Comments 89
Кроме возврата значения, здесь также определено, что в случае валидного email сразу присваивать его значение (делаем Command) полю Email.
То есть достаточно назвать метод "TryChangeEmail", который пытается изменить email и возвращает статус изменения, и вашей проблемы с недопониманием что делает метод не будет. Разделение на 2 метода тут не требуется.
Еще важнее, что эти два уровня могут находиться даже в двух разных звеньях (tiers) и оптимизироваться раздельно, никак не затрагивая друг друга.
Командам как правило необходимо делать запросы в процессе работы. И какой толк в этом случае от разделения команд и запросов, если они всё равно получаются сильно связанными?
Запросы лучше делать не из команд, а из process-менеджеров. Для таких транзакций тут не хватает event sourcing.
Командам нужно делать в процессе работы запросы к базе, но эти запросы не будут буквой Q в CQRS.
А смысл дублировать код запросов?
А дублирования обычно и не происходит.
Q: найти всех программистов
C: найти всех программистов и уволить найденных
Это — плохая команда, поскольку подвержена состоянию гонки. Между Q и C наверняка же кто-то просмотрел список программистов и утвердил — и команда должна исполнить именно утвержденное действие, а не абы какое.
Поэтому команды обычно работают с явными списками первичных ключей, в то время как запросы обычно выполняют фильтрацию по неключевым полям.
C: взять сотрудников с id из некоторого списка и уволить найденных
Вы не фантазируйте про обычно/необычно. Есть бизнес-задача: "Реализовать кнопку быстрого увольнения всех программистов, безо всяких утверждений/подтверждений".
Ну или более реалистичный вариант: "Реализовать кнопку быстрой выплаты всем менеджерам зарплаты" :-)
В такой задаче запрос (Q) вообще не нужен, достаточно одной команды (C).
Реализовать отчёт "список всех менеджеров". Опа, и Q появился. И грех не воспользоваться им из C.
Отчёт — это отчёт, к чему там команды?
Q: дай список всех менеджеров
C: возьми (Q) и выдай им зарплату.
Если это две стадии одного сценария использования — то команда должна использовать явный список менеджеров, найденных на первом шаге.
Если же это два различных сценария использования — то лучше им не иметь общего кода. Потому что отчеты имеют свойство меняться по желанию левой пятки начальника, и нежелательно чтобы этот хаос мог затронуть команду. Иными словами, совпадение запросов в Q и C — это случайность, а не закономерность.
Немного странно) Отчёт в моём понимании — это, грубо говоря, табличка с выводом сгруппированных данных. Тот же вывод на экран счёта с конкретными позициями, например.
Если я вас правильно понял, то как в таком случае табличка (т.е. сводка) с менеджерами относится к выплате им зарплаты?
"найти всех программистов" не обязательно выполняются в одном контексте. Разделение Q и C происходит как раз для того, чтобы было удобнее оптимизировать чтение и запись, например читать из быстрого для чтения хранилища (денормализованный nosql), а записывать в стандартную реляционку.
Не воспринимайте query как какой-то промежуточный запрос в базу и серии "найти -> уволить найденных".
Query — "Найти всех программистов" для, например отображения в списке в UI.
Command — "Уволить всех имеющихся программистов", которая попадает в процесс-менеджер, который идет в сервис/аггрегат и с ним уже может общаться через несколько методов и/или через ES или просто через один готовый метод.
Как ни накручивай абстракции, а код получения списка всех программистов будет одинаковый.
Зависит от того, где эти программисты лежат — во Write DB или в Read DB.
CQRS не решает вопрос переиспользования какого-либо кода, а лишь вопрос масштабируемости.
Никто вам не мешает все сваливать в один сервис с одной базой и с методом tryFireEverybody. Когда придется масштабироваться — будете накручивать абстракции.
Да, но мы помним про eventual consistency, как тут уже несколько раз упоминали.
В этом случае нужно будет бороться с CQRS:
1. ждем, пока база синхронизируется (долгий/очень долгий запрос команды)
2. делаем «синхронизацию» руками (сложный и скользкий путь, с множеством проблем)
В целом, подход очень хороший, но он подходит больше для «энтерпрайзов» с большим количеством сложной логики и сложными workflow, где нету необходимости быстро отдать ответ.
