Мы продолжаем рассказывать о буднях Security Operations Center – о реагировании на массовые кибератаки, любопытных кейсах у заказчиков и правилах корреляции событий, позволяющих нам детектировать атаки на заказчиков и пр.
Сегодня мы хотим открыть новый цикл статей, задача которого – продемонстрировать, с какими задачами и трудностями сталкиваются все начинающие (и не очень) SOCостроители, и главное – поделиться нашим опытом по их решению.

В этих статьях мы будем касаться разных вопросов и технического, и методического характера, и максимально отделять коммерческое и маркетинговое позиционирование от реальных задач. В наших планах завершить первый цикл статей как раз к SOC-Форуму, чтобы площадка стала одним из мест для обсуждения данных вопросов.
Начнем с самой популярной задачи, без которого сложно представить SOC, – мониторинга инцидентов.
Security monitoring – реальная задача или новая маркетинговая реальность?
Любой опытный безопасник за свою карьеру пережил немало трендов на новые красивые аббревиатуры. Очередные NG-технологии, искусственные интеллектуальные системы, «золотые» и «серебряные» пули защиты от хакеров и таргетированных атак и т.д. Сейчас одним из таких популярных направлений стал мониторинг инцидентов информационной безопасности. При этом эксперты иногда высказываются, что безопасность не требует мониторинга, а требует только активного блокирования. Однако мы считаем иначе – по двум причинам.
Причина первая: динамика развития компаний
Существуют два глобальных изменения, которые все агрессивнее входят в жизнь каждой компании, обладающих хоть какой-то ИТ-инфраструктурой:
Поэтому подход «тащить и не пущать» уже не просто кажется устаревшим, он не применим. Соответственно, остается только попытаться «возглавить процесс»: контролировать подключения к системе и выполняемые на ней действия, фиксировать аномалии и инциденты.
Причина вторая: интеллектуальность атак и средств защиты
Попытка взлома, отбитая или заблокированная средством защиты, сегодня уже не является поводом для успокоения, поскольку инструментарий злоумышленников, а следовательно, и сами атаки, непрерывно эволюционируют.
Приведем два простых примера.
1. В компании используется NGFW. Такие системы могут детектировать не только внешние атаки, но и потенциально вредоносную активность внутри сети (например, активность бота). И вот в один прекрасный день NGFW заблокировал попытку одного из хостов подключиться к центру управления бот-сетями вредоносного семейства / отправки информации на сервера, подконтрольные злоумышленникам.
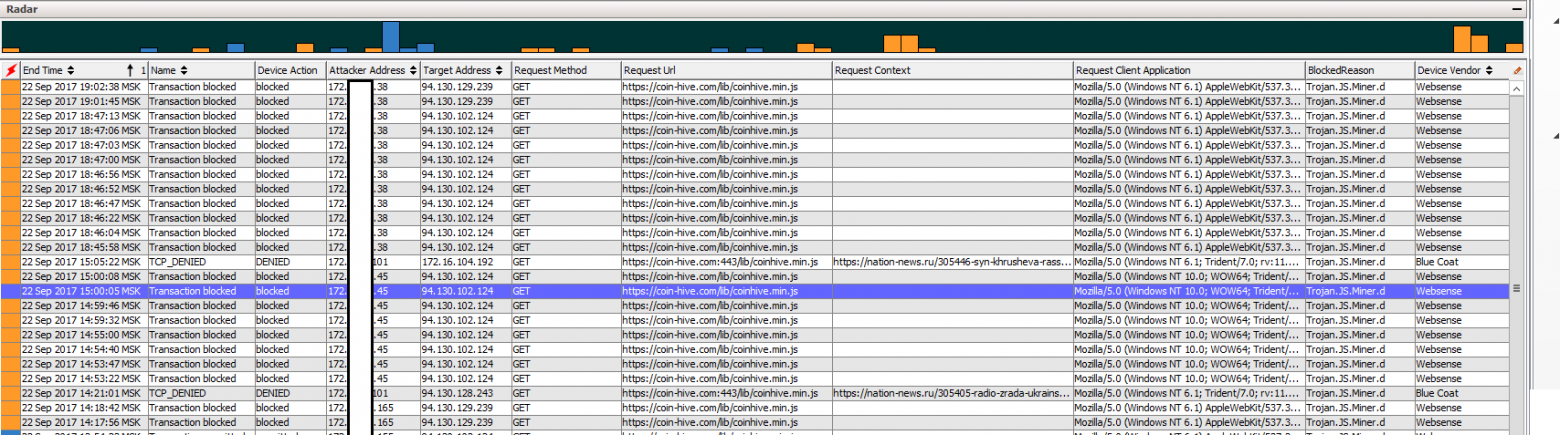
Можно ли утверждать, что на этом инцидент исчерпан? На первый взгляд, да. Наша защита успешно заблокировала подключение, бот не связался с центром управления, и в итоге вредоносная активность в сети не началась. Но давайте копнем глубже: 90% процентов сотрудников компании уже давно пользуются ноутбуками. И если сотрудник решит поработать из дома или из кафе, бот успешно достучится до центра управления, ведь там, за пределами сети предприятия, нет ни NGFW, ни бдительного безопасника. К чему это приведет? На первом этапе – к компрометации всех данных этого ноутбука. На втором – к обновлению протоколов или адресов центра управления бота, что не позволит NGFW успешно блокировать атаку.
