
Всем привет!
Сегодня поговорим о том, для каких задач на самом деле полезна MySQL Master-Master репликация, для каких — полностью бесполезна и вредна, какие мифы и заблуждения с ней связаны и какую практическую пользу можно быстро получить от данной технологии. Приведу конкретные примеры настройки и схемы архитектур.
Говорить о MySQL Master-Master репликации — в контекстах высокой доступности и производительности — модно, но, к сожалению, многие не понимают ее сути и связанных с технологией серьезных ограничений.
Начнем с того, что в классическом MySQL «настоящей» Master-Master репликации — пока нет :-) Но если постараться, можно все таки просто и быстро настроить эффективную схему выживания при отказе одного датацентра и получить свою долю счастья.

Известно, что для настройки Master-Master нужно настроить смещение ИДшников и установить для каждого сервера свой уникальный идентификатор:
Процедура подробно описана в сети, делается просто и быстро… Но это только сначала все просто. На самом деле на пути к успеху нас ожидает множество трупов, сюрпризов и подводных камней :-)
Итог: вы самостоятельно настроили MySQL Master-Master на двух серверах и готовы разбираться дальше.

Нужно четко понять раз и навсегда, что классическая репликация MySQL — асинхронна (в версии 5.6 появилась поддержка ПОЛУ-синхронной репликации; ПОЛУ выделено, т.к. она остается не полностью синхронной до сих пор).
К черту теорию, посмотрим чем нам грозит асинхронность репликации. Данные между БД передаются с произвольной задержкой (от миллисекунд до дней). Для архитектуры Master-Slave со Slave можно приложением просто не читать данные, отставшие на, допустим, 30 секунд. А вот для Master-Master все хуже — у нас нет и не будет (даже в случае ПОЛУ-синхронной репликации) никаких гарантий, что копии БД — синхронны. Т.е. один и тот же запрос может выполняться по-разному на каждой из БД. А одновременное выполнение команд:
также приведет к рассинхронизации данных в обеих БД (да простят нас Кодд и Дейт).
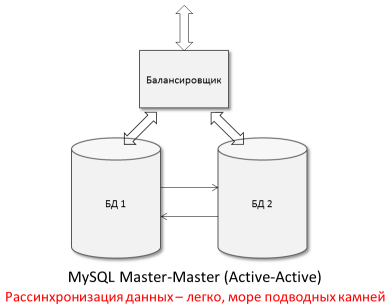
Одновременная вставка в обе БД одинакового уникального значения столбца (не автоинкремента!) — приведет к остановке репликации по ошибке. Таких «жутких» примеров можно привести множество.
И хотя иногда советуют решения типа «ON DUPLICATE KEY UPDATE», игнорирование ошибок и пр. и заодно перелопатить приложение — здравый смысл подсказывает, что подобные подходы — скользкие и ненадежные.
Думаю, очевидно, к какому коллапсу и несогласованности это может привести ваше приложение.
Итог: использовать асинхронный Master-Master для одновременной записи в обе БД без знания подводных камней — опасно и ненадежно и применяется в редких кейсах.

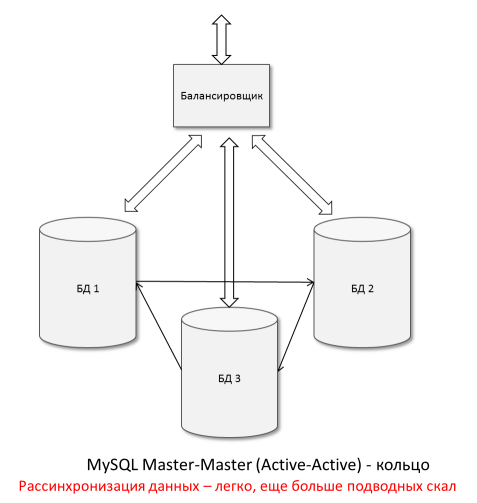
Технически возможно объединить MySQL сервера в кольцо. Однако вышеупомянутые проблемы становятся еще острее — добавляется недетерминизм, связанный с распространением записи по кольцу: можно выполнить обновление одновременно на 1 и 3 узле, а мимоходом раз, и на 2 узле. Что из этого получится на каждой ноде — страшно подумать. А поддерживать такое репликационное хозяйство — «сплошное удовольствие», кошмарный сон системного администратора.
Сейчас, в контексте настоящей синхронной Master-Master репликации (когда целостность данных гарантируется и писать можно одновременно на все ноды кластера) много говорят про Galera. Кто-то скажет, что для этого можно попробовать использовать давно известный MySQL NDB Cluster — но широко известно, что этот «автожир» подходит очень узкому кругу приложений, редко из мира веб.
