
Мы продолжаем рассказывать и показывать как работает Splunk, в частности говорить о возможностях языка поисковых запросов SPL.
В этой статье на основе тестовых данных (логи веб сервера) доступных всем желающим для загрузки мы покажем:
- Как обогатить логи информацией из внешних справочников
- Как можно визуализировать географические данные (данные с координатами)
- Как группировать цепочки событий в транзакции и работать с ними
Под катом вы найдете как сами примеры поисковых запросов, так и результат их выполнения. Вы можете скачать бесплатную версию Splunk, загрузить тестовые данные и повторить все на своем локальном компьютере.
О том как установить Splunk и загрузить тестовые данные мы рассказывали в предыдущих статях нашего блога.
Обогащение данных информацией из внешних справочников
Рассмотрим имеющиеся у нас данные.
sourcetype=access* 
Это события access лога, в которых содержится информация о действиях посетителей сайта (по легенде это сайт интернет-магазина компании, занимающейся продажей компьютерных игр). Поэтому в логах у нас есть такие поля, как (наиболее интересные для обработки и запросов):
- action — действия посетителя сайта
- clientip — ip-адресс посетителя сайта
- productId — код продукта
- categoryId — категория продукта
- JSESSIONID — сковозной id сессии
Как мы уже рассказывали в предыдущем посте, с помощью Splunk мы можем построить различную аналитику посредством поисковых запросов. Например, мы можем посчитать сколько и каких продуктов покупали, за опредленный временной период:
sourcetype=access* action=purchase | stats count by productId | sort -count
Но! Так как в наших логах кроме productId нет больше никакой информации о продукте, мы не видим что это за товар, сколько он стоит и так далее. Поэтому было бы удобно подгрузить соответствующие поля из внешнего справочника.
В качестве справочника возьмем простой csv файл с интересующей нас информацией о названии продукта и его цене, и загрузим его в Splunk. Сразу скажу, что это самый простой ручной способ обогащения. Понятно, что Splunk может забирать данные из реляционных баз данных, делать запросы к API и прочее.
После того как Вы скачали справочник, нужно загрузить его в Splunk и разметить поля. Подробная инструкция здесь. Если Вы все сделали правильно, то должны получить следующие результаты поискового запроса:
| inputlookup prices_lookup 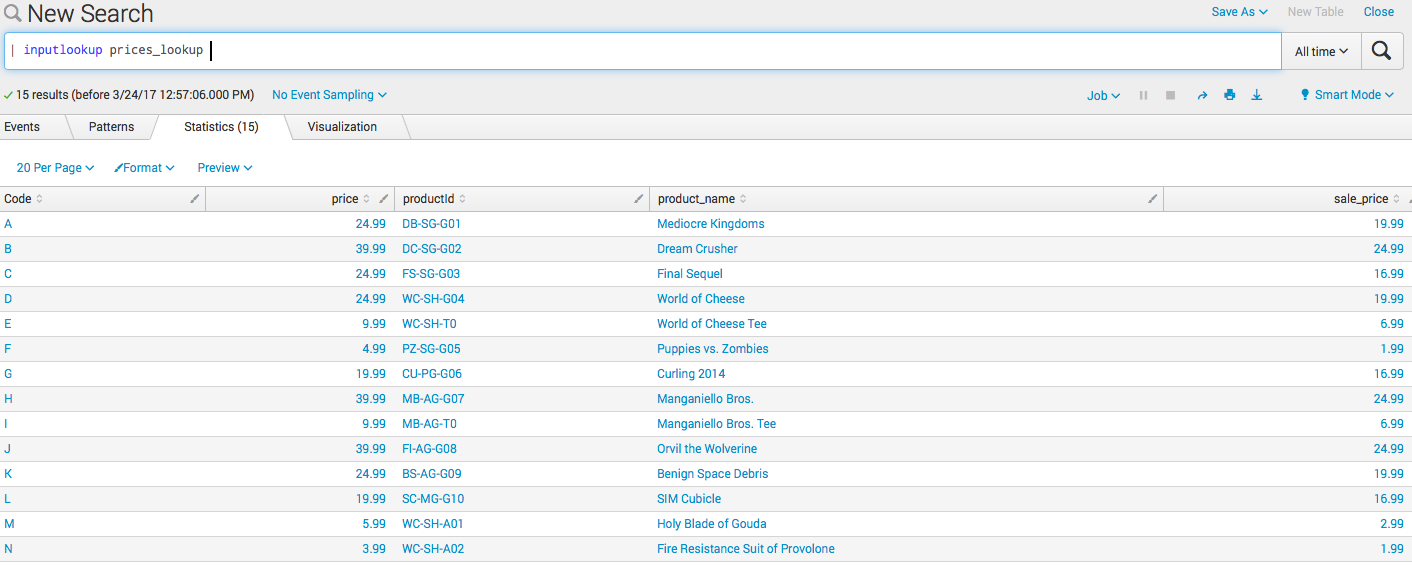
По сути мы просто добавили табличку со справочником в Splunk, теперь давайте сделаем так, чтобы система «дописала» значения этих полей к нашим событиям. Понятно, что она никак не изменит исходные события, а просто логически подтянет поля.
