Comments 152
Прямо в студии запускается, с подсветкой потенциально проблемных мест?
Гат дэмн!
А по ценовым политикам какие намёки?
А по ценовым политикам какие намёки?
Оу ееееееееее
Сделал пулл-реквест github.com/Microsoft/msbuild/pull/240
Насколько я понимаю ReSharper тоже покажет warning для этого if, что-то вроде «Expression is always true», хотя может быть и нет, потому что вызывается фунция.
В общем я о том, будет ли смысл покупать PVS-Studio, если есть R#? Вы планируете конкурировать с ним или дополнять?
В общем я о том, будет ли смысл покупать PVS-Studio, если есть R#? Вы планируете конкурировать с ним или дополнять?
Прежде чем приступить к созданию PVS-Studio для C# мы провели исследование конкурентов. И уверены, что сможем хорошо показать себя и составить им серьезную конкуренцию. Т.е. хотя только сейчас появилась новая диагностика, это не значит, что проект начат позавчера. Мы серьезно подошли к вопросу предварительного исследования и к самой разработке.
Смотрели и на ReSharper. Да, он, наверное, найдёт эту ошибку (нет возможности сейчас проверить). Но чуть в сторону, и он уже молчит. Например, он промолчит на выражении:
Здесь два одинаковых выражения a == b «разделены» подвыражением b == c.
И наоборот, ReSharper зря ругается на специфическую, но распространённую проверку вида:
Ему не нравится 'A' == 0x41 и 'a' == 0x61.
Анализатор PVS-Studio будет более дотошный и при этом содержать больше исключений. Плюс уникальные диагностики.
Смотрели и на ReSharper. Да, он, наверное, найдёт эту ошибку (нет возможности сейчас проверить). Но чуть в сторону, и он уже молчит. Например, он промолчит на выражении:
if (a == b && b == c && a == b) nop();
Здесь два одинаковых выражения a == b «разделены» подвыражением b == c.
И наоборот, ReSharper зря ругается на специфическую, но распространённую проверку вида:
if ('0' == 0x30 && 'A' == 0x41 && 'a' == 0x61)
nop();Ему не нравится 'A' == 0x41 и 'a' == 0x61.
Анализатор PVS-Studio будет более дотошный и при этом содержать больше исключений. Плюс уникальные диагностики.
if ('0' == 0x30 && 'A' == 0x41 && 'a' == 0x61)
А в чём её смысл?
Убеждаемся, что символы представлены в кодировке ASCII. Некоторые хотят слишком всё контролировать :).
Ни разу не видел шарповых исходников в кодировке, отличной от UTF-8.
Не суть важно. Пусть UTF-8 (первые 7F символов совпадают). Главное хотят убедиться, что '0' это 0x30 и так далее.
Он по стандарту языка будет 0x30.
Я встречал проверку sizeof(char) == 1. Хотя согласно стандарту с++ нет смысла делать такую проверку. А она есть. Нет смысла обсуждать рациональность подобного кода. Надо просто учитывать такой вариант. И примером я хотел показать, что мы внимательно собираем всякие такие случае и делаем для них исключения. Это сильная сторона анализатора.
Кмк, тут не исключения нужно делать, а выбрасывать диагностику conditional is always true.
А что делать с конструкциями if(true) и if(false)? Если человек такое написал, то он явно так и хотел, а почему — ему виднее. Но if(false) сейчас и в VS без предупреждения не пройдёт.
Ему виднее, но чаще всего это временные конструкции, пусть постоянно напоминание будет.
И какой смысл в этих конструкциях? Можно же просто закомментировать или блок, или условие.
Если закомментировать — полезет следующий уровень предупреждений, про всякие неиспользованные переменные. И автоформатирование через некоторое время начнёт сбиваться.
У if(false) есть масса интересных и полезных применений.
habrahabr.ru/company/infopulse/blog/137385
habrahabr.ru/company/infopulse/blog/137385/#comment_4599424 и см. другие комментарии
habrahabr.ru/company/infopulse/blog/137385
habrahabr.ru/company/infopulse/blog/137385/#comment_4599424 и см. другие комментарии
Насчёт комментариев там бред, потому что в нормальных редакторах (молчу уж про IDE) проблемы не существует. Чтобы неиспользуемый код не удаляли, существуют комментарии для людей. Какой-то смысл может быть для рефакторинга, но возиться с рефакторингом кода, который не используется — занятие сомнительное, да и тот же R# умеет смотреть код в комментариях при рефакторинге.
Выполнение кода в режиме отладки для C# абсолютно неактуально, потому что есть Intermediate Window, Edit and Continue и прочие радости жизни. В последней версии поддерживается всё вплоть до лямбд.
Выкрутасы с кодом с помощью макросов в мире C# невозможны.
Коммитить неработающий код и оставлять неработающий — зло, для этого есть VCS. В мире Git проблемы «надо хоть что-нибудь закоммитить в общий репозиторий, а то изменений уже на 1000 файлов», как в SVN, не существует. Подсветка кода
Итого, остаётся только рефакторинг, а он по отдельности теряет смысл тоже.
Выполнение кода в режиме отладки для C# абсолютно неактуально, потому что есть Intermediate Window, Edit and Continue и прочие радости жизни. В последней версии поддерживается всё вплоть до лямбд.
Выкрутасы с кодом с помощью макросов в мире C# невозможны.
Коммитить неработающий код и оставлять неработающий — зло, для этого есть VCS. В мире Git проблемы «надо хоть что-нибудь закоммитить в общий репозиторий, а то изменений уже на 1000 файлов», как в SVN, не существует. Подсветка кода
if (false) как проблемного — это благо для блока кода на стадии «WIP».Итого, остаётся только рефакторинг, а он по отдельности теряет смысл тоже.
Явно так и хотел — ок, но это же не означает, что conditional вдруг стал не always true/false.
Решарпер позволяет отключать конкретные диагностики. Мне кажется, это здравый консенсус.
Решарпер позволяет отключать конкретные диагностики. Мне кажется, это здравый консенсус.
Для вашего интереса (или интереса общественности):
В языке C это верно
А вот в С++ это
Может быть в Вашем случае тоже делалась проверка размера литерала, а не типа?
В языке C это верно
sizeof('A') == 4 А вот в С++ это
sizeof('A') == 1 Может быть в Вашем случае тоже делалась проверка размера литерала, а не типа?
