is a good way to decrease a money that you spend for the servers. However there is one way to spend much less expenses - to use Node.Js.
Node.Js built on the one thread server with non-blocking I/O, that means that it consume much less energy and doesn't need so much RAM, because it use it more "clever" native server. But Node.Js cannot work with mathematical calculations, because it will stuck, that's why in this situation the multithreaded server with blocking I/O is better. However, it is true only for calculations, but for the work with disk, data, databases etc. Node.Js is better, faster and cheaper.
