На первом в истории полностью виртуальном мероприятии РИТ++, прошедшем в конце мая, инженер Qrator Labs — Георгий Тарасов, рассказал публике про веб-скрейпинг, он же парсинг, популярным языком. Мы решили предоставить вашему вниманию транскрипцию выступления. Видео в конце публикации.

Всем привет! Наша компания достаточно давно занимается проблематикой защиты от DDoS-атак, и в процессе этой работы мне удалось достаточно подробно познакомиться со смежными сферами — изучить принципы создания ботов и способы их применения. В частности — web scraping, то есть массовый сбор публичных данных с веб-ресурсов с использованием ботов.
В какой-то момент эта тема меня необычайно увлекла многообразием прикладных задач, в которых скрейпинг с успехом используется. Здесь надо отметить, что наибольший интерес для меня представляет «темная сторона» веб-скрейпинга, то есть вредные и плохие сценарии его использования и негативные эффекты, которые он может оказать на веб-ресурсы и бизнес, с ними связанный.
При этом в силу специфики нашей работы чаще всего именно в такие (плохие) кейсы приходилось подробно погружаться, изучая интересные детали. И результатом этих погружений стало то, что мой энтузиазм передался коллегам — мы реализовали свое решение по отлову нежелательных ботов, ну а у меня накопилось достаточно историй и наблюдений, которые составят интересный, надеюсь, для вас материал.

Я буду рассказывать о следующем:
Начнем с безобидного гипотетического сценария — представим, что вы студент, завтра утром у вас защита курсовой работы, у вас по материалам «конь не валялся», не хватает ни цифр, ни выдержек, ни цитат — и вы понимаете, что за оставшуюся часть ночи перелопатить всю эту базу знаний вручную у вас нет ни времени, ни сил, ни желания.
Поэтому, по совету старших товарищей, вы расчехляете питоновскую командную строку и пишете простой скрипт, который принимает на вход URL’ы, ходит туда, загружает страницу, парсит контент, находит в нем интересующие ключевые слова, блоки или цифры, складывает их в файлик или в табличку и идет дальше.
Заряжаете в этот скрипт необходимое количество вам адресов научных публикаций, онлайн-изданий, новостных ресурсов — он быстро все перебирает, складывая результаты. Вам же остается только по ним нарисовать графики и диаграммы, таблицы — а на следующее утро с видом победителя получаете свой заслуженный балл.
Давайте подумаем — сделали ли вы кому-нибудь в процессе плохо? Ну, если только вы не парсили HTML регулярным выражением, то скорее всего никому плохо вы не сделали, а тем более сайтам, на которые вы таким образом сходили. Это однократная деятельность, ее можно назвать скромной и незаметной, и вряд ли кто-то пострадал от того, что вы пришли, быстро и незаметно схватили необходимый вам кусочек данных.
С другой стороны — будете ли делать это снова, если все получилось в первый раз? Давайте признаемся — скорее всего, будете, потому что вы только что сэкономили кучу времени и ресурсов, получив, скорее всего, даже больше данных, чем изначально рассчитывали. И это не ограничивается только научными, академическими или общеобразовательными изысканиями.

Потому что информация стоит денег, а вовремя собранная информация стоит еще больших денег. Именно поэтому скрейпинг является серьезной статьей заработка для большого количества людей. Это популярная тема на фрилансе: зайдите и увидите кучу заказов с просьбой собрать те или иные данные или написать скрейпинговый софт. Также есть коммерческие организации, занимающиеся скрейпингом на заказ или предоставляющие платформы для этой активности, так называемый scraping as a service. Такое многообразие и распространение возможно, в том числе и потому, что скрейпинг сам по себе чем-то нелегальным, предосудительным, не является. С правовой точки зрения к нему очень трудно придраться — особенно на текущий момент, мы скоро узнаем почему.

Для меня особый интерес представляет еще и то, что в техническом плане бороться со скрейпингом вам никто не может запретить — это создает интересную ситуацию, в которой участники процесса по обе стороны баррикад имеют возможность в публичном пространстве обсуждать техническую и организационную сторону этого дела. Двигать вперед, в некоторой степени, инженерную мысль и вовлекать в этот процесс все больше людей.

С точки зрения правовых аспектов, ситуация, которую мы сейчас рассматриваем — с дозволенностью скрейпинга, не всегда была такой ранее. Если мы немного посмотрим на хронологию достаточно хорошо известных судебных исков, связанных со скрейпингом, то увидим, что еще на его заре первым иском была претензия компании eBay к скрейперу, который собирал данные с аукционов, и суд запретил ему заниматься этой деятельностью. Дальнейшие 15 лет статус-кво более-менее сохранялся — крупные компании выигрывали суды против скрейперов, когда обнаруживали их воздействие. Facebook и Craigslist, а также некоторые другие компании отметились исками, закончившимися в их пользу.
Однако год назад все внезапно изменилось. Суд счел, что претензия LinkedIn к компании, собиравшей публичные профили пользователей и резюме, является необоснованной, оставил без внимания письма и угрозы с требованием остановить активность. Суд постановил, что сбор публичных данных, вне зависимости от того, делает его бот или человек, не может быть основанием для претензии со стороны компании, демонстрирующей эти публичные данные. Такой мощный юридический прецедент сместил баланс в пользу скрейперов и позволил большему количеству людей проявлять, демонстрировать и пробовать собственный интерес в данной области.
Однако, глядя на все эти в целом безобидные вещи, не стоит забывать, что у скрейпинга много и негативных применений — когда данные собираются не просто для дальнейшего использования, но в процессе реализуется идея нанесения какого либо ущерба сайту, или бизнесу который за ним стоит, либо попытки обогатиться каким-то образом за счет пользователей целевого ресурса.
Посмотрим на несколько знаковых примеров.

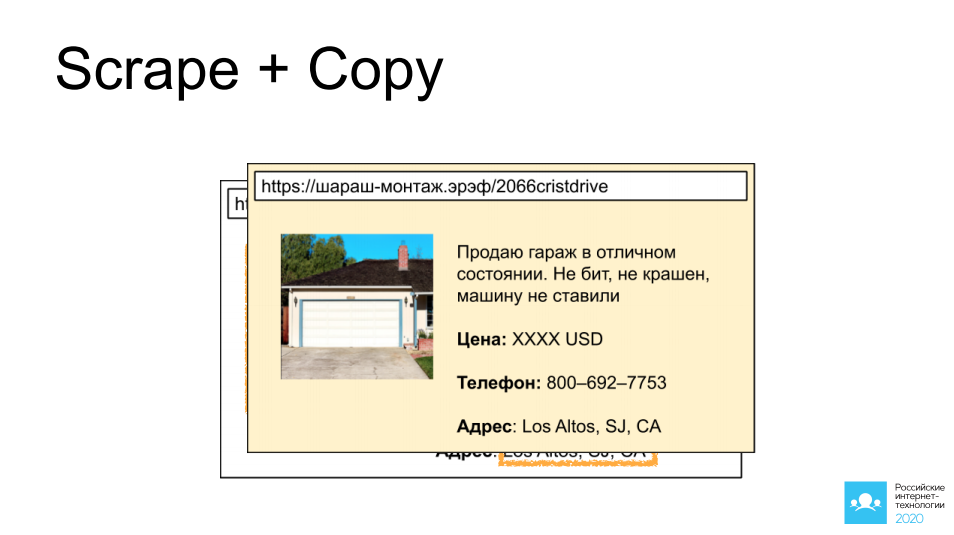
Первым из которых является скрейпинг и копирование чужих объявлений с сайтов, которые предоставляют доступ к таким объявлениям: автомобили, недвижимость, личные вещи. Я в качестве примера выбрал замечательный гараж в Калифорнии. Представьте, что мы натравливаем туда бота, собираем картинку, собираем описание, забираем все контактные данные, и через 5 минут это же объявление у нас висит на другом сайте похожей направленности и, вполне возможно, что выгодная сделка произойдет уже через него.
Если мы немножечко здесь включим воображение и подумаем в соседнюю сторону — что если этим занимается не наш конкурент, а злоумышленник? Такая копия сайта может хорошо пригодиться чтобы, для примера, затребовать с посетителя предоплату, или просто предложить ввести данные платежной карты. Дальнейшее развитие событий вы можете представить самостоятельно.
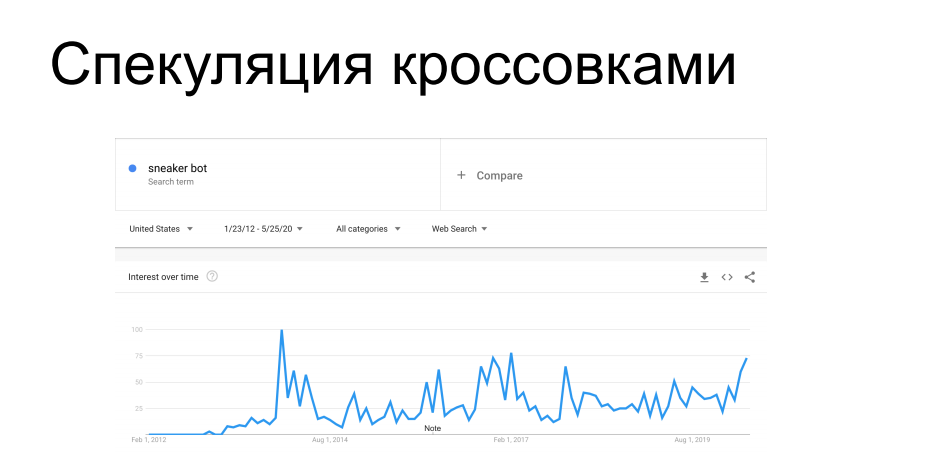
Другой интересный случай скрейпинга это скупка товаров ограниченной доступности. Производители спортивной обуви, такие, как Nike, Puma и Reebok, периодически запускают кроссовки лимитированных и т.н. сигнатурных серий — за ними охотятся коллекционеры, они находятся в продаже ограниченное время. Впереди покупателей на сайты обувных магазинов прибегают боты и сгребают весь тираж, после чего эти кроссовки всплывают на сером рынке с совершенно другим ценником. В свое время это взбесило вендоров и ритейл, который их распространяет. Уже 7 лет они борются со скрейперами и т.н. сникер-ботами с переменным успехом, как техническими, так и административными методами.