Про sizeof('x') в Си мы конечно знаем. А имелось ровно то, что я написал. Во многих программах можно встретить код вида:
Первый попавшийся пример
static int ply_type_check(void) {
assert(sizeof(char) == 1);
assert(sizeof(unsigned char) == 1);
assert(sizeof(short) == 2);
assert(sizeof(unsigned short) == 2);
assert(sizeof(long) == 4);
assert(sizeof(unsigned long) == 4);
assert(sizeof(float) == 4);
assert(sizeof(double) == 8);
if (sizeof(char) != 1) return 0;
if (sizeof(unsigned char) != 1) return 0;
if (sizeof(short) != 2) return 0;
if (sizeof(unsigned short) != 2) return 0;
if (sizeof(long) != 4) return 0;
if (sizeof(unsigned long) != 4) return 0;
if (sizeof(float) != 4) return 0;
if (sizeof(double) != 8) return 0;
return 1;
}
Второй попавшийся пример
void WavOutFile::write(const char *buffer, int numElems)
{
int res;
if (header.format.bits_per_sample != 8)
{
throw runtime_error("Error: WavOutFile::write(const char*, int) accepts only 8bit samples.");
}
assert(sizeof(char) == 1);
res = fwrite(buffer, 1, numElems, fptr);
if (res != numElems)
{
throw runtime_error("Error while writing to a wav file.");
}
bytesWritten += numElems;
}
Третий попавшийся пример
static int
TIFFWriteDirectoryTagCheckedAscii(TIFF* tif, uint32* ndir, TIFFDirEntry* dir, uint16 tag, uint32 count, char* value)
{
assert(sizeof(char)==1);
return(TIFFWriteDirectoryTagData(tif,ndir,dir,tag,TIFF_ASCII,count,count,value));
}
А почему не хотите проверять при помощи sizeof(TEXT('a'))? Например:
#include <Windows.h>
#include <iostream>
#if UNICODE
#define TCOUT wcout
#else
#define TCOUT cout
#endif
using namespace std;
int main() {
PCTSTR str = sizeof(TEXT('a')) > 1 ? TEXT("Unicode") : TEXT("ANSI");
TCOUT << str << endl;
return 0;
}
У вас какой-то неправильный решарпер. 9.2 очень даже ругается на два повторяющихся условия:
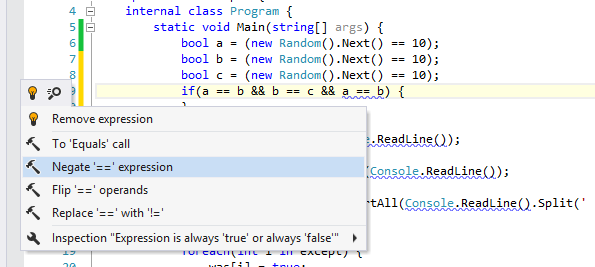

И на

if ('0' == 0x30 && 'A' == 0x41 && 'a' == 0x61)R# ругается по делу. Выражение же всегда true.
Теоретическая ошибка вовсе не повод выдавать сообщение. См. мои прочие комментарии.
Все строки в шарпе хранятся в юникоде (это их внутреннее представление). Вы не сможете придумать такую ситуацию (по крайней мере не хакая CLR), чтобы это выражение выдало false.
Вопрос в том, всегда ли первые 127 байт в кодировке, в которой написан текст программы — ASCII. Что там будет после компиляции, уже следующий этап.
На C конструкция if('я'==(char)255) вряд ли кого-нибудь удивит. Хотя в конкретном файле она всегда либо true, либо false, просто в разных системах увидят разную букву.
На C конструкция if('я'==(char)255) вряд ли кого-нибудь удивит. Хотя в конкретном файле она всегда либо true, либо false, просто в разных системах увидят разную букву.
Мы сейчас не про текст, а про строку. Если мы считываем файл, мы указываем кодировку, в которой читаем. Если строка уже в памяти, то она уже в юникоде, и соответственно однозначно определяется. Выражение if ('0' == 0x30) не изменяется между запусками и выдаст один ответ на любой машине с любой архитектурой, потому что это одно и то же с точки зрения спецификации языка.
Представьте себе, что программа набита на перфокартах в кодировке EBCDIC, в которой код нуля — 0xF0 (подозреваю, что проверка пришла примерно из тех времён). Чему будет равно значение '0'? Должен ли компилятор преобразовать символ из текста программы с кодом 0xF0 в символ из Unicode, и присвоить ему код 0x0030?
Должен ли компилятор преобразовать символ из текста программы с кодом 0xF0 в символ из Unicode, и присвоить ему код 0x0030?Если компилятор знает, что исходный файл в кодировке EBCDIC — да, должен. Если не знает — то будет ошибка компиляции…
Пример с русскими буквами интереснее. Там и правда возможно «недопонимание» компилятором кодировки исходного файла.
Чем вы кормите своего единорога, что он блюет постоянно? Недоделанным кодом, что ли?
когда планируется PVS-Studio для Си и С++ для микроконтроллеров и встраиваемых систем?
А то давно пора: мир IoT нагрянул, в промышленности тоже много крупных проектов, ребята из кейла вообще предлагают полноценные RTOS с веб сервисами чуть ли не с апачем и мускулом.
Объёмы кода пухнут на глазах, количество разработчиков тоже уже далеко не один на проект.
Если что могу примерами кода помочь и уделить Вам время.
А то давно пора: мир IoT нагрянул, в промышленности тоже много крупных проектов, ребята из кейла вообще предлагают полноценные RTOS с веб сервисами чуть ли не с апачем и мускулом.
Объёмы кода пухнут на глазах, количество разработчиков тоже уже далеко не один на проект.
Если что могу примерами кода помочь и уделить Вам время.
Ну, уже сейчас можно взять PVS-Studio в режиме standalone и натравливать на листинги после gcc.
два года назад пытался — PVS-Studio вообще не заработала (gcc + eclipse)
для железа кстати немного своя специфика, ради производительности или размера прошивки порой необходимо нарушать те принципы которые проверяет сама студия. А часть специфики связана с реалтаймом и заморочками самого железа. Т.е. нужно сделать профиль игнорирования ряда проверок например для ARM-Cortex Mx. И это в лучшем случае. Но я думаю что игнорированием части проверок не обойтись, например для АВР (где есть память программ и память данных и раздельные указатели разных видов и соответственно могут быть свои специфичные ошибки).
для железа кстати немного своя специфика, ради производительности или размера прошивки порой необходимо нарушать те принципы которые проверяет сама студия. А часть специфики связана с реалтаймом и заморочками самого железа. Т.е. нужно сделать профиль игнорирования ряда проверок например для ARM-Cortex Mx. И это в лучшем случае. Но я думаю что игнорированием части проверок не обойтись, например для АВР (где есть память программ и память данных и раздельные указатели разных видов и соответственно могут быть свои специфичные ошибки).
Тема конечно интересная. Я и сам балуюсь с микроконтроллерами. Но одно дело интерес, другое дело рациональная трата сил. С микроконтроллерами есть две беды:
- Масса микроконтроллеров, сред разработки, компиляторов со своими расширениями. Не понятно, что собственно поддерживать. С этой точки зрения с C# все на порядок проще и понятней. Делаем инструмент для Visual Studio и получаем клиентов.
- Все равно программы как правило малы и над проектом трудится в среднем 1-3 разработчиками (личные ощущения). Продать им PVS-Studio — трудно. В основном это продукт для средних и больших проектов. А идея с «индивидуальным» анализатором CppCat провалилась.
1. gcc будет достаточно на первое время в арм он покрывает много, и даже для авр немало кто пишут.
2. Рабочее место программиста — железячника стоит бешенных денег, один только осциллограф может стоить 100тр, а может лям.
А проекты бывают очень старые и обросшие. И их пишут коллективы. Просьба не судить только по своему уровню.
2. Рабочее место программиста — железячника стоит бешенных денег, один только осциллограф может стоить 100тр, а может лям.
А проекты бывают очень старые и обросшие. И их пишут коллективы. Просьба не судить только по своему уровню.
И самое главное — цена ошибки в прошивке крайне велика. Это десятки и сотни миллионов рублей.
Особенно если это нечто промышленное / медецинское / военное без возможности обновления самой прошивки.
