Comments 39
Хочу отметить, что мы ожидаем значительный (от 2-3х, осторожная оценка) прирост производительности в следующей версии Zabbix 2.2, которая пока существует только в виде альфы, но готова для предварительного тестирования. Насколько большой — покажет время и реальные цифры от пользователей и клиентов.
У нас на этой версии большие проблемы с postgres и latest data, она не работает ))
Это ведь пока ещё альфа, работаем над ошибками.
На zabbix conference 2013 было большое сравнение производительности mysql и postgresql для работы с zabbix'ом от консультанта по постгресу. Почитайте, мб перейдёте на mysql, и проблема пропадёт
www.zabbix.com/img/zabconf2013/presentations/Which_Database_is_Better_for_Zabbix.pdf
www.zabbix.com/img/zabconf2013/presentations/Which_Database_is_Better_for_Zabbix.pdf
Zabbix I/O действительно кушает многовато. В AWS на бесплатном микроинстансе кушает помимо бесплатных I/O еще доллара на 2-3 в месяц, при этом мониторит только 3 VDS с стандартными тэмплейтами и раз в 5 минут. Примерно столько-же кушали 5 небольших инет-магазина.
Zabbix I/O складывается из двух основных величин: запись собранной информации и апдейты некоторых таблиц при получении данных. Понятно, что записи исторической информации на диск никак не избежать, но в Zabbix 2.2 мы практически полностью избавились от апдейтов, их не будет. Это позволит сэкономить как минимум половину I/O.
Главное, я думаю, правильно настраивать время хранения raw данных в zabbix, хранить 7-14 дней их в базе, все остально агрегированные значения, про это многие забывают и база из-за индексов разрастается и тормозит на запись. Хорошая производительность заббикса вполне достижима.
Читал эту статью в блоге заббикса, тоже была идея перевести ее. У вас все равно лучше получилось :)
Тем не менее мои 70 значений в секунду кажутся жалкими на фоне описываемой конфигурации. Еще интересно на сколько большой запас получается. То есть если zabbix_server даже на короткое время остановится, после запуска клиенты начнут засыпать сервер значениями, на сколько, интересно, быстро они будут разобранными?
Тем не менее мои 70 значений в секунду кажутся жалкими на фоне описываемой конфигурации. Еще интересно на сколько большой запас получается. То есть если zabbix_server даже на короткое время остановится, после запуска клиенты начнут засыпать сервер значениями, на сколько, интересно, быстро они будут разобранными?
Статью перевёл wabbit, все плюсы ему. Если сервер остановится на короткое время, то никаких проблем не возникнет. Да, клиенты начнут засыпать сервер значениями, но внутри Заббикса есть буферизация. Новые данные попадут в буфер который будет разгребаться воркерами. Это упрощённая картина.
В случае длительных остановок картина уже не настолько радужная, могут пройти десятки минут или даже часы пока прокси не отправит все накопленные данные на сервер. А таких данных для высоконагруженного прокси может быть очень много — сотни миллионов записей.
В случае длительных остановок картина уже не настолько радужная, могут пройти десятки минут или даже часы пока прокси не отправит все накопленные данные на сервер. А таких данных для высоконагруженного прокси может быть очень много — сотни миллионов записей.
После прочтения таких статей освежается понимание, какое все-таки огромное число слоев абстракции и кода лежит между прикладным уровнем и железом. Казалось бы, 10000 серверов. Не так и много — при том, что производительность процессоров исчисляется миллиардами операций в секунду, памяти — гигабайтами в секунду, дисков — сотнями мегабайт в секунду, сети — гигабитами, а объем оперативной памяти — сотнями гигабайт. Да на экране в разрешении 1024x769 около миллиона точек, а любая 3d-игра сменяет весь этот массив по 60 раз в секунду! Ан нет, нужно 4 машины, чтобы только мониторить эти 10000 серверов. Причем заббикс еще хорошо оптимизирован…
UFO just landed and posted this here
Отвечу за Corey Shaw. Да, он работает без housekeeper, что фактически является де-факто стандартом по установке Заббикса для мониторинга большой (более 5000 устройств или более 2000 NVPS) инфраструктуры.
