
Доброго времени суток.
В этой статье я хочу сделать обзор одного из главных нововведений в Visual Studio 2010, а именно — функционального языка программирования F#.
Рассматривать синтаксис и потенциал F# мы будем на примере создания своего собственного интерпретатора для придуманного нами языка программирования (Ведь рассказвать о чем-то всегда интереснее на примерах).
Опишем задачу, которую мы собираемся решать, а именно — синтаксис нашего языка программирования, он будет достаточно прост, вот приблизительно то, что мы хотим видеть:
function Summ(a,b,c)
{
val d = a+b+c;
print d;
return d;
}
function MyEvaluations(a,b,c)
{
val in = Summ(a,b,1);
val out = Summ(b,c,1);
val d = in*out;
return d;
}
function Program()
{
print(MyEvaluations(1,2,3));
}
Итак, у нас есть поддержка функций с передачей параметров и возвращаемым значением, печать, арифметические операции и локальные переменные.
Начнем это реализовывать, для этого нам понадобится установить дополнительный пакет F# Power Pack отсюда
Лексика
Теперь создаём новый проект F# из онлайн шаблона F# Parsed Language Starter и очищаем все файлы кроме lexer.fslДля того, чтобы разобраться с содержимым этого файла, давайте для начала разберём наш язык по косточкам. Под словом «лексема», будем понимать минимальные кирпичики из которых состоит язык программирования.
К лексемам относятся ключевые слова, скобки, запятые, имена, в общем всё то, из чего состоит исходный код программы. На уровне лексем у нас не существует функций и прочих логических единиц.
Откроем файл lexer.fsl
В F# аналогом namespace служит ключевое слово module, аналогом using — ключевое слово open, поэтому первое, что мы сейчас напишем — будет определение той области, в которой мы работаем:
{
module Lexer
open System
open Parser
open Microsoft.FSharp.Text.Lexing
let lexeme lexbuf =
LexBuffer<char>.LexemeString lexbuf
}
let digit = ['0'-'9']
let whitespace = [' ' '\t' ]
let newline = ('\n' | '\r' '\n')
let symbol = ['a'-'z''A'-'Z']
Переменные в F# объявляются с помощью ключевого слова let, также, мы можем здесь использовать регулярные выражения.
Итак, удаляем весь код ниже строки
rule tokenize = parse
которая является служебным маркером, обозначающим что ниже пойдёт описание нашего языка, и вставляем следующий код:
| whitespace { tokenize lexbuf }
| newline { tokenize lexbuf }
// Operators
| "+" { PLUS }
| "-" { MINUS }
| "*" { MULTIPLE }
| "/" { DIVIDE }
| "=" { EQUALS }
// Misc
| "(" { LPAREN }
| ")" { RPAREN }
| "," { COMMA }
| ";" { ENDOFLINE }
| "{" { BEGIN }
| "}" { END }
// Keywords
| "function" { FUNCTIONKW }
| "return" { RETURN }
| "var" { VARIABLE }
Так как данный файл будет обрабатываться дополнительными средствами библиотеки PowerPack, то непосредственно F# код в этом файле окружен первым блоком фигурных скобок.
Это самая простая часть, здесь мы просто пишем строковые константы или регулярные выражения, которые присутствуют в нашем языке, у нас их будет немного: арифметические операторы, скобки, три ключевых слова, запятая и точка с запятой.
Далее при помощи регулярных выражений мы обучим наш интерпретатор «вытаскивать» цифры и имена переменных/функций из кода. По сути на этом этапе мы превратили наш plain text код в такую последовательность объектов:
FUNCTIONKEYWORD NAME LPAREN NAME COMMA NAME COMMA NAME RPAREN
BEGIN
VARIABLE NAME EQUALS NAME PLUS NAME PLUS NAME ENDOFLINE
…..
Каждый объект имеет свой тип, который указан в примере выше.
Однако объекты DECIMAL и NAME должны иметь ещё и значение.
