 |
В данном посте я хочу рассказать об очень простом способе генерации музыки в заданном стиле с помощью контекстно-зависимой грамматики. |
Введение
Работать мы будем с файлами в формате MIDI. Да, хабраюзер, я рыдаю вместе с тобой, но именно в этом формате уже изначально прописаны какие в мелодии инструменты, ноты, длительности. А вот из MP3 их уже не получишь (тривиальным методом по крайней мере), а так бы хотелось...
Но не будем отчаиваться, в интернетах водится масса качественных MIDI-файлов. Могу порекомендовать сервис HamieNET.com. Он позволяет не только скачать MIDI-файл, но и слить сразу мелодию, конвертированную в MP3, а также слить XML-файл, полученный из MIDI, отображает треки, содержащиеся в файле, позволяет прослушать их по одному и т.д. Также есть онлайн-сервис конвертирования вашего MIDI в MP3. Правда, если не платить деньги, то можно конвертировать только одну мелодию в день.
Демонстрация работы
Это оригинальная мелодия Nightwish — Ever Dream:
ссылка зеркало
А это, то, что получилось в результате работы алгоритма:
ссылка зеркало
Это просто перезапуск проги, ничего не меняя, мелодия немного отличается:
ссылка зеркало
В первом варианте, конечно, слышны иногда косяки, во втором все более плавно.
Описание алгоритма
Алгоритм основан на построении контекстно-зависимой грамматики по исходной мелодии, а затем генерировании на основе этой грамматики новой мелодии по заданной начальной последовательности.
Для того, чтобы создать мелодию, нам нужны какие-то правила: например, какие ноты могут идти после текущей последовательность нот. Плюс построения новой мелодии на основе уже существующей в том, что нам не нужно самим придумывать эти правила, а мы просто берем их заданной мелодии.
Все эти правила образуют собой грамматику. Контекстно-зависимая она, потому что и левая, и правая часть правила могут быть окружены контекстом из терминальных и нетерминальных символов. Скорее всего сейчас непонятно, о чем вообще идет речь и что это за страшные слова. Но давайте рассмотрим пример и все сразу встанет на свои места.
Возьмем обычную строку: ABCDEFGIKFHLEFJ. И начнем строить для нее грамматику, начав, скажем, с символа F (вообще это нужно проделать для каждого символа).
Нам нужно написать правило, которое бы указывало нам, какую букву следует поставить, если мы вдруг встретили символ F. Записывается это так: F -> что-то. Как видим, мы не можем создать такое правило, так как лишь по одной букве не можем определить что же должно идти следом: после F может идти как G, так и H или J. Поэтому мы добавляем контекст к нашей букве F, контекст — это символы, окружающие F. Возьмем по одной букве перед F. Получим EF и KF. Контекстом для буквы F здесь служат буквы E и K. Мы с вами только что расширили контекст на один символ, поэтому данный метод построения грамматики называется методом динамически расширяющегося контекста.
Посмотрим можем ли мы сейчас создать правило. После KF идет H, и больше нет других вариантов. Мы получили первое конечное правило: KF -> H (читается как «KF продуцирует H). Теперь, если, например, на конце строки мы встретим KF и нужно будет продлить строку на один символ, мы смело напишем H.
Но у нас еще осталась проблема: после EF может идти как G, так и J. Поэтому мы должны расширить контекст еще на один символ: DEF и LEF. И наконец-то мы получили конечные правила:
KF -> H
DEF -> G
LEF -> J
Это правила для буквы F, в зависимости от ее контекста мы выбираем какое-то одно правило из трех.
Процесс генерации новой строки выглядит следующим образом: дана начальная последовательность, например ADEF. Начинаем брать буквы с конца. F — нет правила с такой левой частью, расширяем контекст — EF, опять нет, расширяем — DEF, есть такое правило, ставим G, получаем ADEFG. Начинаем все сначала: берем букву G и т.д. столько раз, сколько нам нужно.
Будет удобно представлять грамматику в виде дерева. Для буквы F дерево будет иметь следующий вид:
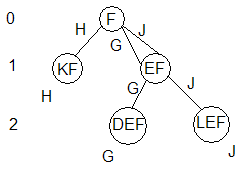
В узлах находятся левые части правил, рядом с узлами написаны правые части правил — возможные продукции. Числа слева от дерева указывают, на каком контекстном уровне находятся узлы.
Теперь перед нами встает следующая проблема: если мы будем генерировать новую последовательность строго по заданным правилам, то мы получим в точности исходную строку (мелодию), а мы хотим создать новую. Поэтому в ряде случаев мы должны не доходить до конечного правила, а взять промежуточное. Это означает, что иногда, встретив скажем такую последовательность: ADEF, мы не будем расширять контекст до конечного правила DEF -> G, а остановимся на F и рандомом или каким-то другим методом выберем любую продукцию (H, G, J) у узла F в дереве. Или остановимся на EF и выберем продукцию G или J. Т.е. мы случайно выбираем уровень контекста в дереве и продукцию на этом уровне.