UFO just landed and posted this here
Статья называется «Масштабируя Zabbix», но в результате мы получили отказоустойчивое, но не масштабируемое решение. Здесь узкое место — сам zabbix_server и база данных, которые никак не масштабируются.
В сети есть презентация на highload от яндекса, где они тотально решили эту проблему. Было бы замечательно, если бы они поделились техническими подробностями своего решения.
В сети есть презентация на highload от яндекса, где они тотально решили эту проблему. Было бы замечательно, если бы они поделились техническими подробностями своего решения.
Мне кажется, что мониторинг не является критически важным сервисом, от которого зависит работа бизнеса. Не думаю что имеет смысл тратить тонну усилий и средств чтобы делать HA.
К тому же я вижу, что основной упор в статье делается на мускул, как критичную точку. А репликация MySQL в свою очередь — асинхронна, поэтому в данном контексте эту проблему никак не решить.
К тому же я вижу, что основной упор в статье делается на мускул, как критичную точку. А репликация MySQL в свою очередь — асинхронна, поэтому в данном контексте эту проблему никак не решить.
700.000 элементов. Прекрасная работа.
Неужели такие расширенные шаблоны действительно необходимы. Возможно, чуть сложности можно было поубавить если подкорректировать шаблоны.
Более хорошее решение предложила моя жена: сначала обновиться MySQL до 5.6 и потом разбираться.
Вам очень повезло.
Неужели такие расширенные шаблоны действительно необходимы. Возможно, чуть сложности можно было поубавить если подкорректировать шаблоны.
Более хорошее решение предложила моя жена: сначала обновиться MySQL до 5.6 и потом разбираться.
Вам очень повезло.
После очистки таблиц InnoDB не возвращает место диску, оставляя его себе для новых данных.
innodb_file_per_table спасет отца русской демократии. А вообще в свое время я решил проблему производительности zabbix весьма радикально. Я сменил MySQL на PostgreSQL и забыл про проблемы с MySQL.
Зато появились новые проблемы.
— надо как-то партиционировать
— вакуум
— жрет ресурсов просто тонну
— репликация, если масштабировать
В новой версии, которая альфа, есть специфические для postgres проблемы, которые надо решать, иначе все со скрипом работает. Например тот же раздел latest data.
Наоборот думаем, обратно на mysql переезжать ))
— надо как-то партиционировать
— вакуум
— жрет ресурсов просто тонну
— репликация, если масштабировать
В новой версии, которая альфа, есть специфические для postgres проблемы, которые надо решать, иначе все со скрипом работает. Например тот же раздел latest data.
Наоборот думаем, обратно на mysql переезжать ))
— надо как-то партиционировать
Breaking news! Партицирование в PostgreSQL есть.
— вакуум
Автоваакуум ваш друг и он уже в поставке начиная с 9 версии.
— жрет ресурсов просто тонну
Это вам кто рассказал? Я вообще на ту же самую машину ставил. Я вот сколько времени работаю с СУБД MySQL и СУБД PostgreSQL могу сказать, что PostgreSQL работает лучше.
— репликация, если масштабировать
Из коробки. В PostgreSQL 9.3 добавили штатную процедуру remastering.
В новой версии, которая альфа, есть специфические для postgres проблемы, которые надо решать, иначе все со скрипом работает.
Это у товарищей из Zabbix есть специфичные проблемы с руками. Знаете когда для того чтобы сменить СУБД для работы надо пересобрать софт потому что используется определяется #define в коде, я начинаю подозревать, что тут что-то не так. Про код я вообще молчу. Я пару раз заглядывал для исправления в код как сервера, так и веб-интерфейса и как-то у меня это вызвало когнитивный дисонанс. Хотя при всем этом zabbix весьма хорош как мониторинг.
Вы не думайте, что я тут холиварю, но мне postgres хочется сменить уже довольно давно.
