Это даже не шутка, похоже, что именно эта картинка наиболее точно отражает суть этих БД, и в конце будет понятно почему:

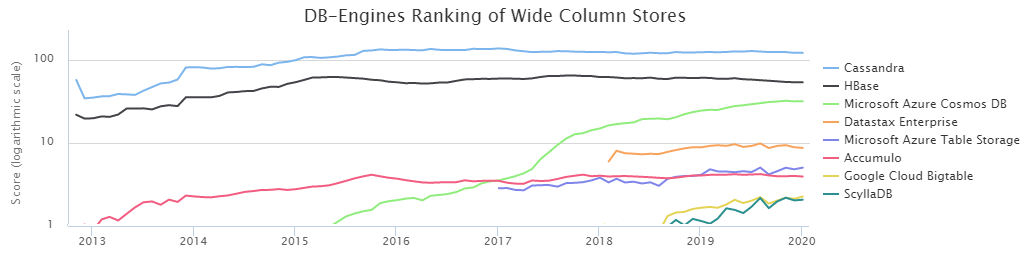
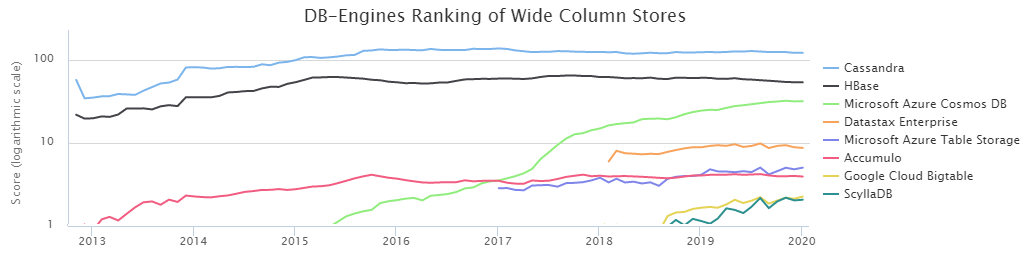
Согласно DB-Engines Ranking, две самых популярных NoSQL колоночных базы — это Cassandra (далее CS) и HBase (HB).
Волею судеб наша команда управления загрузки данных в Сбербанке уже давно и плотно работает с HB. За это время мы достаточно хорошо изучили её сильные и слабые стороны и научились её готовить. Однако наличие альтернативы в виде CS все время заставляло немного терзать себя сомнениями: а правильный ли выбор мы сделали? Тем более, что результаты сравнения, выполненного DataStax, говорили, что CS легко побеждает HB практически с разгромным счетом. С другой стороны, DataStax — заинтересованное лицо, и верить на слово тут не стоит. Также смущало достаточно малое количество информации об условиях тестирования, поэтому мы решили выяснить самостоятельно, кто же является королем BigData NoSql, и полученные результаты оказались весьма интересны.
Однако прежде чем перейти к результатам выполненных тестов, необходимо описать существенные аспекты конфигураций среды. Дело в том, что CS может использоваться в режиме допускающем потерю данных. Т.е. это когда только один сервер (нода) отвечает за данные некоего ключа и если он по какой-то причине отвалился, то значение этого ключа будет потеряно. Для многих задач это не критично, однако для банковской сферы это скорее исключение, чем правило. В нашем случае принципиально иметь несколько копий данных для надежного хранения.
Поэтому рассматривался исключительно режим работы CS в режиме тройной репликации, т.е. создание кейспейса выполнялось с такими параметрами:
Далее есть два способа обеспечить необходимый уровень консистентности. Общее правило:
NW + NR > RF
Что означает, что количество подтверждений от нод при записи (NW) плюс количество подтверждений от нод при чтении (NR) должно быть больше фактора репликации. В нашем случае RF = 3 и значит подходят следующие варианты:
2 + 2 > 3
3 + 1 > 3
Так как нам принципиально важно максимально надежно сохранить данные, была выбрана схема 3+1. К тому же HB работает по аналогичному принципу, т.е. такое сравнение будет более честным.
Необходимо отметить, что DataStax в своем исследовании делали наоборот, они ставили RF = 1 и для CS и для HB (для последней путем изменения настроек HDFS). Это действительно важный аспект, потому что влияние на производительность CS в этом случае огромное. Например, на картинке ниже показан рост времени требующегося для загрузки данных в CS:
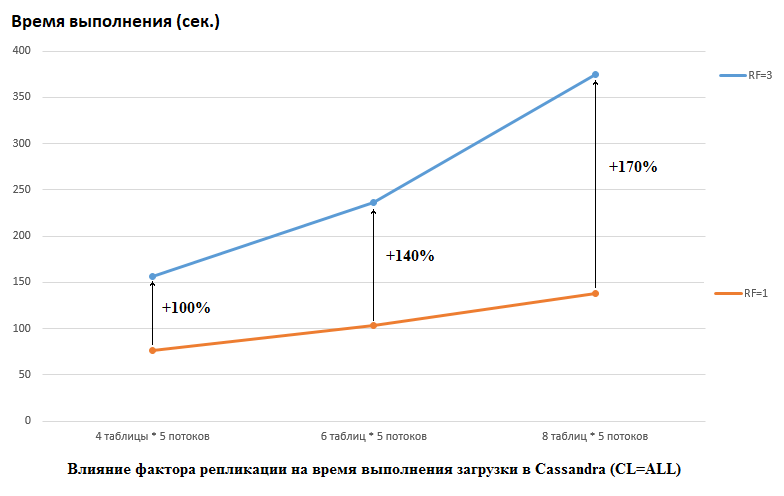
Тут мы видим следующее, чем больше конкурирующих потоков пишет данные, тем дольше времени это занимает. Это естественно, но важно, что при этом деградация производительности для RF=3 существенно выше. Иными словами, если мы пишем в 4 таблицы в каждую по 5 потоков (итого 20), то RF=3 проигрывает примерно в 2 раза (150 секунд RF=3 против 75 для RF=1). Но если мы увеличим нагрузку, загружая данные в 8 таблиц в каждую по 5 потоков (итого 40), то проигрыш RF=3 уже в 2,7 раз (375 секунд против 138).
Возможно, отчасти в этом заключается секрет успешного для CS нагрузочного тестирования выполненного DataStax, потому что для HB на нашем стенде изменение фактора репликации с 2 до 3 не оказало никакого влияния. Т.е. диски не являются узким местом для HB для нашей конфигурации. Однако тут есть много и других подводных камней, потому что нужно отметить, что наша версия HB была немного пропатчена и затюнена, среды совершенно разные и т.д. Также стоит отметить, что возможно я просто не знаю как правильно готовить CS и существуют какие-то более эффективные способы работать с ней и надеюсь в комментариях мы выясним это. Но обо всем по порядку.
Все тесты производились на железном кластере состоящем из 4 серверов, каждый в конфигурации:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 threads.
Диски: 12 штук SATA HDD
java version: 1.8.0_111
Версия CS: 3.11.5
Настройки GC:
Памяти jvm.options выделялось 16Gb (еще пробовали 32 Gb, разницы не замечено).
