I've long wanted to create educational materials on the topic of Information Theory + Machine Learning. I found some old drafts and decided to polish them up here, on Habr.
Information Theory and Machine Learning seem to me like an interesting pair of fields, the deep connection between which is often unknown to ML engineers, and whose synergy has not yet been fully revealed.
When I tell colleagues that LogLoss on the test set and Mutual Information between the prediction and the predicted value are directly related, and that you can get one from the other using a simple formula, they often express genuine surprise. There is a link from the LogLoss Wikipedia page to Mutual Information, but that's about it.
Information Theory can become (or rather, has become) a source of understanding how and why different ML methods work, especially neural networks, and can also provide ideas for improving gradient-based optimization methods.
Let's start with basic concepts like Entropy, Information in a message, Mutual Information, and channel capacity. Next, there will be materials on the similarity between tasks of maximizing Mutual Information and minimizing Loss in regression problems. Then there will be a section on Information Geometry: Fisher metric, geodesics, gradient methods, and their connection to Gaussian processes (moving along the gradient using SGD is moving along the geodesic with noise).
It's also necessary to touch upon AIC, Information Bottleneck, and discuss how information flows in neural networks – Mutual Information between layers (Information Theory of Deep Learning, Naftali Tishby), and much more. It's not certain that I'll be able to cover everything listed, but I'll try to get started.
1. Basic Definitions


Let's describe them. We'll start with basic definitions
Definition 1.1: Uncertainty is the logarithm base 2 of the number of equiprobable possibilities:  . It is measured in bits. For example, the uncertainty of an unknown binary word of length k is equal to k.
. It is measured in bits. For example, the uncertainty of an unknown binary word of length k is equal to k.
Logarithm
The logarithm base 2 of a number is how many times you need to divide the number by 2 to get a number less than or equal to 1. For example,

For non-powers of two, this function smoothly extends. For example,

An important property of logarithms:

Try to derive it from the non-strict definition above for the case when  and
and  are powers of two.
are powers of two.
Binary words
Binary words of length k are sequences of zeros and ones of length k. Each character in a binary words is called a bit. For example, here are binary words of length 5:
00000, 00001, 00010, 00011, 00100, 00101, ... , 11100, 11101, 111110, 11111
There are 32 of them.  , which means the uncertainty of a 5-bit word is 5.
, which means the uncertainty of a 5-bit word is 5.
That's exactly the number of unknown bits in an unknown 5-bit binary word.
Thus, each symbol in a binary word is called a "bit," but a "bit" is also a unit of uncertainty measurement. And this example helps to understand why.
For brevity,  is simply denoted as
is simply denoted as  throughout.
throughout.
Definition 1.2: Information in a message is the difference in uncertainty before receiving the message and after.