Правильно?
Именно, все верно, причем для высоконагруженных энтерпрайзов.
Если вам интересно, могу посоветовать вот эту книжку.
Насколько я понимаю, в CQRS зависимость почти всегда односторонняя: обработчики команд могут обновлять данные для чтения, но никогда не читают их.
В случае, когда нужно перед записью данных их прочитать (а нужно практически всегда), то читают из данных для записи (если нет event sourcing, а данные реляционные), или обработчик команд имеет внутреннее состояние, которое и используется для принятия решений (и обновляется при вызовах команд) — это в случае, если есть ивент сорсинг и данные для записи так просто не прочесть.
Ну и опять же, даже в случае с ивент сорсингом, можно хранить дополнительные реляционные данные (хотя это и влечет дополнительные проблемы).
В CQRS данные для чтения (для запросов) могут отличаться от данных для обработки (для команд). Поэтому дублирования (и гонки) тут не будет, скорее всего.
Да они везде могут отличаться. А могут и не отличаться. Смысл дублировать логику, если нужны ровно те же данные?
Если они не отличаются, CQRS не нужен.
Смысл его в том, чтобы оптимизировать производительность приложения, выполняя расчеты (трансформации данных) во время записи (а не во время чтения).
Поэтому же CQRS подходит только приложениям, у которых интенсивность чтения намного больше интенсивности записи.
Никто не мешает "оптимизировать производительность приложения, выполняя расчеты во время записи" и без разделения кода на кучки. От того, что вы разделили код на C и Q предагрегация у вас в коде волшебным образом не появится.
Ну, в общем-то, да. Можно.
CQRS, если он с командами и event sourcing-ом, имеет много больше точек оптимизации, плюс некоторые фичи, типа получения состояния на любой момент времени.
И разделение кода на кучки — это так само получается, если все это реализовывать.
ПС Разделение кода на C и Q — это, вообще-то, здравая идея, которая называется CQS (command-query separation). Этот принцип говорит, что каждый метод в приложении должен либо возвращать данные, либо их модифицировать, но модификация при чтении — это плохая идея.
Модификация при чтении — это либо говнокод, либо такая бизнес задача (считать число запросов, например). CQ®S тут ни при чём. А вот чтение при модификации — необходимая штука. А корень всех проблем — неидемпотентность. Например, запрос getTime, хотя и ничего не изменяет, но не идемпотентен, поэтому его ни закешировать, ни дёрнуть лишний раз нельзя. А вот команда setUserName(name), хотя и изменяет данные, но идемпотентен, а значит её можно спокойно вызывать сколько угодно раз, получая один и тот же результат, или наоборот, не вызывать, если имя пользователя и так уже равно передаваемому.
То есть достаточно назвать метод «TryChangeEmail», который пытается изменить email и возвращает статус изменения, и вашей проблемы с недопониманием что делает метод не будет. Разделение на 2 метода тут не требуется.
Конечно, в случае такого простого примера это может и не понадобиться.
Основная суть заключается в том, чтобы в подобных ситуациях было контролируемое разделение. В качестве другого примера можно взять более сложную и довольно типичную задачу: имеется метод, в котором идет создание нового пользователя, а после этого метод возвращает связанный с ним объект или его Id. Тем самым смешиваются команда и запрос.
На что это влияет? Это сразу отбрасывает возможность асинхронной операции, а это означает, что пользователь будет вынужден ждать, пока завершится операция, и вернется результат. Т.к. мы вынуждены возвращать результат сразу после команды, мы не сможем, например, добавить дополнительную БД, которая бы хранила и возвращала данные для запросов, а команды бы выполнялись на другой БД, тем самым распределяя нагрузку.
Иными словами, чем сложнее логика, тем больше эти и какие-либо другие факторы будут сказываться как на производительности, так и на сложности самого приложения.
Командам как правило необходимо делать запросы в процессе работы. И какой толк в этом случае от разделения команд и запросов, если они всё равно получаются сильно связанными?
