
Мы в 1995-м
Мой коллега как-то срочно повёз в Мурманск блоки питания – там завод встал 30 декабря, ни одна служба доставки не работала. Да и с проводником или лётчиком не передашь. Плюс железа такого ни у кого уже лет 5 нет. Нашёл чудом через знакомых, загрузил в машину, сам поехал. По дороге машина сломалась, он её в -25 прямо под сильным ветром чинил. Приехал, они блоки в стойку вставили – так они прямо там сразу погорели.
В общем, берите чай и заходите внутрь слушать тёплые добрые истории. У нас на поддержке сотни заказчиков, включая самые крупные компании в стране. Случалось всё что угодно. Буду потихоньку рассказывать, как мы начинали, и что делаем сейчас.
Вступление
Сразу скажу, что рассказывать я буду именно и только про сервис «тяжелого» дорогостоящего оборудования: RISC-серверы IBM, HP и SUN (который теперь Oracle), системы хранения для больших данных EMC, IBM, Hitachi, коммутаторы уровня ядра CISCO, Nortel, HPN и т.д. От таких систем зависит, например, будут ли работать колл-центры банков, сможем ли мы снять деньги в банкомате, зарегистрироваться на рейс или дозвониться до нужного нам человека в нужное время.
Тараканы в домашнем ПК всем и так понятны. А вот то, что они живут и в серверах – это немного интереснее, и ответственность системного инженера таких систем и оборудования значительно выше. Заказчиков по понятным причинам называть я не имею права, но кто в курсе, много кого узнает. В половине случаев – ошибочно, потому что одни и те же истории имеют свойство повторяться. Да, и ещё, где совсем критичные баги шли, я поменял некоторые второстепенные детали по просьбе безопасников. Но поехали.
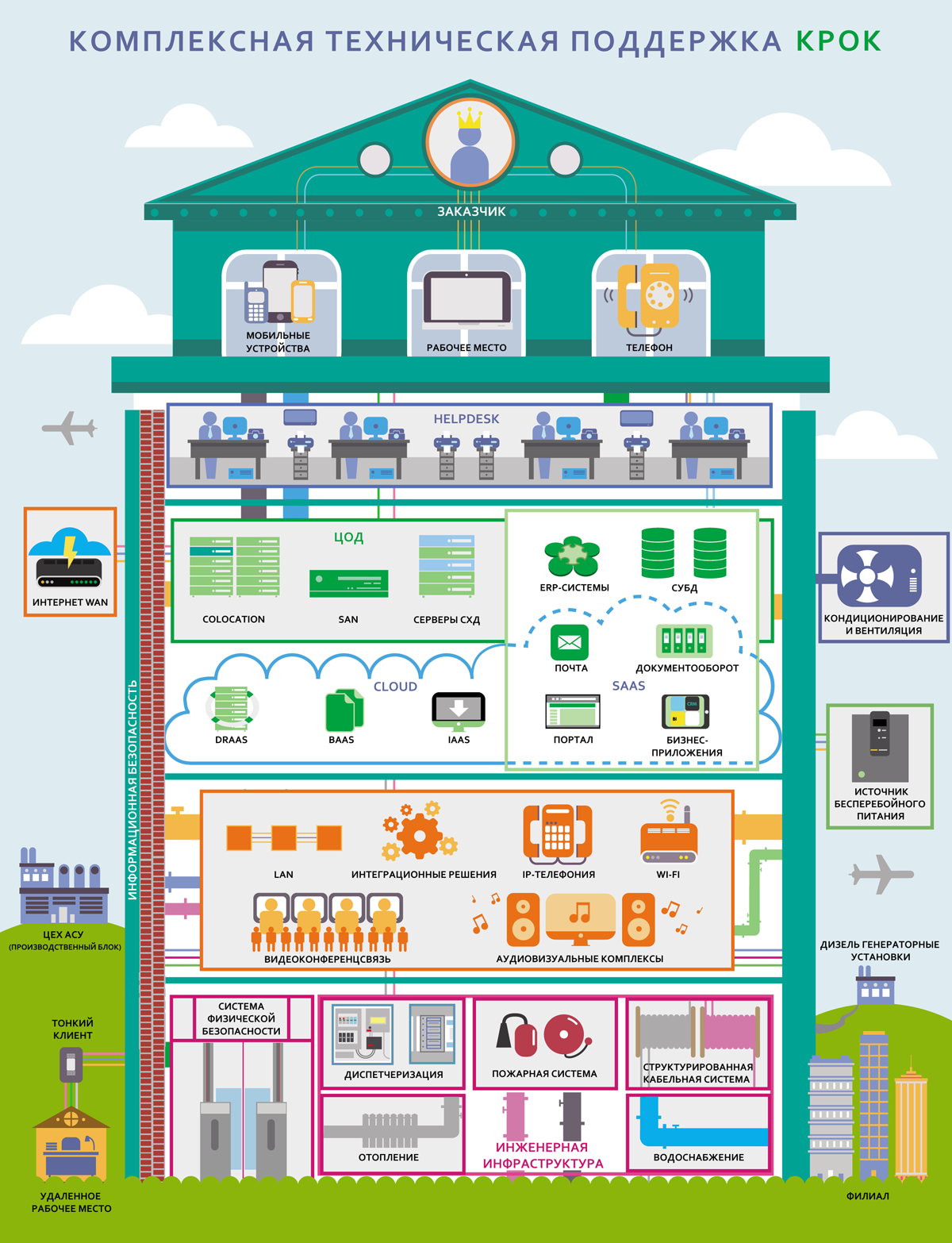
Вот этим мы занимаемся
Моя самая запомнившаяся история такая. Настроили мы как-то кластер в одном банке. И базу данных на нём. Всё это прекрасно работает по отдельности, но стоит запустить реальный запрос – он не проходит. Пинги при этом ходят нормально. Из другого места пробуем – всё хорошо. Несколько дней смотрели, стали уже по