Срез КТ с зонами «матового стекла»
Пациентам с подтверждённым COVID-19 делают компьютерную томографию лёгких. Если повезёт — один раз, если нет — несколько. В первый раз нужно оценить уровень поражения в процентах. В зависимости от квартиля степени поражения определяется дальнейшая схема лечения, и они разительно отличаются. В апреле 2020 мы узнали, что есть две сложности:
- КТ — трёхмерное изображение, каждый слой такого изображения называется срезом. При 300–800 срезах лёгких на КТ врачи тратят от 1 до 15 минут на поиск характерных зон, чтобы определить степень поражения. Одна минута — это «на глаз», 30 минут — это среднее при ручном выделении и подсчёте зон повреждённой ткани. В сложных случаях результат может обрабатываться до часа.
- Точность диагностики уровня поражения коронавирусом экспертами «на глаз» высока на границах 0–30 % и 70–100 %. В диапазоне 30–70 погрешность очень высока, и мы обратили внимание, что кто-то из рентгенологов, как правило, системно завышает процент поражения на глаз, а кто-то занижает.
Задача сводится к определению повреждённой ткани лёгких и подсчёту доли их объёма к общему лёгких.
В конце апреля в кооперации с клиниками мы подготовили датасет обезличенных исследований пациентов с подтверждённым ПЦР-анализом COVID-19, отдали комиссии из десяти отличных экспертов-рентгенологов и разметили выборку для обучения с учителем.
В конце мая была бета. В июле была готовая модель для разных видов используемого в России КТ-оборудования. Мы — это команда в Лаборатории по искусственному интеллекту Сбера. Мы в целом публикуем свои разработки в научной литературе (MICCAI, AIME, BIOSIGNALS), а про это будем рассказывать ещё на AI Journey.
Почему это важно
Рентгенологи в конце апреля уже получили очереди. Важно было:
- Увеличить пропускную способность точек с КТ-исследованиями.
- Увеличить точность исследований во-вторых.
- Дать возможность точно видеть изменение по уровню поражения между снимками одного пациента (а это может быть и пара процентов, важно понимать, больше стало или меньше).
Дальше, в первую волну, ситуация стала хуже, потому что опытные врачи-рентгенологи заболевали и выходили из процесса. Падала точность и скорость.
Искусственный интеллект хорош в задачах классификации медицинских данных. Правильная приоритизация пациентов спасает жизни, потому что чем точнее мы определяем степень поражения, тем больше шансов, что серьёзно заболевший человек получит вовремя необходимые препараты и (если всё пошло хуже) ИВЛ. И что человек, у которого лёгкие поражены не так сильно, не займёт его место в больнице.
Оценка доли поражения — одна из сложных и ресурсоёмких задач для человека в диагностике, потому что нужно оценить большой объём очагов неправильной формы, разбитых на множество срезов.
Сама задача
На входе — аксиальные срезы определённой толщины. Обычно в настройках ставится от 0,5 мм до 2,5 мм. Грудная клетка — это от 300 до 800 двухмерных картинок. Они приведены в примерное соответствие друг с другом, то есть уже преобразованы так, чтобы можно было выстроить, условно, снимки на полупрозрачной плёнке заданной же толщины, и получилась бы модель грудной клетки. Но всё уже давно, разумеется, в цифровом виде.