В CQRS предлагается стремиться к тому, чтобы команда (или запрос) выполняла только строго определенную задачу, а вот сама команда уже может являться частью какой-либо бо́льшей задачи.
То есть все необходимые запросы и валидация должны быть сделаны до того, как команда начнет выполняться, и ей должны быть переданы необходимые данные. Тем самым будут иметься отдельные Query, вместо того, чтобы выполнять их в команде.
Как теперь делать создание нового пользователя и получение его id?
Как поиск его по имени пользователя? А если кто-то другой это имя пользователя в это же время зарегистрировал, как мы сможем это понять и не начать использовать чужую запись?
Как я понимаю, ваша описанная схема вообще не дружит с транзакциями.
Можно придумать обходные пути (двухфазный коммит, версионирование), но это уже усложнение, а не упрощение. Подобные усложнения приходится использовать для big data, но это вынужденная мера, а не преимущество подхода.
А вот если бы вы разрешили командам одновременно писать и получать данные, а запросам бы запретили писать — то уже стало бы удобнее этим пользоваться.
И как cqrs предлагает справляться с проблемой консистентности изменений?
проблему консистентности данных я бы оставил слою хранения данных. код должен будет обработать ошибку выполнения команды в соответствии с требованиями.
А вот если бы вы разрешили командам одновременно писать и получать данные, а запросам бы запретили писать — то уже стало бы удобнее этим пользоваться.
мне кажется, что CQRS не запрещает обращения к базе для чтения в командах (и точно не запрещает этого во всей подсистеме выполнения команд). тем не менее, лично я выношу код чтения в подготовку контекста команды, в коде исполнения оставляя исключительно операции записи.
В данных для записи консистентность будет строгая (как в обычном приложении). А вот между базами для чтения и для записи будет eventual consistency, то есть они будут согласованы когда-нибудь, но не прямо сейчас. Именно поэтому в обработчиках команд обычно не используется Read DB.
имеется метод, в котором идет создание нового пользователя, а после этого метод возвращает связанный с ним объект или его Id. Тем самым смешиваются команда и запрос.
И как потом найти свежесозданного пользователя, если команда не будет возвращать нам его id?
Это сразу отбрасывает возможность асинхронной операции
Не отбрасывает. Возвращается либо id создаваемого пользователя, либо id асинхронной операции. Иначе о результате команды можно узнать лишь как-нибудь косвенно.
Т.к. мы вынуждены возвращать результат сразу после команды, мы не сможем, например, добавить дополнительную БД, которая бы хранила и возвращала данные для запросов
Можем. Создаём 2 соединения: из одного читаем, в другое пишем. Оба соединения могут быть легко инкапсулированы в одном субд адаптере, позволяя программисту вообще не думать о том, что у него есть 2 базы.
