
This article coincides with the beta testing start of PVS-Studio C# for Linux, as well as the plugin for Rider. For such a wonderful reason, we checked the source code of the Nethermind product using these tools. This article will cover some distinguished and, in some cases, funny errors.
Nethermind is a fast client for .NET Core Ethereum for Linux, Windows, MacOs. It can be used in projects when setting up Ethereum or dApps private networks. Nethermind open source code is available on GitHub. The project was established in 2017 and is constantly evolving.
Introduction
Do you like manual labor? For example, such as finding errors in program code. It stands to reason, it's rather tedious to read and analyze your own fragment of code or a whole project in search of a tricky bug. It's no big deal if a project is small, let's say 5,000 lines, but what if its size has already exceeded one hundred thousand or a million lines? In addition, it might be written by several developers and in some cases not in a very digestible form. What is to be done in this case? Do we really have to fall behind on sleep, have no regular meals, and spend 100% of time probing into all these endless lines in order to understand where this nasty mistake is? I doubt that you would like to do this. So what shall we do? Maybe there are modern means to somehow automate this?

Here a tool like a static code analyzer comes into play. Static analyzer is a tool for detecting defects in the source code of programs. The advantage of this tool over manual check boils down to these points:
- it almost doesn't spend your time when searching for an erroneous fragment. At least it's definitely faster than a human looking for a failed copy-paste;
- it doesn't get tired, unlike a person who will need rest after some time of searching;
- it knows a lot of error patterns that a person may not even be aware of;
- it uses technologies such as: data flow analysis, symbolic execution, pattern matching, and others;
- it allows you to regularly perform the analysis at any time;
- and so on.
Of course, usage of a static code analyzer doesn't replace or obviate the need of code reviews. However, with this tool code reviews become more productive and useful. You can focus on finding high-level errors, imparting knowledge, rather than just wearily review code in search of typos.
If you became interested in reading more about it, then I suggest the following article, as well as an article about the technologies used in PVS-Studio.
PVS-Studio C# for Linux/macOS
We are currently porting our C# analyzer to .NET Core, and we are also actively developing a plugin for the Rider IDE.
If you are interested, you can sign up for beta testing by filling out the form on this page. Installation instructions will be sent to your mail (don't worry, it's very simple), as well as a license for using the analyzer.
This is how Rider looks like with the PVS-Studio plugin:
A bit of outrage
I'd like to mention that some fragments of the Nethermind code were difficult to perceive, as lines of 300-500 characters are normal for it. That's it, code in one line without formatting. For example, these lines might contain both several ternary operators, and logical operators, they got everything there. It's just as 'delightful' as the last Game of Thrones season.
Let me make some clarifications for you to become aware of the scale. I have an UltraWide monitor, which is about 82 centimeters (32 inches) long. Opening the IDE on it in full screen, it fits about 340 characters, that is, the lines that I'm talking about don't even fit. If you want to see how it looks, I left the links to files on GitHub:
Example 1
private void LogBlockAuthorNicely(Block block, ISyncPeer syncPeer)
{
string authorString = (block.Author == null ? null : "sealed by " +
(KnownAddresses.GoerliValidators.ContainsKey(block.Author) ?
KnownAddresses.GoerliValidators[block.Author] : block.Author?.ToString())) ??
(block.Beneficiary == null ? string.Empty : "mined by " +
(KnownAddresses.KnownMiners.ContainsKey(block.Beneficiary) ?
KnownAddresses.KnownMiners[block.Beneficiary] : block.Beneficiary?.ToString()));
if (_logger.IsInfo)
{
if (_logger.IsInfo) _logger.Info($"Discovered a new block
{string.Empty.PadLeft(9 - block.Number.ToString().Length, '
')}{block.ToString(Block.Format.HashNumberAndTx)} {authorString}, sent by
{syncPeer:s}");
}
}→ Link to the file
Example 2
private void BuildTransitions()
{
...
releaseSpec.IsEip1283Enabled = (_chainSpec.Parameters.Eip1283Transition ??
long.MaxValue) <= releaseStartBlock &&
((_chainSpec.Parameters.Eip1283DisableTransition ?? long.MaxValue)
> releaseStartBlock || (_chainSpec.Parameters.Eip1283ReenableTransition ??
long.MaxValue) <= releaseStartBlock);
...