Для этого напишем следующие строки:
| digit+('.'digit+)? { DECIMAL(Double.Parse(lexeme lexbuf)) }
| symbol+ { VARNAME(String.Copy(lexeme lexbuf)) }
| eof { EOF }
Можно трактовать это как вызов конструктора. Всё что находится в фигурных скобках — это наши типы данных. После обработки текст программы будет представлять собой последовательность объектов этих типов.
eof — служебная лексема, сигнализирующая о конце разбираемого текста
Синтаксический разбор
Чтобы было немного понятнее откуда взялись типы данных, и почему NAME имеет строковое содержимое, а DECIMAL числовое — откроем файл Parser.fsy и вставим в него следующий код:%{
open ParserLibrary
open System
%}
%start start
%token <Double> DECIMAL
%token PLUS MINUS MULTIPLE DIVIDE
%token LPAREN RPAREN
%token FUNCTIONKW RETURN VARIABLE
%token BEGIN END
%token EQUALS
%token <String> VARNAME
%token ENDOFLINE
%token COMMA
%token EOF
%type <WholeProgram> start
%%
Здесь указаны все наши типы данных, если наш тип должен иметь значение — то тип этого значения пишется в угловых скобках.
start — это так называемая «аксиома грамматики», то, что мы будем пытаться «собрать» при интерпретации нашего кода.
Грамматика записывается в следующей форме:
ТипДанных: | Первый возможный набор состовляющих | Второй возможный набор состовляющих | … | …
Первая строка будет выглядеть так:
start: | WholeProgram
Это говорит о том, что цель нашего разбора — получить «целую программу»
«Целая программа» в ближайшем рассмотрении у нас представляет собой просто список функций
Поэтому запишем этот факт:
WholeProgram:
| FunctionDescription
| WholeProgram FunctionDescription
Стоит отметить достаточно необычный вид формирования списков в данной форме записи, дело в том, что количество «составных частей» для каждого элемента должно быть фиксированным, и чтобы не ограничивать количество возможных функций в нашем языке — мы идём на такую уловку. Когда система находит первую функцию — она создаёт из неё объект WholeProgram, когда она видит вторую функцию — у нас рядом оказываются WholeProgram (от первой фунции) и FunctionDescription (вторая функция), и система сворачивает оба этих объекта в новый WholeProgram, снимая таким образом ограничение на общее количество функций в тексте программы.
Если проиллюстрировать грамматику, мы получим примерно следующую картинку:

Запишем теперь что же представляет из себя функция:
FunctionDescription:
| FunctionKeyWord FunctionTitle Begin End
| FunctionKeyWord FunctionTitle Begin OperatorsList End
Мы могли бы ограничиться только вторым вариантом представления, но в таком случае пустые функции приводили бы к ошибке в работе интерпретатора, как видно из кода, функция состоит из ключевого слова, заголовка, фигурных скобок и, возможно, набора операторов внутри функции — её тела.
Заголовок функции состоит из её имени, круглых скобок и, возможно, списка параметров:
FunctionTitle:
| VarName LParen RParen // Функция без параметров
| VarName LParen VarName RParen // Функция с одним параметром. Так как параметры разделяются запятыми, то нам проще будет вынести вариант без запятых отдельно
| VarName LParen VarName AdditionParametersList RParen // Функция с множеством параметров
Объекты AdditionParametersList и OperatorsList являются списками и поэтому определяются аналогично WholeProgram:
OperatorsList:
| Operator
| OperatorsList Operator
AdditionParametersList:
| Comma VarName
| AdditionParametersList Comma VarName
Оператор представляет собой одну строку нашей программы внутри тела функции, пусть в нашем языке будет возможно два варианта:
Operator:
| VaribaleKeyWord VarName Equals Expression EndOfLine
| ReturnKeyWord Expression EndOfLine
Что соответствует например строкам:
val d = in*out;
return d;
Изначально у нас было определено 4 арифметические операции, учтем что умножение и деление являются более приоритетными операциями чем сложение и вычитание:
Expression:
| Expression PLUS HighExpression
| Expression MINUS HighExpression
| HighExpression // Так как в определении "Operator"'а у нас фигурирует только Expresson, необходимо учесть возможность отсутствия сложения и вычитания и "провалиться" на уровень ниже.