2. Уже достаточно давно антивирусные агенты научились выявлять и блокировать хакерские утилиты, например, печально известный mimikatz. И вот мы настроили соответствующую политику в нашей компании и зафиксировали блокировку. На одном из хостов ИТ-администраторов был запущен и заблокирован mimikatz.

Этот пример аналогичен предыдущему – с одной стороны, компрометации учетных записей не произошло, инцидент исчерпан. Но, даже если оставить в стороне ненормальность самой ситуации и желание в ней разобраться (сам ли ИТ-администратор запускал утилиту и для чего), ничто не помешает злоумышленнику еще раз попытаться получить доступ. Он попытается «прибить» процесс антивируса, использует версию, которая антивирусом не определяется, например, при применении powershell-аналогов. В конце концов, просто найдет хост без антивируса и получит интересующую его информацию там.

В итоге, проигнорировав анализ и разбор заблокированной атаки, мы оставляем действия злоумышленников без контроля. И вместо того, чтобы купировать их попытки захватить нашу инфраструктуру, мы оставляем их с развязанными руками, позволяя придумать новый способ атаки и вернуться к ней с ранее захваченных позиций.
Два этих примера доказывают, что оперативный мониторинг и тщательный анализ событий ИБ может не только помочь в выявлении и разборе инцидентов, но и усложнить жизнь злоумышленников.
Некоторое время назад между темой SOC и мониторинга ставился знак равенства, а дальше он же возникал между понятиями «мониторинг» и «SIEM». И, хотя вокруг этой темы сломано много копий, хочется вернуться к этому вопросу, чтобы он не смущал нас в дальнейшем.
В мировой практике и даже на территории России известны подходы к решению задач мониторинга и построения SOC вообще без применения SIEM. Один из крупнейших и самых успешных SOC прошлого десятилетия был целиком построен на оперативной регулярной работе сотрудников: на высокорегулярной основе дежурная смена анализировала журналы антивируса, прокси, IPS и других средств защиты – где руками, где базовыми скриптами, где умными отчетами. Этот подход позволял закрывать 80% задач baseline мониторинга (к примерам базовых задач и начального подхода я подойду детальнее в следующем разделе).
Так зачем же на самом деле нужна платформа SIEM/Log Management в плоскости задач мониторинга? Попробуем разобрать на примерах.
Use case 1. Собрать все инциденты «в одну кучу».
На первый взгляд эта задача может показаться бесполезной, но, на самом деле, трудно переоценить потребность заказчиков в ее решении. Особенно когда их цель –не обработка каждого детекта со средства защиты, а поиск определенных закономерностей. Например, выявление повторяющихся событий/инцидентов (когда проблема методически не устранена), фиксация странных активностей с одного хоста/на один хост (первые робкие шаги к модному слову kill chain), анализ частотности срабатываний.
Безусловно, для решения столь утилитарной задачи SIEM, по-честному, не нужен. Вполне приемлемым вариантом здесь может стать service desk с учетом заявок и правильная работа с отчетами из него (анализ закономерностей глазами).
Но, тем не менее, когда компания запускает у себя SIEM, ее, как правило мотивирует именно желание собрать все инциденты в едином окне, поэтому включаем этот use case в наш список.