}→ Link to the file
public void
Will_not_reject_block_with_bad_total_diff_but_will_reset_diff_to_null()
{
...
_syncServer = new SyncServer(new StateDb(), new StateDb(), localBlockTree,
NullReceiptStorage.Instance, new BlockValidator(Always.Valid, new
HeaderValidator(localBlockTree, Always.Valid, MainnetSpecProvider.Instance,
LimboLogs.Instance), Always.Valid, MainnetSpecProvider.Instance,
LimboLogs.Instance), Always.Valid, _peerPool, StaticSelector.Full,
new SyncConfig(), LimboLogs.Instance);
...
}→ Link to the file
Would it be nice to search for such an error in such a fragment? I'm sure, everyone is perfectly aware that it wouldn't be nice and one shouldn't write code in this way. By the way, there is a similar place with an error in this project.
Analysis results
Conditions that don't like 0
Condition 1
public ReceiptsMessage Deserialize(byte[] bytes)
{
if (bytes.Length == 0 && bytes[0] == Rlp.OfEmptySequence[0])
return new ReceiptsMessage(null);
...
}PVS-Studio warning: V3106 Possibly index is out of bound. The '0' index is pointing beyond 'bytes' bound. Nethermind.Network ReceiptsMessageSerializer.cs 50
In order to take a close look at the error, let's consider the case with the 0 number of elements in the array. Then the bytes.Length == 0 condition will be true and when accessing the array element the IndexOutOfRangeException type exception will occur.
Perhaps, the code author wanted to exit the method right away if the array is empty or the 0 element is equal to a certain value. Yet it seems like the author got "||" and "&&" confused. I suggest fixing this problem as follows:
public ReceiptsMessage Deserialize(byte[] bytes)
{
if (bytes.Length == 0 || bytes[0] == Rlp.OfEmptySequence[0])
return new ReceiptsMessage(null);
...
}Condition 2
public void DiscoverAll()
{
...
Type? GetStepType(Type[] typesInGroup)
{
Type? GetStepTypeRecursive(Type? contextType)
{
...
}
...
return typesInGroup.Length == 0 ? typesInGroup[0] :
GetStepTypeRecursive(_context.GetType());
}
...
}PVS-Studio warning: V3106 Possibly index is out of bound. The '0' index is pointing beyond 'typesInGroup' bound. Nethermind.Runner EthereumStepsManager.cs 70
Here we have the case, similar to the above. If the number of elements in typesInGroup is 0, then when accessing the 0 element, an exception of IndexOutOfRangeException type will occur.
But in this case I don't understand what the developer wanted. Most likely, null has to be written instead of typesInGroup[0].
An error or an uncomplete optimization?
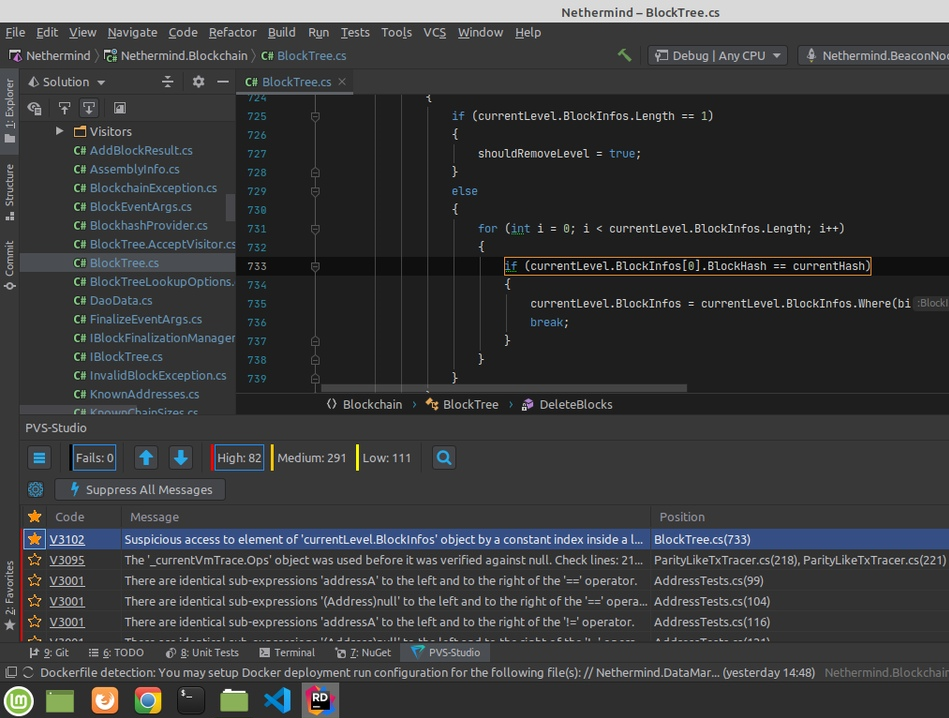
private void DeleteBlocks(Keccak deletePointer)
{
...
