Всем привет!
Недавно прошла ночь в финтехе от Яндекса и поскольку Яндекс сам не рассказал о нем здесь, это сделаю я. Чтобы попасть на мероприятие нужно было решить несложную задачку.
Статья будет включать 3 темы: предыстория, попытки решения, послесловие и мои мысли.
П.С. вся статья носит авторский характер и написана в вольном стиле.
Короткая предыстория
Ближе к ночи я писал код и листал ленту ВК, пока компьютер компилировал мой код.
Неожиданно мое внимание привлек интересный рекламный пост в ленте. Меня заинтересовал даже не столько пост, сколько его формат. "Приглашаем (крутых?) разработчиков на закрытое "пати" для дружеского общения и найма (к сожалению, ссылка на рекламный пост у меня не сохранилась), - так можно передать суть поста и красочная картинка внизу.
Ремарка: "Крутых" я написал курсивом, потому что в рекламе как будто говорилось о >мидл уровне, хотя в оригинале об этом не сказано.
Интересно, Я не только тратит бюджет на рекламу вакансий (что обыденно), но и организует тусовки закрытого формата, а это уже что-то новенькое. Умело проработанная дизайнером картинка и не менее яркая отдельная страничка вселяли уверенность в серьезность мероприятия. В качестве фейс-контроля выступала задача, что только придавало ажиотажа.
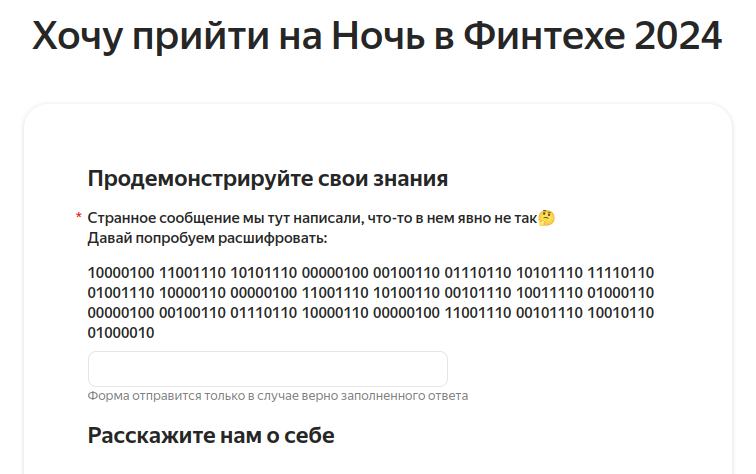
Задача
Cтранное сообщение мы тут написали, что-то в нем явно не так?Форма отправится только в случае верно заполненного ответа
Давай попробуем расшифровать:
10000100 11001110 10101110 00000100 00100110 01110110 10101110 11110110 01001110 10000110 00000100 11001110 10100110 00101110 10011110 01000110 00000100 00100110 01110110 10000110 00000100 11001110 00101110 10010110 01000010
Поле для ответа:
Попытки решения
На протяжении всего процесса я придерживался правила "решение должно быть очень простым, 5, 15, максимум 30 минут, иначе они потеряют конверсию"
Попытка 1 - кураж
Да это же обычные ASCII символы, классика, любой студент первокурсник это решит!
ASCII - (American Standard Code for Information Interchange) это самая популярная кодировка и самое популярное представление текста в виде чисел в мире.
Заменяем числа на буквы, вуаля! Задача решена за 30 секунд!
Результат:
�ή&v��N�Φ.�F&v��.�B
(Редакторы могут это по разному отображать, но суть одна - нечитаемо)
Твое лицо, когда ответ для набора байтов это не ASCII символы

Вероятно, мой мозг испытал в этот момент все 5 стадий принятия:
отрицание, гнев, торг, депрессия, принятие.
Более опытные коллеги заметили подвох сразу:
В ASCII только 128 кодов, в то время как байт содержит 256 возможных комбинаций.

Попытка 2 - игнорирование
А давайте просто проигнорируем байты, которые выходят за диапазон 128? - А давайте!
И вышла очередная тарабарщина, из букв и знаков препинания (служебных символов), только более короткая.
Попытка 3 - что ж, видимо придется все таки прочитать условие задачи ...
<<Давай попробуем расшифровать>>
Раз это шифр, то обязан быть и ключ и алгоритм шифрования.
