В каком случае инкремент элементов вектора std::vector будет быстрее – если они имеют тип uint8_t или uint32_t?
Чтобы не рассуждать отвлечённо, рассмотрим две конкретные реализации:
На этот вопрос легко ответить, используя бенчмарк, и чуть позже мы так и сделаем, но для начала попробуем угадать (это называется «рассуждением на основе базовых принципов» – так звучит более наукообразно).
Во-первых, стоит задать вопрос: Каков размер этих векторов?
Что ж, давайте выберем какое-нибудь число. Пусть будет 20 000 элементов в каждом.
Далее, известно, что тестировать мы будем на процессоре Intel Skylake, – посмотрим характеристики команд сложения для 8-битных и 32-битных операндов при непосредственной адресации. Оказывается, основные показатели у них одинаковые: 1 операция на такт и задержка 4 такта на обращение к памяти (1). В данном случае задержка не имеет значения, поскольку каждая операция сложения выполняется независимо, так что расчётная скорость – 1 элемент на такт при условии, что вся остальная работа по выполнению цикла будет проходить в параллельном режиме.
Можно также заметить, что 20 000 элементов соответствуют набору данных размером 20 Кбайт для версии с uint8_t и целых 80 Кбайт для версии с uint32_t. В первом случае они идеально умещаются в кэш уровня L1 современных компьютеров с архитектурой x86, а во втором – нет. Получается, 8-битная версия получит фору благодаря эффективному кэшированию?
Наконец, отметим, что наша задача очень напоминает классический случай автоматической векторизации: в цикле с известным числом итераций выполняется арифметическая операция над элементами, последовательно расположенными в памяти. В таком случае 8-битная версия должна иметь колоссальное преимущество по сравнению с 32-битной версией, так как одна векторная операция будет обрабатывать вчетверо больше элементов и в целом процессоры Intel выполняют векторные операции над однобайтовыми элементами с той же скоростью, что и над 32-битными элементами.
Ладно, хватит разглагольствовать. Пора обратиться к тесту.
Я получил следующие тайминги для векторов из 20 000 элементов на компиляторах gcc 8 и clang 8 с разными уровнями оптимизации:
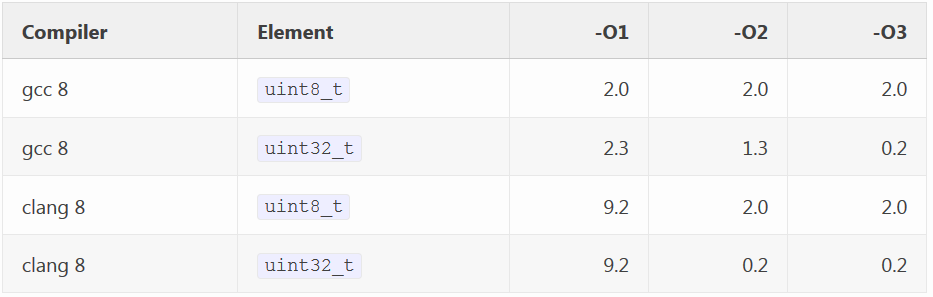
Получается, что, за исключением уровня -O1, вариант с uint32_t быстрее варианта с uint8_t, причём в некоторых случаях значительно: в 5,4 раза на gcc на уровне -O3 и ровно в 8 раз на clang на обоих уровнях, -O2 и -O3. Да-да, инкремент 32-битных целых чисел в std::vector выполняется до восьми раз быстрее, чем инкремент 8-битных целых чисел на популярном компиляторе при стандартных настройках оптимизации.
Как обычно, обратимся к листингу ассемблера в надежде, что он прольёт свет на происходящее.
Вот листинг для gcc 8 на уровне -O2, где 8-битная версия «всего лишь» в 1,5 раза медленнее 32-битной версии (2):
8-bit:
32-bit:
32-битная версия выглядит именно так, как мы и ожидали от неразвёрнутого (3) цикла: инкремент (4) с указанием адреса, затем три команды управления циклом: add rax, 4 – инкремент индуктивной переменной (5) и пара команд cmp и jne для проверки условия выхода из цикла и условного перехода по нему. Выглядит всё здорово – разворачивание компенсировало бы затраты на инкремент счётчика и проверку условия, и наш код почти достиг бы максимально возможной скорости 1 элемент на такт (6), но для приложения с открытым кодом и так сойдёт. А что же в 8-битной версии? Помимо команды inc с указанием адреса выполняются две дополнительные команды чтения из памяти, а также команда sub, взявшаяся непонятно откуда.