пакетам разбирать. В итоге нашли в этой подсети с пользователями сетевой принтер, который имел небольшой баг. И вот он как мина замедленного действия всю свою долгую трудовую жизнь ждал звёздного часа. И дождался. В итоге он ловил конкретно наши пакеты. Вынули его из розетки – всё заработало как надо.
Через год история с Убийцей Пакетов повторилась. Уже у другого заказчика. Они там бились головой об стену пару дней, потом нас позвали разобраться, что не так. Смотрим — по документации все сетевые узлы одинаковые, по факту же одна из коробочек по цвету отличалась. Вынули – трафик сразу пошел. Потом выяснилось, что это был неоригинальный модуль, который поставили при ремонте. И прошивка у него другая. Мы его просто заменили на нормальный.
Как всё развивалось?
Сначала было вот так. В 90-х, чтобы собрать компьютер, нужно было ещё собрать всё по отдельности работающее на одной материнской плате – и вот здесь вас могли ждать любые сюрпризы. Совместимость надо было проверить, да и допуски у железа были такие, что две одинаковые вроде железки могли совершенно по-разному работать.

Это мы в 2002-2003 тестируем компьютеры.
Сначала техподдержка была своего рода работой на грани микроэлектроники. Потом начали вставать проблемы совместимости железа, а неполадки решались заменой целых модулей. Теперь главная работа в администрировании, потому что всё очень сильно усложняется, и главные инциденты связаны чаще всего с софтом.
Или вот приезжает оригинальная железка и оригинальный же блок питания к ней. Но почему-то последний в отсек не влезает хоть ты тресни. Не может быть такого, но с реальностью не поспоришь. Запускать надо уже утром, поэтому можно напильником чуть подточить один из углов БП – и он запихивается как надо. Сделаете так?
Да? А вдруг вы что-то не поняли, и сейчас потеряете гарантию ценой в сотни тысяч долларов? Или, с другой стороны, вдруг вендор ошибся сам? Сейчас вы ему уголок отрежете – а завтра сервис-инженеры поставщика за задницу возьмут – «кто разрешал так поступать?».