Да и платёжеспособность в этих отраслях очень даже неплохая.
Особенно если сделаете проверку например по индустриальным стандартам и начнёте сотрудничать с организациями которые занимаются анализом качества кода и его сертификацией для МК в индустрии и медицине.
Особенно если это нечто промышленное / медецинское / военное без возможности обновления самой прошивки.
Да и платёжеспособность в этих отраслях очень даже неплохая.
Особенно если сделаете проверку например по индустриальным стандартам и начнёте сотрудничать с организациями которые занимаются анализом качества кода и его сертификацией для МК в индустрии и медицине.
И самое главное — цена ошибки в прошивке крайне велика. Это десятки и сотни миллионов рублей.
Особенно если это нечто промышленное / медецинское / военное
Или если это прошивка двигателя от фольксвагена :)
Слово «ошибка» здесь мало уместно.
А как насчёт забытого отладочного кода? Оставили какой-нибудь if(0), а включить в обычном режиме забыли.
Программеры WW ведь должны уметь препроцессор #ifdef _DEBUG
иначе я очень рад, что у меня бибика пыжик и на фольц не хватило денег.
иначе я очень рад, что у меня бибика пыжик и на фольц не хватило денег.
Сам факт того, что их ПО умеет детектить режим лабораторных испытаний, уже о многом говорит.
О чём же?
В Windows, например, есть стандартная функция IsDebuggerPresent. Точно такой же «детектор режима лабораторных испытаний».
В Windows, например, есть стандартная функция IsDebuggerPresent. Точно такой же «детектор режима лабораторных испытаний».
А вот и нифига.
Их софт детектирует по режиму вождения, что сейчас проводятся тесты.
geektimes.ru/post/263012
Их софт детектирует по режиму вождения, что сейчас проводятся тесты.
geektimes.ru/post/263012
Да, я знаю, что их софт делает.
Зачем он это делает — никто пока не знает наверняка.
Про навигатор от Яндекса, который записывал все разговоры, тоже думали, что это происки Большого Брата — а оказалась банальная халатность.
Зачем он это делает — никто пока не знает наверняка.
Никогда не приписывайте злому умыслу то, что вполне можно объяснить глупостью.
Про навигатор от Яндекса, который записывал все разговоры, тоже думали, что это происки Большого Брата — а оказалась банальная халатность.
Так это не совсем тот _DEBUG, а более глубокое тестирование… на реальных машинах.
cppcat как раз не умел микроконтроллеры :(
когда планируется PVS-Studio для Си и С++ для микроконтроллеров и встраиваемых систем?Статический анализатор кода PVS-Studio 6.22 адаптирован для ARM-компиляторов (Keil, IAR)
Windows 10 x64, MS VisualStudio 2015. Скачал триальный вариант PVS-Studio. Запукаю PVS-Studio_setup.exe, но ничего не происходит.
когда будет для java?
И для php полуйста!
plugins.jetbrains.com/plugin/7622 — без шуток)
Проснитесь и возьмите FindBugs.
Вы шутите, да?
FindBugs не нашел вот такой элементарной ошибки:
Вопрос: как я могу теперь доверять FindBugs, если он гонит такую лажу?
FindBugs не нашел вот такой элементарной ошибки:
public DoublePoint getAveragePoint(List<DoublePoint> points) {
double summeX = 0;
double summeY = 0;
for (DoublePoint point : points){
summeX = summeX = point.getX();
summeY = summeY = point.getY();
}
double averageX = summeX / points.size();
double averageY = summeY / points.size();
return new DoublePoint(averageX, averageY);
}
Вопрос: как я могу теперь доверять FindBugs, если он гонит такую лажу?
ой-йо-ой, надо через codestyle запретить 2-ый присваивания. Ошибка есть, конечно, но добавив один if она уже становится недектируемой.
Видимо, это всё-таки не считается за баг. А ловит FindBugs на самом деле много. Во-вторых, нервничать не стоит, а стоит написать авторам багрепорт/предложение. В-третих, IDEA такое место всё-таки посдвечивает сама, да и Eclipse, думаю, тоже найдёт.
Ни один анализатор не находит всех ошибок, поскольку это невозможно. Зачастую разработчики анализаторов решают, что их инструмент будет искать некоторое подмножество ошибок, которое не обнаруживается другими инструментами (компилятором, IDE), поскольку смысла в таком дублировании не много.
По конкретному примеру. Подобную опечатку, как уже упомянули, легко находят IDE. Пара простейших юнит-тестов аналогично решает проблему. В конце концов, в данном конкретном случае можно (было) использовать оператор +=, более явно отображающий смысл действия.
По конкретному примеру. Подобную опечатку, как уже упомянули, легко находят IDE. Пара простейших юнит-тестов аналогично решает проблему. В конце концов, в данном конкретном случае можно (было) использовать оператор +=, более явно отображающий смысл действия.
Мне абсолютно все равно как и что показывает IDE и какие тесты были или не были написаны. Я хочу запустить анализатор и получить хоть какой то вменяемый результат. Причем под вменяемым результатом я имею ввиду не «используйте здесь ArrayList вместо LinkedList потому что он быстрее», а действительно ошибки или подозрительные места. Если анализатор этого не делает, то он мне не нужен. FindBugs не нашел в нашем проекте ни ОДНОЙ ошибки, но зато кучу всяких мелочей как в примере с листами. Это тоже не плохо, но я ожидаю совсем другого. В общем, FindBugs это не анализатор в смысле поиска ошибок и мы от него ничего не ждем, поэтому я интересовался, когда будет версия PVS Studio под Java.
Попробуйте использовать IntellijIDEA — у неё помимо автоматической подсветки ошибок есть инспекция кода. Примерно так и работает: открываете проект, запускаете, получаете список ошибок. Довольно много реальных проблем находит, в том числе указанную вами. Другие инструменты JetBrains тоже таким инструментом обладают (PyCharm, CLion). Я не фанат IDE, но порой проверяю подобным образом свои и чужие проекты.
Вот результат инспекции вашего примера:
А вот, к примеру, коммит с правкой некоторых ошибок, найденных PyCharm в ipython: github. Сравнение с None с помощью == в Python не критично, но может привести к неприятным последствиям.
Вот результат инспекции вашего примера:
screenshot
А вот, к примеру, коммит с правкой некоторых ошибок, найденных PyCharm в ipython: github. Сравнение с None с помощью == в Python не критично, но может привести к неприятным последствиям.
Я боюсь вы меня не правильно понимаете.
Мне нужна дополнительная «линия обороны». И эта линия должна быть не зависимой от других, как например IDE и тесты. Этими линиями занимаются другие люди и в другое время. Меня интересуют ошибки, которые ведут к неправильному поведению кода и как следствие к неправильному результату. Проблемы типа «все медленно» меня не интересуют, мне нужен на выходе корректный результат. Придет этот результат через 100 мс или через час, мне абсолютно все равно. Поэтому я ищу абсолютно независимый анализатор(пусть даже как плагин к IDE), который ищет действительно ошибки, а не проблемы типа «это не эффективно» или «это не красиво».