Партиционировать что-то как-то и эффективно партиционировать — это разные же вещи. Поэтому я и написал «как-то». Конкретно для zabbix надо еще заморочиться, что там распартиционировать, чтобы не тормозило.
Автовакуум не работает. Точнее он неэффективен. Все плавно поттупляет и постепенно идет полная деградация.
Из коробки что? master-slave репликация? Она не очень тут помогает, у нас 99% времени идет запись. Я вообще не очень доволен такой репликацией, когда по сети гоняются несжатые бинарники в просто диких количествах. Валы не долетели: синхронная репликация — клиент пятисотит, асинхронная — жестко жрется память и 30% снижение производительности БД. 9.3 тут вроде получше, да, но он только на днях релизнулся.
Про define не скажу ничего, у нас два разных пакета. zabbix-psql, zabbix-mysql, нет таких проблем ))
Ну а ресурсы — тут все у всех по разному.
Партиционировать что-то как-то и эффективно партиционировать — это разные же вещи. Поэтому я и написал «как-то». Конкретно для zabbix надо еще заморочиться, что там распартиционировать, чтобы не тормозило.
Автовакуум не работает. Точнее он неэффективен. Все плавно поттупляет и постепенно идет полная деградация.
Из коробки что? master-slave репликация? Она не очень тут помогает, у нас 99% времени идет запись. Я вообще не очень доволен такой репликацией, когда по сети гоняются несжатые бинарники в просто диких количествах. Валы не долетели: синхронная репликация — клиент пятисотит, асинхронная — жестко жрется память и 30% снижение производительности БД. 9.3 тут вроде получше, да, но он только на днях релизнулся.
Про define не скажу ничего, у нас два разных пакета. zabbix-psql, zabbix-mysql, нет таких проблем ))
Ну а ресурсы — тут все у всех по разному.
Партиционировать что-то как-то и эффективно партиционировать — это разные же вещи. Поэтому я и написал «как-то». Конкретно для zabbix надо еще заморочиться, что там распартиционировать, чтобы не тормозило.
Условия партицирования точно такие же как и в MySQL. Да более заморочно, но работает проверенно.
Автовакуум не работает. Точнее он неэффективен. Все плавно поттупляет и постепенно идет полная деградация.
Дурацкий конечно вопрос, но вы его настраивали?
Из коробки что? master-slave репликация? Она не очень тут помогает, у нас 99% времени идет запись. Я вообще не очень доволен такой репликацией, когда по сети гоняются несжатые бинарники в просто диких количествах.
Можно подумать в MySQL лучше.
Про define не скажу ничего, у нас два разных пакета. zabbix-psql, zabbix-mysql, нет таких проблем ))
Вот по этому и разные.
Ну а ресурсы — тут все у всех по разному.
В случае PostgreSQL надо подтюнить. А то большую часть времени когда я сталкиваюсь PostgreSQL говно, а вот MySQL да! Люди банально не тюнили PostgreSQL под свою машину и запускали с параметрами по умолчанию. А потом такие удивляются а чего он так процессор и диск жрет.
Ну конечно мы все настраивали и не по разу. Вот именно, что все более заморочено.
Репликация в postgres просто отвратная. Я уже молчу, что появилась она не так давно. И не решает почти никаких проблем с определенного профиля нагрузки, только добавляет. Galera cluster -> xtrabackup — работает не в пример отлично и настроить проще.
Postgresql у нас в проектах жив только потому, что там все просто прекрасно с geo, а мы такое используем очень интенсивно.
В остальном — mysql проще и лучше, особенно от percona.
Я про говно, кстати, не говорил. БД как БД. Со своими плюсами и минусами. Не панацея только ни разу. Мускуль такой же ))
Репликация в postgres просто отвратная. Я уже молчу, что появилась она не так давно. И не решает почти никаких проблем с определенного профиля нагрузки, только добавляет. Galera cluster -> xtrabackup — работает не в пример отлично и настроить проще.
