

We have recently talked about how to deploy a Tarantool Cartridge application. However, an application's life doesn't end with deployment, so today we will update our application and figure out how to manage topology, sharding, and authorization, and change the role configuration.
Feeling interested? Please continue reading under the cut.
Where did we leave off?
Last time, we set up the following topology:

The sample repository has changed a bit: there are new files called
getting-started-app-2.0.0-0.rpm and hosts.updated.2.yml. You do not have to pull the new version, you can just download the package by clicking this link, and you need hosts.updated.2.yml only to look there if you have trouble changing the current inventory.If you have followed all the steps from the previous part of this tutorial, you now have a cluster configuration with two
storage replica sets in the hosts.yml file (hosts.updated.yml in the repository).First, start the virtual machines:
$ vagrant up
An up to date version of the Tarantool Cartridge Ansible role should already be installed. Just in care run the following command:
$ ansible-galaxy install tarantool.cartridge,1.0.2
So, the current cluster configuration:
---
all:
vars:
# common cluster variables
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package
cartridge_cluster_cookie: app-default-cookie # cluster cookie
# common ssh options
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
storage-2:
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica:
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
storage-2-replica:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
storage-2:
# GROUP INSTANCES BY REPLICA SETS
replicaset_app_1:
vars: # replica set configuration
replicaset_alias: app-1
failover_priority:
- app-1 # leader
roles:
- 'api'
hosts: # replica set instances
app-1:
replicaset_storage_1:
vars: # replica set configuration
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # leader
- storage-1-replica
roles:
- 'storage'
hosts: # replica set instances
storage-1:
storage-1-replica:
replicaset_storage_2:
vars: # replica set configuration
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # replica set instances
storage-2:
storage-2-replica:
Go to http://localhost:8181/admin/cluster/dashboard and make sure that your cluster is operating correctly.
As before, we change this file step-by-step and watch how the cluster changes. You can always look up the final version in
hosts.updated.2.ymlLet's start!
Updating the application
First, we are going to update our application. Make sure you have the
getting-started-app-2.0.0-0.rpm file in your current directory (otherwise, download it from the repository).Specify the path to a new version of the package:
---
all:
vars:
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-2.0.0-0.rpm # <==
cartridge_enable_tarantool_repo: false # <==
We have set
cartridge_enable_tarantool_repo: false so that the role does not include the repository with the Tarantool package that we had already installed last time. It slightly speeds up the deployment process but it isn't obligatory.Run the playbook with the
cartridge-instances tag:$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-instances
And check that the package has been updated:
$ vagrant ssh vm1
[vagrant@svm1 ~]$ sudo yum list installed | grep getting-started-app
Check that the version is
2.0.0:getting-started-app.x86_64 2.0.0-0 installed
Now you can safely try out the new version of the application.
Enabling sharding
Let's enable sharding so that we can later get to managing
storage replica sets. It's an easy thing to do. Add the cartridge_bootstrap_vshard variable to the all.vars section:---
all:
vars:
...
cartridge_cluster_cookie: app-default-cookie # cluster cookie
cartridge_bootstrap_vshard: true # <==
...
hosts:
...
children:
...
Run:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-config
Note that we have specified the
cartridge-config tag to run only the tasks related to the cluster configuration.Open the Web UI http://localhost:8181/admin/cluster/dashboard and note that the buckets are distributed among storage replica sets as
2:3 (as you may recall, we specified these weights for the replica sets):
Enabling automatic failover
Now we are going to enable the automatic failover mode in order to find out what it is and how it works.
Add the
cartridge_failover flag to the configuration:---
all:
vars:
...
cartridge_cluster_cookie: app-default-cookie # cluster cookie
cartridge_bootstrap_vshard: true
cartridge_failover: true # <==
...
hosts:
...
children:
...
Start cluster management tasks again:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-config
When the playbook finishes successfully, you can go to the Web UI and make sure that the
Failover switch in the top right corner is now switched on. To disable the automatic failover mode, simply change the value of cartridge_failover to false and run the playbook again.Now let's take a closer look at this mode and see why we enabled it.