Мне нужна дополнительная «линия обороны». И эта линия должна быть не зависимой от других, как например IDE и тесты. Этими линиями занимаются другие люди и в другое время. Меня интересуют ошибки, которые ведут к неправильному поведению кода и как следствие к неправильному результату. Проблемы типа «все медленно» меня не интересуют, мне нужен на выходе корректный результат. Придет этот результат через 100 мс или через час, мне абсолютно все равно. Поэтому я ищу абсолютно независимый анализатор(пусть даже как плагин к IDE), который ищет действительно ошибки, а не проблемы типа «это не эффективно» или «это не красиво».
Я понимаю.
Ну так вот, в IDEA как раз можно выбрать, какие типы ошибок вас интересуют, а какие нет. Да и во многих других анализаторах это настраивается. IDEA находит она сотни ошибок, вот одна из вкладок (вся не вошла):
Создаёте файл-профиль с интересными типами и периодически запускаете скрипт, публикуя отчёт где-нибудь в CI. Ниже пример запуска привёл.
Ну так вот, в IDEA как раз можно выбрать, какие типы ошибок вас интересуют, а какие нет. Да и во многих других анализаторах это настраивается. IDEA находит она сотни ошибок, вот одна из вкладок (вся не вошла):
screenshot
Создаёте файл-профиль с интересными типами и периодически запускаете скрипт, публикуя отчёт где-нибудь в CI. Ниже пример запуска привёл.
Да, а ещё у них обычно есть отдельный скрипт для запуска инспекции без запуска IDE. Можно настраивать профили инспекции, указывая только нужные вам проверки (чтобы не смотреть на ненужную вам «неэффективность»). Передаёте скрипту путь к проекту, профиль, и куда складывать результат. Он вам xml-ки сгенерит.
$ ./bin/inspect.sh ../IdeaProjects/untitled/ Project_Default report
Using default project profile
$ ls report/
CanBeFinal.xml SillyAssignment.xml SpellCheckingInspection.xml UnusedAssignment.xml unused.xml WeakerAccess.xml XmlUnboundNsPrefix.xml
А почему, собственно, «The value point.getY() assigned to 'summeY' is never used»? Конечно, используется только результат последнего присваивания, но ведь используется же?
Ну вот это позиция, с которой Andrey2008 с сотоварищами пытаются бороться. Запустил анализатор, пролистал список ошибок, не заметил ничего интересного, закрыл. Плохой анализатор, негодный. Ребята из PVS-Studio твердят, что статический анализ для повседневного пользования, а не для разовой проверки проекта, который уже был релизнут и пользователи его гоняют вовсю. Возможно, FindBugs нашёл бы вам некоторые баги через пару секунд после их появления, но вы их сами потом нашли через месяц, после того как департамент тестирования вам о них сообщил (все довольны, тестеры открыли больше тикетов, разработчики закрыли больше тикетов, работа кипит, зарплата капает, в отчётах есть что писать).
Пример с ArrayList мне непонятен. FindBugs не имеет такой диагностики. Но вообще мысль правильная, нечего использовать LinkedList.
FindBugs способен найти очень крутые и нетривиальные баги. Просто надо знать, с какой стороны читать отчёт.
Жалко только, что команда почти распалась и FindBugs очень медленно развивается. Если есть свободные художники, приходите, шлите патчи :-)
Пример с ArrayList мне непонятен. FindBugs не имеет такой диагностики. Но вообще мысль правильная, нечего использовать LinkedList.
FindBugs способен найти очень крутые и нетривиальные баги. Просто надо знать, с какой стороны читать отчёт.
Жалко только, что команда почти распалась и FindBugs очень медленно развивается. Если есть свободные художники, приходите, шлите патчи :-)
FindBugs реагирует на этот код, просто с низким приоритетом (почему-то):
Аналогично для summeY. У вас, наверно, по дефолту минимальный ранк или минимальный приоритет выставлены выше (что в принципе логично). Могу глянуть, возможно, имеет смысл поднять приоритет. Надо посмотреть, проанализировать, сколько таких багов выдаётся на опенсорсных проектах и много ли среди них ложных сработок. С другой стороны такую тривиальную багу любая IDE подсветит, хоть IDEA, хоть Eclipse. FindBugs не пытается сдублировать всё, что умеют все популярные IDE. Это у вас реальная проблема в коде или вы искусственно пример сконструировали? Вы IDE пользуетесь? Если пользуетесь, то странно, как такая бага могла у вас в коде вообще возникнуть…
Bug: Dead store to summeX in TestDoublePoint.getAveragePoint(List)
This instruction assigns a value to a local variable, but the value is not read or used in any subsequent instruction. Often, this indicates an error, because the value computed is never used.
Note that Sun's javac compiler often generates dead stores for final local variables. Because FindBugs is a bytecode-based tool, there is no easy way to eliminate these false positives.
Rank: Of Concern (20), confidence: Low
Pattern: DLS_DEAD_LOCAL_STORE
Type: DLS, Category: STYLE (Dodgy code)
Аналогично для summeY. У вас, наверно, по дефолту минимальный ранк или минимальный приоритет выставлены выше (что в принципе логично). Могу глянуть, возможно, имеет смысл поднять приоритет. Надо посмотреть, проанализировать, сколько таких багов выдаётся на опенсорсных проектах и много ли среди них ложных сработок. С другой стороны такую тривиальную багу любая IDE подсветит, хоть IDEA, хоть Eclipse. FindBugs не пытается сдублировать всё, что умеют все популярные IDE. Это у вас реальная проблема в коде или вы искусственно пример сконструировали? Вы IDE пользуетесь? Если пользуетесь, то странно, как такая бага могла у вас в коде вообще возникнуть…
Видимо, низкий приоритет как раз из-за этого:
Я думаю, это в современных версиях компилятора уже неактуально. Вероятно, можно будет поднять приоритет до нормального. Подумаем.
Note that Sun's javac compiler often generates dead stores for final local variables. Because FindBugs is a bytecode-based tool, there is no easy way to eliminate these false positives.
Я думаю, это в современных версиях компилятора уже неактуально. Вероятно, можно будет поднять приоритет до нормального. Подумаем.
Мы используем IDEA, на ней стоит плагин FindBugs(версия 3.0.0). Этот баг не был вообще найден(т.е. вот вообще, пишет для этого конкретного класса:
Баг возник потому что каждый совершил мелкую ошибку: разработчик проигнорировал сообщения IDE, ревьюер прогнал FindBugs и полностью ему доверился, а когда на код смотрел, ошибку так же не заметил, тестер не заметил, что для этой элементарной методы не был написан тест. В результате мы имеем то, что имеем. Штука в том, что теперь репутация FindBugsa у нас в фирме ниже плинтуса и этот случай теперь рассказывается из уст в уста как пример редкостной лажы.
FindBugs-IDEA: found 0 bugs in 1 class).
using FindBugs-IDEA 0.9.993.329-trunk with Findbugs version 3.0.0
Баг возник потому что каждый совершил мелкую ошибку: разработчик проигнорировал сообщения IDE, ревьюер прогнал FindBugs и полностью ему доверился, а когда на код смотрел, ошибку так же не заметил, тестер не заметил, что для этой элементарной методы не был написан тест. В результате мы имеем то, что имеем. Штука в том, что теперь репутация FindBugsa у нас в фирме ниже плинтуса и этот случай теперь рассказывается из уст в уста как пример редкостной лажы.