HighExpression:
| HighExpression MULTIPLY Operand
| HighExpression DIVIDE Operand
| Operand // Аналогично, в случае отсутствия умножения и деления - работаем сразу с переменными.
Такое разделение позволит разобрать выражение 2+2*2 как Expression Plus HighExpression, а затем развернуть HighExpression в отдельное поддерево: Expression Plus (HighExpression MULTIPLY Operand), что позволит корректно обработать приоритет операций.
На нижнем уровне, операндом у нас может быть или число, имя существующей переменной, имя функции, или (если мы хотим) — выражение в скобках.
Operand:
| DECIMAL
| VarName
| FunctionTitle
| LParen Expression RParen // Возвращаясь к Expression мы создаём своего вида рекурсию, позволяющую обрабатывать неограниченную вложенность скобок.
Вернёмся к нашему F# (теперь уже в чистом виде) и рассмотрим такую возможность как конструкторы с сопоставлением по образцу, а именно — опишем только что использовавшиеся типы данных
namespace ParserLibrary
open System
type Operator =
| VarOperator of string * Expression
| ReturnOperator of Expression
and Operand =
| DECIMALOP of Double
| SUBEXPROP of Expression
| VARNAMEOP of String
| FUNCOP of FunctionTitle
and HighExpression =
| MULTIPLY of HighExpression * Operand
| DIVIDEOP of HighExpression * Operand
| VAR of Operand
and Expression =
| SUMM of Expression * HighExpression
| SUB of Expression * HighExpression
| HighExpression of HighExpression
and FunctionTitle = String * List<String>
and FunctionDescription = FunctionTitle * OperatorsList
and OperatorsList = List<Operator>
and AdditionParamsList = List<String>
and WholeProgram = List<FunctionDescription>
По сути мы объявили 9 объектов, каждый из которых имеет несколько именованных конструкторов с разными параметрами (на самом деле такой набор конструкторов подобен union в C++)
Отметим, что звёздочка "*" в данном контексте является не умножением, а разделителем параметров, т.е. конструктор с именем VarOperator для типа Operator принимает строку (string) и выражение (expression)
Всё что нам осталось сделать, чтобы завершить первую часть написания нашего интерпретатора — это связать эти типы данных в файле Parser.fsy, для этого напротив каждого условия в фигурных скобках пишем соответствующий конструктор
Выглядеть это будет следующим образом:
start: WholeProgram { $1 }
WholeProgram:
| FunctionDescription { $1 :: [] }
| WholeProgram FunctionDescription { $1 @ ($2 :: []) }
FunctionTitle:
| VARNAME LPAREN RPAREN { $1, [] }
| VARNAME LPAREN VARNAME RPAREN { $1, $3 :: [] }
| VARNAME LPAREN VARNAME AdditionParamsList RPAREN { $1, $3 :: $4 }
AdditionParamsList:
| COMMA VARNAME { $2 :: [] }
| AdditionParamsList COMMA VARNAME { $1 @ ($3 :: []) }
OperatorsList:
| Operator { $1 :: [] }
| OperatorsList Operator { $1 @ ($2 :: []) }
FunctionDescription:
| FUNCTIONKW FunctionTitle BEGIN END { $2, [] }
| FUNCTIONKW FunctionTitle BEGIN OperatorsList END { $2, $4 }
Operator:
| VARIABLE VARNAME EQUALS Expression ENDOFLINE { VarOperator($2, $4) }
| RETURN Expression ENDOFLINE { ReturnOperator($2) }
Expression:
| Expression PLUS HighExpression { SUMM($1, $3) }
| Expression MINUS HighExpression { SUB($1, $3) }
| HighExpression { HighExpression $1 }
HighExpression:
| HighExpression MULTIPLE Operand { MULTIPLY($1, $3) }
| HighExpression DIVIDE Operand { DIVIDEOP($1, $3) }
| Operand { VAR $1 }
Operand:
| DECIMAL { DECIMALOP($1) }
| VARNAME { VARNAMEOP($1) }
| FunctionTitle { FUNCOP($1) }
| LPAREN Expression RPAREN { SUBEXPROP($2) }
$1, $2 и т.д. — это номер переменной в условии
На примере этого кода познакомимся с ещё одной замечательной возможностью F# — работой со списками.
