
При запуске любого теста производительности (инструмента по бенчмаркингу) на кластере критично всегда то, какой именно будет использоваться набор данных, и здесь мы покажем, почему при запуске теста производительности HBase на кластере важно выбрать «хорошо соответствующий по объему» набор данных.
Производительность вашей рабочей нагрузки и результаты тестирования на одном и том же кластере в зависимости от конфигурации кластера HBase и размера дата сета могут заметно варьироваться. Следует выбирать тот или иной размер набора данных в зависимости от того, что именно вы пытаетесь понять, тестируя производительность кластера. Чтобы показать разницу между набором данных, который умещается в доступном кэше, и набором, который нужно вытягивать из низлежащего хранилища, мы провели два теста YCSB с соответствующим образом выбранными размерами наборов данных на одном и том же кластере CDP Private Cloud Base 7.2.2. Мы использовали наборы данных размером 40 ГБ и 1 ТБ. Ниже сравнивается пропускная способность для разных рабочих нагрузок YCSB. Чем выше столбец, тем лучше пропускная способность.

Когда приложение пытается выполнить чтение на кластере HBase, региональный сервер, обрабатывающий запрос, сначала проверяет, находятся ли необходимые результаты в блоке данных, который уже локален для процесса, проверяя кэш-память. Если блок данных там присутствует, то клиентский запрос может обслуживаться непосредственно из кэш-памяти, и это считается попаданием в кэш (cache hit). Однако, если блок в настоящее время не является локальным для процесса region сервера, это считается кэш-промахом (cache miss). Такой блок считывается из HFile - хранилища HDFS. В зависимости от использования кэша этот блок может быть сохранен в кэш-памяти для будущих запросов.
Как и ожидалось (это показано в сводной диаграмме ниже), рабочая нагрузка, при которой большая часть набора данных попадает в кэш-память, имеет меньшие задержки и гораздо большую пропускную способность по сравнению с рабочей нагрузкой, при которой доступ к данным осуществляется через HFiles в HDFS.
Чтобы правильно выбрать размеры дата сетов для достижения целей тестирования, важно проверить размеры динамической области памяти RegionServer, кэш-памяти L1 и L2, кэш-памяти буферов ОС, а затем задать соответствующий размер набора данных. После того, как выполнение рабочей нагрузки YCSB завершилось, хороший параметр для проверки (его можно использовать в качестве способа проверки того, что все работало, как ожидалось) - это то, какая часть данных была обслужена из кэш-памяти (попадание в кэш), и сколько данных было получено из HDFS. Это отношение попаданий в кэш region сервера к общему количеству запросов на чтение и есть коэффициент попаданий в кэш.
Вы можете найти эту информацию в значении коэффициента попадания в кэш L1 «l1CacheHitRatio». Если в вашем кластере установлена кэш-память L1 и L2, то кэш L1 обслуживает блоки индекса, а кэш L2 - блоки данных, и вы можете для справки записать конфигурации L1 «l1CacheHitRatio» и L2 «l2CacheHitRatio».
В оставшейся части мы рассмотрим детали нашего стенда для тестов, выберем размер наборов данных, а затем запустим тесты YCSB на этих дата сетах.
Конфигурация кластера HBase, используемая для этого теста::
- Используется кластер с 6 узлами (1 master + 5 региональных серверов)
- Узлы: Dell PowerEdge R430, 20c / 40t Xenon e5-2630 v4 @ 2.2 ГГц, 128 ГБ ОЗУ, диски 4-2 ТБ
- Безопасность: не настроена (без Kerberos)
- Версия CDP: CDP Private Cloud Base 7.2.2 6-узловой кластер HBase с 1+ 5 региональными серверами
- Используемый JDK - jdk1.8_232
- Region сервера HBase были настроены с 32 ГБ heap памяти
- Мастер узел HBase был настроен с 4 ГБ heap памяти
- Для кэша L1 с LruBlockCache был использован размер кэша 12,3 ГБ.
- Общий кэш L1 в кластере составляет 61 ГБ (12,3 * 5 = 61 ГБ).
- L2 off heap кэш в кластере не был настроен.
Вариант 1: данные полностью помещаются в доступный кэш в кластере.
В нашем кластере HBase мы настроили в общей сложности 61 ГБ (12,3 ГБ * 5) для 5 региональных серверов, выделенных для кэша L1. Для набора данных, который полностью помещается в кэш, мы выбрали дата сет размером 40 ГБ.
