В этой статье мы рассмотрим, что такое анализ сетевого трафика для мониторинга и управления производительностью сетевых приложений, а также коснёмся различий между анализом сетевого трафика в режиме реального времени и ретроспективным анализом трафика (Retrospective Network Analysis, RNA).
Введение
Есть такой маркетинговый приём: выбрать востребованное на рынке свойство продукта или услуги и заявить, что у твоего продукта или услуги это востребованное свойство тоже есть. Всем нужна белизна зубов – заявим, что и наша зубная паста отбеливает зубы.
С управлением производительностью приложений (APM, Application Performance Management, также Application Performance Monitoring) та же история. Сегодня практически каждый производитель систем сетевого управления заявляет, что его продукты позволяют управлять производительностью приложений. Конечно, «пони тоже кони», но давайте разберёмся, что же такое APM и какой функциональностью должен обладать инструментарий, чтобы носить это гордое имя.
Признаки зрелого APM-решения
Для очень многих измерение времени реакции бизнес-приложения и управление его производительностью – это практически одно и то же. На самом деле, это не совсем так. Измерять время реакции – это необходимо, но этого недостаточно.
APM – это сложный процесс, который включает в себя также измерение, оценку и документирование метрик, относящихся к ИТ-инфраструктуре, и, самое главное, обеспечивающий возможность увязки друг с другом качества работы приложений и качества работы ИТ-инфраструктуры. Другими словами, нужно не только определить, что приложение работает плохо, но и найти «виноватого». Для этого, кроме измерения времени реакции, нужно отслеживать ошибки приложений, контролировать диалог клиентов с серверами, видеть тренды. И всё это нужно делать одновременно для всего активного сетевого оборудования (коммутаторы, маршрутизаторы и т.д.), всех серверов, а также каналов связи.
В приведённой ниже таблице перечислены 10 ключевых признаков зрелого APM-решения.
| Ключевой признак | Комментарий |
|---|---|
| 1. Комплексный мониторинг | Для быстрого определения «масштабов бедствия» и корневых причин сбоев необходимо одновременно контролировать метрики, характеризующие работу приложений, и метрики, характеризующие работу всей ИТ-инфраструктуры без исключения. |
| 2. Высокоуровневые отчёты | Необходимы для понимания качества предоставления ИТ-сервисов в масштабе всего предприятия. Должны включать предустановленные панели (dashboards), отчёты, пороговые значения, базовые линии, шаблоны сообщений о сбоях. Обязательно должна быть возможность детализации информации (drill down). |
| 3. Возможность настроить безопасный обмен данными | Для быстрого устранения проблем и планирования мощностей необходима кооперация между различными отделами ИТ-Службы. Поэтому зрелое APM-решение должно обеспечивать возможность безопасного обмена данными. Это относится как к real time данным, так и к результатам статистической, экспертной и других обработок. |
| 4. Непрерывный захват сетевых пакетов | Контролируя объекты по SNMP, WMI и т.п., безусловно, можно оценить качество работы приложений, но увидеть всю картину целиком и понять, что и почему произошло – сложно. Более правильно – постоянно захватывать весь сетевой трафик полностью (не только заголовки), а когда происходит какое-то, требующее расследование событие, то анализировать содержимое захваченных сетевых пакетов. |