Или вот сервер приезжает, одного драйвера нет. В Рунете дистрибутив лежит, но левый. Будете брать или неделю подождёте? Если возьмёте – то будете пользоваться несертифицированными драйверами, что в случае чего может стать серьёзной проблемой. Если нет – сорвёте дедлайн. У меня, кстати, был такой случай: производитель железа выпустил новый драйвер с патчем для одной экзотической ситуации, а поставщик его в пакет не включил – у них программа тестов на пару месяцев. Я написал официальное письмо с вопросом, можно ли ставить чтобы хоть как-то заработало. К счастью, пошли навстречу, подтвердили, что можно, конечно, только до конца тестов у них не могут обещать, что внезапных перезагрузок не будет.
Местами нас даже ругают: «здесь бы даже мой сосед починил, вон, только предохранитель заменить». Мы тоже это знаем, только корпус без сертифицированного инженера вскрывать нельзя, гарантия. Но с точки зрения пользователя – мы злые нехорошие люди, которые решили, что буква инструкции важнее всего в мире.
Кстати, до недавнего времени один специалист паял. Хоть и в большинстве случаев надо целыми блоками менять, паял. Иногда были вентиляторы, когда нельзя, например, железку у вендора найти. Или есть где-то на заводе устройство, которому уже лет 15, и оно там очень нужно. Ломается, а запчастей не найти, ни платных, ни бесплатных, никаких вообще. Приносят к нему, он смотрит, прозванивает. Ну чего бы не спаять? Взял – спаял. Теперь нету этой романтики, да и вендоры очень щепетильно относятся ко всему, что не замена модуля.
Сегодня ремонт железа выглядит так: на стойке загорается светодиод напротив сбойного модуля, приходит SMS от мониторинга, ты берёшь модуль на складе (а обычно он есть – это как раз наша работа), вытаскиваешь битый и ставишь новый. Всё, ремонт окончен.
А вот 10 лет назад ещё запомнившаяся история была. Звонит мне в 2 ночи инженер, и говорит:
— Ой, заказчик звонил, у них там что-то с локальной сетью.
— А чего?
— Я не знаю (он студент был, стажер наш, еще не все знал и понимал).
— У нас сервисный контракт с ними есть?
— Нет, нету контракта.
Звоню коллеге, спрашиваю, что делать — помогать или нет? Он говорит:
— Да ты что! Там к утру всех поувольняют, у них как раз сейчас время отчетов. В общем, если мы можем, давай поможем.
Звоню обратно инженеру, рассказываю что и как. Ну, в общем, «секс по телефону» — разбираемся, ищем нужные модули, проверяем, что там есть память, софт, всё это собираем. Заказчик всё понял, очень обрадовался, что ему хоть кто-то помогает, прислал машину. «Встречайте молодого человек в очках, в кислотном свитере с разводами, берцы, штаны как у Битлов, волосы дыбом зачёсаны, рядом наш охранник… видите такого?». Нашли. Увидели, привезли на место, всё поменяли, завелось.
Утром коллега приходит, говорит — «Вот, они мне с утра отдали подписанные контракты, я их там не мог больше месяца подписать, а с утра пришел, а они лежат». Оказалось, мы были не первыми, кому они позвонили, но единственными, кто к ним вообще приехал. Тогда это подвиг был, а сейчас в SLA заложено – туда-то бежать, то-то делать.
Ещё сейчас у нас для работы на микроуровне вместо паяльника декомпилятор. Вот пример. В конце каждого месяца падал один колл-центр. За время падения могло пропускаться доо 3-4 тысяч звонков. Начали разбираться, пару багов нашли, но туда или нет – непонятно. Вендор всё железо проверил, тоже чисто. Но нет, в следующем месяце колл-центр снова упал, начали уже грешить на сервер виртуализации, поменяли на физический, оказалось снова не то. А если и в следующем месяце опять упадёт – убытки будут огромные. Пришлось декомпилировать смежные системы. Оказалось, в одном месте был неверный таймаут, поменяли. Все заработало. Но так, кстати, декомпилировать тоже не всегда можно, на всё нужно разрешение.
