Сегодня мы рассмотрим тему, которая не в полной мере раскрыта в современном мире ИТ: живая миграция контейнеров, как она работает за кулисами и какие проблемы решает. Спрос на данную технологию продолжает стремительно расти, поскольку она открывает новые возможности, предоставляя больше свободы в управлении жизненным циклом приложений.
Живая миграция контейнеров подразумевает собой процесс перемещения приложения между разными физическими машинами или облаками без прерывания работы приложения и разрыва связи с пользователем. Память, файловая система и сетевое соединение контейнеров, запущенные поверх «голой» аппаратуры, передаются от исходного хост-компьютера к месту назначения, поддерживая рабочее состояние без прерывания работы.
Существует несколько проблем, которые может решить живая миграция:
Все выше упомянутые проблемы можно решить, и сейчас мы расскажем несколько вариантов решения данных проблем без помощи живой миграции.
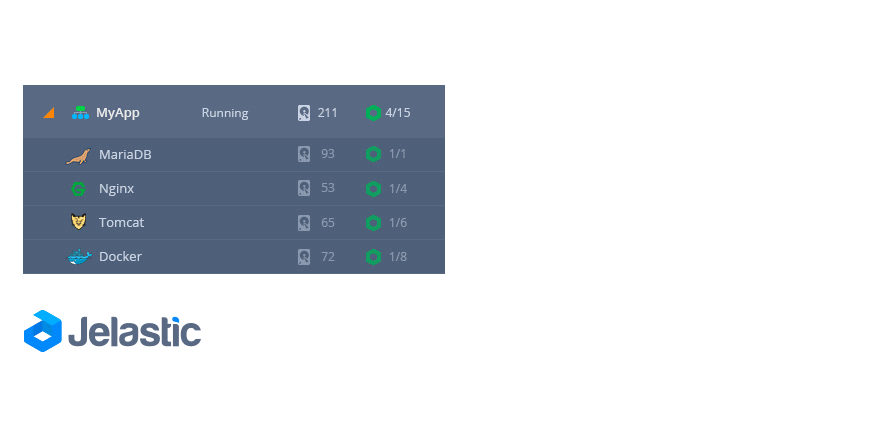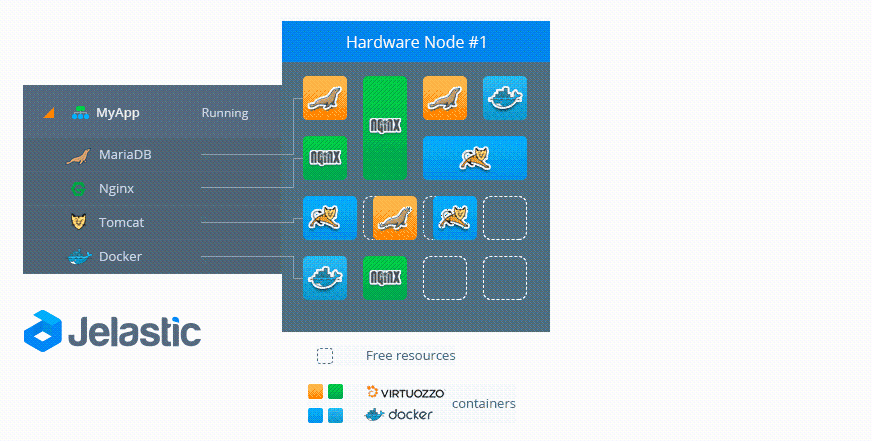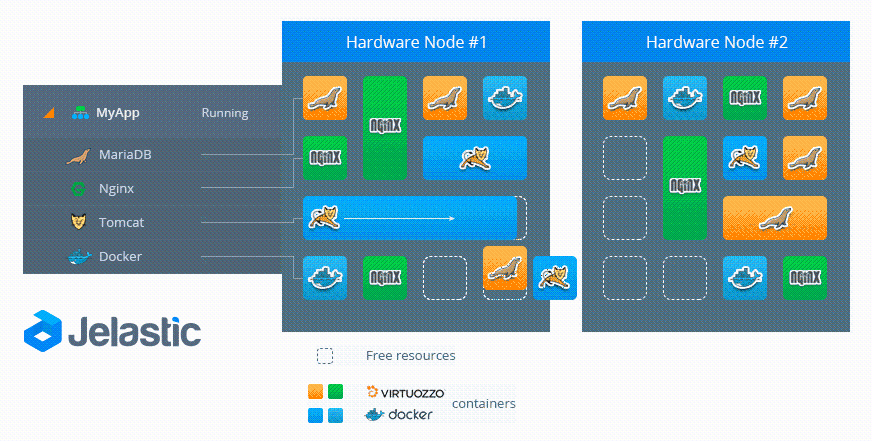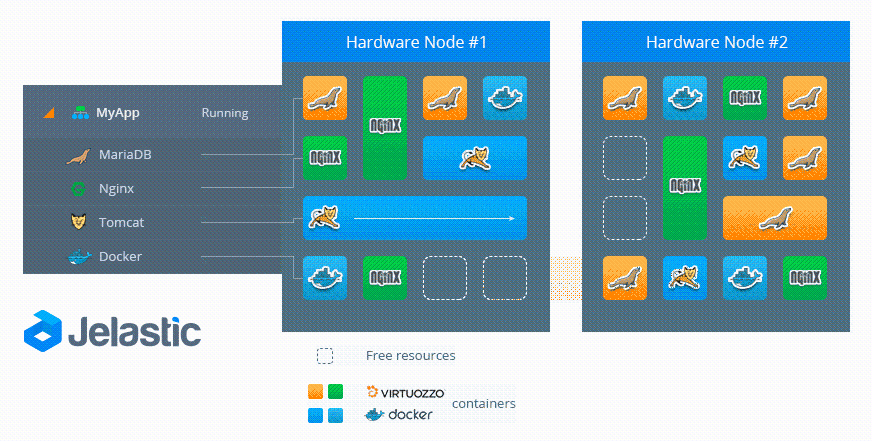
Давайте рассмотрим процесс живой миграции с технической стороны на примере следующей схемы:
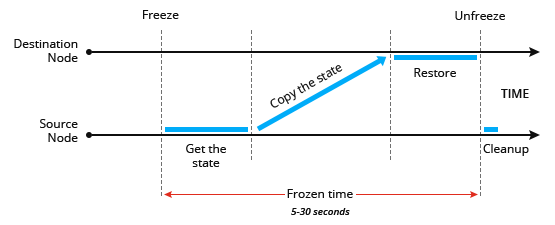