This is also measured in bits.
For example, Vanya has chosen a number from 1 to 100. We are told that it is less than or equal to 50. The uncertainty before the message is  , and after the message, it is
, and after the message, it is  . Therefore, there is 1 bit of information in this message. By skillfully asking binary questions (questions to which the answer is either YES or NO), you can extract exactly 1 bit of information.
. Therefore, there is 1 bit of information in this message. By skillfully asking binary questions (questions to which the answer is either YES or NO), you can extract exactly 1 bit of information.
Some questions are inefficient. For instance, the question "Is the number less than or equal to 25?" reduces uncertainty by  bits with a probability of 0.25, and with a probability of 0.75, it only reduces it by
bits with a probability of 0.25, and with a probability of 0.75, it only reduces it by  bits, which on average is
bits, which on average is  bits. If you divide the set of possibilities in a ratio of
bits. If you divide the set of possibilities in a ratio of  , with your question, then the average amount of information in the answer is
, with your question, then the average amount of information in the answer is  .
.
We will denote this expression as  or
or  . Here, as programmers, we overload the function H to work in two cases - when a pair of numbers is input, the sum of which is 1, and when one number is from the interval [0, 1].
. Here, as programmers, we overload the function H to work in two cases - when a pair of numbers is input, the sum of which is 1, and when one number is from the interval [0, 1].
Definition 1.3: 
Plot H(x)
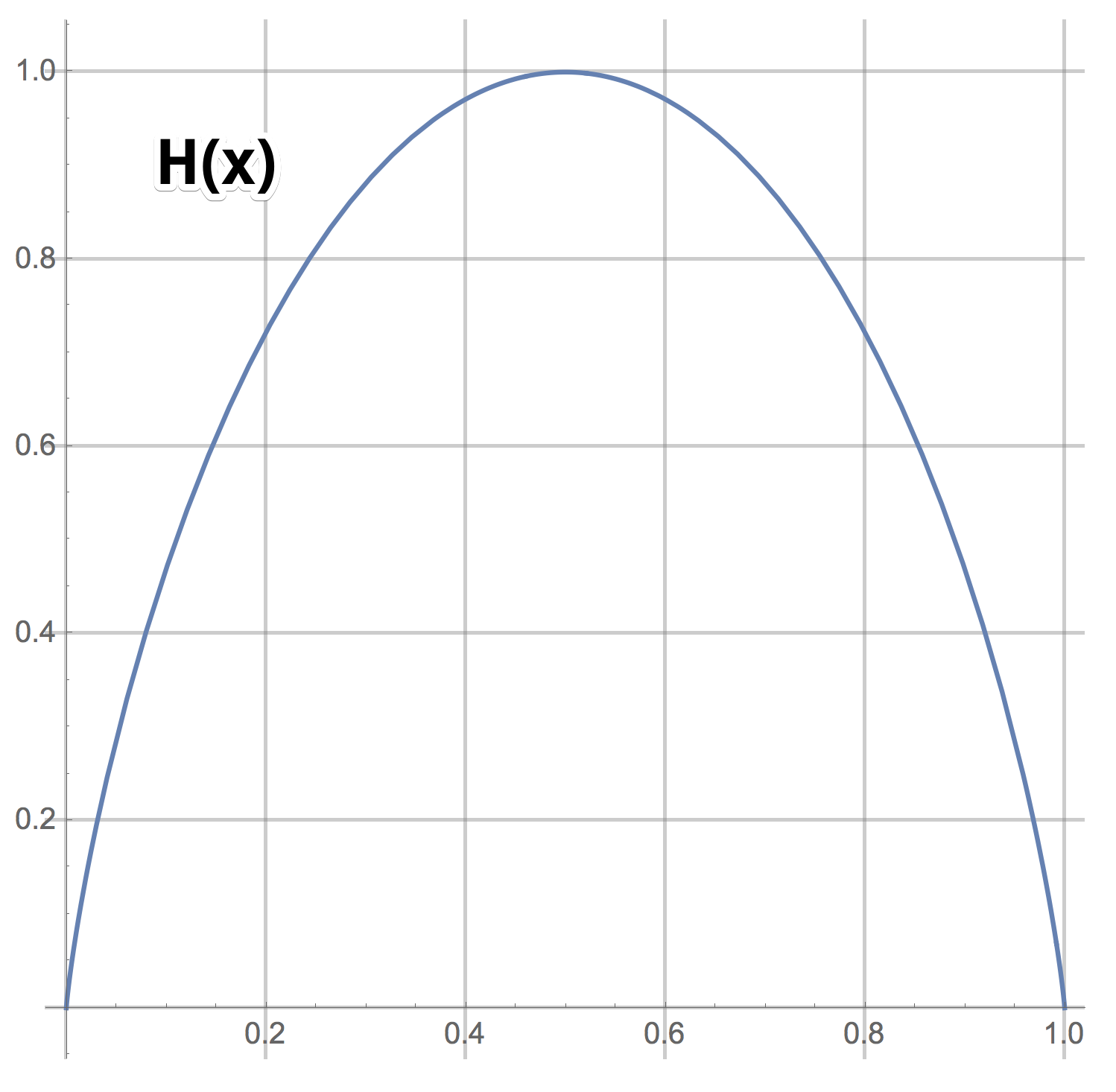
It's evident that by asking binary questions, you can extract a maximum of 1 bit of information on average (the maximum value of the function  . Let's reiterate: yes, you can directly ask questions like "Is the number equal to 57?" and if you're lucky, you can get log(100) bits of information. However, if luck is not on your side, you will only get log(100/99) bits of information. The average number of bits of information for such types of questions is
. Let's reiterate: yes, you can directly ask questions like "Is the number equal to 57?" and if you're lucky, you can get log(100) bits of information. However, if luck is not on your side, you will only get log(100/99) bits of information. The average number of bits of information for such types of questions is which is noticeably less than 1.
which is noticeably less than 1.
In this example, there are 100 possibilities, which means the initial uncertainty is – this is how many binary questions you, on average, need to ask Vanya to find out the answer. However, the number is not an integer, so you need to round it up.
– this is how many binary questions you, on average, need to ask Vanya to find out the answer. However, the number is not an integer, so you need to round it up.
If we ask not binary questions but questions that imply a natural number from 1 to M as the answer, we can get more than one bit of information in a single response. If we ask a question for which all M answers are equally likely, then on average, we will get  bits. However, if the probability of answer i is p(i), then the average number of bits in the response will be:
bits. However, if the probability of answer i is p(i), then the average number of bits in the response will be:

