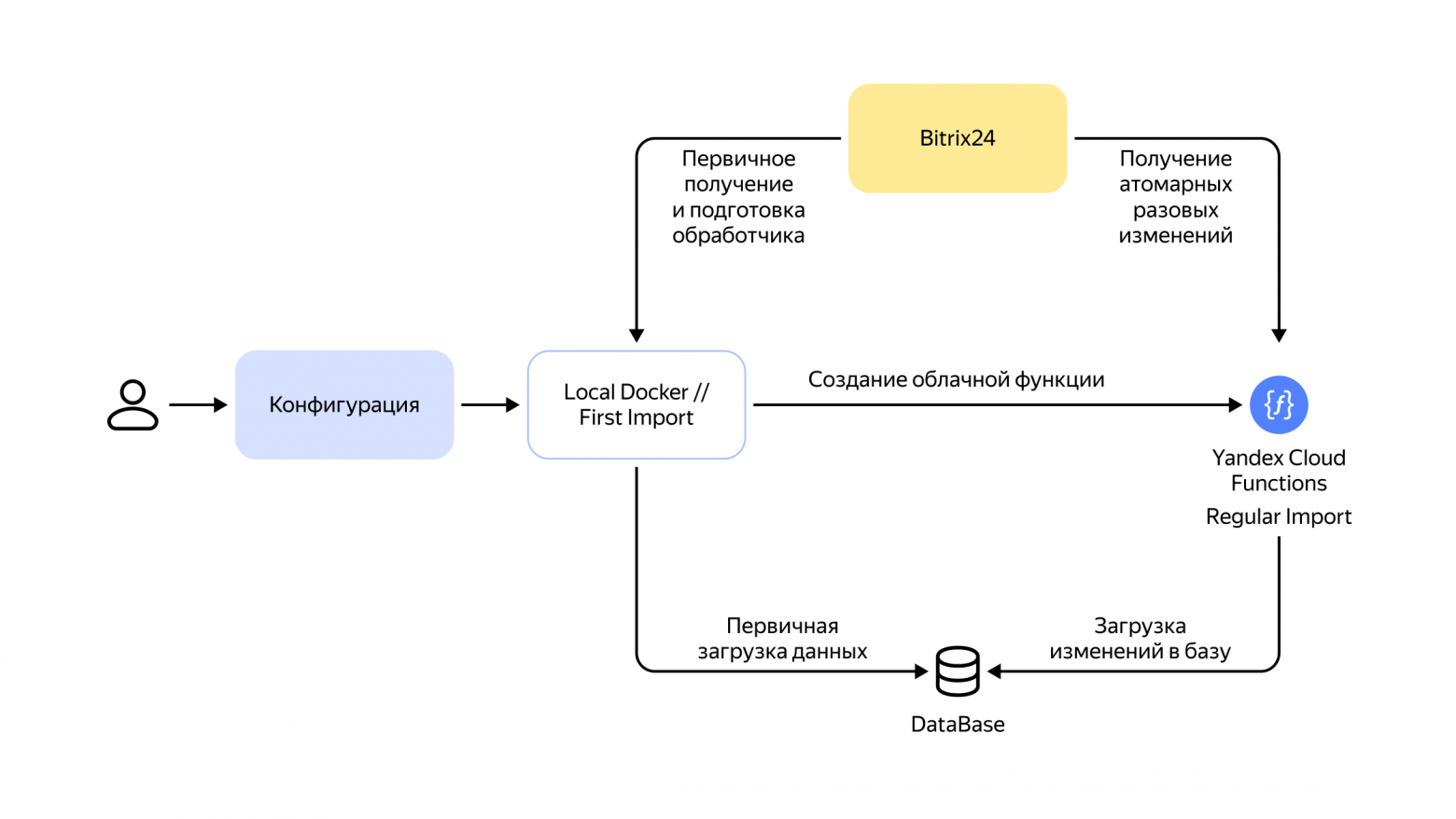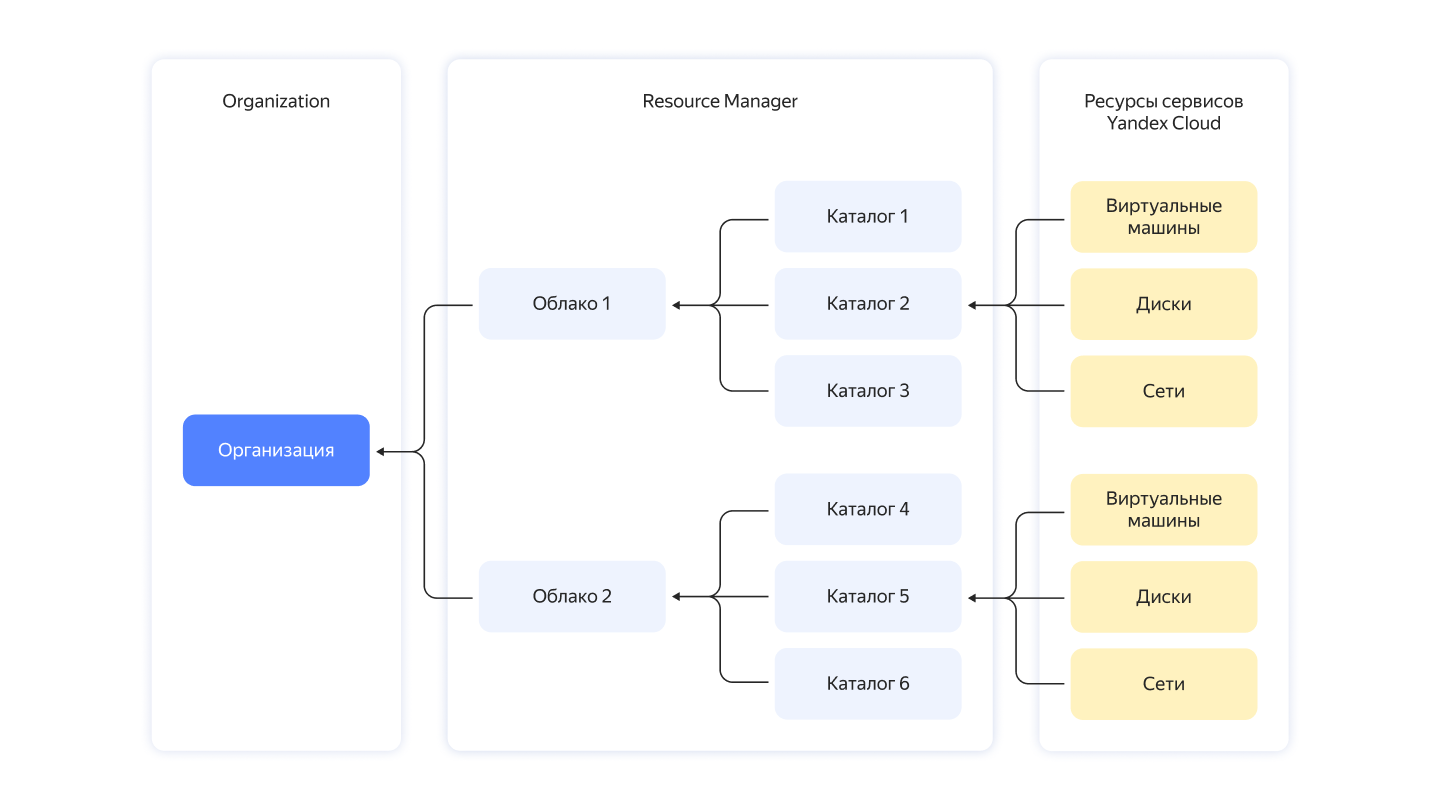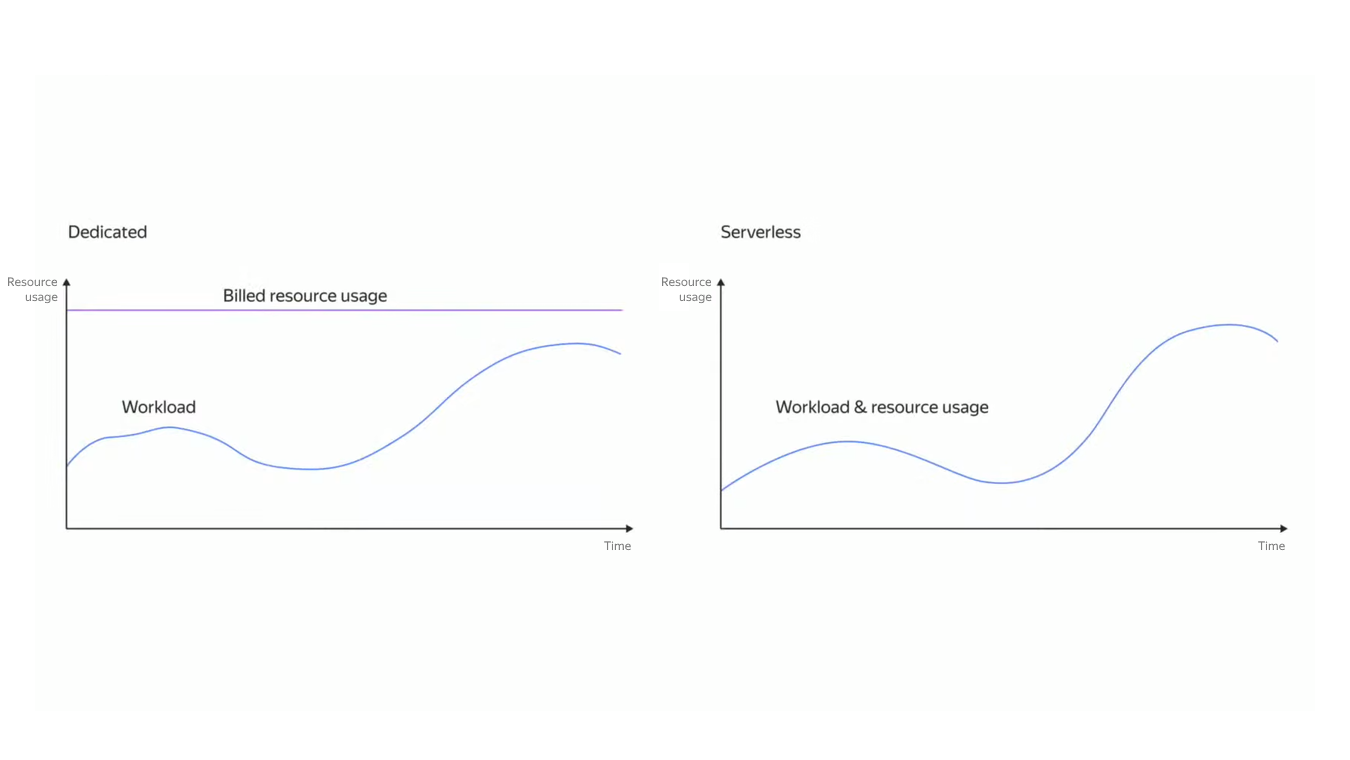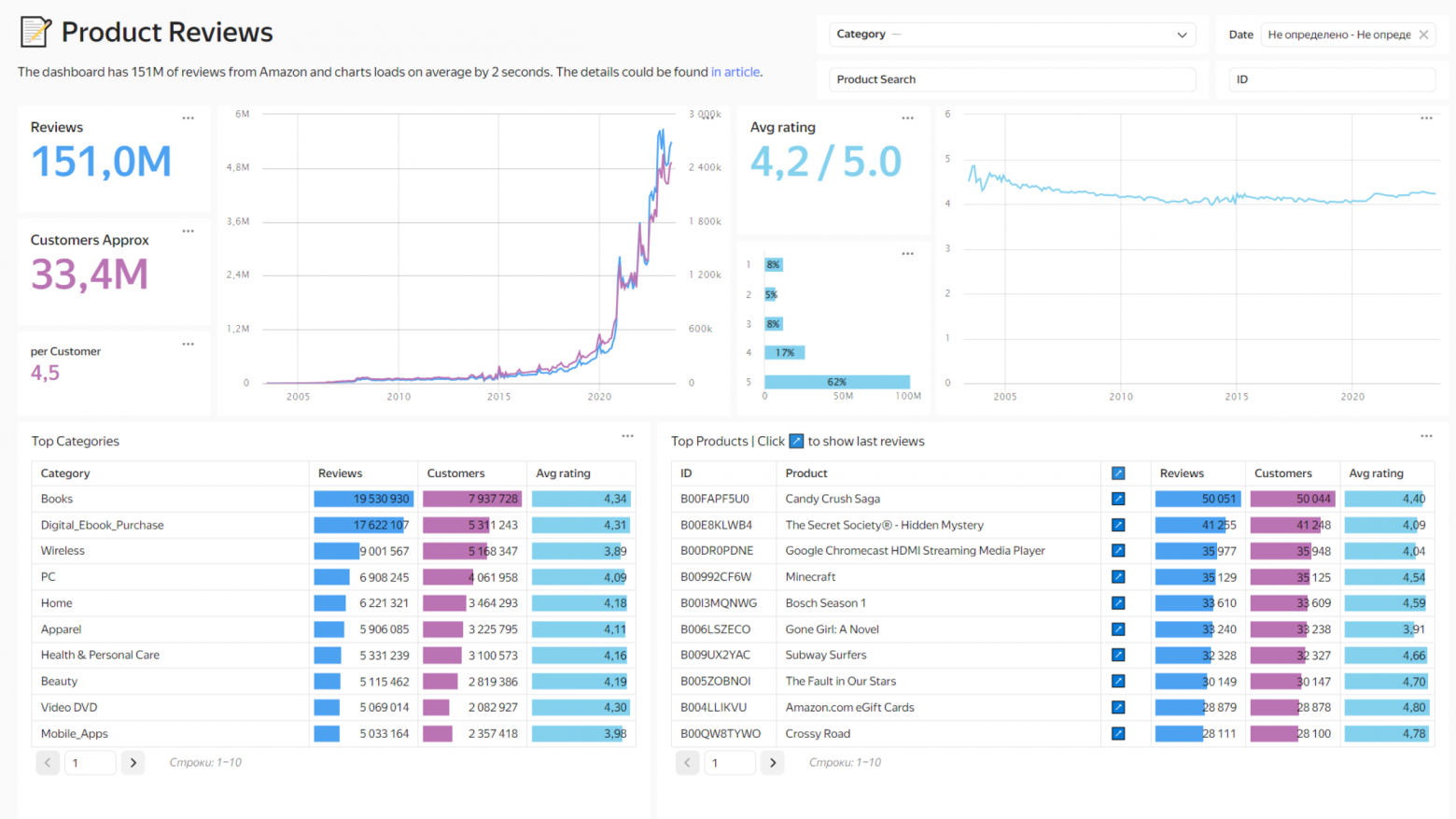