Иногда приходится реверс-инженирить железо. Бывает, что в старую систему надо воткнуть новый компонент, а управляющего софта нет: надо пытаться понять протокол, дописать функционал. Или же, наоборот, к старому оборудованию надо новую железку. Был вот случай, когда на одном заводе от лазерного станка программатор на перфокартах украли (по ошибке, думали сам станок забирают). Всё же просто – надо понять, что на вход подавать вместо перфокарты, и будет опять работать. Реверс-инжиниринг во всей красе.
Или бывает, что выходит новое железо, скорости меняются, тайминги плывут. То что было почти константами, на новом оборудовании может и не так вычисляться. И где проблема – непонятно, может, железо сырое, может, софт с багами, а, может, где-то на стыке в почти случайной ситуации накапливается ошибка.
Что ещё поменялось?
Ну, наверное, стало больше профилактики. Обычно поломка – это не только прямые убытки, но и репутационные риски. Например, представьте, что банкоматы одного из банков на сутки вылетают из-за аварии в ЦОДе. Потери огромные. Соответственно, все критические системы сами диагностируются и по возможности затачиваются под замену до выхода из строя. Как флеш-диски в серверных хранилищах – точно знают свой момент отказа.
Или вот раньше мы по стране ездили, а сейчас много чего стало администрироваться удалённо. Но всё равно мы и в Южно-Сахалинск срочно вылетали, и в Якутии на оленях в санях до железа ездили.
Из старых историй – один раз приезжаем смотреть железо заказчика, где критическая почта тоссится, а там мыши в контуре питания поселились. Им там тепло, вкусно – изоляцию жрут. Тараканов тоже часто встречали. Сервера в тазиках видели (чтобы водой с пола не залило). Кстати, мелкая живность зимой в серверные заводов и крупных складов так и бежит. Перегрызут что-нибудь мелкое, глюки пойдут непонятные, а продиагностировать можно только по месту. Или, лучше, мелкие зверьки выступают в роли проводников. Не очень хороших, но проводников. Отсюда и трудно воспроизводимые проблемы. Тараканы иногда изображают такие спонтанные плавкие предохранители.
Ещё появилось много новых сервисов. Раньше просто «торговали телами» — отправляли выездных админов. Сейчас у нас есть круглосуточная консалтинг, горячая линия, выделенные сервис-инженеры (это парни, которые, как пожарные, всё время ждут срочного выезда), склады запчастей под конкретные объекты, «детективы» (расследуют инциденты), есть плановые замены железа, куча обязанностей с обновлением ПО, сложное управление базами данных, детальная отчётность, финпланирование, документирование, мониторинг, аудиты, инвентаризации, тестовые стенды для нового железа, аренда железа для горячих замен и так далее. Мы же помогаем переезжать, и мы же «поднимали» и обучали десятки технических команд в крупных компаниях.
Что заказчику важно?
Когда мы начинали – чтобы хоть кто-то что-то сделал. Сейчас — качество и скорость. Заказчики становятся требовательны. Если раньше приходил бородатый дядька, говорящий на непонятном языке, к нему с пониманием относились. Потому что другого нет. А сейчас всегда должен быть человек, который понимает процесс в целом – например, если встаёт завод, надо чтобы он быстро смог финансовому директору нарисовать меры исправления ситуации или назвать то, что может ремонт ускорить. И ещё потом надо объяснить, что это было, почему, есть ли шансы, что повториться. И кому оторвать руки, чтобы больше не случилось.
Также изменятся ситуация у самих вендоров, которые стремятся соответствовать все более высоким стандартам обслуживания. Например, у Cisco организована замена вышедшего из строя оборудования в течение 4х часов не только в Москве, но и в других регионах. При этом специалисты вендора также работают 24х7.