Вариант 2: набор данных больше, чем доступная емкость кэш-памяти в кластере.
Во втором сценарии мы хотим, чтобы данные были намного больше, чем доступный кэш. Чтобы выбрать подходящий размер набора данных, мы проверли как настроенный блочный кэш HBase, так и буферный кэш ОС в кластере. В нашем кластере HBase сконфигурированный блочный кэш L1 составляет 61 ГБ (при агрегировании по серверам RegionServers). Каждый узел имел в общей сложности 128 ГБ ОЗУ, и любая память, не выделенная для серверного процесса, могла использоваться ОС для эффективного кэширования базовых блоков HDFS и увеличения общей пропускной способности. В нашей тестовой конфигурации для этой цели доступно около 96 ГБ кэш-памяти ОС на каждом узле региональном сервере (без учета памяти, используемой DataNode или процессами ОС - для упрощения). Суммируя это по 5 региональным серверам, потенциально получим почти 500 ГБ для буферов (96 ГБ * 5 региональных серверов). Таким образом, мы выбрали размер набора данных 1 ТБ, превышающий как настроенный блочный кэш, так и доступный буферный кэш ОС.
Преобразование целевых размеров данных в параметры YCSB
В YCSB размер строки по умолчанию составляет 1 КБ, поэтому в зависимости от того, сколько строк вы загружаете в «таблицу пользователя» YCSB, можно легко оценить размер данных «таблицы пользователя» YCSB. Таким образом, если загружается 1 миллион строк, то вы загружаете 1000000 * 1 КБ = 1 ГБ данных в таблицу пользователей YCSB.
Размеры наборов данных, используемых для наших двух тестов, были следующими:
· 40 ГБ данных с 40 миллионами строк
· 1 ТБ данных с 1 миллиардом строк
Методология тестирования
CDP Private Cloud Base 7.2.2 была установлена в кластере с 6 узлами и дата сетом с 40 миллионами строк (общий размер набора данных => 40 ГБ), и были запущены рабочие нагрузки YCSB. После загрузки данных мы ожидали завершения всех compaction операций перед тем, как начать тестирование.
Рабочими нагрузками YCSB, которые выполнялись на HBase, были:
1. рабочая нагрузка A: 50% операций чтения и 50% обновления
2. рабочая нагрузка C: 100% чтения
3. рабочая нагрузка F: 50% чтение и 50% обновление/чтение-изменение-записи: соотношение 50/50
4. пользовательская UpdateOnly рабочая нагрузка: 100% обновление
Для измерения пропускной способности YCSB каждая рабочая нагрузка YCSB (A, C, F и UpdateOnly) выполнялась в течение 15 минут, и повторялась 5 раз без перерыва между запусками*. Показанные результаты представляют собой средние значения, полученные для последних 3 из 5 запусков. Первые 2 тестовых прогона были проигнорированы.
После завершения прогонов с 40 ГБ мы удалили таблицу пользователей и повторно сгенерировали 1 миллиард строк, чтобы создать набор данных размером 1 ТБ, и повторно провели тесты с той же методологией в том же кластере.
Результаты тестирования
Результаты YCSB с 40 ГБ
При объеме 40 ГБ данные могут полностью поместиться в 61 ГБ кэш-памяти L1 в кластере. Коэффициент попадания в кэш L1, наблюдаемый в кластере во время теста, был близок к 99%.
Совет: для небольших наборов данных, когда данные могут поместиться в кэш, мы также можем использовать параметр кэширования при загрузке и предварительно "разогреть" кэш-память, чтобы получить 100% коэффициент попадания в кэш, используя параметр таблицы PREFETCH_BLOCKS_ON_OPEN
Мы выполняли каждую рабочую нагрузку YCSB в течение 15 минут по 5 раз и взяли средние значения из последних 3 прогонов, чтобы избежать искажений при первой серии.
Результаты с коэффициентом попадания в кэш L1 99% на региональных серверах приведены ниже в таблице:
Тест | Количество операций | Пропускная способность | Средняя задержка | 95 Задержка | 99 Задержка |
|
| (число операций / сек) | (мс) | (мс) | (мс) |
Нагрузка С | 148558364 | 165063 | 0.24 | 0,30 | 0,48 |
UpdateOnly | 56727908 | 63030 | 0,63 | 0,78 | 1,57 |
Нагрузка A | 35745710 | 79439 | 0,40 | 0,54 | 0,66 |
Нагрузка F | 24823285 | 55157 | 0,58 | 0,70 | 0,96 |
YCSB Результаты с набором данных 1 ТБ
В случае 1 ТБ данные не помещаются в 61 ГБ L1 кэш в кластере или в буферный кэш ОС на 500 ГБ. Коэффициент попадания в кэш L1 в кластере, наблюдаемый во время теста, составлял 82-84%.