То есть все необходимые запросы и валидация должны быть сделаны до того, как команда начнет выполняться, и ей должны быть переданы необходимые данные.
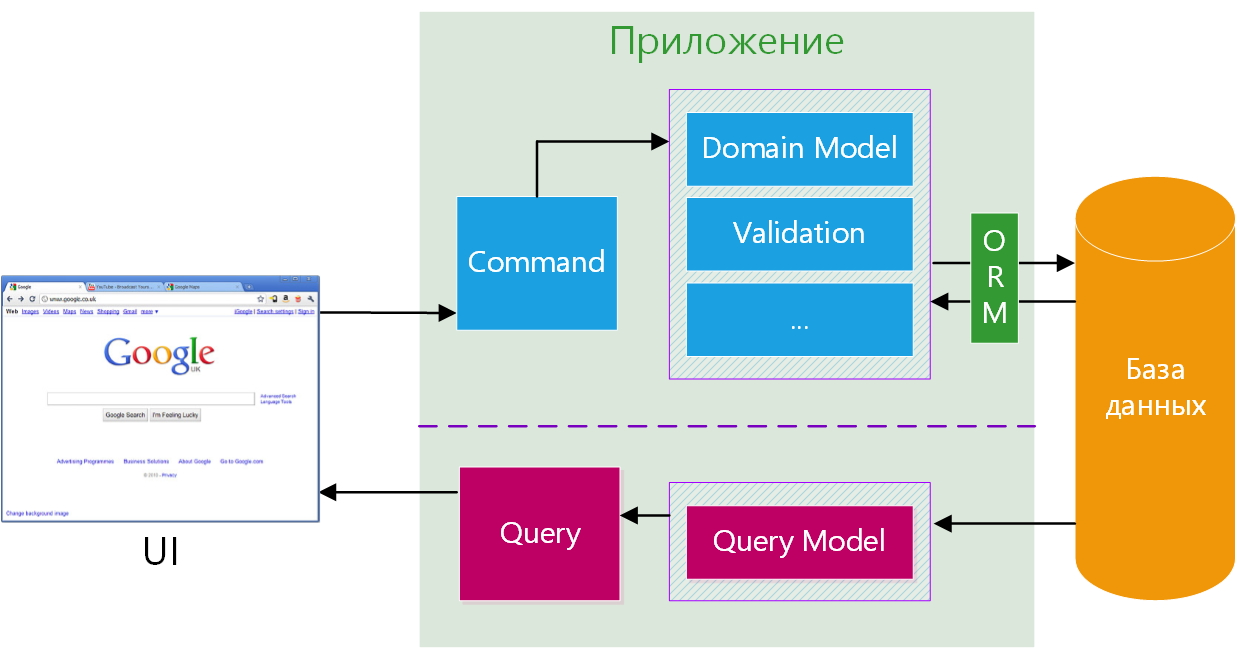
И как потом найти свежесозданного пользователя, если команда не будет возвращать нам его id?
Генерировать Id перед созданием пользователя, если только это не автоинкремент в БД (возможные проблемы с которым уже не относятся к CQRS).
Не отбрасывает. Возвращается либо id создаваемого пользователя, либо id асинхронной операции. Иначе о результате команды можно узнать лишь как-нибудь косвенно.
Если используется обычный async/await, то да. Если же команда обрабатывается в очереди, то здесь не получится что-либо вернуть.
Можем. Создаём 2 соединения: из одного читаем, в другое пишем. Оба соединения могут быть легко инкапсулированы в одном субд адаптере, позволяя программисту вообще не думать о том, что у него есть 2 базы.
Если только эти БД обновляются одновременно, но обычно БД для чтения обновляется позже, через какое-то время после изменений в БД для записи, иначе в ней пропадет смысл при её частом обновлении. То есть не получится сразу после создания пользователя получить по нему данные, его просто еще не будет существовать.
Генерировать Id перед созданием пользователя, если только это не автоинкремент в БД
Вот абстракции и потекли. Не, я, конечно, за предгенерацию id, но это далеко не всегда возможно.
Если же команда обрабатывается в очереди, то здесь не получится что-либо вернуть.
Идентификатор элемента очереди. Или вы исповедуете принцип "с моей стороны вылетело, а дальше судьба команды меня не волнует"?
То есть не получится сразу после создания пользователя получить по нему данные, его просто еще не будет существовать.
Ну так сами себе же создали проблемы :-) Если бы команда сразу же и возвращала данные свежесозданного пользователя или запросы могли сходить в основную базу и заполнить кеш, то таких проблем бы не было.
Идентификатор элемента очереди. Или вы исповедуете принцип "с моей стороны вылетело, а дальше судьба команды меня не волнует"?
Задаете correlation id команде и ждете себе спокойно по каналу чтения событие "пользователь создан" (или что там у вас в бизнес логике прописано) с нужным cid. Получили ивент, достали все нужные данные. Выигрыш тут в прекрасной масштабируемости канала чтения.
Более того, в конечном приложении вы это разделение можете спрятать обратно в модель и отдать один метод "создать пользователя", возвращающий ID. Только внутрянка у вас CQRS+ES.
Вот абстракции и потекли. Не, я, конечно, за предгенерацию id, но это далеко не всегда возможно.
Как и строгое следование принципам CQS. Все сводится к балансу между жестким следованием принципами и производственной необходимостью, и какие последствия это может за собой повлечь.
Идентификатор элемента очереди. Или вы исповедуете принцип «с моей стороны вылетело, а дальше судьба команды меня не волнует»?
Зависит от реализации.