Вот листинг с комментариями:
8-bit:
Здесь vector::begin и vector::end – это внутренние указатели std::vector, которые он использует для указания на начало и конец последовательности элементов, содержащихся внутри выделенной для него области (7), – это, по сути, те же значения, которые используются для реализации vector::begin() и vector::end() (хотя они и имеют другой тип). Выходит, все дополнительные команды – лишь следствие вычисления vector.size(). Вроде ничего необычного? Но ведь в 32-битной версии, разумеется, тоже вычисляется size(), однако в том листинге этих команд не было. Вычисление size() произошло только один раз – за пределами цикла.
Так в чём же дело? Краткий ответ – алиасинг указателей. Развёрнутый ответ я дам ниже.
Вектор v передаётся функции по ссылке, которая, по сути, есть замаскированный указатель. Компилятор должен обратиться к членам v::begin и v::end вектора, чтобы вычислить его размер size(), а в нашем примере size() вычисляется на каждой итерации. Но компилятор не обязан слепо подчиняться исходному коду: он вполне может вынести результат вызова функции size() за пределы цикла, но только если точно знает, что семантика программы от этого не изменится. С этой точки зрения единственным проблемным местом цикла является инкремент v[i]++. Запись происходит по неизвестному адресу. Может ли такая операция изменить значение size()?
Если запись происходит в std::vector<uint32_t> (т.е. по указателю uint32_t *), то нет, она не может изменить значение size(). Запись в объекты типа uint32_t может модифицировать только объекты типа uint32_t, а указатели, задействованные при вычислении size(), имеют другой тип (8).
Однако в случае с uint8_t, по крайней мере на распространённых компиляторах (9), ответ будет таким: да, теоретически значение size() может измениться, так как uint8_t – это псевдоним для unsigned char, а массивы типа unsigned char (и char) могут алиаситься с любым другим типом. Это значит, что, по мнению компилятора, запись по указателям на uint8_t способна модифицировать содержимое памяти неизвестного происхождения по любому адресу (10). Поэтому он предполагает, что каждая операция инкремента v[i]++ может изменить значение size(), и потому вынужден вычислять его заново на каждой итерации цикла.
Мы-то с вами знаем, что запись в память, на которую указывает std::vector, никогда не изменит его собственный size(), ведь это означало бы, что вектор сам каким-то образом был выделен внутри собственной кучи, а это практически невозможно и сродни проблеме курицы и яйца (11). Но компилятору это, к сожалению, неведомо!
Хорошо, мы выяснили, почему версия с uint8_ немного медленнее версии uint32_t на gcc на уровне -O2. Но чем объяснить громадную разницу – до 8 раз – на clang или том же gcc на -O3?
Тут всё просто: в случае с uint32_t clang может выполнить автовекторизацию цикла:
Цикл был развёрнут 8 раз, и это в общем-то максимальная производительность, какую только можно получить: один вектор (8 элементов) на такт для кэша L1 (больше не получится из-за ограничения в одну операцию записи на такт (12)).
Для uint8_t векторизация не производится, потому что ей препятствует необходимость вычислять size() для проверки условия цикла на каждой итерации. Причина отставания всё та же, а само отставание гораздо больше.
Самые низкие тайминги объясняются автовекторизацией: gcc применяет её только на уровне -O3, а clang – и на уровне -O2, и на уровне -O3 по умолчанию. Компилятор gcc на уровне -O3 генерирует несколько более медленный код, чем clang, потому что он не разворачивает автовекторизованный цикл.
Мы выяснили, в чём проблема – как же её исправить?
Для начала попробуем один способ, который, правда, не будет работать, – а именно, напишем более идиоматический цикл, основанный на итераторе:
Код, который сгенерирует gcc на уровне -O2, будет несколько лучше варианта с size():
Две лишние операции чтения превратились в одну, так как i мы теперь сравниваем с указателем end вектора, а не вычисляем заново size(), вычитая из указателя конца указатель начала вектора. По количеству команд этот код догнал код с uint32_t, поскольку дополнительная операция чтения слилась с операцией сравнения. Однако проблема никуда не делась и автовекторизация по-прежнему недоступна, так что uint8_t всё ещё значительно отстаёт от uint32_t – более чем в 5 раз как на gcc, так и на clang на тех уровнях, где предусмотрена автовекторизация.
Попробуем что-нибудь другое. У нас снова ничего не получится, а точнее, мы найдём ещё один неработающий способ.
В этом варианте мы вычисляем size() только один раз до цикла и помещаем результат в локальную переменную:
Вроде бы должно сработать? Проблема была в size(), а теперь мы велели компилятору зафиксировать результат size() в локальной переменной s в начале цикла, а локальные переменные, как известно, не пересекаются с другими данными. Мы фактически сделали то, чего не мог сделать компилятор. И код, который он сгенерирует, действительно будет лучше (по сравнению с первоначальным):
Здесь только одна лишняя операция чтения и нет команды sub. Но что делает эта лишняя команда (rdx, QWORD PTR [rdi]), если она не участвует в вычислении размера? Она считывает указатель data() из v!