Вы наверняка слышали истории, когда при онлайн покупке требовалось лично прийти в магазин кроссовок, или про honeypot с кроссовками за $100k, которые бот скупал не глядя, после чего его владелец хватался за голову — все эти истории находятся в этом тренде.
И ещё один похожий случай — это исчерпание инвентаря в онлайн-магазинах. Он похож на предыдущий, но в нем никаких покупок на деле не производится. Есть онлайн-магазин, и определенные позиции товаров, которые приходящие боты сгребают в корзину в том количестве, которое отображается как доступное на складе. В итоге легитимный пользователь, пытающийся купить товар, получает сообщение о том, что данного артикула нет в наличии, огорченно чешет затылок и уходит в другой магазин. Сами же боты после этого сбрасывают набранные корзины, товар возвращается в пул — а тот, кому он был нужен, приходит и заказывает. Или не приходит и не заказывает, если это сценарий мелких пакостей и хулиганства. Отсюда видно, что даже если прямого финансового ущерба онлайн-бизнесу такая деятельность не наносит, то она как минимум может серьезно покорежить бизнес метрики, на которые будут ориентироваться аналитики. Такие параметры, как конверсия, посещаемость, востребованность товара, средний чек корзины — все они будут сильно испачканы действиями ботов по отношению к этим товарным позициям. И перед тем, как эти метрики брать в работу, их придется старательно и кропотливо очищать от воздействия скрейперов.
Помимо такой бизнес направленности, есть и вполне заметные технические эффекты, возникающие от работы скрейперов — чаще всего, когда скрейпинг делается активно и интенсивно.
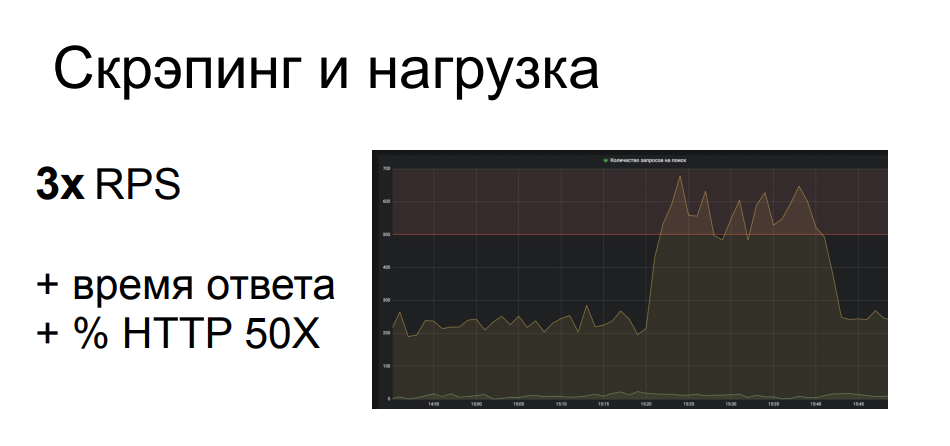
Один из примеров из нашей практики у одного из клиентов. Скрейпер пришел на локацию с параметризованным поиском, который является одной из самых тяжелых операций в бэкенде рассматриваемой структуры. Скрейперу понадобилось перебрать достаточно много поисковых запросов, и он из 200 RPS к этой локации сделал почти 700. Это серьезно нагрузило часть инфраструктуры, из-за чего пошла деградация качества сервиса для остальных легитимных пользователей, взлетело время ответа, посыпались 502-е и 503-и ошибки. В общем, скрейпера это ничуть не волновало и он сидел и делал свое дело, пока все остальные судорожно обновляли страничку браузера.
Отсюда видно, что такая активность может вполне классифицироваться как прикладная DDoS-атака — и зачастую так оно и бывает. Особенно если онлайн-магазин не такой большой, не имеет многократно зарезервированной по производительности и расположению инфраструктуры. Такая активность вполне может если не положить ресурс полностью — скрейперу это не очень выгодно, так как он в данном случае не получит свои данные — то заставить всех остальных пользователей серьезно огорчиться.
Но, помимо DDoSа, у скрейпинга есть еще интересные соседи из сферы киберпреступности. Например, перебор логинов-паролей использует похожую техническую базу, то есть с помощью тех же самых скриптов это можно делать с упором на скорость и производительность. Для credential stuffing используют наскрейпленные откуда-то пользовательские данные, которые засовываются в поля форм. Ну и тот пример с копированием контента и выкладыванием его на похожих сайтах — это серьезная подготовительная работа для того, чтобы подсовывать фишинговые ссылки и заманивать ничего не подозревающих покупателей.
Для того чтобы понять как разные варианты скрейпинга могут с технической точки зрения повлиять на ресурс попробуем посчитать вклад отдельных факторов в эту задачу. Займемся некоторой арифметикой.
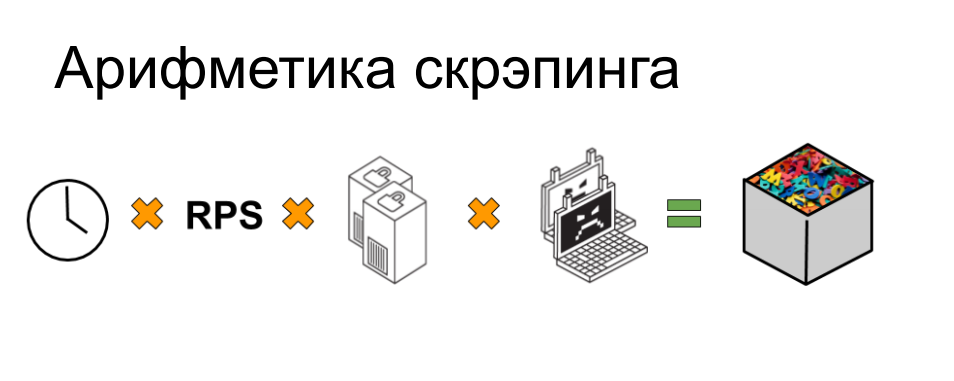
Представим, что у нас справа куча данных, которые нам нужно собрать. У нас есть задача или заказ выгрести 10 000 000 строчек товарных позиций, ценники например или котировки. И в левой части у нас есть бюджет времени, так как завтра или через неделю эти данные заказчику будут уже не нужны — они устареют, придется собирать их снова. Поэтому нужно уложиться в некоторый таймфрейм и, используя собственные ресурсы, сделать это оптимальным образом. У нас есть некоторое количество серверов — машин и айпи-адресов, за которыми они находятся, с которых мы будем ходить на интересующий нас ресурс. У нас есть некоторое количество инстансов пользователей, которыми мы прикидываемся — есть задача убедить онлайн-магазин или некоторую публичную базу в том, что это разные люди или разные компьютеры ходят за какими-то данными, чтобы у тех, кто будет анализировать логи, не возникало подозрений. И у нас есть некоторая производительность, интенсивность запросов, с одного такого инстанса.
Понятно, что в простом кейсе — одна хост-машина, студент с ноутбуком, перебирающий Washington Post, будет сделано большое количество запросов с одними и теми же признаками и параметрами. Это будет очень хорошо заметно в логах, если таких запросов будет достаточно много — а значит найти и забанить, в данном случае по айпи адресу, легко.
По мере усложнения скрейпинговой инфраструктуры появляется большее количество айпи адресов, начинают использоваться прокси, в том числе домовые прокси — о них чуть попозже. И мы начинаем мультиинстансить на каждой машине — подменять параметры запросов, признаки которые нас характеризуют, с той целью, чтобы в логах все это дело размазалось и было не столь бросающимся в глаза.
Если мы продолжаем в эту же сторону, то у нас появляется возможность в рамках этого же уравнения уменьшать интенсивность запросов с каждого такого инстанса — делая их более редкими, более эффективно их ротируя, чтобы запросы от одних и тех же пользователей не попадали рядом в логи, не вызывая подозрений и будучи похожими на конечных (легитимных) пользователей.
Ну и есть граничный случай — у нас в практике один раз был такой кейс, когда к заказчику пришел скрейпер с большого количества IP-адресов с совершенно разными признаками пользователей за этими адресами, и каждый такой инстанс сделал ровно по одному запросу за контентом. Сделал GET на нужную страничку товара, спарсил ее и ушел — и больше ни разу не появлялся. Такие кейсы довольно редки, так как для них нужно задействовать бóльшие ресурсы (которые стоят денег) за то же самое время. Но при этом отследить их и понять, что кто-то вообще приходил сюда и скрейпил, становится намного сложнее. Такие инструменты для исследования трафика, как поведенческий анализ — построение паттерна поведения конкретного пользователя, сильно усложняются. Ведь как можно делать поведенческий анализ, если нет никакого поведения? Нет истории действий пользователя, он ранее никогда не появлялся и, что интересно, больше с тех пор тоже ни разу не пришел. В таких условиях, если мы не пытаемся на первом же запросе что-то сделать, то он получит свои данные и уйдет, а мы останемся ни с чем — задачу по противодействию скрейпингу мы здесь не решили. Поэтому единственная возможность — это по первому же запросу догадаться, что пришел не тот, кого мы хотим видеть на сайте, и отдать ему ошибку или другим способом сделать так, чтобы он свои данные не получил.
Для того чтобы понять, как можно двигаться по этой шкале усложнения в построении скрейпера, посмотрим на арсенал, которым обладают создатели ботов, который чаще всего применяется — и на какие категории его можно разделить.