Looking into failover
You have probably noticed the
failover_priority variable that we specified for each replica set. Let's look into it.Tarantool Cartridge provides an automatic failover mode. Each replica set has a leader, that is, the instance where the record is written. If anything happens to the leader, one of the replicas takes over its role. Which one? Look at the
storage-2 replica set:---
all:
...
children:
...
replicaset_storage_2:
vars:
...
failover_priority:
- storage-2
- storage-2-replica
In
failover_priority, we specified the storage-2 instance as the first one. In the Web UI, it is the first one in the replica set instance list and is marked with a green crown. This is the leader, or the first instance specified in failover_priority:
Now let's see what happens if something is wrong with the replica set leader. Go to the virtual machine and stop the
storage-2 instance:$ vagrant ssh vm2
[vagrant@vm2 ~]$ sudo systemctl stop getting-started-app@storage-2
Back to the Web UI:
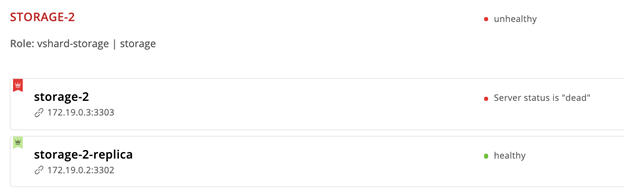
The crown of the
storage-2 instance turns red, which means that the assigned leader is unhealthy. But storage-2-replica now has a green crown, so this instance took over the leader role until storage-2 comes back into operation. This is the automatic failover in action.Let's bring
storage-2 back to life:$ vagrant ssh vm2
[vagrant@vm2 ~]$ sudo systemctl start getting-started-app@storage-2
Everything is back to normal:
Now we change the instance order in failover priority. We make
storage-2-replica the leader and remove storage-2 from the list:---
all:
vars:
...
hosts:
...
children:
...
replicaset_storage_2:
vars: # replica set configuration
...
failover_priority:
- storage-2-replica # <==
...
Run
cartridge-replicasets tasks for instances from the replicaset_storage_2 group:$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasets
Go to http://localhost:8181/admin/cluster/dashboard and check that the leader has changed:

But we removed the
storage-2 instance from the configuration, why is it still here? The fact is that when Cartridge receives a new failover_priority value at the input, it arranges the instances as follows: the first instance from the list becomes the leader followed by the other specified instances. Instances left out from failover_priority are arranged by UUID and added to the end.Expelling instances
What if you want to expel an instance from the topology? It is straightforward: just assign the
expelled flag to it. Let's expel the storage-2-replica instance. It is the leader now, so Cartridge will not let us do this. But we're not afraid so we'll try:---
all:
vars:
...
hosts:
storage-2-replica:
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
expelled: true # <==
...
We specify the
cartridge-replicasets tag because expelling an instance is a change in topology:$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasets
Run the playbook and observe the error:

Cartridge doesn't let the current replica set leader be removed from the topology. This makes good sense because the replication is asynchronous, so expelling the leader is likely to cause data loss. We need to specify another leader and only then expel the instance. The role first applies the new replica set configuration and then proceeds to expelling the instance. So we change the
failover_priority and run the playbook again:---
all:
vars:
...
hosts:
...
children:
...
replicaset_storage_2:
vars: # replica set configuration
...
failover_priority:
- storage-2 # <==
...
$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasets
And so
storage-2-replica disappears from the topology!
Please note that the instance is expelled permanently and irrevocably. After removing the instance from the topology, our Ansible role stops the systemd service and deletes all the files of this instance.