Чтобы выполнить миграцию, платформа замораживает контейнер в исходном узле, блокируя память, процессы, файловую систему и сетевые соединения, и сохраняет состояние этого контейнера. После этого он копируется в узел назначения. Платформа восстанавливает состояние и размораживает контейнер в данном узле. Затем, в исходном узле осуществляется процесс быстрой очистки данных мигрирующего контейнера.
Всё довольно таки просто: вы получаете, копируете и восстанавливаете состояние контейнера. Однако, в этом случае нужно принимать во внимание период заморозки, который нужно учитывать при разработке (архитектуры) приложений, так как этот момент может оказаться критическим для некоторых из них.
Существует два способа осуществления живой миграции. Одним из них является предварительное копирование памяти. Если вы хотите перенести контейнер, платформа направит отслеживаемую память на исходный узел, и будет копировать эту память одновременно с узлом назначения до тех пор, пока различие не станет минимальным. После этого платформа замораживает контейнер, получает оставшееся состояние, переносит его на узел назначения, восстанавливает и размораживает его.
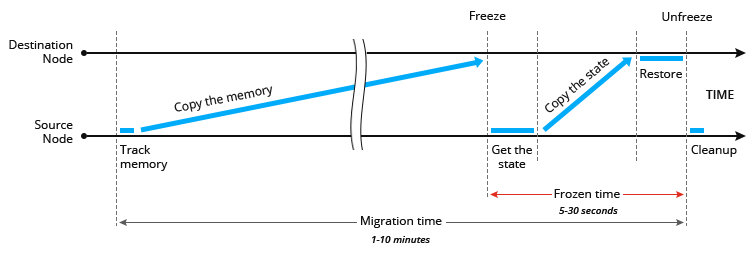
Другой способ — пост-копирования памяти, или другими словами — ленивая миграция. Система вначале замораживает контейнер в исходном узле, получает состояние наиболее быстро меняющихся страниц памяти, переносит состояние на узел назначения, восстанавливает его и размораживает контейнер. Остальная часть состояния в фоновом режиме копируется из исходного узла на узел назначения.

