В этой статье мы рассмотрим, как организовать мониторинг производительности и доступности ИТ-сервисов без использования GUI-роботов и систем класса Real User Monitoring (RUM).
Решение, которое будет описано ниже, предназначено для тех, кому продукты класса Real User Monitoring стоимостью несколько сот тысяч долларов слишком дороги, а понимание того, что анализа обращений в Service Desk и анкетирования пользователей мало, уже пришло.
Проблема
Часто «мониторинг» производительности и доступности ИТ-сервисов (далее – качества ИТ-сервисов) сводится к анализу обращений пользователей в Service Desk и/или проведению анкетирования: оцените качество сервиса от 1 до 5, с какими именно проблемами вы столкнулись (выберите из списка) и т.д. Эффективно управлять качеством предоставления ИТ-сервисов таким образом очень сложно.
Примечание. Согласно теории инцидентом следует считать всякое снижение качества ИТ-сервиса. Однако на практике пользователи регистрируют не все случаи снижения качества сервиса, а только те, которые были восприняты ими как критические для выполнения бизнес задач. Кроме того, прежде чем обратиться в поддержку, часто пользователи пытаются решить или обойти проблему самостоятельно, ищут решение в интернете, советуются с коллегами и т.п., и часто им это удаётся. Об инцидентах, решённых пользователем самостоятельно, поддержке тоже ничего не известно.
Для небольшого аутсорсера с небольшим числом клиентов этого может быть достаточно. Но чем больше клиентов и чем сложнее ИТ-сервис, тем труднее становится отслеживать его качество по одним только отзывам или обращениям в службу поддержки. Получаемая таким образом информация неполна, множество мелких проблем в работе ИТ-сервиса остаются для его поставщика не известными.
Методы мониторинга качества ИТ-Сервиса
Более продвинутые методы мониторинга качества ИТ-сервиса – это:
- мониторинг ИТ-инфраструктуры;
- мониторинг времени реакции бизнес-приложения (прежде всего, GUI-роботами);
- Real User Monitoring (RUM).
Охарактеризуем каждый из них.
В основе первого метода лежит представление, что здоровье ИТ-инфраструктуры коррелирует с доступностью сервиса. В целом это действительно так, но для эффективного использования требуется правильная настройка пороговых значений системы мониторинга. Настройка пороговых значений системы мониторинга – это вообще главная сложность в использовании системы мониторинга. Если же настройка системы мониторинга не проведена, можно эффективно отслеживать только доступность элементов ИТ-инфраструктуры по ping, что, конечно, не тождественно возможности реально пользоваться сервисом. Все элементы инфраструктуры ip-телефонии могут быть доступны по ping, а пользоваться связью невозможно – звук булькает, изображение замирает.
Для мониторинга времени реакции бизнес-приложений сегодня чаще всего используются GUI-роботы. GUI-роботы имитируют поведение пользователя в пользовательском интерфейсе. Это довольно эффективный инструмент мониторинга доступности ИТ-сервиса, но с двумя «но». Во-первых, GUI-роботы – это плохо масштабируемое решение, во-вторых, они радикально упрощают действия пользователя. Например, эмулировать сложную транзакцию GUI-робот, скорее всего, не сможет.
Второго недостатка лишён Real User Monitoring (RUM) – пассивный мониторинг реальных действий пользователя. Чаще всего для этого используются анализаторы сетевого трафика. Это действительно мониторинг всех действий пользователя, но стоят продукты этого класса по несколько сот тысяч долларов. Если у вас есть средства под RUM и вы готовы их на это потратить, используйте RUM. Если нет, решение без RUM описано ниже.