Definition 1.4: The entropy of a discrete distribution  is defined by the formula (1) above.
is defined by the formula (1) above.
Here, we have overloaded the function H for the case when a discrete distribution is provided as input.
SO: The first straightforward way to arrive at the formula for entropy  is to calculate the average number of bits of information in response to a question with equiprobable answers.
is to calculate the average number of bits of information in response to a question with equiprobable answers.
Let's go further. Suppose Vanya doesn't choose a number but samples it from the distribution  . How many binary questions do we need to ask Vanya to determine the sampled number? Intuitively, we need to divide the set of possibilities into two subsets, not necessarily of equal size but with approximately equal total probability, and ask Vanya which of the two subsets contains the sampled number. Get the answer and continue in the same manner with the reduced set of possibilities - again dividing it into two subsets with roughly equal probability, asking Vanya which of the two subsets contains the sampled number, and so on. The idea is good but not quite practical. It turns out it's more effective to work backward and start building the partition tree from the bottom. Specifically, find the two least probable outcomes and merge them into a single new outcome, thus reducing the number of possibilities by 1. Then, once again, find the two least probable outcomes and merge them into a new one, and so on, ultimately constructing a binary tree. The numbers are located in the leaves of this tree. The internal nodes are labeled with sets of numbers from the subtree they represent, and the root is labeled with the set of all numbers. This tree provides an algorithm for how to ask Vanya questions. You should start at the root of the tree and ask Vanya which way to go - left or right (which of the two children subsets contains the sampled number) according to this tree structure. This tree not only provides the recipe for the fastest average method of guessing the number but also serves as the Huffman algorithm for data compression.
. How many binary questions do we need to ask Vanya to determine the sampled number? Intuitively, we need to divide the set of possibilities into two subsets, not necessarily of equal size but with approximately equal total probability, and ask Vanya which of the two subsets contains the sampled number. Get the answer and continue in the same manner with the reduced set of possibilities - again dividing it into two subsets with roughly equal probability, asking Vanya which of the two subsets contains the sampled number, and so on. The idea is good but not quite practical. It turns out it's more effective to work backward and start building the partition tree from the bottom. Specifically, find the two least probable outcomes and merge them into a single new outcome, thus reducing the number of possibilities by 1. Then, once again, find the two least probable outcomes and merge them into a new one, and so on, ultimately constructing a binary tree. The numbers are located in the leaves of this tree. The internal nodes are labeled with sets of numbers from the subtree they represent, and the root is labeled with the set of all numbers. This tree provides an algorithm for how to ask Vanya questions. You should start at the root of the tree and ask Vanya which way to go - left or right (which of the two children subsets contains the sampled number) according to this tree structure. This tree not only provides the recipe for the fastest average method of guessing the number but also serves as the Huffman algorithm for data compression.
Task 1.1: Study the Huffman code. Prove that a text with an original length of  characters, in its compressed form, has a length bounded from below by
characters, in its compressed form, has a length bounded from below by  bits, and under favorable circumstances, it achieves this bound.
bits, and under favorable circumstances, it achieves this bound.
So, the formula  arises when solving the problem of finding the minimum average number of binary questions needed to determine the outcome of a random variable with distribution
arises when solving the problem of finding the minimum average number of binary questions needed to determine the outcome of a random variable with distribution  .
.
This is the second way to arrive at formula (1).
For a random variable  , we will use the following notations for the entropy of its distribution
, we will use the following notations for the entropy of its distribution  (once again, "overloading" the function
(once again, "overloading" the function  ):
):
 or
or  or
or  or
or 
There's yet another, a third, simple way to arrive at the formula for entropy, but it requires knowledge of the Stirling formula.
Task 1.2: You have an unknown binary word of length k (a sequence of ones and zeros, a total of  characters). You are told that it contains 35% ones. What is the value of
characters). You are told that it contains 35% ones. What is the value of  for large
for large 
Answer
Approximately , where
, where 
Task 1.3: Vanya has an unknown word of length k in an alphabet of size M. He has provided the proportions of all the letters in the word as  .
.
What is the value of I(message) / k for large k?
Answer