Первичная, самая простая категория, с которой большинство читателей знакомы — это скриптовый скрейпинг, использование достаточно простых скриптов для того, чтобы решать относительно сложные задачи.

И данная категория является, пожалуй, самой популярной и подробно задокументированной. Даже сложно порекомендовать, что конкретно читать, потому что, реально, материала море. Куча книжек написана по этому методу, есть масса статей и публикаций — в принципе достаточно потратить 5 / 4 / 3 / 2 минуты (в зависимости от нахальства автора материала), чтобы спарсить свой первый сайт. Это логичный первый шаг для многих, кто начинает в веб-скрейпинге. “Starter pack” такой деятельности это чаще всего Python, плюс библиотека, которая умеет делать запросы гибко и менять их параметры, типа requests или urllib2. И какой-нибудь HTML-парсер, чаще всего это Beautiful Soup. Также есть вариант использовать либы, которые созданы специально для скрейпинга, такие, как scrapy, которая включает в себя все эти функциональности с удобным интерфейсом.
С помощью нехитрых трюков можно прикидываться разными девайсами, разными пользователями, даже не имея возможности как-то масштабировать свою деятельность по машинам, по айпи адресам и по разным аппаратным платформам.

Для того чтобы сбить нюх у того, кто инспектирует логи на стороне сервера, с которого собираются данные, достаточно подменять интересующие параметры — и делать это нетрудно и недолго. Посмотрим на пример кастомного лог-формата для nginx — мы записываем айпишник, TLS-информацию, интересующие нас хедеры. Здесь, конечно, не все, что обычно собирается, но данное ограничение необходимо нам для примера — посмотреть на подмножество, просто потому что все остальное еще проще «подкинуть».
Для того, чтобы нас не банили по адресам, мы будем использовать residential proxy, как их называют за рубежом — то есть, прокси с арендованных (или взломанных) машин в домовых сетях провайдеров. Понятно, что забанив такой айпи адрес, есть шанс забанить какое-то количество пользователей, которые в этих домах живут — а там вполне могут оказаться посетители вашего сайта, так что иногда делать такое себе дороже.
TLS-информацию также не сложно подменить — взять наборы шифров популярных браузеров и выбрать тот, который понравится — наиболее распространенный, или ротировать их периодически, для того чтобы представляться разными устройствами.
Что касается заголовков — referer с помощью небольшого изучения можно выставлять такой, какой понравится скрейпленному сайту, а юзерагент мы берем от Chrome, или Firefox, чтобы он ничем не отличался от десятков тысяч других юзеров.
Дальше, жонглируя этими параметрами, можно представляться разными устройствами и продолжать скрейпить, не боясь как-то отметиться для невооруженного взгляда, ходящего по логам. Для вооруженного взгляда это все-таки несколько труднее, потому что такие простые уловки нейтрализуются такими же, достаточно простыми, контрмерами.

Сравнение параметров запроса, заголовков, айпи адреса друг с другом и с публично известными позволяет отлавливать самых наглых скрейперов. Простой пример — к нам пришел поисковой бот, но только IP у него почему-то не из сети поисковика, а из какого-нибудь облачного провайдера. Даже сам Гугл на странице, описывающей Googlebot, рекомендует делать reverse lookup DNS-записи для того, чтобы убедиться, что данный бот реально пришел с google.com или других валидных ресурсов Гугла.
Таких проверок бывает много, чаще всего они рассчитаны на тех скрейперов, которые не заморачиваются фаззингом, какой-то подменой. Для более сложных кейсов есть более надежные и более тяжеловесные методы, например подсунуть этому боту Javascript. Понятно, что в таких условиях борьба уже неравная — ваш питоновский скриптик не сможет выполнить и интерпретировать JS-код. Но это может сделать автор скрипта — если у автора бота есть достаточно времени, желания, ресурсов и навыка, чтобы пойти посмотреть в браузере, что делает ваш Javascript.
Суть проверок в том, что вы интегрируете скрипт в вашу страницу, и вам важно не только то, чтобы он выполнился — а еще чтобы он продемонстрировал какой-то результат, который обычно POST’ом отправляется обратно на сервер перед тем, как на клиента высыпется контент, и сама страничка загрузится. Поэтому, если автор бота решил вашу загадку и захардкодит правильные ответы в свой питоновский скрипт, либо, к примеру, поймет, где ему нужно парсить сами строки скрипта в поисках нужных параметров и вызываемых методов, и будет вычислять ответ у себя — он сможет обвести вас вокруг пальца. Вот, в качестве примера.

Я думаю, что некоторые слушатели узнают этот кусочек javascript'a — это проверка, которая раньше была у одного из самых крупных облачных провайдеров в мире перед доступом к запрашиваемой странице, компактная и очень простая, и в то же время без ее изучения так просто на сайт не пробиться. При этом, применив чуть-чуть усилий, мы можем попросить страницу в поисках интересующих нас JS-методов, которые будут вызываться, от них, отсчитав, найти интересующие нас значения, которые должны быть вычислены, и всунуть себе в код вычисления. После не забыть несколько секунд поспать из-за задержки, и вуаля.

Мы попали на страницу и дальше можем парсить то, что нам нужно, потратив не больше ресурсов, чем на создание самого нашего скрейпера. То есть с точки зрения использования ресурсов нам ничего дополнительного для решения таких задач не нужно. Понятно, что гонка вооружений в этом ключе — написание JS-челленджей и их парсинг и обход сторонними средствами — ограничивается только временем, желанием и навыками автора ботов и автора проверок. Эта гонка может длиться довольно долго, но в какой-то момент большинству скрейперов это становится неинтересно, ведь есть более интересные варианты с этим справиться. Зачем сидеть и парсить JS-код у себя в Python, если можно просто взять и запустить браузер?