Заходим во вкладку Settings → Lookups → Automatic lookups → New
Name: — любое имя
Lookup table: prices_lookup (или как вы нававли Вашу таблицу)
Sourcetype: access_combined_wcookie
Lookup input fields: productId=productId
Lookup output fields: price=price, product_name=product_name, sale_price=sale_price

После чего все сохраняем и меняем Permissions на All Apps и Read/Write everyone как предыдущей инструкции.
Если все сделано правильно, то теперь при поиске по данному sourcetype должны быть достпны добавленные нами поля (чтобы они отображались снизу каждого события нужно зайти во вкладку All fields и выбрать их в качестве Interesting fields). Заметьте, что в самих событиях этой информации нет, так как они не изменялись.
sourcetype="access_combined_wcookie" product_name="*"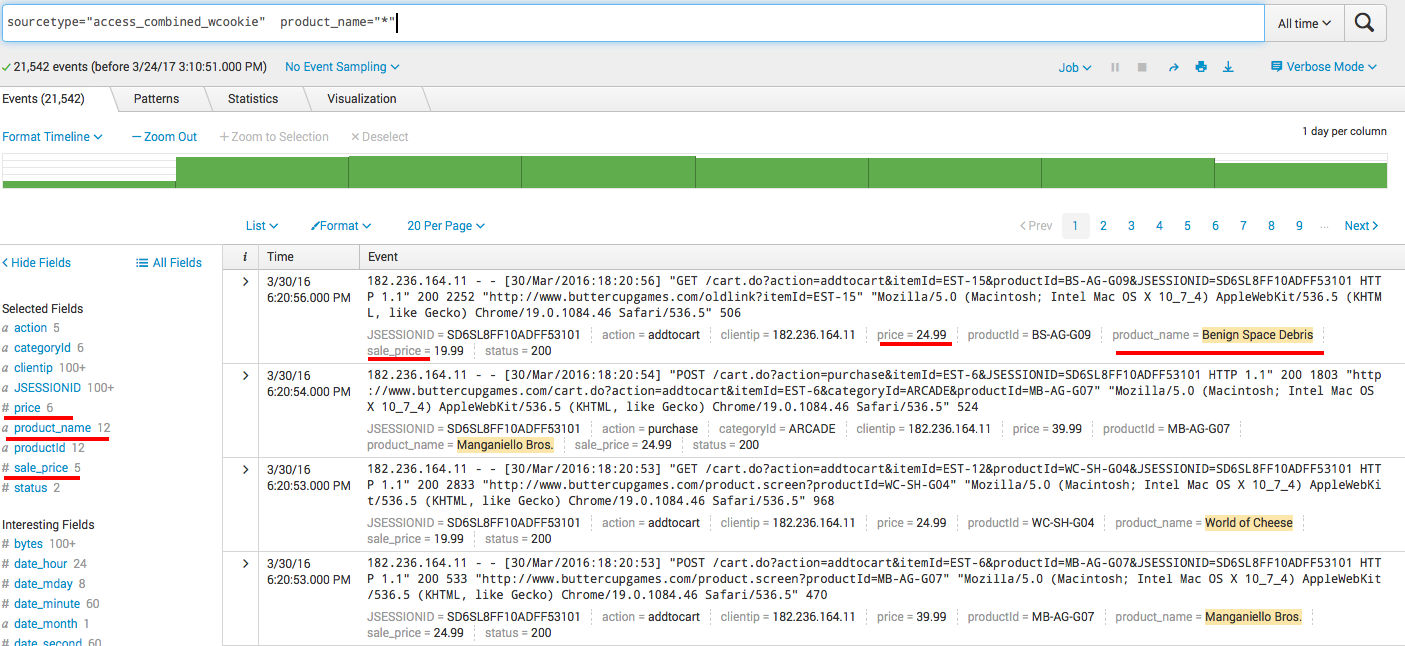
Вот теперь результаты наших запросов могут быть куда интереснее. К примеру, мы можем посчитать ту же самую аналитику только уже с привязкой к деньгам и финансовым результатам.