Мы с интересом следим за Galera — возможно именно на ней в будущем будут строить подлинные Master-Master кластера, а пока посмотрим что полезного можно извлечь из имеющихся хорошо проверенных стабильных инструментов.

Однако, все не так печально. Как бы не ругали классическую MySQL Master-Slave репликацию за:
эта «рабочая лошадка» используется очень широко и приносит массу пользы и счастья системным администраторам:
В «полезную лошадку» можно достаточно быстро превратить и асинхронную Master-Master репликацию. Обычно данную архитектуру называют Master-Master (Active-Passive):
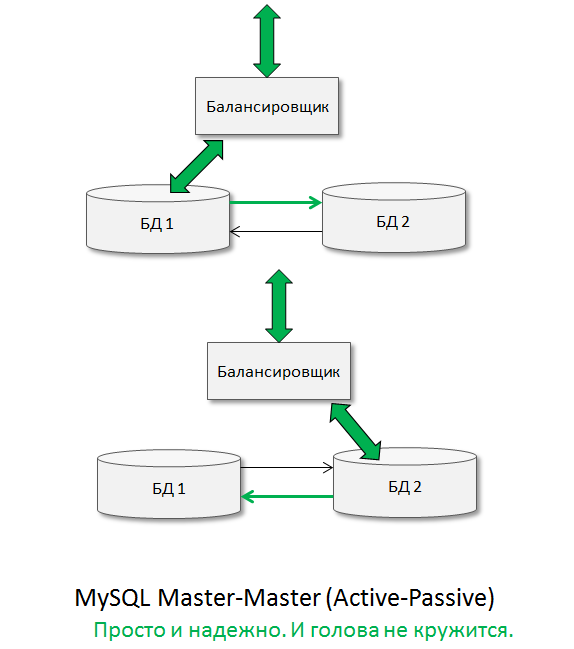
Идеи просты: пишем в одну БД, вторая используется как горячий бэкап, в который можно при необходимости БЫСТРО НАЧАТЬ ПИСАТЬ ДАННЫЕ! Именно «быстро начать писать данные» и дает этой архитектуре такую полезность и HighAvailability-льность.

Немного покурив и подумав, можно увидеть еще одно замечательное применение этой «рабочей лошадки» — способность выдержать аварию в локальном датацентре. Нужно просто держать горячую БД в Master-Master (Active-Passive) в другом датацентре, можно и на другом континенте:
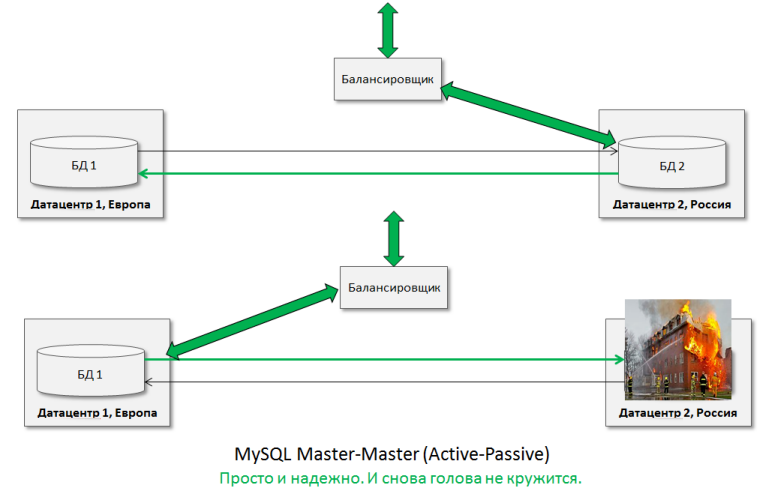
Да, вижу, стрелка в горящий датацентр уже не нужна, но оставим для целостности восприятия картинки :-)
Ну а дальше никто нам не запрещает масштабировать чтения на данной архитектуре, получив локальный относительно датацентра кластер:
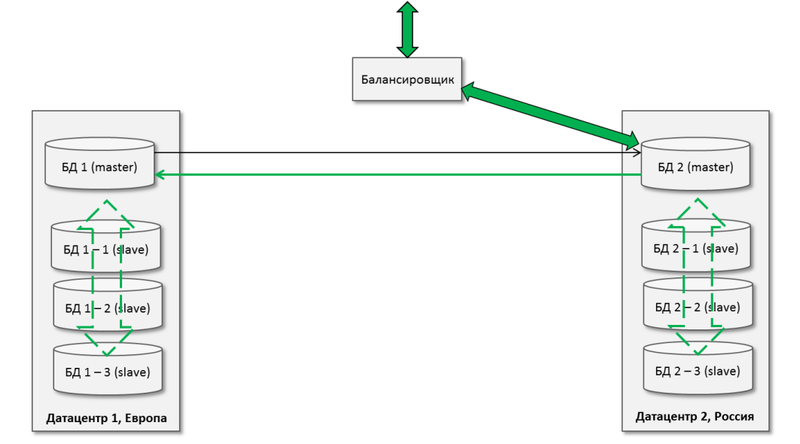
Только не забываем включить опцию логирования обновлений на мастере для подчиненных серверов.