Мы выполняли каждую рабочую нагрузку по 15 минут по 5 раз и брали средние значения из последних 3 запусков, чтобы избежать искажений первых прогонов.
Результаты с 1 ТБ данных и коэффициентом попадания в кэш L1 82-84% на региональных серверах показан ниже в таблице:
Тест | Количество операций | Пропускная способность | Средняя задержка | 95 Задержка | 99 Задержка |
|
| (число операций / сек) | (мс) | (мс) | (мс) |
Нагрузка C | 2727037 | 3030 | 13,19 | 55,50 | 110,85 |
UpdateOnly | 56345498 | 62605 | 0,64 | 0,78 | 1,58 |
Нагрузка A | 3085135 | 6855 | 10,88 | 48,34 | 97,70 |
Нагрузка F | 3333982 | 3704 | 10,45 | 47,78 | 98,62 |
* Пропускная способнось (число операций / сек) = Количество операций в секунду
Анализ:
Сравнивая результаты тестирования для двух наборов данных разных размеров, указанных выше, мы можем увидеть, как может варьироваться пропускная способность рабочей нагрузки - от 3 до 165 тыс. операций в секунду для 40 ГБ, при более быстром доступе к данным с разогретым кэшем по сравнению с вытягиванием данных из хранилища HDFS.
На диаграмме ниже показана пропускная способность. Она сравнивается для разных рабочих нагрузок при запуске с двумя наборами данных разного размера. Чем выше столбец, тем лучше пропускная способность.

Как видно на илюстрации, рабочие нагрузки YCSB, которые считывают данные, такие как рабочая нагрузка A, рабочая нагрузка C и рабочая нагрузка F, показывают гораздо лучшую пропускную способность в случае 40 ГБ дата сета, когда данные легко помещаются в кэш, чем в случае 1 ТБ данных, когда к данным HFile необходимо было получить доступ из HDFS.
Если посмотреть на коэффициенты попадания в кэш, то у набора данных 40 ГБ он составляет около 99%, а у набора данных 1 ТБ - около 85%, так что 15% данных в наборе 1 ТБ были получены из хранилища HDFS.
Пользовательская рабочая нагрузка UpdateOnly в обоих случаях имела одинаковую пропускную способность, поскольку выполнялось только обновление, но не считывание данных.
Во время тестов работы HBase мы внимательно смотрим на задержки 95-го и 99-го процентилей. Средняя задержка - это просто общая пропускная способность, деленная на общее время, однако 95-й и 99-й процентили показывают реальные выбросы, которые влияют на общую пропускную способность рабочей нагрузки. В случае 1 ТБ выбросы с высокой задержкой в 95-м и 99-м процентилях приводят к снижению пропускной способности, а в случае набора 40 ГБ кэш с малой задержкой в 99-м процентиле приводит к увеличению общей пропускной способности.
Ниже показано сравнение задержки для средней задержки, задержки 95-го процентиля и задержки 99-го процентиля, а также ее различия для разных рабочих нагрузок при запуске с наборами данных разного размера.