Выражение v[i] реализуется как *(v.data() + i), а член, возвращаемый data() (и являющийся, по сути, обычным указателем begin), порождает ту же проблему, что и size(). Правда, я эту операцию не заметил в исходном варианте, потому что там она была «бесплатной», ведь её все равно нужно было выполнить, чтобы вычислить размер.
Потерпите ещё чуть-чуть, мы почти нашли решение. Нужно просто убрать из нашего цикла все зависимости от содержимого std::vector. Проще всего это сделать, если немного модифицировать нашу идиому с итератором:
Теперь всё круто изменилось (здесь мы сравниваем только версии с uint8_t – в одной мы сохраняем итератор end в локальной переменнойперед циклом, в другой – нет):

Это небольшое изменение дало нам 20-кратный прирост скорости на уровнях с автовекторизацией. Причём код с uint8_t не просто догнал код с uint32_t – он обогнал его почти ровно в 4 раза на gcc -O3 и clang -O2 и -O3, как мы и ожидали в самом начале, полагаясь на векторизацию: в конце концов, именно вчетверо больше элементов может быть обработано векторной операцией и вчетверо меньшая пропускная способность нам требуется – независимо от уровня кэша (13).
Если вы дочитали до этого места, то, должно быть, всё это время восклицали про себя:
А как же for-цикл с обходом диапазона, появившийся в C++11?
Спешу вас обрадовать: он работает! Это, по сути, синтаксический сахар, за которым скрывается почти в том же виде наша версия с итератором, где мы фиксировали указатель end в локальной переменной до начала цикла. Так что быстродействие у него то же.
Если бы нам вдруг вздумалось вернуться в древние, пещерные времена и написать C-подобную функцию, то такой код тоже замечательно сработал бы:
Здесь указатель на массив a и переменная size передаются в функцию по значению, поэтому они не могут быть изменены в результате записи по указателю a (14) – совсем как локальные переменные. Производительность у этого кода такая же, как у предыдущих вариантов.
Наконец, на тех компиляторах, где эта опция доступна, вы можете объявить вектор с __restrict (15):
Ключевое слово __restrict не входит в стандарт C++, но входит в стандарт C начиная с C99 (как restrict). Если в компиляторе оно реализовано как расширение C++, то, скорее всего, оно будет подчиняться семантике C. Разумеется, в C нет ссылок, поэтому можете мысленно заменить ссылку на вектор указателем на вектор.
Обратите внимание, что restrict не обладает транзитивным свойством: действие спецификатора __restrict, с которым объявлена ссылка на std::vector, распространяется только на члены самого вектора, но не на область кучи, на которую ссылается v.data(). В нашем случае большего не требуется, потому что (как в случае с локальными переменными) достаточно лишь убедить компилятор, что сами по себе члены, указывающие на начало и конец вектора, ни с чем не пересекаются. Оговорка по поводу restrict, однако, всё равно актуальна, так как запись через v.data() может по-прежнему привести к изменению других объектов в вашей функции из-за алиасинга.
Тут мы приходим к последнему – и весьма неутешительному – выводу. Дело в том, что все показанные выше решения применимы только к этому конкретному случаю, когда вектор теоретически может помешать сам себе. Решение заключалось в том, чтобы вынести за пределы цикла или изолировать результат вызова size() или end() вектора, а не в том, чтобы втолковать компилятору, что запись в данные вектора не затрагивает другие данные. Такой код будет сложно масштабировать по мере роста функции.
Проблема алиасинга никуда не делась, и команды записи по-прежнему могут попасть «куда угодно» – просто в этой функции нет других данных, которые могут быть затронуты… пока. Как только в ней появится новый код, всё повторится. Вот пример навскидку. Если в малых циклах у вас происходит запись в массивы из элементов типа uint8_t, придётся воевать с компилятором до конца (16).
Буду рад любым отзывам. У меня пока ещё нет системы комментирования (17), поэтому, как обычно, обсуждение будем вести в этом треде на HackerNews.
Перевод статьи публикуется с разрешения автора. Оригинальная публикация: Travis Downs. Incrementing vectors.
Чтобы не рассуждать отвлечённо, рассмотрим две конкретные реализации:
void vector8_inc(std::vector<uint8_t>& v)
{
for (size_t i = 0; i < v.size(); i++)
{
v[i]++;
}
}
void vector32_inc(std::vector<uint32_t>& v)
{
for (size_t i = 0; i < v.size(); i++)
{
v[i]++;
}
}Попробуем угадать
На этот вопрос легко ответить, используя бенчмарк, и чуть позже мы так и сделаем, но для начала попробуем угадать (это называется «рассуждением на основе базовых принципов» – так звучит более наукообразно).