В простом случае команда вполне может вернуть статус выполнения успешно/неуспешно.
В другом случае команда может послать событие, что создание пользователя завершилось успешно, или не успешно, если по какой-то причине выполнить команду не удалось, и затем как-либо оповестить пользователя.
Или вообще без оповещения пользователя, вызывающему коду может лишь понадобиться знать, смогла ли команда выполниться или нет, чтобы, например, попытаться её выполнить снова в случае неудачного выполнения (типа недоступности сервера для отправки email).
CQRS в этом плане выступает как основа для подобных действий.
Ну так сами себе же создали проблемы :-) Если бы команда сразу же и возвращала данные свежесозданного пользователя или запросы могли сходить в основную базу и заполнить кеш, то таких проблем бы не было.
Потому что БД для чтения используется для повышения производительность запросов на чтение, а не записи, в первой ссылке в источниках об этом рассказывается подробнее.
UX меняется в случае использования CQRS с разными БД или Event Sourcing.
Командам как правило необходимо делать запросы в процессе работы. И какой толк в этом случае от разделения команд и запросов, если они всё равно получаются сильно связанными?
Если это использовать в связке с DDD — Domain Aggregate, то у агрегата должна быть вся информация для выполнения команды и он не должен делать запросы по ходу этого дела. Единственные запросы у агрегата — сохранение и восстановление своего состояния. При применении eventsourcing там все вообще очень хорошо и красиво абстрагируется.
Вообще CQRS имеет смысл быть для высоко нагруженных систем.
Одна БД для записи информации, 4 БД для чтения информации. Иначе зачем делить логику, как мне кажется это методология или новомодное словечко вечно вырывается из контекста !
Хотелось бы узнать у Бертрана Мейера какое у него было железо !
https://ru.wikipedia.org/wiki/CQRS
На практике, CQRS дает возможность пропустить все проверки утверждений в действующей системе, чтобы повысить её производительность, не боясь того, что это изменит её поведение. CQRS также предотвращает возникновение некоторых гейзенбагов.
Как я и говорил для повышения производительности !
Чтение из одной базы, а запись в другую реализуется одним if-ом. Для этого не нужны никакие CQ®S.
Ага. Буквально вчера троллил это для файлов:
struct Stream
{
File output;
File input;
this( string output , string input = output )
{
this.output = File( path , "ab" );
this.input = File( path , "rb" );
}
auto put( Data )( Data data )
{
auto offset = this.output.tell;
this.output.lockingBinaryWriter.put( data );
return offset;
}
auto read( Data )( ulong offset )
{
Unqual!Data[1] buffer;
this.input.seek( offset );
this.input.rawRead( buffer );
return cast( Data ) buffer[0];
}
}void main()
{
auto stream = Stream( "target.bin" , "source.bin" );
stream.put( 777 );
stream.put( "Hello" );
writeln( stream.read!ulong( 0 ) );
}Только это будет не CQRS, и не будет его преимуществ. В CQRS данные для чтения имеют структуру, оптимизированную для чтения, поэтому чтение будет быстрое за счет более медленной записи. Например, вместо расчета прибыли при создании отчета (путем суммирования всех проводок) мы рассчитываем прибыль при создании каждой проводки.
Все эти оптимизации вовсе не обязательно выпячивать наружу. Запросили у "модели отчёта" прибыль — она взяла предагрегированное значение из быстрой базы. Передали ей флаг "хочу актуальные данные" — она пересчитала прибыль по медленной базе. Тут же она может и закешировать полученное значение в быструю базу. Уповая на CQRS вы не получаете никаких преимуществ, зато получаете кучу ограничений.
АПИ CQRS систем — это отражение их eventual consistency. То есть факта, что отправив команду системе, результат нужно получать другим способом.
ну да, CQRS нужен для масштабирования на чтение
redux очень похож на CQRS+event sourcing. Данные для чтения — это state, данные для записи — это бекэнд. В серверную архитектуру его, конечно, один в один не перенести, но подходы и проблемы очень похожи.
В реальных приложениях практически невозможно использовать "чистые" команды, которые не возвращают результата. Нужно будет обрабатывать ошибки, а также получать какие-то минимальные результаты, например, идентификаторы созданных сущностей и т.д.
