
Perhaps every microcontroller software developer has heard about special coding standards to help improve the code security and portability. One of such standards is MISRA. In this article, we'll take a closer look at what this standard is, its concept and how to use it in your projects.
Many of our readers have heard that PVS-Studio supports the classification of its warnings according to the MISRA standard. At the moment, PVS-Studio covers more than 100 MISRA C rules: 2012 and MISRA C++: 2008.
This article aims to kill three birds with one stone:
- Tell what MISRA is for those who aren't yet familiar with this standard;
- Remind the world of embedded development what we can do;
- Help new employees of our company, who will also develop our MISRA analyzer in future, to become fully acquainted with it.
I hope I can make it interesting. So let's get going!
The History of MISRA
The history of MISRA began a long time ago. Back then in early 1990s, the «Safe IT» UK government program provided funding for various projects somehow related to security of electronic systems. The MISRA (Motor Industry Software Reliability Association) project itself was founded to create a guide for developing software of microcontrollers in ground vehicles — in cars, mostly.
Having received funding from the state, the MISRA team took up the work, and by November 1994 released their first guide: "Development guidelines for vehicle based software". This guide hasn't been tied to a specific language yet, but I must admit that the work has been done impressively and it has concerned, probably, all conceivable aspects of embedded software development. By the way, recently the developers of this guide have celebrated the 25th anniversary of such an important date for them.
When the funding from the state was over, the MISRA members decided to continue working together on an informal basis, as it continues to this day. Generally speaking, MISRA (as an organization) is a community of stakeholders from various auto and aircraft industries. Now these parties are:
- Bentley Motor Cars
- Ford Motor Company
- Jaguar Land Rover
- Delphi Diesel Systems
- HORIBA MIRA
- Protean Electric
- Visteon Engineering Services
- The University of Leeds
- Ricardo UK
- ZF TRW
Very strong market players, aren't they? Not surprisingly, their first language-related standard, MISRA C, has become commonplace among developers of critical embedded systems. A little later, MISRA C++ appeared. Gradually, versions of the standards have been updated and refined to cover the new features of languages. As of this writing, the current versions are MISRA C: 2012 and MISRA C++: 2008.
Main concept and examples of rules
MISRA's most distinctive features are its incredible attention to details and extreme meticulousness in ensuring safety and security. Not only did the authors collect all C and C++ deficiencies in one place (as for example, the authors of CERT) — they also carefully worked out the international standards of these languages and wrote out any and all ways to make a mistake. After, they added rules on code readability to insure the clean code against a new error.
To understand the scale of seriousness, let's look at a few rules taken from the standard.
On the one hand, there are decent, worthwhile rules that must always be followed, no matter what your project is for. For the most part, they are designed to eliminate undefined/unspecified/implementation-defined behavior. For example:
- Don't use the value of an uninitialized variable
- Don't use the pointer to FILE after the stream closes
- All non-void functions should return a value
- Loop counters mustn't be of the floating-point type
- and others.
On the other hand, there are rules, the benefits of which aren't hard to plumb, but which (from the point of view of ordinary projects) can be occasionally violated:
- Don't use goto and longjmp
- Every switch should end with default label
- Don't write unreachable code
- Don't use variadic functions
- Don't use address arithmetic (except [] and ++)
- ...
Such rules are not bad either, and combined with the previous ones, they already give a tangible increase to security, but is this enough for highly dependable embedded systems? They are used not only in the automotive industry, but also in aviation, aerospace, military and medicine industries.
We don't want any X-ray machine to irradiate patients with a dose of 20,000 rads because of a software error, so the usual «everyday» rules are not enough. With human lives and big money on the line, meticulousness is indispensable. Here's where the rest of MISRA rules come into play:
- The suffix 'L' in the literal must always be capital (the lower case letter 'l' can be confused with 1)
- Don't use the «comma» operator (it increases the chance of making a mistake)
- Don't use recursion (a small microcontroller stack can easily overflow)
- The bodies of the statements if, else, for, while, do, switch have to be wrapped in curly brackets (potentially you can make a mistake when the code is aligned incorrectly)
- Don't use dynamic memory (because there's a chance of not releasing it from the heap, especially in microcontrollers)
- … and many, many of these rules.