So, Task 1.3 is indeed the third way to arrive at formula (1).
Definition 1.5: Information in a message about a certain random variable is the difference in entropies: 
The values of a random discrete variable can be seen as letters, and each successive letter in a word is just another measurement of the random variable. So, the information in a message about a certain random variable is the number of bits of information about measurements of that random variable, normalized by the number of measurements.
Problem 1.4: What is the entropy of the discrete distribution  ? How much information is contained in the message
? How much information is contained in the message  , where
, where  has the distribution
has the distribution  ?
?
Answer


This result requires acceptance. How can this be? – We were given seemingly non-zero information, eliminated the most probable option from the possibilities. However, the uncertainty about the remaining possibilities remains the same, so the formula  yields an answer of 0.
yields an answer of 0.
Task 1.5: Provide an example of a finite distribution and a message that does not reduce but increases uncertainty.
Ответ
 , and message = "this is not the first element". Then
, and message = "this is not the first element". Then 
The ancient wisdom "in much wisdom is much grief" in this context gets another interesting interpretation: the modern world, science, and human life are such that new "messages" about history and the structure of the world only increase uncertainty.
Discrete distributions on a countable set of values that decay exponentially (geometric progressions) have the property of unchanged uncertainty when receiving information, meaning that among the first elements, there is no correct answer. Distributions with less than exponential decay (e.g.,  ) only increase uncertainty when discarding the first elements.
) only increase uncertainty when discarding the first elements.
Problem 1.6: Write the formula for the entropy of the Poisson distribution

Find a simple approximation for large  .
.
Answer

Task 1.7: Given the distribution  of a real random variable. Let
of a real random variable. Let  be the average number of binary questions needed to determine some outcome of the random variable with an accuracy of
be the average number of binary questions needed to determine some outcome of the random variable with an accuracy of  . Find an approximate expression for
. Find an approximate expression for  for small values of
for small values of  .
.
Answer


(see definition of entropy of a continuous distribution below).
Definition 1.6: The entropy of a continuous distribution is given by

Here, we have once again overloaded the symbol H for the case when the argument is a probability density function (PDF).
Task 1.8: Given two distributions  and
and  of two real random variables. What does the difference
of two real random variables. What does the difference  approach as
approach as  ?
?
Answer

Task 1.9: What is the entropy of a normal distribution  ?
?
Answer

Task 1.10: Write down the formula for the entropy of an exponential distribution  .
.
Problem 1.11: A random variable  is a mixture of two random variables, meaning its distribution
is a mixture of two random variables, meaning its distribution  is a weighted sum of distributions:
is a weighted sum of distributions:

Let the set of values taken by  not overlap with the set of values taken by
not overlap with the set of values taken by  , in other words, let the supports of these two random variables not intersect. Find an expression for the entropy
, in other words, let the supports of these two random variables not intersect. Find an expression for the entropy  in terms of the entropies
in terms of the entropies  and
and  .
.
Answer

The last equality here is possible only because the supports of  and
and  from the two distributions do not overlap as stated in the problem. Next, we will transform this expression into
from the two distributions do not overlap as stated in the problem. Next, we will transform this expression into