Во-первых, стоит задать вопрос: Каков размер этих векторов?
Что ж, давайте выберем какое-нибудь число. Пусть будет 20 000 элементов в каждом.
Далее, известно, что тестировать мы будем на процессоре Intel Skylake, – посмотрим характеристики команд сложения для 8-битных и 32-битных операндов при непосредственной адресации. Оказывается, основные показатели у них одинаковые: 1 операция на такт и задержка 4 такта на обращение к памяти (1). В данном случае задержка не имеет значения, поскольку каждая операция сложения выполняется независимо, так что расчётная скорость – 1 элемент на такт при условии, что вся остальная работа по выполнению цикла будет проходить в параллельном режиме.
Можно также заметить, что 20 000 элементов соответствуют набору данных размером 20 Кбайт для версии с uint8_t и целых 80 Кбайт для версии с uint32_t. В первом случае они идеально умещаются в кэш уровня L1 современных компьютеров с архитектурой x86, а во втором – нет. Получается, 8-битная версия получит фору благодаря эффективному кэшированию?
Наконец, отметим, что наша задача очень напоминает классический случай автоматической векторизации: в цикле с известным числом итераций выполняется арифметическая операция над элементами, последовательно расположенными в памяти. В таком случае 8-битная версия должна иметь колоссальное преимущество по сравнению с 32-битной версией, так как одна векторная операция будет обрабатывать вчетверо больше элементов и в целом процессоры Intel выполняют векторные операции над однобайтовыми элементами с той же скоростью, что и над 32-битными элементами.
Ладно, хватит разглагольствовать. Пора обратиться к тесту.
Бенчмарк
Я получил следующие тайминги для векторов из 20 000 элементов на компиляторах gcc 8 и clang 8 с разными уровнями оптимизации:
Получается, что, за исключением уровня -O1, вариант с uint32_t быстрее варианта с uint8_t, причём в некоторых случаях значительно: в 5,4 раза на gcc на уровне -O3 и ровно в 8 раз на clang на обоих уровнях, -O2 и -O3. Да-да, инкремент 32-битных целых чисел в std::vector выполняется до восьми раз быстрее, чем инкремент 8-битных целых чисел на популярном компиляторе при стандартных настройках оптимизации.
Как обычно, обратимся к листингу ассемблера в надежде, что он прольёт свет на происходящее.
Вот листинг для gcc 8 на уровне -O2, где 8-битная версия «всего лишь» в 1,5 раза медленнее 32-битной версии (2):
8-bit:
.L3:
inc BYTE PTR [rdx+rax]
mov rdx, QWORD PTR [rdi]
inc rax
mov rcx, QWORD PTR [rdi+8]
sub rcx, rdx
cmp rax, rcx
jb .L332-bit:
.L9:
inc DWORD PTR [rax]
add rax, 4
cmp rax, rdx
jne .L932-битная версия выглядит именно так, как мы и ожидали от неразвёрнутого (3) цикла: инкремент (4) с указанием адреса, затем три команды управления циклом: add rax, 4 – инкремент индуктивной переменной (5) и пара команд cmp и jne для проверки условия выхода из цикла и условного перехода по нему. Выглядит всё здорово – разворачивание компенсировало бы затраты на инкремент счётчика и проверку условия, и наш код почти достиг бы максимально возможной скорости 1 элемент на такт (6), но для приложения с открытым кодом и так сойдёт. А что же в 8-битной версии? Помимо команды inc с указанием адреса выполняются две дополнительные команды чтения из памяти, а также команда sub, взявшаяся непонятно откуда.
Вот листинг с комментариями:
8-bit:
.L3:
inc BYTE PTR [rdx+rax] ; инкремент по адресу v[i]
mov rdx, QWORD PTR [rdi] ; загрузка v.begin
inc rax ; i++
mov rcx, QWORD PTR [rdi+8] ; загрузка v.end
sub rcx, rdx ; end - start (т.е. vector.size())
cmp rax, rcx ; i < size()
jb .L3 ; след. итерация если i < size()Здесь vector::begin и vector::end – это внутренние указатели std::vector, которые он использует для указания на начало и конец последовательности элементов, содержащихся внутри выделенной для него области (7), – это, по сути, те же значения, которые используются для реализации vector::begin() и vector::end() (хотя они и имеют другой тип). Выходит, все дополнительные команды – лишь следствие вычисления vector.size(). Вроде ничего необычного? Но ведь в 32-битной версии, разумеется, тоже вычисляется size(), однако в том листинге этих команд не было. Вычисление size() произошло только один раз – за пределами цикла.