Концепция
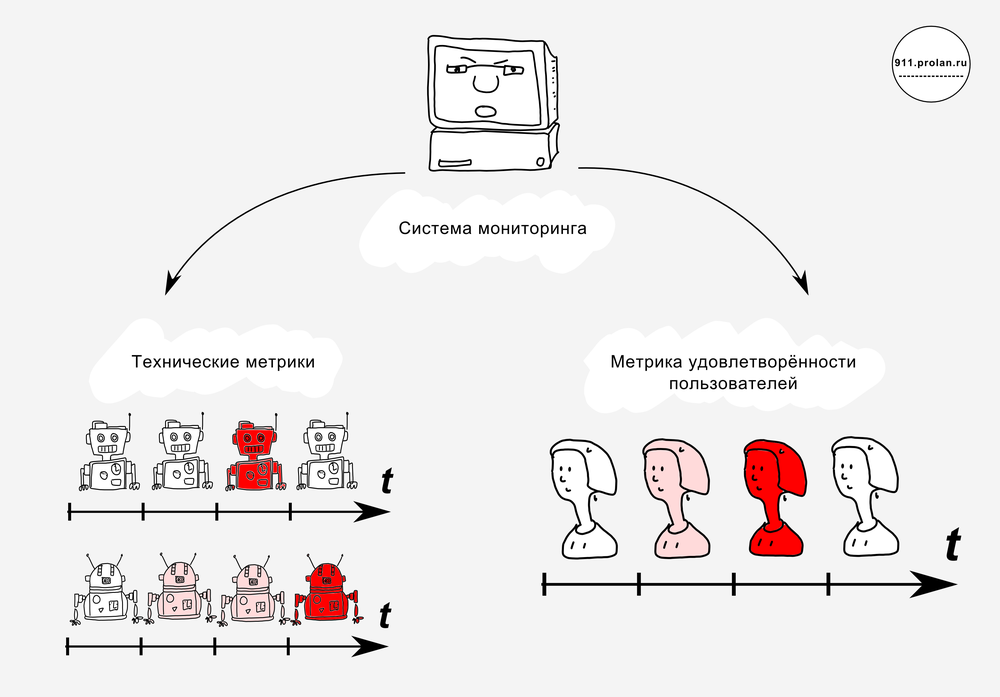
Сегодня дело обстоит так, что контактами с пользователями (прежде всего, приёмом и обработкой обращений по поводу инцидентов и сервисных запросов) занимается служба поддержки, а проактивным мониторингом – системный администратор (системные администраторы). Системный администратор следит, чтобы инциденты не возникали, а служба поддержки работает с уже случившимися инцидентами, стремясь возможно быстрее восстановить упавшее качество сервиса.
Конечная цель того и другого (и проактивного мониторинга, и управления инцидентами) – сделать так, чтобы качество ИТ-сервиса поддерживалось на высоком уровне, а пользователи были довольны.
В своей работе системный администратор использует (или не использует) систему мониторинга. Как правило, система мониторинга отслеживает состояние и здоровье ИТ-инфраструктуры и производительность бизнес-приложений. Но система мониторинга устроена (или должна быть устроена) так, что она может отслеживать всё, что угодно – не только здоровье ИТ-инфраструктуры и производительность бизнес-приложений. Стоит только добавить соответствующий модуль.
Так почему бы не поручить системе мониторинга отслеживать удовлетворённость пользователей?
Ведь, в конечном счёте, мониторинг ИТ-инфраструктуры нужен только постольку, поскольку здоровье ИТ-инфраструктуры обеспечивает предоставление ИТ-сервиса клиенту. Деньги платит клиент, а не компьютеры и маршрутизаторы.
Примечание. Цель мониторинга качества ИТ-сервиса с точки зрения поставщика сервиса – не мониторинг абстрактного качества сервиса как такового, а обеспечение удовлетворённости пользователей качеством сервиса.
Мониторинг удовлетворённости пользователей
Пользователи сообщают в ИТ-службу (собственно, Service Desk) только о тех случаях недовольства, которые представляются им критическими для их функционала и в то же время неразрешимыми (неадекватных личностей и большое начальство оставим за скобками).
Сделаем так, чтобы пользователи жаловались на всякие мелкие трудности в ходе работы с ИТ-сервисом. Но принимать такие обращения – назовём их жалобами – службой поддержки нельзя – их будет очень много (если правильно поставить дело), и служба поддержки будет ими просто завалена.
Поэтому жалобы будут приниматься не службой поддержки, а системой мониторинга.
Система мониторинга будет:
- отслеживать жалобы как ещё одну метрику, наряду с метриками здоровья серверов, каналов связи и т.п.;
- оценивать эту новую метрику или метрики по n-балльной шкале;
- при превышении допустимых значений сообщать службе поддержки (создавая запись в Service Desk-системе и сообщая сотрудникам службы, например, по e-mail).
Через систему отчётов можно будет проводить ретроспективный анализ, выявлять сервисы, вызывающие особое недовольство и т.п.
Решение
Отправка жалобы
Пользователь не любит общаться с ИТ-службой. Минимизируем сложность отправки жалобы: пусть она отправляется полностью автоматически по нажатию кнопки или сочетания клавиш.