Ну а теперь представим, что каждая буква — это не буква, а аккорд, а применительно к MIDI-файлу будет вернее сказать, что это совокупность событий (к которым относится включение/выключение ноты, смена канала и т.д.), и вот уже наш алгоритм готов для мелодии.
Еще немного о MIDI
Наткнувшись на онлайн-сервис, позволяющий конвертировать MIDI в XML, я понял, что так с ним будет работать намного удобнее. Также нам нужно проделать еще одну вещь. Есть несколько форматов MIDI файлов. Формат 0 содержит 1 трек, форматы 1 и 2 содержат несколько треков. Чаще всего попадаются MIDI с форматом 1, где под каждый инструмент отводится свой трек: на одном треке играют гитарки, на другом скрипка и т.д. Это добавит некоторые трудности при построении грамматики. Нужно будет следить, что происходит на другом треке. Поэтому мы просто конвертируем формат 1 в формат 0, чтобы все инструменты были в куче на одном треке, а после перегоним еще и в XML. Все эти инструменты доступны здесь.
В конечном итоге получим примерно такой файл:
<?xml version="1.0" encoding="ISO-8859-1"?><br><!DOCTYPE MIDIFile PUBLIC<br> "-//Recordare//DTD MusicXML 0.9 MIDI//EN"<br> "http://www.musicxml.org/dtds/midixml.dtd"><br><MIDIFile><br><Format>0</Format><br><TrackCount>1</TrackCount><br><TicksPerBeat>384</TicksPerBeat><br><TimestampType>Absolute</TimestampType><br><Track Number="0"><br> <Event><br> <Absolute>0</Absolute><br> <ControlChange Channel="2" Control="91" Value="46"/><br> </Event><br> <Event><br> <Absolute>0</Absolute><br> <ProgramChange Channel="2" Number="49"/><br> </Event><br> <Event><br> <Absolute>0</Absolute><br> <ControlChange Channel="2" Control="0" Value="0"/><br> </Event><br>...<br> <Event><br> <Absolute>24908</Absolute><br> <NoteOff Channel="11" Note="41" Velocity="127"/><br> </Event><br> <Event><br> <Absolute>24912</Absolute><br> <NoteOn Channel="11" Note="41" Velocity="127"/><br> </Event><br> <Event><br> <Absolute>24956</Absolute><br> <NoteOff Channel="11" Note="41" Velocity="127"/><br> </Event><br> <Event><br> <Absolute>24960</Absolute><br> <NoteOn Channel="11" Note="41" Velocity="127"/><br> </Event><br>...<br></Track><br></MIDIFile><br><br>* This source code was highlighted with Source Code Highlighter.Здесь мы можем увидеть темп мелодии 384. Вначале устанавливаются настройки каналов для каждого инструмента, но нас больше будут интересовать события NoteOn и NoteOff — включения и выключения ноты. Они содержат канал, на котором играет нота, сам номер ноты и ее скорость. Также мы видим абсолютное время для каждого события. Можно генерировать XML с абсолютным и относительным временем. Абсолютное время — время, прошедшее с самого начала трека, относительное — прошедшее с момента последнего события. Для нас удобнее брать абсолютное, т.к. по нему мы можем легко сгруппировать события, произошедшие в один и тот же момент времени. Эти группы я обзову „аккордами“.