Use case 2. Склеить однотипные инциденты.
Когда речь идет о развивающейся и длительной активности злоумышленника, при неправильной настройке сценария можно столкнуться с явлением под названием «incident storm». Например:
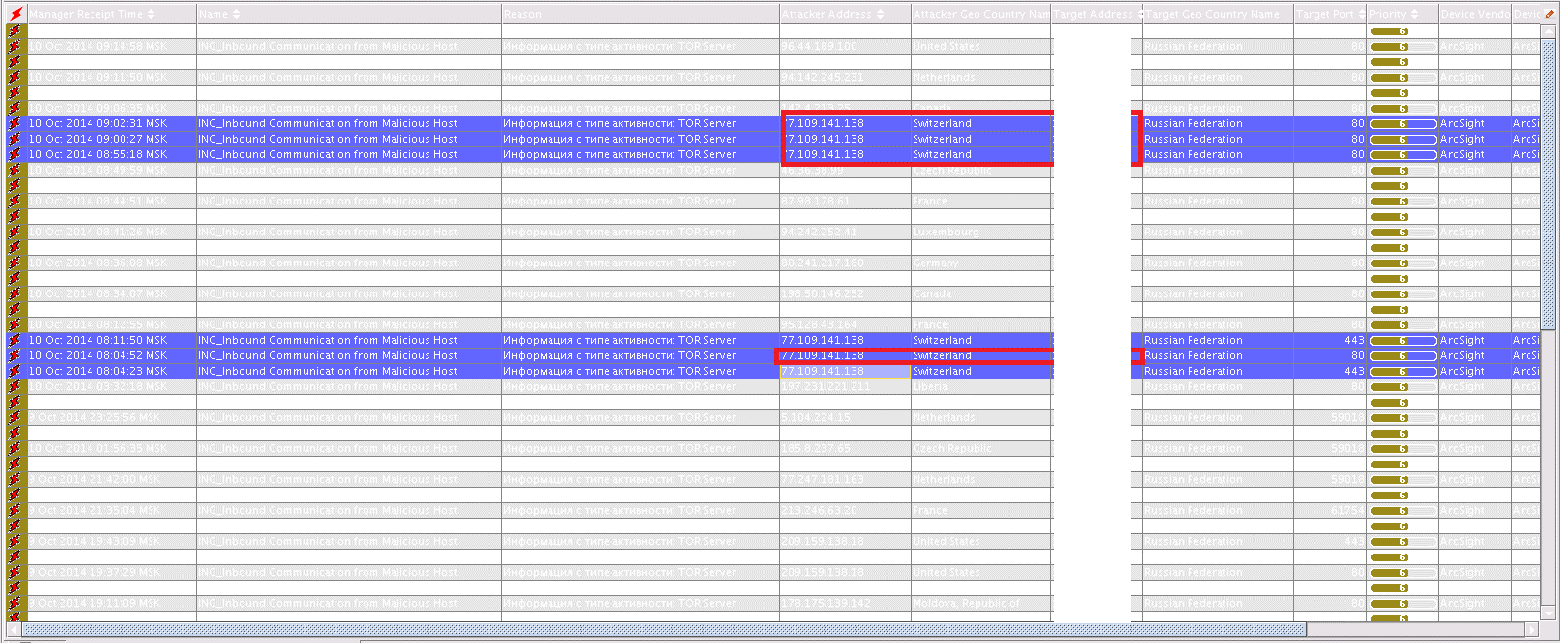
И в этом потоке событий очень легко пропустить инцидент, отличный от указанных активностей. Поэтому правильный SIEM всегда позволит склеить эти активности по ключевым полям, чтобы разбирать их как один общий инцидент.
Use Case 3. Обогатить расследование информацией из дополнительных систем.
После выявления инцидента аналитику обычно предстоит очень большой объем работы по поиску его причин и последствий. Рассмотрим следующий пример: одним из базовых правил мониторинга и контроля во многих международных стандартах является запрет на использование системных неперсонифированных учетных записей в инфраструктуре. И вот перед нами встала задача контролировать вход под учетной записью root на операционной системе Unix. Нужен ли для решения такой задачи SIEM? Безусловно, нет; любой администратор, владеющий основами написания скриптов, с легкостью создаст двухстрочный скрипт, который позволит выявлять такую активность.