Где здесь может быть ключ шифрования?
Каждый криптограф знает, что в настоящем шифротексте не бывает пробелов, только дурак так сделает, соответственно они здесь намеренно, это подсказка.
Да и биты, пусть это не ASCII, но они так удачно расположены, по 8 штук в ряд, это точно последовательность байт, а еще ровные колонки, возможно это просто верстка, а возможно так и задумано, в любом случае, быстрее проверить теорию, чем читать код или менять размер экрана.
Попробуем применить какую-то логическую операцию к каждой строке или колонке или ко всему сразу, в общем как-нибудь, ведь для чего еще нужны биты, если не применять к ним булевы операторы?
Было бы понятнее, если задача представляла собой ровный прямоугольник, но одинокий байт в последней строке портит все догадки, что с ним делать, проигнорировать, применить ко всему сразу, сделать исключение для первой колонки, что это, строка из 1-го байта тогда? В общем слишком много неясностей, поэтому решаю искать только те последовательности, из которых "варится каша" для 1-го из операторов:
1. AND - И
2. OR - ИЛИ
3. XOR - Исключающее или
4. NAND – И-НЕ
5. NOR – ИЛИ-НЕ
6. XNOR – Исключающее ИЛИ-НЕ
К сожалению, каждая из операций дала False на стадии сравнения, т.е. уравнения не получилось и колонки или строки не связаны между собой логическими операциями.
В голове прокрутилась мысль "а что, если применить комбинацию операций", однако это противоречит принципу задачи, "решение должно быть очень простым".
Попытка 4 - Ох, как я не хотел погружаться в кодировки!
Предположим, что это не ASCII кодировка, а UNICODE, а самая популярная реализация UNICODE спецификации это UTF8, которая содержит весь диапазон байта, а не только диапазон 0-127. Плохой новостью было то, что UTF8 так-же не использует диапазон 128-256, вернее использует, но для собственных нужд, типа указания количества байт в символе и т.п.
Что касается UTF16 и UTF32 - то с ними так-же облом, они используют минимум 2 и 4 байта соответственно.
Попытка 5 - придется проявить сообразительность, и выявить побольше хинтов
Что нам даст статистчисекий анализ?
Напишем немного кода на пайтоне:# Наша строка
In [1]: s = '10000100 11001110 10101110 00000100 00100110 01110110 10101110 11110110 01001110 10000110 00000100 11001110 10100110 00101110 10011110 01000110 00000100 00100110 01110110 10000110 00000100 11001110 00101110 10010110 01000010'
# Сделаем список
In [2]: l = s.split()
In [3]: l
Out[3]:
['10000100',
'11001110',
'10101110',
'00000100',
'00100110',
'01110110',
'10101110',
'11110110',
'01001110',
'10000110',
'00000100',
'11001110',
'10100110',
'00101110',
'10011110',
'01000110',
'00000100',
'00100110',
'01110110',
'10000110',
'00000100',
'11001110',
'00101110',
'10010110',
'01000010']
# Переведем в десятичную систему (h - human readable)
In [4]: lh = [int(i, 2) for i in l]
In [5]: lh
Out[5]:
[132,
206,
174,
4,
38,
118,
174,
246,
78,
134,
4,
206,
166,
46,
158,
70,
4,
38,
118,
134,
4,
206,
46,
150,
66]
In [6]: from collections import Counter
In [7]: d = Counter(lh)
In [8]: d
Out[8]:
Counter({132: 1,
206: 3,
174: 2,
4: 4,
38: 2,
118: 2,
246: 1,
78: 1,
134: 2,
166: 1,
46: 2,
158: 1,
70: 1,
150: 1,
66: 1})
# Отсортируем
In [9]: ds = dict(sorted(d.items(), key=lambda item: item[1], reverse=True))
In [10]: ds
Out[10]:
{4: 4,
206: 3,
174: 2,
38: 2,
118: 2,
134: 2,
46: 2,
132: 1,
246: 1,
78: 1,
166: 1,
158: 1,
70: 1,
150: 1,
66: 1}
Не густо, но кое-что есть. В частности мы видим, что самый частый символ - это символ "4", который означает конец передачи данных. Возможно это совпадение, а возможно и нет, копаем дальше ...