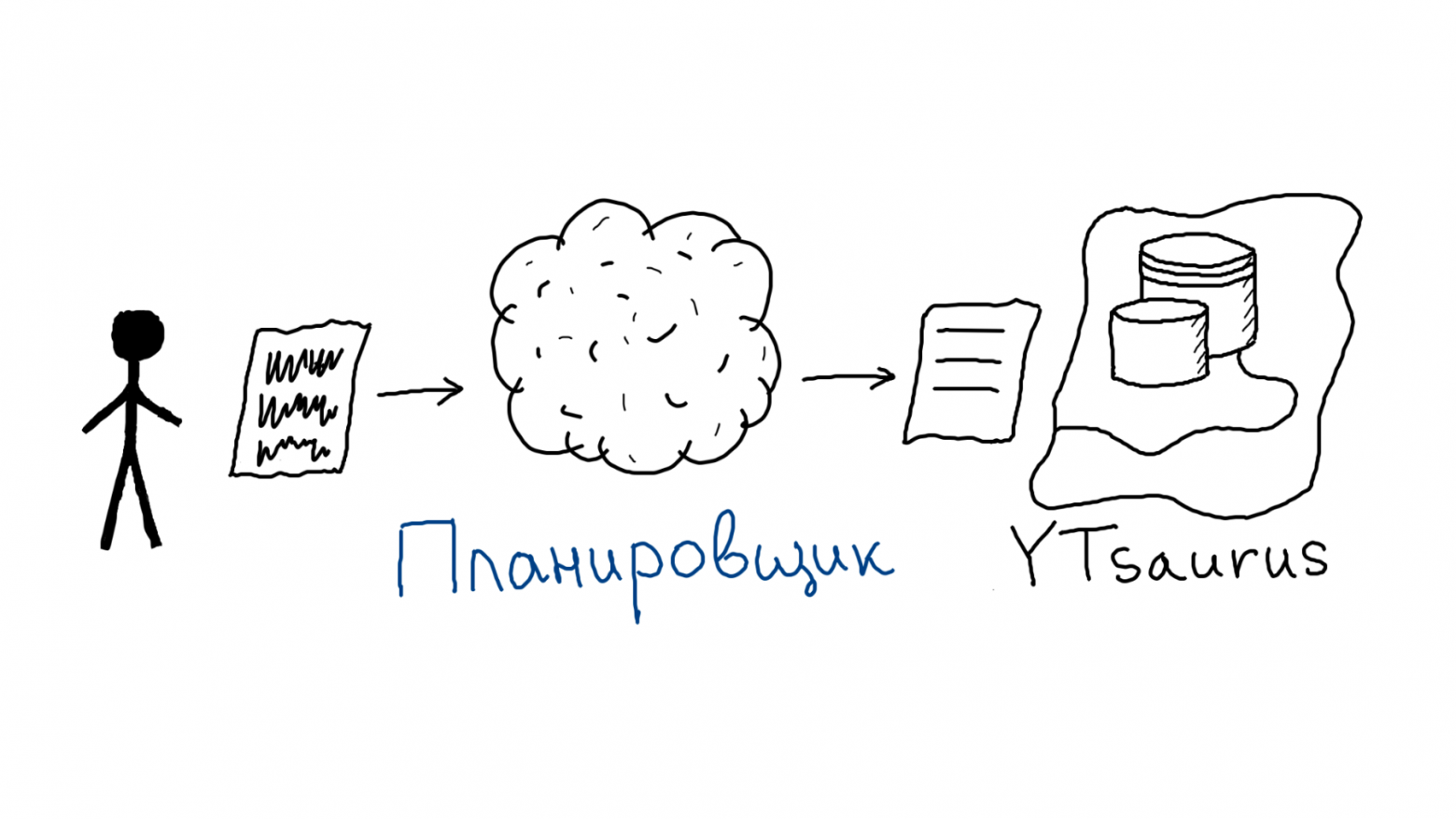
В больших распределённых системах многое зависит от эффективности запросов: если на гигабайте данных неоптимальный запрос может выполняться за миллисекунды, то при увеличении массива в тысячи раз, сервер начнёт кряхтеть, пыхтеть и жаловаться. Чтобы избежать этого, помогут знания о работе распределённых систем и их частей, а именно — планировщиков.
Ещё с университетских времён я исследую распределённые системы, а последние два года в Яндексе адаптирую Apache Spark к внутренней инфраструктуре. Эта статья посвящена Apache Spark, а именно: как мы в рамках YTsaurus делали его ещё эффективнее. Написана она по мотивам моего доклада для «Онтико».