В момент временного снижения качества сервиса (когда сервис подвисает, но заранее известно, что через пару минут он отвиснет), пользователю, как правило, нечего делать. Его бизнес-операции прерваны, но обращаться в поддержку вроде как ни к чему, потому что к тому моменту, как последует реакция, всё уже будет работать. Пользователь не прочь бы выразить своё возмущение и улучшить работу сервиса, но не знает, как это сделать. Он громко ругается на весь отдел: «Опять завис, собака!» или переживает эту драму в себе. Дадим ему Красную Кнопку. Теперь, когда сервис опять затупит, он сначала нажмёт на кнопку, а потом будет ругаться на весь отдел.
Красная Кнопка – это программный агент EPM-Agent Plus. Он устанавливается на компьютеры пользователей или терминальный сервер. К программному агенту прилагается девайс – аппаратная кнопка-нажималка, подключаемая по USB. Именно на неё и нажимает пользователь, когда возникают проблемы с сервисом. Если для кого-то кнопка выглядит старомодно, можно обойтись нажатием комбинации клавиш – это будет равносильно нажатию аппаратной кнопки.

Примечание. Зачем нужна аппаратная кнопка? Красивая. Если поставщик и получатель ИТ-сервиса – разные компании, поставщик сразу поймёт, как использовать эту красивую красную штуку в маркетинговых целях.
EPM-Agent Plus умеет следующее. По нажатию кнопки (аппаратной или комбинации клавиш) он определяет используемое бизнес-приложение и бизнес-операцию, делает скриншот экрана, добавляет значения переменных среды и учётные данные пользователя и отправляет всё это в виде сообщения HelpMe в Агрегатор информации (не в Service Desk!).
Примечание. Вообще говоря, Красная Кнопка умеет не только отправлять жалобы, но и регистрировать инциденты. Поэтому у неё есть два режима работы. В первом по нажатию кнопки открывается диалоговое окно, необходимое для регистрации инцидента. Большинство действий выполняются автоматически, но тип инцидента указать нужно явно, для этого и нужно диалоговое окно. Во втором режиме окно не открывается, программа отрабатывает полностью автоматически. Этот-то режим и используется для отправки жалоб. Чтобы можно было использовать кнопку сразу в двух целях, режимы вызываются разным нажатием кнопки: первый – коротким, обыкновенным, второй – продолжительным, около двух секунд (как включение телефона).
Агрегация жалоб
Сообщение HelpMe – это SOAP-пакет. Сообщения HelpMe собираются (агрегируются) в Агрегаторе информации.
Агрегатор информации – это система мониторинга ProLAN SLA-ON. Помимо собственно системы мониторинга Агрегатор информации включает в себя:
- экспертную систему
- консолидированную базу данных
- средство построения отчётов
Агрегатор информации принимает жалобу (сообщение HelpMe) и записывает её в консолидированную базу данных. Все жалобы собраны вместе и предстоит что-то сделать с ними – не просто так же мы их собирали.
Примечание. Наряду с полнофункциональным ProLAN SLA-ON для некоторых целей можно использовать бесплатный QuTester Plus. QuTester Plus – это пакет, включающий в себя и систему мониторинга, и Красную Кнопку. Функциональность, естественно, урезана, но отсутствуют ограничения по времени. Полнофункциональные ProLAN SLA-ON и Красная Кнопка, в свою очередь, имеют бесплатный тестовый период – 30 дней. Вообще же решение на один-два порядка дешевле продуктов класса Real User Monitoring.
Жалоба и удовлетворённость пользователей
Каждая жалоба – это сигнал о неудовлетворённости пользователя, а содержание Сообщения HelpMe позволяет определить, к какому сервису неудовлетворённость относится, где географически расположен пользователь, из какого он подразделения, какую должность занимает и т.п.
Мы уже узнали гораздо больше об отношении пользователей к нашему сервису, чем если бы пользовались только данными службы поддержки и анкетирования. Но как разобраться в массе сыплющихся отовсюду жалоб?
Группируем жалобы по интересующим нас признакам – например, вот так:
| / | Справочник пользователей | |||
|---|---|---|---|---|
| Справочник операций | / | Топы — Москва | Продавцы — Питер | Все — Сочи |
| Работа в 1С | Метрика 1: Жалобы топов из Москвы на работу 1С | Метрика 4: Жалобы продавцов из Питера на работу 1С и SAP CRM | Метрика 6: Жалобы всех пользователей из Сочи на работу 1С и SAP CRM | |
| Работа в SAP CRM | Метрика 2: Жалобы топов из Москвы на работу SAP CRM | |||
| Интернет | Метрика 3: Жалобы топов из Москвы на работу Интернет | Метрика 5: Жалобы продавцов из Питера и всех пользователей из Сочи на работу Интернет | ||
Теперь эти группы жалоб – метрики, которые отслеживает система мониторинга. Если придёт жалоба пользователя, входящего в группу «Продавцы – Питер», на работу SAP, она будет учтена Метрикой 4, жалоба сочинского пользователя на 1С – Метрикой 6. При помощи метрик удовлетворённости пользователей система мониторинга отслеживает качество ИТ-сервиса. Каждая метрика автоматически оценивается по пятибалльной шкале: «хорошо», «допустимо», «требует внимания», «на грани», «плохо». Например, не более 2 жалоб в день (или в час, или в минуту) из Сочи на работу SAP – это «хорошо», более 2 – «допустимо», более 3 – «требует внимания» и т.д.