It often so happens, that people who first encounter MISRA get the impression that the standard's purpose is to «ban this and ban that». In fact, it is so, but only to some extent.
On the one hand, the standard does have many such rules, but it's not meant to ban all out, but on the other hand, it lists the whole schmeer of ways to somehow violate the code security. For most rules, you choose yourself whether you need to follow them or not. I'll explain this case in more detail.
In MISRA C, rules are divided into three main categories: Mandatory, Required and Advisory. Mandatory are rules that cannot be broken under any pretext. For example, this section includes the rule: «don't use the value of an uninitiated variable». Required rules are less stringent: they allow for the possibility of rejection, but only if these deviations are carefully documented and substantiated in writing. The rest of the rules fall into the Advisory category, which are non-obligatory.
MISRA C++ has some differences: there is no Mandatory category, and most of the rules belong to the Required category. Therefore, in fact, you have the right to break any rule — just don't forget to comment all the deviations. There is also the Document category — these are mandatory rules (deviations aren't allowed) related to general practices such as «Each use of the assembler must be documented» or «An included library must comply with MISRA C++».
Other issues
In fact, MISRA is not just about a set of rules. In fact, it's a guideline for writing safe code for microcontrollers, and so it's full of goodies. Let's take an in-depth look at them.
First of all, the standard contains a fairly thorough description of the backstory: why the standard was created, why C or C++ was chosen, pros and cons of these languages.
We all know the merits of these languages very well. As well as we are also aware of their shortcomings :) High level of complexity, incomplete standard specification, and syntax allowing to easily make a mistake and then search for it for ages — all this can't but be mentioned. For example, you might accidentally write this:
for (int i = 0; i < n; ++i);
{
do_something();
}After all, there is a chance that a person won't notice an extra semicolon, right? Another option is to write code as follows:
void SpendTime(bool doWantToKillPeople)
{
if (doWantToKillPeople = true)
{
StartNuclearWar();
}
else
{
PlayComputerGames();
}
}It's good that both the first and second cases can be easily caught by the rules MISRA (1 — MISRA C: 13.4/MISRA C++: 6.2.1.; 2 — MISRA C: 13.4/MISRA C++: 6.2.1).
The standard contains both description of problem issues and tips on what one has to know before taking on a certain task: how to set up the development process according to MISRA; how to use static analyzers for checking the code for compliance; what documents one has to maintain, how to fill them out and so on.
The appendices at the end also includes: a short list and a summary of the rules, a small list of C/C++ vulnerabilities, an example of a rule deviation documentation, and a few checklists helping to sort out all this bureaucracy.
As you can see, MISRA is not just a set of rules, but almost a whole infrastructure for writing secure code for embedded systems.
Usage in your projects
Imagine the scene: you're going to write a program for an oh-so-needed and responsible embedded system. Or you already have a program, but you need to «port» it to MISRA. So how do you check your code for its compliance to the standard? Do you really have to do it manually?
Manual code verification is an uneasy and even potentially impossible task. Not only does each reviewer have to carefully look through each line of code, but also one has to know the standard nearly by heart. Crazy!
Therefore, the MISRA developers themselves advise using static analysis to test your code. After all, in fact, static analysis is an automated process of code review. You simply run the analyzer on your program and in a few minutes, you get a report of potential violations of the standard. That's what you need, isn't it? All you have to do is review the log and fix the warnings.
The next question is — at what point should we start using MISRA? The answer is simple: the sooner the better. Ideally — before you start writing code at all, because MISRA assumes that you follow the standard for the whole of your code's lifecycle.
Well it is not always possible to write according to MISRA from the very beginning. For example, it is often the case that the project has already been partially or completely implemented, but later the customer wanted the project to meet the standard. In this case, you will have to deal with a thorough refactoring of the existing code.
That's where the pitfall pops up. I'd even say an underwater boulder shows up. What happens if you take a static analyzer and check the «ordinary» project to meet the MISRA standard? Spoiler: you may be scared.