Но теперь давайте посмотрим, что нам, как оператору SOC, нужно дальше сделать с этим событием.

Чем отличаются эти два события? Какое из подключений легитимно, а какое нет? Сейчас у нас есть только ip-адрес, с которого выполнялось подключение. Это, безусловно, не позволяет нам локализовать пользователя. Вот как действовали бы мы:
Только получив всю эту информацию, мы можем считать, что в первом приближении определили виновного.
После этого необходимо оценить воздействие на систему, оказанное после входа под системной записью root. При правильно настроенном аудите нам, в принципе, будет достаточно журналов сервера, но есть одно «но»: сам злоумышленник с этими правами мог с легкостью их модифицировать. Что приводит нас к задаче хранения журналов в независимом источнике (одной из задач, которые часто ставят под SIEM). В итоге, анализ этих журналов позволяет оценить проблему и ее критичность.

Безусловно, большую часть этой работы можно выполнить и без SIEM, но тогда на нее уйдет гораздо больше времени, а аналитик столкнется с серьезными ограничениями. Поэтому хотя SIEM и не строго необходим, при проведении расследований он имеет серьезные преимущества.

Use Case 4. Простая и сложная корреляция.
На эту тему написаны уже сотни статей и презентаций, поэтому надолго останавливаться на данном примере не хочется. Скажу еще раз главное: сегодня, чтобы эффективно выявлять и отражать атаки, нужно уметь выявлять корреляции между событиями ИБ. Будет ли это создание и удаление учетной записи в Active Directory в течение подозрительно короткого интервала или выявление продолжительных vpn-сессий (длиннее 8 часов) на межсетевом экране – не важно. Так или иначе, базовыми скриптами или инструментами самого средства защиты эта задача не решается из-за огромного объема проходящих через него событий безопасности. Для решения таких задач и предназначены платформы SIEM.
Итого: подход к задачам мониторинга на первом этапе не обязательно требует SIEM-платформы, но она существенно упрощает жизнь SOC и его операторов. В долгосрочной перспективе, по мере углубления в задачи по выявлению инцидентов, наличие SIEM перестает быть рекомендацией и становится обязательным условием.
Мониторинг – с чего начать?
Отвечая на вопрос в заглавии этого раздела, большинство заказчиков впадает в одно из двух заблуждений.
Единственной задачей SOC и вообще информационной безопасности является борьба с APT или таргетированными атаками. Наша практика показывает, что до выстраивания базовых процессов мониторинга, наведения порядка в инфраструктуре и «причесывания» процессов реагирования ставить столь амбициозную задачу перед собой не стоит.
О мониторинге можно думать только после того, как вся инфраструктура будет накрыта плотным колпаком из средств защиты и самых современных систем ИБ. По нашим наблюдениям, хороший первый результат по повышению уровня ИБ можно получить, обладая минимальным набором средств защиты. Это подтверждает и статистика, которую мы собираем на регулярной основе: например, в первом полугодии 2017 около 67% событий у заказчиков были зафиксированы при помощи основных сервисов ИТ-инфраструктуры и средств обеспечения базовой безопасности – межсетевых экранов и сетевого оборудования, VPN-шлюзов, контроллеров доменов, почтовых серверов, антивирусов, прокси-серверов и систем обнаружения вторжений.
Итак, процесс мониторинга событий и инцидентов можно начать с достаточно базовых вещей:
Как видите, никакой магии, и даже SIEM-система не нужна. Но выполнение хотя бы этих простых правил и запуск базового мониторинга может стать одним из первых достаточно несложных шагов к вашему движению в экспертные задачи мониторинга и построению собственного Security Operations Center.
Сегодня мы хотим открыть новый цикл статей, задача которого – продемонстрировать, с какими задачами и трудностями сталкиваются все начинающие (и не очень) SOCостроители, и главное – поделиться нашим опытом по их решению.
В этих статьях мы будем касаться разных вопросов и технического, и методического характера, и максимально отделять коммерческое и маркетинговое позиционирование от реальных задач. В наших планах завершить первый цикл статей как раз к SOC-Форуму, чтобы площадка стала одним из мест для обсуждения данных вопросов.
Начнем с самой популярной задачи, без которого сложно представить SOC, – мониторинга инцидентов.
Security monitoring – реальная задача или новая маркетинговая реальность?