Да, я говорю в первую очередь о headless-браузерах, потому что этот инструмент, изначально создававшийся для тестирования и Q&A, оказался идеально подходящим для задач веб-скрейпинга на текущий момент.
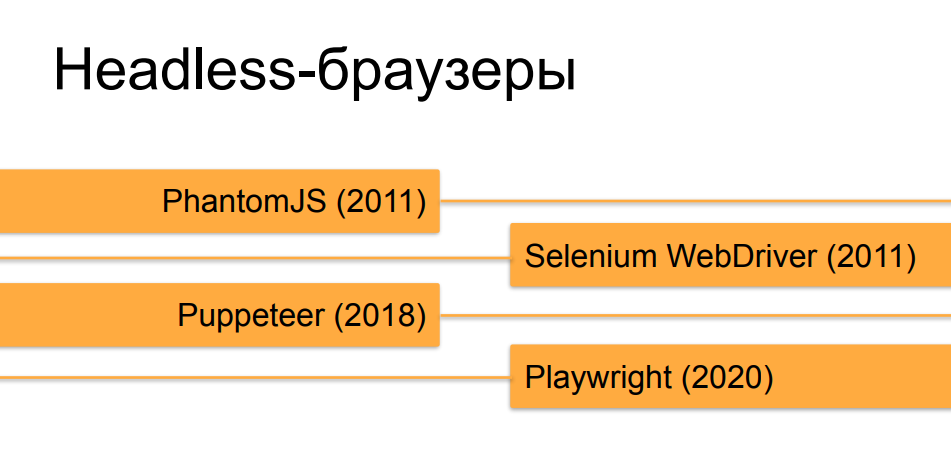
Не будем вдаваться в подробности по headless-браузерам, я думаю, что большинство слушателей о них и так знает. Оркестраторы, которые автоматизируют работу headless-браузеров, претерпели довольно бодрую эволюцию за последние 10 лет. Сначала, в момент возникновения PhantomJS и первых версий Selenium 2.0 и Selenium WebDriver, работающий под автоматом headless-браузер было совсем не трудно отличить от живого пользователя. Но, с течением времени и появлением таких инструментов, как Puppeteer для headless Chrome и, сейчас, творение господ из Microsoft — Playwright, которое делает то же, что и Puppeteer но не только для Хрома, а для всех версий популярных браузеров, они все больше и больше приближают «безголовые» браузеры к настоящим с точки зрения того, насколько их можно сделать с помощью оркестрации похожими по поведению и по разным признакам и свойствам на браузер здорового человека.
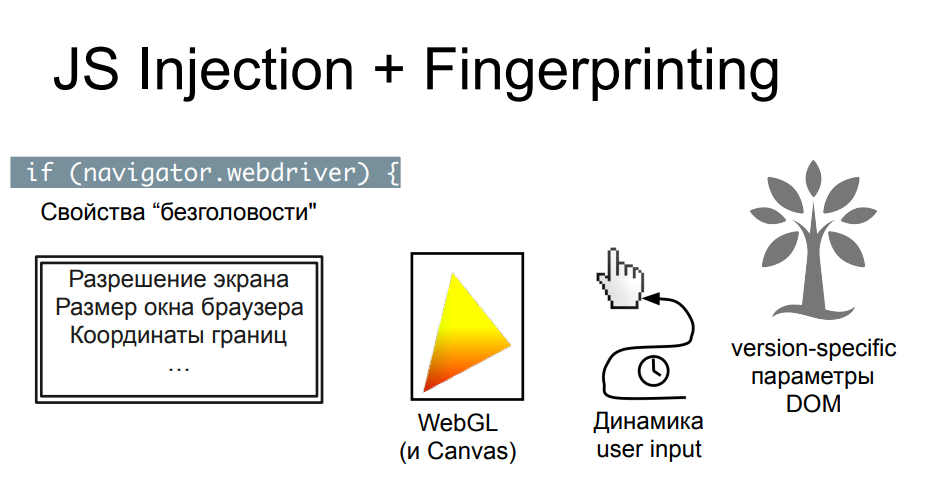
Для того чтобы заниматься распознаванием headless’ов на фоне обычных браузеров, за которыми сидят люди, как правило, используются те же самые javascript’овые проверки, но более глубокие, подробные, собирающие тучу параметров. Результат этого сбора отправляют обратно либо в средство защиты, либо на сайт, с которого скрейпер хотел забрать данные. Эту технологию называют fingerprinting, потому что собирается настоящий цифровой отпечаток браузера и девайса, на котором он запущен.
Вещей, на которые смотрят JS-проверки при фингерпринтинге, довольно много — их можно разделить на некоторые условные блоки, в каждом из которых копание может продолжаться до плюс бесконечности. Свойств действительно очень много, какие-то из них легко спрятать, какие-то менее легко. И здесь, как и в предыдущем примере, очень многое зависит от того, насколько дотошно скрейпер подошел к задаче сокрытия торчащих «хвостов» безголовости. Есть свойства объектов в браузере, которые подменяет по умолчанию оркестратор, есть та самая property (navigator.webdriver), которая выставляется в headless’ах, но при этом ее нет в обычных браузерах. Ее можно спрятать, попытку спрятать можно задетектировать, проверив определенные методы — то что проверяет эти проверки, тоже можно спрятать и подсовывать фальшивый output функциям, которые распечатывают методы, например, и до бесконечности это может длиться.
Другой блок проверок, как правило, отвечает за изучение параметров окна и экрана, которых у headless-браузеров по определению нет: проверка координат, проверка размеров, какой размер у битой картинки, которая не отрисовалась. Есть масса нюансов, которые человек, хорошо знающий устройство браузеров, может предусмотреть и на каждый из них подсунуть правдоподобный (но ненастоящий) вывод, который улетит в проверки fingerprint’а на сервер, который будет его анализировать. Например, в случае отрисовки средствами WebGL и Canvas каких-то картинок, 2D и 3D, можно полностью весь вывод взять готовый, подделать, выдать в методе и заставить кого-то поверить в то, что что-то действительно нарисовалось.
Есть более хитрые проверки, которые происходят не одномоментно, а допустим, JS-код покрутится какое-то количество секунд на странице, или будет вообще постоянно висеть и передавать какую-то информацию на сервер с браузера. К примеру, отслеживание положения и скорости движения курсора — если бот «кликает» только в нужные ему места и переходит по ссылкам со скоростью света, то это можно отследить по движению курсора, если автор бота не додумается в оркестраторе прописать какое-то человекоподобное, плавное, смещение.
И есть совсем дебри — это version-specific параметры и свойства объектной модели, которые специфичны от браузера к браузера, от версии к версии. И для того, чтобы эти проверки корректно работали и не фолсили, например, на живых юзерах с какими-нибудь старыми браузерами, нужно учитывать кучу вещей. Во-первых, нужно успевать за выходом новых версий, видоизменять свои проверки, чтобы они учитывали положение вещей на фронтах. Нужно держать обратную совместимость, чтобы на сайт, защищенный такими проверками смог приходить кто-то на нетиповом браузере и при этом не ловиться как бот, и множество другого.
Это кропотливая, достаточно сложная работа — такими вещами обычно занимаются компании, которые предоставляют bot detection как услугу, и заниматься таким самостоятельно на своем ресурсе — это не очень выгодное вложение времени и средств.
Но, что поделать — нам очень нужно поскрейпить сайт, обвешанный тучей таких проверок на безголовость и вычисляющий наш какой-нибудь headless-chrome с puppeteer’ом несмотря на все, как бы сильно мы ни старались.
Маленькое лирическое отступление — кому интересно поподробнее почитать про историю и эволюцию проверок, например на безголовость Chrome, есть забавная эпистолярная дуэль двух авторов. Про одного автора я знаю не очень много, а второго зовут Antoine Vastel — это молодой человек из Франции, который ведет свой блог о ботах и об их обнаружении, об обфускации проверок и многих других занятных вещах. И вот они со своим визави на протяжении двух лет спорили о том, можно ли задетектить headless Chrome.
А мы двинемся дальше и поймем, что же делать, если не получается headless’ом пробиться через проверки.

Значит, мы не будем использовать headless, а будем использовать большие настоящие браузеры, которые рисуют нам окошки и всякие визуальные элементы. Инструменты, такие как Puppeteer и Playwright позволяют вместо headless’а запускать браузеры с отрисованным экраном, считывать user input оттуда, снимать скриншоты и делать многое другое, что недоступно браузерам без визуальной составляющей.

Помимо обхода проверок на безголовость в этом случае также можно справится со следующей проблемой — когда у нас какие-то элементы хитрые сайтоделы, прячут из текста в картинки, делают невидимыми без совершения дополнительных кликов или каких-то других действий и движений. Прячут какие-то элементы, которые должны быть hidden, и на которые попадаются headless’ы: они-то не знают, что этот элемент сейчас не должен отображаться на экране, и попадаются на этом. Мы можем просто отрисовать в браузере эту картинку, скормить скриншот OCR’у, получить на выходе текст и использовать его. Да, это сложнее, дороже с точки зрения разработки дольше и ест больше ресурсов. Но есть скрейперы, которые работают именно так, и в ущерб скорости и производительности собирают данные таким образом.

«А как же CAPTCHA?» — спросите вы. Ведь OCR’ом (продвинутую) капчу не решишь без каких-то более сложных вещей. На это есть простой ответ — если у нас не получается решать капчу автоматом, почему бы не задействовать человеческий труд? Зачем разделять бота и человека, если можно комбинировать их труд для достижения цели?
Есть сервисы, которые позволяют отправлять им капчу, где она решается руками людей сидящих перед экранами, и через API можно получить ответ на свою капчу, подставить в запрос куку, например, которая будет при этом выдана, и дальше уже автоматизированно обрабатывать информацию с этого сайта. Каждый раз, когда всплывает капча, мы дергаем апишку, получаем ответ на капчу — подсовываем его в следующем вопросе и идем дальше.
Понятно, что это тоже стоит копеечку — решение капчи закупается оптом. Но если наши данные стоят дороже, чем составят затраты на все эти ухищрения, то, в конце концов, почему бы и нет?
Теперь, когда мы посмотрели на эволюцию в сторону сложности всех этих инструментов, давайте подумаем: как поступить, если скрейпинг произошел на нашем онлайн ресурсе — онлайн-магазине, публичной базе знаний, да на чем угодно.

В первую очередь скрейпер нужно обнаружить. Я вам так скажу: далеко не все кейсы публичного сбора вообще приносят негативные эффекты, как мы уже успели рассмотреть в начале доклада. Как правило, более примитивные методы, те же самые скрипты без рейт-лимитирования, без ограничения скорости запроса, могут нанести гораздо больше вред (если их не предотвращать средствами защиты), чем какой-нибудь сложный, изощренный, скрейпинг headful-браузерами с одним запросом в час, который сначала еще нужно как-то найти в логах.