Третья версия должна была ловить это точно также. Тут, честно говоря, вы своих сотрудников больше выставляете с не самой лучшей стороны, чем FindBugs. Ну да, порылся в сорцах плагина (сам IDEA не пользуюсь), по умолчанию стоит MEDIUM priority. Если вы делаете инкрементальный анализ (то есть анализируете конкретный класс, коммит и т. д.), вполне разумно опустить порог до LOW: на одном классе мусор вполне можно проглядеть. Если ревьювер запускал FindBugs в IDEA, почему он предупреждения самой IDEA проигнорировал? Почему решили, что метод тривиальный и не написали тест? Тест сразу бы поставил всякие вопросы интересные. Например, что будет, если подадут на вход пустой список, точка с координатами (NaN, NaN) — это ожидаемый результат или нет? То есть мы имеем шесть косяков, причём отсутствие любого из них позволило бы выявить баг:
Баг не был выявлен, кто виноват? Естественно, FindBugs, он же у вас в конторе не работает и возмутиться не сможет.
- Лень разработчика (игнорирует серьёзные предупреждения IDE)
- Невнимательность ревьювера (ошибку-то глазами видно)
- Лень ревьювера (тоже игнорирует предупреждения IDE)
- Незнание ревьювером инструмента, которым он пользуется (окошко с настройками открывали хоть раз?)
- Лень тестера (зачем тест писать, и так всё просто)
- Слишком низкий приоритет предупреждения по умолчанию у FindBugs
Баг не был выявлен, кто виноват? Естественно, FindBugs, он же у вас в конторе не работает и возмутиться не сможет.
Ваш статический стиль не имеет никакого отношения к профессиональному программированию.
Проверьте меня
http://invo.jinr.ru/ginv/index.html
исходники, доки и руководство на русском и чужом английском присутствуют.
Не менялось примерно с 2007, и это не гордость, это просто.
Просто люблю профи.
Проверьте меня
http://invo.jinr.ru/ginv/index.html
исходники, доки и руководство на русском и чужом английском присутствуют.
Не менялось примерно с 2007, и это не гордость, это просто.
Просто люблю профи.
Имеет ли отношение к профессиональному программированию сравнение указателя с нулём с помощью оператора '<'? :)
Я ещё тот тролль, когда кто-то говорит что он профессионал и не допускает простых ошибок. Я готов к боям, а Вы? :))
const IVariables* depend() const { return mRealization->depend(); }
....
if (a.depend() < 0)
Я ещё тот тролль, когда кто-то говорит что он профессионал и не допускает простых ошибок. Я готов к боям, а Вы? :))
Я же Вам про это и писал. Вы что, C++ незнаете. Просмотрите пред историю,
что и откуда получается.
Статика это бред при сложной логике.
Про троллей что кликали, за свои слова надо отвечать. Кнопку-то нажать легко, а где мозг?
что и откуда получается.
Статика это бред при сложной логике.
Про троллей что кликали, за свои слова надо отвечать. Кнопку-то нажать легко, а где мозг?
Я Вас не понимаю. Прошу изложить Ваши мысли более развёрнуто.
А я Вас. У меня код несколько тысяч строк, Вы привели одну, и при этом не ответили к чему и почему.
Я за свою жизнь перечитал сотни тысяч чужого кода, иль больше, главное можно этой библиотекой пользоваться ли нет.
Язык, стиль или принцип программирования для меня не имеет значения. А как для статического анализа?
Я за свою жизнь перечитал сотни тысяч чужого кода, иль больше, главное можно этой библиотекой пользоваться ли нет.
Язык, стиль или принцип программирования для меня не имеет значения. А как для статического анализа?
Я жаворонок, а тут Вы. Я написал, что думаю, но получилось хамство, и не к Вам, а к нашему министру образования. Удалил.
Или у них нет шансов, как у и председателя центробанка. Но мы, чисто теоретически можем их простить? Или нет ТОВАРИЩ Иосиф Виссарионович?
Еще раз если Вы профи? отвечайте профессионально? Сколько «правилЪных» программ Ви напЫсали?
Или у них нет шансов, как у и председателя центробанка. Но мы, чисто теоретически можем их простить? Или нет ТОВАРИЩ Иосиф Виссарионович?
Еще раз если Вы профи? отвечайте профессионально? Сколько «правилЪных» программ Ви напЫсали?
Товарищу 50 лет, застрял во временах фортрана, алгола и перфокарт, а тут вы со своим C++ и статическим анализом лезете)
У вас есть претензии к алголу и перфокартам? :) И где бы вы без них сейчас были?
У меня совершенно никаких претензий. Всему свое время и своя ниша. У человека просто какие-то устаревшие представления которые он тут выражает в грубой форме.
Не только во времени дело. В том же Фортране нет ловушек со «скрытым» UB, как в плюсах. Именно к этому, как я понимаю, у него претензия.
Хотя форма подачи, конечно, возмутительна.
Хотя форма подачи, конечно, возмутительна.
Сначала я стал сомневаться, как будет работать, например, цикл DO по переменной, которая является параметром функции, если в функцию передан элемент COMMON-блока — гарантируется ли сихронизация. Потом вспомнил, что есть более надёжный пример UB — рекурсия. Которая формально запрещена, но компиляторы проверять её отсутствие не обязаны, так что если пользователь сумеет её устроить, то результат непредсказуем.
Которая формально запрещена, но компиляторы проверять её отсутствие не обязаны, так что если пользователь сумеет её устроить, то результат непредсказуем.
Дело, вероятно, в методе организации подпрограмм т.н. методом прямого копирования.
Я имею в виду не UB сам по себе, а связанную с этим оптимизацию. Когда, например, выкидывается блок кода после строки, возможно вызывающей UB.
Там дело в организации вызова подпрограмм, передачи параметров и адреса возврата. Фортран (по крайней мере, старые версии) устроен так, что может работать на бесстековых машинах, на полностью статической памяти. В отличие от большинства других языков… Так что может быть, без математики при его разработке не обошлось.
Я написал выше:
Дело, вероятно, в методе организации подпрограмм т.н. методом прямого копирования.
А что имеется в виду? Яндекс на эту фразу выдаёт какую-то ерунду, связанную с обработкой материалов.
Те компиляторы, которые мне попадались, организовывали вызов с помощью блока параметров — для каждого вызова создавался специальный участок памяти, заполненный адресами параметров. Некоторые адреса не менялись, другие модифицировались перед вызовом (когда передавался элемент массива).
Те компиляторы, которые мне попадались, организовывали вызов с помощью блока параметров — для каждого вызова создавался специальный участок памяти, заполненный адресами параметров. Некоторые адреса не менялись, другие модифицировались перед вызовом (когда передавался элемент массива).
Это значит, что при CALL PROC(A) никакие параметры не заталкиваются в стек/регистры, не сохраняется точка возврата и не происходит перехода.
Вместо CALL PROC(A) копируется тело самой процедуры. Т.е. процедура тех лет — фактически по-современному — макрос. Подстановка фактических параметров в формальные происходит на этапе компиляции.
Вместо CALL PROC(A) копируется тело самой процедуры. Т.е. процедура тех лет — фактически по-современному — макрос. Подстановка фактических параметров в формальные происходит на этапе компиляции.
Не могу поверить. Это даже для простейших программ давало бы экспоненциальный рост длины кода. Кроме того, библиотечные подпрограммы тоже как-то должны вызываться, а они не обязательно на фортране.
Не могу поверить. Это даже для простейших программ давало бы экспоненциальный рост длины кода.