| Оценка Качества (цвет «индикатора») | >/< | Пороговое значение |
|---|---|---|
| Плохо (красный) | > | 7 |
| На грани (мигающий красный) | > | 5 |
| Требует внимания (жёлтый) | > | 3 |
| Допустимо (мигающий жёлтый) | > | 2 |
| Хорошо (зелёный) | < | 2 |
«Требует внимания» – Пороговое значение Оценки Качества для отправки Агрегированного Снимка Инцидента в Service Desk.
Динамику метрик, а значит удовлетворённости пользователей, можно видеть в режиме реального времени. Зелёные квадратики – «хорошо», мигающие зелёные – «допустимо», появился жёлтый – «требует внимания».
Отчёты
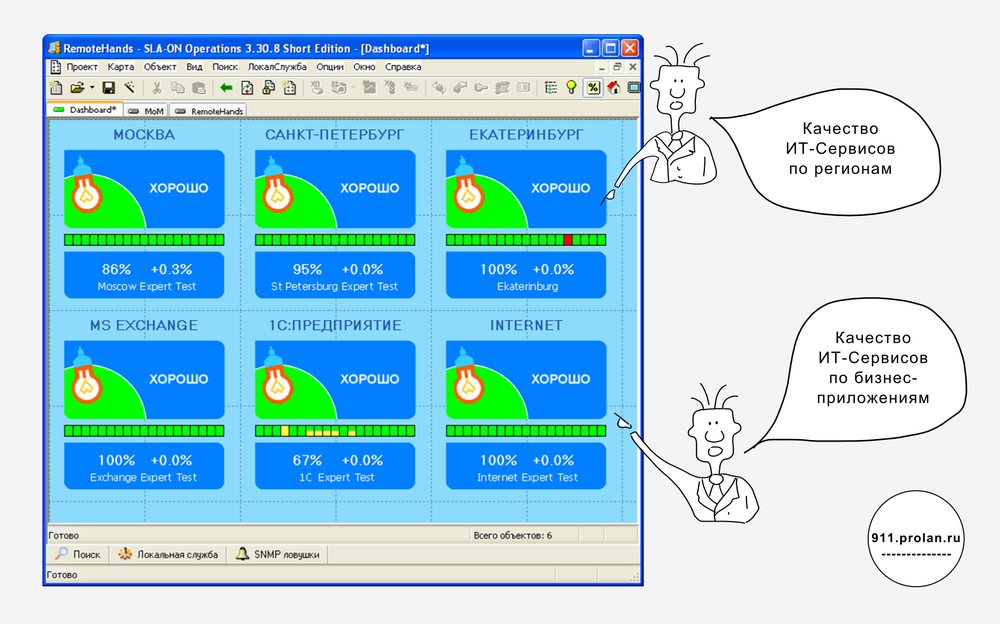
Сырые данные и экспертные оценки можно контролировать в режиме реального времени, Экспертные Оценки в виде цветных светофоров – наносить на географическую карту или схему бизнес процессов. На основе сырых данных и экспертных оценок могут создаваться оперативные и тактические отчёты. Оперативные отчёты позволяют увидеть удовлетворённость пользователей качеством ИТ-сервиса в различных разрезах (аналитиках), например, по офисам продаж. Тактические отчёты позволяют видеть изменение удовлетворённости пользователей качеством ИТ-сервиса на длительных интервалах времени (тренды), Базовые Линии в различных разрезах и т.п.
Агрегированные Снимки Инцидентов
Недостаточно просто оценивать количество жалоб, поступающих на тот или иной сервис от тех или иных пользователей. Нужно сделать так, чтобы сотрудники, ответственные за поддержание качества ИТ-сервиса, могли оперативно узнать о падении качества сервиса и исправить положение, даже если никто из пользователей не зарегистрировал инцидент в Service Desk.