Выражение A :: B означает создание и возврат нового списка, основанного на списке B с добавлением в него элемента A
[] — пустой список
Также мы можем задавать списки в коде напрямую или из диапазонов, например:
[1,2,3,4,5] или [1..5]
В таком случае 100 :: [1..5] вернёт нам вот такой список: [100,1,2,3,4,5]
Оператор @ — создание нового списка из объединения двух существующих.
Например: [1..5] @ [6..10] вернёт [1..10]
Заметим, что в случае с выбором по шаблону — мы указываем именованный конструктор, для тех же типов, которые просто являются синонимами каких либо кортежей (FunctionDescription, OperatorsList и т.д.) — мы просто перечисляем параметры в то порядке, как мы объявили в кортеже.
Итак, это всё что нам необходимо для того, чтобы из простого текста F# сделал нам дерево синтаксического разбора, вторая часть — интерпретация.
Открываем файл Program.fs и пишем open для тех пространств имён, которые мы будем использовать:
open System
open Microsoft.FSharp.Text.Lexing
open System.Collections.Generic;
open ParserLibrary
open Lexer
open Parser
Интерпретация
Далее, для интерпретации, нам понадобится иметь список функций (а лучше — словарь), именованные стеки для каждой функции (чтобы небыло конфликтов имён переменных) и имя выполняемой в данной момент функции.Для этого объявим переменны при помощи уже знакомого нам ключевого слова let:
let stack = Dictionary<String, Dictionary<String,Double>>()
let functionsList = Dictionary<String, FunctionDescription>()
let mutable currentFunctionName = "Program";
В классическом функциональном программировании все объекты неизменяемые, это можно увидеть на примере работы со списками, когда мы вместо добавления элемента в список — создаваём новый на основе сущестующих. Это позволяет безболезненно распараллеливать программы, т.к. не нужно иметь сложных синхронизаций на запись.
F# же, будучи функциональным языком, отлично поддерживает всю библиотеку .NET, позволяя работать с изменяемыми объектами. Полного копирования данных в данном случае не происходит, копируются только ссылки на объекты, это позволяет достичь компроммиса по скорости не ломая возможность красиво распараллеливать данные, своеобразный copy on write, если хотите.
Итак, займёмся интерпретацией:
Начнем с разбора выражения
Объявим функцию с выбором по шаблону, let rec – ключевые слова, EvaluateExpression – имя, expression – параметр.
Вспомним, что объявляя типы мы создавали конструкторы с выбором по шаблону, эти же шаблоны мы используем при выборе ветви исполнения функции. К примеру: если передаваемый параметр expression был создан с помощью конструктора SUMM(expression, highExpression), то мы выполняем ветку сложения, и т.д.
Можно заметить, что эта функция практически повторяет созданные ранее конструкторы, приписывая каждому из них определённое действие
let rec evaluateExpression expression =
match expression with
| SUMM (expr, hexpr) -> (evaluateExpression expr) + (evaluateHighExpression hexpr)
| SUB (expr, hexpr) -> (evaluateExpression expr) - (evaluateHighExpression hexpr)
| HighExpression hexpr -> evaluateHighExpression hexpr
and evaluateHighExpression highExpression =
match highExpression with
| MULTIPLY (hexpr, oper) -> (evaluateHighExpression hexpr) * (EvaluateOperand oper)
| DIVIDEOP (hexpr, oper) -> (evaluateHighExpression hexpr) / (EvaluateOperand oper)
| VAR oper -> EvaluateOperand oper
and EvaluateOperand oper =
match oper with
| DECIMALOP x -> x
| VARNAMEOP x -> stack.Item(currentFunctionName).Item(x)
| FUNCOP x -> evaluateFunction x
| SUBEXPROP x -> evaluateExpression x
Так как мы ввели поддержку переменных и функций, то нам необходимо написать обработчики на этот случай. В случае переменных всё более-менее просто, мы идём в словарь, содержащий значения переменных текущей функции и получаем значение по имени переменной (помним, что VARNAMEOP проассоциирован с типом String)
В случае попадания на функцию – нам необходимо скопировать параметры из вызывающей функции в соответствии с заголовком функции и начать её выполнение.