In this problem, the goal was to show that even in the simple case of non-overlapping supports, entropies do not simply add up with their respective weights, but there is an additional term  . When the weights are equal to 1/2, this additional term is equal to 1.
. When the weights are equal to 1/2, this additional term is equal to 1.
The interpretation of the formula is as follows: when an outcome is measured, with a probability of  , it lies in
, it lies in  , and with a probability of
, and with a probability of  , it lies in
, it lies in  . Consequently, we incur an uncertainty of
. Consequently, we incur an uncertainty of  values on the set
values on the set  , or an uncertainty of
, or an uncertainty of  on the set
on the set  . However, to determine in which set the measurement lies, on average, we will need to ask
. However, to determine in which set the measurement lies, on average, we will need to ask  questions.
questions.
From this, it follows, in particular, that a mixture with coefficients of 1/2 of two normal random variables with the same variance, but significantly different means, has an entropy, that is 1 greater than the entropy of a single normal distribution. The supports of normal random variables span the entire real line, which means they overlap, but in the case of significantly different means, this overlap can be neglected.
Task 1.12: A random variable  is equally likely to be 0 or 1. Another random variable
is equally likely to be 0 or 1. Another random variable  depends on : if
depends on : if  , then
, then  is sampled from
is sampled from  , and if
, and if  , then is sampled from
, then is sampled from  . How many bits of information about the random variable are contained in the message
. How many bits of information about the random variable are contained in the message  (as a function of
(as a function of  )?
)?
Answer
There is a numerical answer to this:
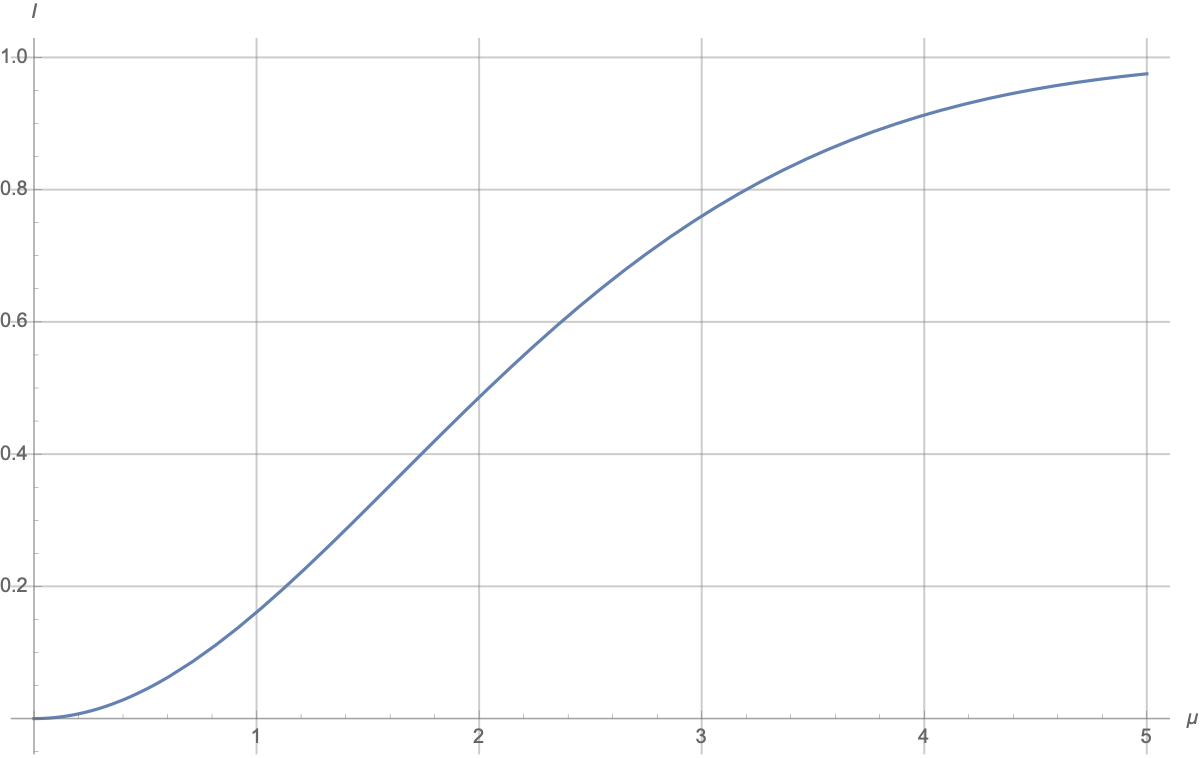
It's clear that the graph starts at 0 and approaches 1:
When
 , both Gaussians are identical, and the message about which one was chosen provides no information.
, both Gaussians are identical, and the message about which one was chosen provides no information.When
 , we have a mixture of two Gaussian distributions with widely separated centers. The message about the value of
, we have a mixture of two Gaussian distributions with widely separated centers. The message about the value of  indicates which of the two "bell curves" the answer is in, reducing the number of possibilities by approximately half, and uncertainty decreases by 1. The "approximation" is related to the fact that the "curves" overlap, but the overlap size quickly decreases with increasing
indicates which of the two "bell curves" the answer is in, reducing the number of possibilities by approximately half, and uncertainty decreases by 1. The "approximation" is related to the fact that the "curves" overlap, but the overlap size quickly decreases with increasing  .
.In the vicinity of
, there is a quadratic growth, roughly  .
.The approach to 1 occurs approximately according to the law