Честно говоря, такая схема репликации работает достаточно надежно и мы ее с успехом применяем на Битрикс24 в облаке Amazon и в решении «Географический веб-кластер». Особенности же ее эксплуатации следующие:

Забыли про синхронизацию контента между ДЦ. Тут все в принципе стандартно:
Облачное хранилище для шары файлов — Clodo.ru, Selectel.ru, Amazon S3, Google Storage и другие. Интенсивное использование CDN. Передача статики между ДЦ посредством csync2, rsync и других подобных инструментов. Обычно тут проблем не возникает.
Стоит посмотреть на проект linux-ha и, видимо, сделать проще на bash ;-) Очень перспективной выглядит Galera. Будем также надеяться, что в MySQL наконец-то сделают «настоящую» Master-Master репликацию, так востребованную сегодня.
И конечно, совсем забыл — данные все равно могут рассинхронизироваться между Master-Master (Active-Passive). Это бывает из-за краха mysql, внезапной перезагрузки сервера, потери позиции репликации, ошибок в ее коде. Ничего страшного, есть лекарство — посложнее:
и попроще типа этого простого скриптика на bash (не используйте на больших таблицах):
На проекте Битрикс24 мы интенсивно используем описанную технологию — и это выручало нас не раз. Последнее падение датацента в амазоне 15 июня сего года прошло незаметно для клиентов — мы автоматически переключились на резервный мастер в другом ДЦ.
В статье мы по полочкам разобрали тему MySQL Master-Master, чтобы в дальнейшем не искать в этой технологии скрытого смысла. Рассмотрели опасные и плохо описанные в сети подводные камни. Выбрали для Master-Master (Active-Passive) простое и практичное применение для обеспечения горячего Master-сервера MySQL в другом датацентре (на другом континенте) и теперь сисдамину можно съездить в отпуск не опасаясь, что на всех нодах репликации данные станут разными (больше не упоминаю имен отцов основателей реляционной теории) или молния ударит в датацентр :-) Всем удачи, хорошего настроения и надежной репликации!
Сегодня поговорим о том, для каких задач на самом деле полезна MySQL Master-Master репликация, для каких — полностью бесполезна и вредна, какие мифы и заблуждения с ней связаны и какую практическую пользу можно быстро получить от данной технологии. Приведу конкретные примеры настройки и схемы архитектур.
Говорить о MySQL Master-Master репликации — в контекстах высокой доступности и производительности — модно, но, к сожалению, многие не понимают ее сути и связанных с технологией серьезных ограничений.
Начнем с того, что в классическом MySQL «настоящей» Master-Master репликации — пока нет :-) Но если постараться, можно все таки просто и быстро настроить эффективную схему выживания при отказе одного датацентра и получить свою долю счастья.
Настройка Master-Master
Известно, что для настройки Master-Master нужно настроить смещение ИДшников и установить для каждого сервера свой уникальный идентификатор:
- dev.mysql.com/doc/refman/5.5/en/replication-options-master.html#sysvar_auto_increment_increment
- dev.mysql.com/doc/refman/5.5/en/replication-options-master.html#sysvar_auto_increment_offset
- dev.mysql.com/doc/refman/5.5/en/replication-options.html#option_mysqld_server-id
Процедура подробно описана в сети, делается просто и быстро… Но это только сначала все просто. На самом деле на пути к успеху нас ожидает множество трупов, сюрпризов и подводных камней :-)
Итог: вы самостоятельно настроили MySQL Master-Master на двух серверах и готовы разбираться дальше.
Синхронность
Нужно четко понять раз и навсегда, что классическая репликация MySQL — асинхронна (в версии 5.6 появилась поддержка ПОЛУ-синхронной репликации; ПОЛУ выделено, т.к. она остается не полностью синхронной до сих пор).