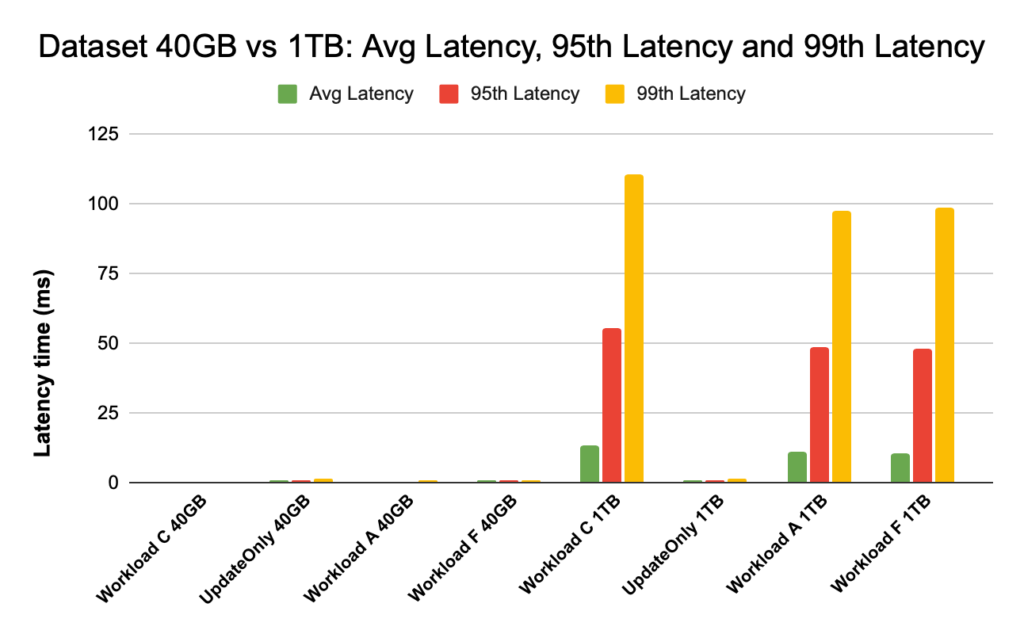
На приведенной выше диаграмме трудно увидеть столбцы, представляющие задержку для набора данных 40 ГБ, поскольку они чрезвычайно малы по сравнению с задержкой, наблюдаемой для набора данных 1 ТБ при доступе к данным из HDFS.
Мы построили график задержки, используя журнал значений задержки, чтобы показать разницу:
Как видно, задержки намного ниже в случае 40 ГБ, когда коэффициент попадания в кэш близок к 99% и большая часть данных рабочей нагрузки доступна в кэше. По сравнению с набором данных размером 1 ТБ, коэффициент попадания в кэш составлял около 85%, поскольку к данным HFile приходилось обращаться из хранилища HDFS.
Средняя задержка 99 для рабочей нагрузки C в случае 40 ГБ, когда 99% данных берутся из разогретого кэша, составляла около 2–4 мс. Задержка 99-го процентиля для той же рабочей нагрузки C в случае 1 ТБ составила около 100 мс (рабочая нагрузка только с чтением).
Это показывает, что попадание в кэш возвращает данные при чтении примерно за 2 мс, а промах кэша и получение данных из HDFS может потребовать в этом кластере около 100 мс.
Рекомендация:
При выполнении сравнительного теста YCSB размер набора данных имеет для результатов теста производительности существенное значение, и, следовательно, правильный размер данных для теста очень важен. В то же время анализ коэффициента попадания в кэш и различия в задержке между минимальной и 99-й задержкой поможет вам определить задержку попадания в кэш по сравнению с тем, когда к данным осуществляется доступ из базового хранилища в кластере.
Совет:
Для проверки коэффициентов попадания в кэш при вашей рабочей нагрузке на региональном сервере вы можете использовать команду:
curl http://:22102/jmx | grep -e l1CacheHitRatio -e l2CacheHitRatio
Вы также можете просмотреть коэффициент попадания в кэш в веб-интерфейсе HBase, выполнив следующие действия:
1. В веб-интерфейсе HBase кликните на региональный сервер.
2. В разделе «Block Cashe» выберите L1 (и L2, если настроен L2), чтобы просмотреть коэффициенты попадания в кэш.
Снимок экрана, показывающий коэффициент попадания для блочного кэша L1, показан ниже:
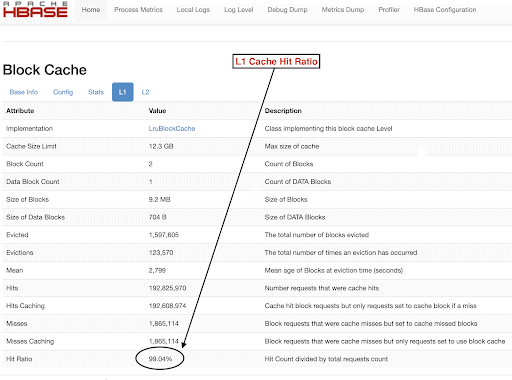
Вот ссылка на дополнительную информацию об экране HBase, показанном выше, и блочном кэше: https://docs.cloudera.com/runtime/7.2.2/configuring-hbase /topics/hbase-blockcache.html
О YCSB
YCSB - это спецификация и набор программ с открытым исходным кодом для оценки возможностей и обслуживания компьютерных программ. Это очень популярный инструмент, используемый для сравнения относительной производительности NoSQL-систем управления базами данных.
Чтобы использовать YCSB для тестирования производительности операционной базы данных, почитайте блог Как запустить YCSB для HBase.