Любой опытный безопасник за свою карьеру пережил немало трендов на новые красивые аббревиатуры. Очередные NG-технологии, искусственные интеллектуальные системы, «золотые» и «серебряные» пули защиты от хакеров и таргетированных атак и т.д. Сейчас одним из таких популярных направлений стал мониторинг инцидентов информационной безопасности. При этом эксперты иногда высказываются, что безопасность не требует мониторинга, а требует только активного блокирования. Однако мы считаем иначе – по двум причинам.
Причина первая: динамика развития компаний
«Мир изменился, я чувствую это в воздухе, я чувствую это в воде».
Галадриэль, CSO Лотлориэна
Существуют два глобальных изменения, которые все агрессивнее входят в жизнь каждой компании, обладающих хоть какой-то ИТ-инфраструктурой:
- Инфраструктура изменяется бешеными темпами. В среднем за месяц в компании может появиться 2-3 новых публичных сервиса. За неделю может быть создано до 40-50 новых серверных виртуальных ресурсов, которые в течение пары дней могут из состояния test development без критических данных обрасти ПДн, карточками и коммерческой тайной и отправиться в расширение кластеров mission critical приложений.
- Пользователи все меньше готовы мириться с такими ограничениями, как заблокированные флешки, закрытый доступ в интернет, запрет на собственные устройства в офисе и т. д. И руководство обычно становится на сторону именно таких пользователей, а не безопасника.
Поэтому подход «тащить и не пущать» уже не просто кажется устаревшим, он не применим. Соответственно, остается только попытаться «возглавить процесс»: контролировать подключения к системе и выполняемые на ней действия, фиксировать аномалии и инциденты.
Причина вторая: интеллектуальность атак и средств защиты
«Погоди, Гретель, вот скоро луна взойдет, и станут видны хлебные крошки».
Гензель, 1 level Security Analyst
Попытка взлома, отбитая или заблокированная средством защиты, сегодня уже не является поводом для успокоения, поскольку инструментарий злоумышленников, а следовательно, и сами атаки, непрерывно эволюционируют.
Приведем два простых примера.
1. В компании используется NGFW. Такие системы могут детектировать не только внешние атаки, но и потенциально вредоносную активность внутри сети (например, активность бота). И вот в один прекрасный день NGFW заблокировал попытку одного из хостов подключиться к центру управления бот-сетями вредоносного семейства / отправки информации на сервера, подконтрольные злоумышленникам.
Можно ли утверждать, что на этом инцидент исчерпан? На первый взгляд, да. Наша защита успешно заблокировала подключение, бот не связался с центром управления, и в итоге вредоносная активность в сети не началась. Но давайте копнем глубже: 90% процентов сотрудников компании уже давно пользуются ноутбуками. И если сотрудник решит поработать из дома или из кафе, бот успешно достучится до центра управления, ведь там, за пределами сети предприятия, нет ни NGFW, ни бдительного безопасника. К чему это приведет? На первом этапе – к компрометации всех данных этого ноутбука. На втором – к обновлению протоколов или адресов центра управления бота, что не позволит NGFW успешно блокировать атаку.
2. Уже достаточно давно антивирусные агенты научились выявлять и блокировать хакерские утилиты, например, печально известный mimikatz. И вот мы настроили соответствующую политику в нашей компании и зафиксировали блокировку. На одном из хостов ИТ-администраторов был запущен и заблокирован mimikatz.
Этот пример аналогичен предыдущему – с одной стороны, компрометации учетных записей не произошло, инцидент исчерпан. Но, даже если оставить в стороне ненормальность самой ситуации и желание в ней разобраться (сам ли ИТ-администратор запускал утилиту и для чего), ничто не помешает злоумышленнику еще раз попытаться получить доступ. Он попытается «прибить» процесс антивируса, использует версию, которая антивирусом не определяется, например, при применении powershell-аналогов. В конце концов, просто найдет хост без антивируса и получит интересующую его информацию там.
В итоге, проигнорировав анализ и разбор заблокированной атаки, мы оставляем действия злоумышленников без контроля. И вместо того, чтобы купировать их попытки захватить нашу инфраструктуру, мы оставляем их с развязанными руками, позволяя придумать новый способ атаки и вернуться к ней с ранее захваченных позиций.