К черту теорию, посмотрим чем нам грозит асинхронность репликации. Данные между БД передаются с произвольной задержкой (от миллисекунд до дней). Для архитектуры Master-Slave со Slave можно приложением просто не читать данные, отставшие на, допустим, 30 секунд. А вот для Master-Master все хуже — у нас нет и не будет (даже в случае ПОЛУ-синхронной репликации) никаких гарантий, что копии БД — синхронны. Т.е. один и тот же запрос может выполняться по-разному на каждой из БД. А одновременное выполнение команд:
UPDATE mytable SET mycol=mycol+1; - на одном сервере
UPDATE mytable SET mycol=mycol*3; - на втором сервере
также приведет к рассинхронизации данных в обеих БД (да простят нас Кодд и Дейт).
Одновременная вставка в обе БД одинакового уникального значения столбца (не автоинкремента!) — приведет к остановке репликации по ошибке. Таких «жутких» примеров можно привести множество.
И хотя иногда советуют решения типа «ON DUPLICATE KEY UPDATE», игнорирование ошибок и пр. и заодно перелопатить приложение — здравый смысл подсказывает, что подобные подходы — скользкие и ненадежные.
Думаю, очевидно, к какому коллапсу и несогласованности это может привести ваше приложение.
Итог: использовать асинхронный Master-Master для одновременной записи в обе БД без знания подводных камней — опасно и ненадежно и применяется в редких кейсах.
Магия кольца
Технически возможно объединить MySQL сервера в кольцо. Однако вышеупомянутые проблемы становятся еще острее — добавляется недетерминизм, связанный с распространением записи по кольцу: можно выполнить обновление одновременно на 1 и 3 узле, а мимоходом раз, и на 2 узле. Что из этого получится на каждой ноде — страшно подумать. А поддерживать такое репликационное хозяйство — «сплошное удовольствие», кошмарный сон системного администратора.
Поддержка синхронной репликации в MySQL
Сейчас, в контексте настоящей синхронной Master-Master репликации (когда целостность данных гарантируется и писать можно одновременно на все ноды кластера) много говорят про Galera. Кто-то скажет, что для этого можно попробовать использовать давно известный MySQL NDB Cluster — но широко известно, что этот «автожир» подходит очень узкому кругу приложений, редко из мира веб.
Мы с интересом следим за Galera — возможно именно на ней в будущем будут строить подлинные Master-Master кластера, а пока посмотрим что полезного можно извлечь из имеющихся хорошо проверенных стабильных инструментов.
Польза от асинхронной MySQL Master-Master репликации
Однако, все не так печально. Как бы не ругали классическую MySQL Master-Slave репликацию за:
- асинхронность (рассинхронизация данных на нодах, отставания ...)
- недостаточную надежность (flush_log_at_trx_commit=1, sync_binlog=1, sync_relay_log=1, sync_relay_log_info=1, sync_master_info=1, — иногда не достаточно, и репликация при рестарте сервера отваливается)
- недостаточная поддержка транзакционности (спасибо патчу Percona Server, в котором эта фича реализована)
эта «рабочая лошадка» используется очень широко и приносит массу пользы и счастья системным администраторам:
- для создания горячего «почти» актуального бэкапа
- для кластеризации чтений с MySQL слейвов
- для вертикального шардинга (фильтруем какие таблицы на какие слейвы переносить)
- для того, чтобы спокойно бэкапить Slave-сервер с помощью mysqldump, не нагружая боевой сервер БД
- и др.
В «полезную лошадку» можно достаточно быстро превратить и асинхронную Master-Master репликацию. Обычно данную архитектуру называют Master-Master (Active-Passive):
Идеи просты: пишем в одну БД, вторая используется как горячий бэкап, в который можно при необходимости БЫСТРО НАЧАТЬ ПИСАТЬ ДАННЫЕ! Именно «быстро начать писать данные» и дает этой архитектуре такую полезность и HighAvailability-льность.
Немного покурив...
Немного покурив и подумав, можно увидеть еще одно замечательное применение этой «рабочей лошадки» — способность выдержать аварию в локальном датацентре. Нужно просто держать горячую БД в Master-Master (Active-Passive) в другом датацентре, можно и на другом континенте:
Да, вижу, стрелка в горящий датацентр уже не нужна, но оставим для целостности восприятия картинки :-)
Ну а дальше никто нам не запрещает масштабировать чтения на данной архитектуре, получив локальный относительно датацентра кластер:
Только не забываем включить опцию логирования обновлений на мастере для подчиненных серверов.