if (currentLevel.BlockInfos.Length == 1)
{
shouldRemoveLevel = true;
}
else
{
for (int i = 0; i < currentLevel.BlockInfos.Length; i++)
{
if (currentLevel.BlockInfos[0].BlockHash == currentHash) // <=
{
currentLevel.BlockInfos = currentLevel.BlockInfos
.Where(bi => bi.BlockHash != currentHash)
.ToArray();
break;
}
}
}
...
}PVS-Studio warning: V3102 Suspicious access to element of 'currentLevel.BlockInfos' object by a constant index inside a loop. Nethermind.Blockchain BlockTree.cs 895
At first glance, the error is obvious — the loop is supposed to iterate over the currentLevel.BlockInfos elements. Nevertheless, authors wrote currentLevel.BlockInfos[0] instead of currentLevel.BlockInfos[i] when accessing it. So we change 0 for i to complete our mission. No such luck! Let's get this over.
At this point we access BlockHash of the zeroth element Length times. If it's equal to currentHash, we take all elements not equal to currentHash from currentLevel.BlockInfos. Then we write them in this very currentLevel.BlockInfos and exit the loop. It turns out that the loop is redundant.
I think that earlier there was an algorithm that the author decided to change/optimize using linq, but something went wrong. Now, in the case when the condition is false, we get meaningless iterations.
By the way, if the developer who had written this had used the incremental analysis mode, then he would have immediately realized that something had been wrong and would have fixed everything straight away. Given the above, I would rewrite the code like this:
private void DeleteBlocks(Keccak deletePointer)
{
...
if (currentLevel.BlockInfos.Length == 1)
{
shouldRemoveLevel = true;
}
else
{
currentLevel.BlockInfos = currentLevel.BlockInfos
.Where(bi => bi.BlockHash != currentHash)
.ToArray();
}
...
}Cases of dereferencing null reference
Dereference 1
public void Sign(Transaction tx, int chainId)
{
if (_logger.IsDebug)
_logger?.Debug($"Signing transaction: {tx.Value} to {tx.To}");
IBasicWallet.Sign(this, tx, chainId);
}PVS-Studio warning: V3095 The '_logger' object was used before it was verified against null. Check lines: 118, 118. Nethermind.Wallet DevKeyStoreWallet.cs 118
The error is in the wrong sequence. First _logger.IsDebug is accessed followed by the _logger check for null. Accordingly, if _logger is null, we'll get the NullReferenceException.
Dereference 2
private void BuildNodeInfo()
{
_nodeInfo = new NodeInfo();
_nodeInfo.Name = ClientVersion.Description;
_nodeInfo.Enode = _enode.Info; // <=
byte[] publicKeyBytes = _enode?.PublicKey?.Bytes; // <=
_nodeInfo.Id = (publicKeyBytes == null ? Keccak.Zero :
Keccak.Compute(publicKeyBytes)).ToString(false);
_nodeInfo.Ip = _enode?.HostIp?.ToString();
_nodeInfo.ListenAddress = $"{_enode.HostIp}:{_enode.Port}";
_nodeInfo.Ports.Discovery = _networkConfig.DiscoveryPort;
_nodeInfo.Ports.Listener = _networkConfig.P2PPort;
UpdateEthProtocolInfo();
}PVS-Studio warning: V3095 The '_enode' object was used before it was verified against null. Check lines: 55, 56. Nethermind.JsonRpc AdminModule.cs 55
The error is completely similar to the one described above, except for this time _enode is to blame here.