Postgresql у нас в проектах жив только потому, что там все просто прекрасно с geo, а мы такое используем очень интенсивно.
В остальном — mysql проще и лучше, особенно от percona.
Я про говно, кстати, не говорил. БД как БД. Со своими плюсами и минусами. Не панацея только ни разу. Мускуль такой же ))
Ну конечно мы все настраивали и не по разу. Вот именно, что все более заморочено.
Весьма интересно так-как я наблюдал строго противоположную ситуацию. Хотя у вас вообще случаем БД не характеризуются следующими факторами
1. Небольшое количество таблиц
2. Большое количество данных в таблицах
3. Простые запросы.
Galera cluster -> xtrabackup — работает не в пример отлично и настроить проще.
Галера это другой коленкор. Стандартный же бекап аналогичен тому что в PostgreSQL такой же log shipping
В остальном — mysql проще и лучше, особенно от percona.
Ну не знаю. У меня видимо запросы к СУБД другие и при них MySQL ведет себя отвратно. Про то как там сделаны триггеры и процедуры я вообще молчу.
В постгресе репликация субъективно и правда захлебывается раньше, чем в mysql (пока). Но у постгресовой репликации есть одно неоспоримое достоинство: она никогда, ни при каких обстоятельствах не ломается, что бы ни происходило с машиной. А вот с mysql везде, где мне приходилось сталкиваться с репликацией, она раз или два в год слетала (то после сбоя по питанию, хотя опция синка стояла двоечка, то просто после резкого наплыва конкурентных запросов на запись). Может, не везло просто, не знаю, но когда на каждый сбой репликации удается найти в их багтрекере релевантный баг, это не очень приятно…
Да есть такое. И еще что хуже, починить ее без LVM snapshot весьма непросто. В случае же PostgreSQL починить с нуля весьма просто.
Ломается еще как. Все от количества данных зависит. Постоянно наблюдаю ситуацию, когда количество апдейтов таково, что сеть не успевает прососать все нагенеренные wal. Async реплики медленно уезжают в рекавери и начинают адски тормозить на простейших селектах.
А если в этот момент прилетит еще и битый wal, то реплику надо переподнимать с нуля. В геокластере, например, это — большая проблема. Ну и пока восстанавливаешь один slave, запросто можно потерять и все остальные ))
Блин почему они не сжимают бинарь, перед тем, как отправить его в сеть.
А если в этот момент прилетит еще и битый wal, то реплику надо переподнимать с нуля. В геокластере, например, это — большая проблема. Ну и пока восстанавливаешь один slave, запросто можно потерять и все остальные ))
Блин почему они не сжимают бинарь, перед тем, как отправить его в сеть.
Круто!
Кто помнит какие обновления были у Adobe 16 июля, так как тов. Corey Shaw вроде там сисадмин?
Кто помнит какие обновления были у Adobe 16 июля, так как тов. Corey Shaw вроде там сисадмин?
Интересно. 9000 новый значений это много. Я со своими 170 с более чем 1000 железок просто скромен. И у меня всего один сервак на котором крутится не только Zabbix но еще и nocproject. Сервак старый HP 360 c 2 проца по 2 ядра, 10 оперативы, три винта в Raid-5. MySQL 5.5 партиционирование.