Так в чём же дело? Краткий ответ – алиасинг указателей. Развёрнутый ответ я дам ниже.
Развёрнутый ответ
Вектор v передаётся функции по ссылке, которая, по сути, есть замаскированный указатель. Компилятор должен обратиться к членам v::begin и v::end вектора, чтобы вычислить его размер size(), а в нашем примере size() вычисляется на каждой итерации. Но компилятор не обязан слепо подчиняться исходному коду: он вполне может вынести результат вызова функции size() за пределы цикла, но только если точно знает, что семантика программы от этого не изменится. С этой точки зрения единственным проблемным местом цикла является инкремент v[i]++. Запись происходит по неизвестному адресу. Может ли такая операция изменить значение size()?
Если запись происходит в std::vector<uint32_t> (т.е. по указателю uint32_t *), то нет, она не может изменить значение size(). Запись в объекты типа uint32_t может модифицировать только объекты типа uint32_t, а указатели, задействованные при вычислении size(), имеют другой тип (8).
Однако в случае с uint8_t, по крайней мере на распространённых компиляторах (9), ответ будет таким: да, теоретически значение size() может измениться, так как uint8_t – это псевдоним для unsigned char, а массивы типа unsigned char (и char) могут алиаситься с любым другим типом. Это значит, что, по мнению компилятора, запись по указателям на uint8_t способна модифицировать содержимое памяти неизвестного происхождения по любому адресу (10). Поэтому он предполагает, что каждая операция инкремента v[i]++ может изменить значение size(), и потому вынужден вычислять его заново на каждой итерации цикла.
Мы-то с вами знаем, что запись в память, на которую указывает std::vector, никогда не изменит его собственный size(), ведь это означало бы, что вектор сам каким-то образом был выделен внутри собственной кучи, а это практически невозможно и сродни проблеме курицы и яйца (11). Но компилятору это, к сожалению, неведомо!
Что насчёт остальных результатов?
Хорошо, мы выяснили, почему версия с uint8_ немного медленнее версии uint32_t на gcc на уровне -O2. Но чем объяснить громадную разницу – до 8 раз – на clang или том же gcc на -O3?
Тут всё просто: в случае с uint32_t clang может выполнить автовекторизацию цикла:
.LBB1_6: ; =>This Inner Loop Header: Depth=1
vmovdqu ymm1, ymmword ptr [rax + 4*rdi]
vmovdqu ymm2, ymmword ptr [rax + 4*rdi + 32]
vmovdqu ymm3, ymmword ptr [rax + 4*rdi + 64]
vmovdqu ymm4, ymmword ptr [rax + 4*rdi + 96]
vpsubd ymm1, ymm1, ymm0
vpsubd ymm2, ymm2, ymm0
vpsubd ymm3, ymm3, ymm0
vpsubd ymm4, ymm4, ymm0
vmovdqu ymmword ptr [rax + 4*rdi], ymm1
vmovdqu ymmword ptr [rax + 4*rdi + 32], ymm2
vmovdqu ymmword ptr [rax + 4*rdi + 64], ymm3
vmovdqu ymmword ptr [rax + 4*rdi + 96], ymm4
vmovdqu ymm1, ymmword ptr [rax + 4*rdi + 128]
vmovdqu ymm2, ymmword ptr [rax + 4*rdi + 160]
vmovdqu ymm3, ymmword ptr [rax + 4*rdi + 192]
vmovdqu ymm4, ymmword ptr [rax + 4*rdi + 224]
vpsubd ymm1, ymm1, ymm0
vpsubd ymm2, ymm2, ymm0
vpsubd ymm3, ymm3, ymm0
vpsubd ymm4, ymm4, ymm0
vmovdqu ymmword ptr [rax + 4*rdi + 128], ymm1
vmovdqu ymmword ptr [rax + 4*rdi + 160], ymm2
vmovdqu ymmword ptr [rax + 4*rdi + 192], ymm3
vmovdqu ymmword ptr [rax + 4*rdi + 224], ymm4
add rdi, 64
add rsi, 2
jne .LBB1_6Цикл был развёрнут 8 раз, и это в общем-то максимальная производительность, какую только можно получить: один вектор (8 элементов) на такт для кэша L1 (больше не получится из-за ограничения в одну операцию записи на такт (12)).
Для uint8_t векторизация не производится, потому что ей препятствует необходимость вычислять size() для проверки условия цикла на каждой итерации. Причина отставания всё та же, а само отставание гораздо больше.