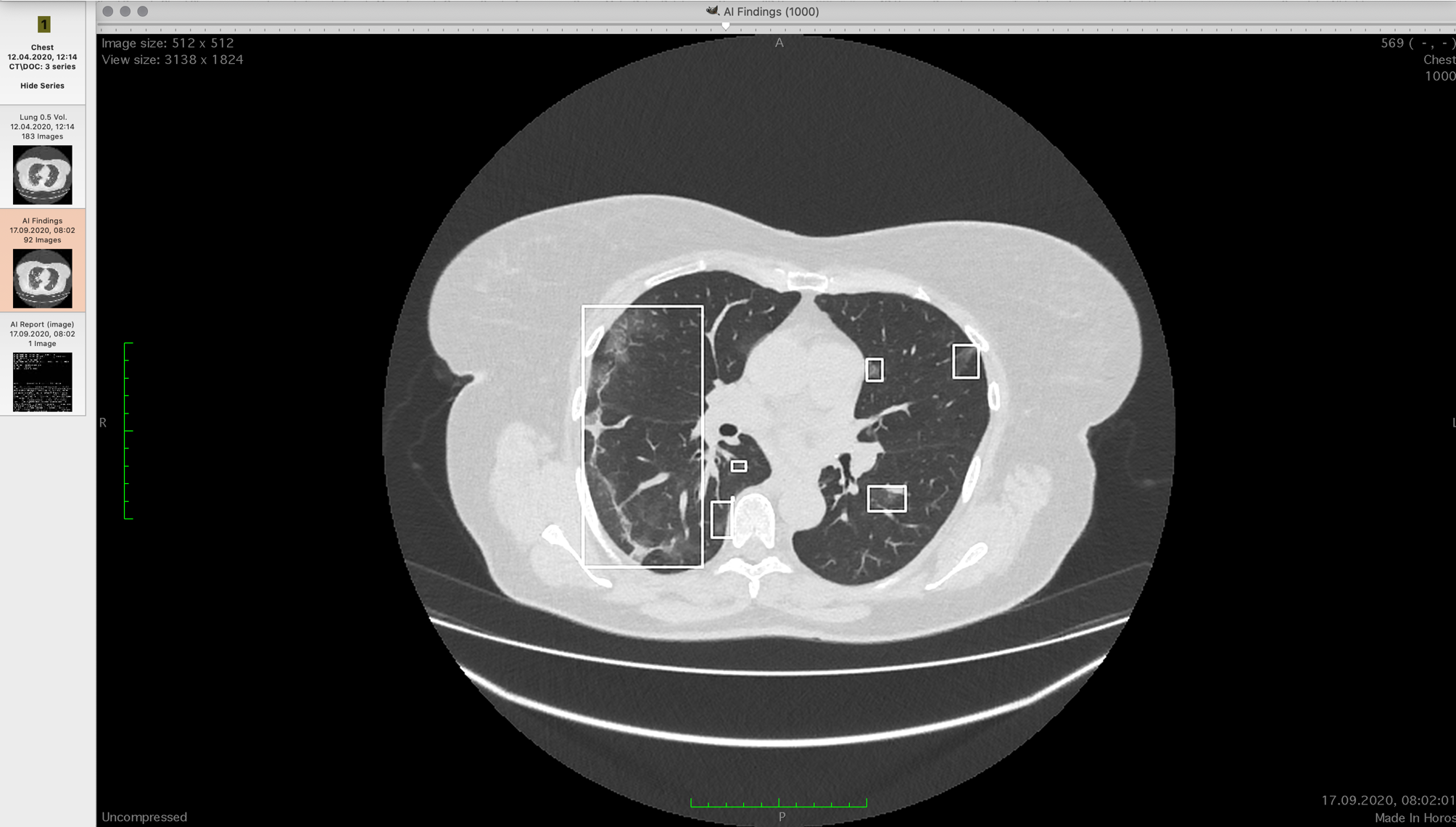
Просмотрщики могут показывать КТ по слоям или строить 3D-модель. Модели не очень информативны для врачей, поскольку по ним сложно понять локализацию очагов данного типа поражений. Профессионалы часто используют мультипланарную реконструкцию — выводят на экран три ортогональных проекции — горизонтальную, фронтальную и сагиттальную. Затем по очереди просматривают каждую ось по срезам, ища необходимое. Происходит это в практике быстро. Нужно три раза просмотреть по 500 вот таких картинок:

У разных врачей получается разный результат по доле поражения после такого просмотра.