Создание таблиц выполнялось командой:
Версия HB: 1.2.0-cdh5.14.2 (в классе org.apache.hadoop.hbase.regionserver.HRegion нами был исключен MetricsRegion который приводил к GC при кол-ве регионов более 1000 на RegionServer)
Создание таблиц:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Тут есть один важный момент — в описании DataStax не сказано, сколько регионов использовалось при создании таблиц HB, хотя это критично для больших объемов. Поэтому для тестов было выбрано кол-во = 64, что позволяет хранить до 640 ГБ, т.е. таблицу среднего размера.
В HBase на момент проведения теста было 22 тысячи таблиц и 67 тысяч регионов (это было бы убийственно для версии 1.2.0, если бы не патч о котором сказано выше).
Теперь что касается кода. Так как не было ясности, какие конфигурации являются более выигрышным для той или иной БД, тесты производились в различных комбинациях. Т.е. в одних тестах загрузка шла одновременно в 4 таблицы (для подключения использовались все 4 ноды). В других тестах работали с 8 разными таблицами. В некоторых случаях размер батча был равен 100, в других 200 (параметр batch — см. код ниже). Размер данных для value 10 байт или 100 байт (dataSize). Всего каждый раз записывалось и вычитывалось по 5 млн. записей в каждую таблицу. При этом в каждую таблицу писали/читали 5 потоков (номер потока — thNum), каждый из которых использовал свой диапазон ключей (count = 1 млн):
Соответственно аналогичный функционал был предусмотрен для HB:
Так как в HB о равномерном распределении данных должен заботиться клиент, то функция соления ключа выглядела так:
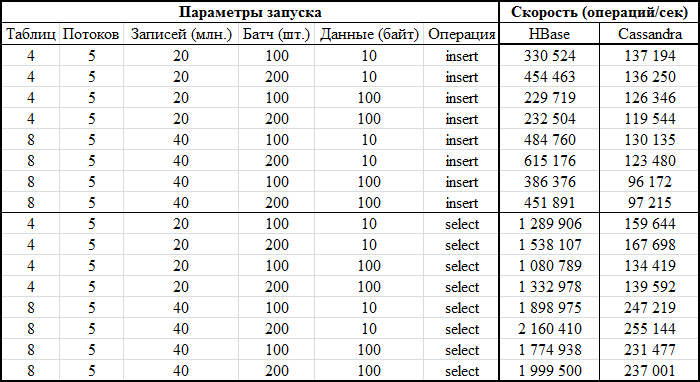
Теперь самое интересное — результаты:
Тоже самое в виде графика:
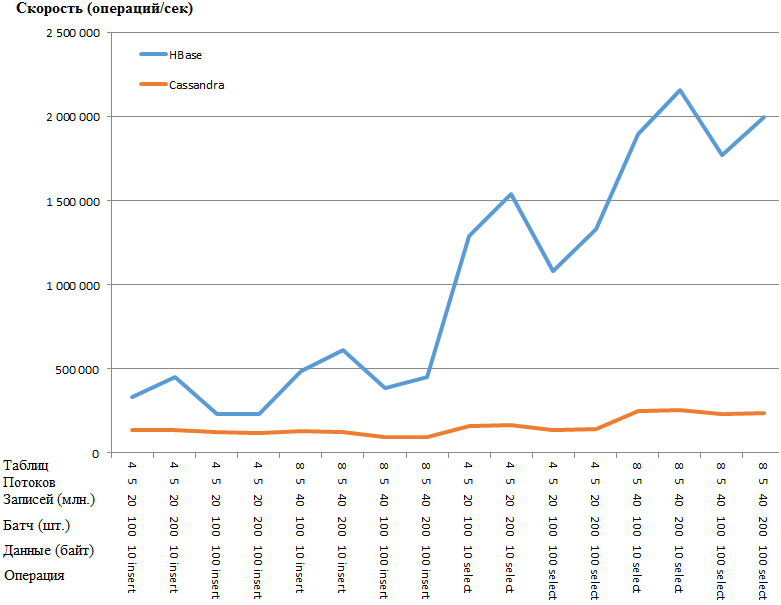
Преимущество HB настолько удивительное, что есть подозрение о наличие какого-то узкого места в настройке CS. Однако гуглеж и кручение наиболее очевидных параметров (вроде concurrent_writes или memtable_heap_space_in_mb) ускорения не дало. При этом в логах чисто, ни на что не ругается.
Данные легли по нодам равномерно, статистика со всех нод примерно одинаковая.
Попытка уменьшать размер батча (вплоть до отправки поштучно) не дала эффекта, стало только хуже. Возможно, что на самом деле это действительно максимум производительности для CS, так как полученные результаты по CS похожи на те, что получились и у DataStax — порядка сотни тысяч операций в секунду. Кроме того, если посмотреть на утилизацию ресурсов, то увидим, что CS использует гораздо больше и ЦПУ и дисков:
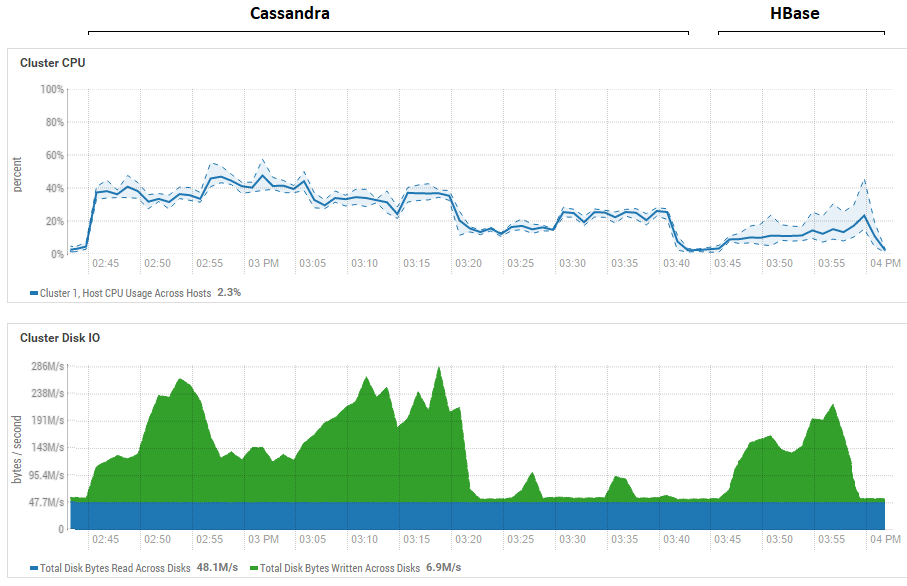
На рисунке показана утилизация во время прогона всех тестов подряд для обоих БД.