Самые низкие тайминги объясняются автовекторизацией: gcc применяет её только на уровне -O3, а clang – и на уровне -O2, и на уровне -O3 по умолчанию. Компилятор gcc на уровне -O3 генерирует несколько более медленный код, чем clang, потому что он не разворачивает автовекторизованный цикл.
Исправляем ситуацию
Мы выяснили, в чём проблема – как же её исправить?
Для начала попробуем один способ, который, правда, не будет работать, – а именно, напишем более идиоматический цикл, основанный на итераторе:
for (auto i = v.begin(); i != v.end(); ++i)
{
(*i)++;
}Код, который сгенерирует gcc на уровне -O2, будет несколько лучше варианта с size():
.L17:
add BYTE PTR [rax], 1
add rax, 1
cmp QWORD PTR [rdi+8], rax
jne .L17Две лишние операции чтения превратились в одну, так как i мы теперь сравниваем с указателем end вектора, а не вычисляем заново size(), вычитая из указателя конца указатель начала вектора. По количеству команд этот код догнал код с uint32_t, поскольку дополнительная операция чтения слилась с операцией сравнения. Однако проблема никуда не делась и автовекторизация по-прежнему недоступна, так что uint8_t всё ещё значительно отстаёт от uint32_t – более чем в 5 раз как на gcc, так и на clang на тех уровнях, где предусмотрена автовекторизация.
Попробуем что-нибудь другое. У нас снова ничего не получится, а точнее, мы найдём ещё один неработающий способ.
В этом варианте мы вычисляем size() только один раз до цикла и помещаем результат в локальную переменную:
for (size_t i = 0, s = v.size(); i < s; i++)
{
v[i]++;
}Вроде бы должно сработать? Проблема была в size(), а теперь мы велели компилятору зафиксировать результат size() в локальной переменной s в начале цикла, а локальные переменные, как известно, не пересекаются с другими данными. Мы фактически сделали то, чего не мог сделать компилятор. И код, который он сгенерирует, действительно будет лучше (по сравнению с первоначальным):
.L9:
mov rdx, QWORD PTR [rdi]
add BYTE PTR [rdx+rax], 1
add rax, 1
cmp rax, rcx
jne .L9Здесь только одна лишняя операция чтения и нет команды sub. Но что делает эта лишняя команда (rdx, QWORD PTR [rdi]), если она не участвует в вычислении размера? Она считывает указатель data() из v!
Выражение v[i] реализуется как *(v.data() + i), а член, возвращаемый data() (и являющийся, по сути, обычным указателем begin), порождает ту же проблему, что и size(). Правда, я эту операцию не заметил в исходном варианте, потому что там она была «бесплатной», ведь её все равно нужно было выполнить, чтобы вычислить размер.
Потерпите ещё чуть-чуть, мы почти нашли решение. Нужно просто убрать из нашего цикла все зависимости от содержимого std::vector. Проще всего это сделать, если немного модифицировать нашу идиому с итератором:
for (auto i = v.begin(), e = v.end(); i != e; ++i)
{
(*i)++;
}Теперь всё круто изменилось (здесь мы сравниваем только версии с uint8_t – в одной мы сохраняем итератор end в локальной переменнойперед циклом, в другой – нет):
Это небольшое изменение дало нам 20-кратный прирост скорости на уровнях с автовекторизацией. Причём код с uint8_t не просто догнал код с uint32_t – он обогнал его почти ровно в 4 раза на gcc -O3 и clang -O2 и -O3, как мы и ожидали в самом начале, полагаясь на векторизацию: в конце концов, именно вчетверо больше элементов может быть обработано векторной операцией и вчетверо меньшая пропускная способность нам требуется – независимо от уровня кэша (13).
Если вы дочитали до этого места, то, должно быть, всё это время восклицали про себя:
А как же for-цикл с обходом диапазона, появившийся в C++11?
Спешу вас обрадовать: он работает! Это, по сути, синтаксический сахар, за которым скрывается почти в том же виде наша версия с итератором, где мы фиксировали указатель end в локальной переменной до начала цикла. Так что быстродействие у него то же.
Если бы нам вдруг вздумалось вернуться в древние, пещерные времена и написать C-подобную функцию, то такой код тоже замечательно сработал бы:
void array_inc(uint8_t* a, size_t size)
{
for (size_t i = 0; i < size; i++)
{
a[i]++;
}
}Здесь указатель на массив a и переменная size передаются в функцию по значению, поэтому они не могут быть изменены в результате записи по указателю a (14) – совсем как локальные переменные. Производительность у этого кода такая же, как у предыдущих вариантов.