А что если 1-ый бит всех байтов в нашей задаче - это знаковый бит?!
Наш способ ведь не учитывал кейс singed / unsigned bit, он по умолчанию unsigned!# Здесь "int(i, 2)" означает unsigned, для signed нужен кардинально другой подходlh = [int(i, 2) for i in l]
Черт знает что я буду делать с отрицательными числами, но возможно, стоить взглянуть на них, ведь проблема именно с ними, т.к. они выходят из диапазона, если трактовать первый бит как знаковый, то все байты будут аккурат в диапазоне ASCII. К тому же это даст новое поле для идей, возможно стоит отсортировать их по возрастанию или отбросить отрицательные, кто знает.
Гуглим python unsigned int = https://stackoverflow.com/a/62696400int.from_bytes(n.to_bytes(length=1, byteorder='little', signed=False), byteorder='little', signed=True)
ЭВРИКА! byteorder='little' - взгляд невольно зацепился за параметр.
А что если наши байты просто написаны в little endian?! Другими словами их нужно читать справа налево, а не слева направо как мы привыкли!
Попытка 6 - решение
Проверяем нашу гипотезу:# Здесь видно, что все наши байты начинаются с 0, т.е. не выходят за диапазон ASCII
# Конструкция с[::-1] просто перевренет строку (реверс), qwerty - ytrewq
# lr - list reversed
In [11]: lr = [с[::-1] for с in l]
In [12]: lr
Out[12]:
['00100001',
'01110011',
'01110101',
'00100000',
'01100100',
'01101110',
'01110101',
'01101111',
'01110010',
'01100001',
'00100000',
'01110011',
'01100101',
'01110100',
'01111001',
'01100010',
'00100000',
'01100100',
'01101110',
'01100001',
'00100000',
'01110011',
'01110100',
'01101001',
'01000010']
# Преобразуем в привычную степень 10
In [13]: lrh = [int(c, 2) for c in lr]
In [14]: lrh
Out[14]:
[33,
115,
117,
32,
100,
110,
117,
111,
114,
97,
32,
115,
101,
116,
121,
98,
32,
100,
110,
97,
32,
115,
116,
105,
66]
# Преобразуем числа в ASCII символы
In [15]: [chr(n) for n in lrh]
Out[15]:
['!',
's',
'u',
' ',
'd',
'n',
'u',
'o',
'r',
'a',
' ',
's',
'e',
't',
'y',
'b',
' ',
'd',
'n',
'a',
' ',
's',
't',
'i',
'B']
# И последний штрих
# Перевернем само направление текста и сделаем обратно строку из списка.
In [16]: ''.join([chr(n) for n in lrh][::-1])
Out[16]: 'Bits and bytes around us!'
Что ж, "а ларчик просто открывался". Действительно существуют разные нотации и интерпретации как читать, все как в мире человеков.
Послесловие
Первые впечатления
Круто, долгожданное решение, я смог, пусть это всего лишь и тест на дурака, но тем не менее! Было интересно мысленно вернуться в далекие времена, когда я изучал эти темы: кодировка, криптография, little / big endian, и освежить знания.
Главное
Здорово, что Яндекс не боится экспериментировать и сориентировался в ситуации. Это мероприятие выглядит действительно крутым и смелым шагом. Я рад, что у нас есть компании, толкающие индустрию вперед!
Несмотря на критику в следующем параграфе, я все равно считаю этот шаг и событие сугубо положительным. Имплементация может хромать, но стратегия на 100% верная.
Критика
И это называется "расшифровать"?! Стыд и позор не знать терминологии. Публичную задачу можно было сформировать корректно, бррр, до сих пор пробирает. Это не шифр, а максимум стеганография. Правильный термин был бы "преобразовать" или "конвертировать". Если эти слова раскрывают слишком много, можно использовать общее описание: "разобраться" или "исправить" (хотя последнее также не совсем корректно, т.к. сообщение не "сломано").
Сложно представить, каким образом эта задача и её цепочка решений может помочь мне и остальным разработчикам в обычной работе. К сожалению, я отдаю себе отчёт, что практическая польза от этой задачи близка к нулю и объективно это выкинутое время. Лично я изучал Little / Big endian один раз в качестве "любопытно знать" и с тех пор мне это пригодилось 0 раз вплоть до этого дня (чудо, что я вообще вспомнил). Между разработкой и Little / Big endian лежит очень много уровней абстракции. Я не буду оценивать ценность этой темы, просто скажу, что для разработчика существует минимум 100 более приоритетных вещей.