Обычно, в зависимости от приложения, время замораживания для каждого контейнера занимает от 5 до 30 секунд. Это действительно короткий срок по сравнению с возможными часами простоя во время обслуживания кластера.
При всех преимуществах живой миграции, также существуют несколько недостатков, которые нужно принимать во внимание перед началом миграции:
Какие компании предлагают живую миграцию контейнеров на сегодняшний день?
Для того, чтобы увидеть процесс миграции приложения Minecraft из AWS на Azure в режиме реального времени без простоев, просмотрите следующее видео:
Живая миграция контейнеров все еще является относительно новой технологией на рынке. Тем не менее, преимущества этой технологии для современного бизнеса очевидны — никаких простоев во время обслуживания, не нужно тратить много усилий на подготовку и проверку рабочей среды в другом облаке. Именно поэтому живая миграция является отличным решением для лучшей доступности и гибкости. Поделитесь своим опытом миграции контейнеров между облаками или датацентрами в режиме реального времени.
Живая миграция – что это?
Живая миграция контейнеров подразумевает собой процесс перемещения приложения между разными физическими машинами или облаками без прерывания работы приложения и разрыва связи с пользователем. Память, файловая система и сетевое соединение контейнеров, запущенные поверх «голой» аппаратуры, передаются от исходного хост-компьютера к месту назначения, поддерживая рабочее состояние без прерывания работы.
Проблемы, которые решает живая миграция
Существует несколько проблем, которые может решить живая миграция:
- Период простоя во время обслуживания аппаратуры
- Несбалансированная загрузка кластера
- Проблемы с облаком
Альтернативные Решения
Все выше упомянутые проблемы можно решить, и сейчас мы расскажем несколько вариантов решения данных проблем без помощи живой миграции.
- Запланированные периоды простоя. Для выполнения технических работ по обслуживанию кластера, нужно пройти три шага:
1. Заранее уведомить пользователей (владельцев приложений) об окне обслуживания и возможном периоде простоя
2. Отключить аппаратное оборудование
3. Подключить обратно только после того, как все необходимые изменения будут выполнены. В этом случае проблемой является относительно большой период простоя.
- Перенаправление трафика. Чтобы выполнить обслуживание кластера необходимо восстановить копию каждого приложения в другом аппаратном узле, затем перенаправить трафик к этой новой копии и закрыть предыдущую. В этом случае проблемой является сложность данного процесса — необходимо иметь специально разработанные приложения для получения высокой доступности и синхронизации данных. Кроме того, для выполнения этой задачи может потребоваться больше аппаратных ресурсов.
- Микросервисы. Детальное деление сервисов приложений на отдельные контейнеры и их распределение по различным физическим серверам помогает избежать периодов простоя в случае сбоя аппаратного обеспечения. Вышедшие из строя контейнеры будут автоматически восстановлены в активном аппаратном узле. Однако в этом случае проблемой является опять же сложность данного процесса, поскольку приложения в кластере должны быть разработаны таким образом, чтобы можно было управлять высокой доступностью и восстановлением процесса после сбоя.
Как Работает Живая Миграция
Давайте рассмотрим процесс живой миграции с технической стороны на примере следующей схемы:
- Исходный Узел (Source Node) — местоположение контейнера перед живой миграцией
- Узел назначения (Destination Node) — местоположение контейнера после живой миграции
Чтобы выполнить миграцию, платформа замораживает контейнер в исходном узле, блокируя память, процессы, файловую систему и сетевые соединения, и сохраняет состояние этого контейнера. После этого он копируется в узел назначения. Платформа восстанавливает состояние и размораживает контейнер в данном узле. Затем, в исходном узле осуществляется процесс быстрой очистки данных мигрирующего контейнера.
Всё довольно таки просто: вы получаете, копируете и восстанавливаете состояние контейнера. Однако, в этом случае нужно принимать во внимание период заморозки, который нужно учитывать при разработке (архитектуры) приложений, так как этот момент может оказаться критическим для некоторых из них.
Существует два способа осуществления живой миграции. Одним из них является предварительное копирование памяти. Если вы хотите перенести контейнер, платформа направит отслеживаемую память на исходный узел, и будет копировать эту память одновременно с узлом назначения до тех пор, пока различие не станет минимальным. После этого платформа замораживает контейнер, получает оставшееся состояние, переносит его на узел назначения, восстанавливает и размораживает его.
