Comments 7
Местами у вас значения фраз получаются прямо противоположными из-за ошибок переводчика. Кто ж так переводит?
И на мой взгляд, автор оригинала приводит примеры, где противоречит себе.
Вот здесь:
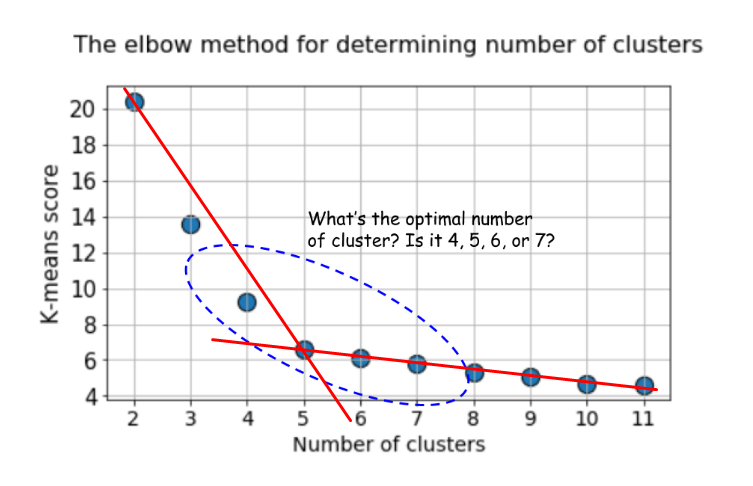
Я вижу хороший локоть (т.е. изменение угла графика) как раз в пяти. А вот в варианте с силуэтом здесь же как раз пик на четверке:
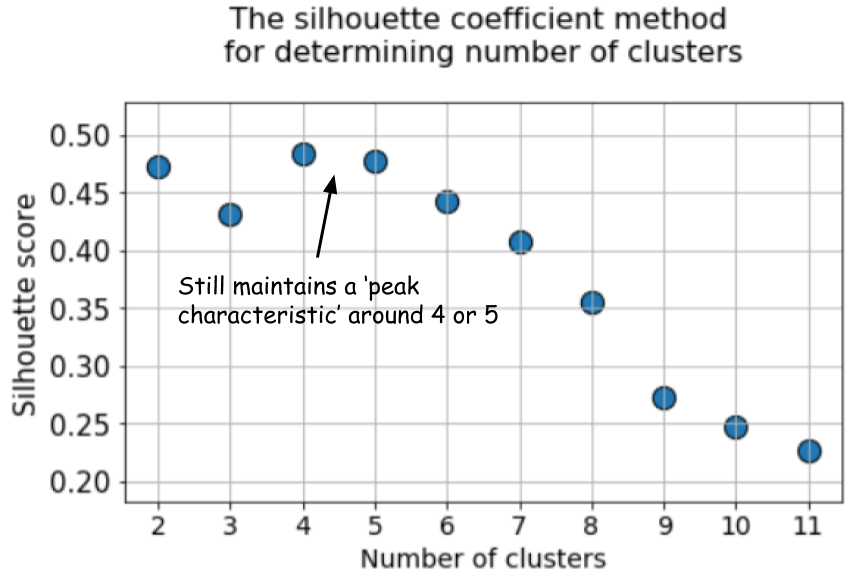
И автор это пытается аргументировать наложением кластеров, но если внимательно посмотреть на скатерплот, видно, что каждая пара кластеров различима хотя бы в одной проекции. Поэтому силуэт здесь банально, имхо, отработал хуже.
Собрал под катом перлы.
«to begin with» переводится не как «с которого нужно начинать», а как вводная конструкция «для начала».
Вы хоть где-то видели, чтобы в статье по машинному обучению метрику или скор переводили как «балл»?
Objective function — это, к вашему сведению, не «объективная» функция, а целевая.
Признаки же. Или координаты, если речь о графике.
В оригинале не «вычислим k-средних по умолчанию», а «вычислим метрику по умолчанию у k-средних».
В оригинале «The difference could not be starker», т.е. ровно наоборот: «Разница очень заметна».
Гауссов шум.
Дисперсии. Variance — это дисперсия, Карл!
Таки не переводится.
Если уже переводите penalty дословно, то «роста штрафа», а не «штрафов».
Как нам узнать количество кластеров, с которого нужно начинать?
«to begin with» переводится не как «с которого нужно начинать», а как вводная конструкция «для начала».
а также последующим откладыванием на графике балла кластеризации
Вы хоть где-то видели, чтобы в статье по машинному обучению метрику или скор переводили как «балл»?
по объективной функции k-средних
Objective function — это, к вашему сведению, не «объективная» функция, а целевая.
(попарные свойства)
Признаки же. Или координаты, если речь о графике.
затем вычислим k-средних по умолчанию
В оригинале не «вычислим k-средних по умолчанию», а «вычислим метрику по умолчанию у k-средних».
Разница не очевидна
В оригинале «The difference could not be starker», т.е. ровно наоборот: «Разница очень заметна».
Если увеличить гауссовы помехи
Гауссов шум.
из-за высокой вариативности
Дисперсии. Variance — это дисперсия, Карл!
максимизации ожиданий
Таки не переводится.
по мере роста штрафов
Если уже переводите penalty дословно, то «роста штрафа», а не «штрафов».
И на мой взгляд, автор оригинала приводит примеры, где противоречит себе.
Вот здесь:
Я вижу хороший локоть (т.е. изменение угла графика) как раз в пяти. А вот в варианте с силуэтом здесь же как раз пик на четверке:
И автор это пытается аргументировать наложением кластеров, но если внимательно посмотреть на скатерплот, видно, что каждая пара кластеров различима хотя бы в одной проекции. Поэтому силуэт здесь банально, имхо, отработал хуже.
Методики хорошие, но не проще ли использовать алгоритмы, основывающиеся на плотности точек в кластерах (density based — те же DBSCAN или OPTICS), когда нам не известно приблизительное число кластеров заранее?
А вот этот скор у имплементации k-means в sklearn — это средняя дистанция от точек до центроида, средняя внутрикластерная дисперсия или что-то более хитрое? Потому что, честно говоря, странно выглядит статья. Давайте сравним средний силуэт (определяемый как среднее по выборке для (b-a)/max(a, b)) с хрен его знает чем, что там у sklearn.cluster.kmeans под капотом, которое вроде бы тоже как-то связано с внутри- и межкластерными дистанциями.
На методе локтя перегиб четко видно если взять вторую производную, что обычно и делают. Тогда график выходит ничем не хуже силуэта.
Sign up to leave a comment.
Кластеризуем лучше, чем «метод локтя»