I might add, that if you forget to check something for null, you'll probably be reminded only when the program crashes. The analyzer will remind you of this and everything will be fine.
Our dearly beloved Copy-Paste
Fragment N1
public static bool Equals(ref UInt256 a, ref UInt256 b)
{
return a.s0 == b.s0 && a.s1 == b.s1 && a.s2 == b.s2 && a.s2 == b.s2;
}PVS-Studio warning: V3001 There are identical sub-expressions 'a.s2 == b.s2' to the left and to the right of the '&&' operator. Nethermind.Dirichlet.Numerics UInt256.cs 1154
Here the same condition is checked twice:
a.s2 == b.s2Since a and b parameters have the s3 field, I assume the developer simply forgot to change s2 for s3 when copying.
It turns out that the parameters will be equal more often than expected by this fragment author. At the same time, some developers suppose that they can't write something like this and they start looking for an error in a completely different place, wasting a lot of energy and nerves.
By the way, errors in comparison functions are generally a classic. Apparently, programmers, considering such functions simple, treat writing their code very casually and inattentively. Proof. Now you know about this, so stay alert :)!
Fragment N2
public async Task<ApiResponse>
PublishBlockAsync(SignedBeaconBlock signedBlock,
CancellationToken cancellationToken)
{
bool acceptedLocally = false;
...
if (acceptedLocally)
{
return new ApiResponse(StatusCode.Success);
}
else
{
return new ApiResponse(StatusCode.Success);
}
...
}PVS-Studio warning: V3004 The 'then' statement is equivalent to the 'else' statement. Nethermind.BeaconNode BeaconNodeFacade.cs 177
For any value of the acceptedLocally variable, the method returns the same. Tough to tell, whether it is an error or not. Suppose a programmer copied a line and forgot to change StatusCode.Success for something else — in this way, it's a real error. Moreover, StatusCode has InternalError and InvalidRequest. Perhaps, it's all the fault of code refactoring and the acceptedLocally value doesn't matter. This way, the condition makes us sit around thinking whether it's an error or not. So in any case, this case is extremely nasty.
Fragment N3
public void TearDown()
{
...
foreach (var testResult in _results)
{
string message = $"{testResult.Order}. {testResult.Name} has "
+ $"{(testResult.Passed ? "passed [+]" : "failed [-]")}";
if (testResult.Passed)
{
TestContext.WriteLine(message);
}
else
{
TestContext.WriteLine(message);
}
}
}PVS-Studio warning: V3004 The 'then' statement is equivalent to the 'else' statement. Nethermind.Overseer.Test TestBuilder.cs 46
There we go again not paying much attention to the check, as we get the same result. So we're wondering and racking our brains thinking about the developer's intentions. A waste of time that could have been avoided by using static analysis and immediately fixing such ambiguous code.
Fragment N4
public void Setup()
{
if (_decoderBuffer.ReadableBytes > 0)
{
throw new Exception("decoder buffer");
}
if (_decoderBuffer.ReadableBytes > 0)
{
throw new Exception("decoder buffer");
}
...
}PVS-Studio warning: V3021 There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless Nethermind.Network.Benchmark InFlowBenchmarks.cs 55
Someone accidently pressed Ctrl+V one extra time. We remove the excess check and everything looks fine. I'm sure that if another condition were important here, then everything would be written in one if block using the AND logical operator.
Fragment N5
private void LogBlockAuthorNicely(Block block, ISyncPeer syncPeer)
{
if (_logger.IsInfo)
{
if (_logger.IsInfo)
{
...
}
}
}PVS-Studio warning: V3030 Recurring check. The '_logger.IsInfo' condition was already verified in line 242. Nethermind.Synchronization SyncServer.cs 244
As in the fourth case, an extra check is performed. However, the difference is that not only does _logger have only one property, it also has, for example, 'bool IsError { get; }'. Therefore, the code should probably look like this:
private void LogBlockAuthorNicely(Block block, ISyncPeer syncPeer)
{
if (_logger.IsInfo)
{
if (!_logger.IsError) // <=
{
...