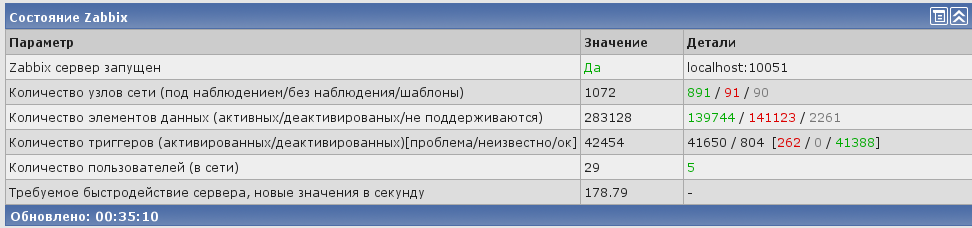
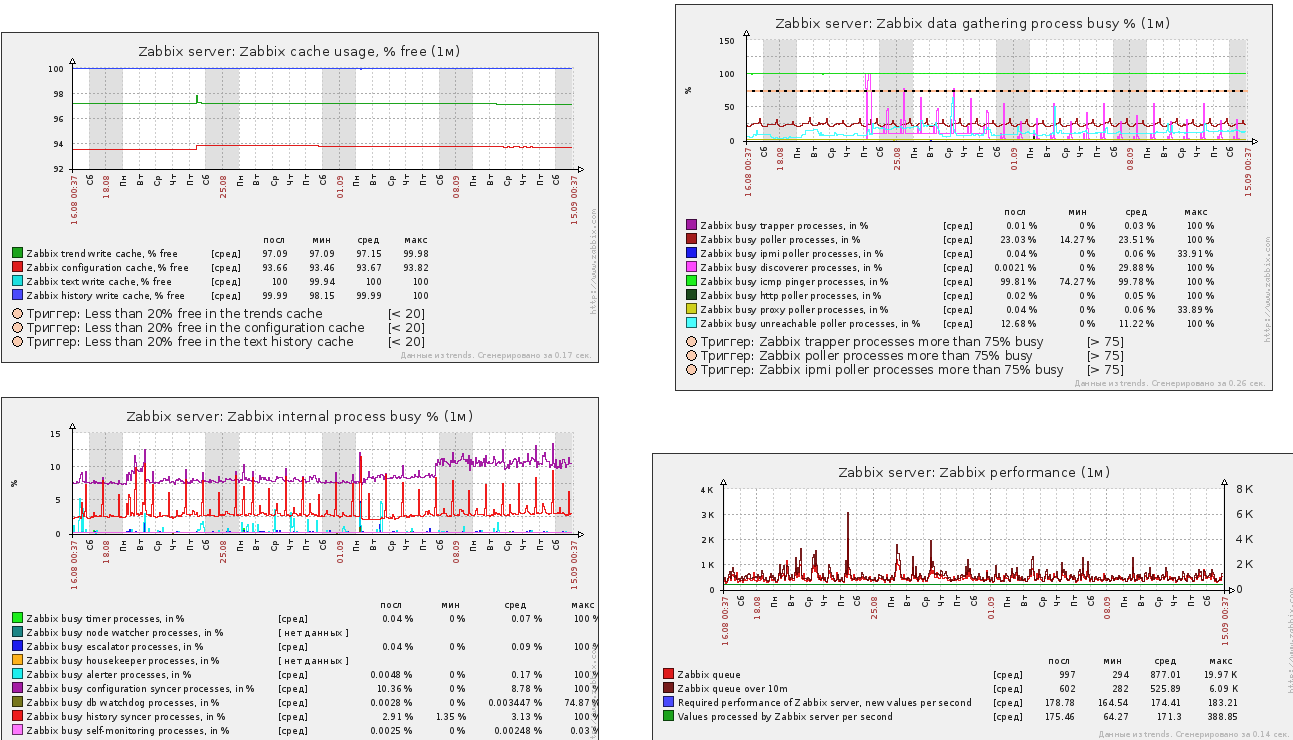
Все оборудование мониторится по SNMP.
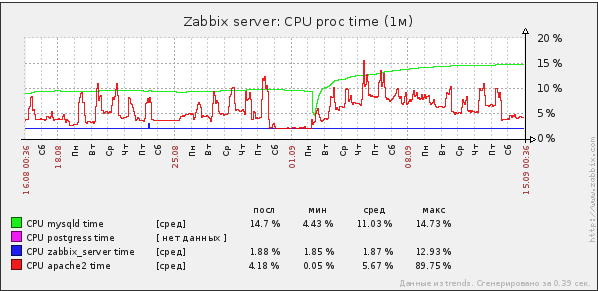
Вот так распределяется время разным процессам.