Наконец, на тех компиляторах, где эта опция доступна, вы можете объявить вектор с __restrict (15):
void vector8_inc_restrict(std::vector<uint8_t>& __restrict v)
{
for (size_t i = 0; i < v.size(); i++)
{
v[i]++;
}
}Ключевое слово __restrict не входит в стандарт C++, но входит в стандарт C начиная с C99 (как restrict). Если в компиляторе оно реализовано как расширение C++, то, скорее всего, оно будет подчиняться семантике C. Разумеется, в C нет ссылок, поэтому можете мысленно заменить ссылку на вектор указателем на вектор.
Обратите внимание, что restrict не обладает транзитивным свойством: действие спецификатора __restrict, с которым объявлена ссылка на std::vector, распространяется только на члены самого вектора, но не на область кучи, на которую ссылается v.data(). В нашем случае большего не требуется, потому что (как в случае с локальными переменными) достаточно лишь убедить компилятор, что сами по себе члены, указывающие на начало и конец вектора, ни с чем не пересекаются. Оговорка по поводу restrict, однако, всё равно актуальна, так как запись через v.data() может по-прежнему привести к изменению других объектов в вашей функции из-за алиасинга.
Разочарование
Тут мы приходим к последнему – и весьма неутешительному – выводу. Дело в том, что все показанные выше решения применимы только к этому конкретному случаю, когда вектор теоретически может помешать сам себе. Решение заключалось в том, чтобы вынести за пределы цикла или изолировать результат вызова size() или end() вектора, а не в том, чтобы втолковать компилятору, что запись в данные вектора не затрагивает другие данные. Такой код будет сложно масштабировать по мере роста функции.
Проблема алиасинга никуда не делась, и команды записи по-прежнему могут попасть «куда угодно» – просто в этой функции нет других данных, которые могут быть затронуты… пока. Как только в ней появится новый код, всё повторится. Вот пример навскидку. Если в малых циклах у вас происходит запись в массивы из элементов типа uint8_t, придётся воевать с компилятором до конца (16).
Комментарии
Буду рад любым отзывам. У меня пока ещё нет системы комментирования (17), поэтому, как обычно, обсуждение будем вести в этом треде на HackerNews.
- Под обращением к памяти здесь подразумевается, что цепочка зависимостей проходит через память: команды записи по одному и тому же адресу должны считать последнее записанное туда значение, поэтому такие операции являются зависимыми (на практике будет использоваться перенаправление для загрузки (STLF), если запись происходит достаточно часто). Зависимости команды add при обращении к памяти могут проявляться и другими способами, например, через вычисление адреса, но для нашего случая это неактуально.
- Здесь показан только малый цикл; код установки прост, и работает он быстро. Чтобы увидеть листинг целиком, загрузите код в godbolt.
- Может быть, его следует назвать просто «свёрнутым»? Как бы то ни было, компилятор gcc обычно не разворачивает циклы даже на уровнях -O2 и -O3 за исключением особых случаев, когда число итераций невелико и известно на этапе компиляции. Из-за этого gcc показывает более низкие результаты в тестах по сравнению с clang, но зато он существенно экономит на размере кода. Заставить gcc разворачивать циклы можно, применяя профильную оптимизацию или включив флаг -funroll-loops.
- На самом деле команда inc DWORD PTR [rax] в gcc – это упущенная оптимизация: почти всегда лучше использовать команду add [rax], 1, так как она состоит всего лишь из 2 объединённых микроопераций против 3 для inc. В данном случае разница составляет всего лишь около 6%, но, если бы цикл был немного развёрнут – так, чтобы повторялась только операция записи, –разница оказалась бы существеннее (дальнейшее разворачивание уже не играло бы роли, так как мы достигли бы предела в 1 операцию записи на такт, который не зависит от общего числа микроопераций).
- Эту переменную я называю индуктивной, а не просто i, как в исходном коде, потому что компилятор преобразовал единичные операции инкремента i в 4-байтовые инкременты указателя, хранящегося в регистре rax, и соответственно с этим подправил условие цикла. В исходном виде наш цикл адресует элементы вектора, а после этого преобразования он инкрементирует указатель/итератор, что является одним из способов снижения стоимости операций.
- На самом деле, если включить -funroll-loops, на gcc скорость составит 1,08 такта на элемент при 8-кратном разворачивании. Но даже с этим флагом он не будет разворачивать цикл для версии с 8-битными элементами, так что отставание в скорости будет ещё заметнее!
- Эти члены имеют модификатор private, и имена их зависят от реализации, но в stdlibc++ они на самом деле не называются start и finish, как в gcc. Они называются соответственно _Vector_base::_Vector_impl::_M_start и _Vector_base::_Vector_impl::_M_finish, т.е. входят в структуру _Vector_impl, которая является членом _M_impl (причём единственным) класса _Vector_base, а тот, в свою очередь, является базовым классом для std::vector. Ну и ну! К счастью, компилятор легко справляется с этим нагромождением абстракций.