Что касается мощного преимущества HB при чтении. Тут видно, что для обоих БД утилизация дисков при чтении крайне низкая (тесты на чтение это завершающая часть цикла тестирования каждой БД, например для CS это с 15:20 до 15:40). В случае HB причина понятна — большая часть данных висит в памяти, в memstore и часть закешировалась в blockcache. Что касается CS, то тут не очень ясно как она устроена, однако также утилизации дисков не видно, но на всякий случай была сделана попытка включить кэш row_cache_size_in_mb = 2048 и установлен caching = {‘keys’: ‘ALL’, ‘rows_per_partition’: ‘2000000’}, но от этого стало даже чуть хуже.
Также стоит еще раз проговорить существенный момент про кол-во регионов в HB. В нашем случае было указано значение 64. Если же уменьшать его и сделать равным например 4, то при чтении скорость падает в 2 раза. Причина в том, что memstore будет забиваться быстрее и файлы будут флашиться чаще и при чтении нужно будет обрабатывать больше файлов, что для HB достаточно сложная операция. В реальных условиях это лечится продумыванием стратегии пресплитинга и компактификации, в частности мы используем самописную утилиту, которая занимается сборкой мусора и сжатием HFiles постоянно в фоновом режиме. Вполне возможно, что для тестов DataStax выделяли вообще 1 регион на таблицу (что не правильно) и это бы несколько прояснило, почему HB так проигрывал в их тестах на чтение.
Предварительные выводы отсюда получаются следующие. Если допустить, что в ходе тестирования не было допущено грубых ошибок, то Cassandra похожа на колосса на глиняных ногах. Точнее, пока она балансирует на одной ноге, как на картинке в начале статьи, она показывает относительно неплохие результаты, но при схватке в одинаковых условиях проигрывает вчистую. При этом учитывая низкую утилизацию CPU на нашем железе мы научились высаживать по два RegionServer HB на хост и тем самым удвоили производительность. Т.е. с учетом утилизации ресурсов ситуация для CS получается еще более плачевная.
Безусловно, эти тесты достаточно синтетические и объем данных, который использовался тут, относительно скромный. Не исключено, что при переходе на терабайты ситуация была бы иная, однако если для HB мы умеем грузить терабайты, то для CS это оказалось проблематично. Она зачастую выдавала OperationTimedOutException даже при этих объемах, хотя параметры ожидания отклика и так были увеличены в разы по сравнению с дефолтными.
Надеюсь, что совместными усилиями мы найдем узкие места CS и если получится её ускорить, то в конце поста обязательно добавлю информацию об итоговых результатах.
UPD: Были применены следующие рекомендации на настройке CS:
disk_optimization_strategy: spinning
MAX_HEAP_SIZE=«32G»
HEAP_NEWSIZE=«3200M»
-Xms32G
-Xmx32G
-XX:+UseG1GC
-XX:G1RSetUpdatingPauseTimePercent=5
-XX:MaxGCPauseMillis=500
-XX:InitiatingHeapOccupancyPercent=70
-XX:ParallelGCThreads=32
-XX:ConcGCThreads=8
Что касается настроек ОС, это достаточно долгая и сложная процедура (получать рута, ребутить сервера и т.д.), поэтому эти рекомендации не применялись. С другой стороны, обе БД в равных условиях, так что все честно.
В части кода, сделан один коннектор для всех потоков пишущих в таблицу:
Данные отправлялись через биндинг:
Это не оказало ощутимого влияния на производительность записи. Для надежности запустил нагрузку инструментом YCSB, абсолютно такой же результат. Ниже статистика по одному потоку (из 4х):
2020-01-18 14:41:53:180 315 sec: 10000000 operations; 21589.1 current ops/sec; [CLEANUP: Count=100, Max=2236415, Min=1, Avg=22356.39, 90=4, 99=24, 99.9=2236415, 99.99=2236415] [INSERT: Count=119551, Max=174463, Min=273, Avg=2582.71, 90=3491, 99=16767, 99.9=99711, 99.99=171263]
[OVERALL], RunTime(ms), 315539
[OVERALL], Throughput(ops/sec), 31691.803548848162
[TOTAL_GCS_PS_Scavenge], Count, 161
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 2433
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.7710615803434757
[TOTAL_GCS_PS_MarkSweep], Count, 0
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0
[TOTAL_GCs], Count, 161
[TOTAL_GC_TIME], Time(ms), 2433
[TOTAL_GC_TIME_%], Time(%), 0.7710615803434757
[INSERT], Operations, 10000000
[INSERT], AverageLatency(us), 3114.2427012
[INSERT], MinLatency(us), 269
[INSERT], MaxLatency(us), 609279
[INSERT], 95thPercentileLatency(us), 5007
[INSERT], 99thPercentileLatency(us), 33439
[INSERT], Return=OK, 10000000
Тут видно что скорость одного потока порядка 32 тыс записей в секунду, работало 4 потока, получается 128 тыс. Кажется, большего на текущих настройках дисковой подсистемы не выжать.
Насчет чтения интереснее. Благодаря советам камрадов его удалось радикально ускорить. Чтение осуществлялось не в 5 потоков, а в 100. Увеличение до 200 эффекта уже не давало. Также в билдер добавлено:
.withLoadBalancingPolicy(new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
В результате, если раньше тест показывал 159 644 ops (5 потоков, 4 таблицы, батч 100), то теперь:
100 потоков, 4 таблицы, батч = 1 (поштучно): 301 969 ops
100 потоков, 4 таблицы, батч = 10: 447 608 ops
100 потоков, 4 таблицы, батч = 100: 625 655 ops
Так как результаты лучше с батчами, прогнал аналогичные* тесты с HB:

*Так как при работе в 400 потоков функция RandomStringUtils, которая использовалась ранее, грузила CPU на 100%, она была заменена более быстрым генератором.
Таким образом, увеличение количества потоков при загрузке данных дает небольшой прирост производительности HB.
Что касается чтения, тут приведены результаты нескольких вариантов. По просьбе 0x62ash выполнялась команда flush перед чтением и также приведены для сравнения несколько других вариантов:
Memstore — чтение из памяти, т.е. до сброса на диск.
HFile+zip — чтение из файлов, сжатых алгоритмом GZ.
HFile+upzip — чтение из файлов без сжатия.
Обращает на себя внимание занятная особенность — маленькие файлы (см. поле «Данные», где записи 10 байт) обрабатываются медленнее, особенно если они сжаты. Очевидно, что это так только до определенного размера, явно файл в 5 Гб не будет обработан быстрее 10 Мб, но явно указывает на то, что во всех этих тестах еще не паханное поле для исследований различных конфигураций.
Для интереса поправил код YCSB для работы с HB батчами по 100 штук, чтобы замерить латентность и прочее. Ниже результат работы 4-х экземпляров, которые писали в свои таблицы, каждый по 100 тредов. Получилось следующее:
Получается, что если у CS AverageLatency(us) на запись 3114, то у HB AverageLatency(us) = 1162 (помним, что 1 операция = 100 записям и поэтому надо делить).