| 5. Детальная информация о работе приложений | Анализировать только время реакции приложения – недостаточно. Чтобы быстро диагностировать сбои, нужна информация о запросах (которые делает приложение), как они выполняются, коды возникающих ошибок и другая информация. |
| 6. Экспертный анализ | Серьёзный экспертный анализ существенно ускоряет диагностику проблем, т.к., во-первых, позволяет автоматизировать процесс анализ информации, во-вторых, если проблема известна, позволяет сразу получить готовое решение. |
| 7. Сквозной (multiple segment / multihop) анализ | Поскольку всё больше бизнес-приложений работают в облаке или через WAN, нужно уметь видеть все задержки и ошибки, возникающие в каждом сегменте сети, через который проходит сетевой трафик (один и тот же пакет). Только так можно быстро локализовать корневую причину сбоя. |
| 8. Гибкие базовые линии | Гибкие (настраиваемые) базовые линии позволяют эффективно контролировать как внутренние, так и облачные приложения. Для облачных приложений пороговые значения контролируемых метрик (прописываемые в SLA) обычно статические (известны заранее) и устанавливаются вручную. Для внутренних приложений лучше подходят динамические базовые линии, т.е. изменяемые автоматически с течением времени, в зависимости о производительности работы приложения. |
| 9. Возможность реконструкции информационных потоков | При анализе проблем, связанных с плохим качеством передачи голоса и видео, а также проблем в области информационной безопасности, важно иметь возможность воспроизвести сетевую активность и работу приложения в тот момент (а также до и после), когда произошло критическое событие. |
| 10. Масштабируемость | Думается, комментарии излишни. |
Анализ сетевого трафика
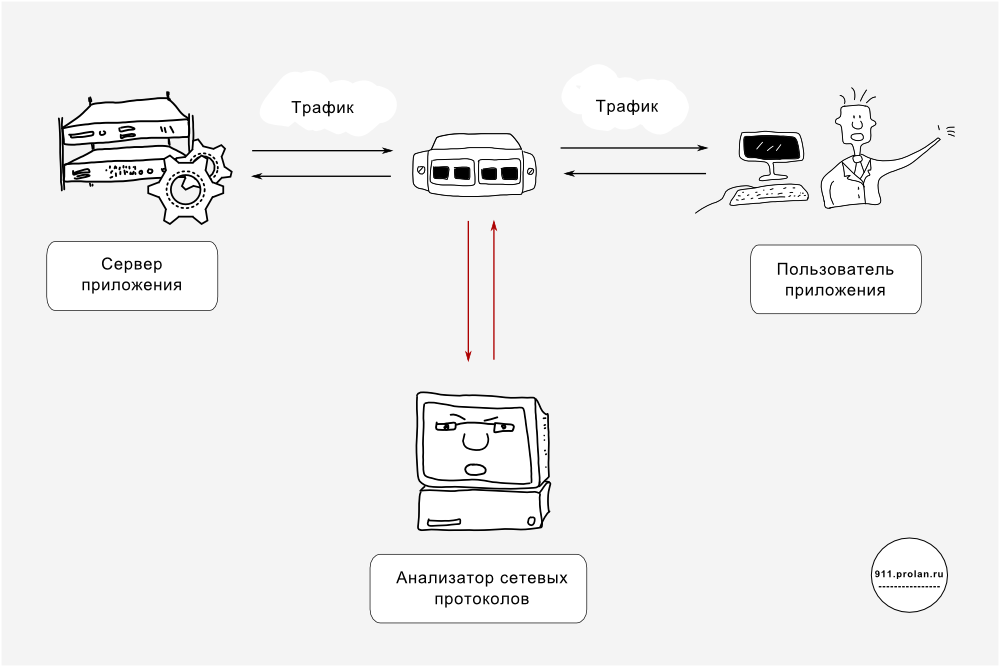
Опытные ИТ-специалисты скажут, за перечисленными выше признаками торчат уши APM-решения, основанного на анализе сетевого трафика. Это действительно так.
Компания Network Instruments выделяет четыре типа решений для управления производительностью приложений:
- решения, основанные на синтетических транзакциях (GUI-роботы)
- решения, использующие программные агенты на стороне сервера
- решения, использующие программные агенты на стороне клиента
- решения, основанные на анализе сетевого трафика
Решения, основанные на анализе сетевого трафика, стоят в этом списке особняком.
В отличие от решений, основанных на синтетических транзакциях или использующих программные агенты на стороне сервера или клиента, сбор данных осуществляется без использования ресурсов системы.
Анализатор сетевого трафика обычно состоит из нескольких зондов и консоли удалённого администрирования. Зонды подключаются к SPAN-портам, что позволяет APM-решению, основанному на анализе сетевого трафика, пассивно слушать трафик, не потребляя ни ресурсы сервера (как это делают программные агенты на стороне сервера и синтетические транзакции), ни клиента (как это делают агенты на стороне клиента) и не создавая дополнительного трафика (как это делают синтетические транзакции и агенты на стороне клиента).
В основе собственно анализа лежит декодирование сетевых протоколов всех уровней, включая уровень приложения. Например, Observer от Network Instruments поддерживает декодирование и анализ всех семи уровней OSI-модели для таких приложений и сервисов, как SQL, MS-Exchange, POP3, SMTP, Oracle, Citrix, HTTP, FTP и др.