- Не стоит использовать CQRS без необходимости, его нужно применять только в самых нагруженных местах (или в системах, которые хорошо на него ложатся, например, основанных на событиях, типа приложений для такси). Реализовывать на нем CRUD — это удовольствие ниже среднего.
redux очень похож на CQRS+event sourcing. Данные для чтения — это state, данные для записи — это бекэнд. В серверную архитектуру его, конечно, один в один не перенести, но подходы и проблемы очень похожи.
А redux-saga — process-менеджеры, все верно.
В реальных приложениях практически невозможно использовать "чистые" команды, которые не возвращают результата. Нужно будет обрабатывать ошибки, а также получать какие-то минимальные результаты, например, идентификаторы созданных сущностей и т.д.
не возвращать данные — общепринятое, но не обязательное решение. Об этом в т.ч. упомянул и Грег Янг, назвав это правило самым большим недопониманием парадигмы.
redux очень похож на CQRS+event sourcing. Данные для чтения — это state, данные для записи — это бекэнд. В серверную архитектуру его, конечно, один в один не перенести, но подходы и проблемы очень похожи.
Подходы похожи, но проблемы заметно другие. Редьюсеры как в redux не написать если все в памяти не хранить, многопользовательский доступ к командам. Плюс проблемы инфраструктуры (евенты тупо могут не в том порядке прийти или вообще не прийти). Но в общем-то все у Грега Янга подробно описано как что решать. С eventsourcing на сервере и redux на клиенте вообще все гладко получается
мы реализовывали эту связку в своем биллинге. И удовольствия, действительно, никакого. Поменялся ивент (а в базе уже лежит пачка ивентов старой версии) — нужно писать адаптеры для того, чтоб аггрегат мог в принципе развернуться, иначе весь прод лежит. В общем, не сказал бы, что store в redux очень похож на eventsourcing, все таки на фронте состояние хранится относительно кратковременно и с такими проблемами наверняка не сталкиваются)
А в ином варианте вы будете проводить миграцию базы. Принципиального отличия нет. Кроме того, в случае event sourcing часто используется гибридный подход с хранением snapshot'а на некоторый момент и event'ов после снэпа. В той же Akka есть готовые куски для реализации такого подхода и обкатанные best practice.
Добавьте в систему события (не путать с event-sourcing) и вы получите отличную архитектуру для микросервисов.
// contract.dll
public class RegisterUser : ICommand { ... }
public class UserRegistered : IEvent { ... }
public class SendEmail : ICommand { ... }
public class UserData { ... }
public class GetUserById : IQuery<UserData> { ... }
// api.exe
public class UserController
{
private IDispatcher _dispatcher;
public void Register(RegisterUserModel model)
{
_dispatcher.Execute(new RegisterUser { ... });
}
}
// domain.exe
public class User { ... }
public interface IUserRepository { ... }
public class UserDomainHandler : ICommandHandler<RegisterUser>, IQueryHandler<GetUserById, UserData>
{
private IDispatcher _dispatcher;
private IUserRepository _repository;
public void Handle(RegisterUser command)
{
var user = new User(...);
_repository.Insert(user);
_dispatcher.Publish(new UserRegistered { ... });
}
public UserData Handle(GetUserById query)
{
var user = _repository.GetById(...);
return new UserData { ... };
}
// email.exe
public interface IEmailService { ... }
public class UserEmailHandler : IEventHandler<UserRegistered>
{
private IDispatcher _dispatcher;
public void Handle(UserRegistered event)
{
var userData = _dispatcher.Query(new GetUserById { ... });
_dispatcher.Execute(new SendEmail { ... });
}
}
public class CommonEmailHandler : ICommandHandler<SendEmail>
{
private IEmailService _emailService;
public void Handle(SendEmail command)
{
_emailService.SendEmail(...);
}
}
Все три процесса независимы и легко маштабируются. Соединяется всё через AMQP (например RabbitMQ).