Для этого, как только оценка какой-либо метрики падает до значения «требует внимания», система мониторинга автоматически формирует Агрегированный Снимок Инцидента и регистрирует в Service Desk – системе новый инцидент. К Агрегированному Снимку Инцидента прикладываются и все относящиеся к нему жалобы (Сообщения HelpMe). Получив Агрегированный Снимок Инцидента, служба поддержки работает с ним, как с обычным инцидентом.
Примечание 1. Интеграция мониторинга качества ИТ-сервиса с мониторингом здоровья ИТ-инфраструктуры и производительности бизнес-приложений облегчает задачу диагностирования причин падения качества.
Примечание 2. Теория допускает и даже поощряет регистрацию инцидентов в службе поддержки не от пользователей, а от автоматизированных систем управления событиями (event management). Имеется в виду система мониторинга, отслеживающая здоровье ИТ-инфраструктуры, и при обнаружении нарушений в её работе (например, не отвечает сервер или недоступен веб-сайт) формирующая автоматический запрос в службу поддержки. Мы делаем то же самое (автоматически регистрируем инцидент при помощи системы мониторинга), но при обнаружении проблем не в ИТ-инфраструктуре, а в удовлетворённости пользователей.
Область применения и ограничения

Очевидно, что просить пользователей постоянно жаловаться на мелкие проблемы (даже максимально упростив эту задачу) – не очень хорошая идея. С какой стати пользователи должны выполнять работу ИТ-Службы – если люди сообщают о проблемах, но ничего не улучшается, они прекратят это делать. Поэтому обращение к пользователям с просьбой нажимать кнопку должно быть, во-первых, обосновано, во-вторых, носить временный характер (1-3 месяца максимум). Логично это делать, например, в следующих случаях:
- Проведение аудита качества ИТ-сервисов (ежегодное техобслуживание). А не появились ли проблемы, о которых мы не знаем; «Просим вас оценить качество получаемого сервиса» и т.п.
- По окончании внедрения новых сервисов. Систематизация жалоб позволит локализовать недоработки бизнес-приложений и/или проблемы в ИТ-Инфраструктуре. «Внедряется новое бизнес-приложение, просим вас нам помочь оценить качество работы подрядчиков».
- При смене CIO или ИТ–команды. Чтобы оценить масштабы бедствия в цифрах.
Основные цели:
- Локализация проблем, что позволяет более эффективно использовать более точные средства диагностики, например, анализатор сетевых протоколов.
- Диагностика скрытых дефектов и узких мест (о которых ИТ-Служба не знает). Чтобы их устранить и пользователи больше не жаловались.
- Определение пороговых значений технических метрик (утилизация, число ошибок, задержки), соответствующих комфортной работе пользователей. Чтобы контролировать производительность и доступность ИТ-Сервисов с использованием имеющиеся системы мониторинга ИТ-Инфраструктуры и без привлечения для этого пользователей. Это очень важная тема, которую мы постараемся раскрыть в отдельной статье.
Выводы

- Мимо «мониторинга» через службу поддержки и анкетирование проходят:
- Случаи ухудшения качества сервиса, проигнорированные пользователем;
- Случаи ухудшения качества сервиса, решённые пользователем самостоятельно;
- Все прочие случаи, когда пользователь не захотел заполнить анкету о качестве услуги и не обратился в поддержку.
- Концепция
- Мониторинг качества ИТ-сервиса для поставщика ИТ-сервиса – это мониторинг удовлетворённости пользователей качеством ИТ-сервиса.
- Чтобы видеть больше, нужно мотивировать пользователей жаловаться на мелкие нарушения в работе ИТ-сервисов.
- Решение
- Пользователи отправляют жалобы нажатием кнопки (Красная Кнопка).
- Жалобы принимают не люди (служба поддержки), а ИТ-система (система мониторинга ProLAN SLA-ON).
- Люди работают не с отдельными жалобами, а с отчётами и Агрегированными инцидентами.
- Область применения и ограничения
- Цель любого мониторинга является – узнавать о проблеме до того, как это скажется на работе пользователей. Поэтому не следует использовать мониторинг при помощи жалоб пользователей как постоянное решение.
- Цели мониторинга при помощи жалоб пользователей – локализация проблем, диагностика скрытых дефектов и узких мест, установление соответствия технических метрик комфортной работе пользователей.
- Применение мониторинга при помощи жалоб пользователей – аудит качества ИТ-сервисов, внедрение новых сервисов, смена CIO или ИТ-команды.