Для этого допишем следующий код:
and evaluateFunction(f:FunctionTitle) =
let caller = currentFunctionName;
let newStack = Dictionary<String, Double>()
let realParams = functionsList.Item (f |> GetFunctionName) |> GetFormalParamsListDecription
let formalParams = GetFormalParamsListTitle(f)
ignore <| List.mapi2 (fun i x y -> newStack.Add(x, stack.Item(caller).Item(y))) realParams formalParams
currentFunctionName <- GetFunctionName(f)
stack.Add(currentFunctionName, newStack)
let operatorsList = functionsList.Item(GetFunctionName f) |> GetOperatorsList
let result = RunFunction operatorsList
ignore <| stack.Remove(currentFunctionName)
currentFunctionName <- caller
result
// Часть вызываемых здесь функций будет определена чуть позже
Это тоже функция, но уже не с выбором по шаблону, а в более привычном для нас виде.
Разберём оператор конвеера (pipeline) “|>”, по сути – это более понятный способ вызова цепочек функций, если раньше нам нужно было писать OuterFunction(InnerFunction(Validate(data))), то в F# можно «развернуть» эту цепочку: data |> Validate |> InnerFunction |> OuterFunction
Обе записи приводят к одинаковому результату, однако при использовании оператора “|>” у нас функции применяются слева направо, в случае длинных цепочек – это более удобно.
Особенностью данных функций служит то, что нам не нужно писать return, например функция
test(a) = a*10
вернёт a*10, это отчасти удобно, однако нам надо позаботится о том, чтобы не вернуть какое либо значение «случайно» (к слову, VS подчеркнёт все непреднамеренные возвраты), для этого мы используем метод ignore, который ничего не делает и ничего не возвращает, чтобы все ignore были у нас в начале строки – мы используем обратный конвеерный оператор "<|", он делает тоже самое что и “|>”, только в обратном направлении, теперь функции применяются справа налево.
В случае простого присваивания, чтобы избежать возврата значения вместо «=» используется оператор “<-“
Разберём подробнее строку:
ignore <| List.mapi2 (fun i x y -> newStack.Add(x, stack.Item(caller).Item(y))) realParams formalParams
Класс List содержит набор методов mapi* (для разного количества списков), суть этих методов в том, что они обрабатывают несколько списков (в нашем случае 2) параллельно, передавая в функцию-обработчик номер элемента в обоих списках и сами элементы в предположении что длины списков равны. Метод mapi2 принимает 3 параметра, функцию обработчик и два обрабатываемых списка.
Например в результате выполнения следующего кода:
let firstList = [1..5]
let secondList = [6..10]
ignore <| List.mapi2 (fun i x y -> Console.WriteLine(10*x+y)) firstList secondList
Так как порядок параметров в скобках при вызове функции и при её описании в нашем языке– одинаковый, то мы просто обрабатываем парами элементы из списков вызова и объявления функции.
Ключевое слово fun определяет новую функцию (можно провести аналогию с лямбдами в C#), которая мы будем использовать для обработки списков, наша функция принимает 3 параметра, i – номер текущего элемента в обоих списках, x и y – соответственно элементы из первого и второго списков.
Таким образом здесь мы копируем в наш новый стек переменную из стека вызывающей функции.
После подготовки параметров мы вызываем функцию, запоминаем результат, удаляем словарь(стек) и восстанавливаем имя вызывающей функции.
let result = RunFunction operatorsList
ignore <| stack.Remove(currentFunctionName)
currentFunctionName <- caller
result
Т.к. return писать не нужно, то для возврата значения просто напишем имя переменной, которую мы хотим вернуть.