}
}
}Or maybe pesky refactoring is responsible for it and one check is no longer needed.
Fragment N6
if (missingParamsCount != 0)
{
bool incorrectParametersCount = missingParamsCount != 0; // <=
if (missingParamsCount > 0)
{
...
}
...
}PVS-Studio warning: V3022 Expression 'missingParamsCount != 0' is always true. Nethermind.JsonRpc JsonRpcService.cs 127
Here we check the condition (missingParamsCount != 0) and if it's true, then again we calculate it and assign the result to the variable. Agree that this is a fairly original way to write true.
Confusing check
public async Task<long>
DownloadHeaders(PeerInfo bestPeer,
BlocksRequest blocksRequest,
CancellationToken cancellation)
{
...
for (int i = 1; i < headers.Length; i++)
{
...
BlockHeader currentHeader = headers[i];
...
bool isValid = i > 1 ?
_blockValidator.ValidateHeader(currentHeader, headers[i - 1], false):
_blockValidator.ValidateHeader(currentHeader, false);
...
if (HandleAddResult(bestPeer,
currentHeader,
i == 0, // <=
_blockTree.Insert(currentHeader)))
{
headersSynced++;
}
...
}
...
}PVS-Studio warning: V3022 Expression 'i == 0' is always false. Nethermind.Synchronization BlockDownloader.cs 192
Let's start from the beginning. When initializing, the variable i is assigned the value 1. Further, the variable is only incremented, therefore, false will always be passed to the function.
Now let's look at HandleAddResult:
private bool HandleAddResult(PeerInfo peerInfo,
BlockHeader block,
bool isFirstInBatch,
AddBlockResult addResult)
{
...
if (isFirstInBatch)
{
...
}
else
{
...
}
...
}Here we are interested in isFirstInBatch. Judging by the name of this parameter, it is responsible for whether something is the first in the line. Hm, first. Let's look again above and see that there are 2 calls using i:
BlockHeader currentHeader = headers[i];
_blockValidator.ValidateHeader(currentHeader, headers[i - 1], false)Don't forget that the countdown in this case comes from 1. It turns out that we have 2 options: either «first» means an element under index 1, or under index 0. But in any case, i will be equal to 1.
It follows that the function call should look like this:
HandleAddResult(bestPeer, currentHeader,
i == 1, _blockTree.Insert(currentHeader))Or in this way:
HandleAddResult(bestPeer, currentHeader,
i - 1 == 0, _blockTree.Insert(currentHeader))And again, if the developer constantly used a static analyzer, then he would write this code and see the warning, he would quickly fix it and enjoy life.
Priority ??
Case 1
public int MemorySize
{
get
{
int unaligned = (Keccak == null ? MemorySizes.RefSize :
MemorySizes.RefSize + Keccak.MemorySize)
+ (MemorySizes.RefSize + FullRlp?.Length
?? MemorySizes.ArrayOverhead) // <=
+ (MemorySizes.RefSize + _rlpStream?.MemorySize
?? MemorySizes.RefSize) // <=
+ MemorySizes.RefSize + (MemorySizes.ArrayOverhead + _data?.Length
* MemorySizes.RefSize ?? MemorySizes.ArrayOverhead)
+ MemorySizes.SmallObjectOverhead + (Key?.MemorySize ?? 0);
return MemorySizes.Align(unaligned);
}
}PVS-Studio warnings:
- V3123 Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part. Nethermind.Trie TrieNode.cs 43
- V3123 Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part. Nethermind.Trie TrieNode.cs 44
The analyzer advises us to check how we use the "??" operators. In order to understand what the problem is, I propose to consider the following situation. Look at this line here:
(MemorySizes.RefSize + FullRlp?.Length ?? MemorySizes.ArrayOverhead)MemorySizes.RefSize and MemorySizes.ArrayOverhead are constants.
public static class MemorySizes
{
...
public const int RefSize = 8;
public const int ArrayOverhead = 20;
...
}Therefore, for clarity, I suggest rewriting the line, substituting their values:
(8 + FullRlp?.Length ?? 20)Now suppose FullRlp is null. Then (8 + null) will be null. Next, we get the expression (null ?? 20), which will return 20.