Если требуется получить информацию о задержках, наиболее близкую к восприятию пользователя, зонды подключаются максимально близко к клиентским устройствам. Правда, в этом случае потребуется большое количество зондов. Если точные данные по задержкам не столь критичны, а количество используемых зондов требуется сократить, зонды подключаются ближе к серверу приложений. Впрочем, изменения в задержке будут видны и в том, и в другом случаях.
Примечание. Можно использовать также мониторинг-свичи, собирающие информацию с нескольких SPAN-портов и TAP’ов для последующего перенаправления в систему мониторинга. Мониторинг-свичи также могут проводить первичный анализ трафика.
Второй важный момент. У всех четырёх типов решений, перечисленных Network Instruments, есть свои преимущества и своя область применения, в которой они справляются с задачами лучше других. Например, самую подробную информацию о приложении позволяют собрать программные агенты, получающие информацию непосредственно из приложения на стороне сервера или клиента через ARM-образный API. Эта информация очень полезна на этапе разработке и первоначальной обкатки приложения, но будет избыточна в процессе нормальной эксплуатации.
С другой стороны, как GUI-роботы с синтетическими транзакциями, так и программные агенты собирают данные о состоянии конкретного приложения (или нескольких приложений). Применение программных агентов с внедрением в код вообще предъявляет довольно высокие требования – вендор должен встроить в приложение поддержку конкретного инструмента мониторинга или предоставить API. Для того чтобы узнать контекст, в котором выполняется приложение, необходимо использовать другие инструменты (возможно, включённые в ту же комплексную систему мониторинга, возможно – отдельные).
Традиционная парадигма сетевого мониторинга – это централизованный сбор, объединение и анализ данных, получаемых из внешних источников информации. Это SNMP-агенты, WMI-провайдеры, различные логи и т.п. Задача системы мониторинга – собрать эти данные, в удобном виде их показать, проанализировать с использованием сервисно-ресурсной модели, и, таким образом, понять, что происходит. Так работают практически все системы мониторинга, в том числе система мониторинга ProLAN.
Анализатор сетевых протоколов позволяет увидеть сразу контекст.
Во-первых, можно увидеть, как работало интересующее нас приложение на фоне работы сетевых сервисов и компонентов ИТ-инфраструктуры. Например, multihop-анализ позволяет выявить сбоящий маршрутизатор, из-за которого рвётся соединение между сервером и клиентом, и т.п. В принципе, анализатор сетевых протоколов может использоваться в качестве универсального решения, одновременно выполняющего функции и управления производительностью приложений, и мониторинга ИТ-инфраструктуры, и управления безопасности.
Во-вторых, никакой другой способ не позволяет увидеть, что происходит на уровне отдельной транзакции и отдельного пакета. Какие пакеты были отправлены, какие потеряны, какие прошли с ошибками (каждый конкретный пакет, а не сколько вообще) и т.п. Анализ работы приложения на уровне отдельной транзакции может быть реализован только с помощью анализатора сетевых протоколов.
Ретроспективный анализ сетевого трафика
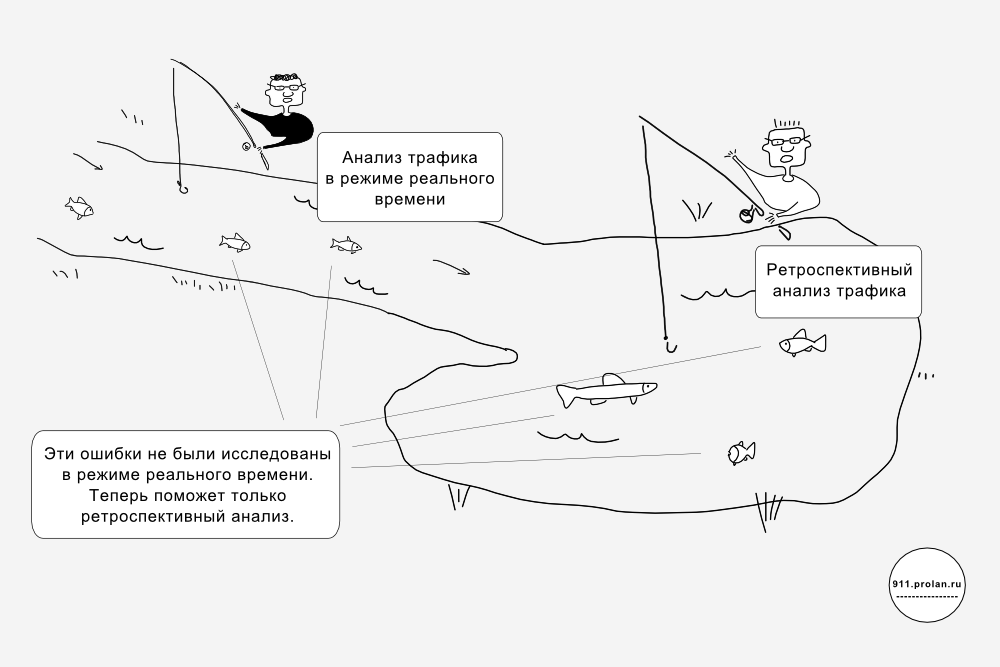
Анализ сетевого трафика может проводиться двумя способами:
- анализ трафика в режиме реального времени (на лету)
- ретроспективный анализ трафика
Ретроспективный анализ трафика предполагает, что весь трафик или какая-то его часть сначала записывается на диск, а потом анализируется.