В целом получается такой вывод — в заданных условиях имеет место существенное преимущество HBase. Однако нельзя исключать, что SSD и тщательный тюнинг ОС изменит картину радикально. Также нужно понимать, что очень многое зависит от сценариев использования, запросто может оказаться так, что если взять не 4 таблицы, а 400 и работать с терабайтами, баланс сил сложится совсем иным образом. Как говорили классики: практика — критерий истины. Надо пробовать. За одно ScyllaDB теперь уже имеет смысл проверить, так что продолжение следует…

Согласно DB-Engines Ranking, две самых популярных NoSQL колоночных базы — это Cassandra (далее CS) и HBase (HB).
Волею судеб наша команда управления загрузки данных в Сбербанке уже давно и плотно работает с HB. За это время мы достаточно хорошо изучили её сильные и слабые стороны и научились её готовить. Однако наличие альтернативы в виде CS все время заставляло немного терзать себя сомнениями: а правильный ли выбор мы сделали? Тем более, что результаты сравнения, выполненного DataStax, говорили, что CS легко побеждает HB практически с разгромным счетом. С другой стороны, DataStax — заинтересованное лицо, и верить на слово тут не стоит. Также смущало достаточно малое количество информации об условиях тестирования, поэтому мы решили выяснить самостоятельно, кто же является королем BigData NoSql, и полученные результаты оказались весьма интересны.
Однако прежде чем перейти к результатам выполненных тестов, необходимо описать существенные аспекты конфигураций среды. Дело в том, что CS может использоваться в режиме допускающем потерю данных. Т.е. это когда только один сервер (нода) отвечает за данные некоего ключа и если он по какой-то причине отвалился, то значение этого ключа будет потеряно. Для многих задач это не критично, однако для банковской сферы это скорее исключение, чем правило. В нашем случае принципиально иметь несколько копий данных для надежного хранения.
Поэтому рассматривался исключительно режим работы CS в режиме тройной репликации, т.е. создание кейспейса выполнялось с такими параметрами:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3};Далее есть два способа обеспечить необходимый уровень консистентности. Общее правило:
NW + NR > RF
Что означает, что количество подтверждений от нод при записи (NW) плюс количество подтверждений от нод при чтении (NR) должно быть больше фактора репликации. В нашем случае RF = 3 и значит подходят следующие варианты:
2 + 2 > 3
3 + 1 > 3
Так как нам принципиально важно максимально надежно сохранить данные, была выбрана схема 3+1. К тому же HB работает по аналогичному принципу, т.е. такое сравнение будет более честным.
Необходимо отметить, что DataStax в своем исследовании делали наоборот, они ставили RF = 1 и для CS и для HB (для последней путем изменения настроек HDFS). Это действительно важный аспект, потому что влияние на производительность CS в этом случае огромное. Например, на картинке ниже показан рост времени требующегося для загрузки данных в CS:
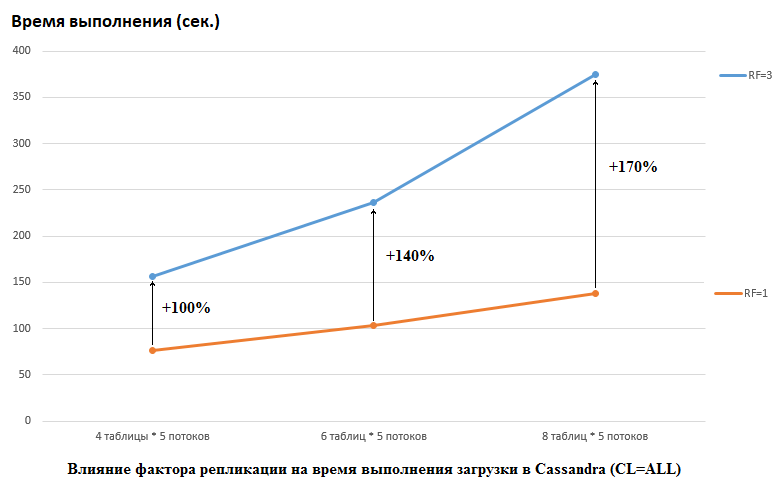
Тут мы видим следующее, чем больше конкурирующих потоков пишет данные, тем дольше времени это занимает. Это естественно, но важно, что при этом деградация производительности для RF=3 существенно выше. Иными словами, если мы пишем в 4 таблицы в каждую по 5 потоков (итого 20), то RF=3 проигрывает примерно в 2 раза (150 секунд RF=3 против 75 для RF=1). Но если мы увеличим нагрузку, загружая данные в 8 таблиц в каждую по 5 потоков (итого 40), то проигрыш RF=3 уже в 2,7 раз (375 секунд против 138).
Возможно, отчасти в этом заключается секрет успешного для CS нагрузочного тестирования выполненного DataStax, потому что для HB на нашем стенде изменение фактора репликации с 2 до 3 не оказало никакого влияния. Т.е. диски не являются узким местом для HB для нашей конфигурации. Однако тут есть много и других подводных камней, потому что нужно отметить, что наша версия HB была немного пропатчена и затюнена, среды совершенно разные и т.д. Также стоит отметить, что возможно я просто не знаю как правильно готовить CS и существуют какие-то более эффективные способы работать с ней и надеюсь в комментариях мы выясним это. Но обо всем по порядку.
Все тесты производились на железном кластере состоящем из 4 серверов, каждый в конфигурации:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 threads.