Поэтому сначала нужно понять, что нас скрейпят — посмотреть на те значения, которые обычно аффектятся при этой деятельности. Мы говорим сейчас про технические параметры и про бизнес-метрики. Те вещи, которые можно увидеть у себя в Grafana, на протяжении времени отсматривая нагрузку и трафик, всякого рода всплески и аномалии. Это можно делать и вручную, если вы не используете средство защиты, но это более надежно делают те, кто умеет фильтровать трафик, обнаруживать разного рода инциденты и матчить их с какими-то событиями. Потому что помимо анализа логов постфактум и помимо анализа каждого отдельного запроса здесь может работать и использование какой-то накопленной средством защиты базы знаний, которая уже видела действия скрейперов на этом ресурсе или на похожих ресурсах, и можно как-то сравнить одно с другим — речь о корреляционном анализе.
Что касается бизнес-метрик — мы уже вспоминали на примере скриптов, которые наносят прямой или косвенный финансовый ущерб. Если есть возможность быстро отслеживать динамику по этим параметрам, то опять же скрейпинг можно заметить — а дальше уже, если вы решаете эту задачу самостоятельно, добро пожаловать в логи вашего бэкенда.
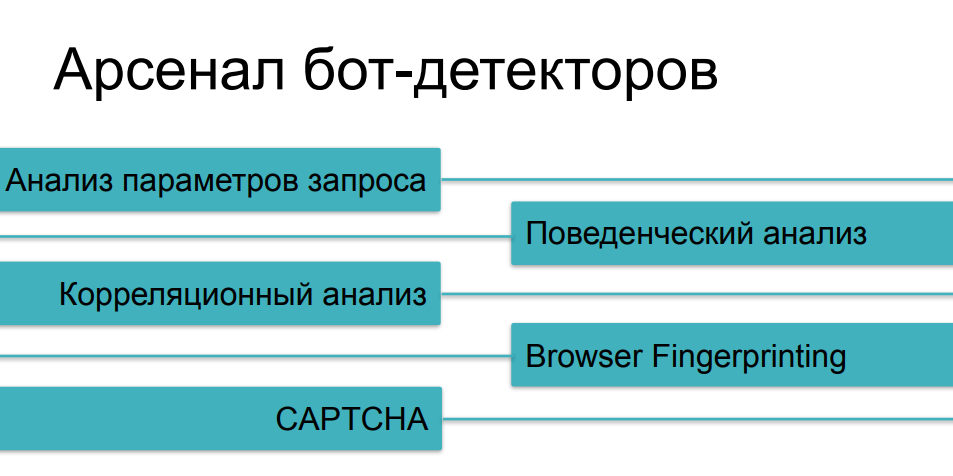
Что касается средств защиты, которые применяются против агрессивного скрейпинга, то большинство методов мы уже рассмотрели, говоря про разные категории ботов. Анализ трафика нам поможет от самых простых кейсов, поведенческий анализ поможет отследить такие вещи, как фаззинг (подмена identity) и мультиинстансинг на скриптах. Против более сложных вещей мы будем собирать цифровые отпечатки. И, конечно же, у нас есть CAPTCHA как последний довод королей — если мы не смогли хитрого бота как-то поймать на предыдущих вопросах, то, наверное, он споткнется на капче, не правда ли?
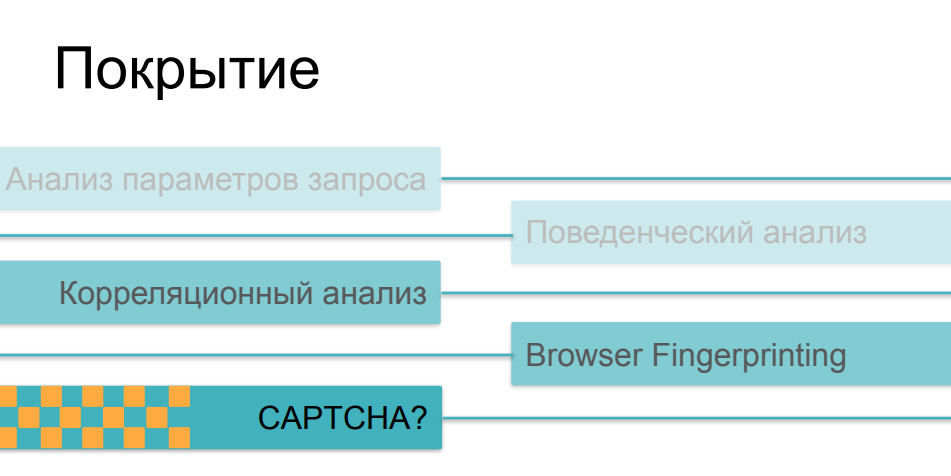
Ну, здесь все немножко сложнее. Дело в том, что по мере увеличения сложности и хитрости проверок они становятся все дороже в основном для клиентской стороны. Если анализ трафика и последующее сравнение параметров с какими-то историческими значениями можно делать абсолютно неинвазивно, без влияния на время загрузки страницы и на скорость работы онлайн ресурса в принципе, то fingerprinting, если он достаточно массивный и делает сотни разных проверок на стороне браузера, может серьезно повлиять на скорость загрузки. А странички с проверками тоже мало кто любит наблюдать в процессе перехода по ссылкам.
Что касается CAPTCHA — это самый грубый и самый инвазивный метод. Это штука, которая реально может отпугнуть пользователей или покупателей от ресурса. Капчу никто не любит, и к ней не от хорошей жизни обращаются — к ней прибегают тогда, когда все остальные варианты не сработали. Здесь есть и еще один забавный парадокс, некоторая проблема с таким применением этих методов. Дело в том, что большинство средств защиты в той или иной суперпозиции применяют все эти возможности в зависимости от того, с насколько сложным сценарием бот активности они столкнулись. Если у нас пользователь сумел пройти анализаторы трафика, если его поведение не отличается от поведения пользователей, если отпечаток его похож на валидный браузер, он преодолел все эти проверки, и тут в конце мы показываем ему капчу — и это оказывается человек… это бывает очень грустно. В итоге капча начинает показываться не злобным ботам, которых мы хотим отсечь, а довольно серьезной доле пользователей — людей, которые могут на это разозлиться и могут в следующий раз не прийти, не купить что-то на ресурсе, не поучаствовать в его дальнейшем развитии.

Учитывая все эти факторы — что же нам в итоге делать, если скрейпинг пришел к нам, мы на него посмотрели и смогли как-то оценить его влияние на наши бизнес- и технические показатели? С одной стороны, бороться со скрейпингом по определению как со сбором публичных данных, машинами или людьми смысла не имеет — вы сами согласились с тем, что эти данные доступны любому пользователю пришедшему из интернета. И решать задачу по ограничению скрейпинга «из принципа» — то есть из-за того что к вам приходят продвинутые и талантливые ботоводы, вы стараетесь их всех забанить — значит потратить очень много ресурсов на защиту, либо собственных, либо использовать дорогостоящее и очень сложное решение, self-hosted или облачное в «режиме максимальной защищенности» и в погоне за каждым отдельным ботом рисковать отпугнуть долю валидных пользователей такими вещами, как тяжелые javascript-проверки, как капча, которая выскакивает на каждом третьем переходе. Все это может ваш сайт до неузнаваемости изменить не в пользу ваших посетителей.
Если вы хотите использовать средство защиты, то нужно искать такие, которые позволят вам менять и как-то находить баланс между той долей скрейперов (от простых до сложных), которую вы будете пытаться отсечь от использования своего ресурса и, собственно, скоростью работы вашего веб-ресурса. Потому что, как мы уже посмотрели, какие-то проверки делаются просто и быстро, а какие-то проверки делаются сложно и долго — и при этом очень заметны для самих посетителей. Поэтому решения, которые умеют применять и варьировать эти контрмеры в рамках общей платформы, позволят вам достичь этого баланса быстрее и качественнее.
Ну и еще очень важно использовать то, что называется «правильный mindset» в изучении всей этой проблематики на своих или чужих примерах. Нужно помнить, что в защите нуждаются не сами публичные данные — их все равно рано или поздно увидят все люди, которые этого хотят. В защите нуждается пользовательский опыт: UX ваших клиентов, покупателей и пользователей, которые, в отличие от скрейперов, приносят вам доход. Вы сможете его сохранить и повысить, если будете лучше разбираться в этой очень интересной сфере.
Большое спасибо за внимание!