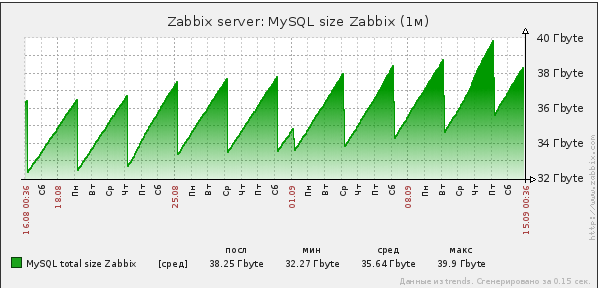
Очень конечно хочется отдельный сервер под БД, тогда я бы смог поднять детальность мониторинга сети на новый уровень. Сейчас все упирается в производительность и размер БД
На графике пила отображает работу удаления старых партиций и создание новых
Учитывая что размер дискового пространства 128 гиг, очень тесно сейчас.
Процессорного времени достаточно, IOwait я считаю очень низким.
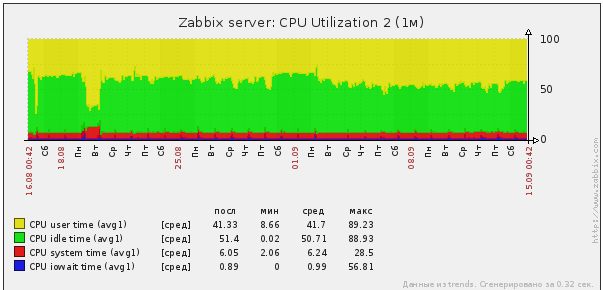
Ну и всякие разные данные
Эта система мониторит большое количество оборудования провайдера. Причем детальность мониторинга такая что можно посмотреть данные от 10G интерфейсов Juniper и вплоть до параметров ADSL каждого конкретного абонента (на более менее серьезных DSLAMах).
Статья очень понравилась, если будет железо под развитие того что я создал, то она станет ориентиром что возможно получить от системы.
ЗЫ Раньше был MySQL 5.1, потом долго пытался заставить работать Postgresql 8.3 9.0 9.1 и так и не добился с ним нормальной производительности. Место жралось, авто вакуум жрал проц большой совковой лопатой. Партиционирование, там честно говоря не очень. Хотя я может просто не умею его (Postgresql) готовить? После всех мучений вернулся к MySQL 5.1 земля и небо ))) Дальше было 5.5 и партиции. В общем сейчас система живет как часы. Сама находит новое железо, сама его добавляет и т.д.

Все оборудование мониторится по SNMP.
Вот так распределяется время разным процессам.

Очень конечно хочется отдельный сервер под БД, тогда я бы смог поднять детальность мониторинга сети на новый уровень. Сейчас все упирается в производительность и размер БД
На графике пила отображает работу удаления старых партиций и создание новых

Учитывая что размер дискового пространства 128 гиг, очень тесно сейчас.
Процессорного времени достаточно, IOwait я считаю очень низким.

Ну и всякие разные данные

Эта система мониторит большое количество оборудования провайдера. Причем детальность мониторинга такая что можно посмотреть данные от 10G интерфейсов Juniper и вплоть до параметров ADSL каждого конкретного абонента (на более менее серьезных DSLAMах).
Статья очень понравилась, если будет железо под развитие того что я создал, то она станет ориентиром что возможно получить от системы.
ЗЫ Раньше был MySQL 5.1, потом долго пытался заставить работать Postgresql 8.3 9.0 9.1 и так и не добился с ним нормальной производительности. Место жралось, авто вакуум жрал проц большой совковой лопатой. Партиционирование, там честно говоря не очень. Хотя я может просто не умею его (Postgresql) готовить? После всех мучений вернулся к MySQL 5.1 земля и небо ))) Дальше было 5.5 и партиции. В общем сейчас система живет как часы. Сама находит новое железо, сама его добавляет и т.д.
Sign up to leave a comment.
Масштабируя Zabbix