Теперь напишем метод runFunction:
and RunFunction(o:OperatorsList) =
ignore <| List.map (fun x -> EvaluateOperator x) o
stack.Item(currentFunctionName).Item("return")
Метод List.map производит итерацию по всем элементам списка, затем мы просто возвращаем результирующую переменную из нашего текущего стека.
and EvaluateOperator operator =
match operator with
| VarOperator (name, expr) -> stack.Item(currentFunctionName).Add(name, evaluateExpression expr)
| ReturnOperator expr -> stack.Item(currentFunctionName).Add("return", evaluateExpression expr)
В нашем языке всего 2 типа операторов, это или объявление переменной или возврат значения, в обоих случаях мы вычисляем значение и добавляем в словарь(стек), в случае возврата мы пользуемся тем фактом, что return в нашем языке — ключевое слово и мы можем спокойно использовать его в своих целях, не боясь конфликта с уже объявленной переменной.
Так как мы хотим использовать в нашем языке пару предопределённых функций, для осуществления ввода-вывода, добавим несколько проверок:
and RunFunction(o:OperatorsList) =
if currentFunctionName.Equals "print" then
stack.Item(currentFunctionName).Add("return", 0.0)
Console.WriteLine(stack.Item(currentFunctionName).Item("toPrint").ToString())
if currentFunctionName.Equals "get" then
Console.Write("Input: ");
stack.Item(currentFunctionName).Add("return", Double.Parse(Console.ReadLine()))
if currentFunctionName.Equals "Program" then
stack.Item(currentFunctionName).Add("return", 1.0)
ignore <| List.map (fun x -> EvaluateOperator x) o
stack.Item(currentFunctionName).Item("return")
Мы проверяем имя функции и, в зависимости от результата, выполняем или печать значения переменной, или считываем значение с клавиатуры.
Чтобы не писать в главном методе return – мы определяем спец. переменную ещё до выполнения тела функции.
В F# используются значащие отступы, в частности — для выделения тела блоков if.
Последнее, что нам осталось сделать – определись недостающие функции, которые мы использовали, и написать оболочку, которая будет использовать наш парсер:
let GetFunctionName f = match f with name, foo -> name
let GetFunctionNameDescription f = match f with t, foo -> GetFunctionName t
let GetFormalParamsListTitle t = match t with foo, paramerers -> paramerers
let GetFormalParamsListDecription f = match f with t, foo -> GetFormalParamsListTitle t
let GetOperatorsList f = match f with foo, o -> o
let GetTitle f = match f with t, too -> t
Так как некоторые типы мы объявили просто синонимами, то после слова with не идёт названия конструктора, идёт просто перечисление всех параметров, после стрелки идёт тело функции, в данном случае мы просто пишем имя переменной которую надо вернуть.
Если писать вызов функций без скобок для Вас непривычно, F# позволяет писать код в таком виде:
let GetFunctionName(f) = match f with name, foo -> name
let GetFunctionNameDescription(f) = match f with t, foo -> GetFunctionName(t)
let GetFormalParamsListTitle(t) = match t with foo, paramerers -> paramerers
let GetFormalParamsListDecription(f) = match f with t, foo -> GetFormalParamsListTitle(t)
let GetOperatorsList(f) = match f with foo, o -> o
let GetTitle(f) = match f with t, too -> t
Эти записи абсолютно эквивалентны.
Последние штрихи
И наконец последнее:printfn "H#"
let mutable source = "";
let rec readAndProcess() =
printf ":"
match Console.ReadLine() with
| "quit" -> ()
| "GO" ->
try
printfn "Lexing..."
let lexbuff = LexBuffer<char>.FromString(source)
printfn "Parsing..."
let program = Parser.start Lexer.tokenize lexbuff
ignore <| List.map (fun x -> functionsList.Add(GetFunctionNameDescription(x),x)) program
functionsList.Add("print",(("print", ["toPrint"]), []))
functionsList.Add("get",(("get", []), []))
printfn "Running..."
ignore <| (functionsList.Item("Program") |> GetTitle |> evaluateFunction)
with ex ->
printfn "Unhandled Exception: %s" ex.Message
readAndProcess()
| expr ->
source <- source + expr
readAndProcess()
readAndProcess()
Определяем новую функцию, в которой мы будем пытаться распарсить введенную с клавиатуры строку, если разбор завершился успешно – добавляем все функции из полученного списка (program) в нашу переменную functionsList.