Два этих примера доказывают, что оперативный мониторинг и тщательный анализ событий ИБ может не только помочь в выявлении и разборе инцидентов, но и усложнить жизнь злоумышленников.
Говорим мониторинг – подразумеваем SIEM?
Некоторое время назад между темой SOC и мониторинга ставился знак равенства, а дальше он же возникал между понятиями «мониторинг» и «SIEM». И, хотя вокруг этой темы сломано много копий, хочется вернуться к этому вопросу, чтобы он не смущал нас в дальнейшем.
В мировой практике и даже на территории России известны подходы к решению задач мониторинга и построения SOC вообще без применения SIEM. Один из крупнейших и самых успешных SOC прошлого десятилетия был целиком построен на оперативной регулярной работе сотрудников: на высокорегулярной основе дежурная смена анализировала журналы антивируса, прокси, IPS и других средств защиты – где руками, где базовыми скриптами, где умными отчетами. Этот подход позволял закрывать 80% задач baseline мониторинга (к примерам базовых задач и начального подхода я подойду детальнее в следующем разделе).
Так зачем же на самом деле нужна платформа SIEM/Log Management в плоскости задач мониторинга? Попробуем разобрать на примерах.
Use case 1. Собрать все инциденты «в одну кучу».
На первый взгляд эта задача может показаться бесполезной, но, на самом деле, трудно переоценить потребность заказчиков в ее решении. Особенно когда их цель –не обработка каждого детекта со средства защиты, а поиск определенных закономерностей. Например, выявление повторяющихся событий/инцидентов (когда проблема методически не устранена), фиксация странных активностей с одного хоста/на один хост (первые робкие шаги к модному слову kill chain), анализ частотности срабатываний.
Безусловно, для решения столь утилитарной задачи SIEM, по-честному, не нужен. Вполне приемлемым вариантом здесь может стать service desk с учетом заявок и правильная работа с отчетами из него (анализ закономерностей глазами).
Но, тем не менее, когда компания запускает у себя SIEM, ее, как правило мотивирует именно желание собрать все инциденты в едином окне, поэтому включаем этот use case в наш список.
Use case 2. Склеить однотипные инциденты.
Когда речь идет о развивающейся и длительной активности злоумышленника, при неправильной настройке сценария можно столкнуться с явлением под названием «incident storm». Например:
- Сценарий по попытке подбора пароля (более 100 неудачных входов). При попытке ввести пароль 900 раз SIEM создаст, в лучшем случае, 9 инцидентов/кейсов в системе учета (или 9 писем в почте/смс на телефоне – нужное подчеркнуть).
- Сценарий по сканированию сети (не менее 10 хостов по 5 различным портам) – при работе внутреннего сканера будет создано несколько сотен кейсов/писем/смс.
И в этом потоке событий очень легко пропустить инцидент, отличный от указанных активностей. Поэтому правильный SIEM всегда позволит склеить эти активности по ключевым полям, чтобы разбирать их как один общий инцидент.
Use Case 3. Обогатить расследование информацией из дополнительных систем.
После выявления инцидента аналитику обычно предстоит очень большой объем работы по поиску его причин и последствий. Рассмотрим следующий пример: одним из базовых правил мониторинга и контроля во многих международных стандартах является запрет на использование системных неперсонифированных учетных записей в инфраструктуре. И вот перед нами встала задача контролировать вход под учетной записью root на операционной системе Unix. Нужен ли для решения такой задачи SIEM? Безусловно, нет; любой администратор, владеющий основами написания скриптов, с легкостью создаст двухстрочный скрипт, который позволит выявлять такую активность.
Но теперь давайте посмотрим, что нам, как оператору SOC, нужно дальше сделать с этим событием.
Чем отличаются эти два события? Какое из подключений легитимно, а какое нет? Сейчас у нас есть только ip-адрес, с которого выполнялось подключение. Это, безусловно, не позволяет нам локализовать пользователя. Вот как действовали бы мы:
- Определить сегмент и имя машины, а также имя ее владельца – (nslookup, логи DHCP, информация из CMDB, память).


- С помощью локальных логов машины и контроллера домена определить список пользователей, которые были активны на ней во время инициации сессии.

- В идеале – по логам запуска процессов/приложений выяснить, кто из активных пользователей инициировал запуск процесса ssh-клиента на хосте (скриншот) и не было ли в это время удаленной работы с данной машиной, например, через утилиты удаленного администрирования (RAT).