шКодим
Опишем класс „аккорда“:
public class Chord<br> {<br> //задержка после предыдущего "аккорда"<br> public int Delay { get; set; }<br> //события<br> public List<string> Events { get; set; }<br><br> public Chord()<br> {<br> Events = new List<string>();<br> }<br> }<br><br>* This source code was highlighted with Source Code Highlighter.Заодно напишем класс для сравнения „аккордов“:
public class ChordComparer : IEqualityComparer<Chord><br> {<br> public bool Equals(Chord x, Chord y)<br> {<br> if (x.Delay != y.Delay)<br> return false;<br> if (x.Events.Count != y.Events.Count)<br> return false;<br> foreach (var ev in x.Events)<br> if (!y.Events.Contains(ev))<br> return false;<br> foreach (var ev in y.Events)<br> if (!x.Events.Contains(ev))<br> return false;<br> return true;<br> }<br><br> public int GetHashCode(Chord obj)<br> {<br> int hash = obj.Delay.GetHashCode();<br> obj.Events.ForEach(ev => hash += ev.GetHashCode());<br> return hash;<br> }<br> }<br><br>* This source code was highlighted with Source Code Highlighter.И класс для сравнения последовательностей „аккордов“:
public class ListComparer : IEqualityComparer<List<Chord>><br> {<br> private ChordComparer cc = new ChordComparer();<br><br> public bool Equals(List<Chord> x, List<Chord> y)<br> {<br> if (x.Count != y.Count)<br> return false;<br> for (int i = 0; i < x.Count; i++)<br> if (!cc.Equals(x[i], y[i]))<br> return false;<br> return true;<br> }<br><br> public int GetHashCode(List<Chord> obj)<br> {<br> int hash = 0;<br> obj.ForEach(ch => ch.Events.ForEach(ev => hash += ev.GetHashCode()));<br> obj.ForEach(ch => hash += ch.Delay.GetHashCode());<br> return hash;<br> }<br> }<br><br>* This source code was highlighted with Source Code Highlighter.Класс узла дерева:
//целиком не вставляется, так что приведен частично<br> public class Node<br> {<br> //значение узла - левая часть правила<br> public List<Chord> Value { get; set; }<br> //лист пар ключ-значение, ключ - возможная продукция, значение - следующий узел, который может быть null<br> public List<KeyValuePair<Chord, Node>> Nodes { get; set; }<br><br> //получить продукцию для переданной последовательности<br> public Chord GetProduction(List<Chord> seq)<br> {<br> //если всего один подузел и у него нет потомков, возвращаем единственно возможную продукцию<br> if (Nodes.Count == 1 && Nodes[0].Value == null)<br> {<br> return Nodes.First().Key;<br> }<br> else<br> {<br> //путь от корня дерева до конечного правила<br> List<Node> path = new List<Node>();<br> ListComparer lc = new ListComparer();<br> path.Add(this);<br> //если последовательность состоит лишь из одного "аккорда", мы не можем расширить контекст,<br> //поэтому возвращаем рандомную продукцию корня<br> if (seq.Count == 1)<br> {<br> if (Nodes.Count != 0)<br> {<br> return Nodes[Helper.rand.Next(Nodes.Count)].Key;<br> }<br> //если вдруг оказалось, что продукций нет, то возвращаем "аккорд", находящийся поблизости от<br> //текущего<br> else<br> {<br> int t = Helper.rand.Next(-10, 11);<br> int index = 0, i;<br> for (i = 0; i < Helper.listchords.Count; i++)<br> if ((index = Helper.listchords[i].IndexOf(seq.Last())) != -1) break;<br> return Helper.listchords[i][Math.Max(0, Math.Min(index + t, Helper.listchords[i].Count - 2))];<br> }<br> }<br> else<br> {<br> //расширяем контекст<br> List<Chord> extseq = seq.GetRange(seq.Count - 2, 2);<br> //ищем в подузлах правило для расширенного контекста<br> List<Node> nodes = Nodes<br> .Where(node => node.Value != null && lc.Equals(node.Value.Value, extseq))<br> .Select(node => node.Value)<br> .Distinct()<br> .ToList();<br> //не нашли, тогда возвращаем рандомную продукцию корня или ближайший "аккорд"<br> if (nodes.Count == 0)<br> {<br> if (Nodes.Count != 0)<br> {<br> return Nodes[Helper.rand.Next(Nodes.Count)].Key;<br> }<br> else<br> {<br> int t = Helper.rand.Next(-10, 11);<br> int index=0, i;<br> for (i = 0; i < Helper.listchords.Count; i++)<br> if ((index = Helper.listchords[i].IndexOf(seq.Last())) != -1) break;<br> return Helper.listchords[i][Math.Max(0, Math.Min(index + t, Helper.listchords[i].Count - 2))];<br> }<br> }<br> //нашли<br> else<br> {<br> //правило для контекста<br> Node rule = nodes.First();<br> //ищем более точное правило, увеличивая контекст<br> rule.GetProduction(seq, ref path, 3);<br> //с вероятностью 60% возвращаем продукцию конечного правила<br> if (Helper.rand.NextDouble() <= 0.6)<br> {<br> return path.Last().Nodes[0].Key;<br> }<br> //с оставшейся вероятностью возвращаем рандомную продукцию рандомного узла ветви дерева,<br> //которая идет от корня до конечного правила<br> else<br> {<br> Node p = path[Helper.rand.Next(path.Count)];<br> return p.Nodes[Helper.rand.Next(p.Nodes.Count)].Key;<br> }<br> }<br> }<br> }<br> }<br><br> //продолжаем искать конечное правило для переданной последовательности, c - уровень контекста<br> private void GetProduction(List<Chord> seq, ref List<Node> path, int c)<br> {<br> //добавляем себя в ветвь<br> path.Add(this);<br> //далее происходит примерно то же самое, что в функции выше<br> }<br> }<br><br>* This source code was highlighted with Source Code Highlighter.Целиком проект можно слить здесь (зеркало).
Важную роль здесь играет то, как вы организуете рандом. Сначала я сделал рандом с распределением Пуассона с матожиданием равным номеру последнего узла, но мелодия сильно лажала, поэтому я оставил более простой вариант.
Пост написан после прочтения данной статьи.