// contract.dll
public class ProductData { ... }
public class CreateProduct : ICommand { ... }
public class ProductCreated : IEvent { ... }
public class GetProductById : IQuery<ProductData> { ... }
public class SearchProducts : IQuery<List<ProductData>> { ... }
// api.exe
public class ProductController
{
private IDispatcher _dispatcher;
public void Create(CreateProductModel model)
{
_dispatcher.Execute(new CreateProduct { ... });
}
public ProductModel Get(int id)
{
var productData = _dispatcher.Query(new GetProductById { ... });
return new ProductModel { ... };
}
public List<ProductModel> Search(string query)
{
var productsData = _dispatcher.Query(new SearchProducts { ... });
return new List<ProductModel>(...)
}
}
// domain.exe
public class ProductDomainHandler : ICommandHandler<CreateProduct>, IQueryHandler<GetProductById, ProductData>
{
private IDispatcher _dispatcher;
private IProductRepository _repository;
public void Handle(CreateProduct command)
{
var product = new Product(...);
_repository.Insert(product);
_dispatcher.Publish(new ProductCreated { ... });
}
public ProductData Handle(GetProductById query)
{
var product = _repository.GetById(...);
return new ProductData { ... };
}
}
// index.exe
public class ProductIndexHandler : IEventHandler<ProductCreated>, IQueryHandler<SearchProducts, List<ProductData>>
{
private IDispatcher _dispatcher;
private IElasticClient _client;
public void Handle(ProductCreated event)
{
var productData = _dispatcher.Query(new GetProductById { ... });
_client.Index(productData);
}
public List<ProductData> Search(SearchProducts query)
{
var data = _client.Search(...);
return data;
}
}
И что самое интересное, вам даже не обязательно разносить по разным процессам, просто переименуйте в domain.dll и index.dll и запускайте внутри одного процесса, минуя AMQP.
Это и не команда, которая ничего не возвращает, и не запрос, который вернет «здесь и сейчас»?
например, запросить примерно это
Task<TResult> GetSomething(какие-то параметры запроса)результат вернется, но не сразу
Так в сущности-то запрос остаётся запросом, асинхронен он или нет. Для асинхронных нужно будет использовать что-то вроде async/await.
а как быть в ситуации с долговременными запросами. Где обработка занимает от 30 сек, что для браузера по-умолчанию будет выходом по ошибке превышения времени ожидания ответа.
Но у меня не браузер, а программа для Windows, но все равно есть операции, когда результат придет, но ОЧЕНЬ далеко не сразу. А поток приложения как понятно блокировать никак нельзя — пользователь не поймет :)
public interface IQueryHandler<in TQuery, out TResult> where TQuery : IQuery<TResult>
{
Task<TResult> Execute(TQuery query);
}
public async Task<TResult> Execute(...)
{
var result = await GetSomething(...);
return result;
}
public ActionResult SearchUsers(string searchString)
{
var query = new FindUsersBySearchTextQuery(searchString);
User[] users =_queryDispatcher.Execute(query);
return View(users);
}Достоинства CQRS
Меньше зависимостей в каждом классе;
честно говоря, при такой реализации способ уменьшения зависимостей кажется спорным. Во-первых мы прибегаем к антипаттерну диктатор (по Марку Симену), когда зависимости мы создаем напрямую через new. На мой взгляд было бы уместнее использовать что-то вроде абстрактной фибрики запросов, тогда в том числе по сигнатуре контроллера было понятно, что он создает запросы. Ну и в плане класса диспетчера, который по факту тоже является антипаттерном сервислокатор, он создает кажующуюся простоту контроллера. На самом деле он не уменьшает количество зависимостей ( и как следствие сложность) класса, он просто скрывает их реальное количество. В итоге мы жертвуем простотой класса с точки зрения понимания его обязанностей и, как следствие, эффективностью рефакторинга. Было бы рациональнее внедрять конкретные обработчики через конструктор, при этом класс стал бы гораздо понятнее
если минусуете — делайте это аргументированно )
FindUsersBySearchTextQuery — это DTO, объект с данными без поведения; у него никогда не появится своих зависимостей. Такие объекты создавать через new можно и нужно.