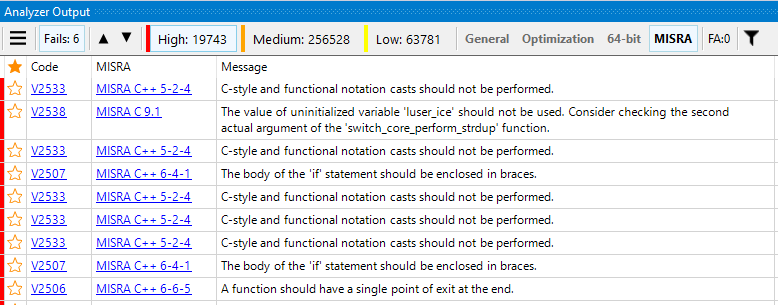
Right, the example in the picture is exaggerated. It shows the result of checking a quite large project that wasn't actually meant for working on microcontrollers. However, when checking already existing code, you might well get one, two, three, or even ten thousand analyzer warnings. New warnings, issued for new or modified code, will simply get lost in this big bunch of warnings.
So what can you do about it? Do you really have to postpone all tasks and go all out on fixing old warnings?
As developers of the static analyzer, we know that so many warnings appear after the check. Therefore, we developed the solution, which can help get use from the analyzer right away without stopping the work. This solution is called «suppress base».
Suppress bases represent the PVS-Studio mechanism that allows you to massively suppress analyzer messages. If you check a project for the first time and get several thousands of warnings — you just need to add them in a suppress base and the next run will give you zero warnings.
This way, you can continue to write and change the code as normal, and in doing so, you'll get messages only about bugs that have just been made in the project. So you will get the most benefit from the analyzer right here and now, without being distracted by raking old bugs. A few clicks — and the analyzer is adopted into your development! You can read the detailed instructions about doing this here.
You may probably wonder: «Wait, what about the hidden warnings?» The answer is quite simple: don't forget about them and fix them by easy stages. For example, you can load the suppress base in the version control system and allow only those commits that don't increase the number of warnings. Thus, gradually your «underwater boulder» will sooner or later grind off without leaving a trace.
Okay, the analyzer is now successfully adopted and we're ready to continue. What to do next? The answer is self-evident — work with the code! But what does it take to be able to declare compliance with the standard? How do you prove that your project complies with MISRA?
In fact, there is no special «certificate» that your code corresponds to MISRA. As the standard stipulates, compliance tracking should be done by two parties: the software customer and the software vendor. The vendor develops software that meets the standard and fills out the necessary documents. The customer, in turn, must make sure that the data from these documents is true.
If you develop software for yourself, then the responsibility for meeting the standard will lie only on your shoulders :)
In general, to prove the compliance of your project, you will need supporting documents. The list of documents that project developers should prepare may vary, but MISRA offers some set as a reference. Let's take a closer look at this set.
You'll need these things to apply for the standard compliance:
- The project itself, whose code complies with Mandatory and Required rules
- Guide enforcement plan
- Documentation on all compiler and static analyzer warnings
- Documentation for all deviations from Required Rules
- Guideline compliance summary
The first is a guide enforcement plan. This is your most important table, and it contains references to all other documents. In its first column is a list of MISRA rules, in the rest, it is noted whether there were any deviations from those rules. This table looks something like this:
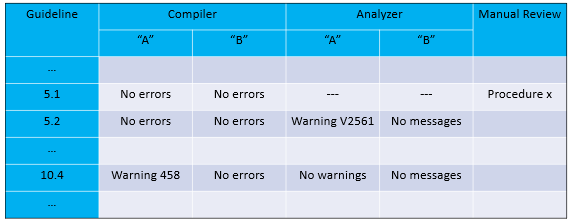
The standard recommends building your project with several compilers, as well as use two or more static analyzers to test your code for compliance. If the compiler or analyzer issues a rule-related warning, you should note it in the table and document the following points: why the warning can't be fixed, whether it is false or not, etc.
If one of the rules can't be checked by a static analyzer, you have to perform manual code review. This procedure must also be documented, after which a link to that documentation should be added to the compliance plan.
If the compiler or static analyzer turns out to be right, or if there are valid rule violations during the code review process, you must either correct them or document them. Again, by attaching the link to the documentation in the table.