Поэтому, кстати, часто хорошая поддержка начинается с написания аварийного плана. Есть специально обученные параноики, которые находят самые вероятные или опасные места отказов, мы их резервируем. Что-то не так – переключаем на резервный ЦОД, например, срочно едем разбираться. Планы, кстати, многоуровневые. Например, приезжает по обычному плану запчасть, а её при разгрузке роняют – что делать? Вскрывают на месте конверт «совсем плохо» — там написано, что делать, если план А сорвался.
Где плана нет, нашим коллегам сложно. У нас как у внешней компании финансовая ответственность, а вот на штатного сисадмина ещё психологическое давление часто очень сильное. «У на все не работает, все сломалось, мы тебя уволим» и так далее. Мало того что проблема, так все кричат, а он в этот момент должен принимать какие-то правильные решения, грамотные. Это потом, через час, можно будет коньяк из-под фальшпола доставать. А сейчас 30 секунд на то чтобы рубильник дёрнуть или кнопку нажать – и ущерб если что, каких-нибудь пару миллионов долларов.
Или вот совсем типичная ситуация для наших дней. К вам приезжает новая железка. Свеженькая, в здоровенной такой упаковке с китайского завода. Вы прогоняете тесты, затем аккуратно ночью включаете её в боевую конфигурацию. Она отлично работает 20 минут, а потом начинает непоправимо глючить. Вы чертыхаетесь, останавливаете сервис на 10 минут, но успеваете убрать её из системы без потерь. Что случилось? Да чёрт его знает. Производитель пару месяцев тестировал готовое решение под нагрузкой, испытывал разные ситуации, отдавал в реальные компании – разве что детей за машину не пускал. И программа была очень обширная. И тут – бац! – всё останавливается именно у вас. Американцы находят баг. Китайцы на коленке собирают патч, вы его накатываете. И тут же начинают сыпаться неполадки со всех сторон там, где всё уже работало. Откат назад ничего не даёт. Вы, что называется, конкретно встреваете.
Почему? Потому что софт плюс железо – это очень сложная штука. Вот взять новый Airbus 370, например. Это такой здоровенный самолёт с кучей подсистем. Там всё задублировано, надёжно, критические узлы работают чуть ли не от удара железкой по другой железке. Перед каждым полётом он проверяется. Представили? Это очень сложная конструкция, в которой есть и программная и аппаратная части, которые разрабатываются десятки лет. Баги там стоят сотни жизней, и все части самолета реально хорошо тестируют. Но баги случаются. Программные пакеты уровня ОС могут быть куда сложнее, чем такой объект.
Теперь посмотрим на любую новую железку или программно-аппаратный комплекс, который внедряется где-то. В любом случае всё это придётся доводить до ума, поддерживать, проверять, обслуживать. В итоге появляются специальные люди, такие своего рода шаманы – знают куда ударить. Это как раз мы.
Важно диагностировать очень быстро. Время простоя часто на секунды считают, и поэтому опыт тут очень важен. Часами гонять тесты просто нет времени. Надо знать тысячи ситуаций от сотен заказчиков, чтобы приехать на место и сразу смотреть куда надо. Это, кстати, ещё одна причина, почему нас считают шаманами. Как Фейнман – приезжаем, тыкаем, все удивляются. Только он наугад в схему показывал, а мы знаем. На некоторых особо критичных объектах у нас в SLA прописано 15 минут на решение проблемы с момента прибытия специалиста, например. Или 30 минут от регистрации инцидента. Где важно? Да, пожалуйста – сбой у сотового оператора, проблемы у банка и так далее. Понятно, что всё несколько раз зарезервировано, но случается всякое.
Ссылки
- Расследование одной аварии
- Если интересно – вот тут есть список наших услуг. И там же контакты для связи, если надо.
- Документы нашего отдела для свободной закачки и использования: пригодятся любой техподдержке и аутсорсингу.
Вот, пока всё. Думаю, у вас тоже есть куча историй из практики. Расскажите самые интересные в комментариях, пожалуйста.
