Универсальные типы в python являются незаменимым инструментом, который позволяет выявлять множество ошибок на моменте написания кода, а также делает код чище и элегантнее.
Меня зовут Саша, и в своей работе часто сталкиваюсь с ситуациями, когда нужно создавать классы, работающие с различными типами, и при этом избегать дублирование кода, а также получать актуальные подсказки от type checker'а.
В этой статье я рассмотрю различные примеры использования универсальных типов и постараюсь доступно описать, в чем разница между инвариантностью, ковариантностью и контравариантностью.
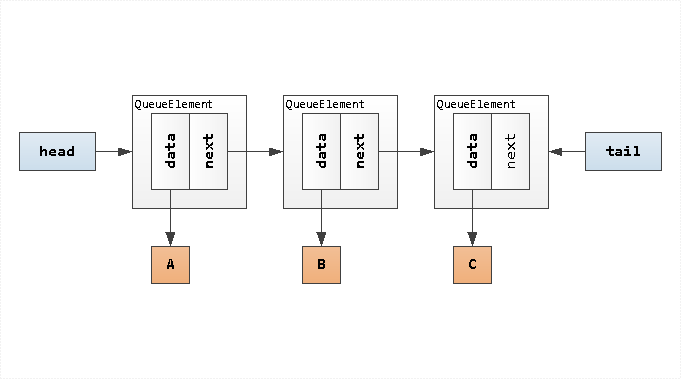
Начнем с самого простого. Предположим, что у нас есть несколько типов документов: обычный и его расширение - складской. Ещё у нас есть реестр, который умеет работать с документами различных типов.