Thus, a compliance plan is a document that will provide documentation for any deviation identified in your code.
Let's briefly touch on directly documenting deviations from the rules. As I mentioned, such documentation is only necessary for Required Rules, because Mandatory rules cannot be violated, and Advisory rules can be violated without any documentation.
If you choose to deviate from the rule, the documentation should include:
- The number of the violated rule
- The exact location of the deviation
- The validity of the deviation
- Proof that the deviation doesn't compromise security
- Potential consequences for the user
As you can see, such approach to documentation makes you seriously wonder whether the violation is worth it. This was done specifically to feel no desire to violate Required rules :)
Now about the summary of compliance with the rules. This paper, perhaps, will be the easiest to fill:
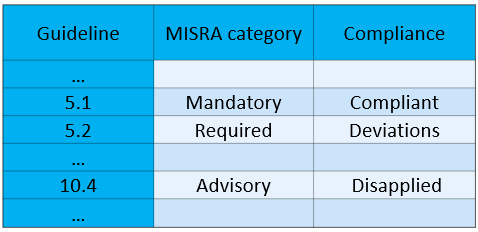
The central column is filled up before you start working with the code, and the right one — after your project is ready.
Here's a reasonable question: why should the categories of rules be specified, if they are already specified in the standard itself? The fact is that the standard allows «promoting» a rule into a stricter category. For example, a customer might ask you to categorize an Advisory rule. Such a «promotion» should be made before working with the code, and the summary of compliance with the rules allows you to explicitly note it.
As for the last column, it's quite simple: you just need to note whether the rule is being used, and if so, whether there are deviations from it.
This whole table is needed so that you can quickly see what priorities rules have and whether the code complies with them. If you're suddenly interested in knowing the exact cause of the deviation, you can always turn to the compliance plan and find the documentation you need.

So you wrote the code carefully following the MISRA rules. You've made a compliance plan and documented everything that could be documented, and you've filled out your compliance resumes. If this is indeed the case, then you have got a very clean, very readable and very reliable code that you now hate :)
Where will your program live now? In an MRI device? In an ordinary speed sensor or in the control system of some space satellite? Yes, you've been through a serious bureaucratic path, but that's no big deal. When it comes to real human lives, you always must be scrupulous.
If you have coped and managed to reach the victorious end, then I sincerely congratulate you: you write high quality safe code. Thank you!
The future of standards
For the finale, I'd like to dwell on the future of standards.
Now MISRA lives and evolves. For example, «The MISRA C:2012 Third Edition (First Revision)» is a revised and enlarged with new rules edition announced at the beginning of 2019. At the same time, the upcoming release of «MISRA C: 2012 Amendment 2 – C11 Core», which is a revised standard of the 2012 year, was announced. This document will comprise rules that for the first time cover C language versions of 2011 and 2018 years.
MISRA C++ keeps evolving as well. As you know, the last standard of MISRA C++ is dated 2008, so the oldest version of the language it covers is C++03. Because of this, there is another standard similar to MISRA, and it is called AUTOSAR C++. It was originally intended as a continuation of MISRA C++ and was intended to cover later versions of the language. Unlike its mastermind, AUTOSAR C++ gets updated twice a year and currently supports C++14. New C++17 and then C++20 updates are yet to come.
Why did I start talking about some other standard? The fact is that just under a year ago, both organizations announced that they would merge their standards into one. MISRA C++ and AUTOSAR C++ will become a single standard, and from now on they will evolve together. I think that's great news for developers who write for microcontrollers in C++, and no less great news for static analyzer developers. There's a lot more to do! :)
Conclusion
Today you hopefully learned a lot about MISRA: read the history of its origin, studied the examples of rules and concept of the standard, considered everything you'll need to use MISRA in your projects, and even got a glimpse of the future. I hope now you have a better understanding of what MISRA is and how to cook it!
In the old tradition, I will leave here a link to our PVS-Studio static analyzer. It is able to find not only deviations from the MISRA standard, but also a huge range of errors and vulnerabilities. If you're interested in trying PVS-Studio yourself, download the demo version and check your project.
That's where my article comes to an end. I wish all readers a merry Christmas and happy New Year's holiday!