Зато никаких временных затрат на вызов. Это реализация самой первой IBM версии, потом использовали уже стандартный вызов, но с поддержкой принципа копирования (т.е. все должно действовать так, будто бы есть прямое копирование, даже если используется стек). Отсюда и сквозные пар-ры во всех стандартах языка.
Кроме того, библиотечные подпрограммы тоже как-то должны вызываться, а они не обязательно на фортране.
Был период, когда обязательно. Или в машинных кодах. Для этого, ЕМНИП, был/есть оператор вызова по адресу.
Описание метода прямого копирования, ЕМНИП, было в руководстве к языку для машины ЕС в разделе истории языка.
Почему-то информацию пока удалось найти только в Вики, и там про Fortran II написано
Early FORTRAN compilers did not support recursion in subroutines. Early computer architectures did not support the concept of a stack, and when they did directly support subroutine calls, the return location was often stored in a single fixed location adjacent to the subroutine code, which does not permit a subroutine to be called again before a previous call of the subroutine has returned.
(в первой версии подпрограмм вообще не было). Понятие «адрес возврата» присутствует явно, даже если нет стека (да он для нерекурсивного вызова и не нужен).
Есть ли идеи, как «метод прямого копирования» мог называться по-английски?
Early FORTRAN compilers did not support recursion in subroutines. Early computer architectures did not support the concept of a stack, and when they did directly support subroutine calls, the return location was often stored in a single fixed location adjacent to the subroutine code, which does not permit a subroutine to be called again before a previous call of the subroutine has returned.
(в первой версии подпрограмм вообще не было). Понятие «адрес возврата» присутствует явно, даже если нет стека (да он для нерекурсивного вызова и не нужен).
Есть ли идеи, как «метод прямого копирования» мог называться по-английски?
Не знаю. В руководстве к FII ничего про это не сказано вообще.
Я заметил, что реализаций второго — до десятка, под каждую машину — свой. И не в каждом FII есть вызов своих подпрограмм по CALL, в зависимости от возможностей машины, для которой тот или иной транслятор написан.
Я допускаю, что это только один из вариантов.
К сожалению, точной информации привести не могу — как уже сказал, вычитал это в руководстве по языку для машины ЕС, так что покрыто пылью истории.
Вот еще в «Языки программирования» Пратт/Зелковиц есть отметка о том, что при реализации подпрограмм в стиле прямого копирования поведение должно быть таким, будто вместо вызова вставлено само тело подпрограммы, и это, мол. специфично для Фортрана.
Это, в принципе, логично: если для какой-то ограниченной машины пришлось применить такой экстравагантный способ реализации ПП, то конвенция вызова должна быть такой, чтобы и на более продвинутых машинах параметры вели себя так же — для переносимости и стандартизации языка.
Я заметил, что реализаций второго — до десятка, под каждую машину — свой. И не в каждом FII есть вызов своих подпрограмм по CALL, в зависимости от возможностей машины, для которой тот или иной транслятор написан.
Я допускаю, что это только один из вариантов.
К сожалению, точной информации привести не могу — как уже сказал, вычитал это в руководстве по языку для машины ЕС, так что покрыто пылью истории.
Вот еще в «Языки программирования» Пратт/Зелковиц есть отметка о том, что при реализации подпрограмм в стиле прямого копирования поведение должно быть таким, будто вместо вызова вставлено само тело подпрограммы, и это, мол. специфично для Фортрана.
Это, в принципе, логично: если для какой-то ограниченной машины пришлось применить такой экстравагантный способ реализации ПП, то конвенция вызова должна быть такой, чтобы и на более продвинутых машинах параметры вели себя так же — для переносимости и стандартизации языка.
По-моему, вот такое потянет на десяток разных UB.
P.S.: Бред однако, на хабр постить ссылку на перепост статьи с хабра, только потому, что на самом хабре ее уже не видно.
В фортране параметры передаются только по ссылке (указателю). Поэтому следует быть особо аккуратным при программировании передачи входного параметра. Входной параметр не должен перевычисляться в подпрограмме. Иначе при подстановке константы в качестве значения входного параметра по возвращении из подпрограммы константа будет испорчена.
P.S.: Бред однако, на хабр постить ссылку на перепост статьи с хабра, только потому, что на самом хабре ее уже не видно.
Да, компилятор не гарантирует, подставит ли он в разные вызовы ссылку на один и тот же экземпляр константы, или на разные. Поэтому, портиться они будут непредсказуемо.
Кстати, если написать
CALL F(1)
N=1
где F меняет свой параметр на двойку, то, скорее всего, в N окажется единица,
а если
CALL G(1.2)
X=1.2
— то в X будет двойка.
Но это, опять же, зависит от компилятора.
CALL F(1)
N=1
где F меняет свой параметр на двойку, то, скорее всего, в N окажется единица,
а если
CALL G(1.2)
X=1.2
— то в X будет двойка.
Но это, опять же, зависит от компилятора.
Это сильно зависит от конкретного компилятора. В MSовском такого не было, как в вашем примере с двумя вызовами.
В RSX на PDP-11/70 на Фортране-4 было. Он решил соптимизировать память, и копировал значение в X из того же места, на которое указывала ссылка из блока параметров вызова функции.
Может быть. В стандарте F77 указано четко, что константа меняться не может и что изменение внутри процедуры формального параметра, которому в соответствие ставится константа — недопустимое действие. Т.е. по идее, это должна быть ошибка этапа компиляции, если мы имеем код вида
и
то вызов А недопустим, потому что PAR1 изменяем. Но, конечно, не все трансляторы это могут отловить, потому что стыковка происходит уже в редакторе связей.
А так получается, что константа «1.2» — это вовсе никакое не число, а именованная константа, которая называется «один точка два» и численно равна 1.2. Т.е. логика вашего компилятора такова, что он считает, будто написано:
REAL*8 SOMECONST
SOMECONST = 1.2
CALL A(SOMECONST)
X=SOMECONST
т.е. он ловит только прямое присвоение в констанут как ошибку, а хитрое — через параметры или икваленс — нет.
SUBROUTINE A(PAR1)
REAL*8 PAR1
PAR1 = PAR1 + 1
RETURN
END
и
PROGRAM MAIN
CALL A(1.2)
END
то вызов А недопустим, потому что PAR1 изменяем. Но, конечно, не все трансляторы это могут отловить, потому что стыковка происходит уже в редакторе связей.
А так получается, что константа «1.2» — это вовсе никакое не число, а именованная константа, которая называется «один точка два» и численно равна 1.2. Т.е. логика вашего компилятора такова, что он считает, будто написано:
REAL*8 SOMECONST
SOMECONST = 1.2
CALL A(SOMECONST)
X=SOMECONST
т.е. он ловит только прямое присвоение в констанут как ошибку, а хитрое — через параметры или икваленс — нет.
Потому что параметры сквозные, это стандарт языка. Нет никаких «входных».
Подпрограмма — фактически макрос в ф., а не то, что мы называем подпрограммой обычно. В старых версиях, которые определяют стандарт. Отсюда и сквозные параметры — да нет на самом деле даже никаких параметров и передачи их.
Я говорил об оптимизации, связанной с UB, см. выше. Когда может быть выкинут кусок кода.
А то, что у языков есть особенности — это не обсуждается даже. У плюсов свои, у других — свои.