Task 1.13: The random variable is structured as follows: first, a number  is sampled from an exponential distribution with mean
is sampled from an exponential distribution with mean  , and then a random number
, and then a random number  is sampled from a Poisson distribution with parameter
is sampled from a Poisson distribution with parameter  . We received a message that one measurement yielded
. We received a message that one measurement yielded  . How many bits of information did we gain about the random variable
. How many bits of information did we gain about the random variable  ? Provide a numerical answer. How many bits of information will the sequence of measurements 10, 9, 11, 8, 10 provide?
? Provide a numerical answer. How many bits of information will the sequence of measurements 10, 9, 11, 8, 10 provide?

Task 1.14: The random variable is constructed as follows: first, a number  is sampled once from a beta distribution with parameters
is sampled once from a beta distribution with parameters  , and then a random number is sampled from a binomial distribution with parameters
, and then a random number is sampled from a binomial distribution with parameters  . We received a message that one measurement of
. We received a message that one measurement of  resulted in 10 (meaning 10 out of 100 coin flips resulted in heads). How many bits of information did we gain about the hidden random variable
resulted in 10 (meaning 10 out of 100 coin flips resulted in heads). How many bits of information did we gain about the hidden random variable  ? Provide a numerical answer. How many bits of information will a sequence of measurements 10, 9, 11, 8, 10 provide?
? Provide a numerical answer. How many bits of information will a sequence of measurements 10, 9, 11, 8, 10 provide?
Task 1.15: Random variables  are sampled from a beta distribution with parameters . The actual values of are unknown to us, but we have been given 10 measurements
are sampled from a beta distribution with parameters . The actual values of are unknown to us, but we have been given 10 measurements  from 10 binomial distributions with parameters
from 10 binomial distributions with parameters  , and this is our knowledge about
, and this is our knowledge about  . How many bits of information will we gain on average about a random binomial variable with parameters when we are told the value of
. How many bits of information will we gain on average about a random binomial variable with parameters when we are told the value of  ? What if are known with absolute certainty (i.e.,
? What if are known with absolute certainty (i.e.,  )? What if 10 is replaced with
)? What if 10 is replaced with  ?
?
This problem can be formulated in the language of machine learning as follows: we have a categorical feature  to predict a binary variable ('will the user click on the banner or not'). How good will our prediction be if, in the training data, we only have historical data about the number of clicks and non-clicks for these 10 categories?
to predict a binary variable ('will the user click on the banner or not'). How good will our prediction be if, in the training data, we only have historical data about the number of clicks and non-clicks for these 10 categories?
Task 1.16: A random variable  follows a normal distribution
follows a normal distribution  . The value of
. The value of  is unknown to us, but we know that it was sampled from a distribution
is unknown to us, but we know that it was sampled from a distribution  . On average, how much information will we gain about
. On average, how much information will we gain about  from the first measurement of ? How will the amount of information gained grow with the number of measurements?
from the first measurement of ? How will the amount of information gained grow with the number of measurements?
Answer
The initial variance  is equal to
is equal to  . After
. After  measurements, the variance decreases to
measurements, the variance decreases to
 .
.
From the initial entropy  , subtract the final entropy
, subtract the final entropy  , and we get
, and we get

Thus, for large  , the information grows as
, the information grows as  , and the error
, and the error  decreases approximately proportionally to
decreases approximately proportionally to  .
.
This means that the number of correct digits in the decimal representation of the number  grows as
grows as  . If you want to get one more correct decimal digit of the number
. If you want to get one more correct decimal digit of the number  , you need to increase the number of measurements
, you need to increase the number of measurements  by a factor of 100.
by a factor of 100.
Continuation:
Part 2 - Mutual Information: In this part, the concept of Mutual Information is explained. It opens doors to error-correcting codes, compression algorithms, and provides a new perspective on Machine Learning problems.
Part 3 - ML & Mutual Information: Fundamentals of Machine Learning in the context of information theory.