Диски: 12 штук SATA HDD
java version: 1.8.0_111
Версия CS: 3.11.5
Параметры cassandra.yml
num_tokens: 256
hinted_handoff_enabled: true
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
hints_directory: /data10/cassandra/hints
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
authenticator: AllowAllAuthenticator
authorizer: AllowAllAuthorizer
role_manager: CassandraRoleManager
roles_validity_in_ms: 2000
permissions_validity_in_ms: 2000
credentials_validity_in_ms: 2000
partitioner: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
— /data1/cassandra/data # каждая директория dataN — отдельный диск
— /data2/cassandra/data
— /data3/cassandra/data
— /data4/cassandra/data
— /data5/cassandra/data
— /data6/cassandra/data
— /data7/cassandra/data
— /data8/cassandra/data
commitlog_directory: /data9/cassandra/commitlog
cdc_enabled: false
disk_failure_policy: stop
commit_failure_policy: stop
prepared_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
saved_caches_directory: /data10/cassandra/saved_caches
commitlog_sync: periodic
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
seed_provider:
— class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
— seeds: "*,*"
concurrent_reads: 256 # пробовали 64 — разницы не замечено
concurrent_writes: 256 # пробовали 64 — разницы не замечено
concurrent_counter_writes: 256 # пробовали 64 — разницы не замечено
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # пробовали 16 Гб — было медленнее
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: false
trickle_fsync_interval_in_kb: 10240
storage_port: 7000
ssl_storage_port: 7001
listen_address: *
broadcast_address: *
listen_on_broadcast_address: true
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: true
native_transport_port: 9042
start_rpc: true
rpc_address: *
rpc_port: 9160
rpc_keepalive: true
rpc_server_type: sync
thrift_framed_transport_size_in_mb: 15
incremental_backups: false
snapshot_before_compaction: false
auto_snapshot: true
column_index_size_in_kb: 64
column_index_cache_size_in_kb: 2
concurrent_compactors: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: false
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: none
client_encryption_options:
enabled: false
internode_compression: dc
inter_dc_tcp_nodelay: false
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
transparent_data_encryption_options:
enabled: false
tombstone_warn_threshold: 1000
tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: false
enable_materialized_views: true
enable_sasi_indexes: true
hinted_handoff_enabled: true
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
hints_directory: /data10/cassandra/hints
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
authenticator: AllowAllAuthenticator
authorizer: AllowAllAuthorizer
role_manager: CassandraRoleManager
roles_validity_in_ms: 2000
permissions_validity_in_ms: 2000
credentials_validity_in_ms: 2000
partitioner: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
— /data1/cassandra/data # каждая директория dataN — отдельный диск
— /data2/cassandra/data
— /data3/cassandra/data
— /data4/cassandra/data
— /data5/cassandra/data
— /data6/cassandra/data
— /data7/cassandra/data
— /data8/cassandra/data
commitlog_directory: /data9/cassandra/commitlog
cdc_enabled: false
disk_failure_policy: stop
commit_failure_policy: stop
prepared_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
saved_caches_directory: /data10/cassandra/saved_caches
commitlog_sync: periodic
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
seed_provider:
— class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
— seeds: "*,*"
concurrent_reads: 256 # пробовали 64 — разницы не замечено
concurrent_writes: 256 # пробовали 64 — разницы не замечено
concurrent_counter_writes: 256 # пробовали 64 — разницы не замечено
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # пробовали 16 Гб — было медленнее
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: false
trickle_fsync_interval_in_kb: 10240
storage_port: 7000
ssl_storage_port: 7001
listen_address: *
broadcast_address: *
listen_on_broadcast_address: true
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: true
native_transport_port: 9042
start_rpc: true
rpc_address: *
rpc_port: 9160
rpc_keepalive: true
rpc_server_type: sync
thrift_framed_transport_size_in_mb: 15
incremental_backups: false
snapshot_before_compaction: false
auto_snapshot: true
column_index_size_in_kb: 64
column_index_cache_size_in_kb: 2
concurrent_compactors: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: false
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: none
client_encryption_options:
enabled: false
internode_compression: dc
inter_dc_tcp_nodelay: false
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
transparent_data_encryption_options:
enabled: false
tombstone_warn_threshold: 1000
tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: false
enable_materialized_views: true
enable_sasi_indexes: true
Настройки GC:
### CMS Settings
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
Памяти jvm.options выделялось 16Gb (еще пробовали 32 Gb, разницы не замечено).
Создание таблиц выполнялось командой:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};Версия HB: 1.2.0-cdh5.14.2 (в классе org.apache.hadoop.hbase.regionserver.HRegion нами был исключен MetricsRegion который приводил к GC при кол-ве регионов более 1000 на RegionServer)
Параметры non-default HBase
zookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 minute(s)
hbase.client.scanner.timeout.period: 2 minute(s)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minute(s)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 hour(s)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 day(s)
HBase Service Advanced Configuration Snippet (Safety Valve) for hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Java Configuration Options for HBase RegionServer:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minute(s)
hbase.snapshot.region.timeout: 2 minute(s)
hbase.snapshot.master.timeout.millis: 2 minute(s)
HBase REST Server Max Log Size: 100 MiB
HBase REST Server Maximum Log File Backups: 5
HBase Thrift Server Max Log Size: 100 MiB
HBase Thrift Server Maximum Log File Backups: 5
Master Max Log Size: 100 MiB
Master Maximum Log File Backups: 5
RegionServer Max Log Size: 100 MiB
RegionServer Maximum Log File Backups: 5
HBase Active Master Detection Window: 4 minute(s)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 millisecond(s)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Maximum Process File Descriptors: 180000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Region Mover Threads: 6
Client Java Heap Size in Bytes: 1 GiB
HBase REST Server Default Group: 3 GiB
HBase Thrift Server Default Group: 3 GiB
Java Heap Size of HBase Master in Bytes: 16 GiB
Java Heap Size of HBase RegionServer in Bytes: 32 GiB
+ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
hbase.rpc.timeout: 2 minute(s)
hbase.client.scanner.timeout.period: 2 minute(s)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minute(s)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 hour(s)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 day(s)
HBase Service Advanced Configuration Snippet (Safety Valve) for hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Java Configuration Options for HBase RegionServer:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minute(s)
hbase.snapshot.region.timeout: 2 minute(s)
hbase.snapshot.master.timeout.millis: 2 minute(s)
HBase REST Server Max Log Size: 100 MiB
HBase REST Server Maximum Log File Backups: 5
HBase Thrift Server Max Log Size: 100 MiB
HBase Thrift Server Maximum Log File Backups: 5
Master Max Log Size: 100 MiB
Master Maximum Log File Backups: 5
RegionServer Max Log Size: 100 MiB
RegionServer Maximum Log File Backups: 5
HBase Active Master Detection Window: 4 minute(s)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 millisecond(s)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Maximum Process File Descriptors: 180000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Region Mover Threads: 6
Client Java Heap Size in Bytes: 1 GiB
HBase REST Server Default Group: 3 GiB
HBase Thrift Server Default Group: 3 GiB
Java Heap Size of HBase Master in Bytes: 16 GiB
Java Heap Size of HBase RegionServer in Bytes: 32 GiB
+ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Создание таблиц:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Тут есть один важный момент — в описании DataStax не сказано, сколько регионов использовалось при создании таблиц HB, хотя это критично для больших объемов. Поэтому для тестов было выбрано кол-во = 64, что позволяет хранить до 640 ГБ, т.е. таблицу среднего размера.
В HBase на момент проведения теста было 22 тысячи таблиц и 67 тысяч регионов (это было бы убийственно для версии 1.2.0, если бы не патч о котором сказано выше).