sourcetype="access_combined_wcookie" action=purchase
| eval profit=price-sale_price
| stats values(productId) as "Код продукта", values(sale_price) as "Цена покупки", values(price) as "Цена продажи", count as "Количество", sum(profit) as "Итого", by product_name
| sort -"Итого"
| rename product_name as "Наименование"
Понятно, что этот пример больше про BI историю. Однако, этот пример с подключением справочников тиражируем и в другие предметные области. К примеру, если говорить про информационную безопасность — мы можем подгружать по CVE коду информацию из баз данных уязвимостей.
И да, совсем забыл! Для удобного редактирования справочников у Splunk есть специальное приложение Lookup Editor, которое можно бесплатно скачать со SplunkBase.
Визуализация данных с географическими координатами
Иногда бывает очень полезно нанести результаты аналитических запросов на географическую карту. Тут ситуация разделяется на 2 случая: первый — когда в данных уже есть такие поля как широта и долгота (именно благодаря им мы можем нанести что-либо на карту), второй — когда этих полей нет. В нашем примере, то есть в наших данных, как раз второй случай (мы имеем много посетителей интернет магазина из разных мест, но данных об их широте и долготе у нас нет, зато у нас есть их ip-адрес). У Splunk есть встроенный функционал определения широты и долготы (а также города, страны и региона) на основе ip-адреса, команда iplocation.
sourcetype="access_combined_wcookie" | iplocation clientipВ результате этого запроса у вас должны появится поля с широтой, долготой, названием города, страны и региона.

Теперь строим какой-нибудь аналитический запрос и наносим на карту. К примеру, посчитаем прибыль по каждому продукту и посмотрим где это покупалось. Для этого используем встроенную функцию geostats.
sourcetype="access_combined_wcookie" action=purchase
| iplocation clientip
| eval profit=price-sale_price
| geostats sum(profit) by product_name
Также можем воспользоваться другим вариантом визуализации и посмотреть прибыльность в разрезе по странам, для этого используется команда geom.
sourcetype="access_combined_wcookie" action=purchase