Всем привет! Наша компания достаточно давно занимается проблематикой защиты от DDoS-атак, и в процессе этой работы мне удалось достаточно подробно познакомиться со смежными сферами — изучить принципы создания ботов и способы их применения. В частности — web scraping, то есть массовый сбор публичных данных с веб-ресурсов с использованием ботов.
В какой-то момент эта тема меня необычайно увлекла многообразием прикладных задач, в которых скрейпинг с успехом используется. Здесь надо отметить, что наибольший интерес для меня представляет «темная сторона» веб-скрейпинга, то есть вредные и плохие сценарии его использования и негативные эффекты, которые он может оказать на веб-ресурсы и бизнес, с ними связанный.
При этом в силу специфики нашей работы чаще всего именно в такие (плохие) кейсы приходилось подробно погружаться, изучая интересные детали. И результатом этих погружений стало то, что мой энтузиазм передался коллегам — мы реализовали свое решение по отлову нежелательных ботов, ну а у меня накопилось достаточно историй и наблюдений, которые составят интересный, надеюсь, для вас материал.
Я буду рассказывать о следующем:
- Зачем вообще люди друг друга скрейпят;
- Какие есть виды и признаки такого скрейпинга;
- Какое влияние он оказывает на целевые веб-сайты;
- Какие средства и технические возможности используют создатели ботов, чтобы заниматься скрейпингом;
- Как разные категории ботов можно попробовать обнаружить и распознать;
- Как поступить и что делать, если скрейпер пришел в гости на ваш сайт (и нужно ли вообще что-то делать).
Начнем с безобидного гипотетического сценария — представим, что вы студент, завтра утром у вас защита курсовой работы, у вас по материалам «конь не валялся», не хватает ни цифр, ни выдержек, ни цитат — и вы понимаете, что за оставшуюся часть ночи перелопатить всю эту базу знаний вручную у вас нет ни времени, ни сил, ни желания.
Поэтому, по совету старших товарищей, вы расчехляете питоновскую командную строку и пишете простой скрипт, который принимает на вход URL’ы, ходит туда, загружает страницу, парсит контент, находит в нем интересующие ключевые слова, блоки или цифры, складывает их в файлик или в табличку и идет дальше.
Заряжаете в этот скрипт необходимое количество вам адресов научных публикаций, онлайн-изданий, новостных ресурсов — он быстро все перебирает, складывая результаты. Вам же остается только по ним нарисовать графики и диаграммы, таблицы — а на следующее утро с видом победителя получаете свой заслуженный балл.
Давайте подумаем — сделали ли вы кому-нибудь в процессе плохо? Ну, если только вы не парсили HTML регулярным выражением, то скорее всего никому плохо вы не сделали, а тем более сайтам, на которые вы таким образом сходили. Это однократная деятельность, ее можно назвать скромной и незаметной, и вряд ли кто-то пострадал от того, что вы пришли, быстро и незаметно схватили необходимый вам кусочек данных.
С другой стороны — будете ли делать это снова, если все получилось в первый раз? Давайте признаемся — скорее всего, будете, потому что вы только что сэкономили кучу времени и ресурсов, получив, скорее всего, даже больше данных, чем изначально рассчитывали. И это не ограничивается только научными, академическими или общеобразовательными изысканиями.
Потому что информация стоит денег, а вовремя собранная информация стоит еще больших денег. Именно поэтому скрейпинг является серьезной статьей заработка для большого количества людей. Это популярная тема на фрилансе: зайдите и увидите кучу заказов с просьбой собрать те или иные данные или написать скрейпинговый софт. Также есть коммерческие организации, занимающиеся скрейпингом на заказ или предоставляющие платформы для этой активности, так называемый scraping as a service. Такое многообразие и распространение возможно, в том числе и потому, что скрейпинг сам по себе чем-то нелегальным, предосудительным, не является. С правовой точки зрения к нему очень трудно придраться — особенно на текущий момент, мы скоро узнаем почему.
Для меня особый интерес представляет еще и то, что в техническом плане бороться со скрейпингом вам никто не может запретить — это создает интересную ситуацию, в которой участники процесса по обе стороны баррикад имеют возможность в публичном пространстве обсуждать техническую и организационную сторону этого дела. Двигать вперед, в некоторой степени, инженерную мысль и вовлекать в этот процесс все больше людей.
С точки зрения правовых аспектов, ситуация, которую мы сейчас рассматриваем — с дозволенностью скрейпинга, не всегда была такой ранее. Если мы немного посмотрим на хронологию достаточно хорошо известных судебных исков, связанных со скрейпингом, то увидим, что еще на его заре первым иском была претензия компании eBay к скрейперу, который собирал данные с аукционов, и суд запретил ему заниматься этой деятельностью. Дальнейшие 15 лет статус-кво более-менее сохранялся — крупные компании выигрывали суды против скрейперов, когда обнаруживали их воздействие. Facebook и Craigslist, а также некоторые другие компании отметились исками, закончившимися в их пользу.
Однако год назад все внезапно изменилось. Суд счел, что претензия LinkedIn к компании, собиравшей публичные профили пользователей и резюме, является необоснованной, оставил без внимания письма и угрозы с требованием остановить активность. Суд постановил, что сбор публичных данных, вне зависимости от того, делает его бот или человек, не может быть основанием для претензии со стороны компании, демонстрирующей эти публичные данные. Такой мощный юридический прецедент сместил баланс в пользу скрейперов и позволил большему количеству людей проявлять, демонстрировать и пробовать собственный интерес в данной области.
Однако, глядя на все эти в целом безобидные вещи, не стоит забывать, что у скрейпинга много и негативных применений — когда данные собираются не просто для дальнейшего использования, но в процессе реализуется идея нанесения какого либо ущерба сайту, или бизнесу который за ним стоит, либо попытки обогатиться каким-то образом за счет пользователей целевого ресурса.
Посмотрим на несколько знаковых примеров.
Первым из которых является скрейпинг и копирование чужих объявлений с сайтов, которые предоставляют доступ к таким объявлениям: автомобили, недвижимость, личные вещи. Я в качестве примера выбрал замечательный гараж в Калифорнии. Представьте, что мы натравливаем туда бота, собираем картинку, собираем описание, забираем все контактные данные, и через 5 минут это же объявление у нас висит на другом сайте похожей направленности и, вполне возможно, что выгодная сделка произойдет уже через него.
Если мы немножечко здесь включим воображение и подумаем в соседнюю сторону — что если этим занимается не наш конкурент, а злоумышленник? Такая копия сайта может хорошо пригодиться чтобы, для примера, затребовать с посетителя предоплату, или просто предложить ввести данные платежной карты. Дальнейшее развитие событий вы можете представить самостоятельно.
Другой интересный случай скрейпинга это скупка товаров ограниченной доступности. Производители спортивной обуви, такие, как Nike, Puma и Reebok, периодически запускают кроссовки лимитированных и т.н. сигнатурных серий — за ними охотятся коллекционеры, они находятся в продаже ограниченное время. Впереди покупателей на сайты обувных магазинов прибегают боты и сгребают весь тираж, после чего эти кроссовки всплывают на сером рынке с совершенно другим ценником. В свое время это взбесило вендоров и ритейл, который их распространяет. Уже 7 лет они борются со скрейперами и т.н. сникер-ботами с переменным успехом, как техническими, так и административными методами.
Вы наверняка слышали истории, когда при онлайн покупке требовалось лично прийти в магазин кроссовок, или про honeypot с кроссовками за $100k, которые бот скупал не глядя, после чего его владелец хватался за голову — все эти истории находятся в этом тренде.
И ещё один похожий случай — это исчерпание инвентаря в онлайн-магазинах. Он похож на предыдущий, но в нем никаких покупок на деле не производится. Есть онлайн-магазин, и определенные позиции товаров, которые приходящие боты сгребают в корзину в том количестве, которое отображается как доступное на складе. В итоге легитимный пользователь, пытающийся купить товар, получает сообщение о том, что данного артикула нет в наличии, огорченно чешет затылок и уходит в другой магазин. Сами же боты после этого сбрасывают набранные корзины, товар возвращается в пул — а тот, кому он был нужен, приходит и заказывает. Или не приходит и не заказывает, если это сценарий мелких пакостей и хулиганства. Отсюда видно, что даже если прямого финансового ущерба онлайн-бизнесу такая деятельность не наносит, то она как минимум может серьезно покорежить бизнес метрики, на которые будут ориентироваться аналитики. Такие параметры, как конверсия, посещаемость, востребованность товара, средний чек корзины — все они будут сильно испачканы действиями ботов по отношению к этим товарным позициям. И перед тем, как эти метрики брать в работу, их придется старательно и кропотливо очищать от воздействия скрейперов.
Помимо такой бизнес направленности, есть и вполне заметные технические эффекты, возникающие от работы скрейперов — чаще всего, когда скрейпинг делается активно и интенсивно.
Один из примеров из нашей практики у одного из клиентов. Скрейпер пришел на локацию с параметризованным поиском, который является одной из самых тяжелых операций в бэкенде рассматриваемой структуры. Скрейперу понадобилось перебрать достаточно много поисковых запросов, и он из 200 RPS к этой локации сделал почти 700. Это серьезно нагрузило часть инфраструктуры, из-за чего пошла деградация качества сервиса для остальных легитимных пользователей, взлетело время ответа, посыпались 502-е и 503-и ошибки. В общем, скрейпера это ничуть не волновало и он сидел и делал свое дело, пока все остальные судорожно обновляли страничку браузера.
Отсюда видно, что такая активность может вполне классифицироваться как прикладная DDoS-атака — и зачастую так оно и бывает. Особенно если онлайн-магазин не такой большой, не имеет многократно зарезервированной по производительности и расположению инфраструктуры. Такая активность вполне может если не положить ресурс полностью — скрейперу это не очень выгодно, так как он в данном случае не получит свои данные — то заставить всех остальных пользователей серьезно огорчиться.
Но, помимо DDoSа, у скрейпинга есть еще интересные соседи из сферы киберпреступности. Например, перебор логинов-паролей использует похожую техническую базу, то есть с помощью тех же самых скриптов это можно делать с упором на скорость и производительность. Для credential stuffing используют наскрейпленные откуда-то пользовательские данные, которые засовываются в поля форм. Ну и тот пример с копированием контента и выкладыванием его на похожих сайтах — это серьезная подготовительная работа для того, чтобы подсовывать фишинговые ссылки и заманивать ничего не подозревающих покупателей.
Для того чтобы понять как разные варианты скрейпинга могут с технической точки зрения повлиять на ресурс попробуем посчитать вклад отдельных факторов в эту задачу. Займемся некоторой арифметикой.