Теперь что касается кода. Так как не было ясности, какие конфигурации являются более выигрышным для той или иной БД, тесты производились в различных комбинациях. Т.е. в одних тестах загрузка шла одновременно в 4 таблицы (для подключения использовались все 4 ноды). В других тестах работали с 8 разными таблицами. В некоторых случаях размер батча был равен 100, в других 200 (параметр batch — см. код ниже). Размер данных для value 10 байт или 100 байт (dataSize). Всего каждый раз записывалось и вычитывалось по 5 млн. записей в каждую таблицу. При этом в каждую таблицу писали/читали 5 потоков (номер потока — thNum), каждый из которых использовал свой диапазон ключей (count = 1 млн):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Соответственно аналогичный функционал был предусмотрен для HB:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Так как в HB о равномерном распределении данных должен заботиться клиент, то функция соления ключа выглядела так:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Теперь самое интересное — результаты:

Тоже самое в виде графика:
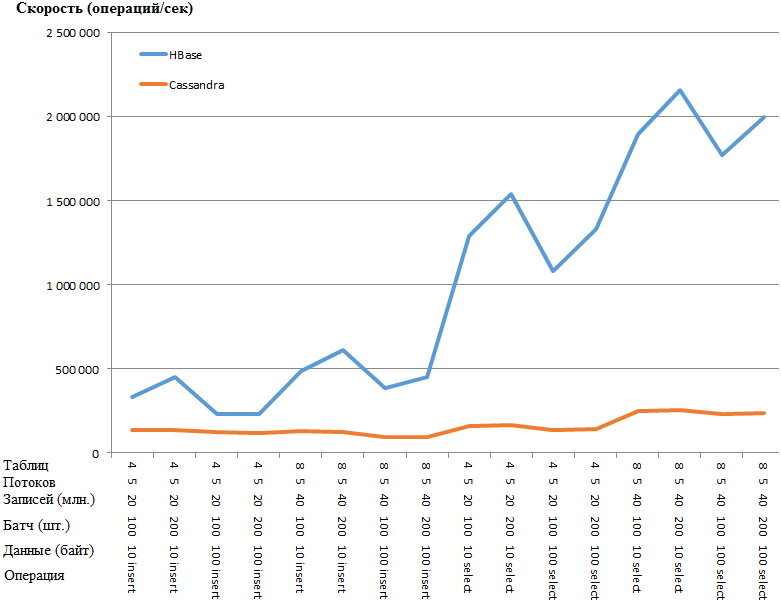
Преимущество HB настолько удивительное, что есть подозрение о наличие какого-то узкого места в настройке CS. Однако гуглеж и кручение наиболее очевидных параметров (вроде concurrent_writes или memtable_heap_space_in_mb) ускорения не дало. При этом в логах чисто, ни на что не ругается.
Данные легли по нодам равномерно, статистика со всех нод примерно одинаковая.
Вот как выглядит статистика по таблице с одной из нод
Keyspace: ks
Read Count: 9383707
Read Latency: 0.04287025042448576 ms
Write Count: 15462012
Write Latency: 0.1350068438699957 ms
Pending Flushes: 0
Table: t1
SSTable count: 16
Space used (live): 148.59 MiB
Space used (total): 148.59 MiB
Space used by snapshots (total): 0 bytes
Off heap memory used (total): 5.17 MiB
SSTable Compression Ratio: 0.5720989576459437
Number of partitions (estimate): 3970323
Memtable cell count: 0
Memtable data size: 0 bytes
Memtable off heap memory used: 0 bytes
Memtable switch count: 5
Local read count: 2346045
Local read latency: NaN ms
Local write count: 3865503
Local write latency: NaN ms
Pending flushes: 0
Percent repaired: 0.0
Bloom filter false positives: 25
Bloom filter false ratio: 0.00000
Bloom filter space used: 4.57 MiB
Bloom filter off heap memory used: 4.57 MiB
Index summary off heap memory used: 590.02 KiB
Compression metadata off heap memory used: 19.45 KiB
Compacted partition minimum bytes: 36
Compacted partition maximum bytes: 42
Compacted partition mean bytes: 42
Average live cells per slice (last five minutes): NaN
Maximum live cells per slice (last five minutes): 0
Average tombstones per slice (last five minutes): NaN
Maximum tombstones per slice (last five minutes): 0
Dropped Mutations: 0 bytes
Read Count: 9383707
Read Latency: 0.04287025042448576 ms
Write Count: 15462012
Write Latency: 0.1350068438699957 ms
Pending Flushes: 0
Table: t1
SSTable count: 16
Space used (live): 148.59 MiB
Space used (total): 148.59 MiB
Space used by snapshots (total): 0 bytes
Off heap memory used (total): 5.17 MiB
SSTable Compression Ratio: 0.5720989576459437
Number of partitions (estimate): 3970323
Memtable cell count: 0
Memtable data size: 0 bytes
Memtable off heap memory used: 0 bytes
Memtable switch count: 5
Local read count: 2346045
Local read latency: NaN ms
Local write count: 3865503
Local write latency: NaN ms
Pending flushes: 0
Percent repaired: 0.0
Bloom filter false positives: 25
Bloom filter false ratio: 0.00000
Bloom filter space used: 4.57 MiB
Bloom filter off heap memory used: 4.57 MiB
Index summary off heap memory used: 590.02 KiB
Compression metadata off heap memory used: 19.45 KiB
Compacted partition minimum bytes: 36
Compacted partition maximum bytes: 42
Compacted partition mean bytes: 42
Average live cells per slice (last five minutes): NaN
Maximum live cells per slice (last five minutes): 0
Average tombstones per slice (last five minutes): NaN
Maximum tombstones per slice (last five minutes): 0
Dropped Mutations: 0 bytes
Попытка уменьшать размер батча (вплоть до отправки поштучно) не дала эффекта, стало только хуже. Возможно, что на самом деле это действительно максимум производительности для CS, так как полученные результаты по CS похожи на те, что получились и у DataStax — порядка сотни тысяч операций в секунду. Кроме того, если посмотреть на утилизацию ресурсов, то увидим, что CS использует гораздо больше и ЦПУ и дисков:
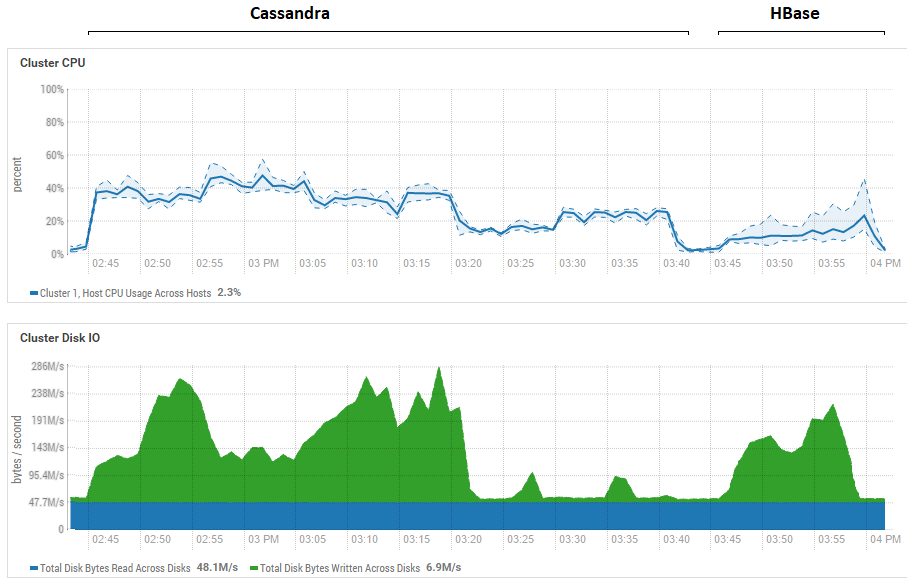
На рисунке показана утилизация во время прогона всех тестов подряд для обоих БД.