| iplocation clientip
| eval profit=price-sale_price
| stats sum(profit) by Country
| geom geo_countries featureIdField=Country
По дефолту, есть маппинг по странам и штатам США, но вы всегда можете сделать свой, на основе широты и долготы и добавить его в Splunk. Например, это могут быть регионы Росиии, или городские округа.
Транзакции или группировка цепочки событий во времени
В том случае, когда у нас есть последовательная цепочка событий, например, процесс пересылки электронной почты, какая-нибудь финансовая операция, или как в случае с нашими данными — посещение web сайта, бывает необходимо объединить эти события в транзакции. То есть из группы отдельных событий событий явно выделить цепочку, группируя их по конкретному признаку.
В нашем случае это поле JSESSIONID — уникальный номер сессии пользователя. Для группировки используем команду transaction.
sourcetype="access_combined_wcookie" | transaction JSESSIONID endswith="purchase" 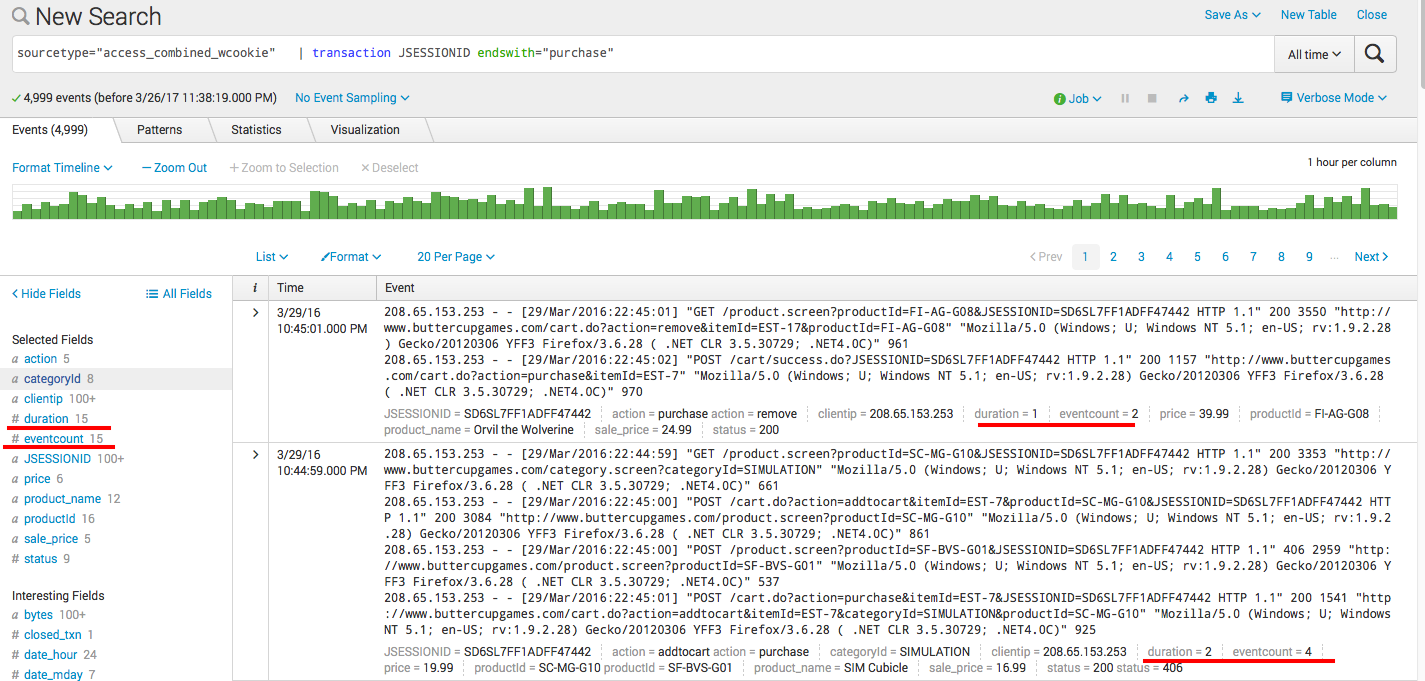
После чего получаем сгруппированные события, а также новые поля: длительность транзакции, и количество сгруппированных событий.
Теперь можно посчитать, к примеру, статистику по длительности сессий, то есть время за которое посетители решались совершить покупку.
sourcetype="access_combined_wcookie" | transaction JSESSIONID endswith="purchase" | search duration>0 | stats min(duration), max(duration), avg(duration) 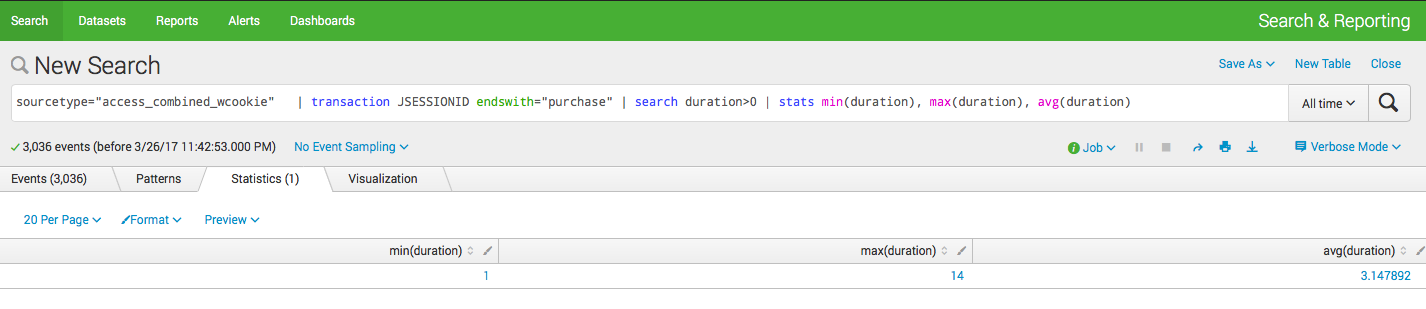
Также можно посчитать количество конкурентных сессий в каждый период времени, для этого есть команда concurrency.
sourcetype="access_combined_wcookie" | transaction JSESSIONID | concurrency duration=duration
В результате, создается новое поле concurrency, которое и считает конкурентные сессии, но, к сожалению, из-за того что наши данные синтетические у нас в любой момент времени есть только одна конкурентная сессия, поэтому этот пример не очень результативен.
Заключение
Конечно, примеры очень простые, но надеюсь, репрезентативные.
На этом мы заканчиваем данную статью!
Пишите свои вопросы если что-то не заработало или не получилось =)
Еще раз сылки на загрузку данных и справочника c ценами.