Только получив всю эту информацию, мы можем считать, что в первом приближении определили виновного.
После этого необходимо оценить воздействие на систему, оказанное после входа под системной записью root. При правильно настроенном аудите нам, в принципе, будет достаточно журналов сервера, но есть одно «но»: сам злоумышленник с этими правами мог с легкостью их модифицировать. Что приводит нас к задаче хранения журналов в независимом источнике (одной из задач, которые часто ставят под SIEM). В итоге, анализ этих журналов позволяет оценить проблему и ее критичность.
Безусловно, большую часть этой работы можно выполнить и без SIEM, но тогда на нее уйдет гораздо больше времени, а аналитик столкнется с серьезными ограничениями. Поэтому хотя SIEM и не строго необходим, при проведении расследований он имеет серьезные преимущества.
Use Case 4. Простая и сложная корреляция.
На эту тему написаны уже сотни статей и презентаций, поэтому надолго останавливаться на данном примере не хочется. Скажу еще раз главное: сегодня, чтобы эффективно выявлять и отражать атаки, нужно уметь выявлять корреляции между событиями ИБ. Будет ли это создание и удаление учетной записи в Active Directory в течение подозрительно короткого интервала или выявление продолжительных vpn-сессий (длиннее 8 часов) на межсетевом экране – не важно. Так или иначе, базовыми скриптами или инструментами самого средства защиты эта задача не решается из-за огромного объема проходящих через него событий безопасности. Для решения таких задач и предназначены платформы SIEM.
Итого: подход к задачам мониторинга на первом этапе не обязательно требует SIEM-платформы, но она существенно упрощает жизнь SOC и его операторов. В долгосрочной перспективе, по мере углубления в задачи по выявлению инцидентов, наличие SIEM перестает быть рекомендацией и становится обязательным условием.
Мониторинг – с чего начать?
Отвечая на вопрос в заглавии этого раздела, большинство заказчиков впадает в одно из двух заблуждений.
Единственной задачей SOC и вообще информационной безопасности является борьба с APT или таргетированными атаками. Наша практика показывает, что до выстраивания базовых процессов мониторинга, наведения порядка в инфраструктуре и «причесывания» процессов реагирования ставить столь амбициозную задачу перед собой не стоит.
О мониторинге можно думать только после того, как вся инфраструктура будет накрыта плотным колпаком из средств защиты и самых современных систем ИБ. По нашим наблюдениям, хороший первый результат по повышению уровня ИБ можно получить, обладая минимальным набором средств защиты. Это подтверждает и статистика, которую мы собираем на регулярной основе: например, в первом полугодии 2017 около 67% событий у заказчиков были зафиксированы при помощи основных сервисов ИТ-инфраструктуры и средств обеспечения базовой безопасности – межсетевых экранов и сетевого оборудования, VPN-шлюзов, контроллеров доменов, почтовых серверов, антивирусов, прокси-серверов и систем обнаружения вторжений.
Итак, процесс мониторинга событий и инцидентов можно начать с достаточно базовых вещей:
- Мониторинг периметра – появляющиеся новые хосты на периметре, эксплуатация критичных уязвимостей, подключения к личным кабинетам и административным интерфейсам с неизвестных адресов.
- Контроль доступа в интернет – попытки использования RAT, посещение вредоносных/фишинговых ресурсов и обращение к центрам управления бот-сетями (как правило, информация о них есть в категориях прокси-сервера).
- Антивирусная защита – заражение серверного сегмента или критичных машин пользовательского сегмента, множественные заражения машин, вирусные эпидемии и т.д.
- Использование хакерского и вредоносного ПО (зачастую информация о нем есть в логах антивирусного ПО и выгружается простым отчетом или запросом к базе данных).
- Анализ подключений в рамках удаленного доступа – одновременное подключение из нескольких точек, подключение с иностранных ip и т.д.
- Контроль учетных записей на Active Directory – создание/удаление, повышение привилегий для ранее существовавших учетных записей, создание новых административных групп и т.д.
Как видите, никакой магии, и даже SIEM-система не нужна. Но выполнение хотя бы этих простых правил и запуск базового мониторинга может стать одним из первых достаточно несложных шагов к вашему движению в экспертные задачи мониторинга и построению собственного Security Operations Center.