Такая задача хорошо подойдет как единый знаменатель для всех направлений: сетевики, devops, разработчики ядра, hardware и т.д. (хотя у последних все равно будет несомненное преимущество).
Вывод: за задачу и ее формулировку жирный минус.
Критикуешь?! - Предложи своё!
Моё: чтобы ответить на вопрос, нужно абстрагироваться от лишнего и ответить себе на вопрос: Какого разработчика Я хочет найти и какой аспект разработки отражает эту суть? Для меня разработка ассоциируется с тремя словами, возможно у Яндекса по-другому: архитектура, скорость, open source фреймворки + готовые решения.
Это задает направление, в котором нужно мыслить. Я не буду навязывать конкретное решение, только дам свой пример: варианты кода с нарушением ООП / SOLID / code style (pep, black, eslint и т.д.).
Хинт для менеджеров и HR:
По моему опыту, оценка написанного кода - это самый эффективный и простой способ оценки кандидата. Джун найдет часть ошибок, мидл - все, а сеньор - даже те, которые вы сами не нашли. Минимум времени и усилий от всех участников, все ошибки известны заранее, оценки формализованы и объективны.
Возможно, у Яндекса были строгие ограничения на размер текста, поле ввода, сроки и т.д., однако даже при таких условиях я сомневаюсь в выборе задачи.
Бонус, как можно сделать лучше
(Особенно актуально, т.к. я в поиске).
Гипотеза:
Что, если все ИЗВЕСТНЫЕ хорошие кандидаты уже наняты? Рынок крутит по кругу заранее известный пулл разработчиков, это отражает термин "нехватка кадров". Возможно, HR стоит взглянуть под новым углом на пулл кадров. Если применять одинаковые метрики на входе - странно ожидать новый результат на выходе.
Подробный список фреймворков и инструментов + примеры задач.
Описание: PostgreSQL, FastAPI, Redis, ClickHouse, Linux, разработка новых фич, API интеграции, код ревью и т.д. хорошо сужает область поиска, но она все еще слишком поверхностна. Убрать компанию из заголовка, и все вакансии станут одинаковыми. Проанализируйте, что делают ваши разработчики, вычлените общее и опубликуйте вместе с вакансией. Идеально - ссылки или скриншоты из задачи из трекера.Возможность проявить свои уникальные качества и мою ветку прокачки скилов.
Большинство метрик идут по статичным характеристикам: опыт, алгоритмы, БД, ООП. Это неплохо, но можно лучше. Такой подход не позволяет проявить, как быстро кандидат может разобраться в документации, фиксить исключения, интегрировать API, использовать свои 100+500 хоткеев и т.д., а это, между прочим, 60% работы, и все это не попадает в перечисленные метрики выше.Задержки и бюрократия.
Здесь все понятно, найм - это игра в испорченный телефон между отделом разработки, HR, менеджментом и т.д., любой позитивный запал ломается об эти скалы. Лично меня всегда тянет сделать пару PR, а не читать однотипные вакансии и делать холодную рассылку резюме. По крайней мере, мой код хоть немного, но точно сделает мир лучше. Я думаю, так мыслит большинство проактивных разработчиков.
В общем, проблемы найма - это большая тема для отдельной статьи, если понравится - я опубликую свои мысли и нестандартный опыт на этот счет.
Помните, мир разработки - это непаханное поле, здесь задачи найдутся всем, от джунов до сеньоров!
Прямо сейчас можно сделать PR в:
FastAPI template - самый популярный проект для развертки нового сервиса на самом современном Python веб-фреймворке.
Heroes of Might and Magic III - open source версия знаменитой игры.
Python Telegram Bot - самый популярный фреймворк для телеграм-ботов на Python.
Категория неначатых проектов из-за здравого пессимизма мейнтейнеров.
Категория устаревших проектов из-за здравого оптимизма мейнтейнеров.
И таких проектов в прямом смысле слова тысячи. Поэтому стагнация или регрессия в IT - это исключительно бизнес-феномен, сам мир разработки открыт для всех желающих!