Риски
Честно говоря, такая схема репликации работает достаточно надежно и мы ее с успехом применяем на Битрикс24 в облаке Amazon и в решении «Географический веб-кластер». Особенности же ее эксплуатации следующие:
- Начните эксплуатацию в режиме statement-based репликации. Если в логе MySQL появляются сообщения, что типа данный запрос опасно выполнять в этом режиме, т.к. порядок его выполнения на Slave может быть другим — включите режим репликации «mixed» (это может потребовать увеличения режима изоляции транзакций в InnoDB до Repeatable Read). Не рекомендую включать «row-based».
- Если вы беспокоитесь о производительности, то скорее всего не будете включать параметры: flush_log_at_trx_commit=1, sync_binlog=1, sync_relay_log=1, sync_relay_log_info=1, sync_master_info=1 (сарказм :-) ). Значит вам придется иногда после аварийных рестартов MySQL поднимать репликацию с последней позиции вручную — покурите с маном команды mysqlbinlog, очень много интересного и полезного можно найти.
- Постарайтесь пока не поднимите репликацию с одной стороны не переключать обратно балансировщик — иначе может начаться каша с данными (и во второй раз Кодд и Дейт могут уже не простить :-) ).
«А компот?»
Забыли про синхронизацию контента между ДЦ. Тут все в принципе стандартно:
Облачное хранилище для шары файлов — Clodo.ru, Selectel.ru, Amazon S3, Google Storage и другие. Интенсивное использование CDN. Передача статики между ДЦ посредством csync2, rsync и других подобных инструментов. Обычно тут проблем не возникает.
Что почитать по этой теме
Стоит посмотреть на проект linux-ha и, видимо, сделать проще на bash ;-) Очень перспективной выглядит Galera. Будем также надеяться, что в MySQL наконец-то сделают «настоящую» Master-Master репликацию, так востребованную сегодня.
И конечно, совсем забыл — данные все равно могут рассинхронизироваться между Master-Master (Active-Passive). Это бывает из-за краха mysql, внезапной перезагрузки сервера, потери позиции репликации, ошибок в ее коде. Ничего страшного, есть лекарство — посложнее:
и попроще типа этого простого скриптика на bash (не используйте на больших таблицах):
#!/bin/bash
DATABASES=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -B -N -e"SHOW DATABASES" | grep -vE '(^binlogs$)|(^performance_schema$)|(^test.*$)|(^information_schema$)'`
for DB in $DATABASES; do
TABLES=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -B -N -D $DB -e"SHOW TABLES"
for TABLE in $TABLES; do
CS_L=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -D $DB -B -N -e"CHECKSUM TABLE $TABLE" | awk '{print $2}'`
CS_R=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_R -D $DB -B -N -e"CHECKSUM TABLE $TABLE" | awk '{print $2}'`
if [ "$CS_L" != "$CS_R" ]; then
echo "${DB}-${TABLE} : DIFF"
mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -D $DB -B -N -e"SELECT * FROM $TABLE" > /var/tmp_data/table_diff_${SHARD_L}.tmp
mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_R -D $DB -B -N -e"SELECT * FROM $TABLE" > /var/tmp_data/table_diff_${SHARD_R}.tmp
diff -u /var/tmp_data/table_diff_${SHARD_L}.tmp /var/tmp_data/table_diff_${SHARD_R}.tmp
rm -f /var/tmp_data/table_diff_${SHARD_L}.tmp /var/tmp_data/table_diff_${SHARD_R}.tmp
else
echo "${DB}-${TABLE} : OK"
fi
done
done
Итоги
На проекте Битрикс24 мы интенсивно используем описанную технологию — и это выручало нас не раз. Последнее падение датацента в амазоне 15 июня сего года прошло незаметно для клиентов — мы автоматически переключились на резервный мастер в другом ДЦ.
В статье мы по полочкам разобрали тему MySQL Master-Master, чтобы в дальнейшем не искать в этой технологии скрытого смысла. Рассмотрели опасные и плохо описанные в сети подводные камни. Выбрали для Master-Master (Active-Passive) простое и практичное применение для обеспечения горячего Master-сервера MySQL в другом датацентре (на другом континенте) и теперь сисдамину можно съездить в отпуск не опасаясь, что на всех нодах репликации данные станут разными (больше не упоминаю имен отцов основателей реляционной теории) или молния ударит в датацентр :-) Всем удачи, хорошего настроения и надежной репликации!