Представим, что у нас справа куча данных, которые нам нужно собрать. У нас есть задача или заказ выгрести 10 000 000 строчек товарных позиций, ценники например или котировки. И в левой части у нас есть бюджет времени, так как завтра или через неделю эти данные заказчику будут уже не нужны — они устареют, придется собирать их снова. Поэтому нужно уложиться в некоторый таймфрейм и, используя собственные ресурсы, сделать это оптимальным образом. У нас есть некоторое количество серверов — машин и айпи-адресов, за которыми они находятся, с которых мы будем ходить на интересующий нас ресурс. У нас есть некоторое количество инстансов пользователей, которыми мы прикидываемся — есть задача убедить онлайн-магазин или некоторую публичную базу в том, что это разные люди или разные компьютеры ходят за какими-то данными, чтобы у тех, кто будет анализировать логи, не возникало подозрений. И у нас есть некоторая производительность, интенсивность запросов, с одного такого инстанса.
Понятно, что в простом кейсе — одна хост-машина, студент с ноутбуком, перебирающий Washington Post, будет сделано большое количество запросов с одними и теми же признаками и параметрами. Это будет очень хорошо заметно в логах, если таких запросов будет достаточно много — а значит найти и забанить, в данном случае по айпи адресу, легко.
По мере усложнения скрейпинговой инфраструктуры появляется большее количество айпи адресов, начинают использоваться прокси, в том числе домовые прокси — о них чуть попозже. И мы начинаем мультиинстансить на каждой машине — подменять параметры запросов, признаки которые нас характеризуют, с той целью, чтобы в логах все это дело размазалось и было не столь бросающимся в глаза.
Если мы продолжаем в эту же сторону, то у нас появляется возможность в рамках этого же уравнения уменьшать интенсивность запросов с каждого такого инстанса — делая их более редкими, более эффективно их ротируя, чтобы запросы от одних и тех же пользователей не попадали рядом в логи, не вызывая подозрений и будучи похожими на конечных (легитимных) пользователей.
Ну и есть граничный случай — у нас в практике один раз был такой кейс, когда к заказчику пришел скрейпер с большого количества IP-адресов с совершенно разными признаками пользователей за этими адресами, и каждый такой инстанс сделал ровно по одному запросу за контентом. Сделал GET на нужную страничку товара, спарсил ее и ушел — и больше ни разу не появлялся. Такие кейсы довольно редки, так как для них нужно задействовать бóльшие ресурсы (которые стоят денег) за то же самое время. Но при этом отследить их и понять, что кто-то вообще приходил сюда и скрейпил, становится намного сложнее. Такие инструменты для исследования трафика, как поведенческий анализ — построение паттерна поведения конкретного пользователя, сильно усложняются. Ведь как можно делать поведенческий анализ, если нет никакого поведения? Нет истории действий пользователя, он ранее никогда не появлялся и, что интересно, больше с тех пор тоже ни разу не пришел. В таких условиях, если мы не пытаемся на первом же запросе что-то сделать, то он получит свои данные и уйдет, а мы останемся ни с чем — задачу по противодействию скрейпингу мы здесь не решили. Поэтому единственная возможность — это по первому же запросу догадаться, что пришел не тот, кого мы хотим видеть на сайте, и отдать ему ошибку или другим способом сделать так, чтобы он свои данные не получил.
Для того чтобы понять, как можно двигаться по этой шкале усложнения в построении скрейпера, посмотрим на арсенал, которым обладают создатели ботов, который чаще всего применяется — и на какие категории его можно разделить.
Первичная, самая простая категория, с которой большинство читателей знакомы — это скриптовый скрейпинг, использование достаточно простых скриптов для того, чтобы решать относительно сложные задачи.
И данная категория является, пожалуй, самой популярной и подробно задокументированной. Даже сложно порекомендовать, что конкретно читать, потому что, реально, материала море. Куча книжек написана по этому методу, есть масса статей и публикаций — в принципе достаточно потратить 5 / 4 / 3 / 2 минуты (в зависимости от нахальства автора материала), чтобы спарсить свой первый сайт. Это логичный первый шаг для многих, кто начинает в веб-скрейпинге. “Starter pack” такой деятельности это чаще всего Python, плюс библиотека, которая умеет делать запросы гибко и менять их параметры, типа requests или urllib2. И какой-нибудь HTML-парсер, чаще всего это Beautiful Soup. Также есть вариант использовать либы, которые созданы специально для скрейпинга, такие, как scrapy, которая включает в себя все эти функциональности с удобным интерфейсом.
С помощью нехитрых трюков можно прикидываться разными девайсами, разными пользователями, даже не имея возможности как-то масштабировать свою деятельность по машинам, по айпи адресам и по разным аппаратным платформам.
Для того чтобы сбить нюх у того, кто инспектирует логи на стороне сервера, с которого собираются данные, достаточно подменять интересующие параметры — и делать это нетрудно и недолго. Посмотрим на пример кастомного лог-формата для nginx — мы записываем айпишник, TLS-информацию, интересующие нас хедеры. Здесь, конечно, не все, что обычно собирается, но данное ограничение необходимо нам для примера — посмотреть на подмножество, просто потому что все остальное еще проще «подкинуть».
Для того, чтобы нас не банили по адресам, мы будем использовать residential proxy, как их называют за рубежом — то есть, прокси с арендованных (или взломанных) машин в домовых сетях провайдеров. Понятно, что забанив такой айпи адрес, есть шанс забанить какое-то количество пользователей, которые в этих домах живут — а там вполне могут оказаться посетители вашего сайта, так что иногда делать такое себе дороже.
TLS-информацию также не сложно подменить — взять наборы шифров популярных браузеров и выбрать тот, который понравится — наиболее распространенный, или ротировать их периодически, для того чтобы представляться разными устройствами.
Что касается заголовков — referer с помощью небольшого изучения можно выставлять такой, какой понравится скрейпленному сайту, а юзерагент мы берем от Chrome, или Firefox, чтобы он ничем не отличался от десятков тысяч других юзеров.
Дальше, жонглируя этими параметрами, можно представляться разными устройствами и продолжать скрейпить, не боясь как-то отметиться для невооруженного взгляда, ходящего по логам. Для вооруженного взгляда это все-таки несколько труднее, потому что такие простые уловки нейтрализуются такими же, достаточно простыми, контрмерами.
Сравнение параметров запроса, заголовков, айпи адреса друг с другом и с публично известными позволяет отлавливать самых наглых скрейперов. Простой пример — к нам пришел поисковой бот, но только IP у него почему-то не из сети поисковика, а из какого-нибудь облачного провайдера. Даже сам Гугл на странице, описывающей Googlebot, рекомендует делать reverse lookup DNS-записи для того, чтобы убедиться, что данный бот реально пришел с google.com или других валидных ресурсов Гугла.
Таких проверок бывает много, чаще всего они рассчитаны на тех скрейперов, которые не заморачиваются фаззингом, какой-то подменой. Для более сложных кейсов есть более надежные и более тяжеловесные методы, например подсунуть этому боту Javascript. Понятно, что в таких условиях борьба уже неравная — ваш питоновский скриптик не сможет выполнить и интерпретировать JS-код. Но это может сделать автор скрипта — если у автора бота есть достаточно времени, желания, ресурсов и навыка, чтобы пойти посмотреть в браузере, что делает ваш Javascript.
Суть проверок в том, что вы интегрируете скрипт в вашу страницу, и вам важно не только то, чтобы он выполнился — а еще чтобы он продемонстрировал какой-то результат, который обычно POST’ом отправляется обратно на сервер перед тем, как на клиента высыпется контент, и сама страничка загрузится. Поэтому, если автор бота решил вашу загадку и захардкодит правильные ответы в свой питоновский скрипт, либо, к примеру, поймет, где ему нужно парсить сами строки скрипта в поисках нужных параметров и вызываемых методов, и будет вычислять ответ у себя — он сможет обвести вас вокруг пальца. Вот, в качестве примера.
Я думаю, что некоторые слушатели узнают этот кусочек javascript'a — это проверка, которая раньше была у одного из самых крупных облачных провайдеров в мире перед доступом к запрашиваемой странице, компактная и очень простая, и в то же время без ее изучения так просто на сайт не пробиться. При этом, применив чуть-чуть усилий, мы можем попросить страницу в поисках интересующих нас JS-методов, которые будут вызываться, от них, отсчитав, найти интересующие нас значения, которые должны быть вычислены, и всунуть себе в код вычисления. После не забыть несколько секунд поспать из-за задержки, и вуаля.
Мы попали на страницу и дальше можем парсить то, что нам нужно, потратив не больше ресурсов, чем на создание самого нашего скрейпера. То есть с точки зрения использования ресурсов нам ничего дополнительного для решения таких задач не нужно. Понятно, что гонка вооружений в этом ключе — написание JS-челленджей и их парсинг и обход сторонними средствами — ограничивается только временем, желанием и навыками автора ботов и автора проверок. Эта гонка может длиться довольно долго, но в какой-то момент большинству скрейперов это становится неинтересно, ведь есть более интересные варианты с этим справиться. Зачем сидеть и парсить JS-код у себя в Python, если можно просто взять и запустить браузер?
Да, я говорю в первую очередь о headless-браузерах, потому что этот инструмент, изначально создававшийся для тестирования и Q&A, оказался идеально подходящим для задач веб-скрейпинга на текущий момент.
Не будем вдаваться в подробности по headless-браузерам, я думаю, что большинство слушателей о них и так знает. Оркестраторы, которые автоматизируют работу headless-браузеров, претерпели довольно бодрую эволюцию за последние 10 лет. Сначала, в момент возникновения PhantomJS и первых версий Selenium 2.0 и Selenium WebDriver, работающий под автоматом headless-браузер было совсем не трудно отличить от живого пользователя. Но, с течением времени и появлением таких инструментов, как Puppeteer для headless Chrome и, сейчас, творение господ из Microsoft — Playwright, которое делает то же, что и Puppeteer но не только для Хрома, а для всех версий популярных браузеров, они все больше и больше приближают «безголовые» браузеры к настоящим с точки зрения того, насколько их можно сделать с помощью оркестрации похожими по поведению и по разным признакам и свойствам на браузер здорового человека.
Для того чтобы заниматься распознаванием headless’ов на фоне обычных браузеров, за которыми сидят люди, как правило, используются те же самые javascript’овые проверки, но более глубокие, подробные, собирающие тучу параметров. Результат этого сбора отправляют обратно либо в средство защиты, либо на сайт, с которого скрейпер хотел забрать данные. Эту технологию называют fingerprinting, потому что собирается настоящий цифровой отпечаток браузера и девайса, на котором он запущен.
Вещей, на которые смотрят JS-проверки при фингерпринтинге, довольно много — их можно разделить на некоторые условные блоки, в каждом из которых копание может продолжаться до плюс бесконечности. Свойств действительно очень много, какие-то из них легко спрятать, какие-то менее легко. И здесь, как и в предыдущем примере, очень многое зависит от того, насколько дотошно скрейпер подошел к задаче сокрытия торчащих «хвостов» безголовости. Есть свойства объектов в браузере, которые подменяет по умолчанию оркестратор, есть та самая property (navigator.webdriver), которая выставляется в headless’ах, но при этом ее нет в обычных браузерах. Ее можно спрятать, попытку спрятать можно задетектировать, проверив определенные методы — то что проверяет эти проверки, тоже можно спрятать и подсовывать фальшивый output функциям, которые распечатывают методы, например, и до бесконечности это может длиться.