Для вызова функции в начале работы программы просто пишем её имя без отступов в конце файла.
Так как у нас в нашем языке есть две предопределённые функции (get и print) – добавляем их, затем выполняем функцию с именем Program.
Последнее что можно описать в этом примере – это интересный способ конструирования объектов для которых мы не определили конструкторы через match
and FunctionTitle = String * List<String>
and FunctionDescription = FunctionTitle * OperatorsList
and OperatorsList = List<Operator>
and AdditionParamsList = List<String>
and WholeProgram = List<FunctionDescription>
Если мы ожидаем объект FunctionTitle, для его создания достаточно заключить его параметры (String и <ListString>) в круглые скобки, указывать тип данных нет необходимости.
("print",(("print", ["toPrint"]), []))
Запуск
Чтож, запустим наш интерпретатор: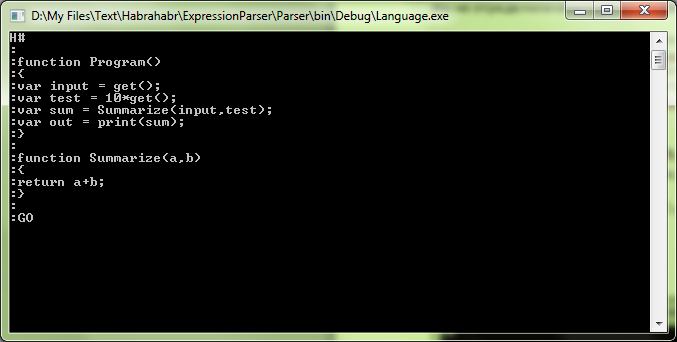
После нажатия Enter мы увидим приглашение ввести значение переменной:
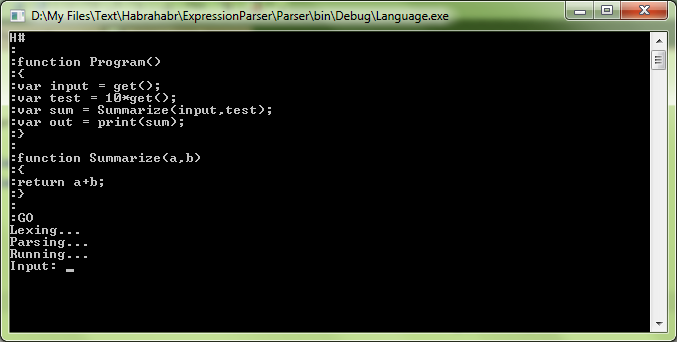
И после этого:
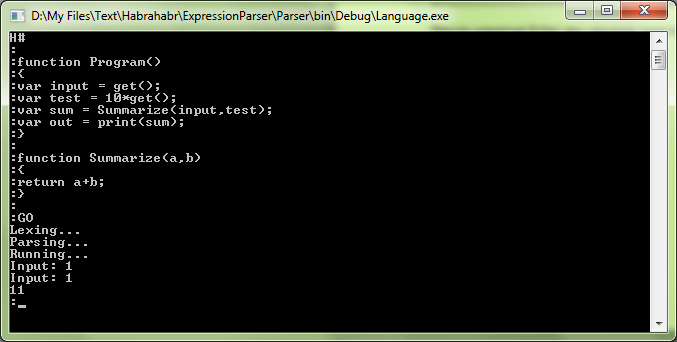
Чтож, программа действительно работает.
Исходный код с бинарниками можно скачать здесь.
Если теперь ещё раз взглянуть на код на F#, то можно увидеть, что мы написали минимум, просто описывающий то, что мы хотим сделать, это позволило написать свой интерпретатор и уложиться всего в ~200 строк кода, F# позволяет избавиться от рутинной работы по написанию кода, который не отвечает на вопрос «что», а отвечает на вопрос «как». Безусловно, программирование на этом языке по началу кажется трудным, но в ряде случаев оно того стоит, так как даёт возможность писать гибкий код, который легко поддерживать.
Спасибо за внимание.