As a result, in case if FullRlp is null, the value from MemorySizes.ArrayOverhead will always be returned regardless of what is stored in MemorySizes.RefSize. The fragment on the line below is similar.
But the question is, did the developer want this behavior? Let's look at the following line:
MemorySizes.RefSize + (MemorySizes.ArrayOverhead
+ _data?.Length * MemorySizes.RefSize ?? MemorySizes.ArrayOverhead) Same as in the fragments above, MemorySizes.RefSize is added to the expression, but note that after the first "+" operator there is a bracket.
It turns out that it is MemorySizes.RefSize which we should add some expression to, and if it is null, then we should add another one. So the code should look like this:
public int MemorySize
{
get
{
int unaligned = (Keccak == null ? MemorySizes.RefSize :
MemorySizes.RefSize + Keccak.MemorySize)
+ (MemorySizes.RefSize + (FullRlp?.Length
?? MemorySizes.ArrayOverhead)) // <=
+ (MemorySizes.RefSize + (_rlpStream?.MemorySize
?? MemorySizes.RefSize)) // <=
+ MemorySizes.RefSize + (MemorySizes.ArrayOverhead + _data?.Length
* MemorySizes.RefSize ?? MemorySizes.ArrayOverhead)
+ MemorySizes.SmallObjectOverhead + (Key?.MemorySize ?? 0);
return MemorySizes.Align(unaligned);
}
}Again, this is only an assumption, however, if the developer wanted different behavior, then one should explicitly indicate this:
((MemorySizes.RefSize + FullRlp?.Length) ?? MemorySizes.ArrayOverhead)In doing so, the one who reads this code wouldn't have to delve into it for a long time puzzling out what is happening here and what the developer wanted.
Case 2
private async Task<JsonRpcResponse>
ExecuteAsync(JsonRpcRequest request,
string methodName,
(MethodInfo Info, bool ReadOnly) method)
{
var expectedParameters = method.Info.GetParameters();
var providedParameters = request.Params;
...
int missingParamsCount = expectedParameters.Length
- (providedParameters?.Length ?? 0)
+ providedParameters?.Count(string.IsNullOrWhiteSpace) ?? 0; // <=
if (missingParamsCount != 0)
{
...
}
...
}PVS-Studio warning: V3123 Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part. Nethermind.JsonRpc JsonRpcService.cs 123
Here again we deal with the priority of the operation "??". Therefore we'll consider this case. Look at this line:
expectedParameters.Length
- (providedParameters?.Length ?? 0)
+ providedParameters?.Count(string.IsNullOrWhiteSpace) ?? 0;Suppose that providedParameters is null, then for clarity, let's replace everything related to providedParameters with null straight away, and substitute a random value instead of expectedParameters.Length:
100 - (null ?? 0) + null ?? 0;Now it's immediately noticeable that there are two similar checks, but unlike the first case there are no parentheses in the second one. Let's run this example. First we get that (null ?? 0) will return 0, then subtract 0 from 100 and get 100:
100 + null ?? 0;Now instead of performing "null ?? 0" and getting (100 + 0), we'll get a completely different result.
First (100 + null) will be executed resulting in null. Then (null ?? 0) is checked leading to the fact that the value of the missingParamsCount variable will be 0.
Since there's a condition that further checks whether missingParamsCount is not equal to null, we can assume that the developer sought exactly this behavior. Let me tell you something — why not put parentheses and clearly express your intentions? Perhaps, this check was due to misunderstanding why in some cases 0 is returned. This is nothing more than a kludge.
And again, we are wasting time, although we might not have done this, if only the developer had used the incremental analysis mode when writing code.
Conclusion
In conclusion, I hope that I was able to convey that the static analyzer is your friend, and not an evil overseer who is just waiting for you to make a mistake.
It should also be noted that by using an analyzer once, or rarely using it, you will still find errors and some of them will even be quickly fixed, but there will also be ones that you need to smash your head at. Therefore, you need to use a static analyzer regularly. Then you will find much more errors and fix them right when writing the code. Doing so, you'll be completely aware of what you are trying to do.
The simple truth is that everyone makes mistakes and that's normal. We all learn from mistakes, but only from those that we notice and delve into. For this reason, use modern tools to search for these very errors, for example — PVS-Studio. Thank you for your attention.