Что касается мощного преимущества HB при чтении. Тут видно, что для обоих БД утилизация дисков при чтении крайне низкая (тесты на чтение это завершающая часть цикла тестирования каждой БД, например для CS это с 15:20 до 15:40). В случае HB причина понятна — большая часть данных висит в памяти, в memstore и часть закешировалась в blockcache. Что касается CS, то тут не очень ясно как она устроена, однако также утилизации дисков не видно, но на всякий случай была сделана попытка включить кэш row_cache_size_in_mb = 2048 и установлен caching = {‘keys’: ‘ALL’, ‘rows_per_partition’: ‘2000000’}, но от этого стало даже чуть хуже.
Также стоит еще раз проговорить существенный момент про кол-во регионов в HB. В нашем случае было указано значение 64. Если же уменьшать его и сделать равным например 4, то при чтении скорость падает в 2 раза. Причина в том, что memstore будет забиваться быстрее и файлы будут флашиться чаще и при чтении нужно будет обрабатывать больше файлов, что для HB достаточно сложная операция. В реальных условиях это лечится продумыванием стратегии пресплитинга и компактификации, в частности мы используем самописную утилиту, которая занимается сборкой мусора и сжатием HFiles постоянно в фоновом режиме. Вполне возможно, что для тестов DataStax выделяли вообще 1 регион на таблицу (что не правильно) и это бы несколько прояснило, почему HB так проигрывал в их тестах на чтение.
Предварительные выводы отсюда получаются следующие. Если допустить, что в ходе тестирования не было допущено грубых ошибок, то Cassandra похожа на колосса на глиняных ногах. Точнее, пока она балансирует на одной ноге, как на картинке в начале статьи, она показывает относительно неплохие результаты, но при схватке в одинаковых условиях проигрывает вчистую. При этом учитывая низкую утилизацию CPU на нашем железе мы научились высаживать по два RegionServer HB на хост и тем самым удвоили производительность. Т.е. с учетом утилизации ресурсов ситуация для CS получается еще более плачевная.
Безусловно, эти тесты достаточно синтетические и объем данных, который использовался тут, относительно скромный. Не исключено, что при переходе на терабайты ситуация была бы иная, однако если для HB мы умеем грузить терабайты, то для CS это оказалось проблематично. Она зачастую выдавала OperationTimedOutException даже при этих объемах, хотя параметры ожидания отклика и так были увеличены в разы по сравнению с дефолтными.
Надеюсь, что совместными усилиями мы найдем узкие места CS и если получится её ускорить, то в конце поста обязательно добавлю информацию об итоговых результатах.
UPD: Были применены следующие рекомендации на настройке CS:
disk_optimization_strategy: spinning
MAX_HEAP_SIZE=«32G»
HEAP_NEWSIZE=«3200M»
-Xms32G
-Xmx32G
-XX:+UseG1GC
-XX:G1RSetUpdatingPauseTimePercent=5
-XX:MaxGCPauseMillis=500
-XX:InitiatingHeapOccupancyPercent=70
-XX:ParallelGCThreads=32
-XX:ConcGCThreads=8
Что касается настроек ОС, это достаточно долгая и сложная процедура (получать рута, ребутить сервера и т.д.), поэтому эти рекомендации не применялись. С другой стороны, обе БД в равных условиях, так что все честно.
В части кода, сделан один коннектор для всех потоков пишущих в таблицу:
connector = new CassandraConnector();
connector.connect(node, null, CL);
session = connector.getSession();
session.getCluster().getConfiguration().getSocketOptions().setConnectTimeoutMillis(120000);
KeyspaceRepository sr = new KeyspaceRepository(session);
sr.useKeyspace(keyspace);
prepared = session.prepare("insert into " + tableName + " (id, title) values (?, ?)");Данные отправлялись через биндинг:
for (Long key = count * thNum; key < count * (thNum + 1); key++) {
String value = RandomStringUtils.random(dataSize, true, true);
session.execute(prepared.bind(key, value));
}Это не оказало ощутимого влияния на производительность записи. Для надежности запустил нагрузку инструментом YCSB, абсолютно такой же результат. Ниже статистика по одному потоку (из 4х):
2020-01-18 14:41:53:180 315 sec: 10000000 operations; 21589.1 current ops/sec; [CLEANUP: Count=100, Max=2236415, Min=1, Avg=22356.39, 90=4, 99=24, 99.9=2236415, 99.99=2236415] [INSERT: Count=119551, Max=174463, Min=273, Avg=2582.71, 90=3491, 99=16767, 99.9=99711, 99.99=171263]
[OVERALL], RunTime(ms), 315539
[OVERALL], Throughput(ops/sec), 31691.803548848162
[TOTAL_GCS_PS_Scavenge], Count, 161
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 2433
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.7710615803434757
[TOTAL_GCS_PS_MarkSweep], Count, 0
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0
[TOTAL_GCs], Count, 161
[TOTAL_GC_TIME], Time(ms), 2433
[TOTAL_GC_TIME_%], Time(%), 0.7710615803434757
[INSERT], Operations, 10000000
[INSERT], AverageLatency(us), 3114.2427012
[INSERT], MinLatency(us), 269
[INSERT], MaxLatency(us), 609279
[INSERT], 95thPercentileLatency(us), 5007
[INSERT], 99thPercentileLatency(us), 33439
[INSERT], Return=OK, 10000000
Тут видно что скорость одного потока порядка 32 тыс записей в секунду, работало 4 потока, получается 128 тыс. Кажется, большего на текущих настройках дисковой подсистемы не выжать.
Насчет чтения интереснее. Благодаря советам камрадов его удалось радикально ускорить. Чтение осуществлялось не в 5 потоков, а в 100. Увеличение до 200 эффекта уже не давало. Также в билдер добавлено:
.withLoadBalancingPolicy(new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
В результате, если раньше тест показывал 159 644 ops (5 потоков, 4 таблицы, батч 100), то теперь:
100 потоков, 4 таблицы, батч = 1 (поштучно): 301 969 ops
100 потоков, 4 таблицы, батч = 10: 447 608 ops
100 потоков, 4 таблицы, батч = 100: 625 655 ops
Так как результаты лучше с батчами, прогнал аналогичные* тесты с HB:

*Так как при работе в 400 потоков функция RandomStringUtils, которая использовалась ранее, грузила CPU на 100%, она была заменена более быстрым генератором.
Таким образом, увеличение количества потоков при загрузке данных дает небольшой прирост производительности HB.
Что касается чтения, тут приведены результаты нескольких вариантов. По просьбе 0x62ash выполнялась команда flush перед чтением и также приведены для сравнения несколько других вариантов:
Memstore — чтение из памяти, т.е. до сброса на диск.
HFile+zip — чтение из файлов, сжатых алгоритмом GZ.
HFile+upzip — чтение из файлов без сжатия.