Рассмотрим, как это работает и зачем это нужно, на примере GigaStor – решения для записи и ретроспективного анализа трафика от Network Instruments. Это программно-аппаратный комплекс, имеющий в своём составе аппаратный зонд, полнодуплексную сетевую карту, хранилище данных и локальную консоль управления. Для удалённого администрирования понадобится интеграция с другими продуктами Network Instruments – уже упомянутым Observer или Observer Reporting Server. Сетевая карта позволяет захватывать трафик из сетей скоростью до 40 Гб/с, а дисковые массивы – хранить до 5 ПБ данных (альтернатива – выгрузка в SAN до 576 ТБ).
Перехват сетевого трафика позволяет узнать, что сейчас происходит с приложениями, пользователями и ИТ-инфраструктурой. Но как узнать, что было пять минут, или час, или день назад? Традиционный способ заключается в том, чтобы снимать значения метрик и записывать их в базу данных. Так делает подавляющее большинство систем мониторинга. Значения и оценки метрик позволяют получить некоторое представление о том, что было в произвольный момент времени, но не более. Тем, что было записано, мы можем воспользоваться. То, что не было записано, потеряно безвозвратно.
Вернуться в прошлое и посмотреть, что происходило в интересующий нас момент, можно только одним способом, как это делает GigaStor и другие решения этого класса (их, впрочем, немного) – записывать весь трафик. Это обуславливает специфические особенности таких решений:
- во-первых, доступ к очень большому дисковому пространству (измеряется терабайтами и петабайтами);
- во-вторых, т.н. функция машины времени, позволяющая отмотать время обратно и посмотреть, что происходило в сети в произвольный момент прошлого.
Возможность путешествия во времени особенно важна в двух случаях:
- когда проблема сложна, повторяется нерегулярно или непонятно, к какой области её отнести («серая проблема»);
- когда имеет место нарушение безопасности.
Коротко рассмотрим оба случая.
В первом случае системный администратор сталкивается с недостатком информации. Если проблема появляется нерегулярно, её трудно отследить и воспроизвести. То же касается сложных и «серых» проблем. Ретроспективный анализ позволяет восполнить этот недостаток информации, ускорив решение проблемы на часы, а может быть, и дни.
Во втором случае проблему нужно решить максимально быстро – в противном случае могут наступить последствия, которые будет трудно исправить. Самый удобный способ – вернуться во времени и отследить действия злоумышленника, как они происходили на самом деле, не тратя время исследование косвенных признаков и т.п.

1. Зрелое APM-решение предполагает не только умение измерять времени реакции приложения, но и ряд свойств, направленных на оценку результатов измерения и быстрое обнаружение и диагностику проблем.
2. Из четырёх типов APM-решений наиболее универсальными для управления производительностью сетевых приложений представляются решения, основанные на анализе сетевых протоколов.
3. Для решения сложных, повторяющихся нерегулярно проблем, а также проблем, связанных с нарушением безопасности, анализа сетевого трафика в режиме реального времени недостаточно. В этих случаях применяется ретроспективный анализ сетевого трафика с записью трафика на диск и т.н. функцией машины времени.