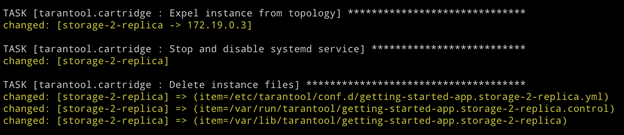
If you suddenly change your mind and decide that the
storage-2 replica set still needs a second instance, you will not be able to restore it. Cartridge remembers the UUIDs of all the instances that have left the topology and will not allow the expelled one to return. You can start a new instance with the same name and configuration, but its UUID will obviously be different, so Cartridge will allow it to join.Deleting replica sets
We have already found out that the replica set leader cannot be expelled. But what if we want to remove the
storage-2 replica set permanently? Of course, there is a solution.In order not to lose the data, we must first transfer all the buckets to
storage-1. For this purpose, we set the weight of the storage-2 replica set to 0:---
all:
vars:
...
hosts:
...
children:
...
replicaset_storage_2:
vars: # replica set configuration
replicaset_alias: storage-2
weight: 0 # <==
...
...
Start the topology control:
$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasets
Open the Web UI http://localhost:8181/admin/cluster/dashboard and watch all the buckets flow into
storage-1: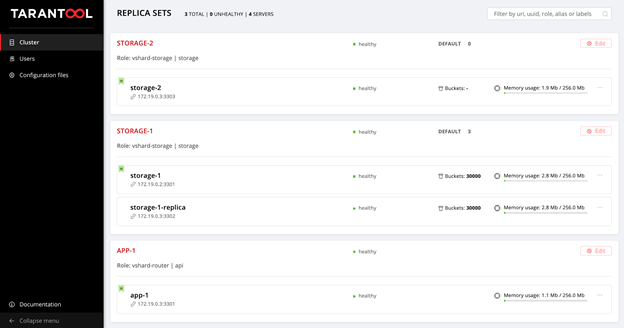
Assign the
expelled flag to the storage-2 leader and say goodbye to this replica set:---
all:
vars:
...
hosts:
...
storage-2:
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
expelled: true # <==
...
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-replicasets
Note that we did not specify the
limit option this time since at least one of the instances with the running playbook must not be marked as expelled.So we're back to the original topology:
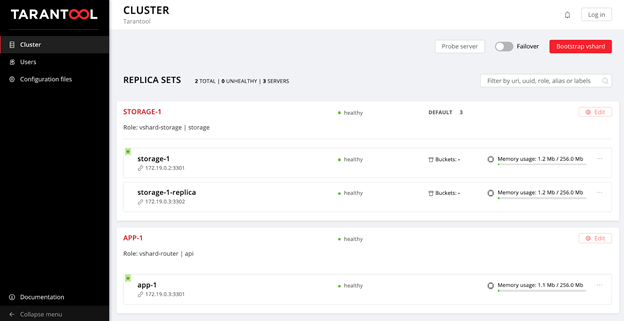
Authorization
Let's take our minds off replica set control and think about safety. Now any unauthorized user can manage the cluster via Web UI. We have to admit; it doesn't look too good.
With Cartridge, you can connect your own authorization module, such as LDAP (or whatever), and use it to manage users and their access to the application. But here we'll be using the built-in authorization module that Cartridge uses by default. This module allows you to perform basic operations with users (delete, add, edit) and implements password verification.
Please note that our Ansible role requires the authorization backend to implement all these functions.
Okay, we need to put theory into practice now. First, we are going to make authorization mandatory, set the session parameters, and add a new user:
---
all:
vars:
...
# authorization
cartridge_auth: # <==
enabled: true # enable authorization
cookie_max_age: 1000
cookie_renew_age: 100
users: # cartridge users to set up
- username: dokshina
password: cartridge-rullez
fullname: Elizaveta Dokshina
email: dokshina@example.com
# deleted: true # uncomment to delete user
...
Authorization is managed within the
cartridge-config tasks, so specify this tag:$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-config
Now http://localhost:8181/admin/cluster/dashboard has a surprise for you:

You can log in with the
username and password of the new user, or as admin, the default user. The password is a cluster cookie; we have specified this value in the cartridge_cluster_cookie variable (it is app-default-cookie, don't bother to check).After a successful login, we open the
Users tab to make sure that everything goes well:
Try adding new users and changing their parameters. To delete a user, specify the
deleted: true flag for that user. The email and fullname values are not used by Cartridge, but you can specify them for your convenience.Application configuration
Let's step back and skim through the whole story.