Другой способ — пост-копирования памяти, или другими словами — ленивая миграция. Система вначале замораживает контейнер в исходном узле, получает состояние наиболее быстро меняющихся страниц памяти, переносит состояние на узел назначения, восстанавливает его и размораживает контейнер. Остальная часть состояния в фоновом режиме копируется из исходного узла на узел назначения.
Обычно, в зависимости от приложения, время замораживания для каждого контейнера занимает от 5 до 30 секунд. Это действительно короткий срок по сравнению с возможными часами простоя во время обслуживания кластера.
Примеры Использования Живой Миграции
- Обслуживание аппаратных средств без периода простоя
- Перераспределение загрузки
- Высокая доступность между зонах доступности в центрах обработки данных (ЦОД)
- Переход к другому облачному провайдеру
Подводные Камни и Возможные Недостатки
При всех преимуществах живой миграции, также существуют несколько недостатков, которые нужно принимать во внимание перед началом миграции:
- Во время живой миграции вы можете заметить некоторое снижение производительности пока контейнер находится в состоянии заморозки. Для некоторых приложений это критический недостаток, так как они не приемлют любое снижение производительности (к примеру, монолитные высоконагруженные онлайн приложения). Однако, кратковременная заморозка не является серьёзным недостатком для большинства приложений в интернете, особенно если говорить о веб-приложениях.
- Другая сложность связана с большим объемом быстро-меняющихся данных, которые не так легко перенести от одного облачного провайдера к другому. Период ожидания и большой объем данных могут препятствовать успешному выполнению живой миграции.
- Публичные IP-адреса в мульти-облаке. Невозможно перенести контейнеры с публичным IP-адресом от одного облачного провайдера к другому, поскольку IP-адрес привязан к конкретному провайдеру.
- Если приложение внутри контейнера использует проприетарный API или проприетарные облачные сервисы конкретного облачного провайдера, выполнить живую миграцию с одного облака на другое может быть очень сложно или даже невозможно.
Живая Миграция на Современном IT-Рынке
Какие компании предлагают живую миграцию контейнеров на сегодняшний день?
- Virtuozzo – эта компания, на самом деле, создала технологию живой миграции контейнеров; они были пионерами в этой области и на сегодняшний момент предлагают движок живой миграции, позволяющий проводить атомарную миграцию контейнера с одного физического хоста на другой.
- runC от Open Containers Initiative является еще одним многообещающим контейнерным решением с поддержкой живой миграции на базе CRIU.
- Jelastic предлагает платформу с оркестрацией контейнеров, которая предоставляет живую миграцию как атомарных контейнеров, так и приложений со сложной топологией развертывания между аппаратными хостами, зонами доступности, центрами обработки данных и облачными провайдерами.
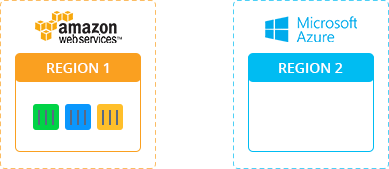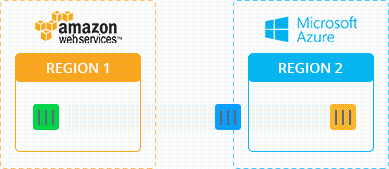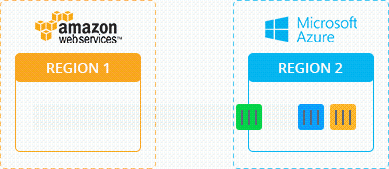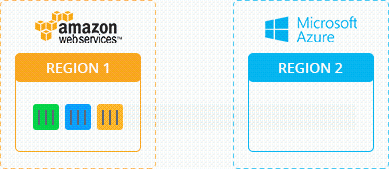
Демо: Миграция Minecraft в Режиме Реального Времени
Для того, чтобы увидеть процесс миграции приложения Minecraft из AWS на Azure в режиме реального времени без простоев, просмотрите следующее видео:
Живая миграция контейнеров все еще является относительно новой технологией на рынке. Тем не менее, преимущества этой технологии для современного бизнеса очевидны — никаких простоев во время обслуживания, не нужно тратить много усилий на подготовку и проверку рабочей среды в другом облаке. Именно поэтому живая миграция является отличным решением для лучшей доступности и гибкости. Поделитесь своим опытом миграции контейнеров между облаками или датацентрами в режиме реального времени.