Другой блок проверок, как правило, отвечает за изучение параметров окна и экрана, которых у headless-браузеров по определению нет: проверка координат, проверка размеров, какой размер у битой картинки, которая не отрисовалась. Есть масса нюансов, которые человек, хорошо знающий устройство браузеров, может предусмотреть и на каждый из них подсунуть правдоподобный (но ненастоящий) вывод, который улетит в проверки fingerprint’а на сервер, который будет его анализировать. Например, в случае отрисовки средствами WebGL и Canvas каких-то картинок, 2D и 3D, можно полностью весь вывод взять готовый, подделать, выдать в методе и заставить кого-то поверить в то, что что-то действительно нарисовалось.
Есть более хитрые проверки, которые происходят не одномоментно, а допустим, JS-код покрутится какое-то количество секунд на странице, или будет вообще постоянно висеть и передавать какую-то информацию на сервер с браузера. К примеру, отслеживание положения и скорости движения курсора — если бот «кликает» только в нужные ему места и переходит по ссылкам со скоростью света, то это можно отследить по движению курсора, если автор бота не додумается в оркестраторе прописать какое-то человекоподобное, плавное, смещение.
И есть совсем дебри — это version-specific параметры и свойства объектной модели, которые специфичны от браузера к браузера, от версии к версии. И для того, чтобы эти проверки корректно работали и не фолсили, например, на живых юзерах с какими-нибудь старыми браузерами, нужно учитывать кучу вещей. Во-первых, нужно успевать за выходом новых версий, видоизменять свои проверки, чтобы они учитывали положение вещей на фронтах. Нужно держать обратную совместимость, чтобы на сайт, защищенный такими проверками смог приходить кто-то на нетиповом браузере и при этом не ловиться как бот, и множество другого.
Это кропотливая, достаточно сложная работа — такими вещами обычно занимаются компании, которые предоставляют bot detection как услугу, и заниматься таким самостоятельно на своем ресурсе — это не очень выгодное вложение времени и средств.
Но, что поделать — нам очень нужно поскрейпить сайт, обвешанный тучей таких проверок на безголовость и вычисляющий наш какой-нибудь headless-chrome с puppeteer’ом несмотря на все, как бы сильно мы ни старались.
Маленькое лирическое отступление — кому интересно поподробнее почитать про историю и эволюцию проверок, например на безголовость Chrome, есть забавная эпистолярная дуэль двух авторов. Про одного автора я знаю не очень много, а второго зовут Antoine Vastel — это молодой человек из Франции, который ведет свой блог о ботах и об их обнаружении, об обфускации проверок и многих других занятных вещах. И вот они со своим визави на протяжении двух лет спорили о том, можно ли задетектить headless Chrome.
А мы двинемся дальше и поймем, что же делать, если не получается headless’ом пробиться через проверки.
Значит, мы не будем использовать headless, а будем использовать большие настоящие браузеры, которые рисуют нам окошки и всякие визуальные элементы. Инструменты, такие как Puppeteer и Playwright позволяют вместо headless’а запускать браузеры с отрисованным экраном, считывать user input оттуда, снимать скриншоты и делать многое другое, что недоступно браузерам без визуальной составляющей.
Помимо обхода проверок на безголовость в этом случае также можно справится со следующей проблемой — когда у нас какие-то элементы хитрые сайтоделы, прячут из текста в картинки, делают невидимыми без совершения дополнительных кликов или каких-то других действий и движений. Прячут какие-то элементы, которые должны быть hidden, и на которые попадаются headless’ы: они-то не знают, что этот элемент сейчас не должен отображаться на экране, и попадаются на этом. Мы можем просто отрисовать в браузере эту картинку, скормить скриншот OCR’у, получить на выходе текст и использовать его. Да, это сложнее, дороже с точки зрения разработки дольше и ест больше ресурсов. Но есть скрейперы, которые работают именно так, и в ущерб скорости и производительности собирают данные таким образом.
«А как же CAPTCHA?» — спросите вы. Ведь OCR’ом (продвинутую) капчу не решишь без каких-то более сложных вещей. На это есть простой ответ — если у нас не получается решать капчу автоматом, почему бы не задействовать человеческий труд? Зачем разделять бота и человека, если можно комбинировать их труд для достижения цели?
Есть сервисы, которые позволяют отправлять им капчу, где она решается руками людей сидящих перед экранами, и через API можно получить ответ на свою капчу, подставить в запрос куку, например, которая будет при этом выдана, и дальше уже автоматизированно обрабатывать информацию с этого сайта. Каждый раз, когда всплывает капча, мы дергаем апишку, получаем ответ на капчу — подсовываем его в следующем вопросе и идем дальше.
Понятно, что это тоже стоит копеечку — решение капчи закупается оптом. Но если наши данные стоят дороже, чем составят затраты на все эти ухищрения, то, в конце концов, почему бы и нет?
Теперь, когда мы посмотрели на эволюцию в сторону сложности всех этих инструментов, давайте подумаем: как поступить, если скрейпинг произошел на нашем онлайн ресурсе — онлайн-магазине, публичной базе знаний, да на чем угодно.
В первую очередь скрейпер нужно обнаружить. Я вам так скажу: далеко не все кейсы публичного сбора вообще приносят негативные эффекты, как мы уже успели рассмотреть в начале доклада. Как правило, более примитивные методы, те же самые скрипты без рейт-лимитирования, без ограничения скорости запроса, могут нанести гораздо больше вред (если их не предотвращать средствами защиты), чем какой-нибудь сложный, изощренный, скрейпинг headful-браузерами с одним запросом в час, который сначала еще нужно как-то найти в логах.
Поэтому сначала нужно понять, что нас скрейпят — посмотреть на те значения, которые обычно аффектятся при этой деятельности. Мы говорим сейчас про технические параметры и про бизнес-метрики. Те вещи, которые можно увидеть у себя в Grafana, на протяжении времени отсматривая нагрузку и трафик, всякого рода всплески и аномалии. Это можно делать и вручную, если вы не используете средство защиты, но это более надежно делают те, кто умеет фильтровать трафик, обнаруживать разного рода инциденты и матчить их с какими-то событиями. Потому что помимо анализа логов постфактум и помимо анализа каждого отдельного запроса здесь может работать и использование какой-то накопленной средством защиты базы знаний, которая уже видела действия скрейперов на этом ресурсе или на похожих ресурсах, и можно как-то сравнить одно с другим — речь о корреляционном анализе.
Что касается бизнес-метрик — мы уже вспоминали на примере скриптов, которые наносят прямой или косвенный финансовый ущерб. Если есть возможность быстро отслеживать динамику по этим параметрам, то опять же скрейпинг можно заметить — а дальше уже, если вы решаете эту задачу самостоятельно, добро пожаловать в логи вашего бэкенда.
Что касается средств защиты, которые применяются против агрессивного скрейпинга, то большинство методов мы уже рассмотрели, говоря про разные категории ботов. Анализ трафика нам поможет от самых простых кейсов, поведенческий анализ поможет отследить такие вещи, как фаззинг (подмена identity) и мультиинстансинг на скриптах. Против более сложных вещей мы будем собирать цифровые отпечатки. И, конечно же, у нас есть CAPTCHA как последний довод королей — если мы не смогли хитрого бота как-то поймать на предыдущих вопросах, то, наверное, он споткнется на капче, не правда ли?
Ну, здесь все немножко сложнее. Дело в том, что по мере увеличения сложности и хитрости проверок они становятся все дороже в основном для клиентской стороны. Если анализ трафика и последующее сравнение параметров с какими-то историческими значениями можно делать абсолютно неинвазивно, без влияния на время загрузки страницы и на скорость работы онлайн ресурса в принципе, то fingerprinting, если он достаточно массивный и делает сотни разных проверок на стороне браузера, может серьезно повлиять на скорость загрузки. А странички с проверками тоже мало кто любит наблюдать в процессе перехода по ссылкам.
Что касается CAPTCHA — это самый грубый и самый инвазивный метод. Это штука, которая реально может отпугнуть пользователей или покупателей от ресурса. Капчу никто не любит, и к ней не от хорошей жизни обращаются — к ней прибегают тогда, когда все остальные варианты не сработали. Здесь есть и еще один забавный парадокс, некоторая проблема с таким применением этих методов. Дело в том, что большинство средств защиты в той или иной суперпозиции применяют все эти возможности в зависимости от того, с насколько сложным сценарием бот активности они столкнулись. Если у нас пользователь сумел пройти анализаторы трафика, если его поведение не отличается от поведения пользователей, если отпечаток его похож на валидный браузер, он преодолел все эти проверки, и тут в конце мы показываем ему капчу — и это оказывается человек… это бывает очень грустно. В итоге капча начинает показываться не злобным ботам, которых мы хотим отсечь, а довольно серьезной доле пользователей — людей, которые могут на это разозлиться и могут в следующий раз не прийти, не купить что-то на ресурсе, не поучаствовать в его дальнейшем развитии.
Учитывая все эти факторы — что же нам в итоге делать, если скрейпинг пришел к нам, мы на него посмотрели и смогли как-то оценить его влияние на наши бизнес- и технические показатели? С одной стороны, бороться со скрейпингом по определению как со сбором публичных данных, машинами или людьми смысла не имеет — вы сами согласились с тем, что эти данные доступны любому пользователю пришедшему из интернета. И решать задачу по ограничению скрейпинга «из принципа» — то есть из-за того что к вам приходят продвинутые и талантливые ботоводы, вы стараетесь их всех забанить — значит потратить очень много ресурсов на защиту, либо собственных, либо использовать дорогостоящее и очень сложное решение, self-hosted или облачное в «режиме максимальной защищенности» и в погоне за каждым отдельным ботом рисковать отпугнуть долю валидных пользователей такими вещами, как тяжелые javascript-проверки, как капча, которая выскакивает на каждом третьем переходе. Все это может ваш сайт до неузнаваемости изменить не в пользу ваших посетителей.
Если вы хотите использовать средство защиты, то нужно искать такие, которые позволят вам менять и как-то находить баланс между той долей скрейперов (от простых до сложных), которую вы будете пытаться отсечь от использования своего ресурса и, собственно, скоростью работы вашего веб-ресурса. Потому что, как мы уже посмотрели, какие-то проверки делаются просто и быстро, а какие-то проверки делаются сложно и долго — и при этом очень заметны для самих посетителей. Поэтому решения, которые умеют применять и варьировать эти контрмеры в рамках общей платформы, позволят вам достичь этого баланса быстрее и качественнее.
Ну и еще очень важно использовать то, что называется «правильный mindset» в изучении всей этой проблематики на своих или чужих примерах. Нужно помнить, что в защите нуждаются не сами публичные данные — их все равно рано или поздно увидят все люди, которые этого хотят. В защите нуждается пользовательский опыт: UX ваших клиентов, покупателей и пользователей, которые, в отличие от скрейперов, приносят вам доход. Вы сможете его сохранить и повысить, если будете лучше разбираться в этой очень интересной сфере.
Большое спасибо за внимание!