We have deployed a small application that stores data about customers and their bank accounts. As you may recall, this application has two implemented roles:
api and storage. The storage role deals with data storage and sharding using the integrated vshard-storage role. The second role (or api) implements an HTTP server with an API for data management. It also has another integral standard role (vshard-router) that controls sharding.So, we send the first request to the application API to add a new client:
$ curl -X POST -H "Content-Type: application/json" \
-d '{"customer_id":1, "name":"Elizaveta", "accounts":[{"account_id": 1}]}' \
http://localhost:8182/storage/customers/create
In return, we get something like this:
{"info":"Successfully created"}
Note that in the URL we have specified the
8082 port of the app-1 instance as this is the port for the API.Now we update the balance of the new user:
$ curl -X POST -H "Content-Type: application/json" \
-d '{"account_id": 1, "amount": ^_^quotϨquot^_^}' \
http://localhost:8182/storage/customers/1/update_balance
We see the updated balance in the response:
{"balance":"1000.00"}
All right, it works! The API is implemented, Cartridge takes care of data sharding, we have already configured the failover priority in case of emergency and enabled authorization. It's time to get down to configuring the application.
The current cluster configuration is stored in a distributed configuration file. Each instance stores a copy of this file, and Cartridge ensures that it is synchronized among all the nodes in the cluster. We can specify the role configuration of our application in this file, and Cartridge will make sure that the new configuration is distributed across all the instances.
Let's take a look at the current contents of this file. Go to the
Configuration files tab and click on the Download button:
In the downloaded
config.yml file, we find an empty table. It's no surprise because we haven't specified any parameters yet:--- []
...
In fact, the cluster configuration file is not empty: it stores the current topology, authorization settings, and sharding parameters. Cartridge does not share this information so easily; the file is intended for internal use, and therefore stored in hidden system sections that you cannot edit.
Each application role can use one or more configuration sections. The new configuration is loaded in two steps. First, all the roles verify that they are ready to accept the new parameters. If there are no problems, the changes are applied; otherwise, the changes are rolled back.
Now get back to the application. The
api role uses the max-balance section, where the maximum allowed balance for a single client account is stored. Let's configure this section using our Ansible role (not manually, of course).So now the application configuration (more precisely, the available part) is an empty table. Now add a
max-balance section there with a value of 100,000, and specify the cartridge_app_config variable in the inventory file:---
all:
vars:
...
# cluster-wide config
cartridge_app_config: # <==
max-balance: # section name
body: 1000000 # section body
# deleted: true # uncomment to delete section max-balance
...
We have specified a section name (
max-balance) and its contents (body). The content of the section can be more than just a number; it can also be a table or a string depending on how the role is written and what type of value you want to use.Run:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-config
And check that the maximum allowed balance has indeed changed:
$ curl -X POST -H "Content-Type: application/json" \
-d '{"account_id": 1, "amount": "1000001"}' \
http://localhost:8182/storage/customers/1/update_balance
In return, we get an error, just as we wanted:
{"info":"Error","error":"Maximum is 1000000"}
You can download the configuration file from the
Configuration files tab once again to make sure the new section is there:---
max-balance: 1000000
...
Try adding new sections to the application configuration, change their contents, or delete them altogether (to do this, you need to set the
deleted: true flag in the section):For more information on using the distributed configuration in roles, see the Tarantool Cartridge documentation.
Don't forget to run
vagrant halt to stop the virtual machines when you're done.Summary
Last time we learned how to deploy distributed Tarantool Cartridge applications using a special Ansible role. Today we updated the application and learned how to manage application topology, sharding, authorization, and configuration.
As a next step, you can try different approaches to writing Ansible Playbook and use your apps in the most convenient way.
If something doesn't work or you have ideas on how to improve our Ansible role, please feel free to create a ticket. We are always happy to help and open to any ideas and suggestions!