Подпрограмма — фактически макрос в ф., а не то, что мы называем подпрограммой обычно. В старых версиях, которые определяют стандарт. Отсюда и сквозные параметры — да нет на самом деле даже никаких параметров и передачи их.
Я говорил об оптимизации, связанной с UB, см. выше. Когда может быть выкинут кусок кода.
А то, что у языков есть особенности — это не обсуждается даже. У плюсов свои, у других — свои.
По стандарту константа — внезапно константа. Так что это косяк реализации.
Это в каком смысле — макрос? Если имеется в виду что-то вроде inline функций, то как подпрограммы могут передаваться параметрами в другие функции, и там успешно вызываться? Мы пользовались этим трюком для организации ассемблерных вставок (передавали массив с кодом, а принимали его, как функцию — и вызывали).
Утро. Тестостерона много, решил померится яйцами, если они конечно есть у присутствующих.
Я по молодости писал на Lisp, точнее на SLisp и RLisp (у него есть даже поддержка ООП).
У меня есть модуль в стандартной поставки Reduce.
Потом на C++ с Qt2, Qt3, если нужно GUI. Например у меня имеется эффективная реализация длинной арифметике на C++. В 1998 делала стандартный GMP 1.2
С 2005 полюбил Python (третий не нравится), PyQt4 (сейчас PySide).
Я например решил задачу сменно-суточного планирования для РЖД (до меня 30 лет ее 13 ВЦ по дороге не могли решить).
В 2001 решил задачу составления расписания
http://www.interface.ru/home.asp?artId=29844
http://www.norcom.ru/habrahabr/post/148232
Итого: не смотря мои коды, Вы просто тупо льете воду. Я знаю примерно за 40 языков
Вот ссылка на мою документацию по моей старой программе (больше 1000 страниц).
http://invo.jinr.ru/ginv/developer_ru/index.html
А перфокарты отлично служат пепельницами (я правда никогда не курил), тарелками и т.д.
За слово товарищ спасибо.
Я по молодости писал на Lisp, точнее на SLisp и RLisp (у него есть даже поддержка ООП).
У меня есть модуль в стандартной поставки Reduce.
Потом на C++ с Qt2, Qt3, если нужно GUI. Например у меня имеется эффективная реализация длинной арифметике на C++. В 1998 делала стандартный GMP 1.2
С 2005 полюбил Python (третий не нравится), PyQt4 (сейчас PySide).
Я например решил задачу сменно-суточного планирования для РЖД (до меня 30 лет ее 13 ВЦ по дороге не могли решить).
В 2001 решил задачу составления расписания
http://www.interface.ru/home.asp?artId=29844
http://www.norcom.ru/habrahabr/post/148232
Итого: не смотря мои коды, Вы просто тупо льете воду. Я знаю примерно за 40 языков
Вот ссылка на мою документацию по моей старой программе (больше 1000 страниц).
http://invo.jinr.ru/ginv/developer_ru/index.html
А перфокарты отлично служат пепельницами (я правда никогда не курил), тарелками и т.д.
За слово товарищ спасибо.
Батюшка, у вас все мысли путаются, куда вам ещё код писать!
Отзовите своих дебилов. Или разговора не будет.
До завтра.
До завтра.
Ребята посмотрите исходники!
А пусть Андрей2008 думает как и что сравнить!
Все в пределах правил. Там работает полиморфизм, а возвращение const УКАЗАТЕЛЯ для const класса их программы это вообще взрыв мозга.
Пока.
А пусть Андрей2008 думает как и что сравнить!
Все в пределах правил. Там работает полиморфизм, а возвращение const УКАЗАТЕЛЯ для const класса их программы это вообще взрыв мозга.
Пока.
Следует немного проще относиться к Хабру — тут, в принципе, неплохие люди, но «понтов» никто не любит, и бить себя в грудь и говорить, что ты круче других заведомо обречено на провал…
А если по-честному, тоже из любопытства посмотрел код, первый файл, который открыл, можно увидеть ниже, под спойлом. Сразу есть замечания:
1. Если удаляете динамическую память по выходу из функции, то лучше использовать scoped pointers. Для цикла тоже актуально!
2. В конце main'a так-то и необязательно явно удалять память, ОС почистит за процессом (при переносе кода в другое место может выстрелить в ногу).
3. Скачет выравнивание — то 4 символа, то два.
4. Старые комментарии в коде — плохой стиль, занимают большой процент функции.
5. Вроде бы название файла не особо соответствует смысловой нагрузке, хотя это я мог не особо вдумчиво читать.
В общем по моему скромному мнению это не выглядит, как код профи :)
А если по-честному, тоже из любопытства посмотрел код, первый файл, который открыл, можно увидеть ниже, под спойлом. Сразу есть замечания:
1. Если удаляете динамическую память по выходу из функции, то лучше использовать scoped pointers. Для цикла тоже актуально!
2. В конце main'a так-то и необязательно явно удалять память, ОС почистит за процессом (при переносе кода в другое место может выстрелить в ногу).
3. Скачет выравнивание — то 4 символа, то два.
4. Старые комментарии в коде — плохой стиль, занимают большой процент функции.
5. Вроде бы название файла не особо соответствует смысловой нагрузке, хотя это я мог не особо вдумчиво читать.
В общем по моему скромному мнению это не выглядит, как код профи :)
Код memory_leak.cpp
int main() {
IVariables* polyvars = new IVariables();
polyvars->add("x[1]");
polyvars->add("x[-1]");
// polyvars->add("x[2]");
// polyvars->add("x[-2]");
// polyvars->add("x[1,2]");
// polyvars->add("x[-1,2]");
// polyvars->add("x[-2,1]");
// polyvars->add("x[-2,-1]");
// polyvars->add("x[com]");
ISystemType* st = new ISystemType(ISystemType::Polynomial, 0, 0);
IMonomInterface* im = IMonomInterface::create(
IMonomInterface::DegRevLex, st, polyvars);
ICoeffInterface* ic = ICoeffInterface::create(ICoeffInterface::GmpZ, st);
IPolyInterface* ip = IPolyInterface::create(
IPolyInterface::PolyList, st, im, ic);
IWrapInterface* iw = IWrapInterface::create(IWrapInterface::C1C2C3, ip);
IDivisionInterface* id = IDivisionInterface::create(
IDivisionInterface::Janet, iw);
std::stringstream ss;
for (int i = 0; i < 1; i++) {
ISetQ *setQ = new ISetQ(iw, 0);
ss << "x[1] + " << i;
setQ->insert(getPoly(ip, ss.str()));
ss.str("");
ss << "x[-1] + " << i;
setQ->insert(getPoly(ip, ss.str()));
ss.str("");
// ss << "x[2] + " << i;
// setQ->insert(getPoly(ip, ss.str()));
// ss.str("");
// ss << "x[-2] + " << i;
// setQ->insert(getPoly(ip, ss.str()));
// ss.str("");
// ss << "x[1,2] + " << i;
// setQ->insert(getPoly(ip, ss.str()));
// ss.str("");
// ss << "x[-1,2] + " << i;
// setQ->insert(getPoly(ip, ss.str()));
// ss.str("");
// ss << "x[-2,1] + " << i;
// setQ->insert(getPoly(ip, ss.str()));
// ss.str("");
// ss << "x[-2,-1] + " << i;
// setQ->insert(getPoly(ip, ss.str()));
// ss.str("");
IAlgorithm* algorithm = new IAlgorithmTQDegree(
setQ, id->create(), 0, 1, 0, 1, 0, 0, 0);
algorithm->build();
delete algorithm;
delete setQ;
}
delete id;
delete iw;
delete ip;
delete ic;
delete im;
delete st;
delete polyvars;
}
> 2. В конце main'a так-то и необязательно явно удалять память, ОС почистит за процессом (при переносе кода в другое место может выстрелить в ногу).