- Стандарт не предписывает, какими должны быть внутренние типы членов std::vector, но в библиотеке libstdc++ они определены просто как Alloc::pointer (где Alloc – это аллокатор для вектора), и для выделенного по умолчанию объекта std::allocated они будут просто указателями типа T*, т.е. обычными указателями на объект – в данном случае uint32_t *.
- Эту оговорку я делаю не просто так. Есть подозрение, что uint8_t может расцениваться как тип, отличный от char, signed char и unsigned char. Поскольку алиасинг работает с символьными типами, это по идее не относится к uint8_t и он должен вести себя как любой другой несимвольный тип. Однако ни один из известных мне компиляторов так не считает: в них всех typedef uint8_t является псевдонимом unsigned char, так что компиляторы не видят между ними разницы, даже если бы они хотели ею воспользоваться.
- Под «неизвестным происхождением» я здесь подразумеваю лишь то, что компилятор не знает, куда указывает содержимое памяти или как оно появилось. Сюда относятся произвольные указатели, переданные в функцию, а также глобальные и статические переменные. Локальные переменные, напротив, хранятся по известным адресам и не пересекаются с другими данными в памяти, поэтому проблемы, связанные с алиасингом, их обычно не затрагивают (разве что локальная переменная каким-то образом покинет свою область видимости). Указатели, созданные с помощью вызовов malloc или new, которые компилятор видит в момент их использования, во многом ведут себя так же, как локальные переменные, по крайней мере с точки зрения некоторых компиляторов: они знают, что такие вызовы выделяют участки памяти, которые больше ни с чем не пересекаются. Впрочем, компиляторы обычно не видят исходный вызов malloc или new.
- Может быть, в случае std::vector это всё-таки возможно? Скажем, мы создали вектор std::vector<uint8_t> a подходящего размера и затем внутри массива a.data() с помощью оператора placement new разместили с соответствующим выравниванием новый вектор b. Теперь вызовем std::swap(a, b), чтобы поменять местами области хранения векторов – получается, вектор b будет находится внутри собственного участка памяти? Вместо перестановки можно напрямую вызвать конструктор перемещения, когда будем размещать вектор b. Практической ценности такой вектор не будет иметь: он сломается при первой же попытке произвести с ним какое-нибудь действие (например, расширить его за счёт добавления нового элемента), что приведёт к очищению выделенной памяти, а значит и к уничтожению самого вектора.
- За один такт можно нормально выровнять только 8 элементов, т.е. на 32 позиции. В данном тесте мне повезло, и объекты std::vector были выравнены именно так по умолчанию.
- Вообще-то можно получить прирост и более чем в 4 раза: это возможно в том случае, если меньший элемент умещается в кэш нижнего уровня, а больший – нет. Именно это и наблюдается в нашем примере: 8-битные элементы вектора умещаются в кэш L1, а 32-битные длиннее его более чем в два раза – зато кэш L2 явно обладает достаточной ёмкостью, поэтому дополнительного прироста скорости не происходит.
- Хотя вектор теоретически может размещаться внутри собственной кучи, указатель – не может: запись по указателю не может изменить сам указатель. У вектора есть дополнительный уровень косвенности, что и делает возможным такой эффект, как в фильме «Начало».
- Цикл в этом примере основан на индексации v[i], но данное решение также работает и с циклом на основе итератора.
- Есть и более радикальные решения. Например, можно создать «непрозрачный» псевдоним, который фактически является просто структурой и служит обёрткой для uint8_t. В сочетании с перегрузкой операторов и, возможно, неявными приведениями типов он будет вести себя, как uint8_t, будучи при этом совсем другим типом с точки зрения компилятора. Примечательно, что это решение прекрасно работает в clang, но совсем не работает в gcc, где даёт тот же код, что и обычный uint8_t. Где-то в недрах своего оптимизатора gcc воспринимает этот тип как символьный вместе со всеми вытекающими проблемами, связанными с алиасингом. Другое решение заключается в том, чтобы завести собственный вектороподобный тип, члены-указатели которого будут объявлены как __restrict.
- Если кто-нибудь может подсказать, где найти быструю и бесплатную систему комментирования, которая работает со статическими сайтами (только не предлагайте Disqus), не имеет рекламы и предоставляет пользователю доступ к данным комментариев (или хотя бы позволяет экспортировать их в нормальном формате), я готов вас выслушать.
Перевод статьи публикуется с разрешения автора. Оригинальная публикация: Travis Downs. Incrementing vectors.