Во-первых мы прибегаем к антипаттерну диктатор (по Марку Симену), когда зависимости мы создаем напрямую через new. На мой взгляд было бы уместнее использовать что-то вроде абстрактной фабрики запросов
Теперь мы вынуждены зависеть от фабрики, да и как она будет создавать объекты запросов/команд? Неужели
new так плох?Ну и в плане класса диспетчера, который по факту тоже является антипаттерном сервислокатор, он создает кажующуюся простоту контроллера. На самом деле он не уменьшает количество зависимостей ( и как следствие сложность) класса, он просто скрывает их реальное количество
Диспетчер делегирует вызов обработчиков по переданному сообщению, используется ли в нём Service Locator или нет — это не важно, он оперирует только определенным списком обработчиков. По этому поводу есть довольно интересная статья (англ.).
В итоге мы жертвуем простотой класса с точки зрения понимания его обязанностей и, как следствие, эффективностью рефакторинга. Было бы рациональнее внедрять конкретные обработчики через конструктор, при этом класс стал бы гораздо понятнее
Это хоть и допустимо, но не эффективно, т.к. стоит учитывать, что количество обработчиков может быть неопределенным, тем более если речь идет о рефакторинге.
new не так плох, просто если класс зависит от фабрики, то из сигнатуры конструктора очевидно, какую ответственность он на себя берет. То есть вот этот контроллер создает внутри запросы и по обработчикам видно — какие именно запросы он создает (и обрабатывает), более того, контроллеры это медиаторы, которые должны выполнять как можно меньше работы, но при этом они могут содержать большое количество зависимостей для делегирования обязанностей между ними.
1. Какую ответственность покажет фабрика? (Да и зачем для достаточно простых DTO фабрика?) То, что в контроллере используются команды/запросы? А из переданного диспетчера это будет не ясно?
2. Чем передача множества обработчиков вместе с возможными другими зависимостями, которые не относятся к CQRS, упростит чтение контроллера. Может, наоборот — усложнит? (Не считая того, что если контроллер содержит слишком много зависимостей, то, возможно, он делает слишком много, и стоит выделить дополнительный контроллер под более конкретные задачи, или же объединить часть зависимостей в одном высокоуровневом компоненте (вроде того же диспетчера)).
3. Из методов и названия контроллера не будет ясно, какие действия он производит?
1) в первую очередь она просто возьмет на себя ответственность за создание запросов/команд и в этом случае будет единственной точка входа для этого. Что полезно
2) Вот говорится как раз о моменте, описанном в скобочках. Передача конкретных обработчиков в конструкторе позволит контролировать сложность класса и вовремя понять, что начинает становиться God-объектом и разделить. При использовании диспетчера это не ясно
3) Это point-of-failure. Если Вы сами пишете эти методы — некоторое время можно будет рассчитывать на то, что название методов адекватно отражает происходящее в них (а по прошествии некоторого времени — уже нет)
В ином же случае помимо названий методов (которые легко посмотреть в студии) придется уже пересматривать эти методы для того, чтоб понять что именно там происходит
Из интересного, что вылезло.
Вызов обработчика команды скрыли за одним классом, который собирал все обработчики и по переданной ему в обработку команде определял подходящий обработчик. Интересные моменты стали вылазить позже. Система довольно сложная и количество обработчиков выросло до нескольких сотен. Они сами по себе довольно простые все с минимумом логики (большая часть бизнес-логики хранится в моделях), но выбор подходящего занимает время (речь о 50-100 милисекундах, но иногда это может быть критично. В итоге пришли к тому, что можно было обойтись и без Service Locator, по причине:
1. При вызове обработки команды и так всегда известно какой обработчик должен ее обрабатывать. Нет необходимости скрывать выбор обработчика, потому что никакой логики выбора там нет.
2. Реализация Service Locator может содержать ошибки, которые как раз всплыли. Это человеческий фактор и он сыграл.
3. Выбор обработчика команды занимает время, которое можно было бы сэкономить.
Чем плох рабоче-крестьянский вариант?
Естественно обмазали интерфейсами для возможности писать юнит тесты.
Получение данных
Валидация данных
Модификация данных
Бизнес логика
Это все отдельные классы, которые работают с DTO.
Основы CQRS