Такой совет и без переноса в другое место будет постреливать.
Вы теряете вызов деструкторов, код в которых может иметь «побочные эффекты»
и выполнять обязательные действия не связанные с памятью, но важные для корректного закрытия процесса.
Такой совет и без переноса в другое место будет постреливать.
Вы теряете вызов деструкторов, код в которых может иметь «побочные эффекты»
и выполнять обязательные действия не связанные с памятью, но важные для корректного закрытия процесса.
А мне как-то все равно, я не в том возрасте, умный услышит, глупый не поймет, хоть и «в принципе неплохой людЪ». Тем более на Хабре в основном подростки и я просто тупо хочу донести до них информацию.
Файл Вы открыли тот, какой поменьше?
Код не мой, его один немец набирал, беря из моего, и чисто для отладки. Он любит отступ 4, а я в два пробела. Точнее ему было лень перенастраивать редактор. Он и дал название, поскольку этот пакет рассчитан на вычисления с динамическими структурами и на вычисления, которые длятся неделями утечки памяти очень важны, а у него была машина с 128 гигов примерно в 2004 году и было интересно это проверить.
Я как-то писал на Хабре про «сборку мусора» на C++, потом удалил из-за срача людей, которым прочитали лекции по азам программирования и они потом возомнили себя специалистами.
Файл Вы открыли тот, какой поменьше?
Код не мой, его один немец набирал, беря из моего, и чисто для отладки. Он любит отступ 4, а я в два пробела. Точнее ему было лень перенастраивать редактор. Он и дал название, поскольку этот пакет рассчитан на вычисления с динамическими структурами и на вычисления, которые длятся неделями утечки памяти очень важны, а у него была машина с 128 гигов примерно в 2004 году и было интересно это проверить.
Я как-то писал на Хабре про «сборку мусора» на C++, потом удалил из-за срача людей, которым прочитали лекции по азам программирования и они потом возомнили себя специалистами.
Хоспади, и тут пидарасы отметились.
Не надо путать нормальных людей с умалишенными комментаторами. Это Интернет, такое случается…
… я просто оставлю эту ссылку здесь: lurkmore.to/Шизофазия
Вот почитал статью по ссылке и заметил, что один пример мне показался странно знаком:
И как раз что-то похожее я видел вчера в комментариях камрада bya, в обсуждении вируса:
Выходит, мы таки зря заминусовали человека? он ведь болен, ему нужна помощь, а мы его в RO…
А может даже по почте слал там длинный эмэйл точнее слал но не помню из-за чего вышло. Нажал на кнопочку выключить и безвозвратно удалил программы не установило программы с сайта нет скачки смотрел пару клипов кино почему-то кусочек
И как раз что-то похожее я видел вчера в комментариях камрада bya, в обсуждении вируса:
Моей программой по составлению расписаний в вузах многие пользуются, исходники потеряны под XP в 2001. Почта их не отправляет, выкладка на сайт не помогает, google и yandex диск не принимает, только через dropbox пока получается.
Выходит, мы таки зря заминусовали человека? он ведь болен, ему нужна помощь, а мы его в RO…
Простите, а bya это точно не чья то попытка пройти тест Тьюринга? И судя по тому, что этот генератор текста считают живым человеком, не так плохо и проходит;)
А вы пробовали сравнивать свой анализатор на каком-то большом проекте чтобы оценить True Positives и False Positives по сравнению с Coverity?
Такого сравнения нет. Это очень сложная, дорогая и неблагодарная работа. Мы даже не пытаемся её сделать. По факту будет потрачено много сил, за что как всегда получим тонны негатива и критики о том, что мы всё неправильно сравниваем, что мы предвзяты и так далее. Только ленивый не критиковал ту статью о сравнении, хотя мы подробно объяснили, как всё непросто. Прошу только внимательно читать эти статьи, чтобы понять нас.
ну а как-то самостоятельно сравнить можно? Не покупая продукт.
Да, Вы можете посмотреть как работает наш анализатор. На сайте доступна демонстрационная версия. У неё есть ограничение по количеству переходов по строчкам кода с потенциальными багами. Как правило, этого достаточно для первого знакомства. Если Вы хотите более подробно исследовать наш инструмент, Вы можете написать к нам в поддержку и мы предоставим ключ на несколько дней.
Давно пора уже было на сишарпников переходить. У них денег больше водится.
Продолжение темы: Первая статья про проверку C# проекта.
Ложное срабатывание
Смысл этого кода — достать из nHibernate-сессии некоторые сущности
return Session.List<Order>(aCriteria).Select(x => Session.Get<OrderEx>(x.Id)).Where(x => x!=null).ToList();V3022 Expression 'x!=null' is always true.Смысл этого кода — достать из nHibernate-сессии некоторые сущности
Order, затем попытаться по-get-ить сущности OrderEx, и последний Where должен отсеять те случаи, где Get<OrderEx>(x.Id) вернул null.Не хочет проверять файлы в проекте, который был подключён к Solution уже после его создания (через Add Existing Project).
И как отключить конкретный тип предупреждений?
И как отключить конкретный тип предупреждений?
Возможно, вы не сохранили файл solution'а? PVS-Studio читает этот файл независимо от студии.
Для отключения предупреждений — меню PVS-Studio|Options...|Detectable Errors (C#).
Для отключения предупреждений — меню PVS-Studio|Options...|Detectable Errors (C#).
Сейчас открыл снова — результат тот же самый: в проекте, созданном вместе с solution, ошибки находит, а в подключённом позже — нет. Более того, в проекте, созданном по New Project, ошибки тоже не видны.
Может быть, дело в том, что директории, в которых лежат проекты, раскиданы по диску как попало, и с директорией, где лежит sln-файл, никак не связаны?
Может быть, дело в том, что директории, в которых лежат проекты, раскиданы по диску как попало, и с директорией, где лежит sln-файл, никак не связаны?
Проекты добавлены в sln файле через относительные пути? В первых версиях PVS-Studio C# была проблема с тем, что не проверялись проекты, заданные через относительные пути. Попробуйте проверить в последней версии, доступной на files.viva64.com/beta/PVS-Studio_setup.exe.
Спасибо, заработало. Получилось немного: 450 предупреждений на 2000 файлов.
Это нормально. Ведь основной эффект в регулярном использовании, а не в разовых запусках. Разовый запуск показывает, что анализатор работоспособен и может находить ошибки, но не более того. Подробнее: www.viva64.com/ru/b/0105
(Прощу прощения, но буду сейчас эту мысль везде приписывать, так как C#-аудитория новая для нас :)
(Прощу прощения, но буду сейчас эту мысль везде приписывать, так как C#-аудитория новая для нас :)
Новая статья о проверке Microsoft Code Contracts
Sign up to leave a comment.
Первый вздох PVS-Studio для C#