Обращает на себя внимание занятная особенность — маленькие файлы (см. поле «Данные», где записи 10 байт) обрабатываются медленнее, особенно если они сжаты. Очевидно, что это так только до определенного размера, явно файл в 5 Гб не будет обработан быстрее 10 Мб, но явно указывает на то, что во всех этих тестах еще не паханное поле для исследований различных конфигураций.
Для интереса поправил код YCSB для работы с HB батчами по 100 штук, чтобы замерить латентность и прочее. Ниже результат работы 4-х экземпляров, которые писали в свои таблицы, каждый по 100 тредов. Получилось следующее:
Одна операция = 100 записей
[OVERALL], RunTime(ms), 1165415
[OVERALL], Throughput(ops/sec), 858.06343662987
[TOTAL_GCS_PS_Scavenge], Count, 798
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7346
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6303334005483026
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 74
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006349669431061038
[TOTAL_GCs], Count, 799
[TOTAL_GC_TIME], Time(ms), 7420
[TOTAL_GC_TIME_%], Time(%), 0.6366830699793635
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 115893.891644
[INSERT], MinLatency(us), 14528
[INSERT], MaxLatency(us), 1470463
[INSERT], 95thPercentileLatency(us), 248319
[INSERT], 99thPercentileLatency(us), 445951
[INSERT], Return=OK, 1000000
20/01/19 13:19:16 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cc
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cc closed
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1165806
[OVERALL], Throughput(ops/sec), 857.7756504941646
[TOTAL_GCS_PS_Scavenge], Count, 776
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7517
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6447899564764635
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 63
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.005403986598113236
[TOTAL_GCs], Count, 777
[TOTAL_GC_TIME], Time(ms), 7580
[TOTAL_GC_TIME_%], Time(%), 0.6501939430745767
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116042.207936
[INSERT], MinLatency(us), 14056
[INSERT], MaxLatency(us), 1462271
[INSERT], 95thPercentileLatency(us), 250239
[INSERT], 99thPercentileLatency(us), 446719
[INSERT], Return=OK, 1000000
20/01/19 13:19:16 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x26f98ad07b6d67e
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Session: 0x26f98ad07b6d67e closed
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1165999
[OVERALL], Throughput(ops/sec), 857.63366863951
[TOTAL_GCS_PS_Scavenge], Count, 818
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7557
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6481137633908777
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 79
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006775305982252128
[TOTAL_GCs], Count, 819
[TOTAL_GC_TIME], Time(ms), 7636
[TOTAL_GC_TIME_%], Time(%), 0.6548890693731299
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116172.212864
[INSERT], MinLatency(us), 7952
[INSERT], MaxLatency(us), 1458175
[INSERT], 95thPercentileLatency(us), 250879
[INSERT], 99thPercentileLatency(us), 446463
[INSERT], Return=OK, 1000000
20/01/19 13:19:17 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cd
20/01/19 13:19:17 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cd closed
20/01/19 13:19:17 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1166860
[OVERALL], Throughput(ops/sec), 857.000839860823
[TOTAL_GCS_PS_Scavenge], Count, 707
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7239
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6203829079752499
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 67
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0057419056270675145
[TOTAL_GCs], Count, 708
[TOTAL_GC_TIME], Time(ms), 7306
[TOTAL_GC_TIME_%], Time(%), 0.6261248136023173
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116230.849308
[INSERT], MinLatency(us), 7352
[INSERT], MaxLatency(us), 1443839
[INSERT], 95thPercentileLatency(us), 250623
[INSERT], 99thPercentileLatency(us), 447487
[INSERT], Return=OK, 1000000
[OVERALL], Throughput(ops/sec), 858.06343662987
[TOTAL_GCS_PS_Scavenge], Count, 798
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7346
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6303334005483026
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 74
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006349669431061038
[TOTAL_GCs], Count, 799
[TOTAL_GC_TIME], Time(ms), 7420
[TOTAL_GC_TIME_%], Time(%), 0.6366830699793635
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 115893.891644
[INSERT], MinLatency(us), 14528
[INSERT], MaxLatency(us), 1470463
[INSERT], 95thPercentileLatency(us), 248319
[INSERT], 99thPercentileLatency(us), 445951
[INSERT], Return=OK, 1000000
20/01/19 13:19:16 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cc
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cc closed
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1165806
[OVERALL], Throughput(ops/sec), 857.7756504941646
[TOTAL_GCS_PS_Scavenge], Count, 776
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7517
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6447899564764635
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 63
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.005403986598113236
[TOTAL_GCs], Count, 777
[TOTAL_GC_TIME], Time(ms), 7580
[TOTAL_GC_TIME_%], Time(%), 0.6501939430745767
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116042.207936
[INSERT], MinLatency(us), 14056
[INSERT], MaxLatency(us), 1462271
[INSERT], 95thPercentileLatency(us), 250239
[INSERT], 99thPercentileLatency(us), 446719
[INSERT], Return=OK, 1000000
20/01/19 13:19:16 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x26f98ad07b6d67e
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Session: 0x26f98ad07b6d67e closed
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1165999
[OVERALL], Throughput(ops/sec), 857.63366863951
[TOTAL_GCS_PS_Scavenge], Count, 818
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7557
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6481137633908777
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 79
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006775305982252128
[TOTAL_GCs], Count, 819
[TOTAL_GC_TIME], Time(ms), 7636
[TOTAL_GC_TIME_%], Time(%), 0.6548890693731299
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116172.212864
[INSERT], MinLatency(us), 7952
[INSERT], MaxLatency(us), 1458175
[INSERT], 95thPercentileLatency(us), 250879
[INSERT], 99thPercentileLatency(us), 446463
[INSERT], Return=OK, 1000000
20/01/19 13:19:17 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cd
20/01/19 13:19:17 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cd closed
20/01/19 13:19:17 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1166860
[OVERALL], Throughput(ops/sec), 857.000839860823
[TOTAL_GCS_PS_Scavenge], Count, 707
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7239
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6203829079752499
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 67
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0057419056270675145
[TOTAL_GCs], Count, 708
[TOTAL_GC_TIME], Time(ms), 7306
[TOTAL_GC_TIME_%], Time(%), 0.6261248136023173
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116230.849308
[INSERT], MinLatency(us), 7352
[INSERT], MaxLatency(us), 1443839
[INSERT], 95thPercentileLatency(us), 250623
[INSERT], 99thPercentileLatency(us), 447487
[INSERT], Return=OK, 1000000
Получается, что если у CS AverageLatency(us) на запись 3114, то у HB AverageLatency(us) = 1162 (помним, что 1 операция = 100 записям и поэтому надо делить).
В целом получается такой вывод — в заданных условиях имеет место существенное преимущество HBase. Однако нельзя исключать, что SSD и тщательный тюнинг ОС изменит картину радикально. Также нужно понимать, что очень многое зависит от сценариев использования, запросто может оказаться так, что если взять не 4 таблицы, а 400 и работать с терабайтами, баланс сил сложится совсем иным образом. Как говорили классики: практика — критерий истины. Надо пробовать. За одно ScyllaDB теперь уже имеет смысл проверить, так что продолжение следует…