Нам нужно измерить объём лёгкого в грудной клетке и найти там все консолидации, а затем оценить их объём. В первой выборке мы взяли 60 000 реконструированных срезов КТ (аппарат снимает в одной оси, но преобразованиями можно получить нужные проекции).
Наши десять врачей не стали оценивать на глаз, а выделили все консолидации вручную, тщательно просмотрев каждый срез. Мы немного обогатили обучающую выборку аугментацией — комбинацией растяжений, сжатий, поворотов и сдвигов на имеющейся выборке.
Алгоритм определяет для каждой точки наличие консолидации. Использованная нейросетевая модель основывается на архитектуре U-Net, опубликованной в 2016 году. Преимущество архитектуры U-Net в том, что нейросеть анализирует исходные изображения в разных масштабах, и это позволяет свёрточным слоям «смотреть» на участки картинки, размер которых растёт в геометрической прогрессии по мере увеличения глубины нейросети. Другими словами, каждая свёртка «смотрит» на маленькую зону 3 × 3 px. Потом происходит уменьшение масштаба в два раза, потом ещё в два: каждая следующая свёртка смотрит на область 3 × 3 пикселя, но за этими пикселями стоят части изображения, уменьшенные в несколько раз (6 × 6, 12 × 12, …). В итоговом ансамбле ещё две свёрточных нейросети похожей архитектуры на базе U-Net, с более тяжелой «сжимающей» частью, чем в оригинальной статье.
Где ошибается сеть, но не ошибаются врачи
Иногда на снимках встречаются так называемые артефакты будь то результат дыхания или движения тела. В этом случае на снимках появляются участки по характеристикам похожие на изменения, но это не является патологией. Даже если модель выделила эти участки, то общее их влияние на результат составляет несколько десятых долей процента, а решения принимаются по квартилям, то есть нужно отнести пациента к одной из четырёх категорий по степени поражения. Поэтому мы пренебрегли этой частью задачи. Гораздо важнее было настроить сеть под каждый тип используемого оборудования в стране.
Нормализация
Томографы пишут файлы в стандарте DICOM, но интерпретация стандарта и форматы записи могут сильно отличаться, поэтому много времени и нервов ушло на поддержку файлов, которые пишут все КТ аппараты. В итоге у нас появился ещё и инструмент сведения всех DICOM-файлов к единому стандарту и единому виду, что пригодится дальше для решения задач уже диагностики, если мы за них возьмёмся. И не только COVID-19.
Наш софт не мешает врачу, а ставится параллельно. У него есть его привычные инструменты и наше решение, которое показывает дополнительную серию с аналитическим отчётом и локализацией найденных консолидаций. Аналитический отчёт выглядит так:

ПО поставляется Оn-premise и включается в рабочий процесс клиники, работая с КТ-аппаратами и рабочими станциями врачей по протоколу DICOM, ставится на сервера клиники внутри защищённого контура, для работы нейросети нужен мощный GPU. Есть так же облачное решение, потому что не каждая региональная клиника может себе такое позволить. Есть особенности с передачей медицинских данных, нужно гарантированно обезличивать.
Почему производители томографов ничего не делали?
Может показаться, что мы одни такие герои, которые взялись за задачу. Нет, были и другие подходы. Чаще всего производители томографов доделывали сортировку по шкале Хаунсфилда (плотности тканей) и выпускали либо готовые, эээ… лицензируемые отдельно плагины, либо методические рекомендации, как выставить настройки так, чтобы увидеть только определённый тип ткани. Это позволило лучше видеть консолидации (в идеале в кадре оставались только характерные для них ткани по плотности для потока излучения), но всё ещё не давало считать автоматически. Более того, разблокировка такой фичи часто стоила дороже, чем несколько наших внедрений и GPU-серверов к ним.
Где смотреть больше деталей
Вот здесь.
Ещё детали.
